线程不安全的集合在并发环境下的问题
- 线程不安全的集合都有哪些
- 可能会出现哪些线程不安全问题
-
- [1. 数据不一致(最常见)](#1. 数据不一致(最常见))
- [2. ConcurrentModificationException(迭代时)](#2. ConcurrentModificationException(迭代时))
- [3. 内存可见性问题](#3. 内存可见性问题)
- 通过代码复现问题与解决问题
线程不安全的集合都有哪些
以我们常用的集合,List,Set和Map为例:
线程不安全的集合 :
- List的接口实现类:ArrayList(动态数组)、LinkedList(双向链表)。
- Set的接口实现类:HashSet(基于HashMap实现) 、TreeSet(基于红黑树实现)、LinkedHashSet(基于LinkedHashMap实现)。
- HashMap的接口实现类:HashMap(基于哈希表)、TreeMap(基于红黑树)和 LinkedHashMap。
可能会出现哪些线程不安全问题
以HashMap为例
1. 数据不一致(最常见)
- 场景:多线程同时执行put()、remove()等操作。
- 后果:可能导致数据丢失或脏读,甚至会损坏到哈希表的结构(如链表成环)。
- 示例:
java
static final HashMap<String, Integer> map = new HashMap<>();
// 线程1和线程2 同时执行put:
map.put("key", 1); // 可能因并发扩容导致链表成环2. ConcurrentModificationException(迭代时)
- 场景:一个线程迭代集合,另一个线程修改集合。
- 后果:抛出异常,程序中断。
- 示例:
java
static final ArrayList<String> list = new ArrayList<>();
// 线程1:迭代
for (String s : list) { ... }
// 线程2:同时修改:
list.add("new"); // 可能抛出ConcurrentModificationException3. 内存可见性问题
- 场景:线程A修改集合后,线程B未立即看到最新值。
- 后果:读取到过期数据(尽管添加final关键字修饰可以保证引用的可见性,但对象内部状态不保证)。
- 示例:
java
static final HashMap<String, Boolean> cache = new HashMap<>();
// 线程A:put 数据
cache.put("key", true);
// 线程B:可能短暂读取到null(未同步时)通过代码复现问题与解决问题
多线程下的数据不一致问题
问题复现
- 首先定义一个用来作为key的自定义实体类Entity.java,并 重写hashCode()和equals() 这两个方法(用于自行控制 重复key的定义 ,这样更符合工作中的实际应用场景)。
- 定义一个用来向Map中put数据的任务类HashMapPutTask.java。
- 最后,定义一个用来启动多线程并发调用的主类TestPut.java。
相关代码如下:
Entity类的定义如下:
java
import java.util.List;
import java.util.Objects;
/**
* 放入map中的实体类
*/
public class Entity {
private Long id;
private String string1;
private String string2;
private String string3;
private List<String> list1;
private List<String> list2;
/**
* 重写hashCode方法:自行定义hash值的计算逻辑
*/
@Override
public int hashCode() {
return Objects.hash(id)
+ Objects.hash(string1)
+ Objects.hash(string2)
+ Objects.hash(string3)
+ Objects.hash(list1)
+ Objects.hash(list2)
;
}
/**
* 重写equals方法:自行定义两个对象是否为同一个对象的判断方式
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || this.getClass() != o.getClass()) return false;
Entity that = (Entity) o;
return id.equals(that.id)
&& string1.equals(that.string1)
&& string2.equals(that.string2)
&& string3.equals(that.string3)
&& Objects.equals(list1, that.list1)
&& Objects.equals(list2, that.list2)
;
}
public void setId(Long id) {
this.id = id;
}
public void setString1(String string1) {
this.string1 = string1;
}
public void setString2(String string2) {
this.string2 = string2;
}
public void setString3(String string3) {
this.string3 = string3;
}
public void setList1(List<String> list1) {
this.list1 = list1;
}
public void setList2(List<String> list2) {
this.list2 = list2;
}
}HashMapPutTask类的定义如下:
java
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.Callable;
public class HashMapPutTask implements Callable<Entity> {
private final int taskId;
public HashMapPutTask(int taskId) {
this.taskId = taskId;
}
@Override
public Entity call() {
String text = TestPut.text;
String regex = "[\\.\\:\\(\\)\\(\\)\\,\\。\\/\\*、]";
Random random = new Random(taskId); //将taskId作为随机数的种子,保证同样的taskId产生的对象完全相同
int startIndex = random.nextInt(text.length() / 2);
int length = text.length() - startIndex;
// 开始构造 key 实体
Entity entity = new Entity();
entity.setId(Long.valueOf(taskId)); //由于taskId是唯一的,并且我们重写了equals方法,所以可以保证所有的key都是不重复的
entity.setString1(text.substring(startIndex, random.nextInt(length) + startIndex + 1));
entity.setString2(text.substring(startIndex, random.nextInt(length) + startIndex + 1));
entity.setString3(text.substring(startIndex, random.nextInt(length) + startIndex + 1));
entity.setList1(Arrays.asList(text.substring(startIndex, random.nextInt(length) + startIndex + 1).split(regex)));
entity.setList2(Arrays.asList(text.substring(startIndex, random.nextInt(length) + startIndex + 1).split(regex)));
// 多线程 并发执行 put方法
TestPut.put(entity, entity);
System.out.println("线程:" + taskId + "\t,put完成");
return entity;
}
}TestPut类的定义如下:
java
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.*;
public class TestPut {
/**
* 使用线程不安全的HashMap
*/
private static final Map<Entity, Entity> map = new HashMap<>();
/**
* 提供给外部 供多线程调用的put方法
*/
public static Entity put(Entity key, Entity value) {
return map.put(key, value);
}
public static void main(String[] args) {
// 获取当前可用处理器的数量(即cpu核数)
int availableProcessors = Runtime.getRuntime().availableProcessors();
int threadCount = availableProcessors * 20; //线程池的线程数
int taskCount = 200000; //任务数量
int count = 0; // 记录遍历map时的实际元素个数
// 创建一个固定大小的线程池
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
// 用于存储多个 Callable 任务,以及线程执行结果的 Future 对象
List<Future<Entity>> futures = new ArrayList<>();
// 记录执行的开始时间
long start = System.currentTimeMillis();
// 启动多线程
for (int i = 0; i < taskCount; i++) {
HashMapPutTask task = new HashMapPutTask(i);
Future<Entity> future = executorService.submit(task);
futures.add(future);
}
// 获取所有任务的处理结果
for (Future<Entity> future : futures) {
try {
Entity result = future.get(); // 阻塞等待结果
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("所有任务执行完成");
// 关闭线程池
executorService.shutdown();
// 遍历map中的元素
for (Map.Entry<Entity, Entity> entry : map.entrySet()) {
count++;
}
System.out.println("当前可用处理器:" + availableProcessors);
System.out.println("线程池的线程数:" + threadCount);
System.out.println("任务数量:" + taskCount);
System.out.println("map.size():" + map.size());
System.out.println("map.entrySet():" + map.entrySet().size());
System.out.println("遍历map时的实际元素个数:" + count);
System.out.println("执行时间(ms):" + (end - start));
}
// 测试文本:用于给实体类的属性赋值
public static String text = "在Java中,集合(Collection)框架是一个非常强大的功能,它提供了一套用于存储、查询和操作一组对象的标准接口和类。Java集合框架主要包括两大类:Collection接口和Map接口。下面是一些常见的集合类以及它们的特点:\n" +
"\n" +
"1. Collection接口\n" +
"a. List接口\n" +
"\u200CArrayList\u200C:基于动态数组实现,支持快速随机访问,但不支持高效的插入和删除操作(在数组中间插入或删除元素时,需要移动大量元素)。\n" +
"\u200CLinkedList\u200C:基于双向链表实现,支持高效的插入和删除操作,但随机访问效率较低。\n" +
"\u200CVector\u200C:早期的动态数组实现,与ArrayList类似,但它是同步的(线程安全),因此性能略低。\n" +
"b. Set接口\n" +
"\u200CHashSet\u200C:基于哈希表实现,不包含重复元素。\n" +
"\u200CLinkedHashSet\u200C:HashSet的子类,内部使用链表维护元素的插入顺序。\n" +
"\u200CTreeSet\u200C:基于红黑树实现,元素是有序的,不允许存储null值。\n" +
"c. Queue接口\n" +
"\u200CLinkedList\u200C:可以作为Queue、Stack或Deque使用,实现了Deque接口,支持FIFO(先进先出)操作。\n" +
"\u200CPriorityQueue\u200C:基于堆结构实现,支持优先级排序。\n" +
"2. Map接口\n" +
"a. HashMap\n" +
"基于哈希表的实现,允许使用null值和null键(从Java 8开始,当键碰撞时使用链表加红黑树的结构优化性能)。\n" +
"b. LinkedHashMap\n" +
"HashMap的子类,维护了记录的插入顺序,或者可以选择访问顺序。\n" +
"c. TreeMap\n" +
"基于红黑树实现,元素按照键的自然顺序或者构造时提供的Comparator进行排序。\n" +
"d. Hashtable\n" +
"早期的哈希表实现,与HashMap类似,但它是同步的(线程安全),因此性能略低。\n" +
"特点总结\n" +
"\u200C线程安全性\u200C:早期的集合如Vector和Hashtable是线程安全的,但在Java 5之后推荐使用更高效的同步策略(如Collections.synchronizedList等)或者使用java.util.concurrent包下的并发集合类来替代它们。\n" +
"\u200C性能\u200C:ArrayList和LinkedList在性能上有明显差异,前者适合随机访问,后者适合频繁的插入和删除操作。HashMap和HashSet提供了快速查找和插入的能力。\n" +
"\u200C有序性\u200C:LinkedHashSet、LinkedHashMap维护元素的插入顺序;TreeSet和TreeMap则保持元素按照自然顺序或者定制顺序排序。\n" +
"\u200C可空性\u200C:HashMap允许null值和null键(从Java 8开始优化了处理null键的方式),而基本类型的Set(如HashSet)不允许存储null值。\n" +
"\u200C并发修改\u200C:在迭代过程中对集合进行结构性修改(如添加或删除元素)可能会导致ConcurrentModificationException异常。从Java 8开始,可以使用Iterator的remove()方法或者Collection.removeIf()方法来避免这个问题。\n" +
"了解这些集合的特点和适用场景,可以帮助开发者根据具体需求选择最合适的集合类型。";
}此时TestPut的运行结果如下:
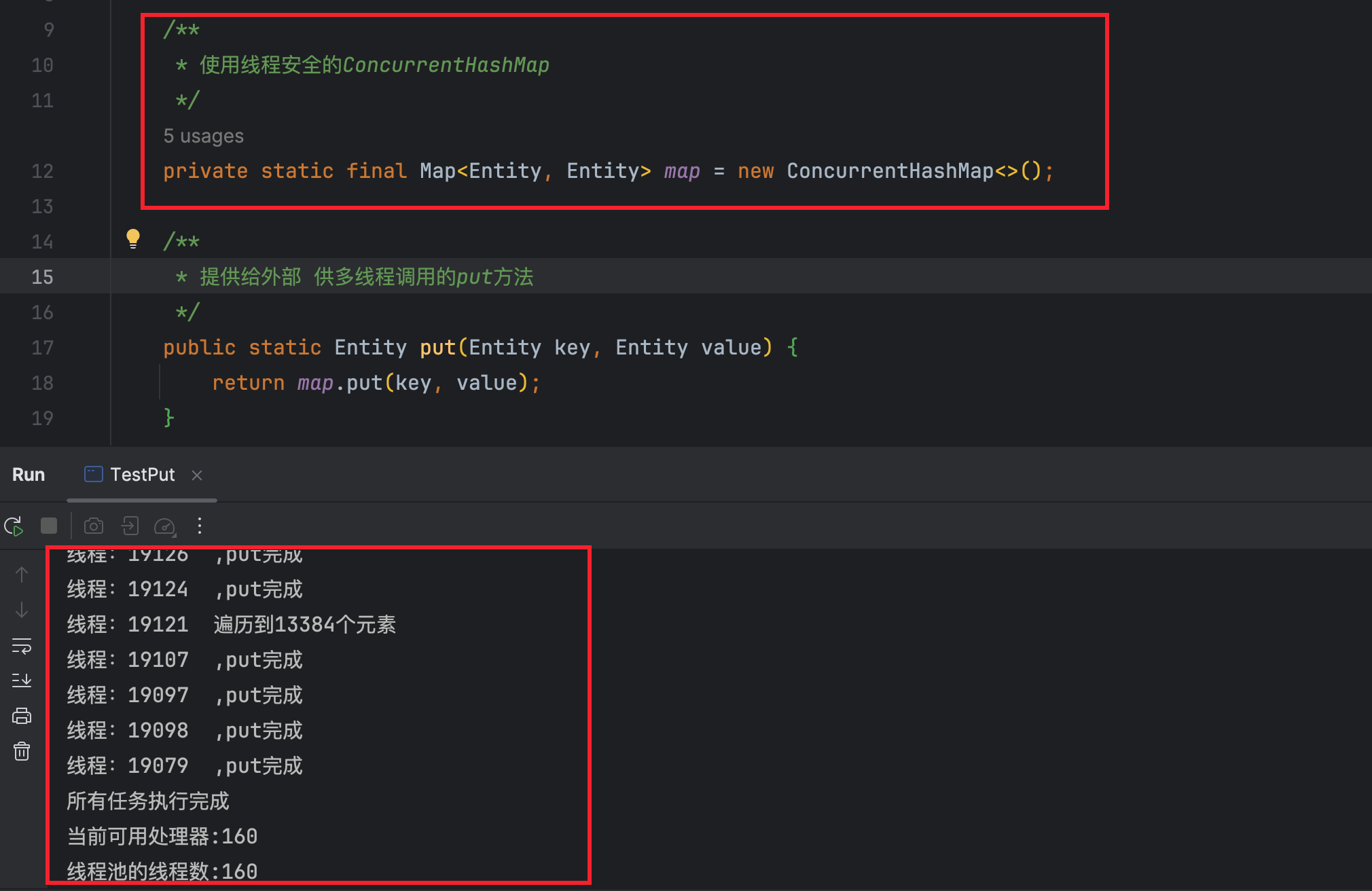
可以看到,使用线程不安全的HashMap,并且在多线程并发put时不加锁
- 会出现数据丢失的问题(put了不重复的key共200000次,最终map.size=199446个)
- 甚至可能出现 破坏HashMap底层数据结构等严重问题(map.size显示是199446个,但实际遍历时只能遍历到106503个元素)。
解决方案
1. 使用线程安全的集合类
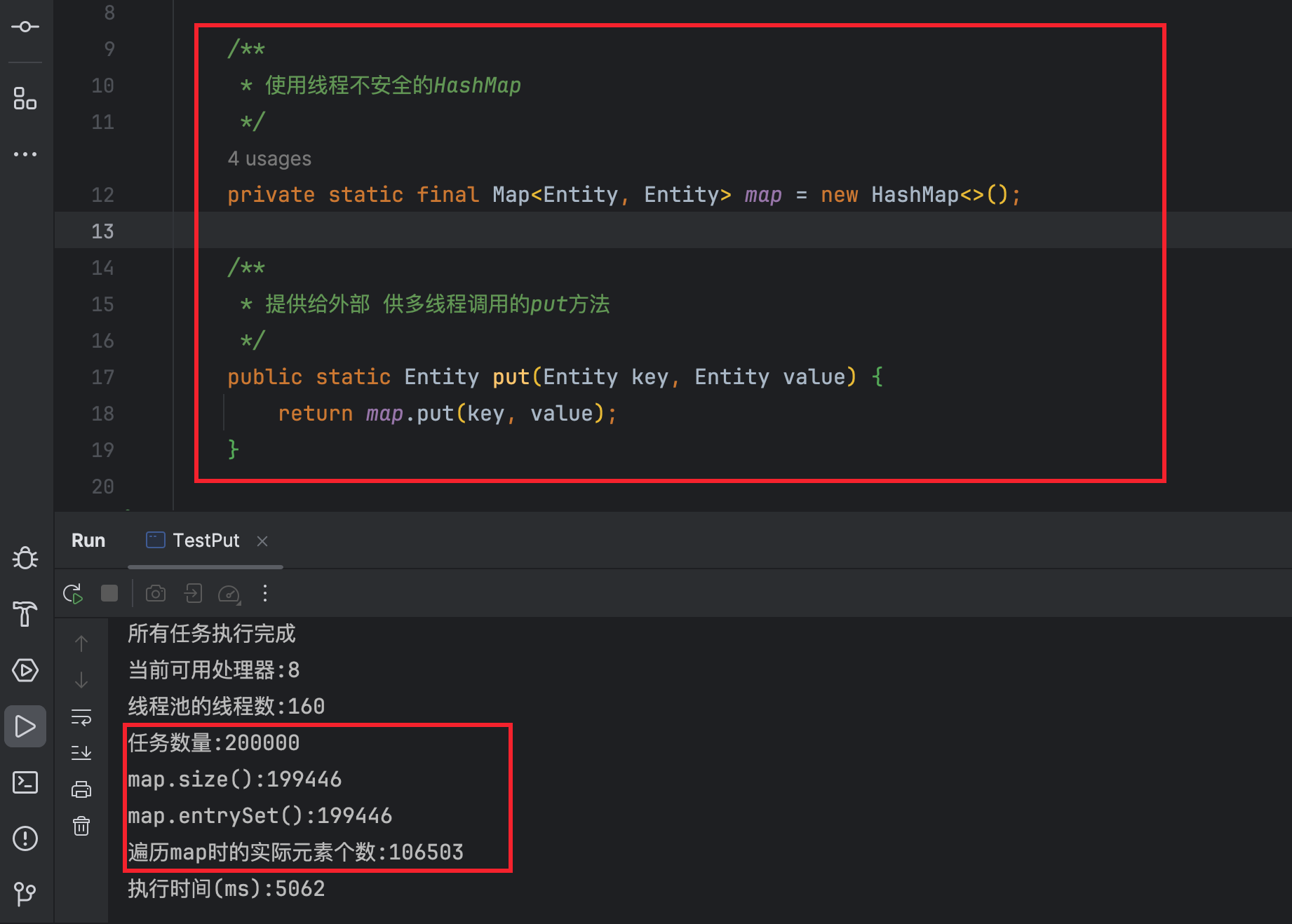
使用线程安全的集合ConcurrentHashMap来存放数据。
java
/**
* 使用线程安全的ConcurrentHashMap
*/
private static final Map<Entity, Entity> map = new ConcurrentHashMap<>();TestPut的运行结果如下:
- 可以看到,耗时几乎没有什么明显变化,且无数据缺失等问题(put了不重复的key共200000次,最终遍历到的元素也是200000个)。
- 但是,ConcurrentHashMap在实际应用中有一个需要注意的点,那就是 ConcurrentHashMap 不允许存储
null键 或 null值 (存入null后 运行时会出现 空指针异常NullPointerException ),
因此,如果业务场景有存入null的需要,建议使用下面 给HashMap的方法加锁的方式自行控制同步。
2. 通过加锁实现同步控制
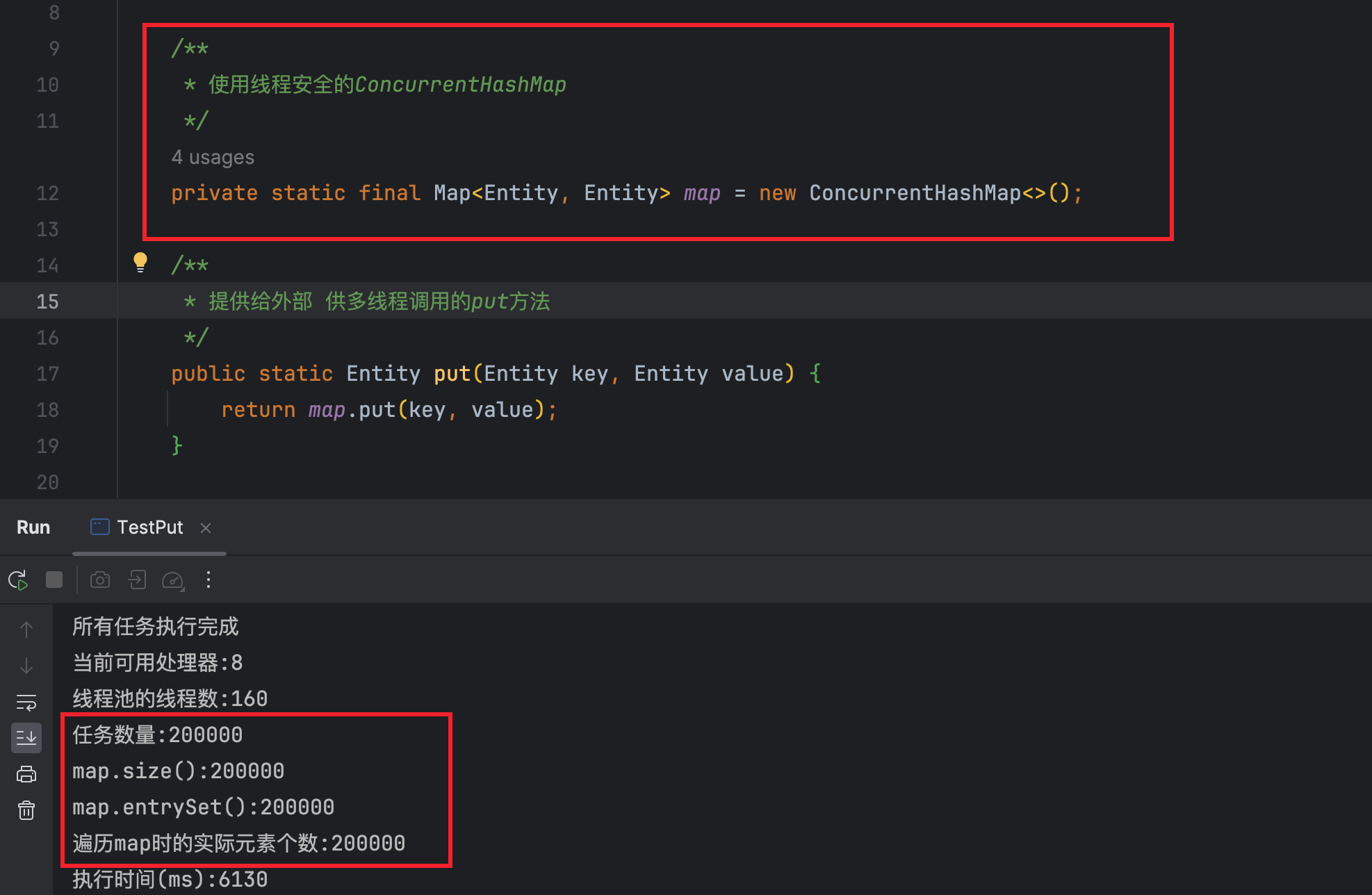
使用线程不安全的HashMap时,修改TestPut中的put方法,在需要串行执行的代码块上添加synchronized锁。
java
/**
* 提供给外部 供多线程调用的put方法
*/
public static Entity put(Entity key, Entity value) {
synchronized (map) {
return map.put(key, value);
}
}TestPut的运行结果如下:
可以看到,put方法内加锁后,会比不加锁时增加耗时,但是不会出现数据丢失等问题(put了不重复的key共200000次,最终遍历到的元素也是200000个)。
多线程下的并发异常 ConcurrentModificationException
问题复现
- 添加一个用于遍历迭代Map的任务类HashMapIterationTask.java。
- 在主类TestPut.java中添加启动任务类HashMapIterationTask.java的代码。
相关代码如下:
HashMapIterationTask类的定义如下:
java
import java.util.Map;
import java.util.concurrent.Callable;
public class HashMapIterationTask implements Callable<Entity> {
private final int taskId;
public final Map<Entity, Entity> map;
public HashMapIterationTask(int taskId, Map<Entity, Entity> map) {
this.taskId = taskId;
this.map = map;
}
@Override
public Entity call() {
int count = 0;
Entity entity = null;
for (Map.Entry<Entity, Entity> entry : map.entrySet()) {
count++;
entity = entry.getKey();
}
System.out.println("线程:" + taskId + "\t遍历到" + count + "个元素");
return entity;
}
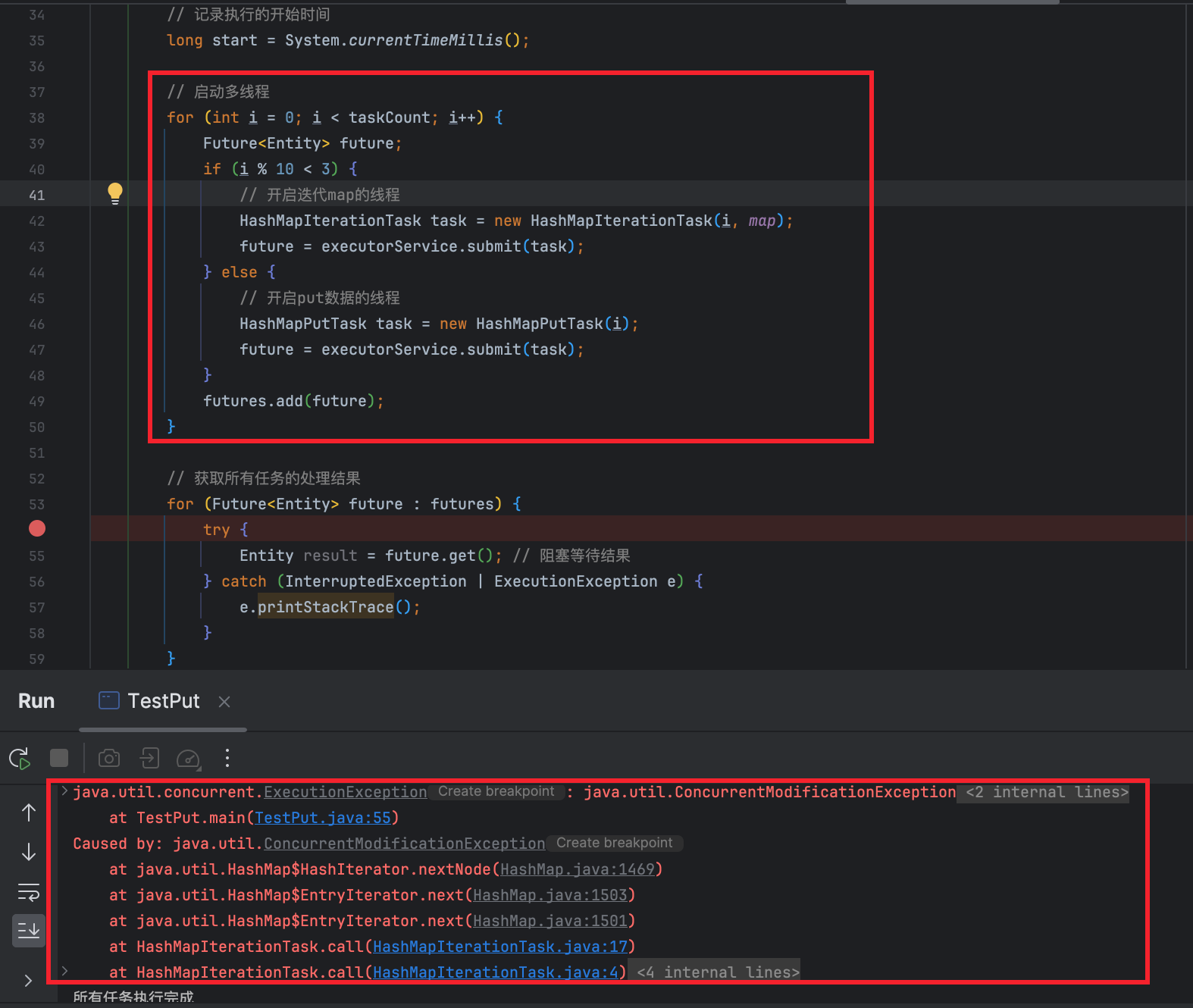
}TestPut中的main函数中修改如下:
java
// 启动多线程
for (int i = 0; i < taskCount; i++) {
Future<Entity> future;
if (i % 10 < 3) {
// 开启迭代map的线程
HashMapIterationTask task = new HashMapIterationTask(i, map);
future = executorService.submit(task);
} else {
// 开启put数据的线程
HashMapPutTask task = new HashMapPutTask(i);
future = executorService.submit(task);
}
futures.add(future);
}即下图标示部分,可以看到,此时出现并发异常。
解决方案
1. 使用线程安全的集合类
使用线程安全的集合类ConcurrentHashMap。