智能体的经典三范式
学习地址: Hello-Agents:从零开始构建智能体系统原理与实践教程
五星好评!!!【good】
ReAct
主要式通过让 ai 掌握(思考、行动)这方面的能力,通过在限定的循环次数内,尽可能得到最优答案
- 为什么要思考?
- 思考是否在现有的ai训练知识中,能够得到答案,思考是否需要借助外部工具进行扩展知识面
- 为什么要行动?
- 从外部获取知识,使用外部工具,获取外部数据
核心思想: 走一步想一步
React的步骤:
思考 ------> 行动 ------> 观察
开始 执行 结果 反馈 结束 任务 思考 行动 观察
代码的实现思路
开始 执行工具及参数 完成 开始 思考 执行 行动 解析 工具执行器 工具1 工具2 结果
1、工具的定义及实现
python
#---各种工具方法
def tool_1(params):
pass
def tool_2(params):
pass
# ----工具执行器
class ToolExecutor:
def __init__(self):
# 初始化这里简单用字典实现工具的存放
self.tools: Dict[str,Dict[str,Any]] = {}
'''
这里定义工具的基本方法
- 注册工具: 将工具保存在字典中
- 得到某个工具:根据工具名称,得到调用函数
- 得到所有工具的描述:主要是得到工具名称,描述,所需要的参数,转成字符串,供LLM使用
'''
def registerTool(self, name: str, description: str, func: callable):
"""
向工具箱中注册一个新工具。
"""
if name in self.tools:
print(f"警告:工具 '{name}' 已存在,将被覆盖。")
self.tools[name] = {"description": description, "func": func}
print(f"工具 '{name}' 已注册。")
def getTool(self, name: str) -> callable:
"""
根据名称获取一个工具的执行函数。
"""
return self.tools.get(name, {}).get("func")
def getAvailableTools(self) -> str:
"""
获取所有可用工具的格式化描述字符串。
"""
return "\n".join([
f"- {name}: {info['description']}"
for name, info in self.tools.items()
])
2、ReAction智能体的编码及实现
(1)定义智能体的提示词
定义ReAction的交互规范提示词
主要由以下部分组成
- 角色:设定智能体的角色
- 工具清单:掌握与外界交互的能力
- 输出规范:【Thought】/【Action],核心点,严格规范LLM以格式化输出,方便程序解析下一步行动该是思考,还是行动
- 动态上下文:记录起始问题,以及过往的思考、行动结果
python
# ReAct 提示词模板
REACT_PROMPT_TEMPLATE = """
请注意,你是一个有能力调用外部工具的智能助手。
可用工具如下:
{tools}
请严格按照以下格式进行回应:
Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。
Action: 你决定采取的行动,必须是以下格式之一:
- `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。
- `Finish[最终答案]`:当你认为已经获得最终答案时。
- 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 finish(answer="...") 来输出最终答案。
现在,请开始解决以下问题:
Question: {question}
History: {history}
"""(2) ReAction实现
核心是循环 : 通过在 "思考" ---> "行动" --->"观察" 中 不断循环,最终达成理想目标,输出结果
其余辅助工具:
- LLM输出的内容进行解析,解析出Thought/Action,从而判断下一步的计划,走一步计划一步
- 工具执行器,当LLM输出含Action的答案时,说明需要执行工具,获取有时效性的知识/计算更精准的数据
- 记录每次思考及行动的输出,提供动态上下文给LLM
python
class ReActAgent:
def __init__(self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5):
self.llm_client = llm_client
self.tool_executor = tool_executor
self.max_steps = max_steps
self.history = []
def run(self, question: str):
"""
运行ReAct智能体来回答一个问题。
"""
self.history = [] # 每次运行时重置历史记录
current_step = 0
while current_step < self.max_steps:
current_step += 1
print(f"--- 第 {current_step} 步 ---")
# 1. 格式化提示词
tools_desc = self.tool_executor.getAvailableTools()
history_str = "\n".join(self.history)
prompt = REACT_PROMPT_TEMPLATE.format(
tools=tools_desc,
question=question,
history=history_str
)
# 2. 调用LLM进行思考
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages)
if not response_text:
print("错误:LLM未能返回有效响应。")
break
# 3. 解析LLM的输出
thought, action = self._parse_output(response_text)
if thought:
print(f"思考: {thought}")
if not action:
print("警告:未能解析出有效的Action,流程终止。")
break
# 4. 执行Action
if action.startswith("Finish"):
# 如果是Finish指令,提取最终答案并结束
final_answer = re.match(r"Finish\[(.*)\]", action).group(1)
print(f"🎉 最终答案: {final_answer}")
return final_answer
tool_name, tool_input = self._parse_action(action)
if not tool_name or not tool_input:
# ... 处理无效Action格式 ...
continue
print(f"🎬 行动: {tool_name}[{tool_input}]")
tool_function = self.tool_executor.getTool(tool_name)
if not tool_function:
observation = f"错误:未找到名为 '{tool_name}' 的工具。"
else:
observation = tool_function(tool_input) # 调用真实工具
# (这段逻辑紧随工具调用之后,在 while 循环的末尾)
print(f"👀 观察: {observation}")
# 将本轮的Action和Observation添加到历史记录中
self.history.append(f"Action: {action}")
self.history.append(f"Observation: {observation}")
# 循环结束
print("已达到最大步数,流程终止。")
return None
# (这些方法是 ReActAgent 类的一部分)
def _parse_output(self, text: str):
"""解析LLM的输出,提取Thought和Action。"""
thought_match = re.search(r"Thought: (.*)", text)
action_match = re.search(r"Action: (.*)", text)
thought = thought_match.group(1).strip() if thought_match else None
action = action_match.group(1).strip() if action_match else None
return thought, action
def _parse_action(self, action_text: str):
"""解析Action字符串,提取工具名称和输入。"""
match = re.match(r"(\w+)\[(.*)\]", action_text)
if match:
return match.group(1), match.group(2)
return None, NoneReAction的特点与局限性
特点:
- 可观察性:可通过思考链路以及行动链路观察到每一步的情况
- 纠错能力,通过每一步的思考以及行动的反馈结果,在下一步进行调整
- 工具结合能力,能调用工具获取知识/精准的数据
局限性:
- 强依赖LLM的能力,如果LLM的输出不规范,解析不了Thought/action,则容易出错
- 执行效率: 串行循环执行,每一步都需要询问LLM,等待下一步操作
- 提示词的脆弱性:词的修改容易影响LLM的输出结果
- 局部最优解:可能会基于目前的反馈做出的思考,不是说不正确,但是可能在长远的目标来看,这部操作不算最好的答案
Plant-and-Solve
与其说ReAction像是在完密室逃脱,通过一点一点,一步一步的破解谜题,找到出口,而Palnt-and-Solve则是像活动策划师一样,为了保证活动的顺利举行,必须要提前规划好每一步骤,将做所有待办项都完成好。
工作原理
两阶段:
- 规划阶段: 负责将问题拆解成多个(可执行、清晰)的步骤/计划
- 执行阶段:严格按照规划阶段的步骤,进行运行,并有记录当前是运行到那个步骤以及相关的上下文
开始规划 执行 执行 执行 结果 问题 规划器 任务集 执行器 t1 t2 t... 记录器
适用场景:
- 数学多步骤任务
- 编程任务:整个项目使用的框架,代码的设计模式,功能函数等
- 多个信息整合的文案编写:如市场调研报告等
Plan-and-Solve 智能体实现
规划阶段
提示词
分为三部分:
- 角色: AI规划专家,阐述了角色以及接下来需要对任务进行拆解
- 问题:变量,用户输入的原始变量
- 输出格式:要求LLM以固定格式输出
python
PLANNER_PROMPT_TEMPLATE = """
你是一个顶级的AI规划专家。你的任务是将用户提出的复杂问题分解成一个由多个简单步骤组成的行动计划。
请确保计划中的每个步骤都是一个独立的、可执行的子任务,并且严格按照逻辑顺序排列。
你的输出必须是一个Python列表,其中每个元素都是一个描述子任务的字符串。
问题: {question}
请严格按照以下格式输出你的计划,``python与``作为前后缀是必要的:
``python
["步骤1", "步骤2", "步骤3", ...]
``
"""代码实现
python
class Planner:
def __init__(self, llm_client):
self.llm_client = llm_client
def plan(self, question: str) -> list[str]:
"""
根据用户问题生成一个行动计划。
"""
prompt = PLANNER_PROMPT_TEMPLATE.format(question=question)
# 为了生成计划,我们构建一个简单的消息列表
messages = [{"role": "user", "content": prompt}]
print("--- 正在生成计划 ---")
# 使用流式输出来获取完整的计划
response_text = self.llm_client.think(messages=messages) or ""
print(f"✅ 计划已生成:\n{response_text}")
# 解析LLM输出的列表字符串
try:
# 找到```python和```之间的内容
plan_str = response_text.split("```python")[1].split("```")[0].strip()
# 使用ast.literal_eval来安全地执行字符串,将其转换为Python列表
plan = ast.literal_eval(plan_str)
return plan if isinstance(plan, list) else []
except (ValueError, SyntaxError, IndexError) as e:
print(f"❌ 解析计划时出错: {e}")
print(f"原始响应: {response_text}")
return []
except Exception as e:
print(f"❌ 解析计划时发生未知错误: {e}")
return []执行阶段
执行阶段分为:执行器与记录器
执行器的提示词与规划的提示词不一样,他专注与当前步骤,并根据上下文了解当前的情况
提示词部分:
- 角色:AI执行师
- 原始问题:原始问题,避免偏离主题
- 计划列表: 规划器得到的规划步骤
- 上下文记录:记录过往的对话
- 当前步骤
python
EXECUTOR_PROMPT_TEMPLATE = """
你是一位顶级的AI执行专家。你的任务是严格按照给定的计划,一步步地解决问题。
你将收到原始问题、完整的计划、以及到目前为止已经完成的步骤和结果。
请你专注于解决"当前步骤",并仅输出该步骤的最终答案,不要输出任何额外的解释或对话。
# 原始问题:
{question}
# 完整计划:
{plan}
# 历史步骤与结果:
{history}
# 当前步骤:
{current_step}
请仅输出针对"当前步骤"的回答:
"""通过循环计划,执行每一步操作,得到每一步的结果,最后一步运行方案就是结果
python
class Executor:
def __init__(self, llm_client):
self.llm_client = llm_client
def execute(self, question: str, plan: list[str]) -> str:
"""
根据计划,逐步执行并解决问题。
"""
history = "" # 用于存储历史步骤和结果的字符串
print("\n--- 正在执行计划 ---")
for i, step in enumerate(plan):
print(f"\n-> 正在执行步骤 {i+1}/{len(plan)}: {step}")
prompt = EXECUTOR_PROMPT_TEMPLATE.format(
question=question,
plan=plan,
history=history if history else "无", # 如果是第一步,则历史为空
current_step=step
)
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
# 更新历史记录,为下一步做准备
history += f"步骤 {i+1}: {step}\n结果: {response_text}\n\n"
print(f"✅ 步骤 {i+1} 已完成,结果: {response_text}")
# 循环结束后,最后一步的响应就是最终答案
final_answer = response_text
return final_answer整合
- 先调用规划器,得到执行步骤
- 执行器得到运行步骤,依次执行计划,最后执行的计划就是结果输出
python
class PlanAndSolveAgent:
def __init__(self, llm_client):
"""
初始化智能体,同时创建规划器和执行器实例。
"""
self.llm_client = llm_client
self.planner = Planner(self.llm_client)
self.executor = Executor(self.llm_client)
def run(self, question: str):
"""
运行智能体的完整流程:先规划,后执行。
"""
print(f"\n--- 开始处理问题 ---\n问题: {question}")
# 1. 调用规划器生成计划
plan = self.planner.plan(question)
# 检查计划是否成功生成
if not plan:
print("\n--- 任务终止 --- \n无法生成有效的行动计划。")
return
# 2. 调用执行器执行计划
final_answer = self.executor.execute(question, plan)
print(f"\n--- 任务完成 ---\n最终答案: {final_answer}")Reflection
名如起名,Reflection 是一个会自我反思的智能体,通过对答案的输出是否创造错误,漏洞,更优的解决方案,得到反馈/建议/优化,从而生成更优的答案
核心思想
执行 -> 反思 -> 优化
- 执行:原始LLM得到的标准答案
- 反思:对上一个的标注答案判断,是否存在错误,遗漏,更优解等,去给出合理建议、优化方向、错误。
- 优化:根据给出的建议,对上一个标准答案更进一步优化。并输出
不断执行这个循环
流程:
开始 结果 需要优化 无需优化 结果 问题 执行 记忆 反思 优化 判断
记忆模块
如果说一个人反思知道自己犯的错误,那需要回忆自己做过的事情,根据不足或错的事情进行反思。
那么Reflection智能体,也要有记忆模块,帮它存起来上一个LLM输出的结果。
比如要优化一个python 算法,必须得给到它自己写的python代码,它才可以分析该代码并进行优化
简单的记忆设计:
- list记录所有记忆
- add_record函数负责添加一个记忆
- get_trajectory函数负责提取所有的记忆,并格式化输出
- get_last_execution函数负责提取最后一次的记忆
python
from typing import List, Dict, Any, Optional
class Memory:
"""
一个简单的短期记忆模块,用于存储智能体的行动与反思轨迹。
"""
def __init__(self):
"""
初始化一个空列表来存储所有记录。
"""
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
"""
向记忆中添加一条新记录。
参数:
- record_type (str): 记录的类型 ('execution' 或 'reflection')。
- content (str): 记录的具体内容 (例如,生成的代码或反思的反馈)。
"""
record = {"type": record_type, "content": content}
self.records.append(record)
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
"""
将所有记忆记录格式化为一个连贯的字符串文本,用于构建提示词。
"""
trajectory_parts = []
for record in self.records:
if record['type'] == 'execution':
trajectory_parts.append(f"--- 上一轮尝试 (代码) ---\n{record['content']}")
elif record['type'] == 'reflection':
trajectory_parts.append(f"--- 评审员反馈 ---\n{record['content']}")
return "\n\n".join(trajectory_parts)
def get_last_execution(self) -> Optional[str]:
"""
获取最近一次的执行结果 (例如,最新生成的代码)。
如果不存在,则返回 None。
"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return NoneReflection智能体的实现
以实现算法编写为例子
提示词设计
既然流程是 执行-> 反思-> 优化,那么提示词设计也分为三部分。
- 一个LLM得到一开始的初始答案
- 第二个LLM对初始答案进行思考
- 第三个提示词对初始答案进行优化
初始执行提示词:
python
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""执行反思提示词:
python
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在<strong>算法效率</strong>上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
``python
{code}
``
请分析该代码的时间复杂度,并思考是否存在一种<strong>算法上更优</strong>的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答"无需改进"。
请直接输出你的反馈,不要包含任何额外的解释。
"""执行优化的提示词:
python
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""智能体的封装
python
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# --- 1. 初始执行 ---
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# --- 2. 迭代循环:反思与优化 ---
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback:
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n```python\n{final_code}\n```")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""一个辅助方法,用于调用LLM并获取完整的流式响应。"""
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
return response_text总结
Reflection 智能体适合场景是对解决方案的质量偏高,而实时性不高
缺点
- 成本偏高,每一个循环都得访问至少2个LLM模型,
- 效率偏慢,采用串行模式,每一个循环都要至少访问2个LLM模型
- 提示词复杂度上升,需要编写多个提示词进行控制
优点
- 高质量解决方案:得益于自我反思的机制,能不断输出高质量答案
- 强鲁棒性:
思维导图
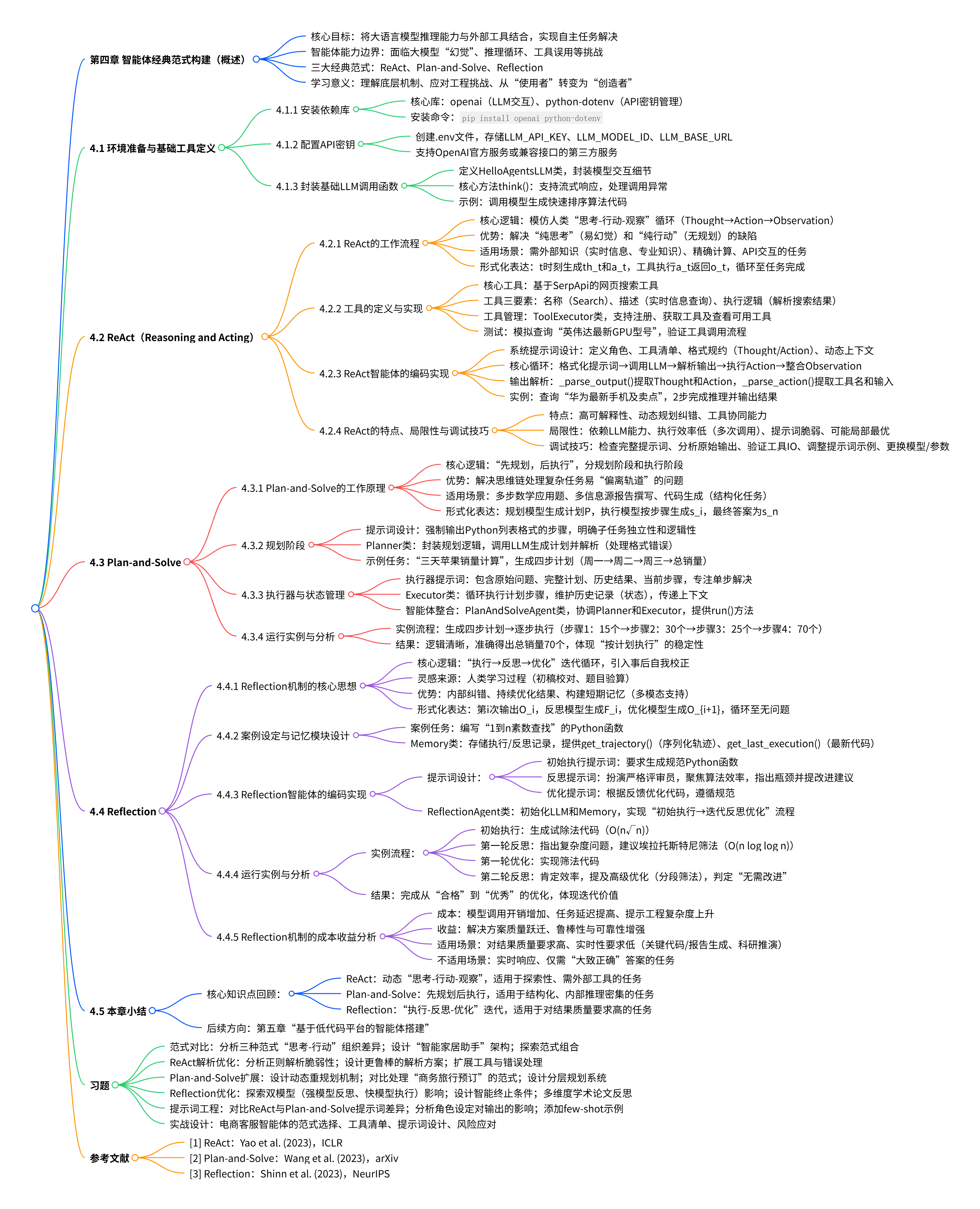
思考
- 介绍了三种经典的智能体范式:ReAct、Plan-and-Solve 和 Reflection。请分析:
-
这三种范式在"思考"与"行动"的组织方式上有什么本质区别?
-
思考:
- ReAct 的思考是基于当前环境下,是否需要调用工具去获取更多时效性知识/准确的数据
- Plan-and-Solve的思考则是对问题的拆解成多个可执行子任务,一步一步执行得到最终答案
- Reflection的思考则是对上一个对话的答案,判断是否还有可优化的空间,并给出优化建议
-
行动
- ReAct的行动是对工具的调用
- Plan-and-Solve的行动则是对plan规划的步骤进行执行
- Reflection的行动是对反思给出的建议,对上一个输出的答案进行优化
-
-
如果要设计一个"智能家居控制助手"(需要控制灯光、空调、窗帘等多个设备,并根据用户习惯自动调节),你会选择哪种范式作为基础架构?为什么?
- 我会选择plan-and-solve的范式作为基础架构
- 用户输入一句话输入多个指令,则需要规划器对指令执行多个子任务划分。
- 然后根据子任务逐个去执行
- 如果需要根据用户习惯自动调节,则需要引入长期记忆模块,记住用户的习惯
- 我会选择plan-and-solve的范式作为基础架构
-
是否可以将这三种范式进行组合使用?若可以,请尝试设计一个混合范式的智能体架构,并说明其适用场景。
- 产品调研报告的生成
- plan-and-solve去拆解报告的生成目录,章节,所需要的数据等
- 需要高质量的解决方案,需要用到Reflection智能体的反思功能,进行总结
- 但是产品数据的时效性可能是过时的,已经不能够为当前的调研做支撑
- 此时引入ReAction 智能体,负责对工具的调用,搜索得到相关的准确性数据,为产品报告提供数据支撑
- 产品调研报告的生成
- 在4.2节的 ReAct 实现中,我们使用了正则表达式来解析大语言模型的输出(如 Thought 和 Action)。请思考:
-
当前的解析方法存在哪些潜在的脆弱性?在什么情况下可能会失败?
- 如果输出没格式化输出时,thought/action正则识别失败,则会导致流程失效并推出
- 当输出内容超过限定token时,thought/action没能显示完成。也会导致失败
-
除了正则表达式,还有哪些更鲁棒的输出解析方案?
- 强提示词约束,让模型输出json格式的thought/action
- 利用LLM的function call 能力,让模型直接调用工具,
- 增加正则匹配的规则,考虑输出错误的形式
- 利用小型LLM对内容整理,辅助LLM的thought/action识别
-
尝试修改本章的代码,使用一种更可靠的输出格式,并对比两种方案的优缺点
python
你必须严格按照以下JSON格式输出,不允许添加任何额外内容:
{
"thought": "你的思考过程",
"action": {
"tool_name": "要调用的工具名",
"tool_input": "工具的输入参数"
}
}- 工具调用是现代智能体的核心能力之一。基于ToolExecutor 设计,请完成以下扩展实践:
提示:这是一道动手实践题,建议实际编写代码
- 为 ReAct 智能体添加一个"计算器"工具,使其能够处理复杂的数学计算问题(如"计算 (123 + 456) × 789/ 12 = ? 的结果")
python
def Calculator(expression):
"""执行计算,使用 asteval 保证安全"""
try:
# 替换中文乘号为英文*,兼容输入
expression = expression.replace("×", "*").replace("÷", "/")
# 初始化安全解释器,禁用外部函数和变量
aeval = Interpreter(
use_numpy=False, # 禁用numpy,简化计算
builtins_override={} # 禁用危险内置函数
)
# 执行计算
result = aeval(expression)
# 处理浮点数和整数的显示
if isinstance(result, float) and result.is_integer():
result = int(result)
return f"计算结果:{result}(表达式:{expression})"
except SyntaxError as e:
return f"表达式语法错误:{str(e)}(输入表达式:{expression})"
except ZeroDivisionError:
return f"计算错误:除数不能为零(输入表达式:{expression})"
except Exception as e:
return f"计算失败:{str(e)}(输入表达式:{expression})"- 设计并实现一个"工具选择失败"的处理机制:当智能体多次调用错误的工具或提供错误的参数时,系统应该如何引导它纠正?
- 设定规范化的错误信息:工具不存在、参数错误、执行工具出错
- 思考:如果可调用工具的数量增加到50个甚至100个,当前的工具描述方式是否还能有效工作?在可调用工具数量随业务需求显著增加时,从工程角度如何优化工具的组织和检索机制?
- Plan-and-Solve 范式将任务分解为"规划"和"执行"两个阶段。请深入分析:
- 在4.3节的实现中,规划阶段生成的计划是"静态"的(一次性生成,不可修改)。如果在执行过程中发现某个步骤无法完成或结果不符合预期,应该如何设计一个"动态重规划"机制?
- 对比 Plan-and-Solve 与 ReAct:在处理"预订一次从北京到上海的商务旅行(包括机票、酒店、租车)"这样的任务时,哪种范式更合适?为什么?
- 尝试设计一个"分层规划"系统:先生成高层次的抽象计划,然后针对每个高层步骤再生成详细的子计划。这种设计有什么优势?
- Reflection 机制通过"执行-反思-优化"循环来提升输出质量。请思考:
- 在4.4节的代码生成案例中,不同阶段使用的是同一个模型。如果使用两个不同的模型(例如,用一个更强大的模型来做反思,用一个更快的模型来做执行),会带来什么影响?
- Reflection 机制的终止条件是"反馈中包含无需改进"或"达到最大迭代次数"。这种设计是否合理?能否设计一个更智能的终止条件?
- 假设你要搭建一个"学术论文写作助手",它能够生成初稿并不断优化论文内容。请设计一个多维度的Reflection机制,从段落逻辑性、方法创新性、语言表达、引用规范等多个角度进行反思和改进。
- 提示词工程是影响智能体最终效果的关键技术。本章展示了多个精心设计的提示词模板。请分析:
- 对比4.2.3节的 ReAct 提示词和4.3.2节的 Plan-and-Solve 提示词,它们显然存在结构设计上的明显不同,这些差异是如何服务于各自范式的核心逻辑的?
- 在4.4.3节的 Reflection 提示词中,我们使用了"你是一位极其严格的代码评审专家"这样的角色设定。尝试修改这个角色设定(如改为"你是一位注重代码可读性的开源项目维护者"),观察输出结果的变化,并总结角色设定对智能体行为的影响。
- 在提示词中加入 few-shot 示例往往能显著提升模型对特定格式的遵循能力。请为本章的某个智能体尝试添加 few-shot 示例,并对比其效果。
- 某电商初创公司现在希望使用"客服智能体"来代替真人客服实现降本增效,它需要具备以下功能:
a. 理解用户的退款申请理由
b. 查询用户的订单信息和物流状态
c. 根据公司政策智能地判断是否应该批准退款
d. 生成一封得体的回复邮件并发送至用户邮箱
e. 如果判断决策存在一定争议(自我置信度低于阈值),能够进行自我反思并给出更审慎的建议
此时作为该产品的负责人:
- 你会选择本章的哪种范式(或哪些范式的组合)作为系统的核心架构?
- 这个系统需要哪些工具?请列出至少3个工具及其功能描述。
- 如何设计提示词来确保智能体的决策既符合公司利益,又能保持对用户的友好态度?
- 这个产品上线后可能面临哪些风险和挑战?如何通过技术手段来降低这些风险?