单张3D胸部CT包 含数百万级像素点,放射科医生需逐切片审阅并系统排查肺部、心脏、气管、纵隔等多器官病变,这一过程不仅耗费大量精力与时间,还容易因视觉疲劳导致早期微小病灶漏诊,直接影响临床诊断的效率与准确性。AI辅助诊断模型本应成为临床诊疗的重要辅助工具,却长期受限于核心技术瓶颈:训练高精度多病种诊断模型需依赖海量专家标注数据,单张3D CT的精细化病灶标注往往耗费医生数小时,大规模数据集的标注成本动辄高达数十万元。这一现实困境让多数医疗机构与科研团队难以承担,严重制约了医学影像AI技术的规模化发展与临床落地。
本推文深度解析一篇发表于医学影像深度学习顶会MIDL 2025的重要论文《Chest-OMDL: Organ-specific Multidisease Detection and Localization in Chest Computed Tomography using Weakly Supervised Deep Learning from Free-text Radiology Report》。清华大学医学院生物医学工程系团队提出的 Chest-OMDL弱监督学习框架,以创新技术路径彻底摆脱对人工标注的依赖,实现了胸部CT器官特异性多病种检测与病灶精准定位的双重突破,其性能全面超越现有主流方法,为医学影像AI的低成本开发与临床转化提供了全新范式
论文链接:https://openreview.net/forum?id=ns6nq592HX
项目链接:https://github.com/JasonW375/Chest-OMDL
推文作者为黄忠祥,审校为龚裕涛、王一鸣。
会议介绍

MIDL(Medical Imaging with Deep Learning)是全球医学影像深度学习领域的顶尖国际学术会议。会议主题涵盖弱监督/无监督学习、多模态融合及模型可解释性等热点方向,吸引了全球数千名研究者参与。
会议网址: https://2025.midl.io/
一 研究背景与主要贡献
1.1研究背景
胸部CT作为诊断咳嗽、胸痛、呼吸困难、发热等症状的核心手段,在临床中应用广泛,仅我国三甲医院放射科每年的胸部CT检查量就不下百万次,尤其在新冠疫情期间,CT更是成为早期筛查和病情评估的关键工具。但AI辅助诊断模型的研发,长期被三大痛点制约。
**(1)数据标注成本高:**训练一个能检测10余种疾病的AI模型,至少需要数千张带精准标注的CT影像。而医学影像标注对专业知识要求极高,必须由资深放射科医生完成,一张3DCT的病灶标注可能需要2-3小时,大规模数据集的标注成本往往高达数百万元,绝大多数科研团队和医院都难以负担。
**(2)现有模型功能单一,可解释性差:**市面上多数医学影像AI模型只能实现是否患病的二分类,无法同时检测多种疾病,更不能定位病灶位置。这意味着医生仍需从头审阅整张CT,AI的辅助价值有限;同时,只给结果不给依据的模式缺乏临床可解释性,难以获得医生信任和监管部门批准。
**(3)泛化能力不足,临床落地难:**现有模型多在单一医院的数据集上训练,而不同医院的CT设备、扫描参数、患者人群存在差异,导致模型在新场景下性能大幅下降。例如,在A医院数据集上训练的模型,在B医院的CT影像上准确率可能从90%跌至60%,严重影响实际应用。
1.2主要贡献
针对上述痛点,Chest-OMDL以弱监督学习为核心,构建了一套从数据准备到模型训练的完整解决方案,主要贡献包括:
**(1)弱监督信号提取:**无需人工标注,直接从医院电子病历中的放射科自由文本报告和CT影像中提取监督信号。用RadBERT语言模型从报告中读出疾病标签,用SAT模型从影像中分割出器官区域,彻底解决了标注成本高的问题。
**(2)创新Y-Mamba三分支架构:**设计了融合特征提取器和器官分割解码器加上疾病异常图生成器的Y形模型,直接实现器官分割、多病种检测以及病灶定位三大功能,打破了传统模型功能单一的局限。
**(3)融入解剖学先验知识,提升精准度:**基于医学常识,将16种胸部疾病与对应的6个核心器官(肺、心脏、气管、胸膜、纵隔、食管)建立关联,让模型只在相关器官区域内检测疾病,大幅减少跨器官假阳性(比如不会把肺部病变误判为心脏疾病)。
**(4)强泛化能力和高可解释性:**在不同医院、不同设备的数据集上均实现SOTA性能,同时输出像素级病灶热力图和器官分割结果,医生能直观看到病变位置和概率,符合临床诊断逻辑。
**(5)覆盖多场景临床需求:**支持16种常见胸部疾病的检测(包括肺气肿、肺结节、心包积液、支气管扩张等),适配常规体检、疾病筛查、重症监护等多种临床场景,实用性极强。
二、研究方法
Chest-OMDL的整体框架简洁高效,核心分为弱监督信号提取和Y-Mamba模型训练两大环节,全程无需人工干预,就能实现高精度的多病种检测与定
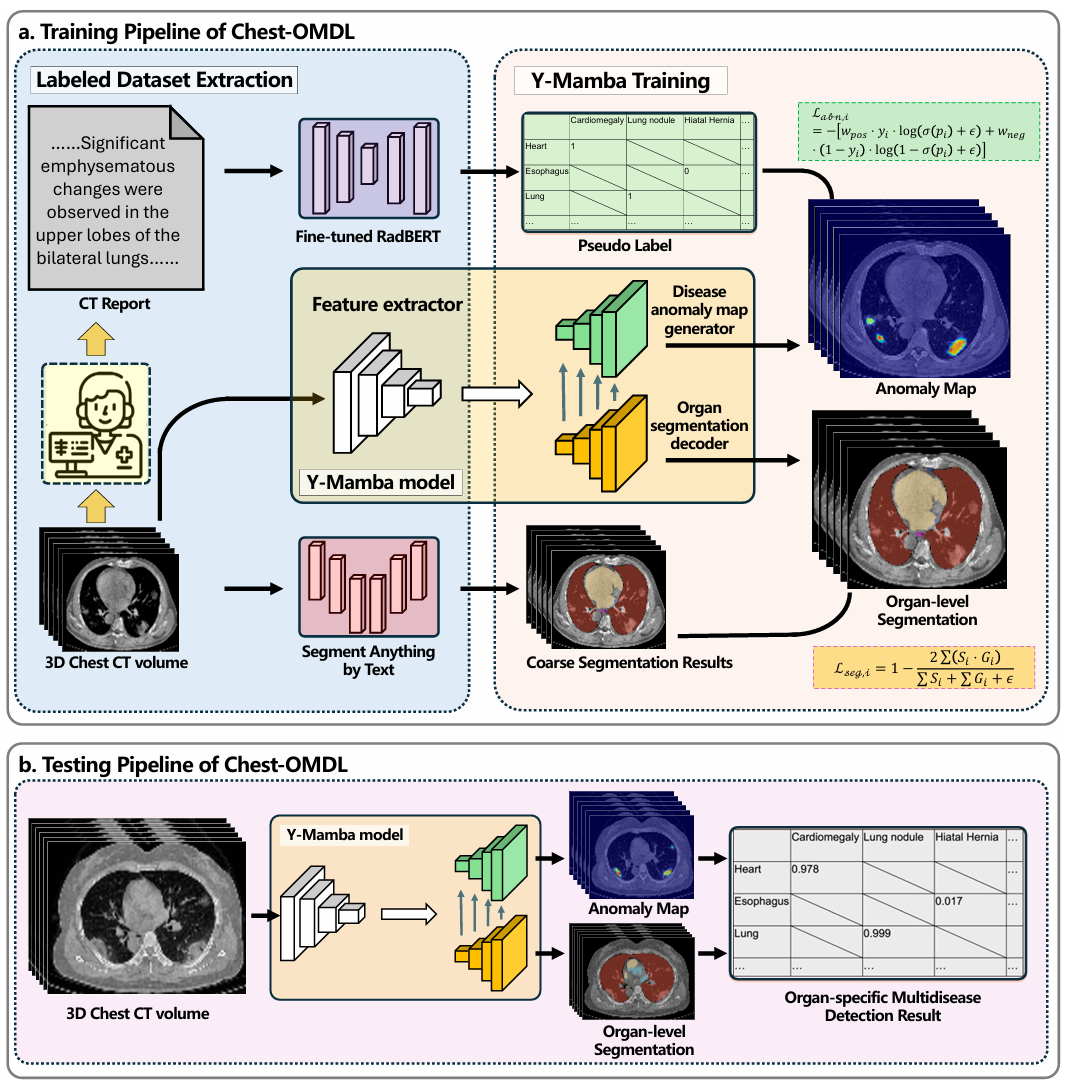
图1 Chest-OMDL流程图
2.1弱监督信号提取
弱监督信号提取是Chest-OMDL的核心创新之一,传统监督学习需要人工标注疾病类型和病灶位置,而该框架通过两种自动化工具提取伪标签替代人工标注,大幅降低了对人工的依赖。
(1)疾病标签提取:用RadBERT读取放射报告
放射科医生在完成CT阅片后,会撰写自由文本报告(比如双肺上叶可见明显肺气肿改变,心包少量积液等),这些报告中包含了丰富的疾病信息。Chest-OMDL采用预训练的RadBERT-RoBERTa-4m模型(专门针对放射科文本优化的语言模型),自动从报告中提取疾病标签。
RadBERT会对报告进行语义分析,识别出16种目标疾病(包括心脏肥大、心包积液、肺结节、磨玻璃影等),并输出患者是否患病。为了验证准确性,研究团队用1000份人工标注的报告进行测试,结果显示RadBERT的平均精确率达0.978、召回率0.974、F1分数0.976,这个精度已经接近资深放射科医生的水平,完全满足模型训练需求。
同时,团队还基于医学常识,将每种疾病与对应的器官关联(比如肺结节对应肺部、心包积液对应心脏),为后续的器官特异性检测打下基础。
(2)器官分割掩码生成:用SAT分割器官区域
要实现病灶定位,首先需要明确各个器官的位置。Chest-OMDL采用Segment Anything by Text(SAT)模型,一种基于文本提示的3D医学影像分割工具,自动生成6个核心器官(肺、心脏、气管和支气管、胸膜、纵隔、食管)的粗分割掩码。
SAT模型的优势在于,无需针对每个器官单独训练,只需输入文本提示(如"分割肺部"),就能快速输出器官的轮廓掩码。研究团队使用扩展后的CT-RATE数据集(包含SAT生成的分割结果),直接采用这些自动生成的粗分割掩码作为训练标签,避免了人工分割的巨大成本。
2.2Y-Mamba模型
为了在弱监督条件下同时完成器官分割、多病种检测和病灶定位,Chest-OMDL设计了创新的Y形Mamba模型(Y-Mamba),其架构基于SegMamba进行改进得到,主要分为三个核心组件。
(1)特征提取器
特征提取器是模型的眼睛,负责从CT影像中提取有价值的信息。它采用3D卷积层(Conv3D)结合LeakyReLU激活函数和实例归一化,先提取基础的空间特征;在深层网络中,还融入了门控空间卷积(GSC)和Mamba层,进一步增强特征表达能力。
GSC层:通过并行的3×3卷积结合1×1卷积门控,能有效抑制无关特征,突出器官边缘、病灶纹理等关键信息;
Mamba层:作为近年来替代Transformer的高效序列建模工具,擅长捕捉长距离依赖关系,能更好地处理3D CT的立体结构,避免因影像尺度大导致的特征丢失。通过下采样逐步降低空间分辨率、增加特征通道数,特征提取器最终输出多尺度的hierarchical特征图,兼顾局部细节(如微小病灶)和全局视野(如器官整体结构)。
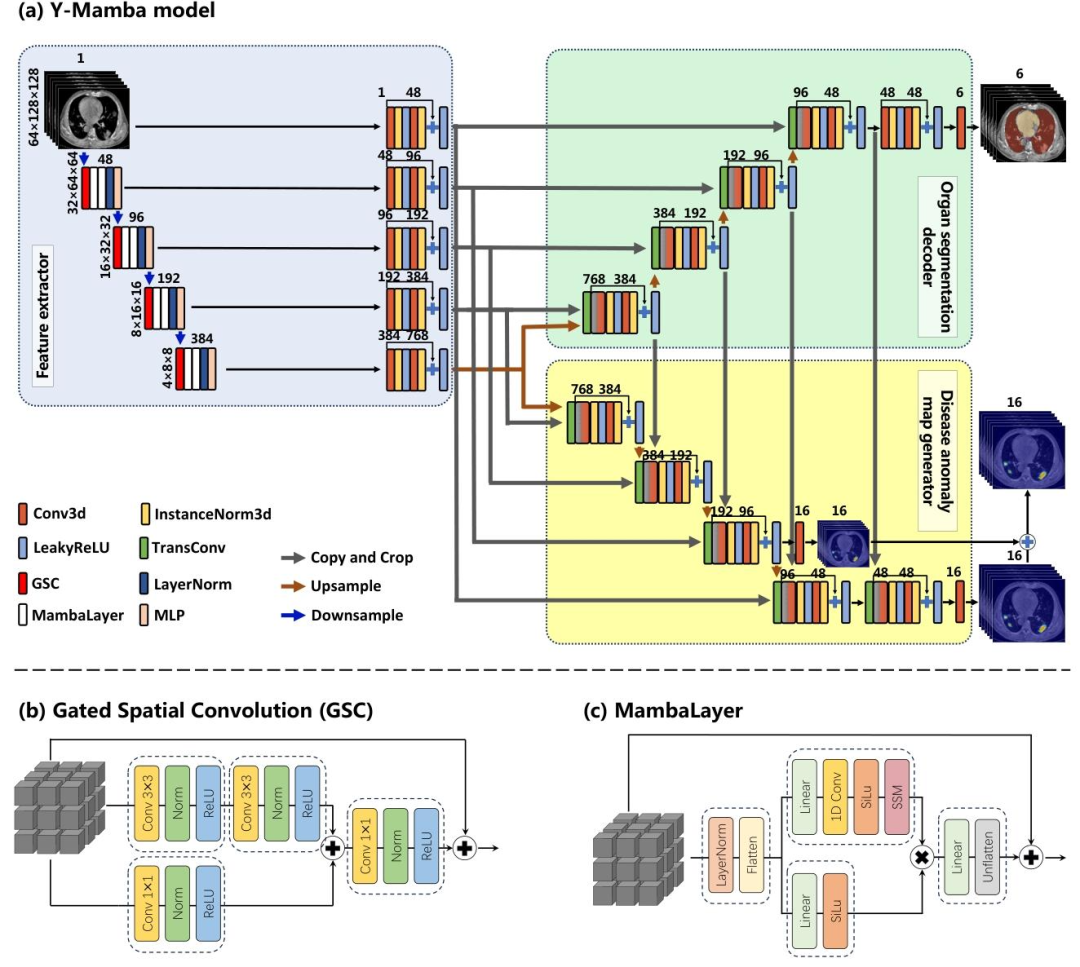
图2 Y-Mamba model流程图
(2)器官分割解码器
器官分割解码器采用编码器-解码器架构,将特征提取器输出的高维特征逐步上采样,同时通过跳跃连融合浅层的细节特征和深层的语义特征,最终生成6个器官的二进制分割掩码(掩码中1代表器官区域,0代表背景)。
为了保证分割精度,解码器使用转置卷积(TransConv)进行上采样,并通过多层感知器(MLP)细化特征。实验结果显示,6个器官的分割Dice相似系数(DSC,衡量分割精度的核心指标)均超过0.84,其中肺部和胸膜的DSC更是高达0.97,接近专业器官分割模型的性能。这为后续的病灶定位提供了精准的解剖学约束。
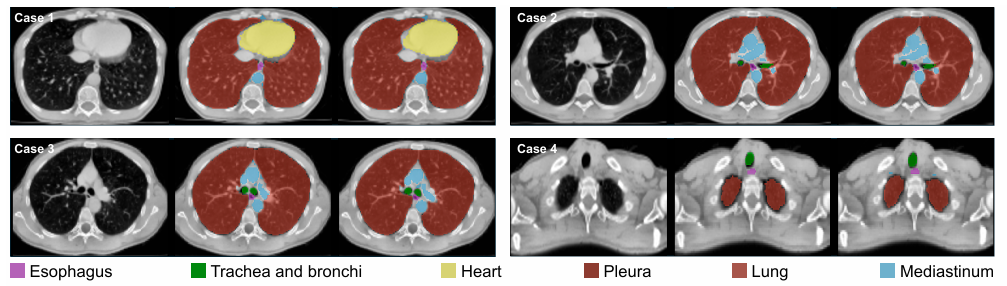
图3 Chest-OMDL
(3)疾病异常图生成器
与器官分割解码器并行,疾病异常图生成器同样基于特征提取器的输出,为16种疾病分别生成一张异常热力图。热力图中每个像素的取值范围为0-1,数值越高表示该位置属于对应疾病病灶的概率越大。
为了实现器官特异性检测,生成器会将每种疾病的异常热力图,与该疾病对应器官的分割掩码进行元素级乘法(比如肺结节的热力图只保留肺部区域的数值,其他器官区域的数值置为0)。这一操作能有效约束模型的注意力,避免跨器官假阳性,让检测结果更精准。
2.3多任务损失函数
要让Y-Mamba同时学好分割和检测两个任务,需要设计合理的损失函数。Chest-OMDL采用动态权重的多任务损失函数,将分割损失和检测损失结合起来。
**(1)分割损失(Dice Loss):**用于优化器官分割精度,该损失能有效衡量预测掩码与真实掩码的重叠程度,推动模型精准分割器官。
**(2)异常检测损失(加权交叉熵损失):**用于优化疾病分类性能,用于解决数据不平衡问题(比如某些罕见病的阳性样本很少)。
**(3)动态权重λ:**为了让模型在训练初期侧重分割任务(打好解剖学基础),后期聚焦检测性能,Chest-OMDL设计了动态衰减的权重λ,公式为。训练初期λ较大(比如1.0),分割损失占比更高;随着epoch增加,λ逐渐衰减,最终稳定在0.5,让两个任务的损失平衡贡献。
三、实验结果
为了全面验证Chest-OMDL的性能,研究团队在三个大规模数据集上进行了严格测试,同时与4种主流方法进行对比,从分类精度、分割效果、泛化能力、定位准确性等多个维度验证了模型的优越性。
3.1实验配置
(1)训练/内部验证数据集
CT-RATE数据集是目前全球最大的公开胸部CT数据集之一,包含25,692张非增强3D胸部CT影像(来自21,304名患者),每张影像都配有对应的放射科文本报告。数据集分为训练集(24,128张CT)和内部验证集(1,564张CT),涵盖不同年龄、性别、疾病类型的患者,数据分布均衡。
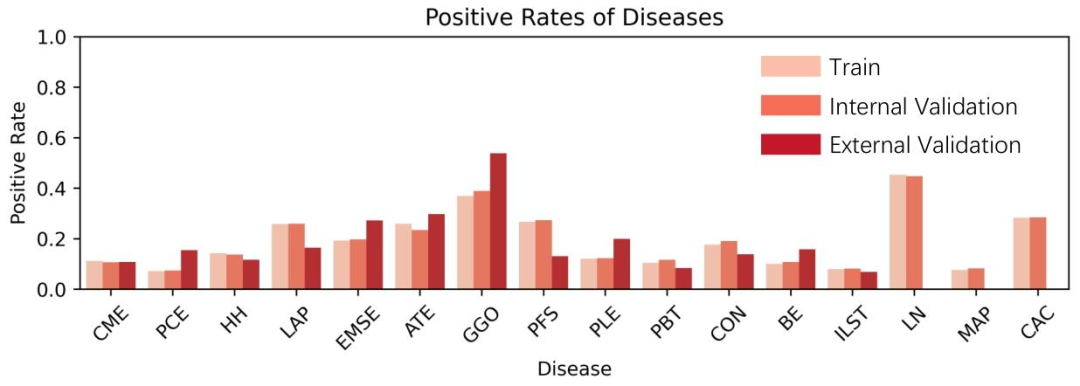
图4数据集中各种疾病**** 样本的 占比
(2)外部验证数据集
外部验证数据集采用RAD-ChestCT数据集,包含3,630张胸部CT影像,来自杜克大学医疗系统,采用与CT-RATE不同的扫描设备和重建技术,用于测试模型的泛化能力(应对分布外数据)。
(3)定位验证数据集
定位验证数据集为新冠CT数据集,包含10张带专家精准标注的新冠感染CT影像,病灶区域(如磨玻璃影、实变)由两名放射科医生标注并经资深专家审核,用于评估模型的病灶定位精度。
(4)对比方法
对比方法选取4种当前SOTA方法作为基线方法,分别是CT-Net(全监督传统分类模型,直接用人工标注的疾病标签训练)、CT-CLIP(Zero-shot,基于对比学习的视觉模型,无需微调即可进行零样本分类)、CT-CLIP(VocabFine,对CT-CLIP的词汇表进行微调后的版本)、CT-CLIP(ClassFine,针对疾病分类任务专门微调的CT-CLIP变体)。
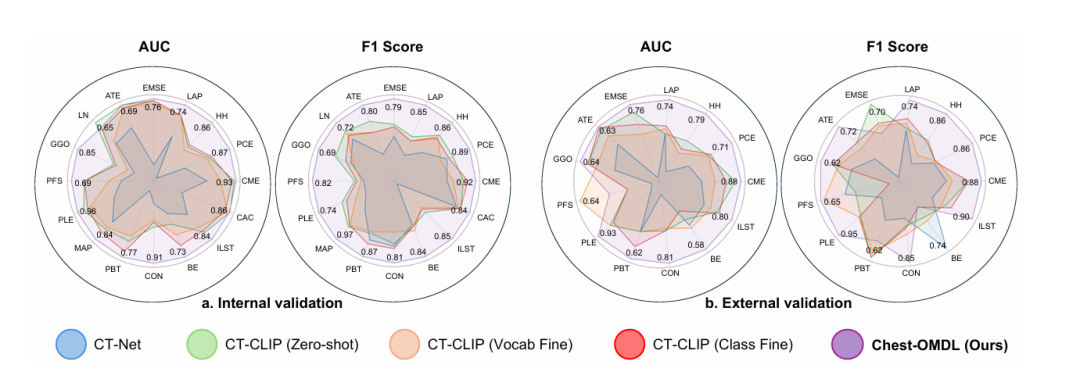
图5五种方法在内部数据集CT-RATE和外部数据集RAD-ChestC上的AUC以及F1 Score****
(5)训练环境
使用4块NVIDIA A800 GPU,训练150个epoch,总训练时间约2天20小时,批次大小为8,优化器采用AdamW,学习率采用余弦退火策略衰减。
3.2核心性能指标
(1)多病种分类性能
分类性能采用AUROC(曲线下面积,衡量区分正负样本的能力)、F1分数(平衡精确率和召回率)、准确率三个核心指标,结果如下表所示。
表1 Chest-OMDL多种疾病下各病种的分类性能
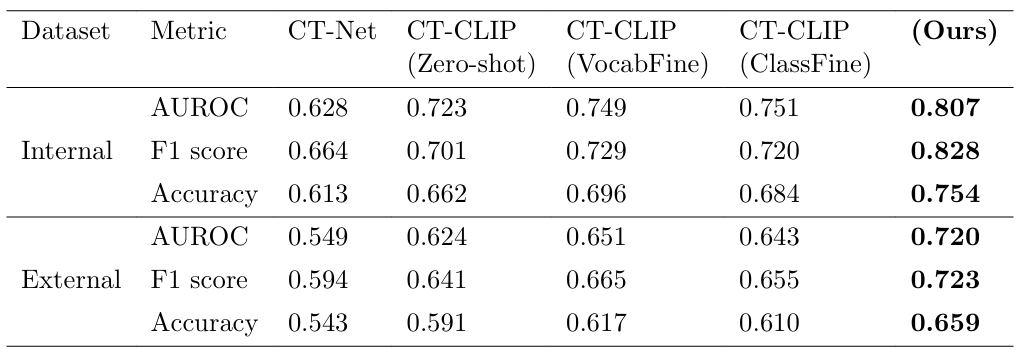
从结果可以看出,内部验证中,Chest-OMDL的AUROC达0.807,较表现最好的对比方法CT-CLIP (ClassFine)提升7.4%;F1分数达0.828,提升15.0%,准确率达0.754,提升10.2%,全面领先。外部验证中,Chest-OMDL的AUROC仍保持在0.720,较CT-CLIP (VocabFine)提升10.60%,而其他方法的性能下降幅度更大(CT-Net从0.628跌至0.549),证明Chest-OMDL具有更强的泛化能力,能更好地适应不同医院的CT影像。
(2)器官分割性能
器官分割采用Dice相似系数(DSC)和归一化表面距离(NSD)两个指标,结果如下表所示。
表2 Chest-OMDL器官分割精度性能

所有6个器官的分割DSC均超过0.84,其中肺部和胸膜的DSC高达0.97,与专门的器官分割模型SegMamba性能相当。这表明,即使使用自动生成的粗分割掩码作为训练标签,Chest-OMDL依然能实现高精度的器官分割,为病灶定位提供了坚实基础。
(3)病灶定位性能
在新冠CT数据集上,Chest-OMDL的病灶定位精度用Dice相似系数(DSC)衡量。结果显示,模型在仅使用器官级弱监督的情况下,实现了0.450的平均DSC,而全监督方法(使用精准病灶标注训练)的DSC为0.673,这意味着Chest-OMDL的定位精度达到了全监督方法的67%。
更值得关注的是,研究团队还进行了少样本微调实验。用仅2个带标注的新冠CT样本对模型进行微调后,DSC迅速提升至0.547,进一步验证了模型的灵活性和实用性。在临床中,只需少量标注样本,就能快速适配特定疾病的定位需求。
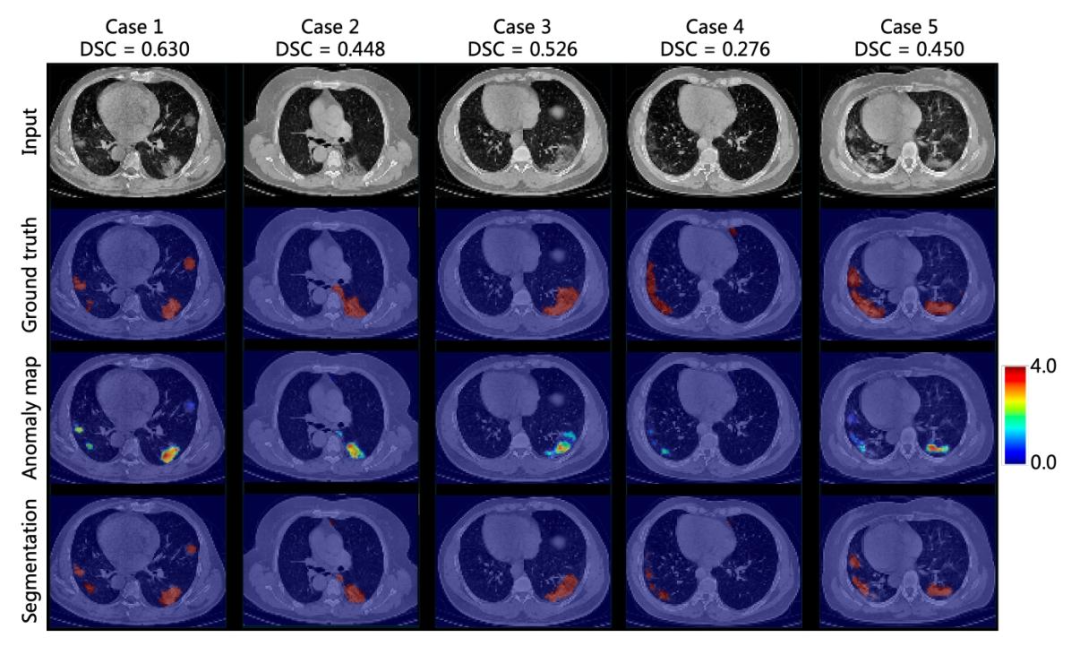
图6 在新冠CT数据集上的异常区域标注展示
3.3消融实验
为了明确Y-Mamba架构、分割任务、动态权重等组件的作用,研究团队设计了三组消融实验。
**(1)模型架构:**对比U-Net(传统分割检测模型)和Y-Mamba。
(2 **)****分割任务:**对比带分割任务的Y-Mamba和无分割任务的Y-Mamba。
**(3)损失权重:**对比动态权重λ和固定权重λ。
实验结果显示,Y-Mamba的AUROC在内部验证集上比U-Net高8.3%,在外部验证集上高9.1%,证明Mamba层和三分支架构在捕捉3D CT特征上的优势。去掉分割任务后,模型的AUROC下降6.7%,F1分数下降8.2%,证明器官分割能为疾病检测提供解剖学约束,有效提升精度。动态权重λ比固定权重λ的AUROC高4.5%,证明动态平衡分割和检测损失的合理性。这些结果充分说明,Chest-OMDL的每个组件都经过精心设计,缺一不可,共同构成了其性能优势的基础。
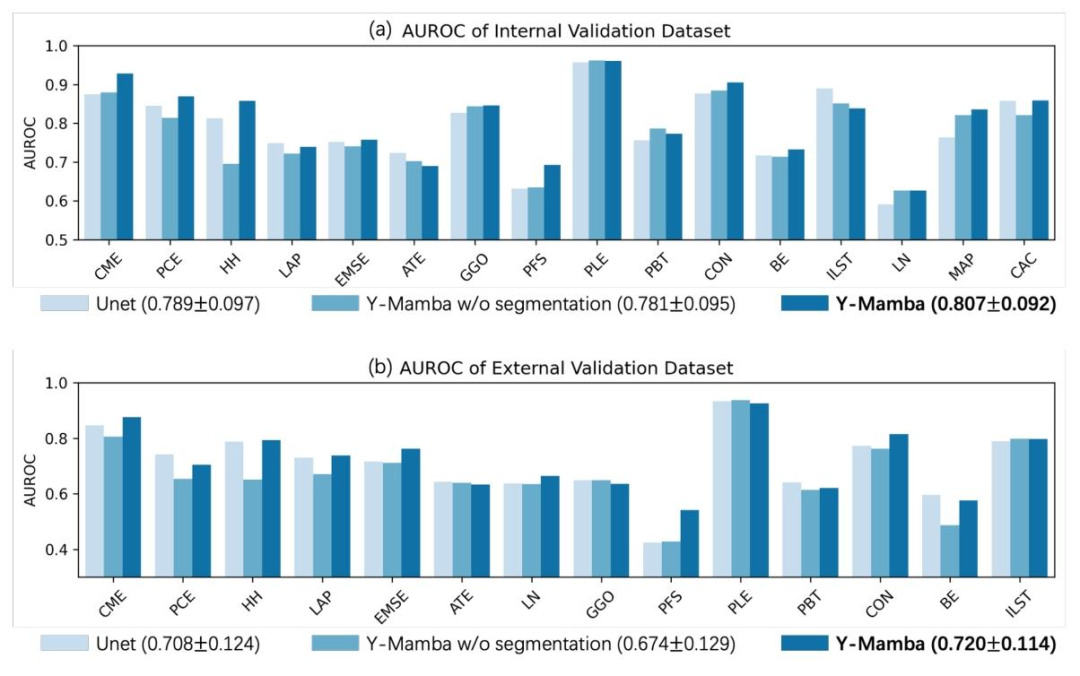
图7 消融实验在内、外部数据集上的结果
四、总结与展 望
Chest-OMDL作为一款弱监督学习框架,通过从放射报告提取疾病标签,结合从CT影像生成器官分割掩码的创新思路,彻底解决了医学影像AI对人工标注的依赖,大幅降低了模型开发成本。其Y-Mamba三分支架构实现了器官分割、多病种检测、病灶定位等目标,性能全面超越现有主流方法,同时具备强泛化能力和高可解释性,完美契合临床需求。模型仍有进一步优化的空间,比如对微小病灶(如直径小于5mm的肺结节)的检测精度还可提升,未来可结合多模态数据(如PET-CT、血液检查结果)进一步增强性能。此外,还可拓展至腹部、头部等其他部位的医学影像分析,实现多部位多病种的统一检测。
总体而言,Chest-OMDL不仅为医学影像AI的低成本开发提供了新范式,更推动了AI辅助诊断技术向临床落地迈出了关键一步。随着技术的不断完善,相信未来会有更多类似的弱监督、高实用的医学AI模型出现,让AI真正成为医生的得力助手,惠及更多患者。