目录
[4.1 MaskDecoder.predict_masks](#4.1 MaskDecoder.predict_masks)
[4.1.2 TwoWayTransformer.forward](#4.1.2 TwoWayTransformer.forward)
[4.1.2.11 TwoWayAttentionBlock.forward](#4.1.2.11 TwoWayAttentionBlock.forward)
[4.1.2.12 self.final_attn_token_to_image------Attention.forward](#4.1.2.12 self.final_attn_token_to_image——Attention.forward)
[attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗](#attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗)
一、前言
下面是第一帧情况下的函数调用顺序。因为文章太长我这边就卡死,所以只能划分很多篇。
2.20 类PromptEncoder.get_dense_pe
2.21 掩码解码器 类MaskDecoder.forward
2.22 类MaskDecoder.predict_masks
2.23 TwoWayTransformer.forward
2.24 TwoWayAttentionBlock.forward(这篇开头在这)
2.25 Attention.forward
2.26 MLP.forward
2.27 Attention.forward(这篇结束在这)
2.28 LayerNorm2d.forward
2.29 MaskDecoder._dynamic_multimask_via_stability
2.30 MaskDecoder._get_stability_scores
2.31 fill_holes_in_mask_scores
2.32 _get_maskmem_pos_enc
2.33 _consolidate_temp_output_across_obj
2.34 _get_orig_video_res_output
四、MaskDecoder.forward
4.1 MaskDecoder.predict_masks
4.1.2 TwoWayTransformer.forward
sam2/modeling/sam/transformer.py
hs, src = self.transformer(src, pos_src, tokens)
上面这句进去就是调用TwoWayTransformer的forward函数。
class TwoWayTransformer(nn.Module):
"""
双向 Transformer:
1. 先让「稀疏点 token」(queries) 与「稠密图像 token」(keys) 做若干层双向 cross-attention;
2. 最后再让 queries 单独对图像做一次 attention,得到增强后的 queries 作为最终输出。
图像 token 只做中间传递,最终原样返回。
"""
def __init__(
self,
depth: int, # 双向 attention block 重复次数
embedding_dim: int, # 通道维度 C
num_heads: int, # 多头注意力的头数
mlp_dim: int, # FFN 中间层维度
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2, # Attention 内部 Q/K 下采样比例
) -> None:
super().__init__()
self.depth = depth # self.depth: 2
self.embedding_dim = embedding_dim # self.embedding_dim: 256
self.num_heads = num_heads # self.num_heads: 8
self.mlp_dim = mlp_dim # self.mlp_dim: 2048
self.layers = nn.ModuleList()
# 堆叠 depth 个双向 attention block
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_dim=mlp_dim,
activation=activation,
attention_downsample_rate=attention_downsample_rate,
skip_first_layer_pe=(i == 0), # 第一层无需给 query 加 PE(已在输入时加好)
)
)
# 最后一层:queries → 图像的 attention
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor, # [B, C, H, W]
image_pe: Tensor, # [B, C, H, W] 图像位置编码
point_embedding: Tensor, # [B, Np, C] 点提示的 embedding(已含 PE)
) -> Tuple[Tensor, Tensor]:
"""
Returns:
processed point embedding [B, Np, C]
processed image embedding [B, H*W, C] (与输入内容相同,仅 reshape)
"""
# image_embedding: torch.Size([1, 256, 64, 64])
# image_pe: torch.Size([1, 256, 64, 64])
# point_embedding: torch.Size([1, 9, 256])
# 1. 把图像展平成 token 序列
bs, c, h, w = image_embedding.shape
# bs:1 c:256 h:64 w:64
image_embedding = image_embedding.flatten(2).permute(0, 2, 1) # [B, H*W, C]
# image_embedding: torch.Size([1, 4096, 256])
image_pe = image_pe.flatten(2).permute(0, 2, 1) # [B, H*W, C]
# image_pe: torch.Size([1, 4096, 256])
queries = point_embedding # [B, Np, C]
# queries: torch.Size([1, 9, 256])
keys = image_embedding # [B, H*W, C]
# keys: torch.Size([1, 4096, 256])
# 2. 逐层双向 attention 更新 queries 和 keys
for layer in self.layers:
# 进入TwoWayAttentionBlock.forward,初始化的时候self.depth:2,所以有两层
# 第一层返回的是:queries:torch.Size([1, 9, 256])
# keys: torch.Size([1, 4096, 256])
# 第二层输入第一层返回的queries和keys 以及:
# point_embedding:torch.Size([1, 9, 256]), 是原始的提示的tokens
# image_pe: torch.Size([1, 4096, 256]), 是原始的图像的位置编码
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding, # 每次把原始 PE 作为 Q 的偏置传进去
key_pe=image_pe,
)
# queries: torch.Size([1, 9, 256])
# keys: torch.Size([1, 4096, 256])
# 3. 最后一层:queries 再对图像做一次 attention
q = queries + point_embedding # 残差加回原始 PE
# q: torch.Size([1, 9, 256])
k = keys + image_pe
# k: torch.Size([1, 4096, 256])
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # [B, Np, C]
# attn_out: torch.Size([1, 9, 256])
queries = queries + attn_out # 残差连接
# queries: torch.Size([1, 9, 256])
queries = self.norm_final_attn(queries) # LayerNorm
# queries: torch.Size([1, 9, 256])
# keys: torch.Size([1, 4096, 256])
# 4. 返回增强后的 queries 和原图 token(下游只拿 queries 用即可)
return queries, keys整体流程一句话总结
"稀疏点 token" 先和"稠密图像 token"在多层的双向 cross-attention 里互相更新;
最后再把更新后的点 token 单独对图像做一次 attention 并残差+Norm,得到最终点特征。
图像 token 只充当信息搬运工,原样返回即可。
2. 逐层双向 attention 更新 queries 和 keys
for layer in self.layers:
进入TwoWayAttentionBlock.forward,初始化的时候self.depth:2,所以有两层
第一层返回的是:queries:torch.Size(1, 9, 256)
keys: torch.Size(1, 4096, 256)
第二层输入第一层返回的queries和keys 以及:
point_embedding:torch.Size(1, 9, 256), 是原始的提示的tokens
image_pe: torch.Size(1, 4096, 256), 是原始的图像的位置编码
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding, # 每次把原始 PE 作为 Q 的偏置传进去
key_pe=image_pe,
)
注意看TwoWayAttentionBlock初始化的时候self.depth:2,所以有两层,第一层我们已经在上一节研究过了,所以我们接下来要进入第二层。但是在第一层的时候我们好像没有关注到下面这两个输入参数
query_pe=point_embedding, # 每次把原始 PE 作为 Q 的偏置传进去
key_pe=image_pe,
这个point_embedding和image_pe是什么东西?
我们回顾一下之前我们画MaskDecoder.predict_masks里面调用transformer之前的那三个输入src, pos_src, tokens,其实这个tokens就是这个point_embedding(点提示嵌入),然后这个image_pe就是把这个pos_src的B, C, H, W变成B, H\*W, C,即1, 256, 64, 64 => 1, 4096, 256,就是图像位置编码
hs, src = self.transformer(src, pos_src, tokens)
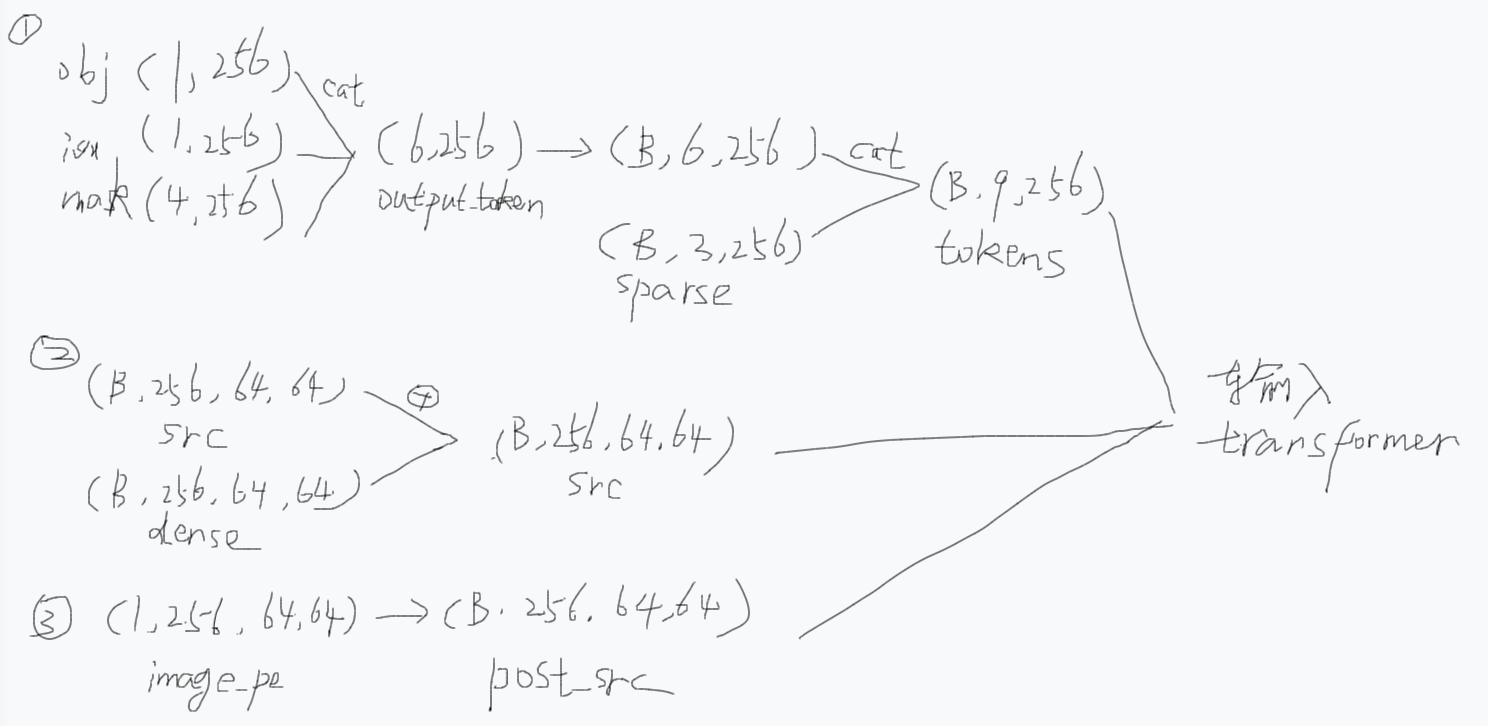
forward里面为什么每次把原始(point_embedding) PE 作为 Q 的偏置传进去,image_pe作为key_pe传进去,是因为在做注意力机制之前要先把位置信息加进去吗?但是image_pe是图像位置编码我理解是有位置信息的,但是point_embedding不就是点提示嵌入向量吗,它也有位置编码吗?
在被不断更新,但它们的位置信息不能丢。
所以每次 attention 前,也要把
image_pe作为key_pe传进去,让 attention 知道每个图像 token 的"空间位置"。
✅ 总结一句话:
point_embedding 和 image_pe 都是「位置编码」,它们分别在 query 和 key 的 attention 计算中作为「位置偏置」被反复使用,因为位置信息是固定的,而 token 表征是不断变化的。
🔍 补充:point_embedding 是怎么来的?
point_embedding 是由「点提示的坐标」经过 `positional_encoding + 内容嵌入」构造出来的,比如:
point_embedding = point_tokens + positional_encoding(xy_coords)所以它已经包含了位置信息,不是纯内容向量。
✅ 小结
变量名 作用 是否包含位置信息 是否随层更新 queries点提示的内容表征 ❌(已剥离) ✅ point_embedding原始点提示(内容+位置) ✅ ❌(固定) keys图像内容表征 ❌(已剥离) ✅ image_pe图像 token 的位置编码 ✅ ❌(固定) 所以每次 attention 前,都要把「固定不变的位置信息」加回去,确保 attention 计算时知道"谁在哪个位置"。
这个地方标记一下,以后要去研究一下(B,9,256)的point_embedding和(B,4096,256]的image_pe它们两个是怎么被构造出来的。其实看上面那张草稿图,我发现其实这个point_embedding源自于transformer的输入变量token,而这个token源自于output_token和sparse_embeddings,这个output_token就是这个点提示的"内容向量",包括一些可学习的语义 token,objectness 打分用的向量obj_score_token、IoU 打分用的向量iou_token、4 个 mask 原型向量,然后这个sparse_embeddings其实就是包含了点提示的"位置信息"(翻前面的文章就知道它融入了位置信息)。至于这个image_pe是PromptEncoder.get_dense_pe(以后要看看这个怎么搞的)来的。
可学习的语义 token 跟 SAM2 根据提示预测出掩码有什么联系呢?就是这是怎么做到的?
一句话先给结论:
「可学习 token」并不是直接"变成"掩码,而是先被当成一组"空白支票"送进 Transformer,让它在图像里找到对应区域,再靠一个小网络把每张支票兑现成掩码、IoU 或 objectness 分数 。
整个过程可以看成三步:
发空白支票(初始化 token)
兑现支票(Transformer 把支票填上"区域信息")
银行取钱(轻量级 MLP 把填好的支票换成掩码/分数)
下面把 SAM 2 的 Prompt Encoder → Mask Decoder 链路拆开讲,你就明白"可学习 token"到底怎么跟提示、跟掩码挂上钩。
发空白支票:token 的语义角色
可学习 token 只有 256-d,数量固定:
1 个 obj_score_token → 负责"这里到底有没有东西"
1 个 iou_token → 负责"我预测的掩码质量多高"
4 个 mask_tokens → 负责"我要生成 4 张不同粒度的掩码原型"
这些向量一开始完全不知道用户点了哪,它们只是"占位符",等 Transformer 去填内容。
- 兑现支票:Two-Way Transformer 填内容
把 6 个 token(或 9 个,如果拼上 3 个用户点)和 4096 个图像 token 一起送进 TwoWayTransformer:
Query:空白支票 token(或加了用户点坐标的 token)
Key / Value:图像 token(来自 image encoder,已经带全局语义)
经过 2 层双向 cross-attention 后,每张"空白支票"都被图像信息填上了"对应区域"的上下文特征 。
此时 token 的 256-d 向量里已经隐式编码了"用户到底想选哪一块"。
银行取钱:轻量级 MLP 换成掩码 / 分数
取出填好的支票
hs = transformer_output[:, s:, :] # 去掉 obj_score_token 的话就是 [B, 5, 256]
3.1 生成 4 张掩码原型(每张 256-d)
mask_embed = self.mask_embed(hs) # 线性层 [B, 4, 256] → [B, 4, 256]
3.2 与 image embedding 做点积得到 4 张 64×64 掩码
masks = torch.einsum('bqc,bchw->bqhw', mask_embed, image_embedding)
3.3 预测 IoU 分数
iou_pred = self.iou_token_head(hs) # [B, 4]
3.4 预测 objectness 分数(可选)
obj_pred = self.obj_score_token_head(hs[:, 0:1, :]) # [B, 1]
mask_embed 就是"填好区域信息"的 4 个 token 再经过一个小 MLP,得到 4 条 256-d 向量。
把这 4 条向量与 64×64×256 的图像特征图做点积,就得到 4 张 64×64 的掩码 logits(再上采样到 256×256)。
IoU / objectness 头同理:用同一组 token 再各接一个线性层,直接回归数值。
- 提示(点/框/掩码)到底起了什么作用?
如果用户给了点/框 ,它们的坐标会先被转成 256-d 位置编码,跟"空白支票"拼在一起送进 Transformer。
→ 相当于在支票上提前写好了"大概区域",Transformer 填内容时更容易聚焦。
如果完全不给提示(自动模式),SAM 2 会把 N 组"空白支票"均匀撒在图像上,靠 objectness 分支选出最有物体的 K 组,再生成掩码。
一张图总结
用户提示坐标
│
▼
positional encoding ─────┐
▼
learnable tokens ──► TwoWayTransformer ──► token 已带"区域上下文"
▼
mask_embed MLP → 4×256-d 向量
▼
与 image embedding 点积 → 4 张 64×64 掩码 logits
▼
上采样 → 256×256 最终掩码所以------
"可学习 token"只是提供了一组"可以任意书写"的语义槽位;真正决定掩码长什么样的是 Transformer 把图像信息写进这些槽位的过程。
4.1.2.11 TwoWayAttentionBlock.forward
sam2/modeling/sam/transformer.py
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
一个 Transformer 块,内部 4 步:
1) sparse queries 自注意力
2) queries cross-attend 到 dense keys(token→image)
3) 对 queries 做 MLP
4) dense keys cross-attend 到 sparse queries(image→token)
通过双向交叉,实现"稀疏点"与"稠密图"信息互通。
"""
super().__init__()
# 1. 自注意力
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
# 2. token→image 交叉注意力
# 又进入TwoWayAttentionBlock.forward
# attention_downsample_rate:2
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
# 3. MLP
self.mlp = MLP(
embedding_dim, mlp_dim, embedding_dim, num_layers=2, activation=activation
)
self.norm3 = nn.LayerNorm(embedding_dim)
# 4. image→token 交叉注意力
self.norm4 = nn.LayerNorm(embedding_dim)
# attention_downsample_rate:2
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe # 首块是否给 Q 加 PE
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# 输入形状示例:
# queries: torch.Size([1, 9, 256]) 稀疏点 token
# keys: torch.Size([1, 4096, 256]) 稠密图像 token
# query_pe:torch.Size([1, 9, 256]) 稀疏点token的绝对位置编码
# key_pe:torch.Size([1, 4096, 256]) 稠密图像token的绝对位置编码
# ---------- 1. 自注意力 ----------
# 第二层 self.skip_first_layer_pe: False
if self.skip_first_layer_pe: # 首层不加 PE,直接 self-attn
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe # 残差加 PE
# q: torch.Size([1, 9, 256])
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out # 残差连接
queries = self.norm1(queries) # [B, 9, 256]
# queries: torch.Size([1, 9, 256])
# ---------- 2. token→image 交叉注意力 ----------
q = queries + query_pe # 给 query 加 PE
# q: torch.Size([1, 9, 256])
k = keys + key_pe # 给 key 加 PE
# k: torch.Size([1, 4096, 256])
# q: torch.Size([1, 9, 256])
# k: torch.Size([1, 4096, 256])
# keys: torch.Size([1, 4096, 256])
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) # 下采样在内部完成
# attn_out: torch.Size([1, 9, 256])
queries = queries + attn_out # 残差
# queries: torch.Size([1, 9, 256])
queries = self.norm2(queries) # [B, 9, 256]
# queries: torch.Size([1, 9, 256])
# ---------- 3. MLP ----------
mlp_out = self.mlp(queries)
# mlp_out: torch.Size([1, 9, 256])
queries = queries + mlp_out # 残差
# queries: torch.Size([1, 9, 256])
queries = self.norm3(queries) # [B, 9, 256]
# queries: torch.Size([1, 9, 256])
# ---------- 4. image→token 交叉注意力 ----------
# 注意:这里"角色互换"------用图像 token 做 Q,去 attend 稀疏点
q = queries + query_pe # 稀疏点继续当"被 attend"的 K/V
# q: torch.Size([1, 9, 256])
k = keys + key_pe # 图像当 Q
# k: torch.Size([1, 4096, 256])
# v: torch.Size([1, 9, 256])
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries) # 形状 [B, 4096, 256]
# attn_out: [1, 4096, 256]
# keys: torch.Size([1, 4096, 256])
keys = keys + attn_out # 残差更新图像 token
# keys: torch.Size([1, 4096, 256])
keys = self.norm4(keys) # [B, 4096, 256]
# queries: torch.Size([1, 9, 256]) 经过归一化数值在(-1,1)
# keys: torch.Size([1, 4096, 256]) 经过归一化数值在(-1,1)
# 返回更新后的 (queries, keys),供下一层或下游使用
return queries, keys总结
稀疏点先 self-attn,增强自身上下文。
再把增强后的点去 attend 图像,提取对应位置特征。
过一遍 MLP,进一步非线性变换。
最后让图像 token 反过来看这些点,把"哪些区域有点"信息写回图像特征。
于是"点"与"图"完成一次双向融合,形状全程保持不变:
queries 始终 B, Np, C,keys 始终 B, H·W, C。
接下来我们继续看第二层发生了什么,第二层的queries和keys是来自于第一层的输出,然后query_pe和key_pe是原始的位置编码。为什么要搞两层?为什么第一层的输出是第二层的输入
「为什么要堆两层 TwoWayAttentionBlock?」------ 一句话:
一层只能完成"点⇄像"的一次握手,两层才能让信息在"点-像-点-像"之间来回打磨,最终让稀疏 token 真正吸收整图上下文,也让图像 token 被稀疏提示充分修正。下面把"第一层输出当第二层输入"这件事拆开说,你就能看到第二层到底多干了什么。
- 第一层:粗对齐------"谁对谁感兴趣"
Query:9 个稀疏 token(带初始 PE)
Key/Value:4096 个图像 token(带初始 PE)
经过
① 自注意力 → ② token→image 交叉 → ③ MLP → ④ image→token 交叉
得到
queries₁ :每个稀疏 token 已经"看"过全图,但只是粗略地把整图信息平均到自己身上。
keys₁ :每个图像 token 被稀疏提示"刷"了一次,但只被刷了一次,还可能残留大量与提示无关的噪声。
此时如果直接拿去解码,mask 边缘往往很毛糙,因为
稀疏 token 只做了"单向"吸收,还没把精细的空间细节再反哺给自己;
图像 token 也只被"刷"了一次,还没被二次修正。
2. 第二层:精打磨------"把第一次对齐后的结果再互刷一次"
把 queries₁、keys₁ 当成新的 Q/K/V,再用同一套规则玩一遍,差异在于:
步骤 第一层输入 第二层输入 第二层多得到什么 自注意力 初始 token 已带粗图像信息的 token token 之间能根据图像上下文重新投票("我这点其实和旁边那点应该更一致") token→image 初始 PE 已修正一次的图像 keys₁ 第二次 attend 时,图像 keys₁ 已经把"无关区域"降权,稀疏 token 拿到的上下文更纯净 image→token 初始图像 token 已被稀疏提示刷过一次的 keys₁ 图像 token 再次被稀疏提示修正,空间一致性更好,边缘更锐 形象比喻:
第一层 = 第一次见面交换名片,知道"大概谁对谁有用";
第二层 = 第二次见面,把名片更新后再交换,只保留真正有用的关系,去掉第一次的误会。
3. 为什么不能再多堆 N 层?
实验上 2 层是 sweet spot(SAM/SAM2 论文都报告了 2 层 > 1 层 >> 3 层)。
再加深会过拟合,且显存线性增长;2 层已让"点-像"双向信息充分回流。
4. 小结一句话
第一层让"点"与"像"互相看见,第二层用"已经互相看见过的"点/像再互相看见一次,从而把第一次的噪声去掉、把边缘对齐、把上下文细化。
所以第一层输出必须作为第二层输入------因为第二层要的是"已对齐一次"的表征,而不是从头再来。
TwoWayTransformer.forward里面,第二层 self.skip_first_layer_pe: False,与第一层不同了,第二层自注意力之前并没有直接把第一层输出的queries拿来做自注意力,而是先加了原始的query_pe,然后再进自注意力,然后输出attn_out之后再加回queries做残差连接,为什么?
(猜测:可能是第一层的时候其实那个queries就是点提示嵌入,那个已经加了sparse_embeddings了,所以有位置编码,所以第一层不用加位置编码了,第二层因为拿到的第一层的queries是经过残差连接的,似乎这样就丢失了原始的位置编码,所以第二层要加回来才能进行自注意力机制。但是为什么第一层自注意力机制不做残差连接,第二层却要呢?)
这里感觉不太清楚,标记一下
猜测(只能猜,代码没注释)
第一层输入的
queries已经是 "内容+位置"的混合体 (PromptEncoder 把坐标编码拼进去了),信息足够完整,作者可能想让 自注意力一次性重排 token,而不是"保留旧值"。
实验上发现 第一层不加残差反而收敛更快 / 精度更高,于是把残差留给了第二层及以后。
第二层 self.skip_first_layer_pe: False
if self.skip_first_layer_pe: # 首层不加 PE,直接 self-attn
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe # 残差加 PE
q: torch.Size(1, 9, 256)
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out # 残差连接
一句话:
第二层已经不是"第一层"了,skip_first_layer_pe 只给第一个 block 用;从第二层开始,自注意力之前必须把位置信息重新"插"回去,否则 token 之间会丢失"谁是谁"的几何坐标,导致自注意力瞎分组。
- 先回忆 skip_first_layer_pe 的语义
(在TwoWayTransformer的初始化里面的创建TwoWayAttentionBlock)
# 只在 TwoWayTransformer 的第一个 block 为 True skip_first_layer_pe = (i == 0)
True :输入的 queries 里已经带 PE (PromptEncoder 把坐标编码拼进去了),不用再额外加,否则位置会被加两次。
False :输入的 queries 是上一层 Transformer 输出的"纯内容向量" ,位置信息被剥离了,必须重新加一次 PE,才能让自注意力知道"我在哪"。
1.第一层输出到底是什么?
经过第一次 TwoWayAttentionBlock 后:
queries₁ = LayerNorm( content₀ + MLP( CrossAttn→Image( SelfAttn( content₀ + PE₀ ) ) ) )
content₀:初始可学习 token + 用户坐标 token(已不含 PE,因为残差后 PE 被减掉)
PE₀ :原始坐标编码,固定不变 ,不参与梯度更新
也就是说,queries₁ 里已经没有 PE 了,只有"被图像上下文更新过的内容"。
2. 第二层自注意力之前不加 PE 会怎样?
9 个 token 完全不知道自己在图像的哪个位置,
自注意力只能根据"内容相似度"瞎分组,
结果:边缘对齐、实例区分度下降,mask 边缘变毛。
3.所以第二层必须重新加 PE
q = queries₁ + query_pe # 把固定坐标重新插回去 attn_out = self_attn(q, q, queries₁) queries₂ = queries₁ + attn_out
query_pe 依旧是初始坐标编码 ,固定、不参与梯度,确保几何位置始终正确。
这样自注意力既能利用"更新后的内容",又能看见"原始几何",才能把同类点聚到一起、把异类点分开。
4.一句话总结
第一层输出是"去掉了位置的纯内容",第二层若不再把位置插回去,自注意力就迷路;因此从第二层开始,每次自注意力前都必须重新加回原始 query_pe。
所以说第二层跟第一层除了那个self.skip_first_layer_pe不同以外,其他好像都是一样的。所以我们就不进自注意力和交叉注意力的函数里面看了(我看过了,是一样的)
4.1.2.12 self.final_attn_token_to_image------Attention.forward
我们看看TwoWayTransformer.forward里面,在经历了两层之后输出的queries和keys又做了残差连接,然后attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys),这个进去也是Attention.forward,我进去调试过,跟token->image时候的
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)一模一样,所以不用看了,只是要知道为什么最后又要搞一次交叉注意力。
queries: torch.Size(1, 9, 256)
keys: torch.Size(1, 4096, 256)
3. 最后一层:queries 再对图像做一次 attention
q = queries + point_embedding # 残差加回原始 PE
q: torch.Size(1, 9, 256)
k = keys + image_pe
k: torch.Size(1, 4096, 256)
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # B, Np, C
attn_out: torch.Size(1, 9, 256)
queries = queries + attn_out # 残差连接
queries: torch.Size(1, 9, 256)
queries = self.norm_final_attn(queries) # LayerNorm
queries: torch.Size(1, 9, 256)
4. 返回增强后的 queries 和原图 token(下游只拿 queries 用即可)
return queries, keys
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) 为什么最后一层:queries 再对图像做一次 attention,token到image,image到token双向注意力还不够吗
这个问题有点复杂,下一节再看
queries = self.norm_final_attn(queries) 这句是TwoWayTransformer初始化中:
self.norm_final_attn = nn.LayerNorm(embedding_dim)
标记一下,因为类初始化在调试中被我跳过了,所以说看不了里面,以后再研究这个。
self.norm_final_attn(queries)内部只做了一件事:
Layer Normalization(层归一化) ,和你在 Transformer 里见到的nn.LayerNorm完全一样。
具体步骤(单条样本视角,维度 C=256)
输入:
queries形状[Np, C],例如[9, 256]
沿着最后一维(通道维)计算
均值
μ = 1/C · Σx_i方差
σ² = 1/C · Σ(x_i -- μ)²归一化
x̂ = (x -- μ) / √(σ² + ε),ε默认1e-5可学习的仿射变换
y = γ ⊙ x̂ + β,其中
γ、β都是长度为C的向量,和输入通道数相同,训练时一起更新。输出:
同样形状
[Np, 256],但数值分布已经被重新拉回到零均值、单位方差,再乘加学习到的尺度/偏置。