原理:
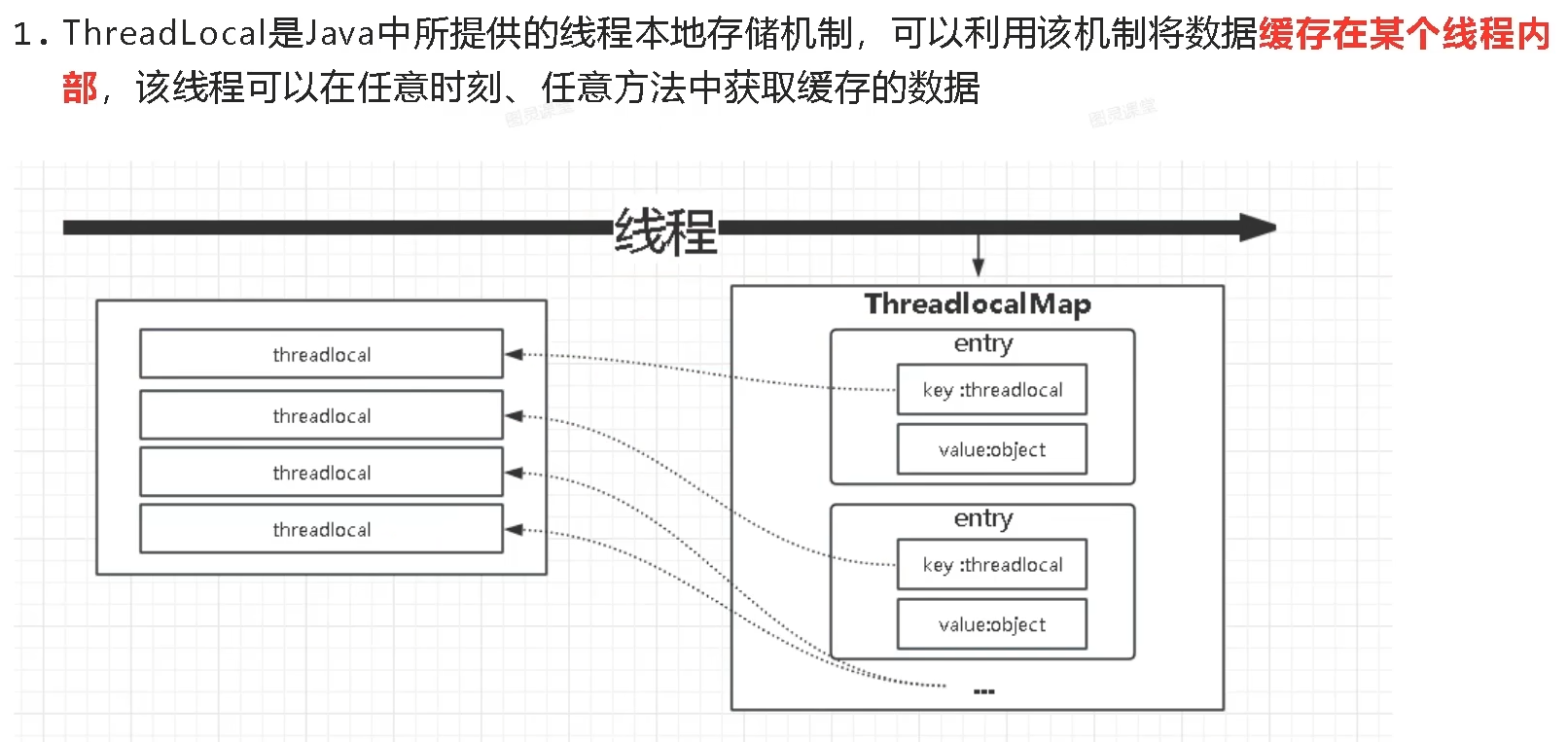

每一个Thread对象中都存在着一个ThreadLocalMap,key为threadlocal对象,value为需要缓存的值,可以简单的理解为threadlocal是一个操作线程中ThreadLocalMap的一个工具类。

在线程第一次使用threadlocal时,创建一个threadlocalmap。
索引如何计算的呢,每创建一个新的threadlocal对象,初始为0,然后加一个特别大的整数作为hash值,然后计算桶下标。
扩容:在元素数量大于数组长度的3分之2时,扩容2倍。索引冲突不同于hashmap,使用的开放寻址法,找下一个空闲的位置,放入。
1.为什么ThreadLocal的key要设计成弱引用?而value不设计成弱引用呢?
- 当开发者使用
ThreadLocal<String> tl = new ThreadLocal<>();后,若tl被置为null(不再使用),此时:
- 如果 ThreadLocalMap 的 key 是强引用:key 会一直引用 ThreadLocal 对象,导致 ThreadLocal 无法被 GC 回收,进而导致 ThreadLocalMap 中对应的 key-value 永远存在(线程存活时),引发内存泄漏。
- 如果 key 是弱引用 :当
tl被置为null后,ThreadLocal 对象没有其他强引用,GC 会回收 ThreadLocal,此时 ThreadLocalMap 中的 key 会变成null,后续可以通过 "清理机制"(比如调用get()/set()/remove()时)移除这些null key对应的 entry,缓解内存泄漏。- value 是强引用,是为了保证 ThreadLocal 存储的数据在 "线程未结束、ThreadLocal 未被回收" 时的有效性 。
- ThreadLocal 的核心作用是 "为线程存储私有数据",如果 value 是弱引用,当外部没有其他强引用指向 value 时,GC 会直接回收 value,导致线程还在运行时,无法获取到原本存储的数据(数据提前丢失),违背了 ThreadLocal 的设计初衷。
- 当然,value 是强引用也会带来风险:如果 ThreadLocal 被回收(key 变成
null),但线程还存活,value 会因为被 ThreadLocalMap 强引用而无法被回收,此时需要主动调用remove()清理 value,否则仍会内存泄漏(这也是为什么建议使用 ThreadLocal 后主动调用remove()的原因)。后面会讲值释放的时机
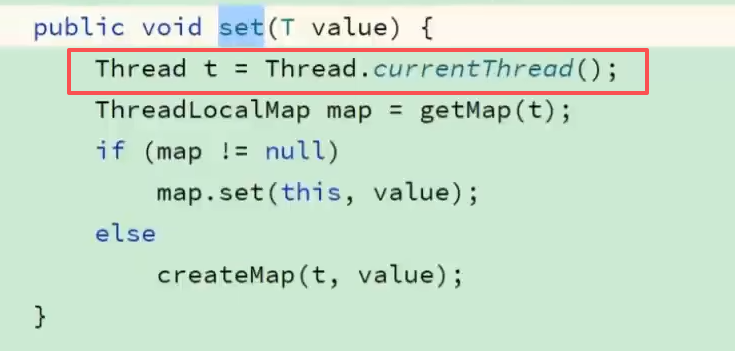
2.get方法
当get时发现key为null了,顺手将值清理,然后放一个key进去(get的key是啥就放啥)
3.set方法
会使用启发式扫描,清除临近的null key,启发次数与元素个数有关,与是否发现null key有关。
不会不清理也不会全清理
3.remove方法
一般我们使用ThreadLocal都是用static修饰,就算Entry中的ThreadLocal是一个弱引用,但是静态变量对它是一个强引用。所以我们需要调用remove方法,自己用了threadlocal,肯定知道什么时候不用了,不依赖于垃圾回收或者别的清理,自己手动将其remove掉。
应用场景
ThreadLocal 核心价值是为每个线程提供独立的变量副本,让线程间数据隔离、线程内数据共享,避免多线程并发问题的同时简化数据传递。以下是它最核心、最常见的应用场景,附具体使用逻辑和示例:
一、核心应用场景(高频)
1. 存储线程私有上下文(最经典)
场景 :Web 开发中存储「当前登录用户信息」「请求 ID」「租户 ID」等,避免在方法间层层传递参数。原理 :每个请求由独立线程处理,ThreadLocal 存储当前请求的上下文,任意业务方法可直接获取,无需透传。示例:
java
// 上下文工具类
public class UserContextHolder {
// 存储当前登录用户ID
private static final ThreadLocal<Long> USER_ID = new ThreadLocal<>();
// 存储请求追踪ID
private static final ThreadLocal<String> REQUEST_ID = new ThreadLocal<>();
// 设置用户ID
public static void setUserId(Long userId) {
USER_ID.set(userId);
}
// 获取用户ID
public static Long getUserId() {
return USER_ID.get();
}
// 必须手动清理,避免内存泄漏
public static void remove() {
USER_ID.remove();
REQUEST_ID.remove();
}
}
// 拦截器中设置上下文(Spring MVC示例)
public class UserInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// 从Token解析用户ID
Long userId = parseUserIdFromToken(request.getHeader("Token"));
UserContextHolder.setUserId(userId);
UserContextHolder.setRequestId(UUID.randomUUID().toString());
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
// 请求结束后清理,关键!
UserContextHolder.remove();
}
}
// 业务层直接获取,无需参数传递
@Service
public class OrderService {
public void createOrder() {
Long currentUserId = UserContextHolder.getUserId();
String requestId = UserContextHolder.getRequestId();
// 业务逻辑...
}
}2. 解决线程不安全的工具类问题
场景 :使用非线程安全的工具类(如 SimpleDateFormat、Random),避免多线程共享导致的并发错误。
原理 :每个线程持有独立的工具类实例,无需加锁,性能优于 synchronized。示例:
java
// 替代共享的SimpleDateFormat,避免线程安全问题
public class DateUtils {
// 每个线程独立的DateFormat实例
private static final ThreadLocal<SimpleDateFormat> DATE_FORMATTER =
ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
public static String format(Date date) {
return DATE_FORMATTER.get().format(date);
}
public static Date parse(String dateStr) throws ParseException {
return DATE_FORMATTER.get().parse(dateStr);
}
}3. 数据库连接 / 事务管理
场景 :数据库连接池分配连接时,为每个线程绑定独立的连接,保证事务的原子性(如 JDBC 手动事务、MyBatis 事务)。原理 :线程内的所有数据库操作共用同一个连接,提交 / 回滚时统一处理,避免跨线程混用连接。简化示例:
java
public class ConnectionHolder {
private static final ThreadLocal<Connection> CONN_HOLDER = new ThreadLocal<>();
// 数据库连接池
private static final DataSource DATA_SOURCE = getDataSource();
// 获取当前线程的连接(无则创建)
public static Connection getConnection() {
Connection conn = CONN_HOLDER.get();
if (conn == null) {
conn = DATA_SOURCE.getConnection();
CONN_HOLDER.set(conn);
}
return conn;
}
// 提交事务并释放连接
public static void commit() {
Connection conn = CONN_HOLDER.get();
if (conn != null) {
try {
conn.commit();
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
CONN_HOLDER.remove();
}
}
}
// 回滚事务
public static void rollback() {
// 逻辑类似...
}
}数据库连接池并非 "必须" 用 ThreadLocal,但结合 ThreadLocal 是实现 "线程绑定连接" 的最优方案 ------ 核心目的是让「同一个线程内的所有数据库操作复用同一个连接 」,保证事务原子性、避免连接混乱,同时简化连接的获取 / 释放逻辑。
1.先明确核心诉求:为什么要给线程绑定连接?
数据库事务的核心要求是:同一个事务内的所有操作(增删改)必须用同一个数据库连接,否则事务无法保证原子性(比如一个操作在连接 A 提交,另一个在连接 B 回滚)。
如果没有 ThreadLocal,直接从连接池拿连接会出现两个问题:
- 线程内多次操作可能拿到不同连接 → 事务失效;
- 需手动传递连接对象(比如在方法参数里传 Connection)→ 代码耦合度极高。
2.ThreadLocal 适配连接池的核心价值
ThreadLocal 为 "线程 - 连接" 提供了无侵入的绑定能力,完美解决上述问题,具体体现在 3 个方面:
1. 保证线程内连接唯一性(事务的基础)
先搞懂:增删改为什么必须要 Connection?
数据库的所有操作(查 / 增 / 删 / 改)本质都是通过「数据库连接(Connection)」和数据库交互------Connection 就像你和数据库之间的 "专属电话线":
- 执行查询:
conn.createStatement().executeQuery("select * from user")→ 靠这条 "电话线" 把 SQL 发过去,结果传回来; - 执行增删改:
conn.createStatement().executeUpdate("insert into order ...")→ 同样要靠这条 "电话线" 发指令。
尤其是增删改通常要在「事务」中执行(比如创建订单时,要扣库存 + 加订单,要么都成、要么都败),而事务是「绑定在 Connection 上」的:
- 你调用
conn.setAutoCommit(false)开启手动事务后,这个 Connection 上的所有操作都会归到同一个事务里; - 只有调用
conn.commit()/conn.rollback(),才能提交 / 回滚这个 Connection 上的所有增删改操作。
再搞懂:为什么会被迫层层传递 Connection?
假设你不用 ThreadLocal,要保证 "创建订单" 的事务原子性(扣库存 + 加订单用同一个 Connection),代码会写成这样:
java
// Service层:创建订单(需要事务)
public class OrderService {
@Autowired
private OrderDAO orderDAO;
@Autowired
private StockDAO stockDAO;
public void createOrder(Order order) {
// 1. 先从连接池拿一个Connection(事务的核心载体)
Connection conn = ConnectionPool.getConnection();
try {
conn.setAutoCommit(false); // 开启手动事务
// 2. 扣库存:必须把这个conn传给DAO,否则DAO会自己拿新连接
stockDAO.reduceStock(conn, order.getGoodsId());
// 3. 加订单:同样要传这个conn,保证和扣库存用同一个连接
orderDAO.addOrder(conn, order);
conn.commit(); // 事务提交
} catch (Exception e) {
conn.rollback(); // 事务回滚
} finally {
conn.close(); // 归还连接到池
}
}
}
// DAO层:扣库存(必须接收上层传的conn)
public class StockDAO {
public void reduceStock(Connection conn, Long goodsId) throws SQLException {
// 用上层传的conn执行SQL,而不是自己拿新连接
String sql = "update stock set num = num -1 where goods_id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setLong(1, goodsId);
ps.executeUpdate();
}
}
// DAO层:加订单(同理)
public class OrderDAO {
public void addOrder(Connection conn, Order order) throws SQLException {
// 必须用同一个conn执行SQL
String sql = "insert into order (id, goods_id) values (?, ?)";
PreparedStatement ps = conn.prepareStatement(sql);
// ... 赋值+执行
}
}核心痛点:如果不用 ThreadLocal,要保证事务内的所有操作共用一个 Connection,就必须把 Connection 作为参数,从 Service→DAO1→DAO2 层层传递 ------ 代码又丑又耦合,一旦漏传,DAO 就会自己从连接池拿新连接,事务直接失效(扣库存成功、加订单失败,数据不一致)。
用 ThreadLocal 后的对比(不用传参):
java
// Service层:不用传Connection,ThreadLocal自动绑定
public void createOrder(Order order) {
Connection conn = ConnectionManager.getCurrentConn(); // 从ThreadLocal拿
try {
stockDAO.reduceStock(order.getGoodsId()); // 不用传conn!
orderDAO.addOrder(order); // 不用传conn!
conn.commit();
} catch (Exception e) {
conn.rollback();
} finally {
ConnectionManager.remove(); // 清空ThreadLocal
}
}
// DAO层:直接从ThreadLocal拿conn,不用接收参数
public class StockDAO {
public void reduceStock(Long goodsId) throws SQLException {
Connection conn = ConnectionManager.getCurrentConn(); // 从ThreadLocal拿
// ... 执行SQL
}
}2. 适配线程池,避免连接混用
实际项目中,Web 请求 / 业务任务通常由线程池处理(比如 Tomcat 线程池):
- ThreadLocal 天然隔离线程池中的不同线程,每个线程只能拿到自己绑定的连接;
- 即使线程复用,只要在任务结束后调用
remove()清空 ThreadLocal,就不会出现 "线程 A 拿到线程 B 的连接" 的问题。
先补前提:线程池的核心特点是 "复用线程"(比如 Tomcat 线程池创建 10 个线程,处理 100 个请求,每个线程会被重复用 10 次)。
先想:没有 ThreadLocal,线程池会出什么问题?
假设你用一个全局 Map 存 "线程 - 连接",代码如下:
java
// 全局Map:线程→连接(不用ThreadLocal的反面例子)
private static Map<Thread, Connection> THREAD_CONN_MAP = new HashMap<>();
// 获取连接
public static Connection getConn() {
Thread currentThread = Thread.currentThread();
// 如果当前线程没有绑定连接,从池里拿一个
if (!THREAD_CONN_MAP.containsKey(currentThread)) {
Connection conn = ConnectionPool.getConnection();
THREAD_CONN_MAP.put(currentThread, conn);
}
return THREAD_CONN_MAP.get(currentThread);
}坑来了 :线程池中的线程 A 处理完请求 1 后,会被放回池里,接着处理请求 2。如果没清空THREAD_CONN_MAP里的 "线程 A - 连接 1",那么:
- 请求 2 用线程 A 处理时,会拿到请求 1 的连接 1 → 相当于 "线程 A(请求 2)拿到了请求 1 的连接",如果请求 1 的事务还没提交,请求 2 的操作会混入请求 1 的事务,导致数据错乱。
再看:ThreadLocal 为什么能适配线程池?
ThreadLocal 的核心特性是:每个线程有独立的变量副本,线程之间完全隔离,且 "线程级别的隔离" 和 "线程是否复用" 无关。
举个 Tomcat 线程池的实际例子:
- 线程池初始化 10 个线程(线程 1~ 线程 10);
- 请求 1 过来 → 分配线程 1 → ThreadLocal 为线程 1 绑定连接 1;
- 请求 1 处理完 → 调用
ThreadLocal.remove()→ 线程 1 的 Connection 副本被清空; - 线程 1 回到线程池,处理请求 2 → ThreadLocal 为线程 1 重新绑定连接 2(和连接 1 无关);
- 线程 2 处理请求 3 → ThreadLocal 为线程 2 绑定连接 3,线程 1 和线程 2 的副本互不干扰。
关键逻辑:
- 线程复用只是 "线程对象被重复使用",但 ThreadLocal 给每个线程维护的副本是 "跟着线程走的",线程 1 的副本永远只属于线程 1,线程 2 拿不到;
- 只要在请求 / 任务结束时调用
remove(),就能清空当前线程的副本,避免下一次复用线程时,拿到上一次的连接。
一句话总结:
线程池的问题是 "线程会被复用,容易混用上一次的连接";ThreadLocal 的优势是 "线程内副本隔离 + 手动 remove 清空",既保证同一个线程内的连接唯一,又避免线程复用时的连接混用。
3.关键注意点:ThreadLocal 不是连接池的 "必须项",但却是 "最优项"
- 不用 ThreadLocal 也能实现线程绑定连接(比如手动维护一个
Map<Thread, Connection>),但:Map需加锁保证线程安全,性能低于 ThreadLocal(ThreadLocal 无锁);Map无法自动感知线程销毁,容易导致连接泄漏;- 代码复杂度远高于 ThreadLocal。
- 只有 "无需事务的简单查询"(每次拿连接、用完就还),可以直接从连接池拿连接而不用 ThreadLocal------ 但这类场景只是少数。
总结
数据库连接池 + ThreadLocal 的组合,是 **"连接复用(池)" + "线程内连接唯一(ThreadLocal)"** 的黄金搭配:
- 连接池解决 "连接创建 / 销毁开销大" 的问题;
- ThreadLocal 解决 "线程内连接统一、事务原子性、代码解耦" 的问题。
这也是 Spring 事务管理(@Transactional)的底层核心逻辑 ------Spring 正是通过 ThreadLocal 将 Connection 绑定到当前线程,保证事务内所有操作复用同一个连接。
二、扩展场景(偏进阶)
- 日志追踪:存储线程级的日志上下文(如 traceId、spanId),让全链路日志能关联到同一个请求;
- 缓存隔离:为每个线程维护独立的本地缓存(区别于全局缓存),适用于线程内短期复用的数据;
- 测试框架:单元测试中隔离不同测试用例的线程变量,避免测试数据互相干扰。
三、使用注意事项(必看)
- 必须手动清理 :线程池复用线程时,ThreadLocal 中的数据不会自动清空,需在任务结束后调用
remove(),否则会导致内存泄漏或数据错乱; - 避免存储大对象:每个线程都持有副本,大对象会占用大量内存;
- 不依赖 ThreadLocal 传参:核心业务逻辑尽量通过方法参数传递,ThreadLocal 仅用于上下文类数据,降低耦合。