引言
在人工智能时代,获取数据是第一步。爬虫技术能帮我们打开网页背后的信息。对于初学者来说,Selenium是一个非常友好的入门选择------它不仅能获取网页数据,还能模拟真实用户的操作,比如点击按钮、输入文字、上传文件等。我们之前学习的requests库虽然简单高效,但它只能获取静态网页内容。现在许多网站都使用JavaScript动态加载数据,这时候就需要Selenium库了。它可以等待页面完全加载,获取渲染后的完整内容,就像你用浏览器看到的那样。
一、Selenium基础知识
1、什么是Selenium?
Selenium最初是为Web应用程序测试而生的工具。Selenium可以录制我们的操作,然后自动重复执行,就像一个不知疲倦的测试员。但既然Selenium能控制浏览器,那为什么不把它用来抓取数据呢?于是,Selenium在爬虫领域也开始应用了起来。
2、Selenium工作原理
Selenium的工作原理为:首先,我们编写的Python代码通过调用Selenium库发出指令;随后,这些指令被传递给对应浏览器的WebDriver驱动,该驱动将代码命令转换为浏览器能直接理解并执行的底层操作,最后,浏览器根据接收到的命令完成相应的网页交互。不同的浏览器需要各自专属的WebDriver程序,并且必须确保WebDriver的版本与浏览器版本严格匹配,以保证整个通信链路的顺畅和功能的正常运行。
Python代码 → Selenium库 → WebDriver驱动 → 浏览器二、环境搭建
1、安装Selenium库
打开命令行(Windows用户按Win+R,输入cmd),输入:
pip install selenium==4.11.0 -i https://pypi.mirrors.ustc.edu.cn/simple/2、下载浏览器驱动
先查看浏览器版本:
1)、Edge浏览器:右上角三个点 → 帮助和反馈 → 关于Microsoft Edge
2)、Chrome浏览器:右上角三个点 → 帮助 → 关于Google Chrome
下载地址:
Edge驱动:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Chrome驱动:https://chromedriver.storage.googleapis.com/index.html
Firefox驱动:https://github.com/mozilla/geckodriver/releases3、配置驱动路径
Windows把下载的msedgedriver.exe(Edge)或chromedriver.exe(Chrome)放到Python安装目录的Scripts文件夹里,也可以者任何位置,但要在代码中指定完整路径。
4、验证安装是否成功
创建一个测试文件:如果看到浏览器自动打开并显示百度页面,则代表环境配置成功。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.baidu.com')
print("浏览器已成功打开!")
input("按回车键关闭浏览器...")
driver.quit()
三、Selenium基础操作
1、打开你的第一个网页
使用Selenium进行网页自动化操作时,首先需要从selenium库中导入webdriver模块以及针对特定浏览器(如Edge)的配置选项Options,并通过binary_location参数指定浏览器程序的准确路径来初始化浏览器选项。接着,利用配置好的选项创建并启动对应的WebDriver实例,该实例会控制一个真实的浏览器窗口;随后,调用driver.get()方法导航至目标网址,并使用time.sleep()短暂暂停以便观察页面加载效果;最后,为确保资源释放,必须调用driver.quit()方法来完全关闭浏览器及相关的驱动程序。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
# 创建浏览器选项
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
# 启动浏览器
driver = webdriver.Edge(options=edge_options)
# 访问网页
driver.get('https://www.baidu.com')
# 等待5秒,看看效果
time.sleep(5)
# 关闭浏览器
driver.quit()
2、同时打开多个标签页
在Selenium中,可以通过执行JavaScript代码实现同时打开并管理多个标签页,首先配置并启动Edge浏览器驱动,使用driver.get()方法打开初始网页;随后,利用driver.execute_script()执行window.open()函数在新标签页中依次打开其他指定网址。通过driver.window_handles可以获取所有标签页的窗口句柄,并使用driver.switch_to.window()方法切换到目标标签页进行后续操作,从而实现在同一浏览器中同时打开多个网页的效果。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
# 先打开百度
driver.get('https://www.baidu.com')
# 在新标签页中打开B站
driver.execute_script("window.open('https://www.bilibili.com','_blank');")
# 再打开一个学习网站
driver.execute_script("window.open('https://www.shuyishe.com','_blank');")
# 获取所有标签页的句柄
handles = driver.window_handles
print(f"当前打开了 {len(handles)} 个标签页")
# 切换到第二个标签页(B站)
driver.switch_to.window(handles[1])
print("现在显示的是B站页面")
input("按回车键关闭所有页面...")
driver.quit()
3、获取网页源代码
在Selenium中,获取网页源代码首先要配置并启动Edge浏览器驱动并导航至目标网页,随后通过driver.page_source属性即可获取浏览器当前已渲染完成的完整HTML代码,可以对其内容进行查看或将其保存到本地文件,最后通过driver.quit()关闭浏览器。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.baidu.com')
# 获取渲染后的完整HTML代码
html_source = driver.page_source
# 查看前1000个字符
print(html_source[:1000])
# 保存到文件
with open('baidu_page.html', 'w', encoding='utf-8') as f:
f.write(html_source)
driver.quit()
四、网页交互
1、在搜索框输入文字
通过Selenium在网页搜索框中输入文字首先要配置并启动Edge浏览器驱动,并导航至目标网页;随后,利用driver.find_element方法配合定位策略来定位页面的输入框元素;定位成功后,调用元素的send_keys方法即可将指定文本(如"Python编程")输入到搜索框中。如果页面存在多个相似元素,则需改用find_elements获取元素列表并通过索引选取目标元素,最后通过driver.quit()关闭浏览器。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.bilibili.com/')
# 方法1:通过标签名找到输入框
#search_box = driver.find_element(by=By.TAG_NAME, value="input")
#search_box.send_keys("Python编程")
# 方法2:如果页面有多个input,可以用索引
driver.find_elements(by=By.TAG_NAME, value="input")[0].send_keys("Python")
input("看看输入框里是不是有文字了?按回车关闭...")
driver.quit()
2、自动搜索:输入文字并回车
通过配置并启动Edge浏览器驱动并导航至Bilibili网站后,可使用Selenium的find_element方法定位页面的输入框元素,随后调用send_keys方法在其中输入"Python教程"并组合模拟按下回车键(通过Keys.RETURN)以触发搜索。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('http://www.bilibili.com')
# 找到搜索框,输入Python,然后按回车
search_box = driver.find_element(by=By.TAG_NAME, value="input")
search_box.send_keys("Python教程" + Keys.RETURN)
# 等待页面加载
import time
time.sleep(3)
print("搜索完成!页面标题是:", driver.title)
driver.quit()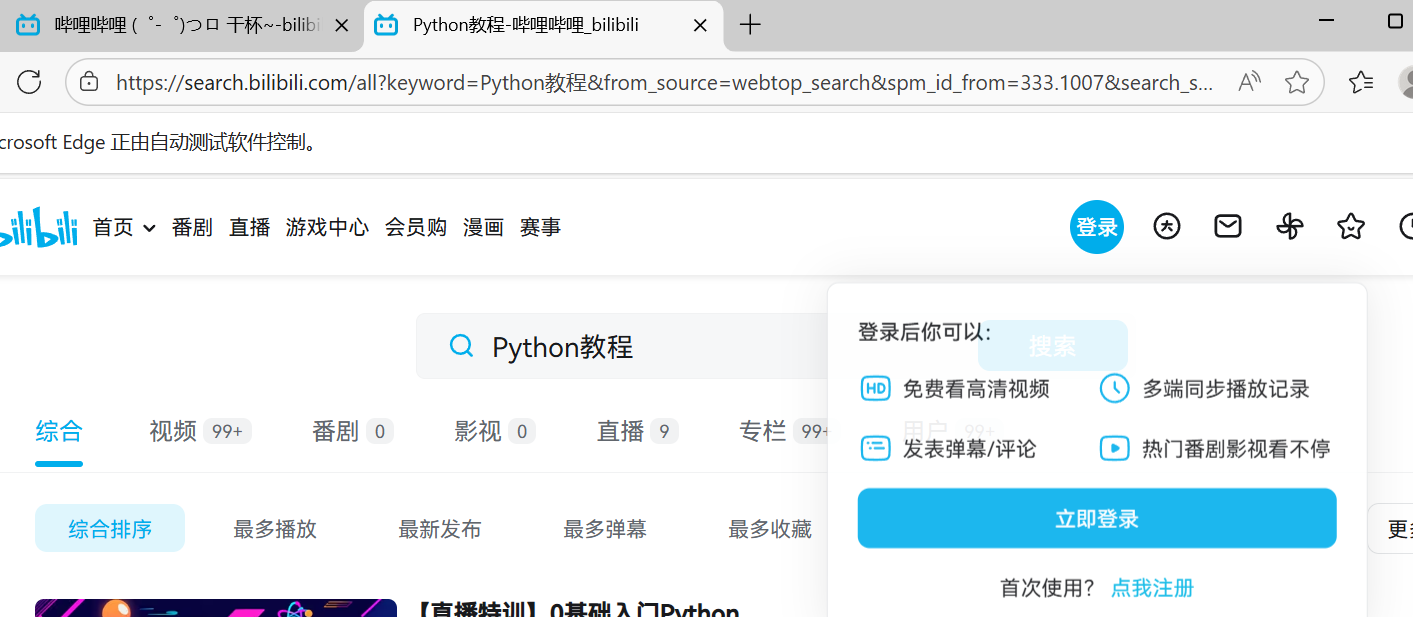
3、上传文件:百度识图
通过配置并启动Edge浏览器驱动并访问百度识图的上传页面后,使用Selenium的find_element方法通过By.NAME定位属性名为file的文件上传输入框元素,随后调用send_keys方法将待上传图片的完整本地路径输入至该元素,从而触发文件上传流程;上传后通过短暂等待确保识别完成,再利用By.CLASS_NAME定位到显示识别结果的元素,获取并打印其文本内容,最后就完成了从网页上传图片到获取识别结果。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://graph.baidu.com/pcpage/index?tpl_from=pc')
# 方法1:通过name属性找到文件上传input
input_element = driver.find_element(by=By.NAME, value="file")
# 输入图片的完整路径(记得改成你自己的图片路径)
input_element.send_keys(r"D:\python\PythonProject1\R-C.jpg")
# 等待识别结果
time.sleep(5)
# 获取识别结果
result_element = driver.find_element(by=By.CLASS_NAME, value="graph-guess-word")
print("百度识图认为这张图片是:", result_element.text)
driver.quit()
五、定位元素大法
1、八大定位方法
八大元素定位方法中,可以通过多种策略精准定位网页上的目标元素:这包括通过唯一标识的ID、通过表单元素的NAME、通过样式的CLASS_NAME、通过HTML标签类型的TAG_NAME、通过精确或部分文本匹配链接的LINK_TEXT与PARTIAL_LINK_TEXT,以及功能强大且灵活的CSS_SELECTOR和XPATH。
# 1. 通过ID定位(最准确,但ID可能动态变化)
# driver.find_element(By.ID, "kw")
# 2. 通过NAME定位
# driver.find_element(By.NAME, "wd")
# 3. 通过CLASS_NAME定位
# driver.find_element(By.CLASS_NAME, "s_ipt")
# 4. 通过TAG_NAME定位(找特定类型的标签)
#search_box = driver.find_element(By.TAG_NAME, "input")
# 5. 通过链接文本定位(精确匹配)
# driver.find_element(By.LINK_TEXT, "新闻")
# 6. 通过部分链接文本定位(模糊匹配)
# driver.find_element(By.PARTIAL_LINK_TEXT, "新")
# 7. 通过CSS选择器定位(最灵活)
# driver.find_element(By.CSS_SELECTOR, "#kw")
# 8. 通过XPath定位(功能最强)
# driver.find_element(By.XPATH, "//input[@id='kw']")2、find_element vs find_elements
find_element 用于定位并返回第一个匹配到的单个元素,若未找到则抛出异常;而 find_elements 则返回所有匹配元素的列表,未找到时返回空列表。例如,在获取百度首页所有链接时,可使用 find_elements 配合 By.TAG_NAME 定位所有 <a> 标签,进而统计链接总数并遍历输出前10个非空文本的链接内容。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.baidu.com')
# 获取百度首页的所有链接
all_links = driver.find_elements(By.TAG_NAME, "a")
print(f"首页共有 {len(all_links)} 个链接")
for i, link in enumerate(all_links[:10]): # 只显示前10个
text = link.text
if text: # 过滤空文本
print(f"{i+1}. {text}")
通过笨重的学习我们就已经掌握了Selenium爬虫的基础知识:Selenium的基本原理和工作方式、如何配置开发环境、八大元素定位方法、与网页的各种交互操作。但记住,爬虫技术就像学游泳------光看教程是不够的,必须亲自实践。从简单的百度搜索开始,慢慢尝试更复杂的网站。