
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
上一篇博客,我们已经对基础I/O有了一定的了解,这一篇博客我们继续学习基础I/O准备好了吗~我们发车去探索操作系统的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
理解"一切皆文件"😁
在前面我们一直都在说一个结论,Linux下一切皆文件,那么接下来我们来真正理解一下为什么可以这么说?
前面我们已经提到操作系统对进程会以"先描述,再组织"的方式进行管理,那么操作系统会不会对硬件也进行管理呢?答案是的,操作系统也会对硬件以"先描述,再组织"的方式进行管理~比如使用下面的结构体进行描述:
cpp
struct device
{
int type;
int status;
......
struct list_head node;
}每一个硬件都有对应的操作方式,不同设备有不同的操作实现:
cpp
// 磁盘设备
void read_disk() { ... } // 读取磁盘扇区
void write_disk() { ... } // 写入磁盘数据
// 网卡设备
void read_network() { ... } // 接收网络数据包
void write_network() { ... }// 发送网络数据包
// 键盘设备
void read_keyboard() { ... }// 读取按键输入
// 键盘通常没有write操作
// 显示器设备
void write_display() { ... }// 输出显示内容
// 显示器通常没有read操作有的设备只需要进行读操作,有的设备只需要进行写操作,有的设备需要进行读写操作,这类似于我们之前学习的多态;那么这么多的实现,用户直接使用起来很不方便,所以尽管底层实现千差万别,但用户只需要掌握一套API:
cpp
// 操作任何"文件"都使用相同的函数
read(fd, buf, count); // 从键盘、磁盘、网络读取
write(fd, buf, count); // 向显示器、磁盘、网络写入
open(path, flags); // 打开文件、设备
close(fd); // 关闭任何资源那么我们把所有输入输出资源(设备、管道、套接字等)都抽象为文件 ,用户 统一的操作接口进行使用~所以一切皆文件事实上站在进程的视角【进程访问设备】,在进程眼里一切皆文件~
cpp
// 进程控制块
struct task_struct {
struct files_struct *files; // 指向文件表
};
// 文件表
struct files_struct {
struct file *fd_array[]; // 文件描述符数组
};
// 文件对象
struct file {
struct inode *f_inode; // 文件属性(元数据)
const struct file_operations *f_op; // 操作方法集
// ... 其他字段
};
// 文件操作表(核心!)
struct file_operations {
ssize_t (*read)(struct file *, char __user *, size_t, loff_t *);
ssize_t (*write)(struct file *, const char __user *, size_t, loff_t *);
int (*open)(struct inode *, struct file *);
int (*release)(struct inode *, struct file *);
// ... 几十个操作函数指针
};工作流程图如下:
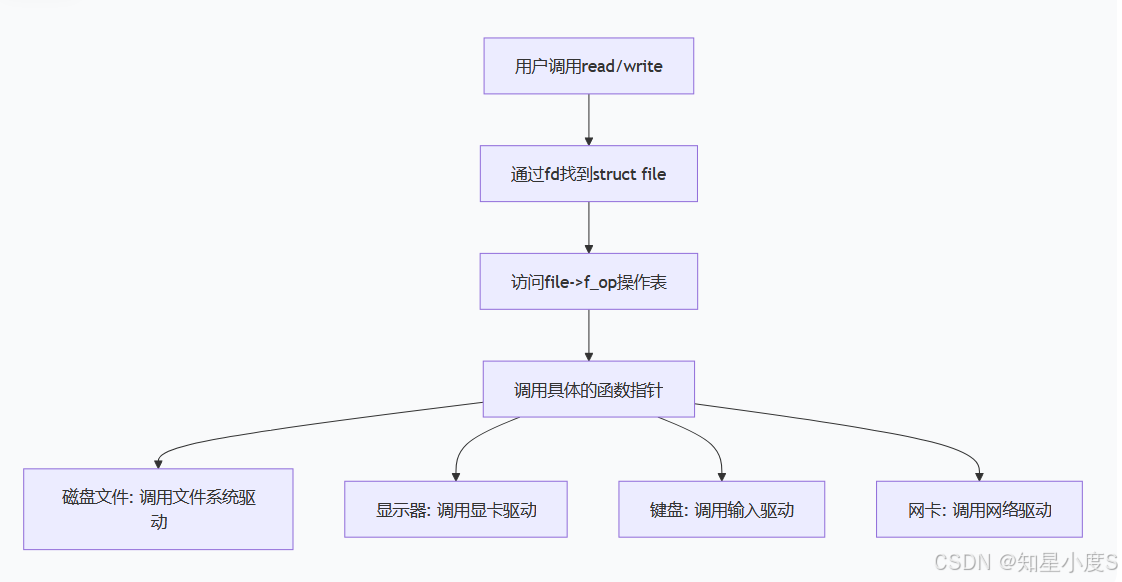
这也就说明了:计算机里面的一切问题,都可以通过添加一个软件层来实现~
缓冲区机制😁
前面我们提到了Linux打开文件,会为我们打开三个文件,创建struct file,那么文件有三个核心:1、文件属性,2、文件内核缓冲区,3、底层设备文件操作表~
接下来,我们来进行一个简单的测试:
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello xiaodu! hello world!");
sleep(5);
return 0;
}
我们可以观察到的程序运行现象是不会立即打印"hello xiaodu!hello world!",等五秒后程序进行打印~程序是按照顺序进行执行的,先执行完printf后再执行sleep,sleep期间数据没有进行输出打印到显示器上,那么数据存放在哪里呢?
答案是存放在FILE缓冲区【语言级别】,注意并不是内核中的缓冲区~之前我们也见过FILE*,那么这个FILE究竟是什么呢?

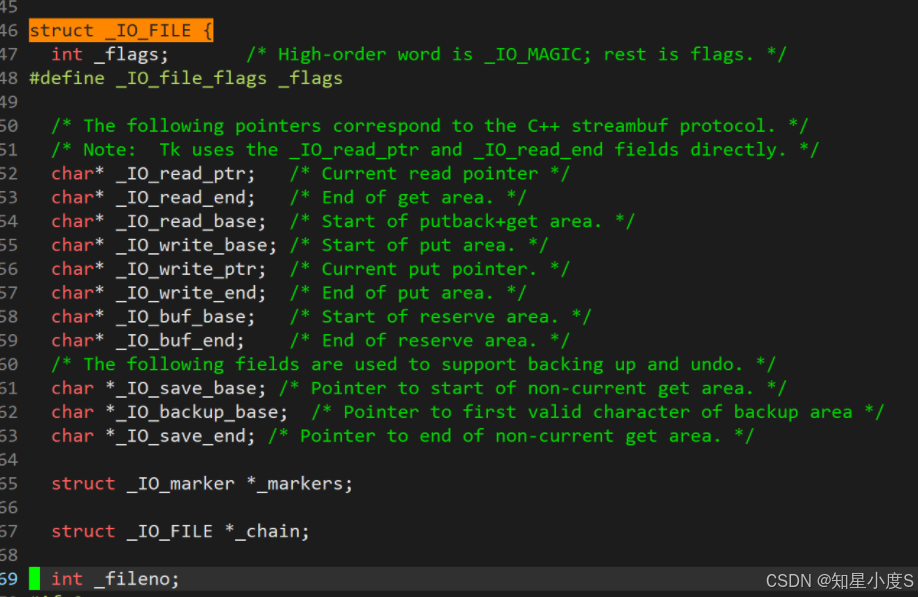
FILE事实上是一个结构体,原型是struct _IO_FILE 。C语言中,所有的输入输出格式化操作都是通过FILE来完成的;我们访问文件(包括标准输入 stdin、标准输出 stdout、标准错误 stderr)都是通过**FILE***指针来进行的。图片展示C库实现中的 _IO_FILE 结构体定义片段,最关键的部分是用于管理缓冲区的指针:
输入缓冲区相关:
_IO_read_ptr:当前读取位置
_IO_read_end:读取区域的结束位置
_IO_read_base:读取区域的起始位置
输出缓冲区相关:
_IO_write_base:写入区域的起始位置
_IO_write_ptr:当前写入位置
_IO_write_end:写入区域的结束位置
缓冲区基础:
_IO_buf_base:整个缓冲区的起始地址
_IO_buf_end:整个缓冲区的结束地址
接下来,我们再来理解一下缓冲区~
缓冲区本质上是一段内存空间 ,用于临时存储数据,允许数据在缓冲区中累积,然后一次性刷新(输出或写入),从而减少I/O操作的次数。这种方式变相地提高了效率,允许进程在单位时间内完成更多工作。
刷新策略 (由语言层面控制):无缓冲 :立即刷新数据。
行缓冲 :在遇到换行符时刷新(常用于显示器输出)。
全缓冲 :当缓冲区写满时才刷新(常用于普通文件操作)。
缓冲区的刷新时机:①进程退出时,主动刷新缓冲区。
②进程强制刷新,例如使用fflush(stdout)函数。
接下来,我们用寄送快递的例子来进一步理解缓冲区:
- 缓冲区的本质
比喻:缓冲区就像你家楼下的菜鸟驿站或快递代收点。
解释:它是一段公共的、临时的存储空间(内存),用于存放数据(快递)。
- 没有缓冲区的问题(无缓冲 / 立即刷新)
场景:如果没有驿站,你每网购一个商品,快递员就必须立即、单独给你送一次货。
问题:快递员(系统)频繁地奔波在路上,效率极低,大部分时间都浪费在"上路"这个动作上。这对应着 无缓冲,立即刷新 策略,每次有数据都要进行一次I/O操作,系统开销巨大。
- 有缓冲区的工作方式(有缓冲 / 写满刷新)
场景:有了驿站后,快递员会把你的多个包裹,以及整个小区所有人的包裹,先集中到驿站。然后驿站再统一进行一次分发管理。
优势:
对快递员(输出方):他不用再为每一个小包裹跑一趟,而是攒够一车再送一次,大大减少了"上路"的次数。这就是所谓的 "一次刷新多次数据,变相减少I/O次数"。
对你(进程):你可以一次性从驿站取走所有快递,或者在方便的时候再去取。这让你在单位时间内能处理更多事情,也就是 "允许进程单位时间内,做更多的工作",从而 "变相提高了效率"。
- 缓冲区的刷新策略(什么时候"送货")
这个比喻同样可以解释不同的刷新策略:
行刷新(显示器):就像一件加急快递。当你输入完一行(按下回车),这个"完整的指令"需要立即被看到和执行,所以立即"送货"(刷新)。
全缓冲(文件):就像普通的海运大集装箱。一定要等箱子完全装满了,才最划算,所以会等缓冲区写满再一次性"发货"(刷新到磁盘)。
- 强制刷新(特殊情况)
比喻:你突然有一个包裹必须立刻拿到,等不到驿站的统一配送了。
解释:这时你就需要主动去驿站取件,或者打电话催促。在代码中,这就是调用 fflush(stdout) 来强制立即刷新缓冲区。
所以缓冲区事实上是一个"中转站",它通过"攒一波再处理"的方式,将多次零碎的、高成本的I/O操作,合并成一次或少数几次批量操作,从而极大地提升了数据处理的整体效率。
接下来,我们写一段代码来进行测试一下:
cpp
#include <stdio.h>
#include <unistd.h>
int main() {
// 测试行缓冲(终端设备)
printf("Line 1 without newline"); // 不会立即显示
sleep(2);
printf(" -> Line 1 continued\n"); // 遇到换行符,立即显示
// 测试全缓冲(文件重定向时)
fprintf(stdout, "This may be buffered");
sleep(2);
fprintf(stdout, " until newline or flush\n");
// 测试无缓冲(stderr)
fprintf(stderr, "Error: immediate output");
sleep(2);
fprintf(stderr, " without buffering\n");
// 手动刷新缓冲区
printf("This waits for flush");
fflush(stdout); // 强制刷新
sleep(2);
printf(" - now continued\n");
return 0;
}
我这里的显示可能不太明显,大家可以在自己的电脑上测试一下~
观察到的现象是无换行符的printf会等待2秒后才显示;stderr的消息会立即显示,不受sleep影响;fflush会立即刷新缓冲区~
前面我们一直在说FILE这个语言级别的缓冲区,那么为什么我们要使用这个语言级别缓冲区呢?直接在系统上进行操作不好吗?这是因为:直接使用系统调用进行I/O效率低下,因为每次调用都有开销。C标准库通过引入FILE和缓冲区机制,减少系统调用次数,从而提升效率。
所以我们就可以知道C语言执行I/O的流程(以printf为例):
①格式化:将数据(如int a = 12345)按格式(%d)转换成字符串。
②写入缓冲区:将格式化后的字符串写入FILE结构体管理的输出缓冲区(outbuffer)中。
③刷新判断:根据刷新策略(立即、行缓冲、全缓冲)判断是否需要将缓冲区数据实际写出。
④系统调用:当需要刷新时,最终调用write等系统调用,将数据交给操作系统。
接下来,我们来看看下面这一段代码:
cpp
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
printf("=== Testing fork with buffers ===\n");
// C库函数(有缓冲区)
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
fwrite("hello fwrite\n", 1, 13, stdout);
// 系统调用(无缓冲区)
write(1, "hello write(syscall)\n", 21);
// 创建子进程
pid_t pid = fork();
if (pid == 0)
{
printf("Child process exiting\n");
}
else
{
printf("Parent process exiting\n");
}
return 0;
}运行程序结果:
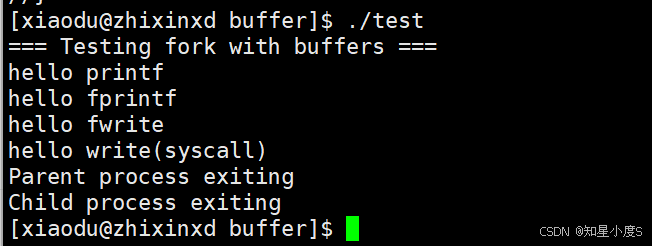
一切正常!
重定向到文件中:
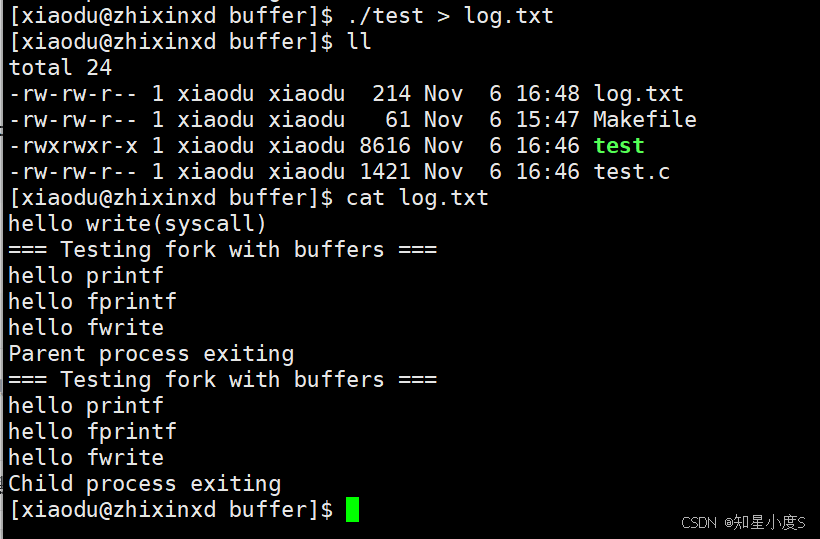
神奇的现象发生了,系统调用write只输出1次,而库函数在有缓冲区的情况下输出2次,并且系统调用write会先进行输出~
①为什么系统调用只输出一次,而库函数输出两次?
因为fork创建子进程时,会复制父进程未刷新的C库缓冲区。重定向到文件后,stdout变为全缓冲 【之前终端输出是行缓冲】,数据暂存缓冲区而未写入。父子进程退出时分别刷新各自缓冲区 ,导致printf等库函数输出两次。系统调用write无用户态缓冲,故只输出一次。我们也可以看到代码中分别是父进程和子进程~
②为什么系统调用write先进行输出?
因为系统调用write绕过用户态缓冲区,直接进入内核 。当数据重定向到文件时,C库的printf/fprintf/fwrite使用全缓冲区,数据暂存于用户空间而不立即写入。write系统调用无用户态缓冲 ,数据立即提交给内核并写入磁盘,因此在文件中最先出现。
总结【一般:C库函数写入文件 全缓冲**,写入显示器** 行缓冲**】**
终端 :每行输出后立即刷新,fork前数据已写入设备
重定向到文件 :数据积压在缓冲区,fork时被复制,退出时双重刷新
简单实现libc库😁
知道了这些理论基础,接下来我们来实现一个简单的libc库~
mystdio.h😝
cpp
#ifndef __MYSTDIO_H_
#define __MYSTDIO_H_
#define FLUSH_NONE 1
#define FLUSH_LINE 2
#define FLUSH_FULL 4
#define SIZE 1024
#define UMASK 0666
#define FORCE 1
#define NORMAL 2
typedef struct MY_IO_FILE
{
int fileno;//文件描述符
int flag;//刷新方式
char outbuffer[SIZE];//缓冲区
int cur;//当前已经使用的空间
int cap;//容量大小
}MYFILE;
MYFILE* myfopen(const char* name,const char* mode);
int mywrite(const char* s,int size,MYFILE* fp);
void myfclose(MYFILE* fp);
void myfflush(MYFILE* fp);
#endif 我们实现了一个简化版的文件操作库。核心是MYFILE结构体,包装了文件描述符并添加一个1024字节的缓冲区。提供四个函数:myfopen打开文件,mywrite写入数据(先攒在缓冲区里),myfflush强制把缓冲区的数据写入文件,myfclose关闭文件前会自动刷新缓冲区。同时我们通过三种缓冲策略(无缓冲/行缓冲/全缓冲)来平衡性能和实时性,本质上是在用户层实现了类似fwrite的缓冲机制。
mystdio.c😝
cpp
#include "mystdio.h"
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
#include <stdlib.h>
MYFILE* myfopen(const char* name,const char* mode)
{
int fd = -1;
//不同打开方式打开文件
if(strcmp(mode,"w")==0)
{
fd = open(name,O_CREAT | O_WRONLY | O_TRUNC,UMASK);
}
else if(strcmp(mode,"r")==0)
{
fd = open(name,O_RDONLY);
}
else if(strcmp(mode,"a")==0)
{
fd = open(name,O_CREAT | O_WRONLY | O_APPEND,UMASK);
}
else if(strcmp(mode,"a+")==0)
{
fd = open(name,O_CREAT | O_RDWR | O_APPEND,UMASK);
}
else
{
//...
}
if(fd < 0)
{
return NULL;
}
MYFILE* fp = (MYFILE*)malloc(sizeof(MYFILE));
if(fp == NULL)
{
return NULL;
}
fp->fileno = fd;
fp->flag = FLUSH_LINE;
fp->cur = 0;
fp->cap = SIZE;
fp->outbuffer[0]=0;
return fp;
}
static void my_fflush_core(MYFILE* fp,int f)
{
if(fp->cur<0)
{
return;
}
if(f == FORCE)//强制刷新
{
write(fp->fileno,fp->outbuffer,fp->cur);
fp->cur=0;
return;
}
else
{
if((fp->flag & FLUSH_LINE)&&(fp->outbuffer[fp->cur-1]=='\n'))
{
write(fp->fileno,fp->outbuffer,fp->cur);
fp->cur=0;
return;
}
else if((fp->flag & FLUSH_FULL)&&(fp->cur==fp->cap))
{
write(fp->fileno,fp->outbuffer,fp->cur);
fp->cur=0;
return;
}
else
{
//....
}
}
}
int mywrite(const char* s,int size,MYFILE* fp)
{
//fwrite的本质是拷贝
memcpy(fp->outbuffer + fp->cur, s ,size);
fp->cur += size;
my_fflush_core(fp,NORMAL);
return size;
}
void myfclose(MYFILE* fp)
{
if(fp->fileno>0)
{
myfflush(fp);//用户-->C
fsync(fp->fileno);//C-->内核
close(fp->fileno);
free(fp);
}
}
void myfflush(MYFILE* fp)
{
my_fflush_core(fp,NORMAL);
}这段代码就是对文件操作的具体实现,实现了一个自定义的文件I/O库,核心功能是带缓冲的文件写入。
主要工作流程:
myfopen - 根据模式(w/r/a/a+)打开文件,创建MYFILE对象并初始化缓冲区
mywrite - 将数据先拷贝到用户层缓冲区,然后根据缓冲策略决定是否写入磁盘
缓冲策略在my_fflush_core中实现:
行缓冲(FLUSH_LINE):遇到换行符就写入
全缓冲(FLUSH_FULL):缓冲区满了才写入
强制刷新(FORCE):立即写入
myfclose - 先刷新剩余数据到C库,再通过fsync确保数据落盘,最后释放资源
简单说就是:写数据时先"攒着",等满足条件(换行/缓冲区满/强制刷新)再一次性写入磁盘,减少系统调用次数,提高I/O效率。我们对标准库fwrite/fclose等函数完成了简化实现。
test.c😝
cpp
#include "mystdio.h"
#include <string.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
MYFILE* fp = myfopen("log.txt","w");
if(fp == NULL )
{
return 1;
}
char data[128];
int cnt=10;
const char* s = "hello xiaodu!";
while(cnt--)
{
snprintf(data,sizeof(data),"%s:%d\n",s,cnt);
mywrite(data,strlen(data),fp);
sleep(2);
}
myfclose(fp);
return 0;
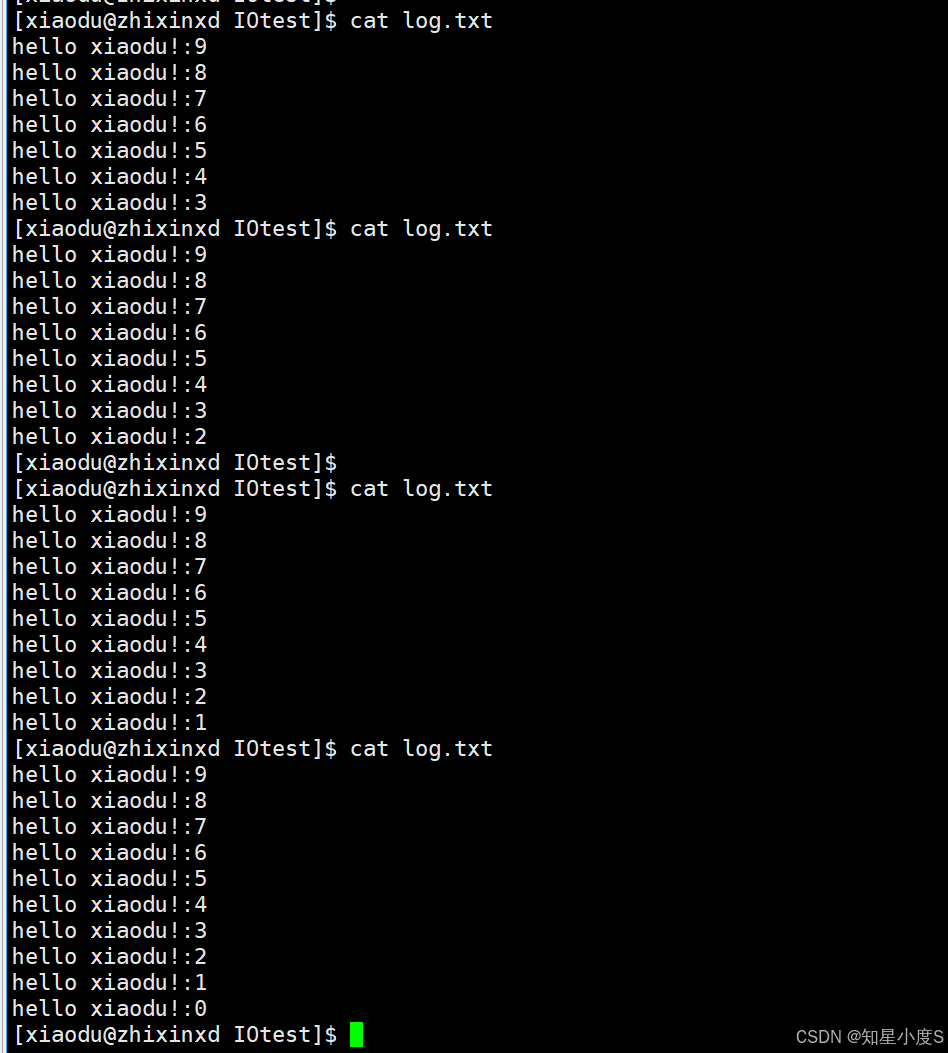
}我们通过这段代码测试自定义文件库的功能:创建一个文件,每隔2秒写入一行"hello xiaodu!"加上递减的数字,共写入10次。最后关闭文件。同时采用行缓冲模式,每次写入的换行符都会触发立即刷新到磁盘,所以即使程序运行20秒,也能实时看到文件内容更新。
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨