JPA 学习笔记 8:与数据库交互
Hibernate 使用EntityManager或Session实例与数据库交互,实际上EntityManager就是一个Session,可以通过以下方式进行转换:
java
Session session = entityManager.unwrap(Session.class);持久化上下文
持久化上下文(Persistence Context)是一种缓存;我们有时称其为"一级缓存",以区别于二级缓存。在持久化上下文的作用范围内,对于从数据库中读取的每个实体实例,以及对于在持久化上下文的作用范围内创建的每个新实体,上下文都持有从实体实例的标识符到实例本身的唯一映射。
一个实体实例相对于给定的持久化上下文可能处于三种状态之一:
- 瞬时状态(transient):没有与持久化上下文关联
- 持久状态(persistent):目前与持久化上下文相关联
- 分离态(detached):之前在另一个会话中持久化,但目前不与持久化上下文关联
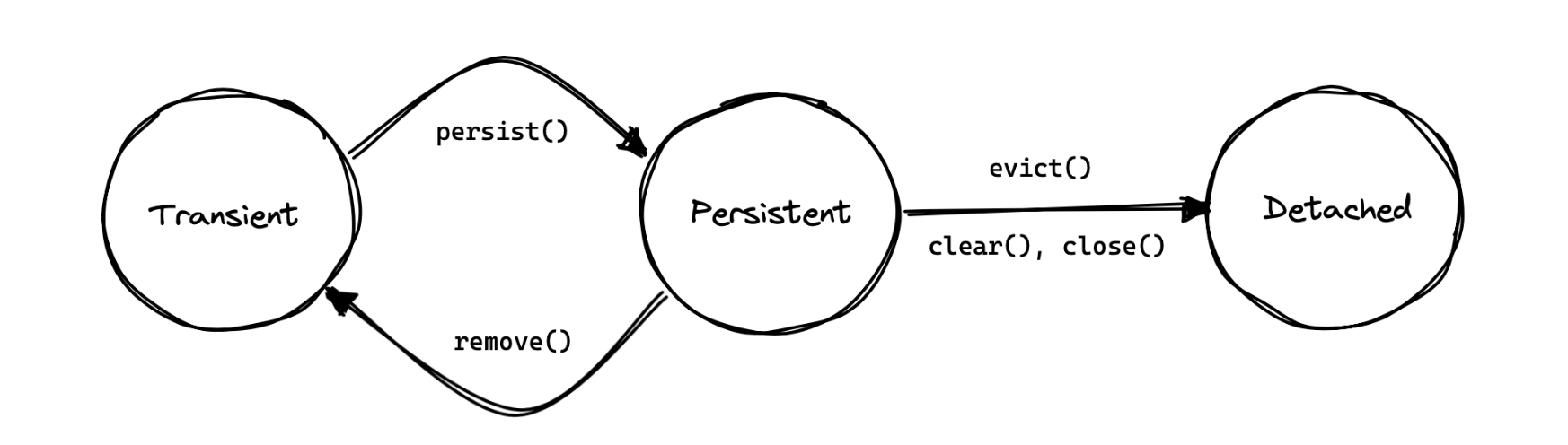
在任何时刻,一个实例最多只能与一个持久化上下文关联。
持久化上下文的生命周期通常与事务的生命周期相对应,尽管也可以存在跨越多个数据库级事务的持久化上下文,这些事务共同构成一个单一的逻辑工作单元。
- 一个持久化上下文------也就是说,一个
Session或EntityManager------绝对绝对不能在多个线程之间或并发事务之间共享。- 在容器环境中,作用域为事务的持久化上下文的生命周期通常会被自动管理。
使用持久化上下文的好处:
- 有助于避免数据别名:如果我们在一个代码段中修改了一个实体,那么在同一持久化上下文中执行的其它代码将看到我们的修改。
- 支持自动脏检查:在修改实体后,我们无需执行任何显式操作来要求 Hibernate 将此更改传播回数据库。相反,当会话刷新时,更改将自动与数据库同步。
- 可以通过避免在给定的工作单元中反复请求特定实体实例时访问数据库来提高性能。
- 能够透明地将多个数据库操作批量处理。
持久化上下文通常是有状态的,而有状态会话会带来一些非常重要的限制:
- 持久化上下文不是线程安全的,不能跨线程共享
- 一个持久化上下文不能跨无关的事务复用,因为那样会破坏事务的隔离性和原子性。
此外,持久化上下文对所有实体持有硬引用,阻止它们被垃圾回收。因此,一旦一个工作单元完成,会话就必须被丢弃。
创建会话
可以手动创建和关闭会话:
java
@SpringBootTest
public class EntityManagerTests {
@Autowired
private EntityManagerFactory entityManagerFactory;
private EntityManager entityManager;
@BeforeEach
public void beforeEach(){
System.out.println("beforeEach");
entityManager = entityManagerFactory.createEntityManager();
}
@AfterEach
public void afterEach(){
System.out.println("afterEach");
entityManager.close();
}
@Test
public void test(){
System.out.println(entityManager);
}
}如果是Session,可以使用:
java
session = sessionFactory.openSession();
session.close();
EntityManager是 JPA 的类,Session是 Hibernate 的类。
管理事务
通常,如果需要使用事务,总是需要在成功后提交事务,失败后回滚事务,代码如下:
java
Session openedSession = sessionFactory.openSession();
Transaction transaction = openedSession.beginTransaction();
try{
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
openedSession.persist(car);
transaction.commit();
}
catch (Exception e){
transaction.rollback();
}
finally{
openedSession.close();
}Hibernate 提供更简洁的 API 完成以上工作:
java
sessionFactory.inTransaction(session -> {
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
session.persist(car);
});如果需要完成事务后返回结果,可以:
java
Car2 toyota = sessionFactory.fromTransaction(session -> {
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
session.persist(car);
return car;
});
System.out.println(toyota);EntityManagerFactory也提供类似的 API:
java
entityManagerFactory.runInTransaction(entityManager -> {
// do the work
...
});不过只在较高版本的 JPA 中存在。
EntityTransaction 接口提供了一种标准的方式来设置事务超时:
java
entityManager.getTransaction().setTimeout(30); // 30 secondsEntityTransaction 还提供了一种将事务设置为只回滚模式的方法:
java
entityManager.getTransaction().setRollbackOnly();处于只回滚模式的事务在完成时会回滚。
对持久化上下文的操作
| 方法名和参数 | 效果 |
|---|---|
| persist(Object) | 将一个临时对象变为持久化对象,并为稍后执行安排一个 SQL insert 语句 |
| remove(Object) | 将持久化对象变为临时对象,并为 SQL delete 语句安排稍后执行 |
| merge(Object) | 将给定分离对象的状态复制到相应的受管持久化实例并返回持久化对象 |
| detach(Object) | 将持久化对象与会话分离而不影响数据库 |
| clear() | 清空持久化上下文并分离所有实体 |
| flush() | 检测持久化对象与会话的关联变化,并通过执行 SQL insert 、 update 和 delete 语句来同步数据库状态与会话状态 |
注意, persist() 和 remove() 对数据库没有立即影响,而是简单地安排一个稍后执行的命令。同时请注意,对于有状态会话没有 update() 操作。当会话刷新时,修改会自动检测。
另一方面,除了 getReference() ,以下操作都会立即访问数据库:
| 方法名和参数 | 效果 |
|---|---|
| find(Class,Object) | 获取给定类型和 ID 的持久化对象 |
| find(Class,Object,LockModeType) | 获取给定类型和 ID 的持久化对象,并请求指定的乐观锁或悲观锁模式 |
| find(EntityGraph,Object) | 获取给定 ID 和 EntityGraph 指定其类型和应被急加载的关联的持久化对象 |
| getReference(Class,id) | 获取给定类型和 ID 的持久化对象的引用,而实际上并不从数据库加载其状态 |
| getReference(Object) | 获取与给定分离实例具有相同身份的持久化对象的引用,而无需实际从数据库加载其状态 |
| refresh(Object) | 使用新的 SQL select 通过数据库获取对象当前状态,刷新其持久化状态 |
| refresh(Object,LockModeType) | 使用新的 SQL select 通过数据库获取对象当前状态,刷新其持久化状态,并请求给定的乐观或悲观锁模式 |
| lock(Object,LockModeType) | 对持久化对象获取乐观锁或悲观锁 |
这些操作中的任何一种都可能抛出异常。现在,如果在与数据库交互时发生异常,就没有好的方法来使当前持久化上下文的状态与数据库表中持有的状态重新同步。
因此,当会话的任何方法抛出异常时,会话被认为不可用。
级联持久化操作
级联是一种便利功能,它允许我们将持久化上下文操作列表中的一项操作从父级传播到其子级。要设置级联,我们指定某个关联映射注解的 cascade 成员,通常是 @OneToMany 或 @OneToOne 。
java
public class Order2 {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(
mappedBy = "order",
cascade = {CascadeType.PERSIST, CascadeType.REMOVE, CascadeType.REFRESH},
orphanRemoval = true
)
private List<OrderItem2> orderItems;
// ...
}这里的orphanRemoval,可以让对象从集合中被删除时,同时从数据库中删除。比如:
java
OrderItem2 orderItem1 = new OrderItem2("Toyota", new BigDecimal("100"), 1d);
OrderItem2 orderItem2 = new OrderItem2("Honda", new BigDecimal("200"), 2d);
OrderItem2 orderItem3 = new OrderItem2("BMW", new BigDecimal("300"), 3d);
Order2 order = new Order2();
order.addOrderItem(orderItem1);
order.addOrderItem(orderItem2);
order.addOrderItem(orderItem3);
session.persist(order);
Optional<OrderItem2> bmw = order.getOrderItems().stream()
.filter(orderItem -> orderItem.getName().equals("BMW"))
.findFirst();
if (bmw.isPresent()){
order.getOrderItems().remove(bmw.get());
}这里会先插入三条order_item数据,再删除一条。
代理和懒加载
因为实体和实体之间是可能存在关联关系的,此时查询出的结果可能存在互相关联,有时候我们并不需要这些关联实体的查询结果,此时这些多余查询都是性能损耗。
Hibernate 提供懒加载的方式用于这种情况,此时查询出的关联实体实例实际上是代理对象,而非真正的实体实例。
比如这里书籍和出版社之间的多对多关系:
java
public class Book10 {
// ...
@ManyToMany(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinTable(name = "book_publisher10",
joinColumns = @JoinColumn(name = "book_id"),
inverseJoinColumns = @JoinColumn(name = "publisher_id"))
private List<Publisher10> publishers;
// ...
}
java
public class Publisher10 {
// ...
@ManyToMany(mappedBy = "publishers", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
List<Book10> books;
// ...
}通过懒加载查询:
java
Publisher10 publisher = session.get(Publisher10.class, 1L);
boolean initialized = Hibernate.isInitialized(publisher.getBooks());
Assertions.assertFalse(initialized);Hibernate.isInitialized可以用于判断查询的结果是从数据库中读取了真实对象抑或是一个代理对象。
可以通过Hibernate.initialize强制从数据库读取数据:
java
Hibernate.initialize(publisher.getBooks());可以通过ession.getReference获取一个代理对象,这在某些时候很有用:
java
Publisher10 publisher = session.get(Publisher10.class, 1L);
Book10 book1 = session.getReference(Book10.class, 1L);
Book10 book2 = session.getReference(Book10.class, 2L);
boolean contains1 = Hibernate.contains(publisher.getBooks(), book1);
boolean contains2 = Hibernate.contains(publisher.getBooks(), book2);
System.out.println(contains1);
System.out.println(contains2);在上面这个例子中,虽然publisher的books属性中是代理对象,但依然可以用Hibernate.contains方法判断出版社是否关联了某本书。这样做可以减少可能的数据库查询。
实体图和立即加载
虽然懒加载在某些时候很有用,但如果我们需要获取关联关系的查询结果,就可能导致多余的查询(1+N 问题):
java
sessionFactory.inTransaction(session -> {
Publisher10 publisher = session.get(Publisher10.class, 1L);
publisher.getBooks().forEach(System.out::println);
});这里出版社关联了两本书,实际执行时 Hibernate 用了两条 SELECT 语句。
这里 Hibernate 已经做了优化,真正的 1+N 这里会使用三条 SELECT 语句。
可以通过实体图(Entity Graph)让 Hibernate 在查询时立即加载实体图中指定的关联实体,即使对应的关联关系是懒加载模式。
java
sessionFactory.inTransaction(session -> {
RootGraph<Publisher10> entityGraph = session.createEntityGraph(Publisher10.class);
entityGraph.addSubgraph("books");
Publisher10 publisher = session.byId(Publisher10.class).withFetchGraph(entityGraph).load(1L);
publisher.getBooks().forEach(System.out::println);
});这里使用session.createEntityGraph创建了实体图,并在实体图中指定了需要关联查询出的关联关系属性。之后的查询使用了实体图,所以 Hibernate 在执行时使用了两个左连接用一条 SELECT 语句查询出了结果。
这里的实体图查询 API (
session.byId(...).withFetchGraph)是 Hibernate 6 中的,Hibernate 7 的 API 有很大差异)。
刷新会话
有时会触发刷新操作,会话将内存中持有的脏状态------即与持久化上下文相关联的实体的状态修改------与数据库中持有的持久化状态同步。当然,它通过执行 SQL INSERT 、 UPDATE 和 DELETE 语句来完成这一操作。
默认情况下,以下事件发生时会触发刷新:
- 当前事务提交时,例如,当
Transaction.commit()被调用时 - 在执行一个查询之前,该查询的结果会受到内存中脏状态的同步影响
- 当程序直接调用
flush()时
比如:
java
Session openedSession = sessionFactory.openSession();
Transaction transaction = openedSession.beginTransaction();
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
// 添加实体
openedSession.persist(car);
// 这里的查询与添加的实体无关,不会触发刷新
List<?> books = openedSession.createSelectionQuery("from Book10")
.getResultList();
// 事务提交时触发刷新
transaction.commit();在上面的示例中,实体对象的添加与之后的查询无关,不会影响查询结果,因此查询不会触发会话刷新。
java
Session openedSession = sessionFactory.openSession();
Transaction transaction = openedSession.beginTransaction();
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
// 添加实体
openedSession.persist(car);
// 这里的查询与添加的实体有关,触发刷新
List<?> cars = openedSession.createSelectionQuery("from Car2")
.getResultList();
// 事务提交时没有改变,不再触发刷新
transaction.commit();在这个例子中,实体对象的添加与之后的查询是有关的,因此查询时会触发会话刷新,会将刚添加的持久对象写入数据库,以保证之后的查询结果正确。
在任何时候都可以手动刷新会话:
java
Session openedSession = sessionFactory.openSession();
Transaction transaction = openedSession.beginTransaction();
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("icexmoon@qq.com");
// 添加实体
openedSession.persist(car);
// 这里手动刷新会话
openedSession.flush();
// 这里的查询与添加的实体有关,但不再触发会话刷新(已经刷新过了)
List<?> cars = openedSession.createSelectionQuery("from Car2")
.getResultList();
// 事务提交时没有改变,不再触发刷新
transaction.commit();由于刷新操作相对昂贵(会话必须检查持久化上下文中的每个实体是否已更改),将刷新模式设置为 COMMIT 偶尔可能是一种有用的优化。但要注意------在这种模式下,查询可能会返回过时的数据:
java
Session openedSession = sessionFactory.openSession();
openedSession.setFlushMode(FlushModeType.COMMIT);
Transaction transaction = openedSession.beginTransaction();
Car2 car = new Car2();
car.setBrand("BWM");
car.setOwner("Jack Chen");
openedSession.persist(car);
// 这里没有刷新会话,会返回脏数据
List<?> cars = openedSession.createSelectionQuery("from Car2")
.getResultList();
System.out.println(cars);
transaction.commit();
openedSession.close();实际测试这里返回的数据会包含刚添加的实体对象,并非过时数据,有可能是容器的影响。
有这几种刷新模式:
Hibernate FlushMode |
JPA FlushModeType |
解释 |
|---|---|---|
| MANUAL | 从不自动刷新 | |
| COMMIT | COMMIT | 在事务提交前刷新 |
| AUTO | AUTO | 在事务提交之前以及执行可能受内存中修改影响的查询之前进行刷新 |
| ALWAYS | 在事务提交之前以及执行每个查询之前进行刷新 |
查询
Hibernate 提供了三种互补的编写查询方式:
- Hibernate 查询语言(HQL),JPQL 的一个极其强大的超集,抽象了现代 SQL 方言的大部分特性
- JPA 标准查询 API,以及扩展,允许通过类型安全的 API 以编程方式构建几乎任何 HQL 查询
- 原生 SQL 查询
HQL
构建 SELECT 的 HQL 查询语句:
java
List<Car2> cars = session.createSelectionQuery("from Car2 where brand like :brand", Car2.class)
.setParameter("brand", "Toyota")
.getResultList();
System.out.println(cars);用 JPA 的方式构建:
java
List<Car2> cars = entityManager.createQuery("from Car2 where brand like :brand", Car2.class)
.setParameter("brand", "Toyota")
.getResultList();
System.out.println(cars);createSelectionQuery() 和 createQuery() 之间的唯一区别在于, createSelectionQuery() 如果传入 insert 、 delete 或 update ,则会抛出异常。
HQL 中的:xxx是命名参数,也可以使用数字标识符组成的位置参数:
java
List<Car2> cars = session.createSelectionQuery("from Car2 where brand like ?1", Car2.class)
.setParameter(1, "Toyota")
.getResultList();
System.out.println(cars);如果查询结果是单个对象,可以:
java
Book10 book = session.createSelectionQuery("from Book10 where isbn=:isbn", Book10.class)
.setParameter("isbn", "1234567891")
.getSingleResult();需要注意的是,当查询不到结果时,.getSingleResult()会产生一个异常。因此更常用的是:
java
Book10 book = session.createSelectionQuery("from Book10 where isbn=?1", Book10.class)
.setParameter(1, "12345678911")
.getSingleResultOrNull();在通过 API 构建 HQL 进行查询时,同样可以指定会话的刷新模式:
java
Book10 book = session.createSelectionQuery("from Book10 where isbn=?1", Book10.class)
.setParameter(1, "12345678911")
.setHibernateFlushMode(FlushMode.COMMIT)
.getSingleResultOrNull();条件查询
除了直接编写完整的 HQL 查询语句进行查询,还可以通过 API 构建 HQL 查询语句:
java
CarSearchDTO dto = new CarSearchDTO();
dto.setBrand("WM");
dto.setOwner("Chen");
HibernateCriteriaBuilder criteriaBuilder = session.getCriteriaBuilder();
JpaCriteriaQuery<Car2> query = criteriaBuilder.createQuery(Car2.class);
JpaRoot<Car2> car = query.from(Car2.class);
JpaPredicate where = criteriaBuilder.conjunction();
if (dto.getBrand() != null){
where = criteriaBuilder.and(where, criteriaBuilder.like(car.get("brand"), "%" + dto.getBrand() + "%"));
}
if (dto.getOwner() != null){
where = criteriaBuilder.and(where, criteriaBuilder.like(car.get("owner"), "%" + dto.getOwner() + "%"));
}
query.select(car).where(where).orderBy(criteriaBuilder.asc(car.get("id")));
List<Car2> cars = session.createSelectionQuery(query).getResultList();
System.out.println(cars);构建更新或删除的 HQL 与之类似:
java
CarSearchDTO dto = new CarSearchDTO();
dto.setBrand("WM");
dto.setOwner("Chen");
HibernateCriteriaBuilder criteriaBuilder = session.getCriteriaBuilder();
JpaCriteriaDelete<Car2> delete = criteriaBuilder.createCriteriaDelete(Car2.class);
JpaRoot<Car2> car = delete.from(Car2.class);
JpaPredicate where = criteriaBuilder.conjunction();
if (dto.getBrand() != null){
where = criteriaBuilder.and(where, criteriaBuilder.like(car.get("brand"), "%" + dto.getBrand() + "%"));
}
if (dto.getOwner() != null){
where = criteriaBuilder.and(where, criteriaBuilder.like(car.get("owner"), "%" + dto.getOwner() + "%"));
}
delete.where(where);
session.createMutationQuery(delete).executeUpdate();原生 SQL 查询
java
NativeQuery<Car2> query = session.createNativeQuery("select * from car2 where brand like :brand", Car2.class);
query.setParameter("brand", "%" + "T" + "%");
List<Car2> cars = query.getResultList();
System.out.println(cars);通常 Hibernate 都可以很好的将结果集映射到对象:
java
NativeQuery<String> query = session.createNativeQuery("select owner from car2 where brand like :brand", String.class);
query.setParameter("brand", "%" + "T" + "%");
List<String> owners = query.getResultList();
System.out.println(owners);默认情况下,在原生 SQL 查询执行时,可能不会触发会话刷新,因为 Hibernate 不知道哪些会话实体改变会影响本次查询结果:
java
session.setHibernateFlushMode(FlushMode.AUTO);
Car2 car = new Car2();
car.setBrand("Toyota");
car.setOwner("Chen");
session.persist(car);
List<Car2> cars = session.createNativeQuery("select * from car2", Car2.class)
.getResultList();
System.out.println(cars);实际测试中这里并不会获取到旧数据,应该是做了优化。
如果要避免原生查询获取到的是旧数据,可以通过以下方式在查询时强制刷新会话:
java
List<Car2> cars = session.createNativeQuery("select * from car2", Car2.class)
.setHibernateFlushMode(FlushMode.ALWAYS)
.getResultList();分页和排序
最简单的是直接在 HQL 语句中排序和分页:
java
List<Car2> cars = session.createSelectionQuery("from Car2 order by id asc limit 10 offset 0", Car2.class)
.getResultList();和 SQL 中常用的
limit 0,10语法略有不同,且必须出现在order by语句之后。
在查询 API 中指定分页参数:
java
List<Car2> cars = session.createSelectionQuery("from Car2", Car2.class)
.setFirstResult(0)
.setMaxResults(10)
.getResultList();另一种写法:
java
List<Car2> cars = session.createSelectionQuery("from Car2", Car2.class)
.setPage(Page.page(10, 0))
.getResultList();分页查询往往需要同时获取总页数:
java
SelectionQuery<Car2> query = session.createSelectionQuery("from Car2", Car2.class);
long resultCount = query.getResultCount();
final int PAGE_SIZE = 10;
List<Car2> cars = query
.setPage(Page.page(PAGE_SIZE, 0))
.getResultList();
System.out.println(cars);
// 总页数
long pageCount = (resultCount + PAGE_SIZE - 1) / PAGE_SIZE;
System.out.printf("查询结果有%d条,共%d页\n", resultCount, pageCount);同样可以通过查询 API 排序:
java
List<Car2> cars = session.createSelectionQuery("from Car2", Car2.class)
.setOrder(List.of(Order.asc(Car2.class,"brand"), Order.desc(Car2.class,"id")))
.setFirstResult(0)
.setMaxResults(10)
.getResultList();表示投影列表
对任意返回的结果集,我们都可以投影到Object[]类型:
java
List<Object[]> cars = session.createSelectionQuery("select brand,owner from Car2", Object[].class)
.getResultList();
for (Object[] car : cars) {
Object brand = car[0];
Object owner = car[1];
System.out.printf("brand:%s,owner:%s\n", brand, owner);
}但这样使用不是很方便,可以使用自定义record:
java
record CarDto(String brand, String owner) {
};
List<CarDto> cars = session.createSelectionQuery("select brand,owner from Car2", CarDto.class)
.setMaxResults(10)
.getResultList();
for (CarDto car : cars) {
String brand = car.brand();
String owner = car.owner();
System.out.printf("brand:%s,owner:%s\n", brand, owner);
}比起自定义类,record的好处是可以在局部代码片段进行声明。
命名查询
可以在实体类上添加一个命名查询:
java
@NamedQuery(name = "Car2.findByBrand", query = "from Car2 where brand like concat('%',:brand,'%')")
public class Car2 {
// ...
}这样做的好处是,在项目启动时,Hibernate 就会检查并加载这些查询语句,如果有语法错误就会立即报错。
执行命名查询:
java
List<Car2> cars = session.createNamedQuery("Car2.findByBrand", Car2.class)
.setParameter("brand", "T")
.getResultList();可以用同样的方式定义原生 SQL 组成的命名查询,不过需要使用@NamedNativeQuery注解。
Hibernate 不能检查原生 SQL 的命名查询是否有语法错误。
元模型生成器
Hibernate 提供一个编译时工具------元模型生成器,它是一个注解处理器,可以在编译时为实体类生成对应的元模型类,对我们简化代码或增加可能的类型检查提供便利。
要使用元模型生成器,需要为项目添加注解处理器,这里以 Maven 为例:
xml
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessorPaths>
<!-- ... -->
<path>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
<version>6.6.29.Final</version>
<!-- Optionally exclude transitive dependencies -->
<exclusions>
<exclusion>
<groupId>org.sample</groupId>
<artifactId>sample-dependency</artifactId>
</exclusion>
</exclusions>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>现在通过 Maven 编译项目,会生成元模型,比如对于实体类Car2,生成的元模型:
java
@StaticMetamodel(Car2.class)
public abstract class Car2_ {
public static final String OWNER = "owner";
public static final String QUERY_CAR2_FIND_BY_BRAND = "Car2.findByBrand";
public static final String ID = "id";
public static final String BRAND = "brand";
public static volatile SingularAttribute<Car2, String> owner;
public static volatile SingularAttribute<Car2, Long> id;
public static volatile EntityType<Car2> class_;
public static volatile SingularAttribute<Car2, String> brand;
public Car2_() {
}
}我们可以将元模型的属性用于原本使用字符串的部分,比如:
java
List<Car2> cars = session.createNamedQuery(Car2_.QUERY_CAR2_FIND_BY_BRAND, Car2.class)
.setParameter(Car2_.BRAND, "T")
.getResultList();这样做的好处是可以避免可能的字符串编写错误。
命名查询
此外,还可以简化命名查询,比如在实体类上添加一个命名查询:
java
@NamedQuery(name = "#findByOwner", query = "from Car2 where owner like concat('%',:owner,'%')")
public class Car2 {
// ...
}不同的是,这个命名查询的名称以#开头。
变化后的元模型中:
java
@StaticMetamodel(Car2.class)
public abstract class Car2_ {
// ...
public static List<Car2> findByOwner(@Nonnull EntityManager entityManager, Object owner) {
return entityManager.createNamedQuery("#findByOwner").setParameter("owner", owner).getResultList();
}
}现在只要调用这个静态方法即可:
java
List<Car2> cars = Car2_.findByOwner(session, "Chen");生成查询方法
利用这种方式生成查询是有限制的,因为我们不能指定返回类型。如果要完全定义查询的签名,可以:
java
public interface CarQuery2 {
@HQL("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')")
List<Car2> findByBrandAndOwner(String brand, String owner);
}编译后生成的元模型:
java
@StaticMetamodel(CarQuery2.class)
public abstract class CarQuery2_ {
// ...
public static List<Car2> findByBrandAndOwner(@Nonnull EntityManager entityManager, String brand, String owner) {
return entityManager.createQuery("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')", Car2.class).setParameter("brand", brand).setParameter("owner", owner).getResultList();
}
}通过元模型方法执行查询:
java
List<Car2> cars = CarQuery2_.findByBrandAndOwner(session, "T", "Chen");元模型会自动为查询方法添加一个EntityManager类型的参数,用于执行查询时的会话实例。如果有需要,我们可以显式地指定会话实例的类型,比如:
java
@HQL("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')")
List<Car2> findByBrandAndOwner2(Session session, String brand, String owner);生成的元模型方法:
java
public static List<Car2> findByBrandAndOwner2(@Nonnull Session session, String brand, String owner) {
return session.createSelectionQuery("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')", Car2.class).setParameter("brand", brand).setParameter("owner", owner).getResultList();
}除了EntityManager和Session,还可以使用StatelessSession或Mutiny.Session。
如果需要用类似的方式定义原生 SQL 组成的查询,需要使用@SQL注解代替@HQL。
实例查询方法
上面的查询方法是静态方法,有时候可能在实例中定义查询方法会带来更多使用上的便捷性。
java
public interface CarQuery3 {
Session session();
@HQL("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')")
List<Car2> findByBrandAndOwner(String brand, String owner);
@HQL("from Car2 where brand like concat('%',:brand,'%')")
List<Car2> findByBrand(String brand);
@HQL("from Car2 where owner like concat('%',:owner,'%')")
List<Car2> findByOwner(String owner);
}需要在接口中定义一个返回会话实例的方法,此外,用于查询的方法签名中不能包含会话实例作为形参。
执行查询:
java
CarQuery3_ query = new CarQuery3_(session);
List<Car2> cars = query.findByBrandAndOwner( "T", "Chen");如果有需要,可以用手写的查询实现替代元模型生成器自动生成的结果:
java
public interface CarQuery3 {
Session session();
default List<Car2> findByBrandAndOwner(String brand, String owner){
Session session = session();
return session.createSelectionQuery("from Car2 where brand like concat('%',:brand,'%') and owner like concat('%',:owner,'%')", Car2.class)
.setParameter("brand", brand)
.setParameter("owner", owner)
.getResultList();
}
// ...
}find
使用@Find注解可以在不编写 HQL 的情况下生成查询方法:
java
public interface CarQuery4 {
Session session();
@Find
List<Car2> findByBrandAndOwner(String brand, String owner);
}与 JPA 的仓库中的方法不同,这里的方法名称不会有任何用途,可以是任何内容,仅仅由方法签名决定 HQL 的生成,因此方法签名中的参数类型和参数名称要与实体属性完全匹配。
生成的查询方法:
java
public List<Car2> findByBrandAndOwner(String brand, String owner) {
HibernateCriteriaBuilder _builder = this.session.getFactory().getCriteriaBuilder();
JpaCriteriaQuery<Car2> _query = _builder.createQuery(Car2.class);
JpaRoot<Car2> _entity = _query.from(Car2.class);
_query.where(new Predicate[]{brand == null ? _entity.get(Car2_.brand).isNull() : _builder.equal(_entity.get(Car2_.brand), brand), owner == null ? _entity.get(Car2_.owner).isNull() : _builder.equal(_entity.get(Car2_.owner), owner)});
return this.session.createSelectionQuery(_query).getResultList();
}这里使用的是_builder.equal,因此生成的 HQL 语句中使用的是=比较查询条件,如果需要使用like进行比较,可以为方法参数添加一个@Pattern注解:
java
@Find
List<Car2> findByBrand(@Pattern String brand);分页和排序
可以将分页排序的相关参数添加到查询方法中,Hibernate 可以正常使用这些参数。
java
@HQL("from Car2 where brand like concat('%',:brand,'%')")
List<Car2> findByBrand(String brand, Page page, Order<? super Car2> order);调用:
java
CarQuery5_ query = new CarQuery5_(session);
List<Car2> cars = query.findByBrand( "o", Page.page(10, 0), Order.asc(Car2_.brand));返回类型
如果返回值只有一个:
java
@Find
Book10 getBookByIsbn(String isbn);如果返回的是部分字段,难以投影到指定实体类,可以:
java
@HQL("select name,isbn from Book10 where name like concat('%',:name,'%')")
List<Object[]> findByName(String name);更好的方式是投影到record:
java
record BookDTO(String name, String isbn) {
}
@HQL("select name,isbn from Book10 where name like concat('%',:name,'%')")
List<BookDTO> findByName2(String name);本文的完整示例可以从这里获取。