前言
在之前的系列中,笔者已经系统梳理了 LangChain 1.0 的核心知识点,并通过一个 多模态 RAG 项目 带领大家实践了 LangChain 1.0 的关键技术。从本篇开始,笔者将为大家进一步分享 LangGraph 1.0 的相关知识。与 LangChain 1.0 相比,LangGraph 1.0 的整体架构变动不大,但其定位发生了重要转变:在 1.0 版本之后,LangGraph 不再是 LangChain 的能力延伸,而是成为 LangChain 的能力底座。它通过灵活的状态管理、"点"与"边"的抽象、记忆机制以及"人在回路"的高效控制,特别适合构建精细化、可编排的工作流。
从本期开始笔者将逐步介绍 LangGraph 1.0 的这些核心特性,并最终使用 LangGraph 搭建一个 邮件自动回复工具流 。本期先从基础入手,讲解 LangGraph 1.0 的核心概念 ,重点解析 "点"与"边" 的设计与使用。
LangGraph1.0 与先前版本变动不大,预计花费三节左右的时间讲解,同时也要说明笔者的专栏《深入浅出LangChain&LangGraph AI Agent 智能体开发》适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 30 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
一、LangGraph 核心特性
LangGraph 是一个极其灵活的框架,其核心设计理念可以概括为:它是一种用于构建智能体的"编程语言" 。
如同任何编程语言都包含数据、函数、控制流等基本要素一样,LangGraph 也提供了功能对等的抽象组件,使开发者能够以声明式的方式编排智能体工作流。其核心特性的对应关系如下:
| 编程语言要素 | LangGraph 对应概念 | 说明 |
|---|---|---|
| 数据 (Data) | 状态 (State) | 工作流执行过程中传递和更新的信息载体。 |
| 函数 (Function) | 节点 (Node) | 对状态进行操作(如调用模型、执行工具)的基本单元。 |
| 控制逻辑 (Control Flow) | 边 (Edge) | 决定节点间执行顺序的逻辑,可以是条件分支 或静态路径,支持串行与并行。 |
| 存储 (Storage) | 检查点 / 记忆 (Checkpointing / Memory) | 状态的持久化机制,允许工作流暂停、恢复或具有长期记忆。 |
| 中断 (Interrupt) | 人在回路 (Human-in-the-Loop) | 通过中断控制流,在关键环节引入人工审核或干预的能力。 |
通过以上组件,LangGraph 使得构建一个具备复杂逻辑、可持续运行且支持人机协作的智能体系统变得直观且高效。
二、状态State和节点Node
2.1 状态State
LangGraph是一个状态图,状态可以理解为图的数据。在定义图之前首先应该定义一个状态作为初始值,在图的更新过程中状态值是可以被图更新并返回给用户的。
图本身是无状态的,在定义图时,首先要定义图将操作的状态。这个状态由图中的所有节点共享。状态通常是一个Python数据结构。定义状态的方式可以采用类型化字典。比如下面代码就定义了包含名为nList字符串列表的状态值。当图被调用时,状态会被初始化,LangGraph运行时会选择一个节点来执行,然后它会提供当前状态,运行节点,最后更新状态再到结束。
python
class State(TypedDict):
nlist: List[str]2.2 节点
在LangGraph中,节点的本质是一个函数。节点函数的输入参数是状态,输出则是对状态的更新。举例如下:
python
def node_a(state: State):
...
return ({"nlist":[note]})以上节点函数执行完成后会对字符串列表进行更新。State 可以被持久化(通过 Checkpointing 机制)。这意味着如果节点执行失败或工作流被中断,可以从上一个检查点恢复状态重新运行,保证了工作流的鲁棒性。
2.3 使用LangGraph构建简单图
下面笔者通过一个完整的代码示例,将 State 和 Node 的概念串联起来,构建一个最简单的单节点图。在开始之前,请大家确保已经安装了langgraph相关环境。如未安装,可以运行 pip install -U langgraph命令。
-
导入依赖库
pythonfrom langgraph.graph import START, END, StateGraph -
创建图表的第一步是定义一个State 类,类型是字典。它包含一个字符串类型的列表,状态可以是一个Python数据类也可以是一个Pydantic基类模型,关于pydantic的使用大家可以参考笔者的文章: 深入浅出LangGraph AI Agent智能体开发教程(六)---LangGraph 底层API入门, 也可查看pydantic官方文档, 这里不加赘述了。
pythonclass State(TypedDict): nList: List[str] -
定义节点,节点实际上就是Python函数,该函数接收状态,打印信息然后返回状态的更新。
pythondef node_a(state): print(f"noda_a接收到{state['nList']}") note = "Hello, 我是节点a" return(State(nList=[note])) -
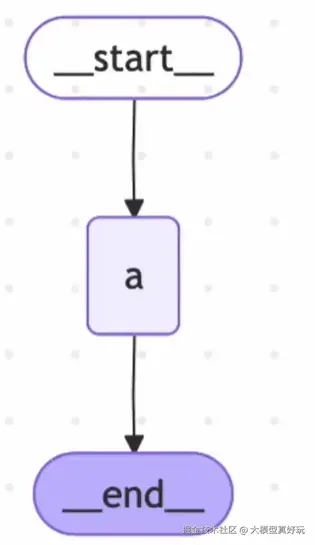
编译状态图,将节点加入到图中,定义为"a"节点,同时添加从START节点到"a"节点的边,然后添加从"a"到END的边。这里的START和END都是LangGraph定义的常量节点,仅包含语义信息。最后编译图
pythonbuilder = StateGraph(State) builder.add_node("a", node_a) builder.add_edge(START, "a") builder.add_edge("a", END) graph = builder.compile()以上代码构建了一个如下的简单图。
-
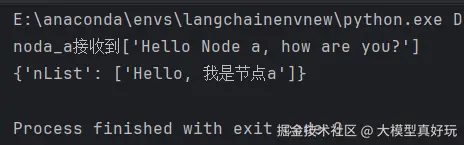
接下来测试这个图,首先使用State初始化一个状态变量,然后通过
.invoke方法运行图。可以看到节点A接收了初始状态,然后当调用图完成后返回了更新后的状态。pythoninitial_state = State( nList=["Hello Node a, how are you?"] ) print(graph.invoke(initial_state))
通过以上案例大家应该可以理解在定义图和状态时,图中所有节点可以共享相同的状态。
三、边
在定义了"数据"(State)和"操作"(Node)之后,笔者接下来介绍边 。边 (Edge) 是 LangGraph 中定义工作流执行逻辑的核心。它决定了节点之间的连接关系与执行顺序,是实现串行、并行、条件分支等复杂逻辑的关键。
3.1 普通边
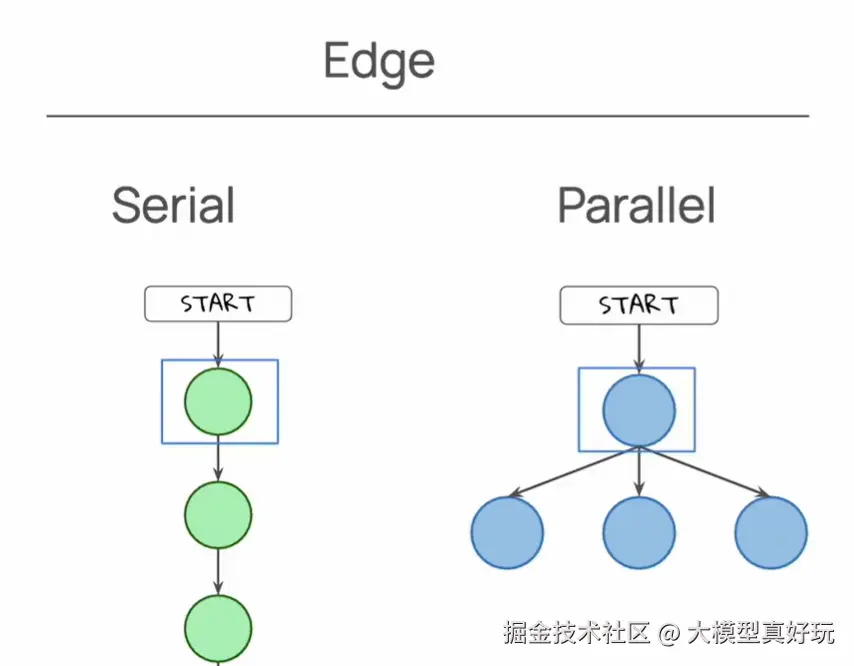
普通边(静态边) 用于连接两个节点,指定了确定无误的执行顺序。它是最简单的控制流,定义了工作流中"下一步该执行谁"。
- 串行执行 :通过连续的普通边连接多个节点,形成一个线性的执行链。例如:
START -> A -> B -> C -> END。 - 并行执行 :一个节点可以同时拥有多个出边(
outgoing edges),指向不同的后续节点。LangGraph 运行时会在当前节点完成后,同时触发所有这些后续节点的执行。
3.2 条件边
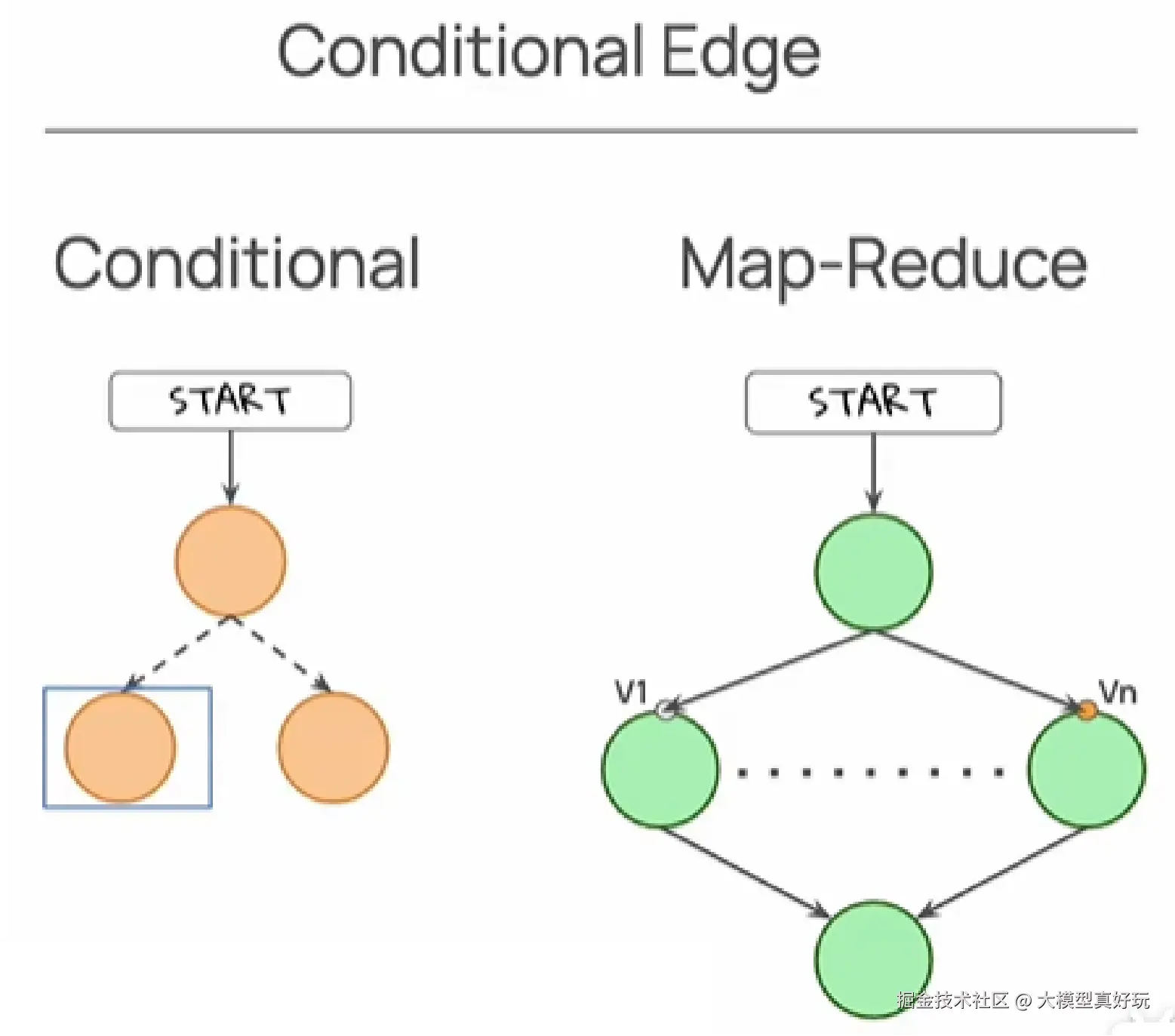
除普通边外,LangGraph还有另一种条件边。条件边允许工作流根据运行时状态动态决定 下一步的执行路径。它需要一个路由函数 ,该函数接收当前状态,并选择下一个要执行的节点。下图左侧根据条件选择将状态传递给下一级左侧节点进行处理。条件边还有一个特殊情况是MapReduce, 它可以创建可变数量的下游节点,并且每个节点都传递了一个唯一值(笔者之后也会讲到)。
3.3 Reducer详解
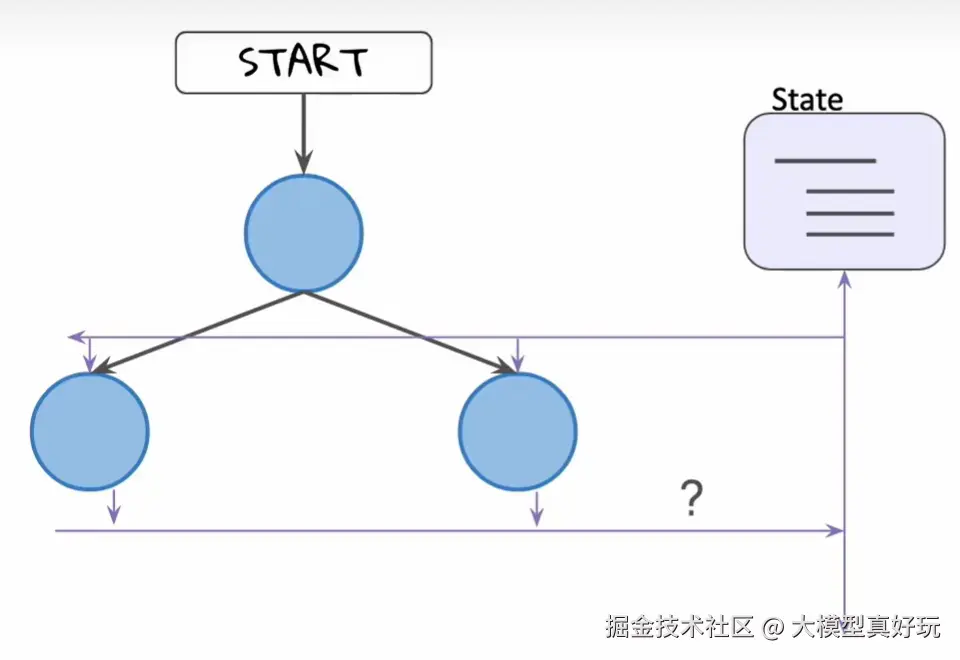
当一个节点拥有多个出边(即触发了并行执行)时,多个后续节点可能同时更新 State 中的同一个字段 。此时就会产生冲突:以谁的更新为准?默认情况下,节点的更新是覆盖式 的。如果节点B和节点C并行执行,都尝试更新state['messages'],后完成的节点会覆盖先完成节点的结果,导致数据丢失。
为了更精确的控制,这时就需要用到Reducer(归约器) 来解决解决此问题。它是一个合并函数 ,定义了当多个更新同时作用于同一个状态字段时,应如何合并这些更新。下面的状态定义中的operator.add就是一个Reducer,它指定了列表状态应该是合并而不是覆写
python
import operator
from typing import TypedDict, Annotated
class State(TypedDict):
nList: Annotated[list[str], operator.add]LangGraph 提供了一些开箱即用的 Reducer,下表列出了最常见的几种:
| Reducer 函数 | 导入来源 | 适用数据类型 | 主要行为 | 典型应用场景 |
|---|---|---|---|---|
operator.add |
operator (Python标准库) |
int, float |
数值累加 | 计数器、计分器 |
operator.extend |
operator (Python标准库) |
List[T] |
列表扩展 (list.extend) |
收集多项结果,如搜索条目 |
operator.or_ |
operator (Python标准库) |
Set[T] |
集合取并集,自动去重 | 收集标签、唯一ID集合 |
update_dict |
langgraph.utils |
Dict |
合并字典,新值覆盖旧键 | 更新配置或元数据 |
除了使用内置的Reducer外,开发者甚至可以自定义reducer进行处理。Reducer就是一个合并函数,该函数接收当前值和新传入值作为参数,并在函数中定义处理逻辑。以下是一个自定义Reducer的代码示例:该函数合并新值和旧值并返回去重后结果。
python
from typing import TypedDict, List, Annotated
from langgraph.graph import START, END, StateGraph
def deduplicate_merge(old_list: List[str], new_list: List[str]) -> List[str]:
"""自定义Reducer:合并列表并去重"""
combined = old_list + new_list
return list(dict.fromkeys(combined)) # 保持顺序的去重
class MyState(TypedDict):
unique_items: Annotated[List[str], deduplicate_merge]
from typing import TypedDict, List, Annotated
class State(TypedDict):
unique_items: Annotated[List[str], deduplicate_merge]
def node_a(state: State) -> State:
print(f"Adding 'A' to {state['unique_items']}")
return State(unique_items=["A"])
def node_A_extra(state: State) -> State:
print(f"Adding 'A' to {state['unique_items']}")
return State(unique_items=["A"])
builder = StateGraph(State)
builder.add_node("a", node_a)
builder.add_node("a_extra", node_A_extra)
builder.add_edge(START, "a")
builder.add_edge("a", "a_extra")
builder.add_edge("a_extra", END)
graph = builder.compile()
initial_state = State(
unique_items = ['Initial String']
)
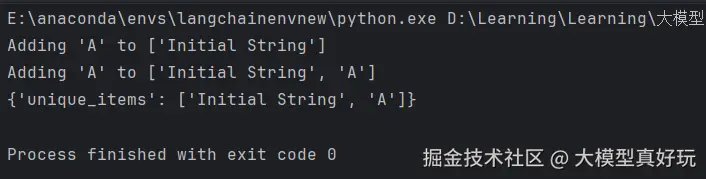
print(graph.invoke(initial_state))上面代码的图结构如下所示,按理说列表中应该有两个"A",但是因为添加时会去重,所以最后列表中只有这一个"A"了。

最后的结果如下:
3.4 探索LangGraph边的并行与数据共享
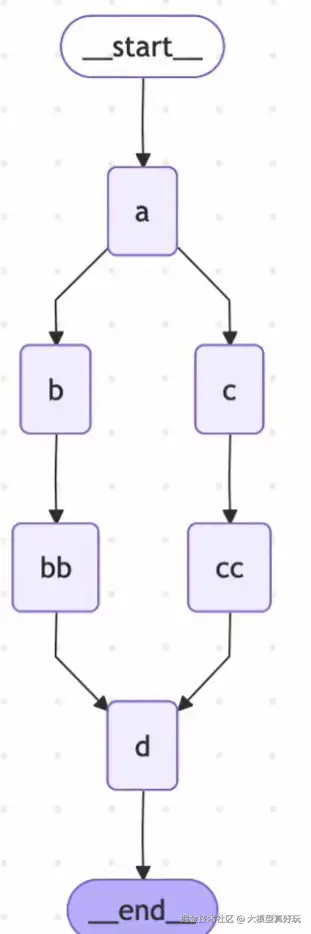
笔者接下来将构建下图所示的工作流,来帮助大家直观理解并行执行 与全局状态共享。
-
第一步同样的需要定义状态,不同的是这里的状态需要用reducer来指明列表的状态是累加而不是覆盖原来的值
pythonimport operator from typing import TypedDict, List, Annotated class State(TypedDict): nList: Annotated[List[str], operator.add] -
下一步来定义节点函数,每个节点都接收状态,并返回对
nList字段的更新pythondef node_a(state: State) -> State: print(f"Adding 'A' to {state['nList']}") return State(nList=["A"]) def node_b(state: State) -> State: print(f"Adding 'B' to {state['nList']}") return State(nList=["B"]) def node_c(state: State) -> State: print(f"Adding 'C' to {state['nList']}") return State(nList=["C"]) def node_bb(state: State) -> State: print(f"Adding 'BB' to {state['nList']}") return State(nList=["BB"]) def node_cc(state: State) -> State: print(f"Adding 'CC' to {state['nList']}") return State(nList=["CC"]) def node_d(state: State) -> State: print(f"Adding 'D' to {state['nList']}") return State(nList=["D"]) -
用状态实例化StateGraph,然后添加定义好的节点并按照参考图中的边将不同的节点连接起来,最后编译图。
pythonbuilder = StateGraph(State) builder.add_node("a", node_a) builder.add_node("b", node_b) builder.add_node("c", node_c) builder.add_node("bb", node_bb) builder.add_node("cc", node_cc) builder.add_node("d", node_d) builder.add_edge(START, "a") builder.add_edge("a", "b") builder.add_edge("a", "c") builder.add_edge("b", "bb") builder.add_edge("c", "cc") builder.add_edge("bb", "d") builder.add_edge("cc", "d") builder.add_edge("d", END) graph = builder.compile() -
提供一个初始状态来调用图表,大家先来思考一下最后的运行结果。
pythoninitial_state = State( nList = ['Initial String'] ) print(graph.invoke(initial_state))

- 并行与合并 :节点B和C在同一步骤 中并行执行,它们都接收到了来自节点A更新后的状态
['Initial', 'A']。它们的更新("B"和"C")通过Reducer被追加 到了nList中。 - 全局状态共享 :节点BB和CC运行时,它能"看到"的状态包含了其上游节点B的更新
('B'),也包含了并行分支节点C的更新`('C') 。这是因为LangGraph的状态是全局共享的,边只控制执行顺序,不隔离数据。
3.5 条件边
对于条件边笔者这里直接通过代码讲解,使用条件边实现下图结构,下图中的虚线表示条件边,实线表示普通边。

-
定义状态
pythonfrom langgraph.graph import START, END, StateGraph import operator from typing import TypedDict, List, Annotated class State(TypedDict): nList: Annotated[List[str], operator.add] -
定义节点函数
pythondef node_a(state: State): return def node_b(state: State): return State(nList=['B']) def node_c(state: State): return State(nList=['C']) -
定义图,首先添加实线普通边
pythonbuilder = StateGraph(State) builder.add_node("a", node_a) builder.add_node("b", node_b) builder.add_node("c", node_c) builder.add_edge(START, "a") builder.add_edge("b", END) builder.add_edge("c", END) graph = builder.compile() -
学习条件边的定义方法,条件边需要定义条件路由函数,该函数接受状态并返回一个值,这个值代表想要分支到的下一节点。笔者下面定义的函数接收图最近一次写入的状态,然后返回一个值。
pythondef conditional_edge(state: State) -> Literal['b', 'c', END]: select = state["nList"][-1] if select == "b": return 'b' elif select == 'c': return 'c' elif select == 'q': return END else: return END -
在构建图时使用添加条件边的语法来添加条件边,
pythonbuilder.add_conditional_edges("a", conditional_edge) -
测试条件边的逻辑。下面代码笔者从用户那里获取输入作为初始输入状态,然后用该状态调用图表:
pythonuser = input('b, c or q to quit:') input_state = State( nList=[user] ) graph.invoke(input_state)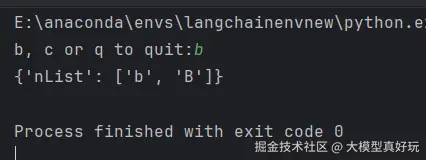
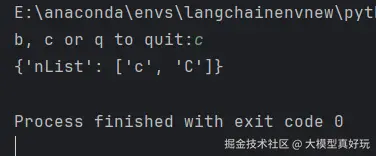
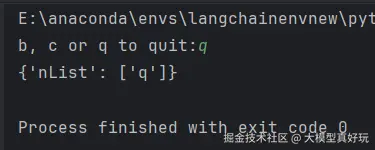
可以看到当用户输入b, 会走到b节点,在b节点中添加字符串'B', 当用户输入c, 会走到c节点,在c节点中添加字符串'C',输入q 则会直接到结束节点,这就是条件边的控制逻辑。完整代码大家可以关注笔者的同名微信公众号 大模型真好玩 ,并私信: LangChain智能体开发免费获取。
以上就是今天的全部内容啦!内容篇幅较长,大家消化一下~
四、总结
本期分享笔者为大家介绍了LangGraph 1.0,LangGraph1.0是构建智能体的编程语言。它通过状态(State) 管理数据,节点(Node) 作为处理函数,边(Edge) 定义串行、并行或条件执行逻辑。借助Reducer 处理并行写入冲突,并支持人在回路控制。这使其成为搭建复杂、可编排AI工作流的强大底座。本期分享着重介绍了LangGraph的节点和边的定义,并用点和边构造了简单的图。然而LangGraph不仅仅有如上所示的图的定义方法,在下期分享笔者将为大家介绍更多点和边的构建方法,以及介绍记忆Memory和人在回路Human In the loop,大家敬请期待~
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前已更新30讲,正在更新LangGraph1.0速通指南,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。