| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之RunnablePassthrough |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
31、零基础学AI大模型之Milvus索引实战
32、零基础学AI大模型之Milvus DML实战
33、零基础学AI大模型之Milvus向量Search查询综合案例实战
33、零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
34、零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
35、零基础学AI大模型之LangChain整合Milvus:新增与删除数据实战
36、零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析
37、零基础学AI大模型之LangChain Retriever
38、零基础学AI大模型之MultiQueryRetriever多查询检索全解析
39、零基础学AI大模型之LangChain核心:Runnable接口底层实现
40、零基础学AI大模型之RunnablePassthrough
本文章目录
- 零基础学AI大模型之RunnableParallel
-
- 一、RunnableParallel:链中的"并行处理器"
- 二、基础用法:从显式定义到简化写法
-
- [1. 显式定义:用`RunnableParallel`类](#1. 显式定义:用
RunnableParallel类) - [2. 简化写法:直接用字典{}](#2. 简化写法:直接用字典{})
- [1. 显式定义:用`RunnableParallel`类](#1. 显式定义:用
- 三、核心应用场景:哪些地方需要并行链?
-
- [1. 多数据源并行检索](#1. 多数据源并行检索)
- [2. 多模型输出对比](#2. 多模型输出对比)
- [3. 多维度文档分析](#3. 多维度文档分析)
- 四、实战:基于本地模型的"LangChain学习资源并行推荐"
-
- [1. 实战目标](#1. 实战目标)
- [2. 完整代码](#2. 完整代码)
- 五、实战关键解析:并行链的效率优势
零基础学AI大模型之RunnableParallel
一、RunnableParallel:链中的"并行处理器"
核心定义:多任务并行,结果字典化
RunnableParallel是Runnable的子类,核心作用就一个:让多个子Runnable同时执行,最后将每个子任务的结果按"键-值"形式合并成字典返回。
它的类定义逻辑很清晰:
python
class RunnableParallel(Runnable[Input, Dict[str, Any]]):
"""
并行执行多个Runnable的容器类
输出结果:{子任务键1: 子任务1结果, 子任务键2: 子任务2结果, ...}
"""简单说,你给每个并行任务起个"名字"(键),指定对应的Runnable(值),它就会让这些任务一起跑,最后用字典把结果打包给你。
关键特性:为什么选并行链?
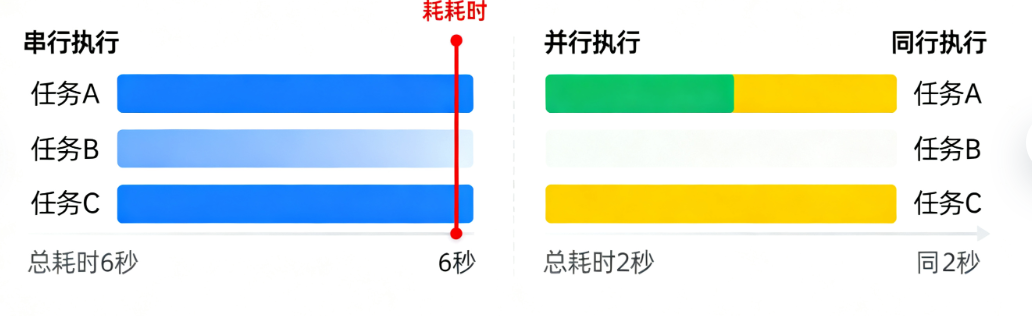
| 特性 | 说明 | 优势示例 |
|---|---|---|
| 并行执行 | 所有子Runnable同时启动,不互相等待 | 3个检索任务各耗时2秒,并行总耗时仅2秒(串行需6秒) |
| 自动结果合并 | 无需手动拼接结果,自动生成结构化字典 | 直接通过result["context1"]获取第一个检索结果 |
| 字典自动转换 | 写链时直接用字典{},LCEL会自动转为RunnableParallel | 简化代码,不用显式实例化RunnableParallel |
| 输入共享 | 所有子任务接收相同的原始输入 | 一个用户问题,同时传给多个Retriever或模型 |
二、基础用法:从显式定义到简化写法
1. 显式定义:用RunnableParallel类
适合需要明确声明"这是并行任务"的场景,结构清晰,易于维护。
python
from langchain_core.runnables import RunnableParallel
from langchain_openai import ChatOpenAI
# 初始化本地模型
local_model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.7
)
# 定义两个并行任务:分析问题情感 + 提取问题关键词
parallel_chain = RunnableParallel(
sentiment=local_model | "分析用户问题的情感倾向,返回正面/负面/中性",
keywords=local_model | "提取用户问题中的核心关键词,用逗号分隔"
)
# 执行:两个任务并行跑,结果合并成字典
result = parallel_chain.invoke("LangChain的RunnableParallel很好用!")
print("情感分析结果:", result["sentiment"].content)
print("关键词提取结果:", result["keywords"].content)2. 简化写法:直接用字典{}
LCEL有个便捷设计:当你在链中用字典传递多个Runnable时,会自动转换为RunnableParallel,代码更简洁。
上面的例子可以简化成这样,效果完全一致:
python
# 简化写法:字典自动转为RunnableParallel
parallel_chain = (
{
"sentiment": local_model | "分析用户问题的情感倾向,返回正面/负面/中性",
"keywords": local_model | "提取用户问题中的核心关键词,用逗号分隔"
}
)
# 执行逻辑不变
result = parallel_chain.invoke("LangChain的RunnableParallel很好用!")日常开发更推荐简化写法,能减少代码冗余。
三、核心应用场景:哪些地方需要并行链?
RunnableParallel不是"花架子",而是解决实际痛点的工具,这三个场景最常用:
1. 多数据源并行检索
同时从多个向量库/数据源拉取信息,快速整合上下文(比如同时查"博客文档"和"官方文档")。
python
# 假设你有两个Retriever:博客文档检索器、官方文档检索器
blog_retriever = ... # 你的博客文档Retriever
official_retriever = ... # LangChain官方文档Retriever
# 并行检索两个数据源
multi_retrieval_chain = (
{
"blog_context": blog_retriever, # 检索你的博客文档
"official_context": official_retriever, # 检索官方文档
"question": RunnablePassthrough() # 透传用户问题
}
| prompt | local_model # 后续用两个上下文生成答案
)2. 多模型输出对比
用本地模型和其他模型(或不同参数的本地模型)同时生成结果,对比效果(比如测试不同temperature的输出差异)。
python
# 初始化两个不同参数的本地模型
local_model_low_temp = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.2 # 低随机性,结果更稳定
)
local_model_high_temp = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.9 # 高随机性,结果更多样
)
# 并行对比两个模型输出
model_compare_chain = (
{
"stable_output": local_model_low_temp,
"diverse_output": local_model_high_temp
}
)
# 执行:同时得到两种风格的结果
result = model_compare_chain.invoke("总结RunnableParallel的核心用法")3. 多维度文档分析
对一篇文档同时做"摘要生成""目录提取""字符统计",一次性拿到多维度结果。
python
from langchain_core.runnables import RunnableLambda
# 并行处理文档:摘要+目录+统计
doc_analysis_chain = (
{
"summary": local_model | "生成文档的300字摘要",
"toc": local_model | "提取文档的三级目录,用列表呈现",
"stats": RunnableLambda(lambda doc: { # 自定义统计逻辑
"char_count": len(doc),
"line_count": doc.count("\n") + 1
})
}
)
# 执行:传入文档文本,并行得到三个维度结果
doc_text = "(你的博客文章内容)..."
result = doc_analysis_chain.invoke(doc_text)四、实战:基于本地模型的"LangChain学习资源并行推荐"
做一个实用场景:用户输入学习需求,并行生成"工具推荐"和"书籍推荐" ,快速整合学习资源。
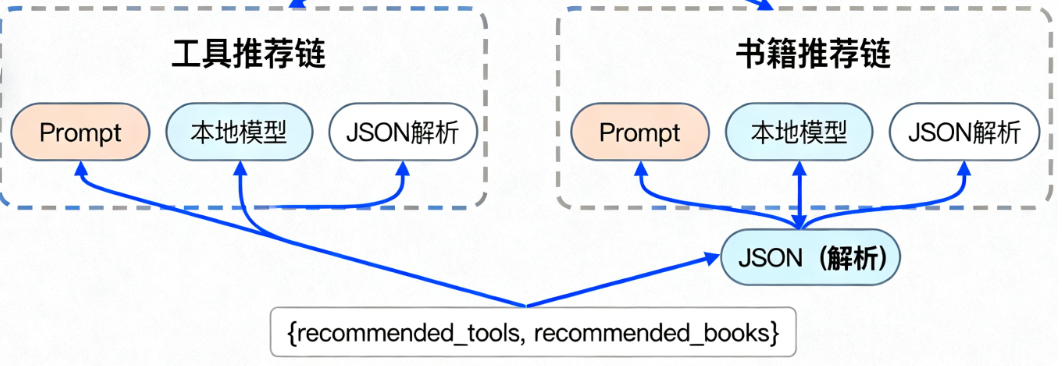
1. 实战目标
- 输入:用户的LangChain学习需求(如"零基础学LangChain并行链")。
- 并行任务1:推荐3个相关学习工具(如向量库、调试工具)。
- 并行任务2:推荐3本相关学习书籍(含简介)。
- 输出:合并两个任务的结果,用JSON格式返回(方便后续解析)。
2. 完整代码
步骤1:初始化组件(本地模型+Prompt+解析器)
python
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
# 1. 初始化本地模型
local_model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.7
)
# 2. 定义两个并行任务的Prompt(都用JSON输出,方便解析)
# Prompt1:推荐学习工具
tool_prompt = ChatPromptTemplate.from_template("""
根据用户需求{demand},推荐3个相关的LangChain学习工具。
返回JSON格式,键包括:tool_name(工具名)、usage(用途)、advantage(优势)。
示例格式:
[
{"tool_name": "xxx", "usage": "xxx", "advantage": "xxx"},
{"tool_name": "xxx", "usage": "xxx", "advantage": "xxx"}
]
""")
# Prompt2:推荐学习书籍
book_prompt = ChatPromptTemplate.from_template("""
根据用户需求{demand},推荐3本相关的AI大模型/LangChain书籍。
返回JSON格式,键包括:book_name(书名)、author(作者)、intro(简介)。
示例格式:
[
{"book_name": "xxx", "author": "xxx", "intro": "xxx"},
{"book_name": "xxx", "author": "xxx", "intro": "xxx"}
]
""")
# 3. 初始化JSON解析器
json_parser = JsonOutputParser()步骤2:构建并行推荐链
python
# 构建两个子链:Prompt→本地模型→JSON解析
tool_chain = tool_prompt | local_model | json_parser
book_chain = book_prompt | local_model | json_parser
# 构建并行链:合并两个子链结果
recommend_parallel_chain = (
RunnablePassthrough() # 透传用户需求给两个子链
| {
"recommended_tools": tool_chain, # 并行任务1:工具推荐
"recommended_books": book_chain # 并行任务2:书籍推荐
}
)步骤3:执行与结果展示
python
# 输入用户需求
user_demand = "零基础学LangChain的RunnableParallel并行链,需要实用工具和入门书籍"
# 执行并行链
result = recommend_parallel_chain.invoke({"demand": user_demand})
# 打印结果
print("=== 并行推荐结果 ===")
print("\n1. 推荐学习工具:")
for tool in result["recommended_tools"]:
print(f"- 工具名:{tool['tool_name']}")
print(f" 用途:{tool['usage']}")
print(f" 优势:{tool['advantage']}\n")
print("2. 推荐学习书籍:")
for book in result["recommended_books"]:
print(f"- 书名:{book['book_name']}")
print(f" 作者:{book['author']}")
print(f" 简介:{book['intro']}\n")预期输出(示例)
=== 并行推荐结果 ===
1. 推荐学习工具:
- 工具名:LangChain CLI
用途:命令行调试LangChain链,查看执行流程
优势:无需写代码,快速验证并行链逻辑
- 工具名:LangSmith
用途:监控LangChain链运行状态,查看并行任务耗时
优势:可视化并行任务进度,便于性能优化
- 工具名:Milvus
用途:向量数据库,配合并行链做多数据源检索
优势:支持高并发检索,适配本地模型场景
2. 推荐学习书籍:
- 书名:《LangChain实战:构建大模型应用》
作者:工藤学编程(示例)
简介:含Runnable系列组件实战,适合零基础入门
- 书名:《大模型开发指南:从API到本地部署》
作者:AI技术团队
简介:详细讲解本地模型配置与并行任务优化
- 书名:《向量数据库与RAG实战》
作者:数据工程师联盟
简介:含多数据源并行检索案例,适配LangChain生态五、实战关键解析:并行链的效率优势
这个案例中,RunnableParallel解决了两个核心问题:
- 节省时间:工具推荐和书籍推荐两个任务并行执行,总耗时≈单个任务耗时(假设单个任务3秒,并行总耗时≈3秒,串行则需6秒)。
- 结果结构化 :自动用字典合并结果,无需手动拼接两个子链的输出,后续解析更方便(比如直接遍历
result["recommended_books"])。
如果用串行链,不仅耗时翻倍,还需要额外定义变量保存中间结果,代码复杂度会显著增加。
如果这篇文章对你有帮助,别忘了点赞关注哦!😊