本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

1、研究背景与动机
现实困境:医学分割的"变量太多、泛化太难"
医学图像分割长期由 U-Net/FCN 系 主导,但一换数据集就要改很多东西:网络结构细节、预处理方式、训练配置、推理与后处理策略等等,而且这些选择彼此耦合,处理不好就直接掉性能。论文直言:每个基准要想打得好,几乎都需要"专门定制"的架构和训练方案,这让研究结论难以在更广的场景里复现与泛化。
作者进一步指出:很多"看起来有效"的架构新招数,其实可能只是补了一个没充分调好的基线;当把整条 pipeline 认真优化后,这些"花哨模块"的收益并不成立------真正被低估的是非架构层面的设计(预处理、训练、推理、后处理)。这正是社区里"堆模块→小数据集验证→难以泛化"的症结。
统一检验场:Medical Segmentation Decathlon(MSD)
MSD 的目标就是逼迫算法跨 10 个不同实体/模态/几何与规模的数据集仍能工作;而且不允许对每个数据集手工调参,方法必须自动适配。这直接把"泛化+自动化"作为第一性目标。
作者的核心判断与诉求
与其再造一个"更复杂"的网络,不如把 U-Net 做到极致:
以简单、稳健的 2D/3D U-Net(以及级联)为基石;
系统定义并自动化整条 pipeline 的关键环节------重采样与归一化等预处理、损失/优化器/增广等训练、滑窗与 TTA 等推理、以及必要连通性约束等后处理;
让这些决策随数据特性和硬件约束自适应,而不是靠人"拍脑袋"。
由此提出:nnU-Net("无新网络")
不是造新架构,而是做一套**自配置(self-configuring)**的分割框架:
内置 2D U-Net、3D U-Net、U-Net 级联 三种基底;按数据各向异性、体素间距、体积大小等规则自动选择与配置(如 patch 大小、下采样层数、批量与显存平衡等)。
自动确定是否启用级联(先低分辨率粗分割、再全分辨率精修),解决 3D 大体积下"视野不足/显存受限"的痛点。
在 MSD 规则下完成全自动端到端流程,并通过 5 折交叉验证 + 自动模型选择/集成 输出最优结果。
预期价值与验证
这套"把该管的都管好"的思路,带来的不是某个数据集的小幅提升,而是跨数据集的稳定优势:在 MSD 的在线榜单上(论文提交时),除一个子类外,所有任务/类别的平均 Dice 都达到当时最佳,证明了 自动化 + 标准化 pipeline 的有效性与可迁移性。
一句话动机
nnU-Net 的动机:与其不停"造新层、叠新块",不如把 U-Net 的整条工程化流程做成"可随数据自配置的标准管线",用系统化、自动化的方式解决医学分割里"泛化难、可复现差、人工调参重"的根问题。
2、核心创新点
-
自配置(Self-configuring)Pipeline
输入不是网络设计,而是数据集本身。nnU-Net 会读取数据集的体素间距、图像大小、各向异性情况等 → 然后自动推导:
Patch 大小
网络层数、卷积核大小
批大小(受 GPU 显存限制自动调整)
这样,不用人工拍脑袋调参,不同数据集都能自动适配。
-
多尺度/多维度 U-Net 组合
内置三种架构:
2D U-Net:适合各向异性很强的数据(如切片分辨率差异大)。
3D U-Net:适合中小尺寸体积。
级联 U-Net:先低分辨率粗分割,再高分辨率精修,解决大体积下视野不足/显存限制。
nnU-Net 会根据数据特性自动选择/组合这些模型。
-
预处理自动化
自动分析数据集特征,决定:
重采样策略(是否各向同性化)
强度归一化方式(如 Z-score、截断)
数据增强方式(翻转、旋转、Gamma 校正等)
保证不同模态(CT/MRI)输入都能统一。
-
训练策略标准化
固定并验证过的一整套训练配置:
损失函数:Dice + CrossEntropy 混合
优化器:SGD + Nesterov 动量
学习率调度:poly decay
数据增强:强大且通用的一揽子方案
这些不再靠经验随意设置,而是通过系统验证成为 默认最优配置。
-
推理与后处理优化
推理阶段:
使用 滑动窗口推理(避免内存溢出),并带有 重叠/加权融合。
自动应用 测试时增强(TTA),提升稳健性。
后处理:
自动判定并应用 连通性约束(如仅保留最大连通域),提升临床可用性。
-
模型选择与集成自动化
每个数据集都会进行 5 折交叉验证,记录验证集表现。
系统会自动选择表现最佳的单模型,或者做 模型集成(ensemble)。
保证最终结果稳定,不依赖人工挑选。
🔑 总结一句话
nnU-Net 的创新点不是提出新层/新模块,而是: 👉 把 U-Net 做成一个能根据数据自动调整的"标准工厂流水线" ------ 自动配置网络结构、多维度组合、预处理、训练、推理、后处理、模型选择与集成。
3、模型的网络结构
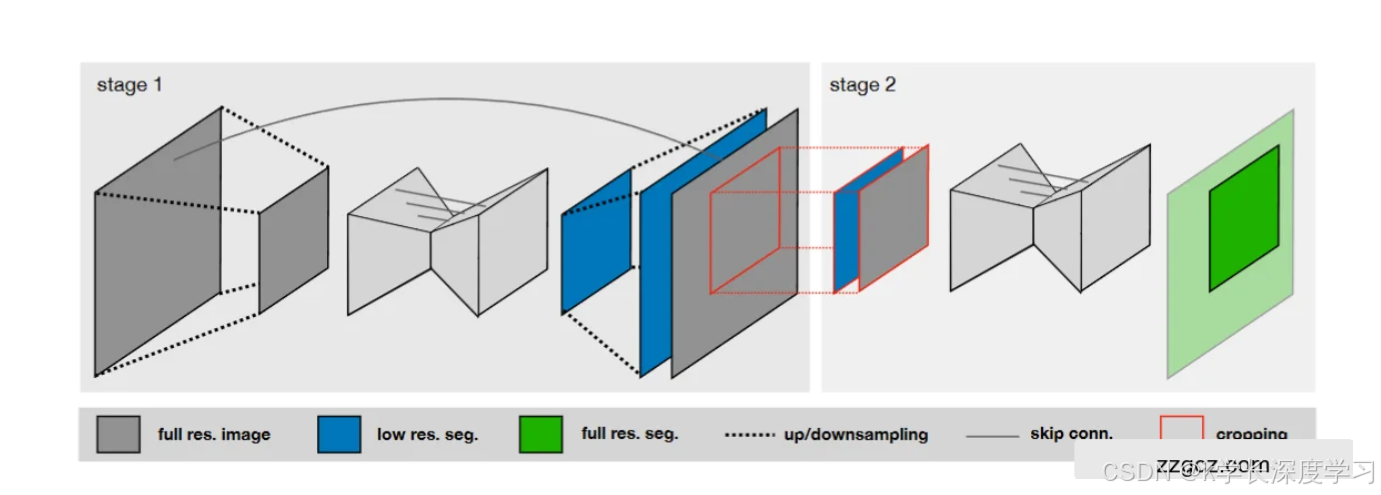
(1)整体框架
nnU-Net 的网络结构本质上还是 U-Net,但它提供了三种自动选择的变体:
2D U-Net:用于切片级任务(适合各向异性很强的数据)。
3D U-Net:直接对 3D 体数据进行分割(适合中小体积)。
3D 级联 U-Net(Cascade U-Net):先粗分割、再精细分割,适合大体积医学影像(图中展示的就是这种结构)。
(2)级联 U-Net 的两阶段设计
这张图展示了 Stage 1 + Stage 2 的流程:
👉 Stage 1:低分辨率粗分割
输入:原始全分辨率图像(灰色块)。
首先对图像进行 下采样,得到低分辨率输入。
使用一个 3D U-Net 在低分辨率下训练 → 输出一个 低分辨率的粗分割结果(蓝色块)。
这样做的好处:
计算量小(节省显存),能保证 U-Net 有更大的感受野。
即便大体积 CT/MRI,也能在有限显存里跑通。
👉 Stage 2:全分辨率精细分割
输入:由 原始图像 + Stage 1 的预测结果(上采样回原始分辨率) 组成(灰色 + 蓝色拼接)。
这一步会 裁剪(cropping,红色框) → 只关注感兴趣的区域,避免背景干扰。
输入一个新的 全分辨率 3D U-Net,结合粗分割信息,做更细粒度的预测 → 输出 全分辨率分割结果(绿色块)。
(3)跳跃连接(Skip Connections)
和经典 U-Net 一样,每个编码层的特征会直接传递到对应的解码层,帮助恢复边界细节。
图中灰色的细线表示这种 skip connection。
这保证了网络在捕捉全局上下文的同时,不丢失局部信息。
(4)为什么要级联?
如果直接用一个全分辨率的 3D U-Net:
显存爆炸,patch 尺寸太小,感受野不足。
对大器官或复杂结构的全局关系学不全。
级联方案的优势:
Stage 1 粗分割保证了 全局一致性(低分辨率大视野)。
Stage 2 精细修正保证了 局部细节准确(全分辨率小 patch)。
这就是 nnU-Net 在大体积任务上表现突出的关键原因。
🔑 总结
基础单元:U-Net(2D/3D)。
自动选择:根据数据特性决定是 2D、3D,还是 级联。
级联结构(图中):
Stage 1:低分辨率 3D U-Net 粗分割(蓝色)。
Stage 2:全分辨率 3D U-Net 精分割(绿色),输入包括原图 + 粗分割结果,并通过裁剪聚焦目标区域。
核心思想:先看"大局",再做"细修",既保证全局一致性,又保留细节精度。
4、存在的重大缺陷
- 计算成本与资源消耗高
nnU-Net 虽然"自动配置",但往往会生成 大而全的网络,在训练和推理时都非常吃显存和算力。
例如 3D U-Net 和级联 U-Net(cascade)需要同时训练多个模型,显存占用和计算开销大,不适合算力受限的临床环境。
作者在论文中也强调过:大体积 3D 数据必须依赖"低分辨率粗分割 + 高分辨率精修"的两阶段模式,否则硬件根本跑不动。 - 过度依赖数据驱动的启发式规则
nnU-Net 并不是"万能自适应",它的自动化决策(例如 patch 大小、是否使用 2D/3D、级联与否)依赖一系列人工设定的启发式规则。
虽然这些规则是经过大量实验总结的,但依然带有经验性质,不一定在所有新模态、新任务下都完全最优。
换句话说,nnU-Net 更像是"专家经验的自动化脚本",而不是彻底学习型的自优化系统。 - 缺乏新颖的网络架构设计
nnU-Net 的核心思路是"把 U-Net 打磨到极致",而不是提出新的架构。
这意味着它的性能上限依然受限于 U-Net 框架本身,缺乏对 长程依赖建模 的能力(相比 TransUNet、Swin-UNet)。
在一些需要强全局上下文的任务中(如器官间关系建模),它可能不如 Transformer 类方法。 - 训练与验证流程繁琐
nnU-Net 默认进行 5 折交叉验证 并做模型选择/集成,这保证了结果稳健,但带来的问题是:
训练成本成倍增加(一次任务要训练好几个模型)。
在实际临床应用中,这种多模型方案推理速度慢,不利于实时应用。 - 主要针对 MSD 设计,跨域泛化有限
nnU-Net 的自动化策略是围绕 MSD(Medical Segmentation Decathlon) 任务精心调试的。
在论文之外的某些极端场景(比如超高分辨率病理切片、非 CT/MRI 的特殊模态),它的默认 pipeline 可能不适用,仍需要人为调整。
5、后续基于此改进创新的模型
(1)更高效的 nnU-Net 变体
nnU-Netv2(2023)
在官方更新中,nnU-Netv2 进一步优化了自动化流程,简化代码、提升易用性。
在不牺牲性能的前提下减少冗余操作,使得训练更高效。
增强了对 多模态数据 的适配能力。
轻量化 nnU-Net(Lite nnU-Net)
在社区衍生研究中,有人提出减少通道数/深度,替换部分模块为更高效卷积,降低显存和计算需求,适合临床实际部署。
(2)结合 Transformer 的混合架构
TransUNet、Swin-UNet 与 nnU-Net 的结合
在 nnU-Net 的 pipeline 中引入 Transformer backbone(比如 Swin Transformer),兼顾 nnU-Net 的自动化优势与 Transformer 的全局建模能力。
代表性工作如 UNETR(3D Transformer U-Net),虽然不是直接在 nnU-Net 上构建,但与 nnU-Net 的理念类似:保留 U 型结构,用 Transformer 替代卷积特征提取。
Transformer-nnU-Net(社区改进版)
研究者尝试将 nnU-Net 的自配置流程与 Vision Transformer 相结合,使其在复杂器官间关系建模上表现更强。
(3)跨模态与跨域泛化
nnU-Net + Domain Adaptation
针对 nnU-Net 在跨医院、跨模态任务上效果下降的问题,研究者引入 对抗学习、风格迁移 等域适配技术。
例如:在 CT→MRI 转换任务上,利用生成模型做模态对齐,再送入 nnU-Net pipeline。
Multi-modal nnU-Net
针对 CT+MRI、PET+CT 等多模态输入,nnU-Net 被扩展为多分支输入架构,结合自适应 pipeline。
(4)自动化程度更高的 AutoML 扩展
nnU-Net + NAS(神经架构搜索)
nnU-Net 依靠启发式规则选择网络深度/patch 大小,但后续研究者把 NAS(Neural Architecture Search) 融入其中,让网络结构本身也能自动进化。
这样可以进一步减少"人为规则",向真正的端到端 AutoML for Medical Segmentation 发展。
Self-supervised nnU-Net
在小样本问题上,研究者引入自监督预训练(如对比学习),结合 nnU-Net pipeline,提高在数据稀缺场景下的表现。
(5)专用场景优化
3D 病理切片(Pathology nnU-Net)
针对超高分辨率的病理全切片图像,nnU-Net 的 pipeline 被修改为分块+金字塔结构。
实时 nnU-Net
在术中场景下,有人研究用压缩版 nnU-Net(减少分辨率、加速推理),保证临床可用性。
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。