AI Agent 框架选型:LangChain、LlamaIndex、Anthropic SDK 和 Codex/Claude Code 怎么选
文章目录
- [AI Agent 框架选型:LangChain、LlamaIndex、Anthropic SDK 和 Codex/Claude Code 怎么选](#AI Agent 框架选型:LangChain、LlamaIndex、Anthropic SDK 和 Codex/Claude Code 怎么选)
-
- [1. 先拆开:一个 Agent 系统到底需要什么](#1. 先拆开:一个 Agent 系统到底需要什么)
- [2. 成品 Agent 和造 Agent 的工具,不在同一层](#2. 成品 Agent 和造 Agent 的工具,不在同一层)
- [3. LangChain:通用 Agent 工程平台,不是单纯的"链"](#3. LangChain:通用 Agent 工程平台,不是单纯的“链”)
- [4. Anthropic SDK:Claude 原生开发栈,适合追求控制力](#4. Anthropic SDK:Claude 原生开发栈,适合追求控制力)
- [5. LlamaIndex:RAG 和私有数据优先](#5. LlamaIndex:RAG 和私有数据优先)
- [6. 从场景倒推选型](#6. 从场景倒推选型)
- [7. 一个实用选型表](#7. 一个实用选型表)
- [8. 常见误区](#8. 常见误区)
-
- [误区一:成品 Agent 能写框架代码,所以框架没用了](#误区一:成品 Agent 能写框架代码,所以框架没用了)
- [误区二:RAG 就等于向量数据库](#误区二:RAG 就等于向量数据库)
- [误区三:Agent 框架越复杂越专业](#误区三:Agent 框架越复杂越专业)
- [误区四:LangChain 和 Anthropic SDK 必须二选一](#误区四:LangChain 和 Anthropic SDK 必须二选一)
- 误区五:选型只看代码行数
- 总结:按复杂度所在层选工具
- 参考
现在做 AI Agent,最容易卡住的不是"有没有框架",而是"我到底在解决哪一层问题"。
同样是让 AI 帮你做事,有人需要一个能直接改代码、读仓库、跑命令的成品工具;有人要把 Claude 接进自己的后端服务;有人要搭一个可长期运行、可恢复、可观察的多步骤 Agent;还有人只是想让模型可靠地读懂公司文档。把这些需求混在一起,就会出现很多看起来正确、实际很绕的选型争论:
- 我已经有 Codex 或 Claude Code 了,还要不要 LangChain?
- LangChain 和 Anthropic SDK 到底是不是竞品?
- 做企业知识库问答,为什么很多人推荐 LlamaIndex?
- Agent 框架是不是越强越好,还是直接调 API 更好?
这篇文章不从产品清单开始,而是从第一性原理拆开:AI Agent 系统到底由哪些最小能力组成,然后再看 LangChain、LangGraph、LangSmith、Deep Agents、Anthropic SDK、Claude Agent SDK、LlamaIndex、Codex/Claude Code 分别在解决哪一层问题。
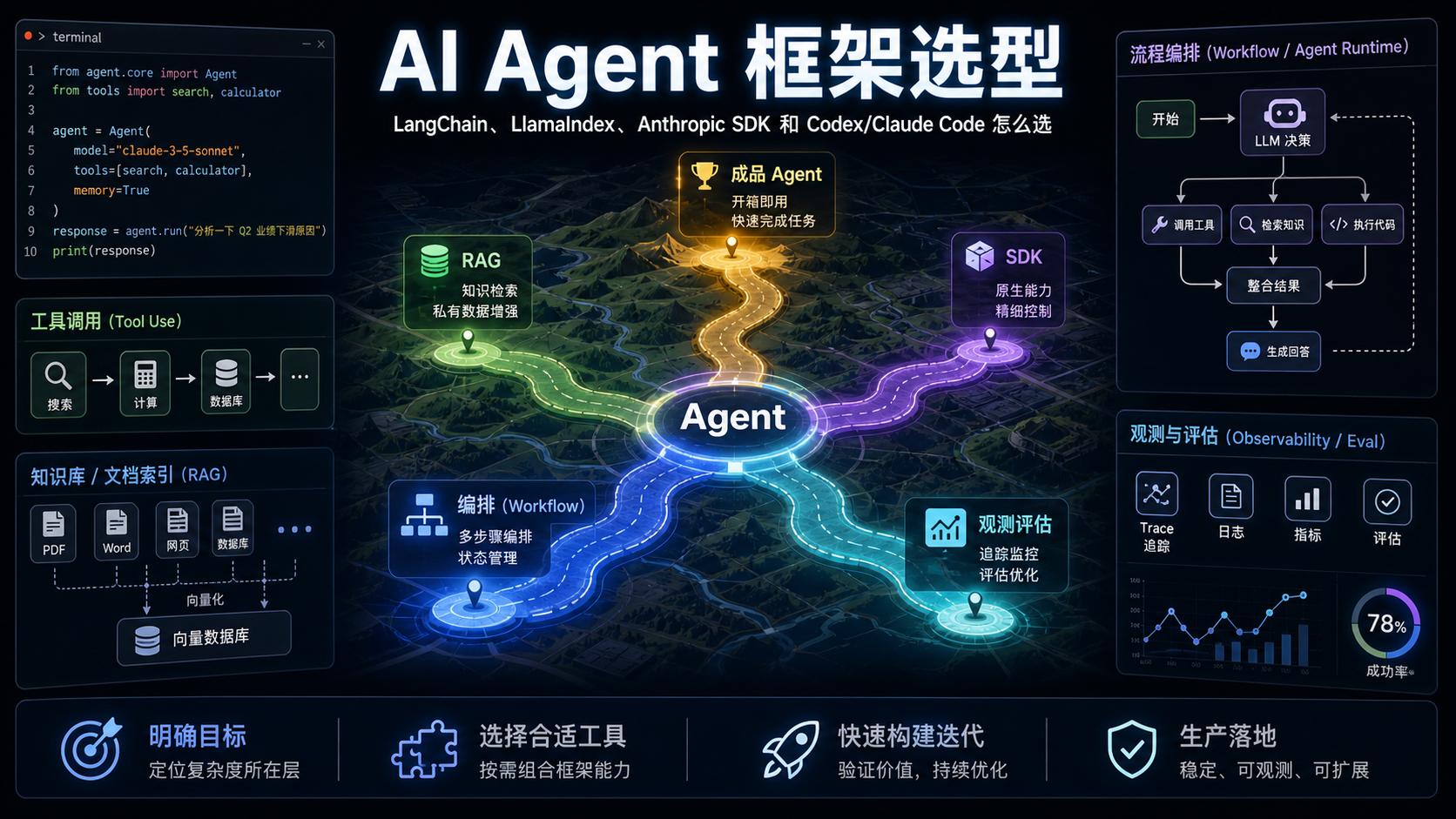
1. 先拆开:一个 Agent 系统到底需要什么

一个实用的 Agent 系统,本质上不是"一个会聊天的大模型",而是几类能力的组合。
第一层是模型调用。你需要把用户输入、系统提示词、上下文、工具定义发给模型,再拿到模型输出。最小形态就是直接调 OpenAI、Anthropic 或其他模型厂商的 API。
第二层是上下文增强。模型预训练时不可能知道你的私有文档、代码仓库、工单、数据库和最新状态,所以要有 RAG、搜索、数据库查询、文件读取等机制,把任务相关的信息放进上下文。
第三层是工具行动。Agent 不只是回答,还要能做事,比如改文件、发请求、查日志、执行命令、提交 PR、更新知识库。这里需要工具 schema、权限边界、执行结果回填、错误处理。
第四层是编排与状态。只调用一次模型还不叫复杂 Agent。复杂任务往往需要拆步骤、路由、并行、循环、人工确认、失败重试、断点恢复。这一层决定系统是"脚本"还是"长期运行的工作流"。
第五层是工程化。上线以后,你要知道每次调用用了什么 prompt、检索到了什么、工具返回了什么、为什么失败、版本变更后效果有没有退化。这就是观测、评估、回放和部署。
所以选型的关键问题不是"哪个框架最强",而是:
我的主要复杂度到底在模型调用、数据检索、工具执行、状态编排,还是生产运维?
2. 成品 Agent 和造 Agent 的工具,不在同一层
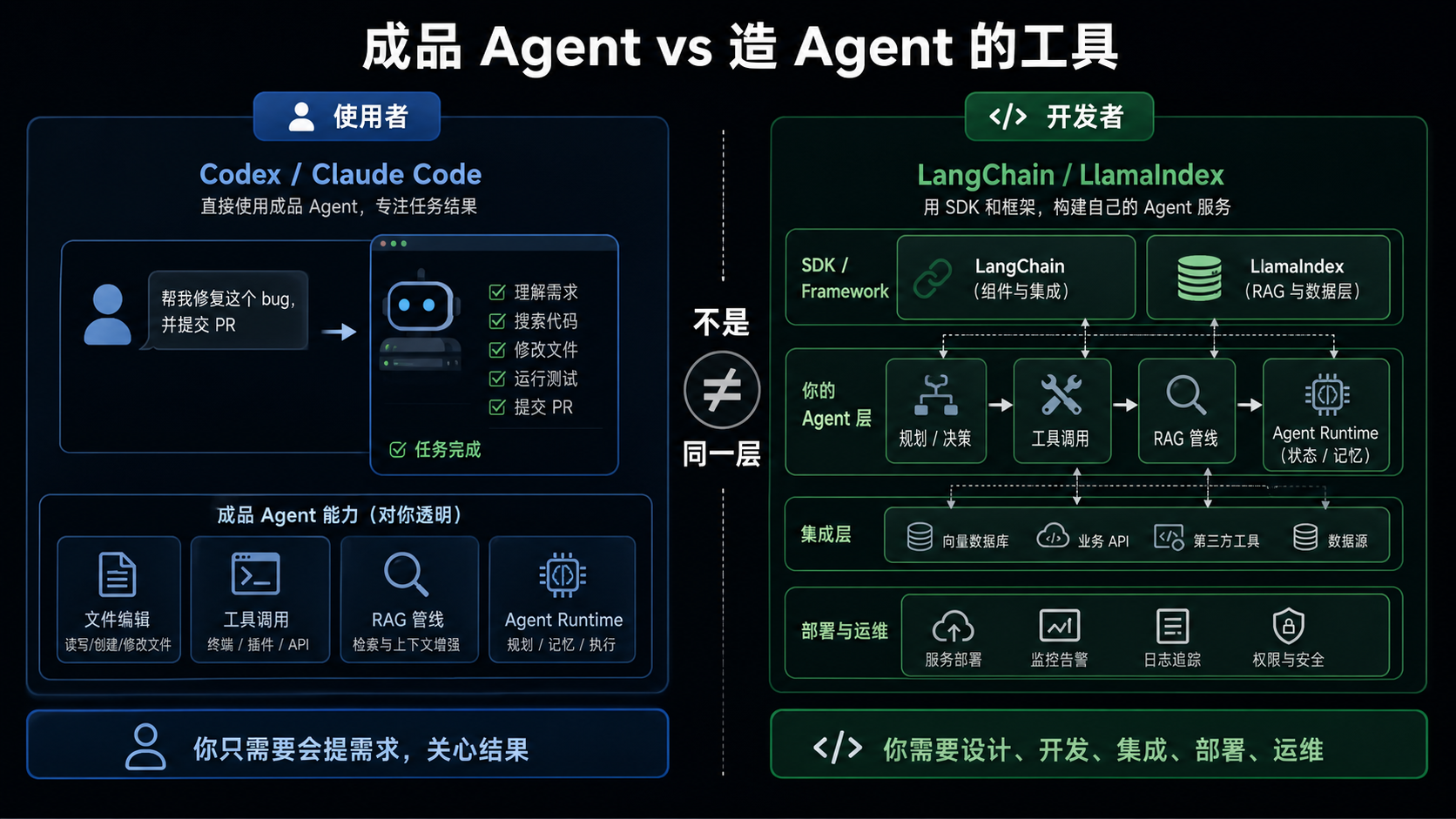
Codex、Claude Code、OpenCode 这类工具,本质上是成品 Agent。你给它一个自然语言任务,它可以读取工程目录、编辑文件、运行测试、解释代码、使用浏览器或外部工具。你是它的使用者。
LangChain、LangGraph、LlamaIndex、Anthropic SDK 这类东西,本质上是用来开发 Agent 或 LLM 应用的工具。你需要写代码,把模型、工具、检索、状态、评估组装成自己的系统。你是 Agent 的建造者。
这就是很多争论的根源。比如"Codex 已经能帮我写一个 RAG 系统,为什么还要 LangChain?"这句话里混了两个层次:
- Codex 是帮你写代码的 Agent。
- LangChain 或 LlamaIndex 是你最终代码里可能使用的库。
你可以让 Codex 帮你写一个不依赖任何框架的 RAG,也可以让 Codex 帮你基于 LlamaIndex 或 LangChain 写一个 RAG。它们不是互斥关系。
更直接地说:
| 你的身份 | 常见需求 | 更像哪类工具 |
|---|---|---|
| Agent 使用者 | 写代码、改 bug、总结资料、生成文档、审查 PR | Codex、Claude Code |
| API 使用者 | 在脚本或服务里调用 Claude/OpenAI | Anthropic SDK、OpenAI SDK |
| Agent 开发者 | 做一个有工具调用和状态流转的 AI 服务 | LangChain、LangGraph、Claude Agent SDK |
| RAG 开发者 | 让模型读懂私有文档、PDF、数据库、知识库 | LlamaIndex、向量库、检索组件 |
| 平台维护者 | 追踪、评估、部署、回放、监控 Agent | LangSmith、Langfuse、OpenTelemetry 等 |
如果只是个人日常工作,优先用成品 Agent,不要为了"显得工程化"先上框架。如果你要把 Agent 能力做成一个可交付、可复用、可部署的系统,才进入框架选型。
3. LangChain:通用 Agent 工程平台,不是单纯的"链"
LangChain 早期给很多人的印象是"把 prompt、LLM、parser 串起来的链式框架"。但从现在的官方定位看,它已经更像一个 Agent 工程平台:上层有 LangChain 的预制 Agent 架构和模型/工具集成,复杂状态流转交给 LangGraph,观测评估部署交给 LangSmith,Deep Agents 则提供更开箱即用的 agent harness。
它真正的价值不是"直接调 API 做不到",而是减少多模型、多工具、多步骤应用里的重复工程。
典型收益有几类:
- 模型抽象:同一个调用形态接 OpenAI、Anthropic、Google、本地模型等。
- 工具抽象:把函数、API、数据库、MCP 工具封装成模型可调用的工具。
- Agent 架构:用
create_agent()或 LangGraph 组织工具调用循环。 - 状态编排:用 LangGraph 表达分支、循环、并行、人工介入、检查点。
- 工程平台:用 LangSmith 做 trace、评估、prompt 管理和部署。
一个极简 LangChain Agent 大概长这样:
python
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"{city}: sunny"
agent = create_agent(
model="anthropic:<your-model>",
tools=[get_weather],
system_prompt="You are a concise assistant.",
)
result = agent.invoke({
"messages": [{"role": "user", "content": "上海天气怎么样?"}]
})
print(result)这段代码的意义不在于"天气查询少写了几行",而在于当工具变多、模型变多、流程要持久化时,你不必从零设计一整套 Agent runtime。
但 LangChain 也有代价:抽象层会增加学习成本,调试时要理解框架内部怎么组织消息、工具调用和状态。如果你的任务只是单次调用、单模型、单工具,直接调 SDK 往往更短、更透明。
4. Anthropic SDK:Claude 原生开发栈,适合追求控制力
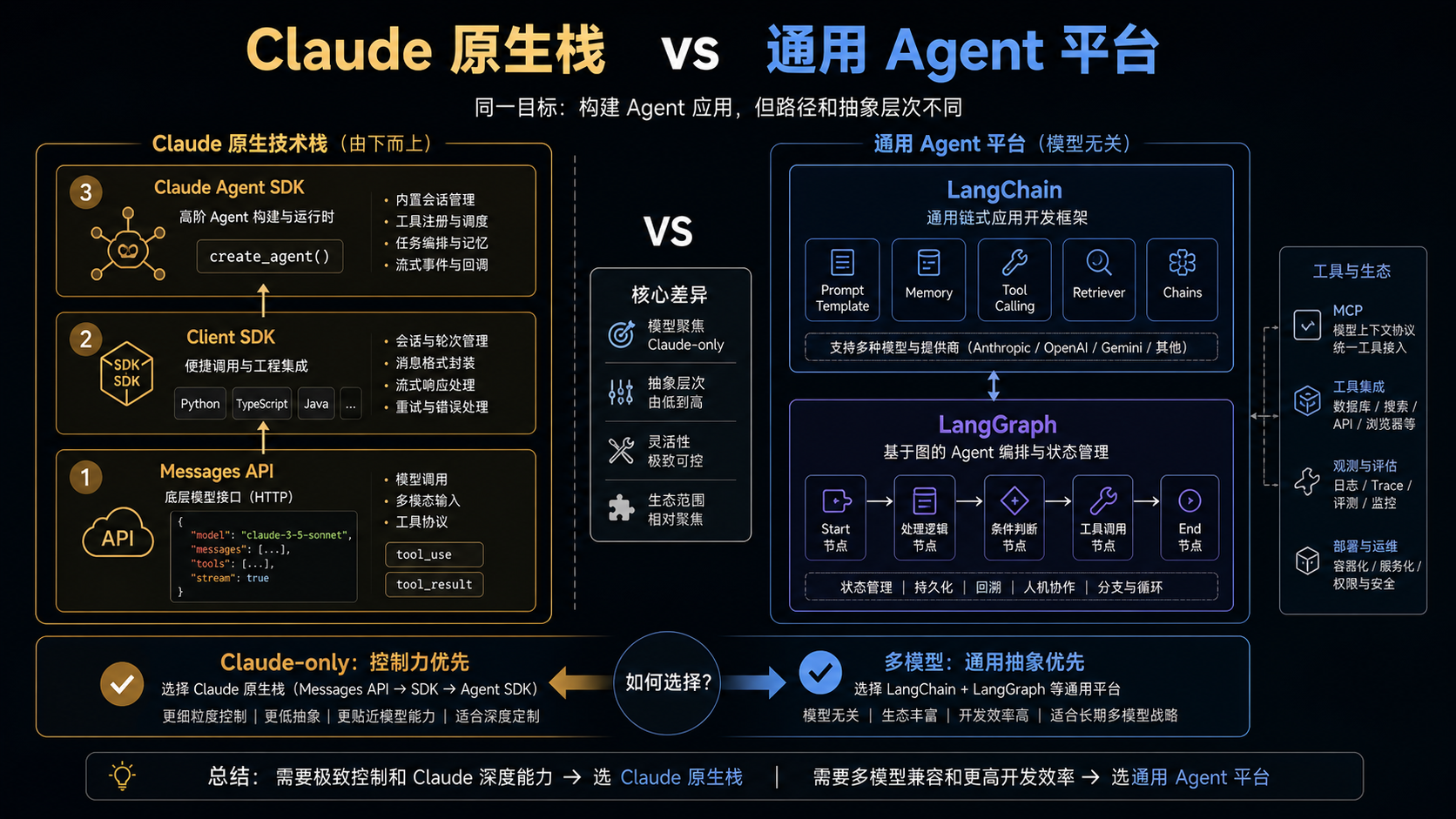
Anthropic 生态可以按三层理解:
- Messages API:最底层 HTTP API,负责对话、流式输出、工具调用、多模态输入等。
- Client SDK:Python、TypeScript、Java、Go 等语言的官方 SDK,封装认证、类型、流式、重试、错误处理。
- Claude Agent SDK:把 Claude Code 作为库来构建生产 Agent,支持工具、MCP、权限、hooks、会话、结构化输出等。
如果你明确只用 Claude,而且希望每一步都透明可控,Anthropic Client SDK 是很好的起点。它没有太厚的框架抽象,代码结构接近原始 API。你要自己管理 agent loop,但也正因为这样,prompt、messages、tool_use、tool_result 的每一步都在你手里。
伪代码大概是这样:
python
from anthropic import Anthropic
client = Anthropic()
response = client.messages.create(
model="<your-claude-model>",
max_tokens=1024,
tools=[...],
messages=[
{"role": "user", "content": "帮我查询订单状态"}
],
)
if response.stop_reason == "tool_use":
# 你执行工具,再把 tool_result 放回下一轮 messages
...这种方式很适合:
- 简单 Claude 应用。
- 延迟、依赖、可控性很敏感的服务。
- 你希望把 agent loop 写成普通代码,而不是交给框架。
- 团队已经熟悉 Claude 的 tool use 和消息结构。
Claude Agent SDK 则站在更高一层:它把 Claude Code 的能力作为库暴露出来,适合"我想做一个自己的编程 Agent / 工作流 Agent,但又想复用 Claude Code 的工具体系、MCP、权限和 hooks"。这和 LangGraph 的区别在于,Anthropic 路线更垂直绑定 Claude,LangGraph 路线更模型无关。
5. LlamaIndex:RAG 和私有数据优先
如果你的问题是"怎么让模型读懂我的数据",LlamaIndex 往往比 LangChain 更贴近主路径。
它的核心不是通用编排,而是上下文增强:数据连接、文档加载、解析、分块、索引、检索、查询引擎、RAG 工作流。官方文档也把它定位为围绕你的数据构建 LLM agent 和 workflow 的框架。
最经典的 5 行 RAG 示例是:
python
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("这个项目的架构是什么?")
print(response)这几行代码背后隐藏了很多 RAG 工程细节:读取文档、构建节点、生成索引、查询、合成回答。对于知识库问答、文档 QA、合同审查、报告分析、复杂 PDF 解析,LlamaIndex 的抽象更自然。
LlamaIndex 的另一个优势是它允许把 RAG 管线当成 Agent 的工具。也就是说,Agent 不必每次都检索,而是在需要数据时调用 QueryEngine。这比"每个问题都先强行检索再回答"更接近真实工作流。
LlamaCloud 和 LlamaParse 则进一步把文档解析、抽取、索引、检索变成托管能力。尤其是 PDF、扫描件、多栏排版、嵌套表格、图表这类资料,问题经常不在"怎么调用模型",而在"模型拿到的文本是不是干净、完整、结构正确"。这时解析质量比 Agent 编排更重要。
一句话总结:
- 数据复杂,优先看 LlamaIndex。
- 流程复杂,优先看 LangGraph。
- Claude 专属,优先看 Anthropic SDK / Claude Agent SDK。
- 日常使用,优先用 Codex / Claude Code 这类成品 Agent。
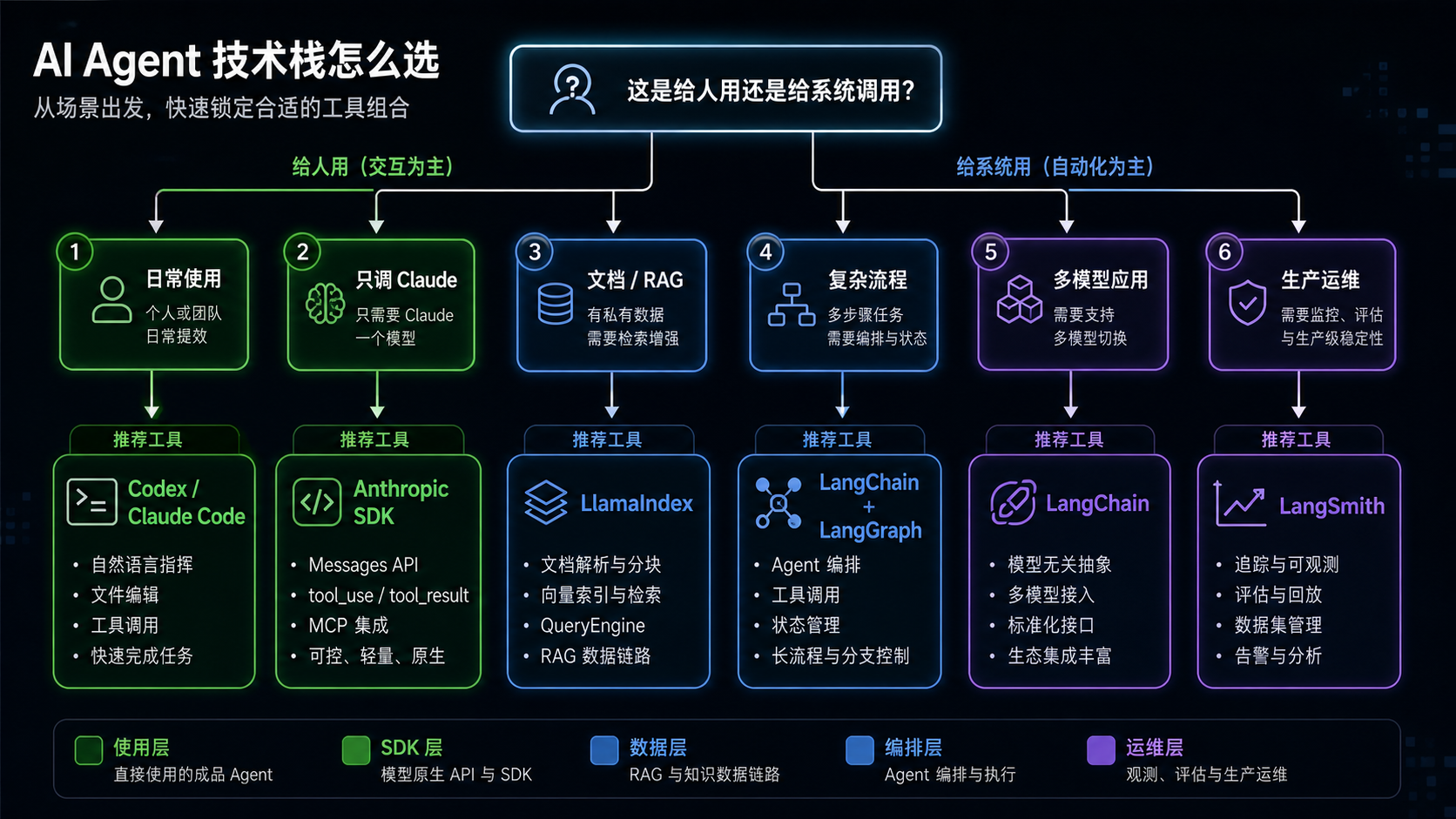
6. 从场景倒推选型
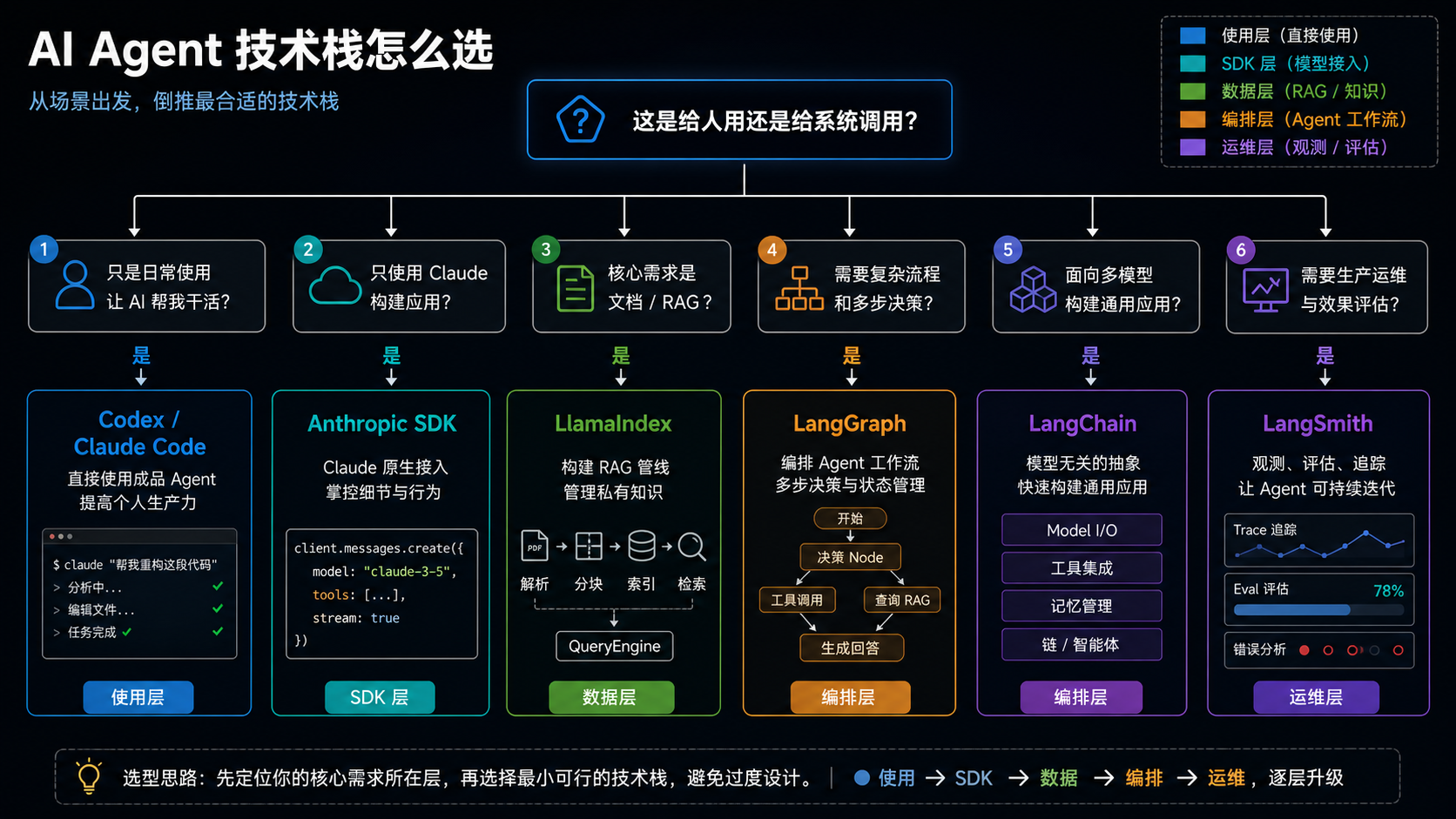
不要先问"LangChain、LlamaIndex、Anthropic SDK 哪个最好"。先问下面几个问题。
问题一:这是给人用,还是给系统调用?
如果是你自己或团队成员日常用来写代码、查资料、做文档、跑任务,成品 Agent 是最短路径。Codex、Claude Code 这类工具已经把文件读写、命令执行、浏览器、MCP、权限、上下文管理做成了用户产品。
如果你要把能力嵌入自己的系统,比如做一个内部知识库问答服务、自动客服、工单分析器、代码审查机器人,那才需要 SDK 或框架。
问题二:复杂度主要在数据,还是流程?
数据复杂:大量 PDF、网页、飞书文档、数据库、工单、图表、扫描件、多数据源,需要解析、分块、索引、检索、rerank。优先考虑 LlamaIndex。
流程复杂:多步骤任务、条件分支、并行子任务、人工确认、长任务恢复、失败重试、多个工具交替调用。优先考虑 LangGraph,或者在 Claude-only 场景下考虑 Claude Agent SDK。
很多真实系统两者都有。常见组合是:
- LlamaIndex 负责 RAG 和 QueryEngine。
- LangGraph 负责任务状态和流程编排。
- LangSmith 或其他观测系统负责 trace、eval、部署和回放。
问题三:是否必须支持多模型?
如果你明确只用 Claude,Anthropic Client SDK 是最直接的底座。它依赖少、路径短、和 Claude 能力同步快。
如果你要同时接 OpenAI、Anthropic、Gemini、本地模型,甚至做模型路由、降级、A/B 测试,LangChain 的统一模型接口会有实际价值。
问题四:是否已经到生产阶段?
原型阶段最重要的是看清问题,不要过早搭复杂平台。很多任务用一次模型调用加少量检索就够了。
但生产阶段问题会变成:
- 每次回答到底用了哪些上下文?
- 工具调用失败怎么重放?
- 新 prompt 是否让质量退化?
- 哪些样本应该进入评估集?
- 长任务怎么恢复?
- 线上成本和延迟怎么追踪?
这时 LangSmith、OpenTelemetry、评估集、回放系统就不再是"可选项",而是工程基础设施。
7. 一个实用选型表
| 场景 | 推荐起点 | 原因 |
|---|---|---|
| 个人写代码、改 bug、写文档 | Codex / Claude Code | 成品 Agent,路径最短 |
| 简单脚本调用 Claude | Anthropic Client SDK | 低依赖、透明、可控 |
| Claude 专属自定义 Agent | Claude Agent SDK | 复用 Claude Code 的工具、MCP、权限和 hooks |
| 多模型、多工具应用 | LangChain | 模型和工具抽象成熟,生态广 |
| 有状态多步骤工作流 | LangGraph | 分支、循环、并行、检查点、人机协作更自然 |
| 企业知识库 / 文档 QA | LlamaIndex | RAG 链路、数据连接、索引和检索是主路径 |
| 复杂 PDF / 表格 / 图表解析 | LlamaParse / LlamaCloud | 解析质量决定最终回答质量 |
| 上生产后的追踪、评估、部署 | LangSmith 或同类平台 | 需要 trace、eval、prompt 管理和部署闭环 |
8. 常见误区
误区一:成品 Agent 能写框架代码,所以框架没用了
成品 Agent 是开发助手,框架是应用里的运行时或库。你可以让 Agent 写框架代码,也可以让它写无框架代码。二者不是同一层。
误区二:RAG 就等于向量数据库
向量库只是 RAG 的一环。真正影响质量的还有解析、清洗、分块、元数据、召回、重排、上下文压缩、答案合成、引用和评估。LlamaIndex 的价值就在于把这条数据链路做成主路径。
误区三:Agent 框架越复杂越专业
Anthropic 的工程文章反复强调一个原则:从最简单的方案开始,只有当复杂度真的带来任务收益时才上 Agent 或框架。复杂框架会带来调试成本、延迟成本和认知成本。
误区四:LangChain 和 Anthropic SDK 必须二选一
不必。LangChain 可以用 Anthropic 作为底层模型 provider;你也可以在 LangGraph 某些节点里直接调用 Anthropic SDK,以便对关键路径保持最大控制力。
误区五:选型只看代码行数
5 行、15 行、50 行只是原型体验。真正决定选型的是后续问题:数据源会不会变多,流程会不会变长,模型会不会切换,是否要多人维护,是否要线上评估和回滚。
总结:按复杂度所在层选工具
AI Agent 技术栈可以用一句话压缩:
模型调用是地基,RAG 解决数据,工具解决行动,编排解决流程,观测评估解决生产。
对应到选型:
- 只是使用 AI 做工作:用 Codex / Claude Code。
- 只是调 Claude:用 Anthropic Client SDK。
- 要复用 Claude Code 能力开发 Agent:用 Claude Agent SDK。
- 要做通用多模型 Agent 应用:用 LangChain。
- 要做复杂状态编排:用 LangGraph。
- 要做私有数据和文档智能:用 LlamaIndex / LlamaParse。
- 要上线维护:补上 LangSmith 或同类观测评估体系。
不要从框架名开始选,从系统复杂度开始选。复杂度在哪一层,工具就应该选在哪一层。
参考
- LangChain 官方文档:LangChain overview
- LangChain 官方文档:Deep Agents overview
- LangSmith 官方文档
- Anthropic Engineering:Building Effective Agents
- Claude API 文档:Client SDKs
- Claude Code 文档:Agent SDK overview
- OpenAI Codex 文档
- LlamaIndex Framework 官方文档
- LlamaParse / LlamaCloud 文档
- LlamaHub
- Anthropic SDK Python GitHub
- Claude Agent SDK Python GitHub
- Claude Code GitHub
- LlamaIndex GitHub