我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
小米不仅造车,还造模型?
2024 年 12 月,当所有人还在关注小米汽车的时候,小米却悄然开源了一款震撼整个 AI 界的大语言模型------MiMo-V2-Flash。这款拥有 309B总参数、15B激活参数 的超大规模模型,不仅在性能上达到了世界顶尖水平,更在深度思考能力上完胜 DeepSeek,重新定义了 AI 模型的效率天花板。
本文将详细介绍这款模型的技术特点、性能表现以及使用方式。
MiMo-V2-Flash
MiMo-V2-Flash 是一个混合专家(MoE)语言模型,拥有 309B总参数 和 15B激活参数。专为高速推理和智能体工作流设计,它采用了新颖的混合注意力架构和多 Token 预测(MTP)技术,在显著降低推理成本的同时实现了最先进的性能。
1. 介绍
MiMo-V2-Flash 在长上下文建模能力和推理效率之间创造了新的平衡。主要特性包括:
- 混合注意力架构:以 5:1 的比例交织滑动窗口注意力(
SWA)和全局注意力(GA),采用激进的 128-token 窗口。通过可学习的attention sink bias(注意力沉降偏置),在保持长上下文性能的同时,将KV缓存存储减少了近 6 倍。 - 多 Token 预测(
MTP):配备了轻量级MTP模块(每块 0.33B 参数),使用密集FFN。这将推理期间的输出速度提升了 3 倍,并有助于加速RL训练中的rollout。 - 高效预训练:使用
FP8混合精度在 27T token 上训练,原生 32k 序列长度。上下文窗口支持最长 256k。 - 智能体能力:后训练利用多教师在线策略蒸馏(
MOPD)和大规模智能体RL,在SWE-Bench和复杂推理任务上实现了卓越性能。
2. 模型下载
| 模型 | 总参数 | 激活参数 | 上下文长度 | 下载地址 |
|---|---|---|---|---|
| MiMo-V2-Flash-Base | 309B | 15B | 256k | 🤗 HuggingFace |
| MiMo-V2-Flash | 309B | 15B | 256k | 🤗 HuggingFace |
重要提示:我们还开源了 3 层
MTP权重,以促进社区研究。
3. 评估结果
基础模型评估
MiMo-V2-Flash-Base 在标准基准测试中展现出强大的性能,超越了参数量显著更大的模型。
| 类别 | 基准测试 | 设置/长度 | MiMo-V2-Flash Base | Kimi-K2 Base | DeepSeek-V3.1 Base | DeepSeek-V3.2 Exp Base |
|---|---|---|---|---|---|---|
| 参数 | 激活参数 / 总参数 | - | 15B / 309B | 32B / 1043B | 37B / 671B | 37B / 671B |
| 通用 | BBH | 3-shot | 88.5 | 88.7 | 88.2 | 88.7 |
| MMLU | 5-shot | 86.7 | 87.8 | 87.4 | 87.8 | |
| MMLU-Redux | 5-shot | 90.6 | 90.2 | 90.0 | 90.4 | |
| MMLU-Pro | 5-shot | 73.2 | 69.2 | 58.8 | 62.1 | |
| DROP | 3-shot | 84.7 | 83.6 | 86.3 | 86.6 | |
| ARC-Challenge | 25-shot | 95.9 | 96.2 | 95.6 | 95.5 | |
| HellaSwag | 10-shot | 88.5 | 94.6 | 89.2 | 89.4 | |
| WinoGrande | 5-shot | 83.8 | 85.3 | 85.9 | 85.6 | |
| TriviaQA | 5-shot | 80.3 | 85.1 | 83.5 | 83.9 | |
| GPQA-Diamond | 5-shot | 55.1 | 48.1 | 51.0 | 52.0 | |
| SuperGPQA | 5-shot | 41.1 | 44.7 | 42.3 | 43.6 | |
| SimpleQA | 5-shot | 20.6 | 35.3 | 26.3 | 27.0 | |
| 数学 | GSM8K | 8-shot | 92.3 | 92.1 | 91.4 | 91.1 |
| MATH | 4-shot | 71.0 | 70.2 | 62.6 | 62.5 | |
| AIME 24&25 | 2-shot | 35.3 | 31.6 | 21.6 | 24.8 | |
| 代码 | HumanEval+ | 1-shot | 70.7 | 84.8 | 64.6 | 67.7 |
| MBPP+ | 3-shot | 71.4 | 73.8 | 72.2 | 69.8 | |
| CRUXEval-I | 1-shot | 67.5 | 74.0 | 62.1 | 63.9 | |
| CRUXEval-O | 1-shot | 79.1 | 83.5 | 76.4 | 74.9 | |
| MultiPL-E HumanEval | 0-shot | 59.5 | 60.5 | 45.9 | 45.7 | |
| MultiPL-E MBPP | 0-shot | 56.7 | 58.8 | 52.5 | 50.6 | |
| BigCodeBench | 0-shot | 70.1 | 61.7 | 63.0 | 62.9 | |
| LiveCodeBench v6 | 1-shot | 30.8 | 26.3 | 24.8 | 24.9 | |
| SWE-Bench (AgentLess) | 3-shot | 30.8 | 28.2 | 24.8 | 9.4* | |
| 中文 | C-Eval | 5-shot | 87.9 | 92.5 | 90.0 | 91.0 |
| CMMLU | 5-shot | 87.4 | 90.9 | 88.8 | 88.9 | |
| C-SimpleQA | 5-shot | 61.5 | 77.6 | 70.9 | 68.0 | |
| 多语言 | GlobalMMLU | 5-shot | 76.6 | 80.7 | 81.9 | 82.0 |
| INCLUDE | 5-shot | 71.4 | 75.3 | 77.2 | 77.2 | |
| 长上下文 | NIAH-Multi | 32K | 99.3 | 99.8 | 99.7 | 85.6 |
| 64K | 99.9 | 100.0 | 98.6 | 85.9 | ||
| 128K | 98.6 | 99.5 | 97.2 | 94.3 | ||
| 256K | 96.7 | - | - | - | ||
| GSM-Infinite Hard | 16K | 37.7 | 34.6 | 41.5 | 50.4 | |
| 32K | 33.7 | 26.1 | 38.8 | 45.2 | ||
| 64K | 31.5 | 16.0 | 34.7 | 32.6 | ||
| 128K | 29.0 | 8.8 | 28.7 | 25.7 |
- 表示模型可能无法遵循提示或格式。
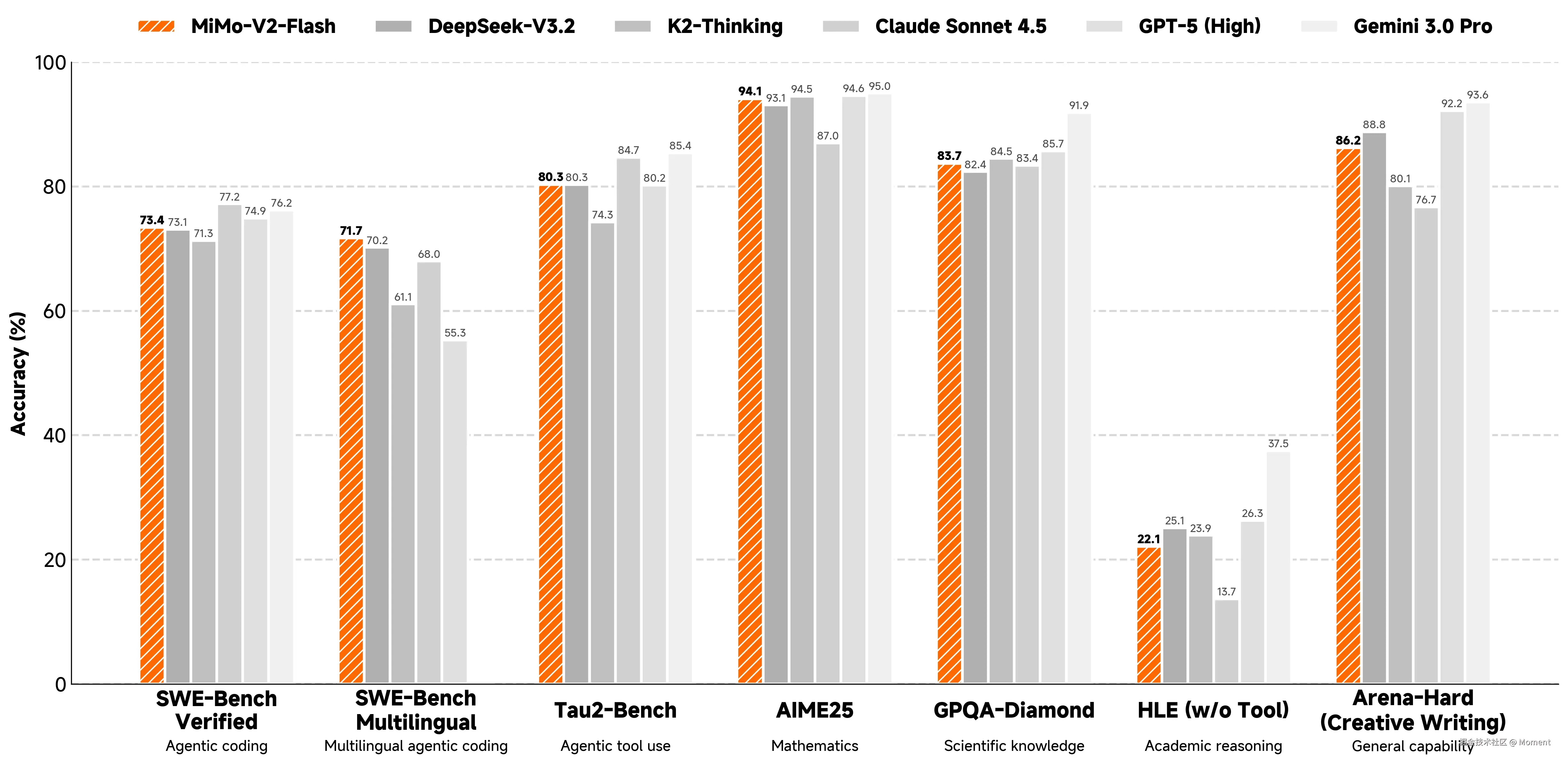
后训练模型评估
通过采用 MOPD 和智能体 RL 的后训练范式,模型在推理和智能体性能上达到了最先进水平。
| 基准测试 | MiMo-V2 Flash | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | Gemini-3.0 Pro | Claude Sonnet 4.5 | GPT-5 High |
|---|---|---|---|---|---|---|
| 推理 | ||||||
| MMLU-Pro | 84.9 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 |
| GPQA-Diamond | 83.7 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 |
| HLE (无工具) | 22.1 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 |
| AIME 2025 | 94.1 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 |
| HMMT Feb. 2025 | 84.4 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 |
| LiveCodeBench-v6 | 80.6 | 83.1 | 83.3 | 90.7 | 64.0 | 84.5 |
| 通用写作 | ||||||
| Arena-Hard (困难提示) | 54.1 | 71.9 | 53.4 | 72.6 | 63.3 | 71.9 |
| Arena-Hard (创意写作) | 86.2 | 80.1 | 88.8 | 93.6 | 76.7 | 92.2 |
| 长上下文 | ||||||
| LongBench V2 | 60.6 | 45.1 | 58.4 | 65.6 | 61.8 | - |
| MRCR | 45.7 | 44.2 | 55.5 | 89.7 | 55.4 | - |
| 代码智能体 | ||||||
| SWE-Bench Verified | 73.4 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 |
| SWE-Bench Multilingual | 71.7 | 61.1 | 70.2 | - | 68.0 | 55.3 |
| Terminal-Bench Hard | 30.5 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 |
| Terminal-Bench 2.0 | 38.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 |
| 通用智能体 | ||||||
| BrowseComp | 45.4 | - | 51.4 | - | 24.1 | 54.9 |
| BrowseComp (带上下文管理) | 58.3 | 60.2 | 67.6 | 59.2 | - | - |
| τ²-Bench | 80.3 | 74.3 | 80.3 | 85.4 | 84.7 | 80.2 |
4. 模型架构
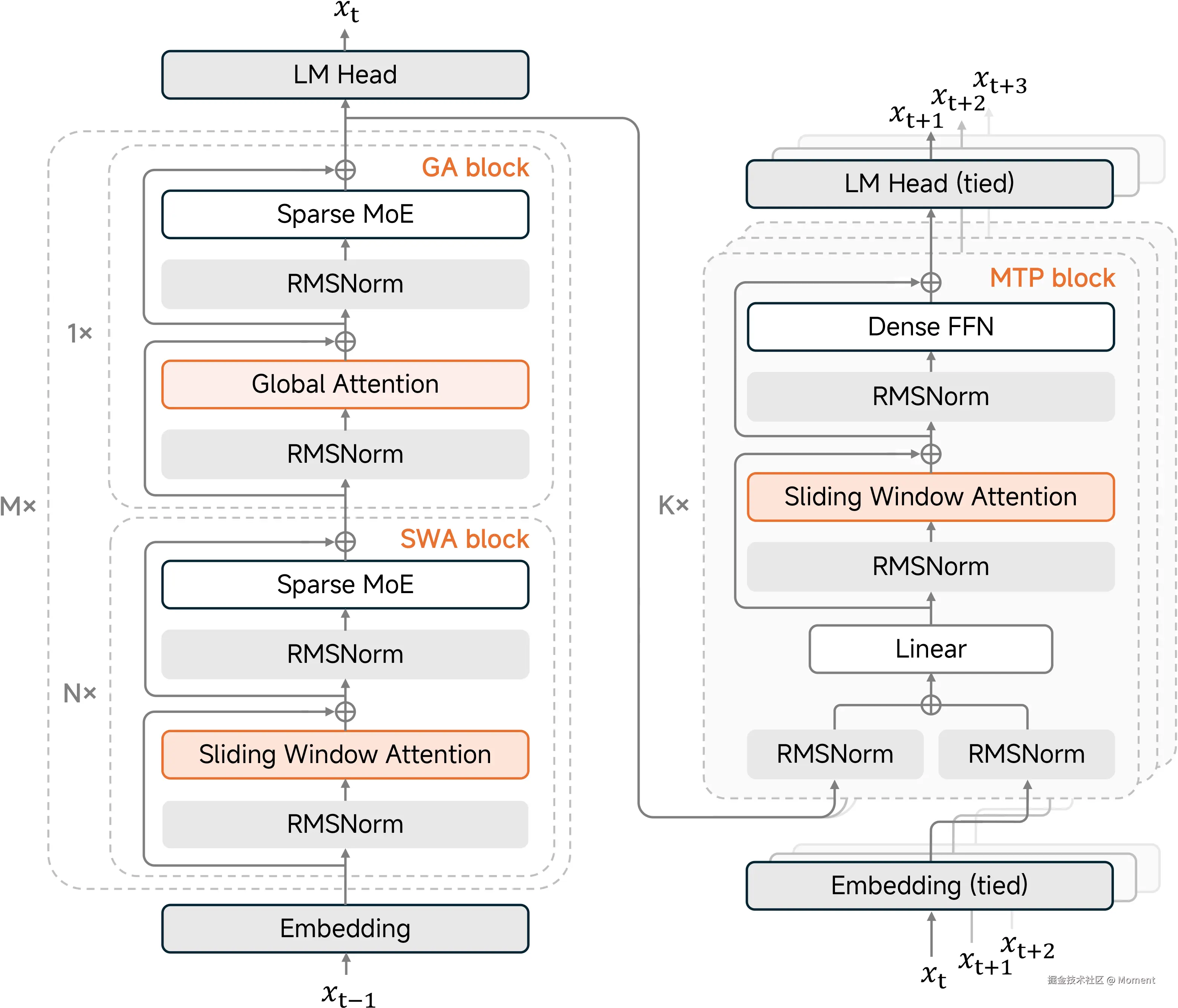
混合滑动窗口注意力
MiMo-V2-Flash 通过交织局部滑动窗口注意力(SWA)和全局注意力(GA)来解决长上下文的平方复杂度问题。
- 配置:M=8 个混合块的堆叠。每个块包含 N=5 个
SWA层,之后是 1 个GA层。 - 效率:
SWA层使用 128 个 token 的窗口大小,显著减少了KV缓存。 - 沉降偏置:应用可学习的注意力沉降偏置,即使在激进的窗口大小下也能保持性能。
轻量级多 Token 预测(MTP)
与传统的推测解码不同,我们的 MTP 模块原生集成用于训练和推理。
- 结构:使用密集
FFN(而非MoE)和SWA(而非GA)来保持较低的参数量(每块 0.33B)。 - 性能:促进自推测解码,将生成速度提升 3 倍,并缓解小批量
RL训练期间的GPU空闲问题。
5. 后训练技术亮点
MiMo-V2-Flash 利用专门设计的后训练流程,通过创新的蒸馏和强化学习策略最大化推理和智能体能力。
5.1 多教师在线策略蒸馏(MOPD)
我们引入了 多教师在线策略蒸馏(MOPD),这是一种将知识蒸馏重新定义为强化学习过程的新范式。
- 密集 Token 级指导:与依赖稀疏序列级反馈的方法不同,
MOPD利用领域特定的专家模型(教师)在每个 token 位置提供监督。 - 在线策略优化:学生模型从自己生成的响应中学习,而不是从固定数据集学习。这消除了暴露偏差,并确保更小、更稳定的梯度更新。
- 固有的奖励鲁棒性:奖励源于学生和教师之间的分布差异,使该过程天然抵抗奖励黑客攻击。
5.2 扩展智能体强化学习
我们大幅扩展了智能体训练环境,以提高智能和泛化能力。
- 大规模代码智能体环境:我们利用真实世界的 GitHub 问题创建了超过 100,000 个可验证任务。我们的自动化流程维护着一个能够运行超过 10,000 个并发 pod 的
Kubernetes集群,环境设置成功率达 70%。 - Web 开发的多模态验证器:对于 Web 开发任务,我们采用基于视觉的验证器,通过录制的视频而非静态截图来评估代码执行。这减少了视觉幻觉并确保功能正确性。
- 跨域泛化:我们的实验表明,在代码智能体上的大规模
RL训练能有效泛化到其他领域,提升数学和通用智能体任务的性能。
5.3 先进的强化学习基础设施
为了支持大规模 MoE 模型的高吞吐量 RL 训练,我们在 SGLang 和 Megatron-LM 基础上实现了多项基础设施优化。
- Rollout 路由重放(
R3):解决MoE路由在推理和训练之间的数值精度不一致问题。R3在训练阶段重用rollout中的确切路由专家,以可忽略的开销确保一致性。 - 请求级前缀缓存:在多轮智能体训练中,此缓存存储先前轮次的
KV状态和路由专家。它避免了重新计算,并确保跨轮次的采样一致性。 - 细粒度数据调度器:我们扩展了
rollout引擎以调度细粒度序列而非微批次。结合部分rollout,这显著减少了长尾任务导致的GPU空闲。 - 工具箱和工具管理器:使用
Ray actor池的两层设计来处理资源争用。它消除了工具执行的冷启动延迟,并将任务逻辑与系统策略隔离。
6. 推理与部署
MiMo-V2-Flash 支持 FP8 混合精度推理。我们推荐使用 SGLang 以获得最佳性能。
使用建议:我们推荐将采样参数设置为 temperature=0.8, top_p=0.95。
使用 SGLang 快速开始
bash
pip install sglang
# 启动服务器
python3 -m sglang.launch_server \
--model-path XiaomiMiMo/MiMo-V2-Flash \
--served-model-name mimo-v2-flash \
--pp-size 1 \
--dp-size 2 \
--enable-dp-attention \
--tp-size 8 \
--moe-a2a-backend deepep \
--page-size 1 \
--host 0.0.0.0 \
--port 9001 \
--trust-remote-code \
--mem-fraction-static 0.75 \
--max-running-requests 128 \
--chunked-prefill-size 16384 \
--reasoning-parser qwen3 \
--tool-call-parser mimo \
--context-length 262144 \
--attention-backend fa3 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--enable-mtp
# 发送请求
curl -i http://localhost:9001/v1/chat/completions \
-H 'Content-Type:application/json' \
-d '{
"messages" : [{
"role": "user",
"content": "Nice to meet you MiMo"
}],
"model": "mimo-v2-flash",
"max_tokens": 4096,
"temperature": 0.8,
"top_p": 0.95,
"stream": true,
"chat_template_kwargs": {
"enable_thinking": true
}
}'注意事项
重要提示:在带有多轮工具调用的思考模式中,模型会在
tool_calls旁边返回一个reasoning_content字段。要继续对话,用户必须在每个后续请求的messages数组中保留所有历史reasoning_content。
重要提示:强烈推荐使用以下系统提示,请从英文和中文版本中选择。
英文版本
plaintext
You are MiMo, an AI assistant developed by Xiaomi.
Today's date: {date} {week}. Your knowledge cutoff date is December 2024.中文版本
plaintext
你是MiMo(中文名称也是MiMo),是小米公司研发的AI智能助手。
今天的日期:{date} {week},你的知识截止日期是2024年12月。7. 引用
如果您觉得我们的工作有帮助,请引用我们的技术报告:
bibtex
@misc{mimo2025flash,
title={MiMo-V2-Flash Technical Report},
author={LLM-Core Xiaomi},
year={2025},
url={https://github.com/XiaomiMiMo/MiMo-V2-Flash/paper.pdf}
}8. 相关链接
- 🤗 HuggingFace 模型页面
- 📔 技术报告
- 📰 官方博客
- 🗨️ 在线体验 - Xiaomi MiMo Studio
- 🎨 API 平台
- 💻 GitHub 仓库
9. 结论
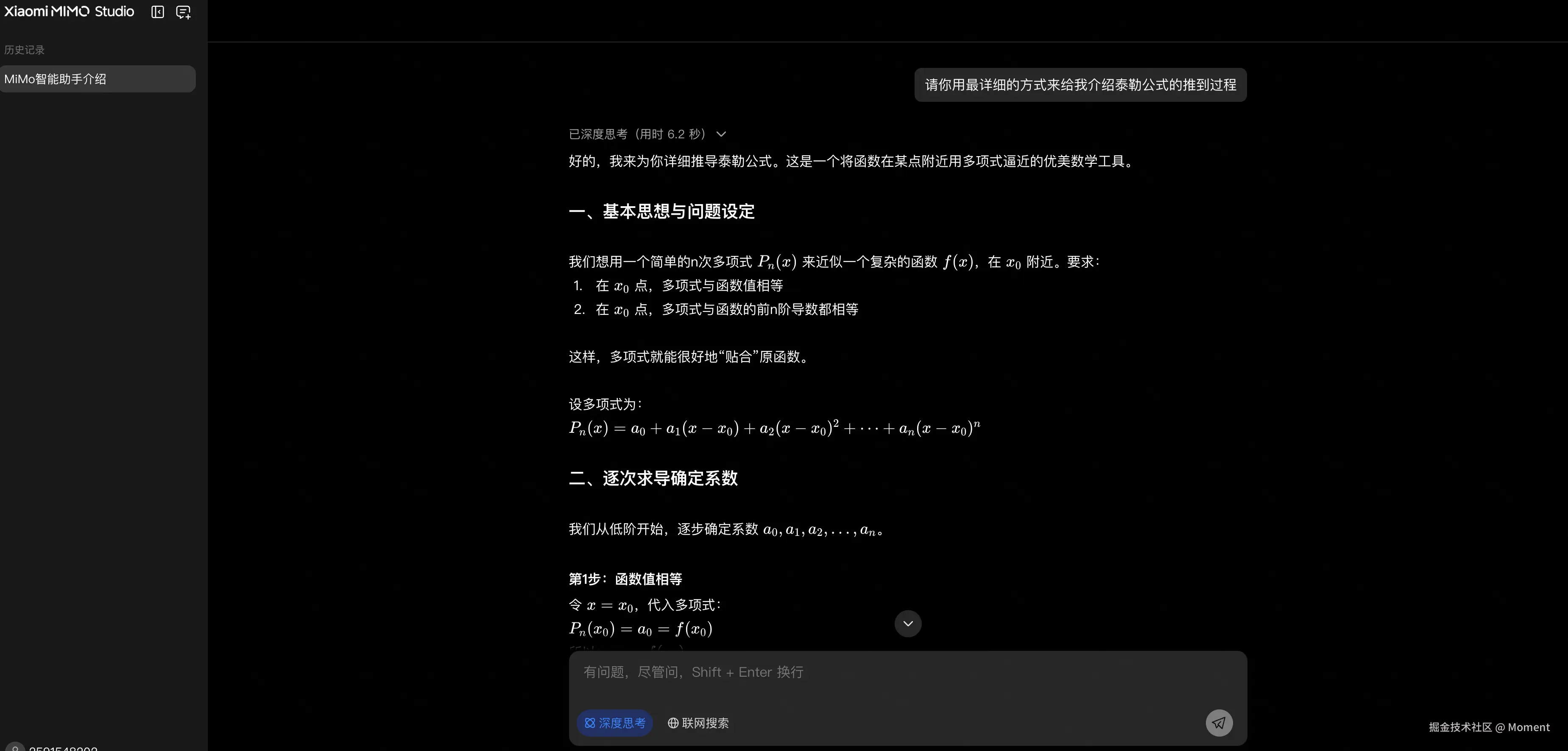
MiMo-V2-Flash 不仅在基准测试中展现出卓越的性能,更在实际应用场景中展现出独特的优势。特别是在深度思考能力方面,通过对比测试可以明显看出,在基本相同的输出结果质量下,小米 MiMo-V2-Flash 的深度思考功能相比 DeepSeek 具有显著优势。
这一优势体现在多个方面:
- 思考深度 :
MiMo-V2-Flash能够进行更深入、更系统的思考,展现出更强的逻辑推理能力 - 思考效率:在保证输出质量的前提下,能够更快速地完成深度思考过程
- 思考质量:思考过程更加结构化、条理清晰,能够更好地展现推理路径
这种深度思考能力的优势,使得 MiMo-V2-Flash 在复杂推理任务、学术研究、代码分析等需要深度思考的场景中,能够为用户提供更高质量、更可靠的智能服务。