1.获取渲染后的网页代码
其实就是用selenium库获取百度首页完整html源码
python
'''获取渲染后的网页代码'''
from selenium import webdriver#导入selenium主模块
from selenium.webdriver.edge.options import Options#edge浏览器配置选项
from time
edge_options =Options()#创建edge浏览器的配置对象
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
#指定edge浏览器的安装路径(告诉selenium浏览器在哪)
driver = webdriver.Edge(options=edge_options)
#启动一个真正的edge浏览器(后台打开,可能看不到)
driver.get('https://www.baidu.com')#控制浏览器访问百度首页
#time.slepp(10)#如果想要窗口停留,就加入time模块,这里是停留十秒
print(driver.page_source)#获取浏览器渲染完成后的完整html代码并打印出来运行代码就会驱动浏览器打开一个百度网盘的网页
2.向网页中输入文字并开始搜索
python
'''向网页中输入文字并开始搜索'''
from selenium import webdriver#导入selenium主模块
from selenium.webdriver.edge.options import Options
#导入edge浏览器的配置选项类,用于设置浏览器启动参数
from selenium.webdriver.common.keys import Keys
#导入Keys类,包含各种键盘按键常量(如回车键,空格键等)
from selenium.webdriver.common.by import By
#导入By类,用于指定查找元素的方式(如By.ID、By.NAME)
edge_options =Options()
#创建edge浏览器的配置选项对象,用于设置浏览器启动参数
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
#浏览器位置,每个人的都不同
driver =webdriver.Edge(options=edge_options)
#启动edge浏览器实例,传入配置选项,后台会打开一个edge窗口
driver.get('http://www.bilibili.com')#控制浏览器访问b站首页
driver.find_element(by=By.TAG_NAME,value="input").send_keys("薛之谦"+ Keys.RETURN)
#driver.find_element在页面中查找第一个<input>标签,也就是该页面的搜索框,这个可以打开网页检查
#.send_keys向找到的搜索框中输入想查找的内容词条,然后模拟按下回车键
# KeyS.RETURN 用于模拟按下回车键
input('dd')#这里设置一个输入语句,等待用户输入,程序就会停在这里,是一个简单的暂停方法,防止脚本执行完毕后浏览器立即关闭效果,在B站搜索框输入'薛之谦'并执行搜索
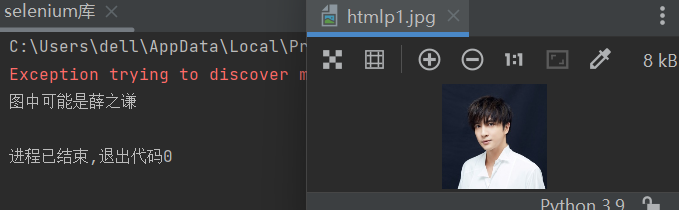
3.在百度识图中上传图片,实现对图片的识别
python
'''在百度识图中上传图片,实现对图片的识别(进阶版)'''
from selenium import webdriver#导入库的主模块,用于控制浏览器
from selenium.webdriver.edge.options import Options
#导入edge浏览器的配置选项类,用于设置浏览器启动参数
from selenium.webdriver.common.by import By导入By类,用于指定查找元素的方式
import time
#设置无头模式(不显示浏览器窗口)
edge_options = Options()
#将--headless 参数添加到 WebDriver 的配置中时,它告诉浏览器在"无头"模式下运行。
#无头模式意味着浏览器在没有图形界面的情况下运行。
#这对于执行自动化测试或者在服务器上运行爬虫时非常有用,因为它节省了资源,并且运行速度可能更快。
edge_options.add_argument('--headless')#这个存在是是否会弹出网页面,这里是无头模式
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver =webdriver.Edge(options=edge_options)
#获取网页
driver.get('https://graph.baidu.com/pcpage/index?tpl_from=pc')
# driver.find_elements(by=BY.TAG_NAME,value="input")[1].send_keys(r"图片路径")#这里是把下面两行代码合并了
input_element = driver.find_element(by=By.NAME,value="file")#定位标题
#上传图片
input_element.send_keys(r"D:\learn\htmlp1.jpg")#图片路径
time.sleep(10)
#获取识别结果
elment = driver.find_element(by=By.CLASS_NAME,value="graph-guess-word")#elements是获取所有标题
print(elment.text)打开该网站我们会发现,我们上传图片,之后要点击按键上传图片
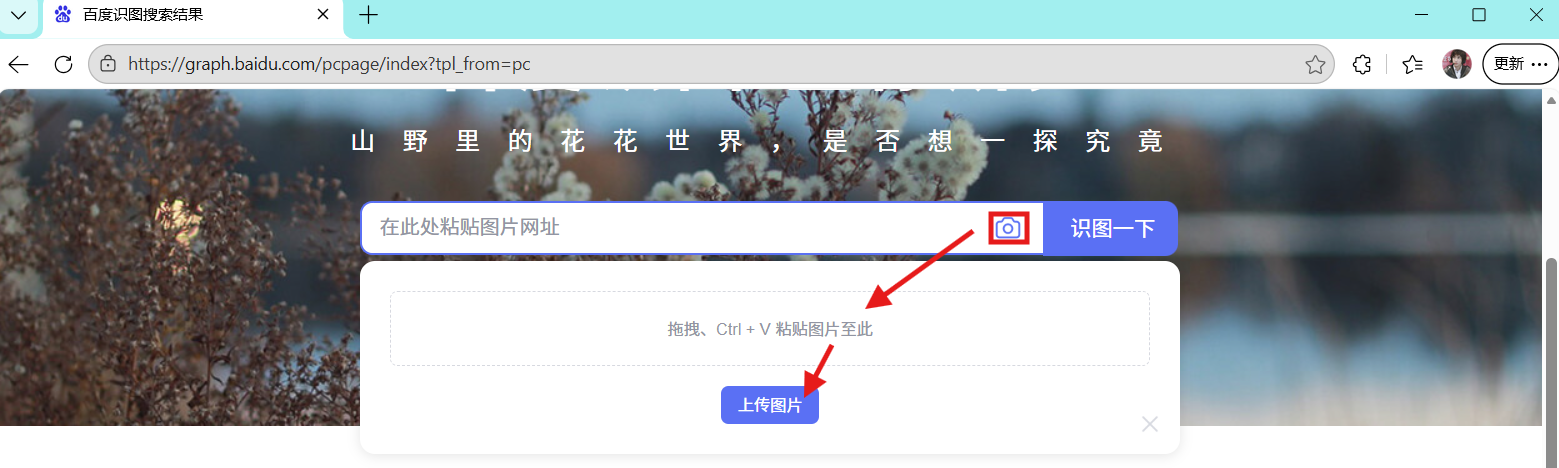
使用百度识图,识别出答案直接打印在python控制台
4.前进后退刷新
这个是网页自动刷新覆盖网页
python
'''前进后退刷新'''
from selenium import webdriver#导入库的主模块
from selenium.webdriver.edge.options import Options
#导入edge浏览器的配置选项类,用于设置浏览器启动参数
import time
edge_options =Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"#edge浏览器的位置
driver =webdriver.Edge(options=edge_options)
#先获取网页
driver.get('http://www.taobao.com')
driver.get('http://www.baidu.com')
driver.get('http://www.bilibili.com')
driver.back() #网页返回到上一步
time.sleep(5)#等待五秒
driver.forward()#网页返回到下一步
time.sleep(5)等待五秒
driver.refresh()#刷新
time.sleep(5)#等待五秒
#driver.quit()#关闭浏览器
driver.close()#关闭当前窗口5.爬取图片(find element)
python
'''爬取图片(find element)2.0'''
import requests
import os
import time
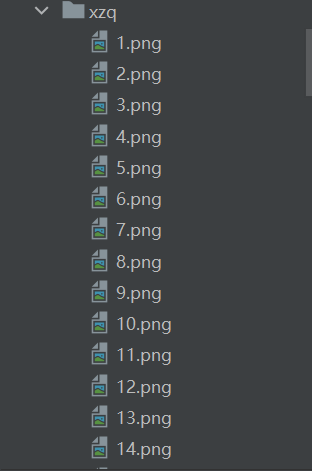
if not os.path.exists("./xzq"):
os.mkdir("./xzq")#不存在这个目录就创造目录
#批量化下载网页资源
from selenium import webdriver导入库的主模块
from selenium.webdriver.edge.options import Options#浏览器的配置选项类,便于参数启动
from selenium.webdriver.common.by import By导入#By类,用于查找标签
edge_options =Options()#初始化一个对象
edge_options.binary_location =r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"#edge的位置
driver=webdriver.Edge(options=edge_options)
driver.get('https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=薛之谦')
#执行JavaScript滚动操作,下拉滚动条
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
#上面两句可以多写几遍能加载更多图片,获取更多图片
img_list=driver.find_elements(By.XPATH, value="//img[@class='img_7rRSL']")#获取图片
# print(img list)
i=1
for img in img_list:#for循环遍历保存图片
# 获取图片的src属性
img_url = img.get_attribute("src")
img_data =requests.get(img_url)
# 保存图片到文件
with open(f"./xzq/{i}.png",'wb') as f:
f.write(img_data.content)
i += 1该网站下加载出的照片会被保存
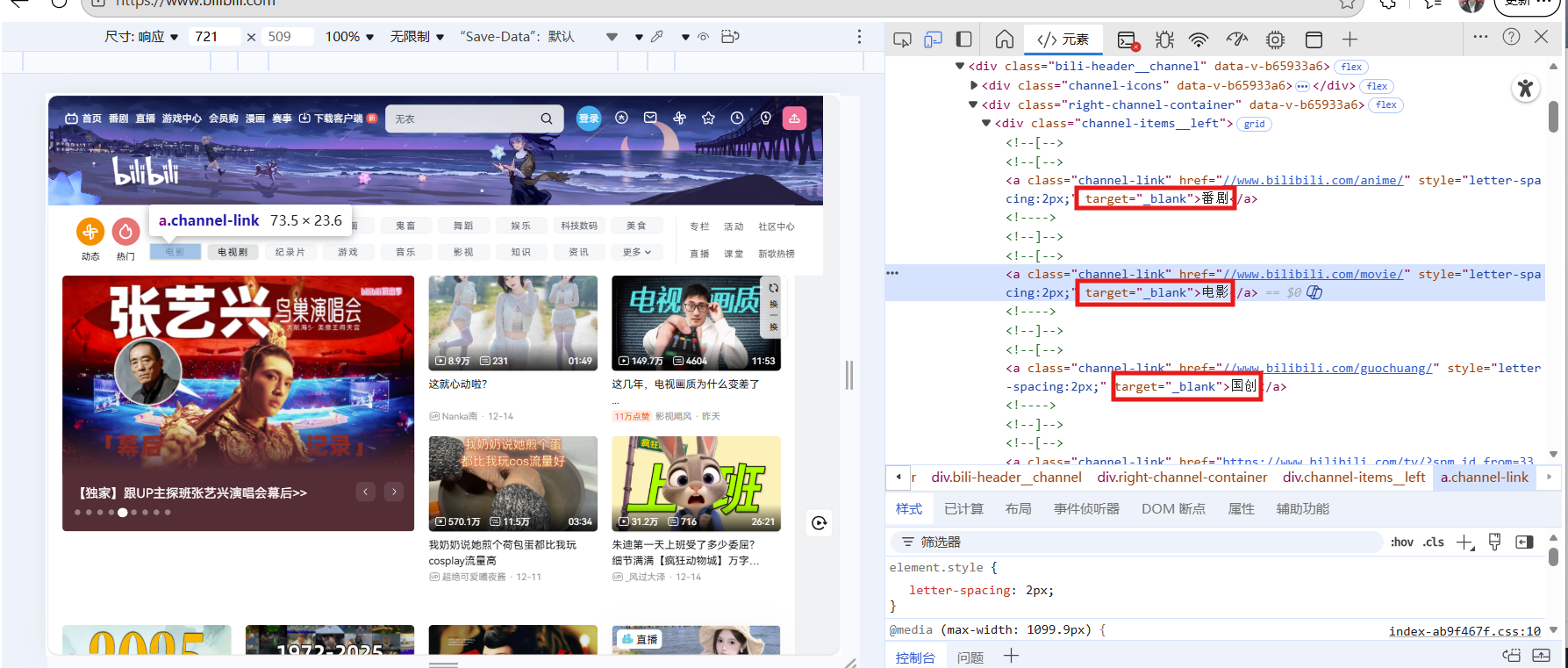
6.模拟点击click方法,点击网页的一些按钮,比如b站该页面下的电影,番剧等这点分类按钮
1)如果我们指定某一个标签点开
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time
edge_options = Options()
edge_options.binary_location =r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver =webdriver.Edge(options=edge_options)
driver.get('https://www.bilibili.com/')
time.sleep(5)
element = driver.find_element(By.LINK_TEXT,'电影')
element.click()
input('dd')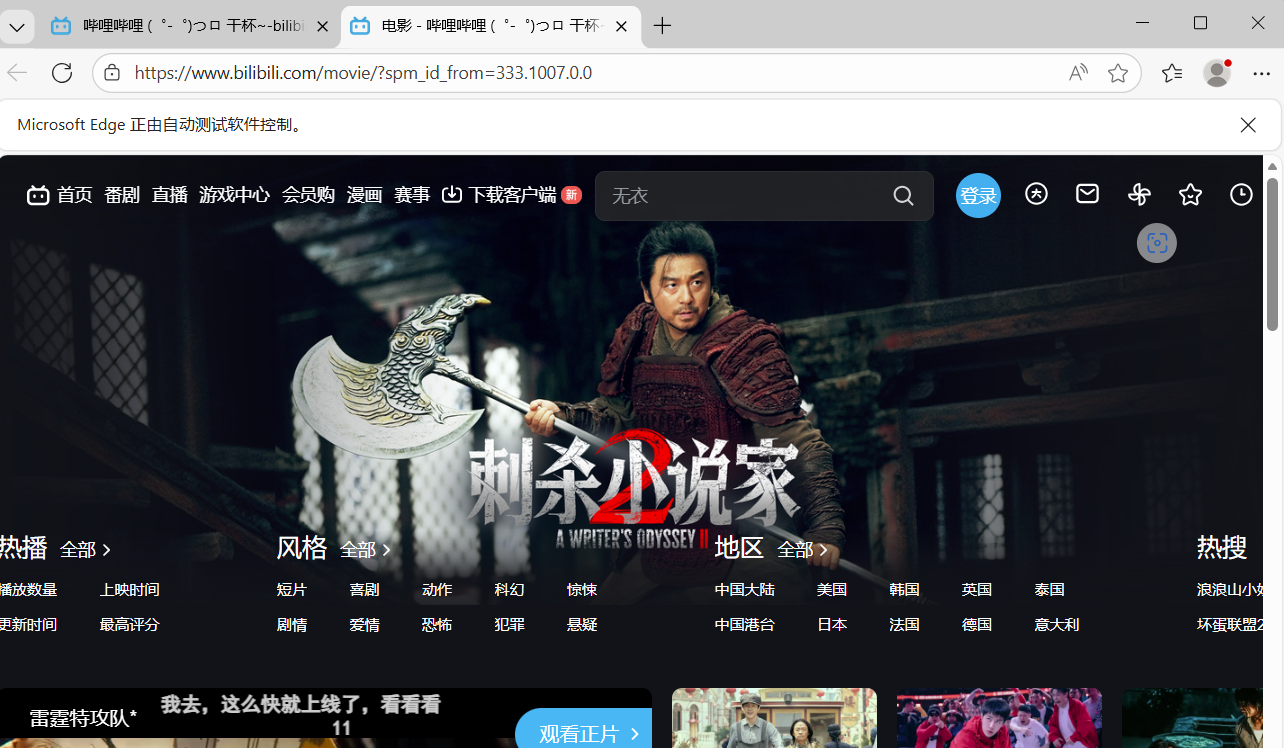
2)如果我们把所有标签收集起来
python
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location =r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver =webdriver.Edge(options=edge_options)
driver.get('https://www.bilibili.com/')
elments = driver.find_elements(by= By.TAG_NAME,value="a")#elements是获取所有标题
for elment in elments:
print(elment.text)#获取标签的内容。当标签比较多的时候
if elment.text =='番剧': #if条件判断,找到你需要的内容
elment.click()#执行对应的操作,这里执行点击,click()
input('dd')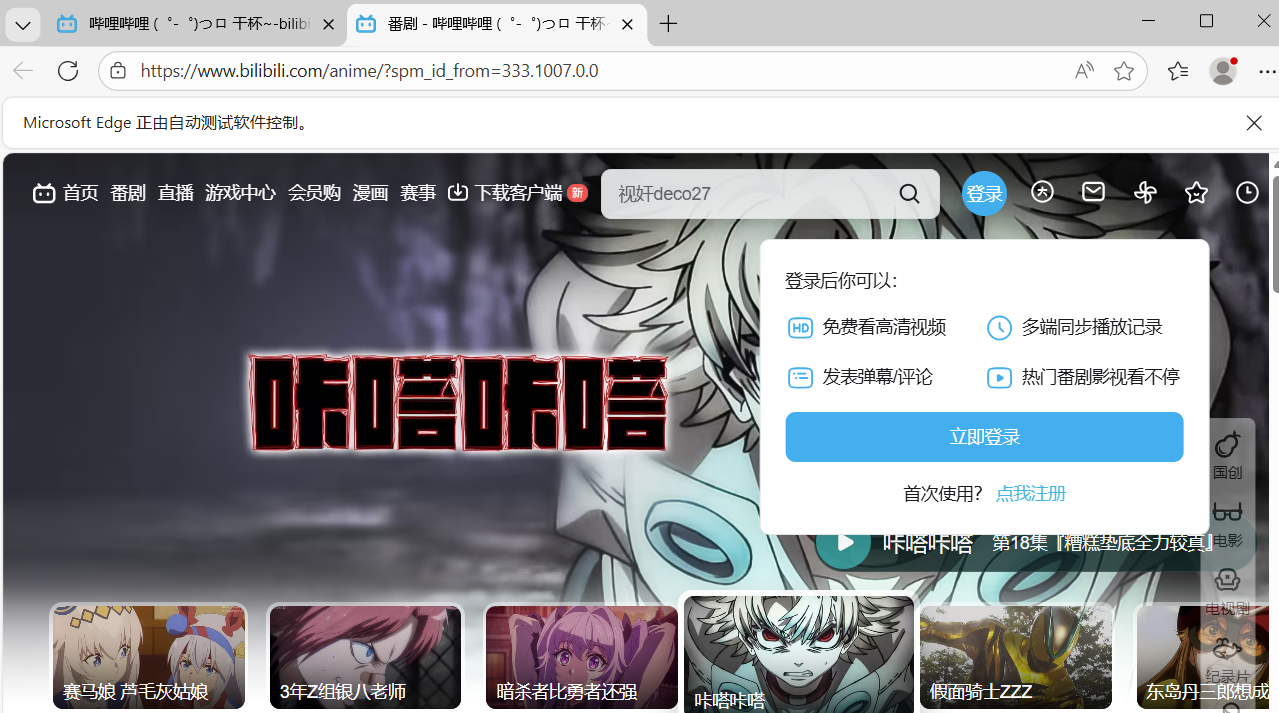
7.苏宁易购好评差评爬取
python
'''苏宁易购好评差评爬取'''
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" ##edge测览器的地加
driver =webdriver.Edge(options=edge_options)
"抓取好评"
driver.get('https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166')
hp_file = open('好评.txt','w',encoding='utf8')#文件对象
def get_py_content(file): #只能获取当前这一页的所有评论#get_py_content是定义了一个函数,函数在什么时候会执行?调用的时候
pj_elments_content = driver.find_elements(by= By.CLASS_NAME,value='body-content')#会寻找到所有class名为body-content的标然
for elment in pj_elments_content:#i =0
file.write(elment.text+'\n')
get_py_content(hp_file)#获取当第一页的评论内容
##这里可以获取下一张的,直到该网页不再有下一页的按钮,因为评论过多所以这里注释,只显示第一页的
# next_elements = driver.find_elements(by= By.XPATH,value='//a[@class="next rv-maidian "]')#xpath,,这里的标签是下一页按钮的标签
# print(next_elements)#标签元素数据,可以对这个类的数据,有一系列的操作,
# while next_elements !=[]:# 是否获取到 下一页的标签,
# next_element = next_elements[0]
# time.sleep(1)# 以确保页面加载完成后再继续执行后续的操作。
# next_element.click()
# get_py_content(hp_file)#功能:是获取当前网页的评论数据,并写入到
# next_elements = driver.find_elements(by= By.XPATH,value='//*[@class="next rv-maidian "]')
hp_file.close()
'''抓取差评'''
driver.get('https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-bad.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166')
cpj_file = open('差评.txt','w',encoding='utf8')
def get_py_content(file):
pj_elments_content = driver.find_elements(by= By.CLASS_NAME,value='body-content')
for elment in pj_elments_content:
file.write(elment.text+'\n')
get_py_content(cpj_file)
# next_elements = driver.find_elements(by= By.XPATH,value='//*[@class="next rv-maidian "]')
# print(next_elements)
# while next_elements !=[]:
# next_element = next_elements[0]
# time.sleep(2)
# next_element.click()
# get_py_content(cpj_file)
# next_elements=driver.find_elements(by= By.XPATH,value='//*[@class="next rv-maidian "]')
cpj_file.close()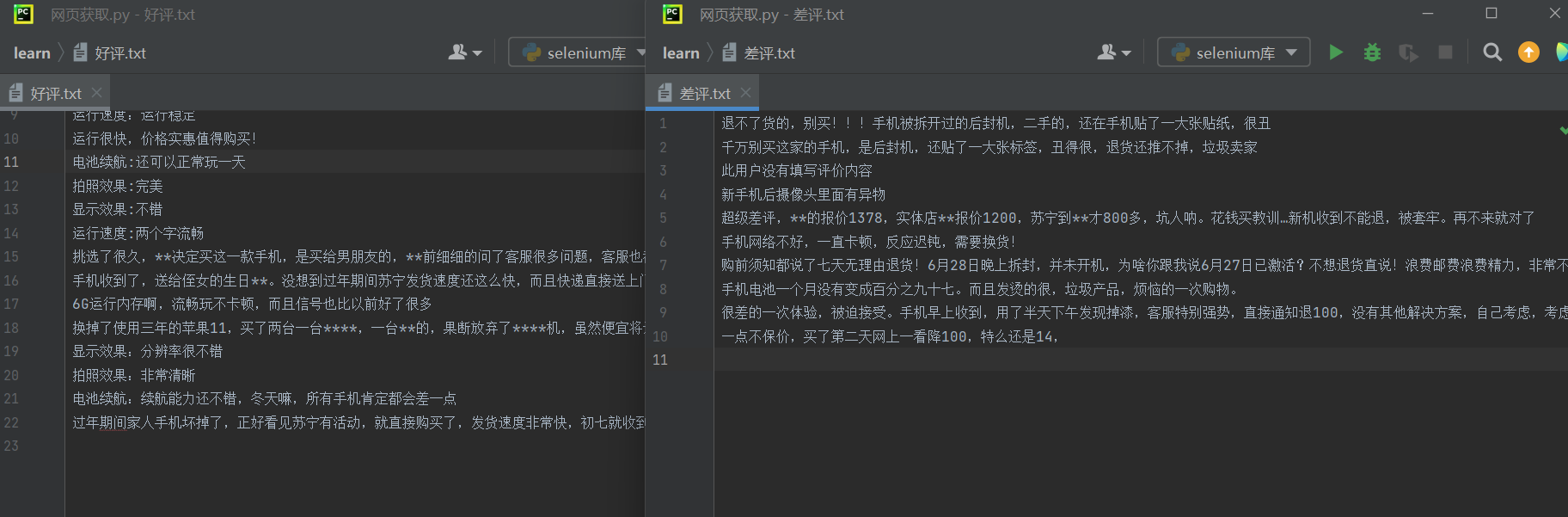
8.项目实现
python
'''项目实现:苏宁易购网站获取医用口罩信息(包含价格,名称,评价数,店铺名称)'''
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
#chrome_options.add_argument('--headless')#无浏览器界面模式
driver=webdriver.Edge(options=edge_options)
driver.get('http://www.suning.com')
element=driver.find_element(by=By.ID,value='searchKeywords')
element.send_keys('医用口罩'+Keys.RETURN)
time.sleep(10)
#执行Javascript代码,将页面滚动到底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(10)
price_elements=driver.find_elements(by=By.CLASS_NAME,value='def-price')
title_elements=driver.find_elements(by=By.CLASS_NAME,value='title-selling-point')
evaluate_elements=driver.find_elements(by=By.CLASS_NAME,value='info-evaluate')
store_elements=driver.find_elements(by=By.CLASS_NAME,value='store-stock')
a=time.strftime('%Y-%m-%d')
f=open(a+'医用口罩.txt','w',encoding='utf-8')
for i in range(len(price_elements)):
f.write(price_elements[i].text+'\t')
f.write(title_elements[i].text+'\t')
f.write(evaluate_elements[i].text+'\t')
f.write(store_elements[i].text+'\n')
f.close()
9.关于爬取图片代码的改进
写为函数,用户只需要输入想要下载的人物名字和图片张数就能完成下载图片的要求
python
def starpget(starname,pnumber):#这里是定义一个函数,名字为starpget
import requests
import os
import time
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By#在函数中必须写清以下操作需要用到的模块
if not os.path.exists(f"./{starname}"):
os.mkdir(f"./{starname}")#先创建文件夹
edge_options =Options()
edge_options.binary_location =r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"#驱动浏览器,注意这里的edge浏览器位置是我的,每个人的不同需要灵活改变
driver=webdriver.Edge(options=edge_options)
driver.get(f'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word={starname}')#根据用户输入的人物名字,获取网页
img_list=[]#定义一个空列表
while len(img_list) < int(pnumber):#当我们列表的长度小于用户输入数字,就进行以下操作,这里是一个循环,要带条件所以选择while
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#滚动,其实while内部这些语句的顺序我设置的不够好,主要是思路
#我这里是先进行滚动条滑动,再存图片,其实也可以先存图片,数量不够再进行滑动滚动条,都可以的,语句顺序可以调整
current_imgs=driver.find_elements(By.XPATH, value="//img[@class='img_7rRSL']")#列表,就是在网页中找到这样标签的元素,然后把元素存入列表
for img in current_imgs:#设置一个变量遍历这个列表,因为我们源代码是批量下载的,不方便我们确定数量,遍历的好处就在于我们能一个一个添加
if len(img_list) = int(pnumber):#等于的时候就停
break
img_list.append(img)#不等于就一个一个添加,再for循环中一次只添加一张
i=1
for img in img_list:
# 获取图片的src属性
img_url = img.get_attribute("src")
img_data =requests.get(img_url)
# 保存图片到文件
with open(f"./{starname}/{i}.png",'wb') as f:
f.write(img_data.content)
i += 1
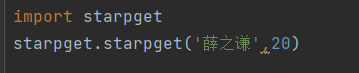
print('下载完毕!')把函数写在一个叫starpget.py的文件里
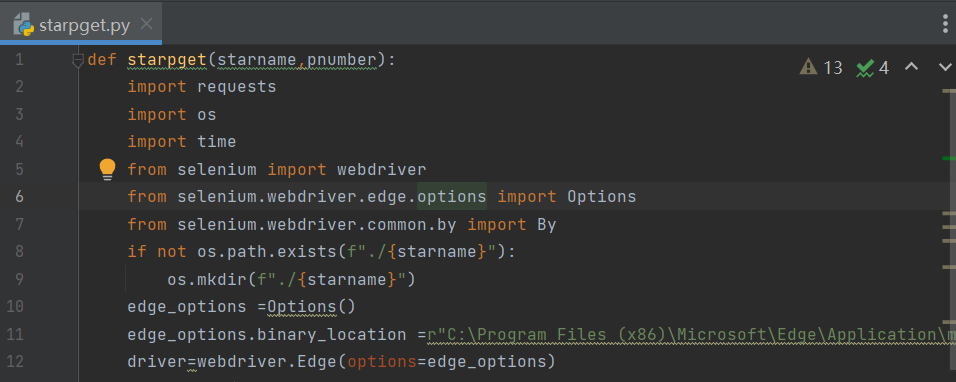
调用的时候先导入模块,再使用函数,第一个starpget是文件名字也就是模块,和使用标准库是一样的,.starpget(参数1,参数2),这是调用函数,人名是字符串要用引号引起来输入