一个看似简单的星号,在正则表达式与文件通配符中却扮演着截然不同的角色,理解这种差异是掌握精准文本匹配的关键。
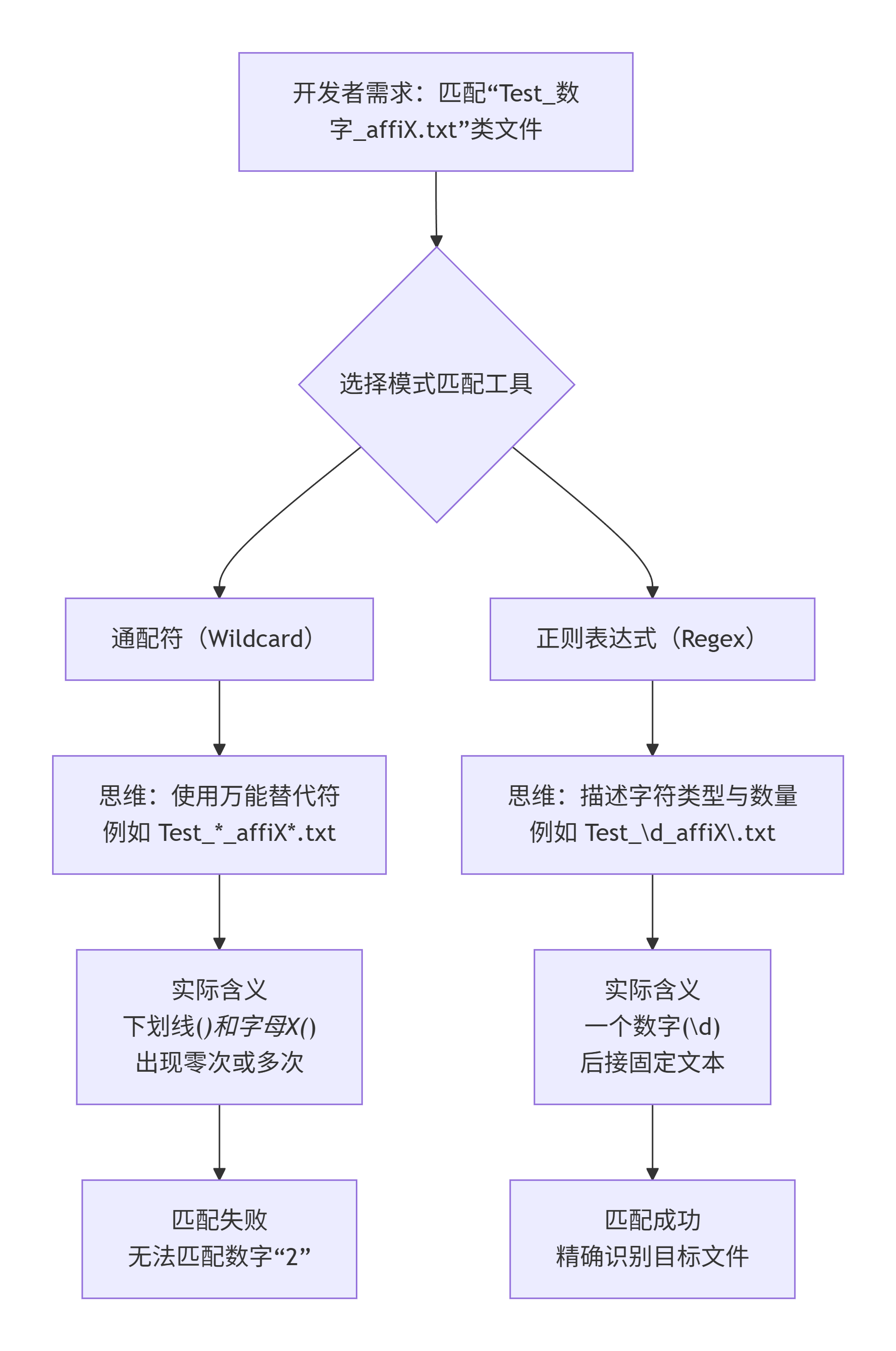
在日常的文件管理工作中,我们经常需要批量操作符合特定模式的文件。比如,想要删除所有名为 Test_2_affiX.txt 和 Test_3_affiX.txt 的文件,一位开发者可能会在批处理脚本中写下这样的正则表达式模式:Set "REGEX_PATTERNS[2]=.*Test_*_affiX*\.txt"。然而,这个模式很可能无法匹配到目标文件,其根源在于对正则表达式中星号 * 的误解------它并不是我们通常所想的"通配符"。
01 核心误区:通配符思维在正则世界中的碰壁
当我们在文件管理器里搜索 *.txt 时,星号 * 可以代表任意数量的任意字符。这种直观的"通配符"(Wildcard)逻辑深入人心。
然而,在正则表达式(Regular Expression)的领域里,相同的符号 * 却被赋予了完全不同的、更精确的语义。它不再是独立匹配任意内容的万能牌,而是一个"量词" ,其作用是修饰它前面的一个字符(或一个分组),表示"前面的元素可以出现零次或多次"。
让我们剖析这个有问题的模式:.*Test_*_affiX*\.txt
.*:这里的点.匹配任意单个字符,*修饰点,表示"任意字符出现零次或多次",这是正确的。Test_:直接匹配文本 "Test_"。*:问题出现 。在这里,*是独立存在的,它尝试修饰前面的字符,也就是下划线_。因此,_*表示"下划线出现零次或多次",它会试图匹配连续的多个下划线(如_,__),而不是匹配数字。_affiX:匹配文本 "_affiX"。*:同样的问题 。这个*修饰前面的字符X,表示 "X出现零次或多次",即尝试匹配连续的多个X(如X,XX)或零个X。\.txt:转义后的点匹配字符 ".",然后匹配 "txt"。
这个模式能匹配 Test___affiX.txt,但无法匹配 Test_2_affiX.txt,因为数字2无法被"零个或多个下划线"所代表。
02 正解之道:用正确的正则表达式构建模式
要精确匹配 Test_数字_affiX.txt 这类文件,我们需要使用正确的正则表达式语法。关键在于,当我们需要匹配一个"占位符"时,不能使用孤立的 *,而应该使用代表"任意字符"的点 .,并用量词修饰它,或者使用更精确的字符集。
以下几种是修正后的方案:
方案一:使用.匹配任意单个字符
如果中间的数字只是一位数,我们可以用 . 来表示这个未知字符。
- 模式 :
Test_._affiX\.txt - 解释 :
Test_匹配固定文本,.匹配任意一个字符(此处为数字),_affiX匹配固定文本,\.匹配字面意义的点,txt匹配固定文本。
方案二:使用\d匹配单个数字
为了更精准地限定中间是数字,可以使用 \d 元字符,它专门匹配0-9的数字。
- 模式 :
Test_\d_affiX\.txt - 解释 :
\d精确匹配一个数字,这比通用的.更具可读性和准确性。
方案三:使用字符集[0-9]匹配单个数字
与 \d 等效,[0-9] 也是一种明确匹配数字范围的方式。
- 模式 :
Test_[0-9]_affiX\.txt - 解释 :
[0-9]定义了一个字符集,匹配从0到9的任意一个数字。
方案四:使用+匹配多位数字
如果中间的数字可能不止一位(如 Test_123_affiX.txt),我们需要使用 + 量词,它表示"前面的元素出现一次或多次"。
- 模式 :
Test_\d+_affiX\.txt - 解释 :
\d+匹配一个或多个连续的数字。
通过对比可以看出,正则表达式的核心在于精确描述字符的类型 和数量,而不是简单的模糊替代。
03 系统对比:通配符与正则表达式的本质差异
理解 * 的误用,本质上是混淆了"通配符"和"正则表达式"这两套不同的模式匹配语言。它们设计目标不同,语法规则也不同。
下面的表格清晰地展示了它们的关键区别:
语法差异举例:
- 匹配所有文本文件 :
- 通配符:
*.txt(简洁直观) - 正则表达式:
^.*\.txt$(需定义开头^、任意内容.*、转义点\.和结尾$)
- 通配符:
- 匹配"img"后接两位数字的图片 :
- 通配符:
img??.jpg(?仅匹配一个字符,不保证是数字,可能匹配imgAB.jpg) - 正则表达式:
^img\d{2}\.jpg$(精准限制为两位数字\d{2})
- 通配符:
04 实战演练:在批处理与编程中应用正则
理解了理论,让我们看看如何在具体环境中应用正确的正则表达式。
场景一:在Windows批处理中筛选文件
虽然原生批处理对复杂正则支持有限,但我们可以借助 findstr 命令进行基础匹配,或通过调用其他工具实现。理解模式本身是第一步。
batch
REM 示例:使用findstr搜索当前目录下所有匹配"Test_单个数字_affiX.txt"的文本文件
REM findstr 的正则表达式语法与标准略有不同,此例为概念演示
findstr /M "^Test_[0-9]_affiX\.txt$" *.txt > result.txt
REM 注释:
REM /M 参数表示只打印包含匹配项的文件名
REM ^ 表示字符串的开始
REM [0-9] 匹配一个数字
REM \. 匹配字面意义的点(.)
REM $ 表示字符串的结束
REM *.txt 指定在所有.txt文件中搜索
REM > result.txt 将结果输出到result.txt文件场景二:在Python中批量处理文件
在Python这类编程语言中,可以方便地使用 re 模块结合文件操作,实现复杂的匹配与处理。
python
import os
import re
# 定义目标目录
directory = '/path/to/your/files'
# 编译正则表达式模式,提高效率
# 模式:Test_开头,接着是至少一个数字,然后是_affiX.txt结尾
pattern = re.compile(r'Test_\d+_affiX\.txt$')
# 遍历目录下的所有文件
for filename in os.listdir(directory):
# 如果文件名完全匹配我们的正则模式
if pattern.fullmatch(filename):
# 构造文件的完整路径
full_path = os.path.join(directory, filename)
# 这里可以执行你的操作,例如打印、删除、移动等
print(f"找到匹配文件: {full_path}")
# os.remove(full_path) # 示例:删除文件(谨慎操作!)
# 注释:
# `re.compile()` 将正则字符串预编译为模式对象,适合重复使用。
# `r'...'` 表示原始字符串,防止反斜杠被Python字符串转义。
# `\d+` 匹配一个或多个数字。
# `\.` 匹配字面意义的点。
# `$` 确保匹配到文件名末尾。
# `pattern.fullmatch()` 要求整个字符串与模式匹配,更严格。
# `os.path.join()` 安全地连接目录和文件名。生词表:
| 单词/短语 | 音标 | 词性 | 释义 | 例句/搭配 |
|---|---|---|---|---|
| Regular Expression | /ˈreɡjələr ɪkˈspreʃn/ | 名词 | 正则表达式,一种描述字符串模式的语法 | Learning regular expression is key to text processing. |
| Wildcard | /ˈwaɪldkɑːrd/ | 名词 | 通配符,用于简单模糊匹配的符号(如*, ?) | Use a wildcard to find all .txt files. |
| Quantifier | /ˈkwɒntɪfaɪə®/ | 名词 | 量词,指定前面元素出现次数的符号(如*, +, ?) | The asterisk is a quantifier meaning "zero or more". |
| Metacharacter | /ˈmetəˌkærɪktə®/ | 名词 | 元字符,在正则中有特殊含义的字符(如 ., ^, $) | The dot is a metacharacter that matches any character. |
| Escape | /ɪˈskeɪp/ | 动词 | 转义,使用反斜杠(\)使元字符失去特殊意义 | You need to escape the dot to match a literal period (\.). |
| Character Class | /ˈkærəktə® klɑːs/ | 名词 | 字符集,用方括号定义的一组待匹配字符(如 0-9, aeiou) | [A-Za-z] is a character class matching any letter. |
| Literal | /ˈlɪtərəl/ | 形容词 | 字面意义的,指匹配字符本身而非其特殊含义 | To search for an asterisk, you need its literal meaning (\*). |
| Pattern | /ˈpætn/ | 名词 | 模式,由正则表达式定义的要匹配的字符串规则 | The script searches for files matching a specific pattern. |
| Batch File | /bætʃ faɪl/ | 名词 | 批处理文件,包含一系列可执行命令的脚本文件(.bat, .cmd) | Automate the task by creating a batch file. |
正则表达式的力量源于其精确性,而非模糊性。当我们在批处理脚本中写下 .*Test_*_affiX*\.txt 而无法得到预期结果时,这正是一个绝佳的学习契机。它提醒我们,在文本处理的工具箱里,既要会用简单快捷的通配符,也要懂得在需要精确控制时,拿起正则表达式这套更精密的手术刀。