文章目录
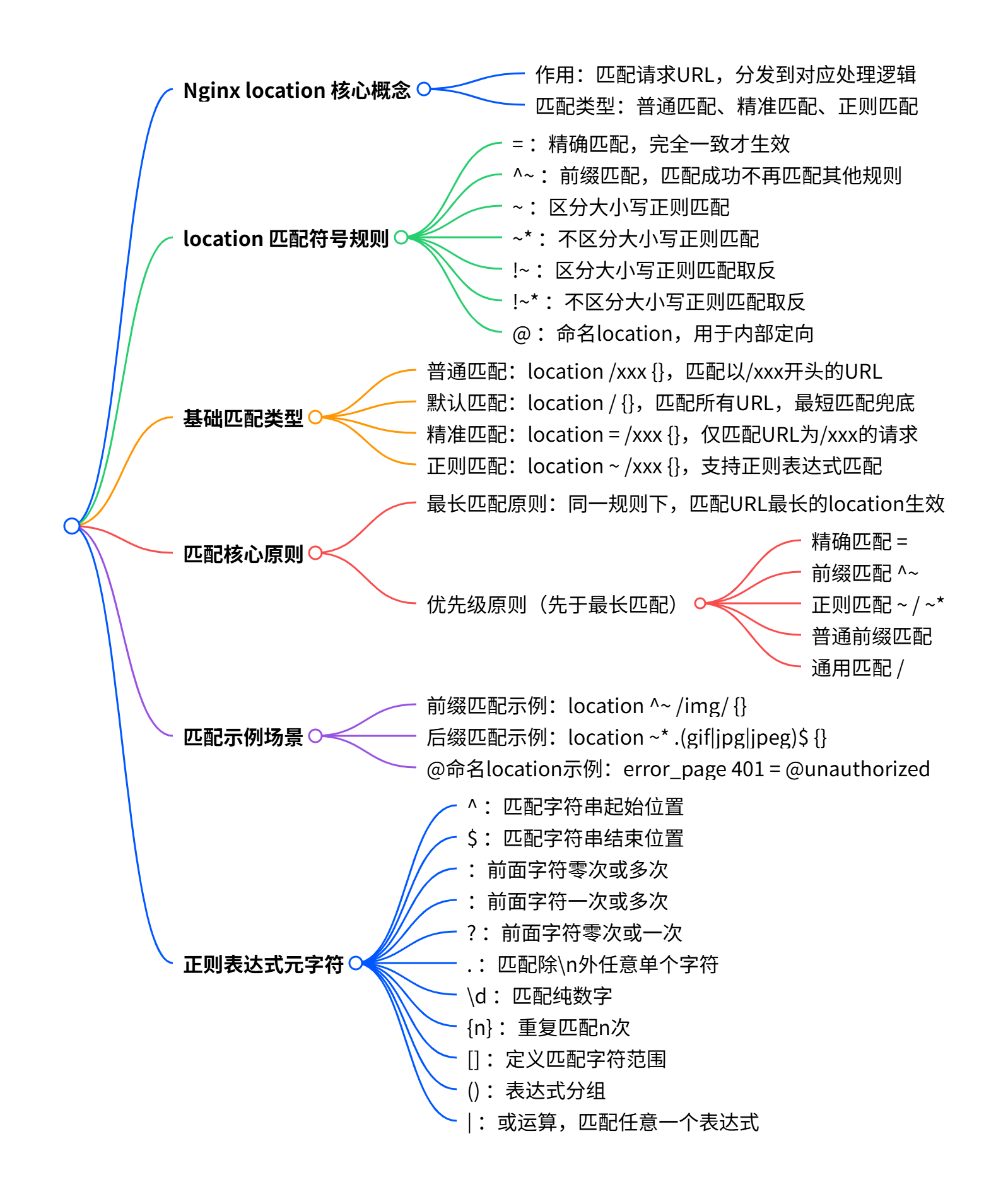
匹配规则
| 符号 | 规则说明 |
|---|---|
| = | 进行普通字符精确匹配,也就是完全匹配 |
| ^~ | 表示普通字符匹配,使用前缀匹配,如果匹配成功,则不再匹配其它 location。 |
| ~ | 区分大小写的匹配 |
| ~* | 不区分大小写的匹配 |
| !~ | 区分大小写的匹配取非,!表示取反 |
| !~* | 不区分大小写的匹配取非。 |
| @ | 定义一个命名的location,使用在内部定向时 |
- 普通匹配:location /xxx {},匹配所有以/xxx开头的url
- 默认匹配:location / {},前缀匹配的特殊情况,匹配所有的url
- 精准匹配:location = /xxx {},精确匹配,只有url为/xxx时,才会匹配,/xx、/xxx/abc 都不匹配
- 正则匹配:location ~ /xxx {},正则匹配,可以使用正则表达式规则匹配
肯定会有善于思考的朋友会问,那我同时有多个location都匹配,怎么办?
所以,有最长匹配原则和匹配优先级规则。
关于最长匹配原则很好理解,一个简单的例子。
我们有如下配置,那么我们访问http://localhost:7000/docs/abc,会走到哪一个location呢?
url会对于2个location:location /docs/abc,location /docs都匹配,那么会选择最长匹配。
conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 7000;
server_name localhost;
charset utf-8;
location /docs/abc {
default_type application/json;
return 200 '{"code":200,"location":"/docs/abc"}';
}
location /docs {
default_type application/json;
return 200 '{"code":200,"location":"/docs"}';
}
}
}现在是不是就理解为什么location / 叫默认匹配了,因为它能匹配所有的url,但是它是最短的,所以只有其他location都没有匹配上的时候,才能匹配到它。
conf
location / {
root html;
index index.html index.htm;
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET,POST,DELETE';
add_header 'Access-Control-Allow-Header' 'Content-Type,*';
}匹配优先级
最长匹配那是针对同一规则下的匹配,如果不同规则,应该怎样匹配呢?
例如,我们nginx配置如下:
conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 7000;
server_name localhost;
charset utf-8;
location /img/abc/xxx {
default_type application/json;
return 200 '{"code":200,"location":"/img/abc/xxx"}';
}
location ~ /img/abc/xxx {
default_type application/json;
return 200 '{"code":200,"location":"~ /img/abc/xxx"}';
}
location ~ /img/abc {
default_type application/json;
return 200 '{"code":200,"location":"~ /img/abc"}';
}
location ^~ /img/abc {
default_type application/json;
return 200 '{"code":200,"location":"^~ /img/abc"}';
}
location /img/abc/xxx/zzz {
default_type application/json;
return 200 '{"code":200,"location":"/img/abc/xxx/zzz"}';
}
}
}下面3个url分别会匹配哪个location呢?
http://localhost:7000/img/abc/xxx/zzz
http://localhost:7000/img/abc/xxx
所以,对于不同规则都能匹配的情况,还需要一个优先级规则。
优先级从高到低排列:
- 精确匹配 =(location = /abc)
- 前缀匹配 ^~ (location ^~ /abc)
- 顺序的正则匹配 或* (location ~ /abc)
- 普通前缀匹配(location /abc)
- 通用匹配(location /)
注意:优先级规则,先于最长匹配规则。
现在,我们对于前面的问题就有答案了:
http://localhost:7000/img/abc/xxx/zzz:匹配location ~ /img/abc/xxx,没有匹配更长的location /img/abc/xxx/zzz,是因为正则匹配优先级,比普通匹配优先级更高。
http://localhost:7000/img/abc/xxx:毫无疑问,匹配location ~ /img/abc/xxx
http://localhost:7000/img/abc:匹配\^\~ /img/abc,因为前缀匹配优先级比普通正则匹配~ /img/abc优先级更高。
location匹配示例
前缀匹配
conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 7000;
server_name localhost;
charset utf-8;
location ^~ /img/ {
default_type application/json;
return 200 '{"code":200,"location":"^~ /img/"}';
}
}
}后缀匹配
conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 7000;
server_name localhost;
charset utf-8;
location ~* \.(gif|jpg|jpeg)$ {
default_type application/json;
return 200 '{"code":200,"location":"后缀匹配"}';
}
}
}@符号
conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 7000;
server_name localhost;
charset utf-8;
location = /401 {
return 401;
}
location = /403 {
return 403;
}
location = /429 {
return 429;
}
error_page 401 = @unauthorized;
error_page 403 = @forbidden;
error_page 429 = @authfail;
location @unauthorized {
default_type application/json;
return 401 '{"code":401,"message":"未授权:token无效或过期","location":"@unauthorized"}';
}
location @forbidden {
default_type application/json;
return 403 '{"code":403,"message":"禁止访问:无该接口权限","location":"@forbidden"}';
}
location @authfail {
default_type application/json;
return 429 '{"code":429,"message":"访问太频繁","location":"@authfail"}';
}
}
}正则表达式元字符说明表
| 元字符 | 功能说明 | 示例 |
|---|---|---|
^ |
匹配输入字符串的起始位置 | - |
$ |
匹配输入字符串的结束位置 | - |
* |
匹配前面的字符零次或多次 | go* 能匹配 g、go、goo、gooo 等 |
+ |
匹配前面的字符一次或多次 | go+ 能匹配 go、go0、gooo,不能匹配 g |
? |
匹配前面的字符零次或一次,等效于 {0,1} |
go? 能匹配 g 或者 go |
. |
匹配除 \n 之外的任何单个字符 |
匹配包括 \n 在内的任意字符可使用 [.\n] |
\ |
转义字符 | \n 匹配换行符,\$ 匹配 $ |
\d |
匹配纯数字 | [0123456789] |
{n} |
重复匹配前面的表达式 n 次 | \d{11}匹配11位数字,简单验证手机号 |
{n,} |
重复匹配前面的表达式 n 次或更多次 | \d{6,} 匹配6位及以上数字 |
{n,m} |
重复匹配前面的表达式 n 到 m 次 | \d{6,12} 匹配6-12位数字 |
[] |
定义匹配的字符范围 | [0-9] 匹配0-9中的任意一个数字,[c] 匹配单个字符 c |
[] |
定义匹配的字符范围 | [a-z]匹配 a-z 小写字母中的任意一个 - |
[] |
定义匹配的字符范围 | [a-zA-Z0-9]匹配所有大小写字母或数字 - |
() |
标记表达式的开始和结束位置,用于分组 | - |
| ` | ` | 或运算符,匹配多个表达式中的任意一个 |