凌晨三点的告警电话刺耳地响起,屏幕上一片飘红的性能指标让DBA(数据库管理员)瞬间清醒,又一个不眠之夜在"救火"中开始了------这种场景曾是DBA工作的日常。
深夜的"救火"场景,本质是传统被动响应运维模式的真实写照。DBA日常的绝大部分精力都被这些突发故障和临时告警所占据,而用于前瞻性优化和架构升级的时间所剩无几。
随着企业数字化转型进入深水区,数据库规模和复杂度呈现爆炸式增长,一套涵盖**"全链路采集、自动化监控与巡检、智能诊断、持续优化"**的完整体系,正将数据库运维从"被动响应"推向"主动预防"的新阶段。
演进历程,数据库运维的时代变局
运维模式的变迁,直接反映了企业数据架构的进化轨迹。早期的数据库运维常常依赖于脚本堆砌和人工值守,运维人员像是全天待命的"救火队员"。他们需要手动登录各个数据库实例,执行重复的检查命令,分析杂乱的日志文件。一旦遇到数据库性能下降或故障,往往需要耗费数小时甚至更长时间进行排查和恢复。
随着业务系统微服务化和分布式架构的普及,加之信创政策的落地,数据库环境变得异常复杂。企业往往同时运行着Oracle、DB2、SQL Server以及各类国产和开源数据库,形成异构混合的数据库环境。传统人工值守的运维方式已无法适应这种规模与复杂度的双重挑战。一项业内调研显示,大型企业平均需要管理超过50套数据库实例,而专职DBA的比例却在下降。
算经济账,被动响应模式的成本也在日益凸显:平均每次严重数据库故障导致业务中断的损失都会达到十几万甚至几十万元,而故障排查和恢复的平均时间至少需要数个小时。
正是在这样的背景下,以云和恩墨为代表的数据库生态软件厂商开始推出zCloud、Bethune X等具备多元异构数据库监控巡检能力的工具产品,通过技术手段将资深DBA的经验转化为系统能力,推动运维模式从"被动响应"向"主动预防"的根本转变。
环节一: 全链路采集,构建运维的感知神经网络
全链路数据采集是智能运维的基石,如同为数据库系统安装了一套精密的"感知神经网络"。传统的监控往往只关注CPU、内存、磁盘空间等基础指标,如同只测量体温而忽略全面的体检。
现代数据库运维需要的是立体化、多层次 的数据采集体系。这不仅包括数据库内部的关键性能指标(如QPS、TPS、活跃会话数、锁等待),还应涵盖操作系统资源使用情况、网络I/O状态以及应用端的业务指标。
以云和恩墨的zCloud为例,该平台支持对30种主流数据库的纳管,采用Agent与非Agent相结合的采集方式,既保障了数据采集的全面性,又降低了对生产环境的影响。
在实际应用中,全链路采集特别强调"可观测性"理念的落地,即通过**日志(Logs)、指标(Metrics)和追踪(Trace)**三大要素的组合,形成对数据库运行状态的完整视图。
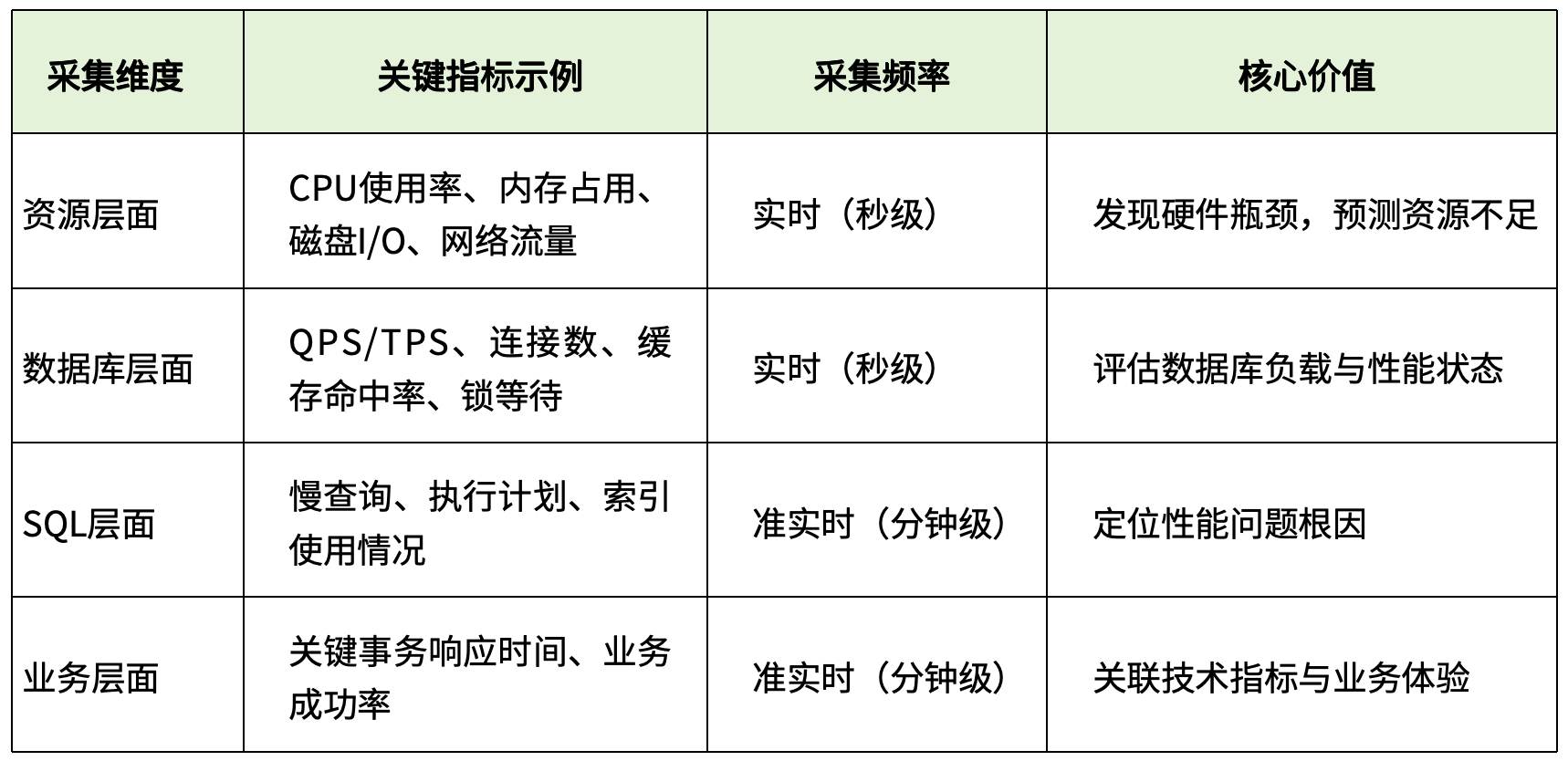
表:全链路采集的关键维度与指标
这种对企业内异构混合数据库环境的"一站式"采集,一改过去需要逐个登录系统、手动设置脚本的繁琐操作,如今通过统一控制台即可完成,为后续的监控巡检乃至智能分析奠定了基础。
环节二: 自动化监控与巡检,建立常态化预防机制
如果说全链路采集是"感官",那么自动化监控与巡检就是运维体系的"反射神经"。监控与巡检常被混淆,实则在运维工作中扮演不同角色:监控侧重于实时跟踪,而巡检则注重预防性检查。
自动化监控的核心目标是"不漏报、少误报、高响应"。这需要精心设计告警策略,避免"告警疲劳"导致的真正问题被忽视。优秀的数据库监控工具(如Bethune X)会预置非常全面的监控指标(通常有数百个),并允许用户根据业务特点自定义告警阈值和通知方式。当指标异常时,可通过邮件、企业微信、钉钉等多种渠道及时通知相关人员。
自动化巡检则更进一步,它模拟资深DBA的日常检查工作,定期对数据库进行全面"体检"。日常巡检通常以较高频率进行,聚焦于数据库健康状态的核心指标;而深度巡检则周期较长,检查范围更广,包括安全性、合规性、性能容量规划等多个维度。
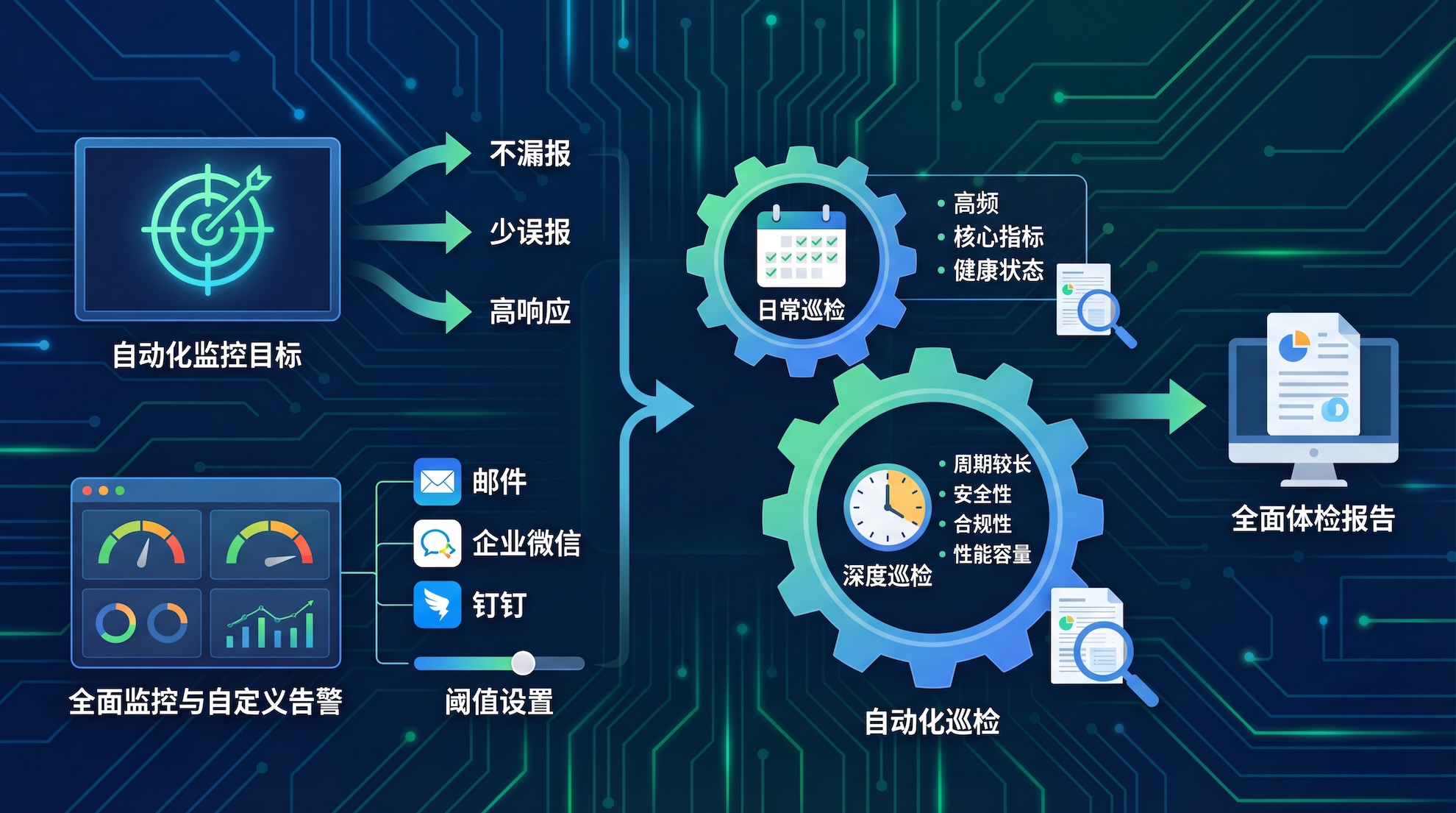
Bethune X的巡检功能采用百分制评分机制,将云和恩墨专家团队十数年积累的实践经验转化为具体的检查项和权重设置。巡检结束后生成详细报告,不仅列出发现的问题,还提供优先级评估和初步解决建议。
值得一提的是,"巡检白名单"是Bethune X中一个特别实用的功能------对于一些短期内无法解决或已明确接受的风险(如特定业务的日志量超出预期),可以将其加入白名单,避免这些已知问题反复出现在报告中干扰判断。这相当于为巡检报告做了"瘦身",使DBA能够专注于新的、更关键的风险点。
环节三: 智能诊断,专家经验的数字化传承
当监控系统发现异常,自动化巡检识别出潜在风险后,接下来最关键的环节是诊断与解决。这正是智能诊断技术的核心价值所在------将资深DBA的排障经验转化为系统可执行的诊断逻辑。
传统模式下,初级工程师遇到复杂问题时,往往需要求助资深专家或花费大量时间查阅文档、尝试各种解决方案。而智能诊断功能如同一位"永不疲倦的专家助手",能够快速分析问题根因,提供针对性的解决建议。
云和恩墨在zCloud 6.7版本中引入了基于大语言模型的智能诊断模块,将私有化部署的DeepSeek或Qwen大模型与公司积累的专家经验知识库相结合。当巡检报告发现问题时,系统不仅能指出问题所在,还能精确分析可能的原因并提供具体的修复命令。
智能诊断的价值在复杂问题场景中尤为突出。以数据库性能问题为例,一款优秀的监控工具可以:
- 通过知识图谱分析异常指标间的关联性,从海量告警中定位问题源头;
- 基于历史成功实践,形成诊断决策树,指导排查路径;
- 对于SQL性能问题,结合大模型推理和运维知识库,提供索引优化、SQL改写等精准建议。
云和恩墨在金杯电工的实践案例中展示了这种智能诊断的实际效果:通过"专家经验+AI大模型"的双轮驱动,数据库监控工具能够迅速分析告警关联性,深挖故障根因并给出解决方案建议,让运维团队彻底告别了"头痛医头、脚痛医脚"的工作模式。
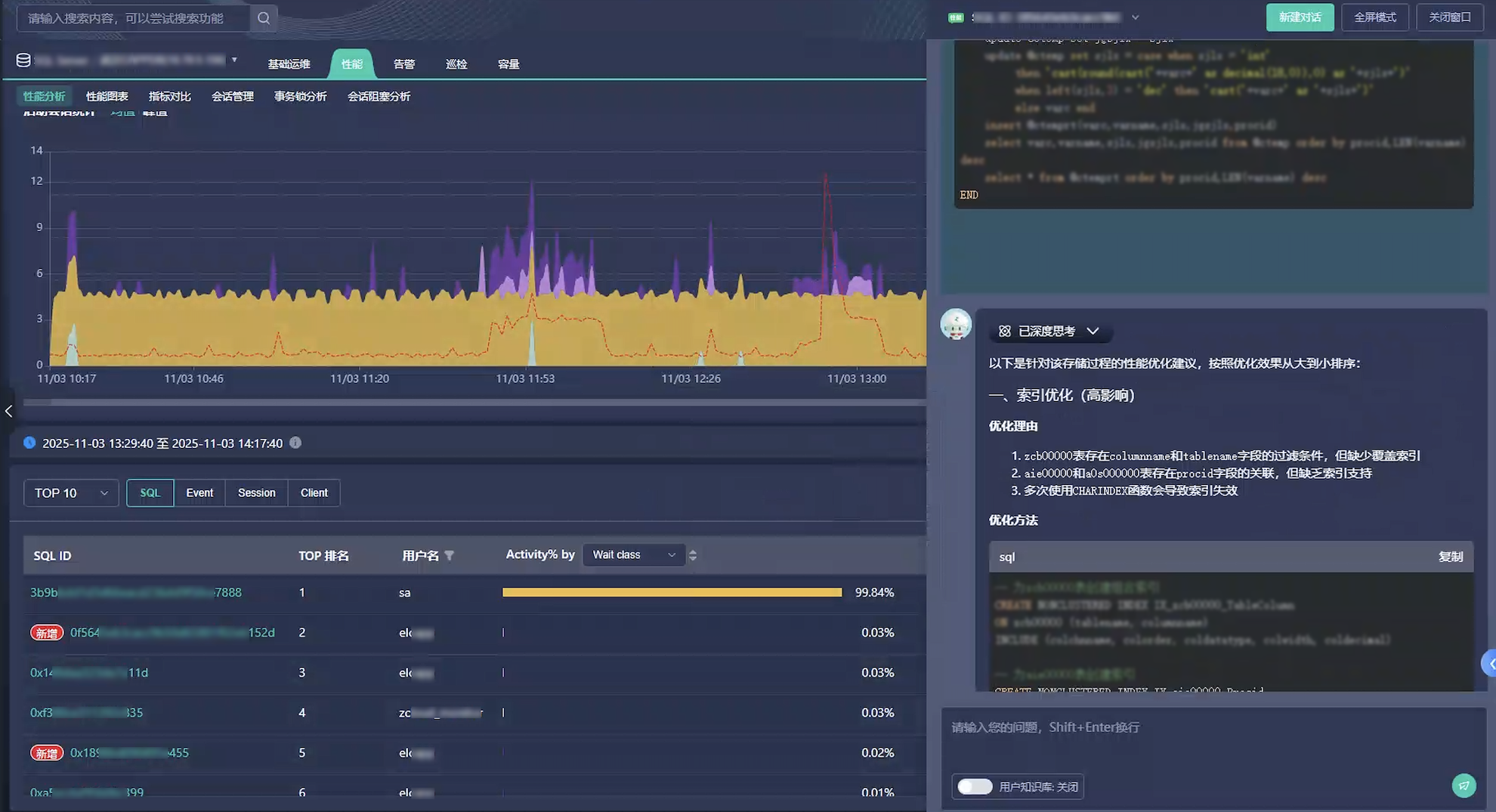
图:Bethune X智能诊断功能,让SQL优化变得简单高效
环节四: 持续优化,形成运维提升的飞轮效应
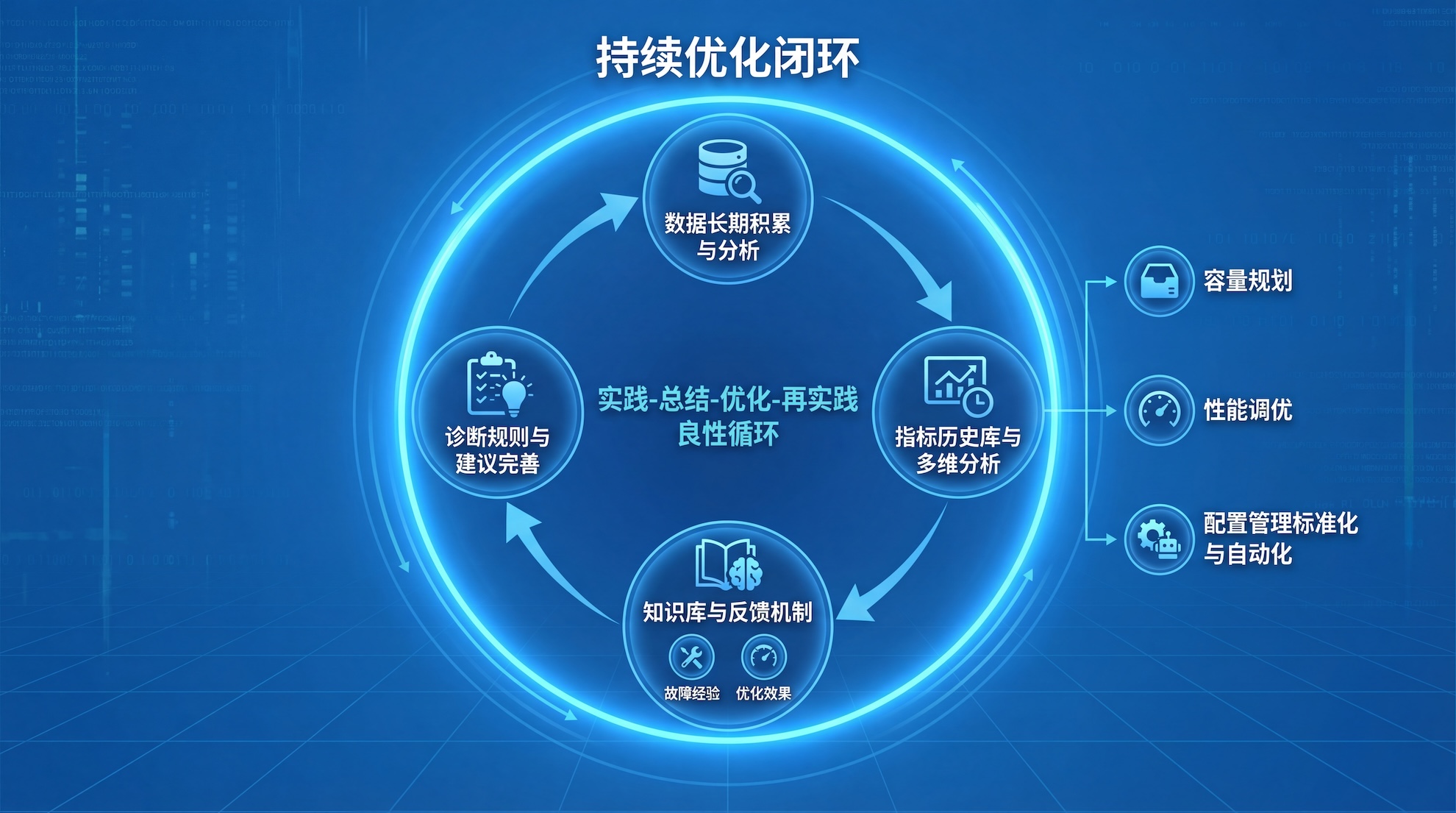
从被动响应到主动预防的转变,最后必须形成一个闭环------持续优化。这是确保运维能力不断提升、适应业务发展的关键环节。
持续优化的基础是数据的长期积累与分析。数据库监控巡检平台应当建立完整的指标历史库,支持多维度的趋势分析和对比。例如,通过对比不同时间段的性能指标,可以发现系统的周期性变化规律;通过关联业务负载与数据库性能数据,可以更准确地进行容量规划。
容量规划是持续优化的重要应用场景。基于历史数据,运维团队可以预测未来一段时间内数据库的资源需求,提前进行扩容或优化,避免因资源不足导致的性能下降。
性能调优则是持续优化的另一个关键领域。智能的监控巡检平台应当能够识别数据库中的低效SQL、缺失索引、不合理的参数配置等问题,并提供具体的优化建议。
配置管理的标准化与自动化也是持续优化的重要组成部分。还是以数据库管理平台zCloud为例,它内置最佳配置模板,支持不同架构类型的自动化安装部署。这不仅确保了数据库部署的一致性和规范性,也大大降低了人为配置错误的风险。
最后,持续优化需要建立反馈机制,将每次故障处理的经验、每次性能优化的效果反馈到知识库中,不断丰富和完善系统的诊断规则和优化建议,形成**"实践-总结-优化-再实践"的良性循环**。
结语
当深夜的告警电话不再频繁响起,数据库运维团队的屏幕被清晰的健康评分和优化建议所占据,那些曾被视为"救火英雄"的DBA们正悄然转变角色。他们不再是四处奔波的急救员,而是坐在指挥中心的系统健康规划师。
**如今的数据库监控巡检已不再是单纯的工具,它更是一种先进的运维管理理念。**每一次优化调整、每一条参数建议都在悄然推动整个数据库生态向着更稳定、更高效的方向演进,最终在企业数字化转型的宏大叙事中,成为数据库安稳运行的可靠保障与业务创新的坚实基础。