目录
Java 集合框架(Collections Framework)是 Java 中用于 存储和操作数据组的重要架构 。它提供了一组接口、实现类和算法。
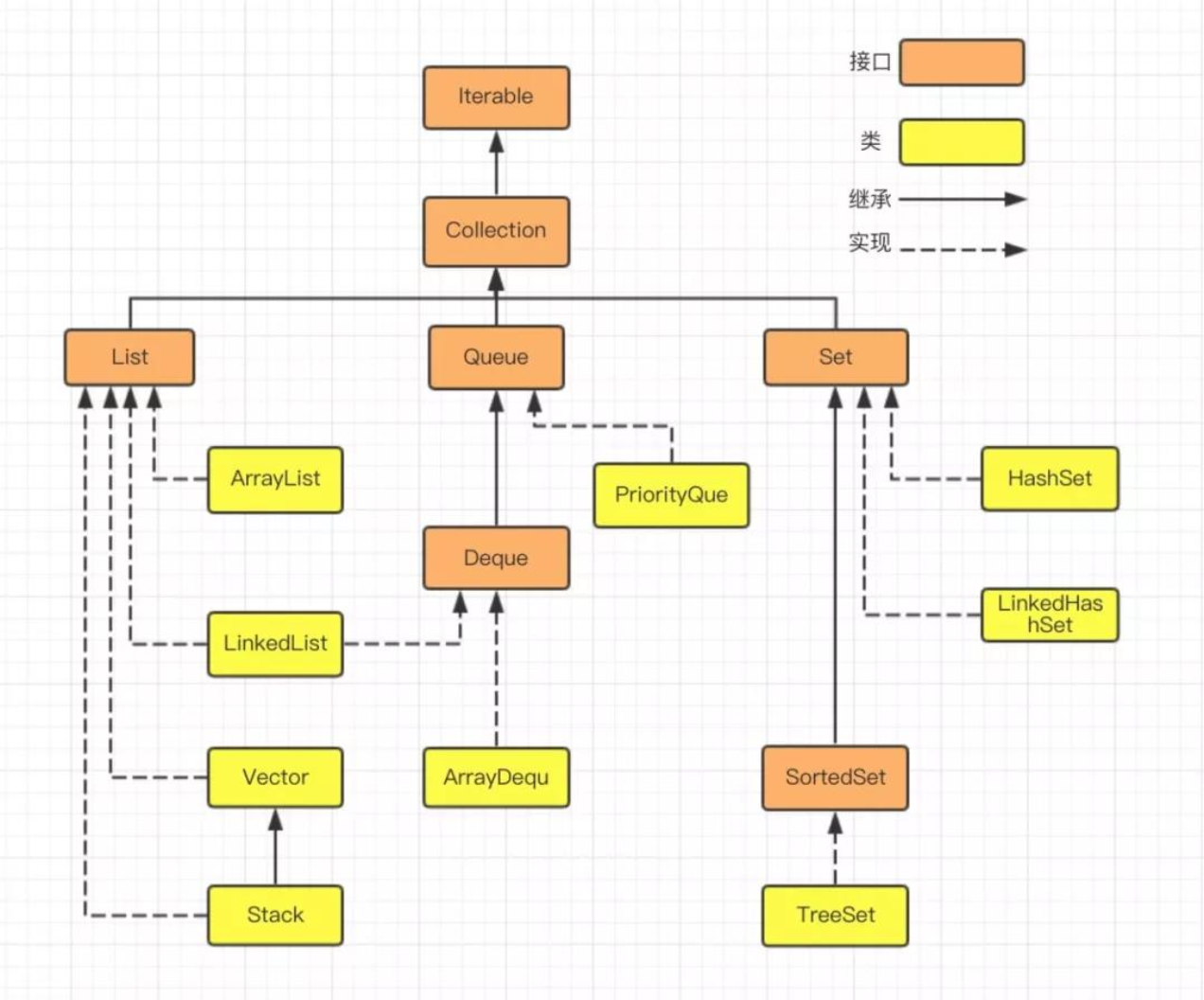
一、集合框架层次结构
Collection (接口)
├── List (接口 - 有序,可重复)
│ ├── ArrayList (实现类)
│ ├── LinkedList (实现类)
│ ├── Vector (线程安全,已过时)
│ └── Stack (继承Vector)
│
├── Set (接口 - 无序,不可重复)
│ ├── HashSet (实现类)
│ │ └── LinkedHashSet (保持插入顺序)
│ ├── SortedSet (接口)
│ │ └── TreeSet (实现类)
│ └── EnumSet (专用于枚举)
│
└── Queue (接口 - 队列)
├── Deque (双端队列接口)
│ ├── ArrayDeque (实现类)
│ └── LinkedList (也实现了Deque)
│
├── PriorityQueue (优先队列)
└── BlockingQueue (阻塞队列接口)
├── ArrayBlockingQueue
├── LinkedBlockingQueue
└── PriorityBlockingQueue
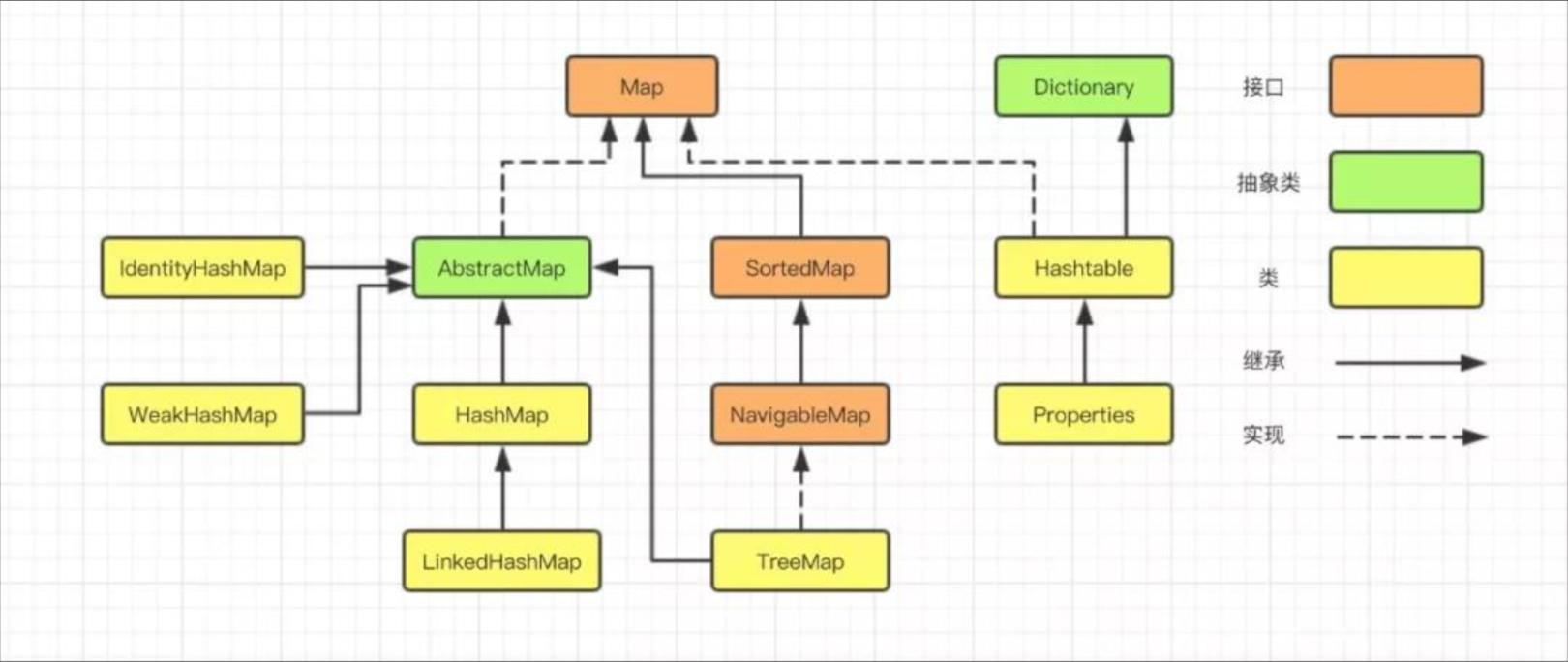
Map (接口 - 键值对)
├── HashMap (实现类)
│ └── LinkedHashMap (保持插入顺序)
├── TreeMap (基于红黑树)
├── Hashtable (线程安全,已过时)
├── WeakHashMap (弱引用)
└── ConcurrentHashMap (并发版)Java集合大致可以分为两大体系,一个是Collection,另一个是Map
Collection:主要由List、Set、Queue接口组成,List代表有序、重复的集合;其中Set代表无序、不可重复的集合;Queue体系集合,代表一种队列集合实现。Map:则代表具有映射关系的键值对集合。
java.util.Collection下的接口和继承类关系简易结构图:
java.util.Map下的接口和继承类关系简易结构图:
其中,Java 集合框架中主要封装的是典型的数据结构和算法,如动态数组、双向链表、队列、栈、Set、Map 等。
二、Collection集合
通过集合的关系图我们可以知道Collection是集合的顶层父类,他定义了集合的基本方法如
基本操作方法
| 方法签名 | 功能描述 | 返回值 | 示例 | 时间复杂度 |
|---|---|---|---|---|
int size() |
返回集合中元素的数量 | 元素个数 | list.size() → 3 |
O(1) |
boolean isEmpty() |
判断集合是否为空 | true/false |
list.isEmpty() → false |
O(1) |
boolean contains(Object o) |
判断是否包含指定元素 | true/false |
list.contains("A") → true |
List: O(n) Set: O(1) TreeSet: O(log n) |
boolean add(E e) |
添加元素到集合 | 是否成功 | list.add("D") → true |
ArrayList: 均摊O(1) LinkedList: O(1) TreeSet: O(log n) |
boolean remove(Object o) |
移除指定元素 | 是否成功 | list.remove("A") → true |
ArrayList: O(n) LinkedList: O(n) HashSet: O(1) |
批量操作方法
| 方法签名 | 功能描述 | 返回值 | 示例 | 说明 |
|---|---|---|---|---|
boolean containsAll(Collection<?> c) |
是否包含集合c中所有元素 | true/false |
list.containsAll(subList) |
检查子集关系 |
boolean addAll(Collection<? extends E> c) |
添加集合c中所有元素 | 是否改变 | list.addAll(anotherList) |
批量添加 |
boolean removeAll(Collection<?> c) |
移除集合c中所有元素 | 是否改变 | list.removeAll(toRemove) |
差集操作 |
boolean retainAll(Collection<?> c) |
仅保留集合c中元素 | 是否改变 | list.retainAll(common) |
交集操作 |
void clear() |
清空集合所有元素 | 无 | list.clear() |
集合变为空 |
转换和迭代方法
| 方法签名 | 功能描述 | 返回值 | 示例 | 说明 |
|---|---|---|---|---|
Object[] toArray() |
转换为Object数组 | Object数组 | list.toArray() |
返回新数组 |
<T> T[] toArray(T[] a) |
转换为指定类型数组 | 指定类型数组 | list.toArray(new String[0]) |
类型安全转换 |
Iterator<E> iterator() |
返回迭代器 | Iterator对象 | list.iterator() |
用于遍历集合 |
default boolean removeIf(Predicate<? super E> filter) |
条件删除 | 是否改变 | list.removeIf(s -> s.length() > 3) |
Java 8+ |
default Spliterator<E> spliterator() |
返回分割迭代器 | Spliterator对象 | list.spliterator() |
Java 8+,并行遍历 |
default Stream<E> stream() |
返回顺序流 | Stream对象 | list.stream() |
Java 8+,流操作 |
default Stream<E> parallelStream() |
返回并行流 | Stream对象 | list.parallelStream() |
Java 8+,并行流操作 |
集合运算方法
| 方法 | 数学运算 | 示意图 | 示例 |
|---|---|---|---|
addAll() |
并集 | A ∪ B | A.addAll(B) |
retainAll() |
交集 | A ∩ B | A.retainAll(B) |
removeAll() |
差集 | A - B | A.removeAll(B) |
常见操作示例
| 操作需求 | 代码示例 | 说明 |
|---|---|---|
| 遍历集合 | for (E e : collection) { ... } |
增强for循环 |
| 安全遍历并删除 | iterator.remove() |
使用迭代器删除 |
| 转换为数组 | String[] arr = coll.toArray(new String[0]) |
推荐写法 |
| 批量添加元素 | coll.addAll(Arrays.asList("A","B","C")) |
初始化集合 |
| 过滤集合 | coll.removeIf(e -> e.startsWith("A")) |
Java 8+ |
| 集合判空 | if (!coll.isEmpty()) { ... } |
优于size() > 0 |
注意事项表格
| 方法 | 注意事项 | 推荐做法 |
|---|---|---|
| contains() | 依赖equals()和hashCode() |
正确实现这两个方法 |
| remove(Object) | 只删除第一个匹配项 | 使用removeIf()删除所有 |
| toArray() | 无参方法返回Object\[\] | 使用带参方法指定类型 |
| addAll() | 可能修改原集合 | 注意并发修改异常 |
| clear() | 不释放元素引用 | 大集合考虑设为null |
| iterator() | 遍历时不能修改集合 | 使用迭代器的remove() |
| 场景 | 建议 | 理由 |
|---|---|---|
| 频繁包含检查 | 使用HashSet |
O(1)时间复杂度 |
| 频繁插入删除 | 使用LinkedList |
首尾操作O(1) |
| 随机访问 | 使用ArrayList |
O(1)索引访问 |
| 需要排序 | 使用TreeSet |
自动维护顺序 |
| 线程安全 | 使用并发集合 | ConcurrentHashMap等 |
| 只读操作 | 使用不可变集合 | Collections.unmodifiableXXX() |
Collection集合中所包含的方法:
java
public interface Collection<E> extends Iterable<E> {
// 基本操作方法
int size();
boolean isEmpty();
boolean contains(Object o);
boolean add(E e);
boolean remove(Object o);
// 批量操作
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
// 数组转换
Object[] toArray();
<T> T[] toArray(T[] a);
// 迭代器
Iterator<E> iterator();
// Java 8 新增方法
default boolean removeIf(Predicate<? super E> filter) { ... }
default Spliterator<E> spliterator() { ... }
default Stream<E> stream() { ... }
default Stream<E> parallelStream() { ... }
}1、Set集合
Set集合的特点:元素不重复,存取无序,无下标;
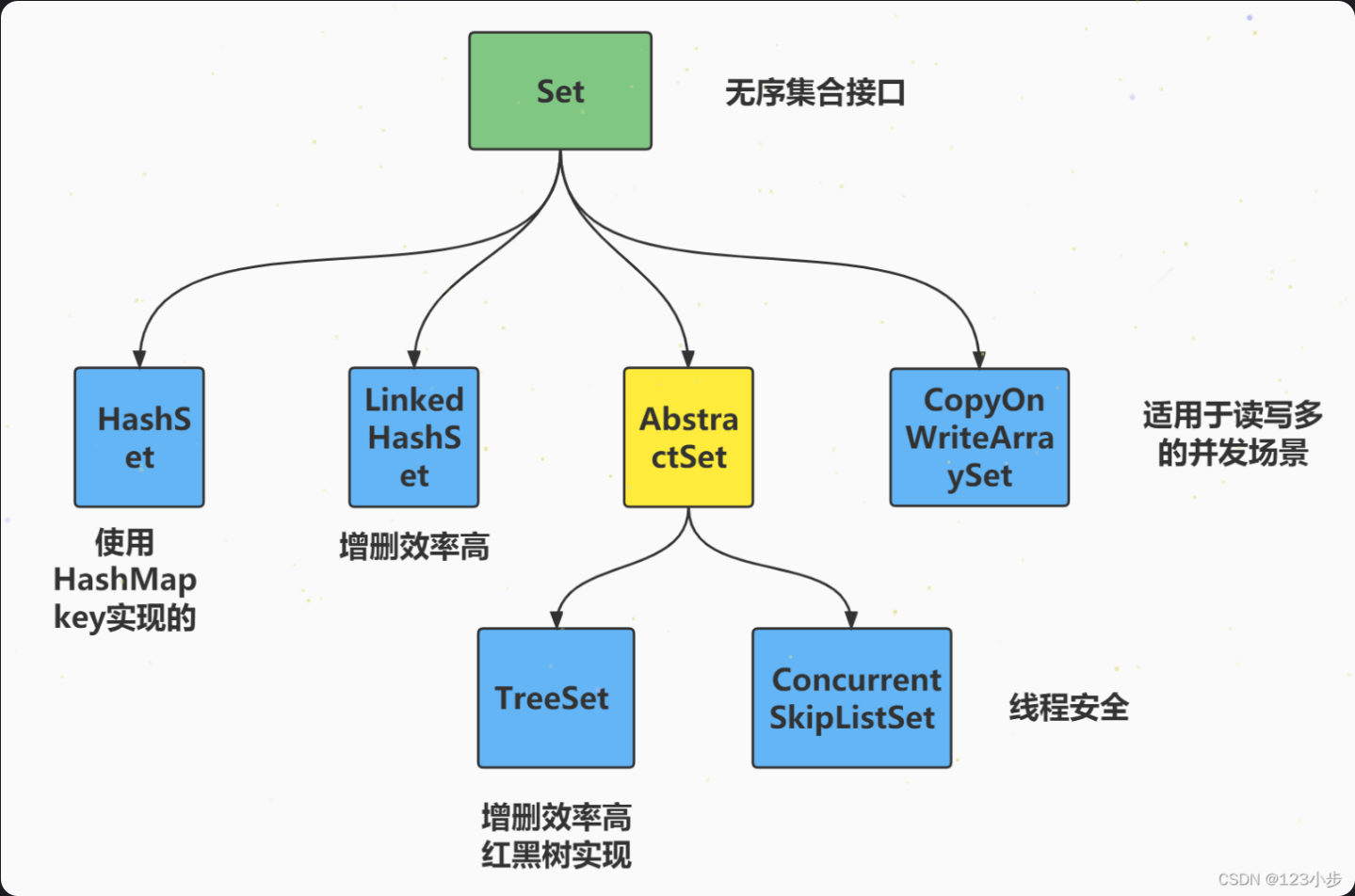
Set<E> (接口)
├── HashSet<E> (实现类)
│ └── LinkedHashSet<E> (子类)
├── SortedSet<E> (接口)
│ └── TreeSet<E> (实现类)
├── EnumSet<E> (实现类)
└── CopyOnWriteArraySet<E> (并发实现)Set 接口核心特性
| 特性 | 说明 |
|---|---|
| 唯一性 | 不允许重复元素 |
| 无序性 | 不保证插入顺序(除LinkedHashSet) |
| 允许null | 大多数实现允许一个null元素 |
| 数学运算 | 支持并集、交集、差集等操作 |
| 无索引 | 不能通过索引访问元素 |
1、HashSet
一个标准的Set集合底层是使用HashMap的Key实现的,特点为:线程不安全,不可重复,无序 。
HashSet 是 Java 中最常用的 Set 实现,基于 HashMap 实现,具有快速查找、插入和删除的特性。
底层实现原理
java
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// 底层使用 HashMap 存储
private transient HashMap<E, Object> map;
// 所有元素共享的虚拟值
private static final Object PRESENT = new Object();
// 构造方法
public HashSet() {
map = new HashMap<>(); // 默认初始容量16,加载因子0.75
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
}核心特性
| 特性 | 说明 |
|---|---|
| 底层实现 | 基于 HashMap(元素作为Key) |
| 唯一性 | 不允许重复元素 |
| 无序性 | 不保证插入顺序 |
| 允许null | 允许一个null元素 |
| 线程安全 | 非线程安全 |
| 性能 | O(1) 的基本操作(平均情况) |
| 扩容 | 默认初始容量16,加载因子0.75 |
构造方法详解
java
// 1. 默认构造(容量16,加载因子0.75)
HashSet<String> set1 = new HashSet<>();
// 2. 指定初始容量
HashSet<String> set2 = new HashSet<>(100); // 初始容量100
// 3. 指定初始容量和加载因子
HashSet<String> set3 = new HashSet<>(100, 0.8f);
// 初始容量100,加载因子0.8
// 4. 从集合构造
List<String> list = Arrays.asList("A", "B", "C", "A");
HashSet<String> set4 = new HashSet<>(list); // 自动去重:[A, B, C]
// 5. 特殊构造(包访问权限,用于LinkedHashSet)
// HashSet(int initialCapacity, float loadFactor, boolean dummy)添加元素
java
// HashSet的add方法实际调用HashMap的put方法
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
// HashMap.put() 方法的核心逻辑:
// 1. 计算key的hash值
// 2. 找到对应的桶(bucket)
// 3. 如果桶为空,直接插入
// 4. 如果桶不为空,遍历链表/红黑树
// 5. 找到相同key(equals为true)则替换值
// 6. 未找到则添加到链表/树末尾删除元素
java
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
// 实际调用HashMap.remove()查找元素
java
public boolean contains(Object o) {
return map.containsKey(o);
}基本操作
java
// 创建HashSet
HashSet<String> fruits = new HashSet<>();
// 1. 添加元素
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
fruits.add("Apple"); // 重复元素,不会添加
fruits.add(null); // 允许null
System.out.println(fruits); // [null, Apple, Banana, Orange]
// 2. 检查元素
boolean hasApple = fruits.contains("Apple"); // true
boolean hasGrape = fruits.contains("Grape"); // false
boolean isEmpty = fruits.isEmpty(); // false
// 3. 删除元素
fruits.remove("Banana"); // 删除成功返回true
fruits.remove("Watermelon"); // 元素不存在返回false
fruits.remove(null); // 删除null元素
// 4. 获取大小
int size = fruits.size(); // 2
// 5. 清空集合
fruits.clear();
System.out.println(fruits); // []遍历方式
java
HashSet<String> set = new HashSet<>();
set.addAll(Arrays.asList("A", "B", "C", "D", "E"));
// 1. 增强for循环
for (String item : set) {
System.out.println(item);
}
// 2. 迭代器
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
System.out.println(item);
// iterator.remove(); // 可以在迭代时删除
}
// 3. Java 8+ forEach
set.forEach(System.out::println);
// 4. 转换为数组遍历
Object[] array = set.toArray();
for (Object obj : array) {
System.out.println(obj);
}
// 5. 转换为流处理
set.stream()
.filter(s -> s.startsWith("A"))
.forEach(System.out::println);集合运算
java
HashSet<Integer> setA = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5));
HashSet<Integer> setB = new HashSet<>(Arrays.asList(4, 5, 6, 7, 8));
// 1. 并集
HashSet<Integer> union = new HashSet<>(setA);
union.addAll(setB);
System.out.println("并集: " + union); // [1, 2, 3, 4, 5, 6, 7, 8]
// 2. 交集
HashSet<Integer> intersection = new HashSet<>(setA);
intersection.retainAll(setB);
System.out.println("交集: " + intersection); // [4, 5]
// 3. 差集 (A - B)
HashSet<Integer> difference = new HashSet<>(setA);
difference.removeAll(setB);
System.out.println("差集A-B: " + difference); // [1, 2, 3]
// 4. 对称差集 (A ∪ B - A ∩ B)
HashSet<Integer> symmetricDiff = new HashSet<>(setA);
symmetricDiff.addAll(setB); // 先并集
HashSet<Integer> tmp = new HashSet<>(setA);
tmp.retainAll(setB); // 交集
symmetricDiff.removeAll(tmp); // 减去交集
System.out.println("对称差集: " + symmetricDiff); // [1, 2, 3, 6, 7, 8]
// 5. 子集判断
boolean isSubset = setA.containsAll(new HashSet<>(Arrays.asList(1, 2))); // true
boolean isSuperset = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5, 6)).containsAll(setA); // true2、LinkedHashSet
LinkedHashSet 是 HashSet 的子类,在 HashSet 的基础上维护了元素的插入顺序,通过双向链表记录插入顺序。
底层实现原理
java
public class LinkedHashSet<E> extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// 继承自HashSet,底层使用LinkedHashMap
// 构造方法调用父类的特殊构造
public LinkedHashSet() {
super(16, 0.75f, true); // 关键:dummy参数为true
}
}
// HashSet中的特殊构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}LinkedHashMap 结构
java
public class LinkedHashMap<K,V> extends HashMap<K,V> {
// 双向链表节点
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 前后指针
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 链表头尾
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
// 访问顺序标志
final boolean accessOrder;
}核心特性
| 特性 | LinkedHashSet | HashSet | TreeSet |
|---|---|---|---|
| 底层实现 | LinkedHashMap | HashMap | TreeMap |
| 唯一性 | ✅ 不允许重复 | ✅ 不允许重复 | ✅ 不允许重复 |
| 顺序性 | ✅ 插入顺序 | ❌ 无序 | ✅ 自然排序 |
| 允许null | ✅ 允许一个null | ✅ 允许一个null | ❌ 不允许null |
| 线程安全 | ❌ 非线程安全 | ❌ 非线程安全 | ❌ 非线程安全 |
| 性能 | O(1) 基本操作 | O(1) 基本操作 | O(log n) 基本操作 |
| 内存开销 | 较高(维护链表) | 较低 | 中等 |
构造方法详解
java
// 1. 默认构造(容量16,加载因子0.75)
LinkedHashSet<String> set1 = new LinkedHashSet<>();
// 2. 指定初始容量
LinkedHashSet<String> set2 = new LinkedHashSet<>(100);
// 3. 指定初始容量和加载因子
LinkedHashSet<String> set3 = new LinkedHashSet<>(100, 0.8f);
// 4. 从集合构造(保持原集合的顺序)
List<String> list = Arrays.asList("C", "A", "B", "C", "A");
LinkedHashSet<String> set4 = new LinkedHashSet<>(list);
// 顺序:[C, A, B](去重,保持第一次出现的顺序)
// 特殊:通过Collections.newSetFromMap()
Set<String> synchronizedSet = Collections.newSetFromMap(
new LinkedHashMap<String, Boolean>()
);基本操作
java
// 创建LinkedHashSet
LinkedHashSet<String> fruits = new LinkedHashSet<>();
// 1. 添加元素(保持插入顺序)
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
fruits.add("Apple"); // 重复,不添加
fruits.add("Grape");
fruits.add(null); // 允许null
System.out.println(fruits);
// 输出:[Apple, Banana, Orange, Grape, null](保持插入顺序)
// 2. 遍历验证顺序
System.out.println("遍历顺序:");
for (String fruit : fruits) {
System.out.println(fruit); // Apple, Banana, Orange, Grape, null
}
// 3. 删除元素(不会影响其他元素的顺序)
fruits.remove("Banana");
System.out.println("删除Banana后:" + fruits);
// [Apple, Orange, Grape, null]
// 4. 插入新元素(添加到末尾)
fruits.add("Peach");
System.out.println("添加Peach后:" + fruits);
// [Apple, Orange, Grape, null, Peach]
// 5. 重新添加已存在元素(位置不变)
fruits.add("Apple"); // Apple已存在,位置不变
System.out.println("重新添加Apple后:" + fruits);
// [Apple, Orange, Grape, null, Peach](顺序不变)迭代器特性
java
LinkedHashSet<Integer> set = new LinkedHashSet<>();
for (int i = 1; i <= 5; i++) {
set.add(i);
}
// 迭代器按插入顺序遍历
Iterator<Integer> iterator = set.iterator();
System.out.print("迭代器输出:");
while (iterator.hasNext()) {
System.out.print(iterator.next() + " "); // 1 2 3 4 5
}
System.out.println();
// 列表迭代器(LinkedHashSet没有直接提供,但可以通过转换)
List<Integer> list = new ArrayList<>(set);
ListIterator<Integer> listIterator = list.listIterator();
while (listIterator.hasNext()) {
System.out.print(listIterator.next() + " ");
}集合运算保持顺序
java
LinkedHashSet<Integer> setA = new LinkedHashSet<>();
Collections.addAll(setA, 1, 3, 5, 7, 9);
LinkedHashSet<Integer> setB = new LinkedHashSet<>();
Collections.addAll(setB, 2, 4, 6, 8, 5, 7);
// 并集(保持setA和setB的插入顺序)
LinkedHashSet<Integer> union = new LinkedHashSet<>(setA);
union.addAll(setB); // setB的元素按setB的顺序添加到末尾
System.out.println("并集:" + union); // [1, 3, 5, 7, 9, 2, 4, 6, 8]
// 交集(保持setA的顺序)
LinkedHashSet<Integer> intersection = new LinkedHashSet<>(setA);
intersection.retainAll(setB);
System.out.println("交集:" + intersection); // [5, 7](保持setA中的顺序)
// 差集(保持setA的顺序)
LinkedHashSet<Integer> difference = new LinkedHashSet<>(setA);
difference.removeAll(setB);
System.out.println("差集:" + difference); // [1, 3, 9](保持setA中的顺序)3、TreeSet
TreeSet 是基于红黑树(Red-Black Tree) 实现的 NavigableSet,元素自动排序 且不允许重复 。
底层实现原理
java
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable {
// 底层使用 TreeMap
private transient NavigableMap<E,Object> m;
// 虚拟值
private static final Object PRESENT = new Object();
// 构造方法
public TreeSet() {
this(new TreeMap<E,Object>()); // 自然排序
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator)); // 定制排序
}
}红黑树特性
java
// TreeMap 中的红黑树节点
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left; // 左子树
Entry<K,V> right; // 右子树
Entry<K,V> parent; // 父节点
boolean color = BLACK; // 颜色(红/黑)
// 红黑树五大特性:
// 1. 节点是红色或黑色
// 2. 根节点是黑色
// 3. 所有叶子节点(NIL)是黑色
// 4. 红色节点的两个子节点都是黑色
// 5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
}核心特性
| 特性 | TreeSet | HashSet | LinkedHashSet |
|---|---|---|---|
| 底层结构 | 红黑树 | 哈希表 | 哈希表+链表 |
| 排序方式 | 自然排序/定制排序 | 无顺序 | 插入顺序 |
| 时间复杂度 | O(log n) | O(1) | O(1) |
| 允许null | ❌(除非指定Comparator) | ✅ | ✅ |
| 线程安全 | ❌ | ❌ | ❌ |
| 内存开销 | 较高 | 较低 | 中等 |
| 范围查询 | ✅ 支持 | ❌ | ❌ |
构造方法详解
java
// 1. 默认构造(自然排序)
TreeSet<Integer> set1 = new TreeSet<>();
// 元素必须实现Comparable接口
// 2. 指定Comparator
TreeSet<String> set2 = new TreeSet<>(Comparator.reverseOrder());
// 3. 从集合构造(使用自然排序)
List<Integer> list = Arrays.asList(5, 2, 8, 1, 9);
TreeSet<Integer> set3 = new TreeSet<>(list);
// 自动排序:[1, 2, 5, 8, 9]
// 4. 从SortedSet构造(保持原有排序)
SortedSet<Integer> sorted = new TreeSet<>(Comparator.reverseOrder());
sorted.addAll(Arrays.asList(5, 2, 8));
TreeSet<Integer> set4 = new TreeSet<>(sorted);
// 保持逆序:[8, 5, 2]
// 5. 使用NavigableMap构造
NavigableMap<String, Object> map = new TreeMap<>();
TreeSet<String> set5 = new TreeSet<>(map);元素排序规则
自然排序(Comparable)
java
// 元素类必须实现Comparable接口
class Student implements Comparable<Student> {
private String name;
private int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
@Override
public int compareTo(Student other) {
// 先按分数排序,分数相同按姓名排序
int scoreCompare = Integer.compare(this.score, other.score);
if (scoreCompare != 0) {
return scoreCompare;
}
return this.name.compareTo(other.name);
}
@Override
public String toString() {
return name + ":" + score;
}
}
// 使用
TreeSet<Student> students = new TreeSet<>();
students.add(new Student("Alice", 85));
students.add(new Student("Bob", 92));
students.add(new Student("Charlie", 78));
students.add(new Student("David", 85)); // 分数相同,按姓名排序
System.out.println(students);
// [Charlie:78, Alice:85, David:85, Bob:92]定制排序(Comparator)
java
// 1. 字符串长度排序
TreeSet<String> byLength = new TreeSet<>(
Comparator.comparing(String::length)
.thenComparing(String::compareTo)
);
byLength.addAll(Arrays.asList("Apple", "Banana", "Cat", "Dog", "Elephant"));
System.out.println(byLength); // [Cat, Dog, Apple, Banana, Elephant]
// 2. 逆序排序
TreeSet<Integer> reversed = new TreeSet<>(Comparator.reverseOrder());
reversed.addAll(Arrays.asList(5, 2, 8, 1, 9));
System.out.println(reversed); // [9, 8, 5, 2, 1]
// 3. 复杂对象多字段排序
class Product {
String name;
double price;
int stock;
}
TreeSet<Product> products = new TreeSet<>(
Comparator.comparing(Product::getPrice)
.thenComparing(Product::getName)
.thenComparingInt(Product::getStock)
);
// 4. 处理null值
TreeSet<String> withNulls = new TreeSet<>(
Comparator.nullsFirst(String::compareTo)
);
withNulls.add(null);
withNulls.add("Apple");
withNulls.add("Banana");
System.out.println(withNulls); // [null, Apple, Banana]基本操作
java
// 创建TreeSet
TreeSet<String> fruits = new TreeSet<>();
// 1. 添加元素(自动排序)
fruits.add("Orange");
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Apple"); // 重复元素,不会添加
// fruits.add(null); // 抛出NullPointerException(默认情况下)
System.out.println(fruits); // [Apple, Banana, Orange]
// 2. 遍历(按排序顺序)
for (String fruit : fruits) {
System.out.println(fruit); // Apple, Banana, Orange
}
// 3. 删除元素
fruits.remove("Banana");
System.out.println(fruits); // [Apple, Orange]
// 4. 清空集合
fruits.clear();
System.out.println(fruits.isEmpty()); // true范围查询操作
java
TreeSet<Integer> numbers = new TreeSet<>();
for (int i = 1; i <= 10; i++) {
numbers.add(i);
}
// 子集操作
SortedSet<Integer> headSet = numbers.headSet(5); // [1, 2, 3, 4]
SortedSet<Integer> tailSet = numbers.tailSet(6); // [6, 7, 8, 9, 10]
SortedSet<Integer> subSet = numbers.subSet(3, 7); // [3, 4, 5, 6]
// 包含边界控制
SortedSet<Integer> headSetInclusive = numbers.headSet(5, true); // [1, 2, 3, 4, 5]
SortedSet<Integer> subSetExclusive = numbers.subSet(3, false, 7, false); // [4, 5, 6]
// 获取范围内的元素(闭区间)
NavigableSet<Integer> range = numbers.subSet(2, true, 8, true);
System.out.println("2到8的范围: " + range); // [2, 3, 4, 5, 6, 7, 8]导航方法
java
TreeSet<Integer> set = new TreeSet<>(Arrays.asList(2, 4, 6, 8, 10));
// 获取首尾元素
Integer first = set.first(); // 2
Integer last = set.last(); // 10
// 小于/小于等于
Integer lower = set.lower(5); // 4(小于5的最大元素)
Integer floor = set.floor(5); // 4(小于等于5的最大元素)
Integer floorExact = set.floor(4); // 4
// 大于/大于等于
Integer higher = set.higher(5); // 6(大于5的最小元素)
Integer ceiling = set.ceiling(5); // 6(大于等于5的最小元素)
Integer ceilingExact = set.ceiling(4); // 4
// 弹出首尾元素
Integer pollFirst = set.pollFirst(); // 2,并从集合移除
Integer pollLast = set.pollLast(); // 10,并从集合移除
System.out.println("弹出后: " + set); // [4, 6, 8]4、ConcurrentSkipListSet
ConcurrentSkipListSet 是基于跳表(Skip List)实现的线程安全的有序集合 ,是 TreeSet 的并发版本
底层实现原理
跳表数据结构
java
// 跳表节点结构
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
// 索引层
volatile Index<K,V>[] indices;
}
// 索引层结构
static class Index<K,V> {
final Node<K,V> node; // 引用的数据节点
final Index<K,V> down; // 下层索引
volatile Index<K,V> right; // 右侧索引
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
}跳表示意图
Level 3: head ------------------------> 50 ------------------------> tail
↓ ↓ ↓
Level 2: head ------------> 30 ------------> 50 ------------> 70 ---> tail
↓ ↓ ↓ ↓ ↓
Level 1: head ----> 10 ----> 30 ----> 40 ----> 50 ----> 60 ----> 70 ---> tail
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
Level 0: head -> 10 -> 20 -> 30 -> 40 -> 50 -> 60 -> 70 -> 80 -> 90 -> tail核心特性
| 特性 | ConcurrentSkipListSet | TreeSet | CopyOnWriteArraySet |
|---|---|---|---|
| 底层结构 | 跳表(Skip List) | 红黑树 | 动态数组 |
| 线程安全 | ✅ 是(无锁CAS) | ❌ 否 | ✅ 是 |
| 有序性 | ✅ 自然排序 | ✅ 自然排序 | ❌ 无序 |
| 并发性能 | ✅ 高(读多写多) | ❌ 低 | ✅ 读多写少 |
| 时间复杂度 | O(log n) | O(log n) | 读O(1),写O(n) |
| 允许null | ❌ 不允许 | ❌ 不允许 | ✅ 允许 |
| 内存开销 | 中等 | 较高 | 高 |
构造方法
java
// 1. 默认构造(自然排序)
ConcurrentSkipListSet<Integer> set1 = new ConcurrentSkipListSet<>();
// 2. 指定Comparator
ConcurrentSkipListSet<String> set2 =
new ConcurrentSkipListSet<>(Comparator.reverseOrder());
// 3. 从集合构造
List<Integer> list = Arrays.asList(5, 2, 8, 1, 9);
ConcurrentSkipListSet<Integer> set3 =
new ConcurrentSkipListSet<>(list);
// 自动排序:[1, 2, 5, 8, 9]
// 4. 从SortedSet构造
SortedSet<Integer> sorted = new TreeSet<>();
sorted.addAll(Arrays.asList(5, 2, 8));
ConcurrentSkipListSet<Integer> set4 =
new ConcurrentSkipListSet<>(sorted);基本操作
java
ConcurrentSkipListSet<String> set = new ConcurrentSkipListSet<>();
// 1. 并发添加元素
Thread t1 = new Thread(() -> {
set.add("Apple");
set.add("Banana");
});
Thread t2 = new Thread(() -> {
set.add("Orange");
set.add("Apple"); // 重复元素,不会添加
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(set); // [Apple, Banana, Orange](已排序)
// 2. 安全遍历
for (String fruit : set) {
System.out.println(fruit); // 线程安全遍历
}
// 3. 删除元素
boolean removed = set.remove("Banana");
System.out.println("删除Banana: " + removed); // true
// 4. 清空集合
set.clear();
System.out.println("是否为空: " + set.isEmpty()); // true并发操作示例
java
public class ConcurrentSetExample {
private final ConcurrentSkipListSet<Integer> numbers =
new ConcurrentSkipListSet<>();
private final int THREAD_COUNT = 10;
private final int OPERATIONS_PER_THREAD = 1000;
public void concurrentTest() throws InterruptedException {
List<Thread> threads = new ArrayList<>();
// 创建生产者线程
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadId = i;
Thread producer = new Thread(() -> {
Random random = new Random();
for (int j = 0; j < OPERATIONS_PER_THREAD; j++) {
int num = random.nextInt(10000);
numbers.add(num); // 并发添加
if (j % 100 == 0) {
// 偶尔删除
Integer first = numbers.pollFirst();
if (first != null) {
// 处理删除的元素
}
}
}
});
threads.add(producer);
}
// 创建消费者线程(只读)
for (int i = 0; i < THREAD_COUNT / 2; i++) {
Thread consumer = new Thread(() -> {
for (int j = 0; j < OPERATIONS_PER_THREAD; j++) {
// 并发遍历(安全)
for (Integer num : numbers) {
// 处理元素
}
// 范围查询
Set<Integer> subset = numbers.subSet(1000, 2000);
// 处理子集
}
});
threads.add(consumer);
}
// 启动所有线程
threads.forEach(Thread::start);
// 等待所有线程完成
for (Thread thread : threads) {
thread.join();
}
System.out.println("最终集合大小: " + numbers.size());
System.out.println("最小值: " + numbers.first());
System.out.println("最大值: " + numbers.last());
}
}导航和范围查询
java
ConcurrentSkipListSet<Integer> set = new ConcurrentSkipListSet<>();
for (int i = 1; i <= 100; i++) {
set.add(i);
}
// 1. 导航方法(线程安全)
Integer lower = set.lower(50); // 49(小于50的最大元素)
Integer floor = set.floor(50); // 50(小于等于50的最大元素)
Integer higher = set.higher(50); // 51(大于50的最小元素)
Integer ceiling = set.ceiling(50); // 50(大于等于50的最小元素)
// 2. 弹出首尾元素(线程安全)
Integer first = set.pollFirst(); // 1,并从集合移除
Integer last = set.pollLast(); // 100,并从集合移除
// 3. 子集操作(返回视图,支持并发修改)
ConcurrentNavigableSet<Integer> headSet = set.headSet(50); // [2..49]
ConcurrentNavigableSet<Integer> tailSet = set.tailSet(51); // [51..99]
ConcurrentNavigableSet<Integer> subSet = set.subSet(20, 80); // [20..79]
// 4. 包含边界的子集
ConcurrentNavigableSet<Integer> inclusiveSubSet =
set.subSet(20, true, 80, true); // [20..80]
// 5. 逆序视图
ConcurrentNavigableSet<Integer> descendingSet = set.descendingSet();
// 逆序遍历
Iterator<Integer> descendingIterator = set.descendingIterator();5、CopyOnWriteArraySet
CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 实现的线程安全 的 Set,采用 "写时复制" 策略,适合读多写少的并发场景。
底层实现原理
java
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {
// 底层使用 CopyOnWriteArrayList
private final CopyOnWriteArrayList<E> al;
// 构造方法
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public CopyOnWriteArraySet(Collection<? extends E> c) {
// 使用CopyOnWriteArrayList的去重构造
al = new CopyOnWriteArrayList<E>();
al.addAllAbsent(c); // 只添加不存在的元素
}
}核心特性
| 特性 | CopyOnWriteArraySet | HashSet | ConcurrentSkipListSet |
|---|---|---|---|
| 底层结构 | 动态数组 | 哈希表 | 跳表 |
| 线程安全 | ✅ 是 | ❌ 否 | ✅ 是 |
| 写时复制 | ✅ 是 | ❌ 否 | ❌ 否 |
| 有序性 | 插入顺序 | 无序 | 自然排序 |
| 允许null | ✅ 允许 | ✅ 允许 | ❌ 不允许 |
| 迭代器 | 快照迭代器 | 快速失败 | 弱一致迭代器 |
| 读性能 | ✅ 极快(无锁) | ✅ 快 | ✅ 快 |
| 写性能 | ❌ 慢(复制数组) | ✅ 快 | ✅ 较快 |
| 内存开销 | 高 | 低 | 中等 |
| 构造方法 |
java
// 1. 默认构造(空集合)
CopyOnWriteArraySet<String> set1 = new CopyOnWriteArraySet<>();
// 2. 从集合构造(自动去重)
List<String> list = Arrays.asList("A", "B", "A", "C");
CopyOnWriteArraySet<String> set2 = new CopyOnWriteArraySet<>(list);
// 结果:[A, B, C](保持第一次出现的顺序)
// 3. 从数组构造(需要先转为集合)
String[] array = {"X", "Y", "X", "Z"};
CopyOnWriteArraySet<String> set3 =
new CopyOnWriteArraySet<>(Arrays.asList(array));
// 4. 从其他Set构造(保持原Set特性)
Set<String> hashSet = new HashSet<>(Arrays.asList("A", "B", "C"));
CopyOnWriteArraySet<String> set4 = new CopyOnWriteArraySet<>(hashSet);添加元素
java
// CopyOnWriteArraySet的add方法
public boolean add(E e) {
return al.addIfAbsent(e); // 关键:保证元素唯一
}
// CopyOnWriteArrayList的addIfAbsent实现
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
// 检查是否已存在
if (indexOf(e, snapshot, 0, snapshot.length) >= 0) {
return false;
}
// 不存在,创建新数组并添加
return addIfAbsent(e, snapshot);
}
private boolean addIfAbsent(E e, Object[] snapshot) {
synchronized (lock) {
Object[] current = getArray();
int len = current.length;
// 再次检查(双重检查锁定模式)
if (snapshot != current) {
int common = Math.min(snapshot.length, len);
for (int i = 0; i < common; i++) {
if (current[i] != snapshot[i] && eq(e, current[i])) {
return false;
}
}
if (indexOf(e, current, common, len) >= 0) {
return false;
}
}
// 创建新数组并添加元素
Object[] newElements = Arrays.copyOf(current, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
}
}查找元素
java
// contains方法(无锁读取)
public boolean contains(Object o) {
return al.contains(o); // 直接读取当前数组
}
// CopyOnWriteArrayList.contains实现
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}迭代器
java
// 返回快照迭代器
public Iterator<E> iterator() {
return al.iterator(); // 基于创建时的数组快照
}
// CopyOnWriteArrayList.iterator实现
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
private final Object[] snapshot;
private int cursor;
COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements; // 保存数组快照
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public E next() {
if (!hasNext()) throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
// 不支持修改操作
public void remove() {
throw new UnsupportedOperationException();
}
}基本操作
java
// 创建CopyOnWriteArraySet
CopyOnWriteArraySet<String> userSet = new CopyOnWriteArraySet<>();
// 1. 添加元素(线程安全)
userSet.add("Alice");
userSet.add("Bob");
userSet.add("Alice"); // 重复,不会添加
userSet.add(null); // 允许null
System.out.println(userSet); // [Alice, Bob, null]
// 2. 并发读取(无需加锁)
boolean hasAlice = userSet.contains("Alice"); // true(无锁读取)
int size = userSet.size(); // 3(无锁读取)
// 3. 安全遍历
for (String user : userSet) {
System.out.println(user); // 不会抛出ConcurrentModificationException
}
// 4. 删除元素
boolean removed = userSet.remove("Bob"); // true
userSet.remove(null); // 删除null元素
// 5. 批量操作
userSet.addAll(Arrays.asList("Charlie", "David", "Eve"));
userSet.removeAll(Arrays.asList("Alice", "Charlie"));
System.out.println("最终集合: " + userSet); // [David, Eve]集合运算
java
CopyOnWriteArraySet<Integer> setA = new CopyOnWriteArraySet<>(
Arrays.asList(1, 2, 3, 4, 5)
);
CopyOnWriteArraySet<Integer> setB = new CopyOnWriteArraySet<>(
Arrays.asList(4, 5, 6, 7, 8)
);
// 1. 并集(线程安全)
CopyOnWriteArraySet<Integer> union = new CopyOnWriteArraySet<>(setA);
union.addAll(setB);
System.out.println("并集: " + union); // [1, 2, 3, 4, 5, 6, 7, 8]
// 2. 交集
CopyOnWriteArraySet<Integer> intersection = new CopyOnWriteArraySet<>(setA);
intersection.retainAll(setB);
System.out.println("交集: " + intersection); // [4, 5]
// 3. 差集
CopyOnWriteArraySet<Integer> difference = new CopyOnWriteArraySet<>(setA);
difference.removeAll(setB);
System.out.println("差集(A-B): " + difference); // [1, 2, 3]
// 4. 对称差集
CopyOnWriteArraySet<Integer> symmetricDiff = new CopyOnWriteArraySet<>(union);
symmetricDiff.removeAll(intersection);
System.out.println("对称差集: " + symmetricDiff); // [1, 2, 3, 6, 7, 8]