ResCLIP
动机
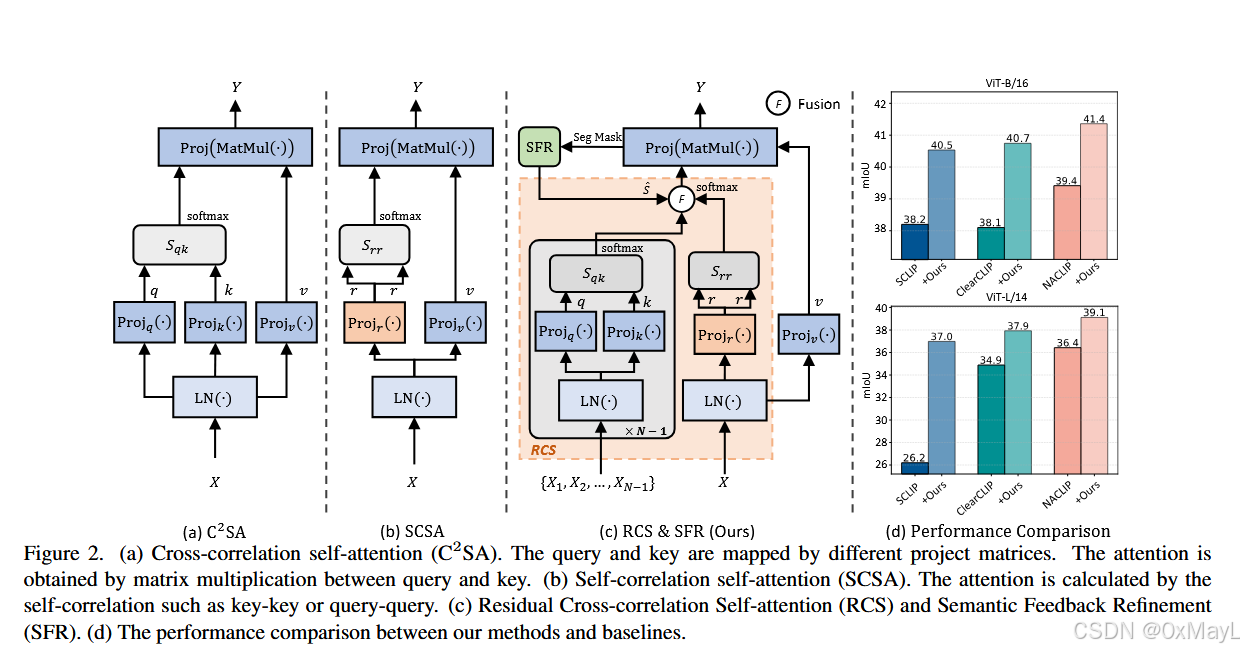
现有方法(如SCLIP、NACLIP)通过将最后一层的标准交叉相关自注意力 (C2SAC^2SAC2SA, Query-Key)替换为自相关自注意力 (SCSA, Query-Query或Key-Key)来解决空间不变性问题 。然而,这些SCSA方法忽略了交叉相关注意力本身能捕获丰富的空间对应关系的特性 。
验证实验
作者发现中间层的C2SA注意力图也能关注局部特征(具有良好的空间协变性 ),还能关注相同类别的特征。

方法
残差C2SA
就是将中间层的交叉注意力图进行平均加权到最后一层的注意力图中。

对应的消融实验。


语义反馈提取
NACLIP的高斯注意力虽然提高了空间局部性,但是却有个致命缺点:各向同性。意味着其只考虑相对距离,没有考虑形状。例如距离相同的高斯核的输出结果一致,但是可能是毫不相干的特征 。
除此之外,好的注意力图不仅应该关注局部特征,还应该关注相同的类别特征。
首先作者使用RCS模块输出后的分割掩码 进一步细化最后一层的注意力图,将相同类别的注意力图直接置为1。


然后为了保持局部性,作者采用连通性的方法削弱类别相同,但是不同连通的patch分数。

最后重新得到注意力矩阵,再通过这一矩阵获得分割掩码。


好的,作为一名AI领域的研究生分析师,我将为您深入解析您提供的论文《ResCLIP: Residual Attention for Training-free Dense Vision-language Inference》的方法部分。
GEMINI总结
🔬 论文分析:ResCLIP
0. 摘要原文翻译
cite_start尽管像CLIP这样的视觉-语言模型在开放词汇任务中取得了显著成功,但它们的应用目前仅限于图像级任务,并且在密集预测方面仍然存在困难。最近的工作通常将密集预测的这种不足归因于最终块中的自注意力层,并通过将原始的查询-键注意力修改为自相关注意力(例如,查询-查询和键-键注意力)取得了令人称赞的结果。然而,这些方法忽略了捕获丰富空间对应关系的交叉相关注意力(查询-键)的特性。在本文中,我们揭示了CLIP非最终层中自注意力的交叉相关性也表现出定位特性。因此,我们提出了**残差交叉相关自注意力(Residual Cross-correlation Self-attention, RCS)模块,它利用来自中间层的交叉相关自注意力来重塑最终块中的注意力。RCS模块有效地重组了空间信息,释放了CLIP中用于密集视觉-语言推理的定位潜力。此外,为了增强对相同类别区域和局部一致性的关注,我们提出了 语义反馈细化(Semantic Feedback Refinement, SFR)**模块,它利用语义分割图来进一步调整注意力分数。通过整合这两种策略,我们的方法------ResCLIP ,可以很容易地作为即插即用模块集成到现有方法中,显著提升它们在密集视觉-语言推理中的性能。广泛的实验证明,我们的方法超越了最先进的免训练方法,验证了所提出方法的有效性。代码可在 https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP)\text{https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP)}https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP) 获取 cite: 1-4, 10-19。
1. 方法动机
a) 作者为什么提出这个方法?阐述其背后的驱动力。
cite_start驱动力在于解决CLIP模型在密集预测任务(如语义分割)中的定位能力不足问题 ,同时保持CLIP的开放词汇泛化能力,并避免昂贵的像素级标注和模型微调成本,因此采用了**免训练(Training-free)**的方案 cite: 10, 28, 30, 31, 185。
b) 现有方法的痛点/不足是什么?具体指出局限性。
- cite_startCLIP的局限性: 尽管CLIP在图像级任务上表现出色,但其在最后一层 的自注意力层中表现出空间不变性(Spatial-invariant)的注意力,这使得它难以进行像素级的密集预测任务 cite: 10, 28, 32, 178, 184, 189, 194。
- cite_start现有免训练方法的局限性: 现有方法(如SCLIP、NACLIP)通过将最后一层的标准交叉相关自注意力 (C2SAC^2SAC2SA, Query-Key)替换为自相关自注意力 (SCSA, Query-Query或Key-Key)来解决空间不变性问题 cite: 11, 32, 102, 103, 190cite_start。然而,这些SCSA方法忽略了 交叉相关注意力本身能捕获丰富的空间对应关系的特性 cite: 12, 104, 192, 193。
c) 论文的研究假设或直觉是什么?用简洁语言概括。
直觉:CLIP的非最终层中包含有用的空间定位信息。
cite_start作者的假设是:尽管CLIP最后一层的交叉相关自注意力(C2SAC^2SAC2SA)表现出空间不变性,但中间层的交叉相关自注意力 却具有类特定特征和定位特性 cite: 13, 107, 108, 125, 195。因此,可以利用这些中间层的定位信息来"修复"(remold)最后一层的注意力,从而增强CLIP的密集预测能力。
2. 方法设计
cite_startResCLIP方法(见图4 )主要由两个模块组成:**残差交叉相关自注意力(RCS)模块和语义反馈细化(SFR)**模块 cite: 127, 213, 252。
a) 给出清晰的方法流程总结(pipeline),逐步解释输入→处理→输出。
方法流程(ResCLIP Pipeline):
- 初始预测(1st Predictions):
- 输入: 图像和文本查询(Text queries)。
- cite_start处理: 图像通过CLIP视觉编码器 (Vision Encoder)得到视觉特征,文本通过CLIP文本编码器 (Text Encoder)得到文本特征。然后,通过余弦相似度(COS)计算密集视觉特征 (XdenseX_{dense}Xdense,来自视觉编码器的非
[cls]token)与文本特征 (XtextX_{text}Xtext)之间的相似性 cite: 179, 180, 182, 226。 - cite_start输出: 初始语义分割预测 (Predictions)和分割掩码(Seg Mask)cite: 221, 227。
- 残差交叉相关自注意力(RCS)模块:
- 输入: CLIP中间层的交叉相关自注意力 (C2SAC^2SAC2SA)和最后一层的自相关自注意力(SCSA)。
- 处理:
- cite_start中间层C2SAC^2SAC2SA聚合: 提取从起始层 sss 到结束层 eee 的 NNN 个中间层中的 C2SAC^2SAC2SA 注意力图 Attni(Sqk)Attn^i(S_{qk})Attni(Sqk),并进行平均聚合 得到 Ac\mathcal{A}cAc cite: 205-207, 209。
Ac=1N∑i=seAqki\mathcal{A}c = \frac{1}{N} \sum{i=s}^e \mathcal{A}{qk}^iAc=N1i=s∑eAqki - cite_start残差融合: 将聚合的交叉相关注意力 Ac\mathcal{A}cAc 与现有方法(如NACLIP)使用的最后一层自相关注意力 As\mathcal{A}sAs 进行残差连接(Fusion) ,得到RCS注意力 ARes\mathcal{A}{Res}ARes cite: 110, 199, 217, 256, 259。
ARes=(1−λres)As+λresAc\mathcal{A}{Res} = (1 - \lambda_{res}) \mathcal{A}s + \lambda{res} \mathcal{A}_cARes=(1−λres)As+λresAc
- cite_start中间层C2SAC^2SAC2SA聚合: 提取从起始层 sss 到结束层 eee 的 NNN 个中间层中的 C2SAC^2SAC2SA 注意力图 Attni(Sqk)Attn^i(S_{qk})Attni(Sqk),并进行平均聚合 得到 Ac\mathcal{A}cAc cite: 205-207, 209。
- 输出: 融合了空间对应信息的RCS注意力权重 ARes\mathcal{A}_{Res}ARes。
- 语义反馈细化(SFR)模块:
- cite_start输入: 初始分割掩码 M\mathcal{M}M (Seg Mask) 和 SCSA 的注意力分数 SsS_sSs(或原始注意力分数) cite: 268, 271, 299。
- 处理:
- cite_start语义掩码创建: 对注意力分数 SSS 的每一行(对应一个补丁 iii)创建一个二值语义掩码 Sm,niS_{m,n}^iSm,ni,其中如果补丁 (m,n)(m,n)(m,n) 与源补丁 iii 在 M\mathcal{M}M 中的语义类别相同,则值为 1,否则为 0 cite: 271, 274, 275。
- cite_start局部一致性增强(衰减函数): 定义衰减函数 h(V,D)=V+(1−V)⋅Dh(V, D) = V + (1-V) \cdot Dh(V,D)=V+(1−V)⋅D cite: 277, 279, 280。
- cite_startVVV 是连通性掩码:如果补丁 (m,n)(m,n)(m,n) 与源补丁 (i′,j′)(i', j')(i′,j′) 之间存在有效路径,则 Vmn=1V_{mn}=1Vmn=1,否则为 0 cite: 281。
- cite_startDDD 是距离衰减函数:使用切比雪夫距离(Chebyshev Distance)计算并归一化距离 d(p,q)d(p,q)d(p,q),得到 D(p,q)=exp(−d(p,q)max(d(⋅,⋅)))D(p,q) = \exp(-\frac{d(p,q)}{\max(d(\cdot,\cdot))})D(p,q)=exp(−max(d(⋅,⋅))d(p,q)) cite: 282, 283, 286。
- cite_start注意力细化: 将语义掩码 SiS^iSi 与衰减函数 h(V,D)h(V, D)h(V,D) 逐元素相乘 (⊙\odot⊙),然后通过高斯核 ϕ\phiϕ 平滑,得到细化后的注意力分数 S^\hat{S}S^ cite: 292-294。
S^i=ϕ(Si⊙h(V,D))\hat{S}^i = \phi(S^i \odot h(V, D))S^i=ϕ(Si⊙h(V,D)) - cite_start最终分数融合: 将细化后的 S^\hat{S}S^ 与 SCSA 分数 SsS_sSs 按权重 λsfr\lambda_{sfr}λsfr 融合,得到语义细化分数 SrS_rSr,再经过 softmax\text{softmax}softmax 得到 Asfr\mathcal{A}{sfr}Asfr cite: 297, 298, 301。
Sr=(1−λsfr)⋅Ss+λsfr⋅S^S_r = (1-\lambda{sfr}) \cdot S_s + \lambda_{sfr} \cdot \hat{S}Sr=(1−λsfr)⋅Ss+λsfr⋅S^
- 输出: 增强了类内一致性和局部性的 Asfr\mathcal{A}_{sfr}Asfr。
- 最终残差注意力与预测(Final Residual Attention):
- cite_start输入: RCS注意力 Ac\mathcal{A}cAc 和 SFR注意力 Asfr\mathcal{A}{sfr}Asfr cite: 301。
- cite_start处理: 将 Ac\mathcal{A}{c}Ac 和 Asfr\mathcal{A}{sfr}Asfr 再次进行残差连接,得到最终的 ResCLIP 注意力 AResCLIP\mathcal{A}{ResCLIP}AResCLIP cite: 300, 301。
AResCLIP=(1−λres)Asfr+λresAc\mathcal{A}{ResCLIP} = (1 - \lambda_{res}) \mathcal{A}{sfr} + \lambda{res} \mathcal{A}_cAResCLIP=(1−λres)Asfr+λresAc - cite_start输出: 使用 AResCLIP\mathcal{A}_{ResCLIP}AResCLIP 替换CLIP最后一层的注意力机制,生成最终的密集预测(Final Predictions)cite: 215, 255。
b) 如果涉及模型结构,请描述每个模块的功能与作用,以及它们如何协同工作。
- RCS(残差交叉相关自注意力):
- cite_start功能: 引入CLIP中间层 的交叉相关自注意力 (C2SAC^2SAC2SA),以捕获丰富的空间对应关系 和定位特性 cite: 14, 15, 110, 200, 302。
- cite_start作用: 它通过残差连接(加权平均)将中间层的定位能力注入到最后一层的注意力(SCSA)中,弥补了SCSA缺乏交叉特征动态的不足 cite: 14, 15, 192, 199。
- SFR(语义反馈细化):
- cite_start功能: 利用模型初始的语义分割掩码 作为反馈 ,显式地增强对相同类别区域 的关注和局部一致性 cite: 16, 116, 267, 303。
- cite_start作用: 它通过语义掩码和距离衰减函数来调整注意力分数,使得注意力更集中于语义相关 且空间邻近的区域,有效减少了注意力中的噪声 cite: 16, 268, 276, 303, 341。
- 协同工作:
- SFR先作用于SCSA的注意力分数 SsS_sSs,生成 Asfr\mathcal{A}_{sfr}Asfr,使其具有语义和局部感知能力。
- RCS利用中间层的 C2SAC^2SAC2SA(Ac\mathcal{A}_cAc)为注意力提供更全局和丰富的空间对应信息。
- cite_start最终,Asfr\mathcal{A}_{sfr}Asfr 和 Ac\mathcal{A}cAc 被二次残差融合 ,得到 AResCLIP\mathcal{A}{ResCLIP}AResCLIP,该注意力融合了SCSA的空间协变特征、中间层C2SAC^2SAC2SA的空间对应关系,以及SFR的语义与局部一致性,从而显著增强了密集预测能力 cite: 301, 303。
c) 如果有公式/算法,请用通俗语言解释它们的意义和在方法中的角色。
-
交叉相关自注意力 Ac\mathcal{A}_cAc 的聚合(公式 5):
Ac=1N∑i=seAqki\mathcal{A}c = \frac{1}{N} \sum{i=s}^e \mathcal{A}_{qk}^iAc=N1i=s∑eAqki- 意义: 这是从CLIP的 sss 层到 eee 层所有标准 (Query-Key)自注意力图的平均值。
- cite_start角色: 它是RCS模块的核心输入。其意义在于,作者发现这些中间层的注意力保留了定位信息,通过平均它们,得到一个稳定且具有定位潜力的注意力权重,用于修复最后一层空间不变的注意力 cite: 108, 206, 207。
-
RCS 残差融合(公式 6):
ARes=(1−λres)As+λresAc\mathcal{A}{Res} = (1 - \lambda{res}) \mathcal{A}s + \lambda{res} \mathcal{A}_cARes=(1−λres)As+λresAc- 意义: 将现有SCSA方法(如NACLIP)的注意力 As\mathcal{A}_sAs(侧重局部和自相似)与中间层定位注意力 Ac\mathcal{A}_cAc(侧重空间对应)进行加权求和。
- cite_start角色: 保证了新注意力 ARes\mathcal{A}{Res}ARes 既利用了现有免训练方法(SCSA)的优点(空间协变),又弥补了其缺点(缺乏交叉特征动态),实现优势互补。λres\lambda{res}λres 控制中间层信息的影响程度 cite: 14, 259, 260。
-
SFR 局部一致性衰减函数 h(V,D)h(V, D)h(V,D)(公式 8):
h(V,D)=V+(1−V)⋅Dh(V, D) = V + (1-V) \cdot Dh(V,D)=V+(1−V)⋅D- cite_start意义: 这是用于调整注意力分数,以增强同语义区域 和局部邻近性的复合函数 cite: 279, 280。
- 角色: 它结合了连通性掩码 VVV 和距离衰减函数 DDD 。
- VVV 确保注意力不受阻碍地流向与源补丁语义连通 的区域(V=1V=1V=1 时,h=1h=1h=1,无衰减)。
- cite_startDDD 对语义相同但空间上不连通 (V=0V=0V=0)的区域,施加距离衰减,惩罚远处或不邻近的补丁,从而维持局部一致性 cite: 277, 281, 282。
3. 与其他方法对比
a) 本方法和现有主流方法相比,有什么本质不同?
| 特征 | ResCLIP (本文方法) | SCSA类方法 (SCLIP, NACLIP, ClearCLIP) | 传统CLIP |
|---|---|---|---|
| 核心机制 | 残差融合 中间层 C2SAC^2SAC2SA 和 SCSASCSASCSA + 语义反馈细化 | 仅修改最后一层注意力 为 SCSA (Key-Key 或 Query-Query) | 最后一层为标准 C2SAC^2SAC2SA (Query-Key) |
| 关注信息 | 丰富的空间对应 (C2SAC^2SAC2SA) + 自相似 (SCSASCSASCSA) + 语义局部一致性(SFR) | 专注于局部自相似特征,以实现空间协变 | 专注于全局结构依赖,导致空间不变性 |
| 定位信息来源 | 中间层 的 C2SAC^2SAC2SA | 无/仅依赖SCSA自身 | 最后一层无用,中间层被忽略 |
| 训练方式 | 完全免训练 (Training-free) | 免训练 | 免训练(作为基线) |
b) 创新点在哪里?明确指出贡献度。
- cite_start新发现(核心洞察): 首次发现CLIP中间层 的交叉相关自注意力 (C2SAC^2SAC2SA)具有类特定特征 和定位特性,这与最后一层的空间不变性形成鲜明对比 cite: 13, 107, 125, 126, 393。
- cite_startRCS模块: 提出了残差交叉相关自注意力(RCS) ,通过将中间层 C2SAC^2SAC2SA 与最后一层注意力(SCSA)残差连接,有效地将空间定位能力注入最终的注意力图 cite: 14, 127。
- cite_startSFR模块: 提出了语义反馈细化(SFR) ,利用初始分割掩码 作为语义反馈,并结合连通性与距离衰减函数,显式地增强类内一致性 和局部性,进一步细化了注意力分数 cite: 16, 116, 127。
- cite_start即插即用: ResCLIP是一个即插即用(plug-and-play)的模块化解决方案,可以无缝集成到现有的SCSA基免训练方法(如SCLIP、NACLIP、ClearCLIP)中,实现显著性能提升 cite: 17, 117, 119, 334。
c) 在什么场景下更适用?分析其适用范围。
- cite_start开放词汇语义分割(OVSS)任务: 这是ResCLIP的主要目标,适用于需要对未见过类别进行像素级密集预测的场景 cite: 137。
- cite_start需要精细定位的密集预测任务: 适用于任何因CLIP最后一层注意力空间不变性而受限的密集预测任务 cite: 10, 15。
- cite_start注重泛化和免训练的场景: 适用于追求高泛化能力、不想进行昂贵像素级微调的场景 cite: 31。
d) 用表格总结 方法对比(优点/缺点/改进点)
| 方法 | 核心机制 | 优点 | 缺点/改进点 |
|---|---|---|---|
| ResCLIP (本文) | RCS(中间层 C2SAC^2SAC2SA 融合)+ SFR(语义反馈) | 1. 显著提升定位能力;2. 融合空间对应、自相似和语义局部性;3. 完全免训练,即插即用。 | 引入两个超参数 λrcs,λsfr\lambda_{rcs}, \lambda_{sfr}λrcs,λsfr 需要调优。 |
| SCSA类 (NACLIP, SCLIP, ClearCLIP) | 仅用 SCSASCSASCSA(如 Key-Key)替换最后一层 C2SAC^2SAC2SA | 1. 解决了最后一层的空间不变性;2. 实现了空间协变特征。 | 忽略了 C2SAC^2SAC2SA 的空间对应特性;缺乏显式的语义和局部一致性增强。 |
| 传统 C2SAC^2SAC2SA (CLIP Baseline) | 原始 Query-Key 自注意力 | 在图像级任务上表现良好;强大的视觉-文本对齐。 | 最后一层注意力空间不变,密集预测能力差。 |
4. 实验表现与优势
a) 作者如何验证该方法的有效性?描述实验设计和设置。
- cite_start任务: 开放词汇语义分割(OVSS) cite: 306。
- cite_start评估指标: 平均交并比(mIoU)cite: 327。
- cite_start数据集: 八个广泛采用的基准数据集,分为带背景类别 (VOC21, Context60, Object)和不带背景类别(VOC20, Context59, Stuff, Cityscapes, ADE20K)两组 cite: 307-310。
- cite_start基线方法: * 直接基线 CLIP cite: 313。
- cite_start最先进的免训练方法:MaskCLIP, SCLIP, NACLIP, ClearCLIP等 cite: 313。
- cite_start有影响力的弱监督方法:Group ViT, TCL, SegCLIP等 cite: 314。
- cite_start集成与消融: ResCLIP作为即插即用模块,被集成到三个主流免训练模型(SCLIP, ClearCLIP, NACLIP)上进行评估 cite: 119, 320cite_start。此外,进行了RCS和SFR模块的消融实验 cite: 377。
- cite_start骨干网络: 主要使用 ViT-B/16 和 ViT-L/14 cite: 325, 321。
b) 实验结果在哪些指标上超越了对比方法?列出几个最具代表性的关键数据和结论。
| 数据集分组 | 骨干网络 | 基线方法 | 基线 mIoU | ResCLIP mIoU | 提升 |
|---|---|---|---|---|---|
| 不带背景 (Avg.) | ViT-B/16 | cite_startNACLIP cite: 19 | 38.2% | 40.3% | cite_start+2.1% cite: 290 |
| 带背景 (Avg.) | ViT-B/16 | cite_startNACLIP cite: 19 | 41.4% | 43.2% | cite_start+1.8% cite: 318, 339 |
| 不带背景 (Avg.) | ViT-L/14 | cite_startSCLIP cite: 46 | 23.6% | 36.7% | cite_start+13.1% cite: 290, 335 |
| 消融(VOC20) | ViT-B/16 | NACLIP Baseline | 79.7% | RCS Alone: 85.5% | cite_start+5.8% cite: 370, 378 |
关键结论:
- cite_start全面超越: ResCLIP作为即插即用模块,在所有测试的基线模型(SCLIP, ClearCLIP, NACLIP)和所有八个数据集上都实现了一致且显著的mIoU提升 cite: 334, 338, 550。
- cite_startSOTA表现: 在ViT-B/16上,集成ResCLIP的NACLIP达到了43.2% mIoU (带背景)和40.3% mIoU(不带背景),超越了主流的弱监督方法,实现了免训练方法的SOTA cite: 333, 339。
- cite_start对大模型的修复能力强: 对于ViT-L/14这种大型骨干网络,ResCLIP对性能的提升更为巨大,例如将SCLIP的平均mIoU从23.6%提升至36.7%,提升了13.1% ,这表明它能有效缓解 现有方法在不同骨干网络上的性能退化问题 cite: 290, 335, 554。
- cite_start定性优势: ResCLIP生成的分割掩码质量更高,噪声更少,能更好地关注对象内部区域,避免了中央空洞或破碎的密集预测 cite: 371, 372, 607, 608。
c) 哪些场景/数据集下优势最明显?提供具体证据。
- cite_startViT-L/14骨干网络: 优势最明显,因为它能显著缓解现有方法在不同骨干网络上的性能退化(如SCLIP在ViT-L/14上提升了13.1%)cite: 290, 335, 554。
- cite_start复杂场景数据集: 在ADE20K上,ResCLIP能保持连贯的建筑分割,避免了其他基线方法常见的内部空洞或碎片化 cite: 608。
- cite_start多实例对象: 在COCO Object数据集上,ResCLIP能更准确地分割成群的动物,并保持个体之间的清晰边界 cite: 610, 611。
d) 是否有局限性?
论文中承认或隐含的不足:
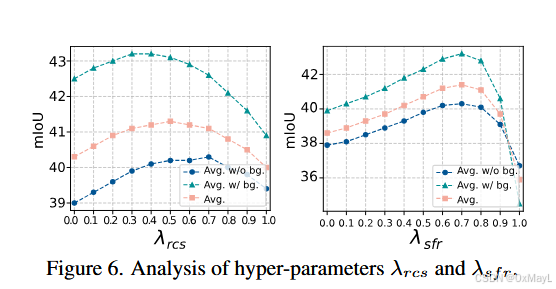
- cite_start超参数敏感性: 引入了两个超参数 λrcs\lambda_{rcs}λrcs 和 λsfr\lambda_{sfr}λsfr,需要进行调优。虽然作者指出适中的值效果最好,但其依赖性仍然存在 cite: 382, 384。
- cite_startSFR依赖初始预测: SFR模块的有效性依赖于初始语义分割掩码 M\mathcal{M}M 的质量。如果初始预测本身很差,SFR的反馈细化效果可能会受限 cite: 268。
- cite_start计算开销(隐含): RCS模块需要从 NNN 个中间层提取并平均注意力图,这会带来额外的计算开销(尽管是免训练,但在推理时增加了计算量)cite: 206, 386。
5. 学习与应用
a) 论文是否开源?如果我想实现/复现这个方法,关键步骤是什么?
- cite_start开源情况: 论文明确指出代码是开源 的:https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP)\text{https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP)}https://github.com/yvhangyang/ResCLIP(https://github.com/yvhangyang/ResCLIP) cite: 19。
- 复现关键步骤:
- cite_start中间层 C2SAC^2SAC2SA 提取与聚合: 确定CLIP视觉编码器中的中间层(如 4→74 \rightarrow 74→7 或 6→96 \rightarrow 96→9 层效果较好),并实现对这些层标准 Query-Key 自注意力图的提取和平均操作(公式 5)cite: 206, 390。
- cite_startRCS 残差连接: 实现 Ac\mathcal{A}_cAc 与现有SCSA注意力 As\mathcal{A}_sAs 的加权融合(公式 6)cite: 256。
- cite_start初始分割掩码生成: 实现第一次推理,使用密集视觉特征和文本特征的余弦相似度,得到初始分割掩码 MMM cite: 182。
- cite_startSFR 连通性与距离计算: 实现基于初始掩码 MMM 的语义连通性检查 VVV 和切比雪夫距离计算 DDD,然后构建衰减函数 h(V,D)h(V, D)h(V,D)(公式 8, 10)cite: 279, 281, 286。
- cite_startSFR 细化与融合: 将 h(V,D)h(V, D)h(V,D) 应用于注意力分数,并通过高斯核平滑 ϕ\phiϕ,最后与 SCSA 分数融合(公式 11, 12),形成最终的 ResCLIP 注意力(公式 13)cite: 292, 297, 301。
b) 需要注意哪些超参数、数据预处理、训练细节?提供实现层面的建议。
- 超参数:
- cite_startλrcs\lambda_{rcs}λrcs:RCS模块的融合权重。建议值 0.50.50.5 cite: 383。
- cite_startλsfr\lambda_{sfr}λsfr:SFR模块的融合权重。建议值 0.70.70.7 ,且在 0.60.60.6 到 0.80.80.8 范围内表现稳定 cite: 383。
- cite_start层聚合范围(s,es, es,e): 聚合中间层 C2SAC^2SAC2SA 的范围。滑动窗口聚合 6→96 \rightarrow 96→9 表现最佳 cite: 390。
- 数据预处理:
- cite_start图像尺寸:输入图像短边调整为 336336336 像素(Cityscapes 为 560560560 像素)cite: 311。
- 训练/推理细节:
- cite_start免训练: 整个过程是免训练/免微调的 cite: 326。
- cite_start推理策略: 采用滑动窗口推理 (Slide Inference),使用 224×224224 \times 224224×224 窗口,步长为 112112112 cite: 312。
- cite_start后处理: 遵循严格的免训练标准,不使用如PAMR或DenseCRF等计算密集型后处理技术,以确保公平比较 cite: 323。
- cite_start文本提示: 仅使用标准的 ImageNet 提示,不使用额外的文本提示策略 cite: 324。
c) 该方法能否迁移到其他任务?如果能,如何迁移?
该方法的核心思想是修复预训练视觉-语言模型(VLM)在最后一层损失的定位能力。
-
可迁移任务:
- cite_start开放词汇目标检测/实例分割: VLM在这些任务中也依赖精细的定位。可以将ResCLIP的增强注意力应用于生成提议区域或细化实例掩码 cite: 10。
- cite_start视觉问答(VQA)/视觉推理(Visual Reasoning)中的证据定位: 需要模型在图像中精确地"看"到文本提及的对象。ResCLIP可以增强 VLM 在推理过程中对相关图像区域的关注,提高定位的准确性 cite: 26。
-
迁移方式:
- cite_startRCS迁移: 保持RCS模块不变,作为预训练模型(如CLIP)的即插即用组件,用于增强视觉编码器最后一层的注意力,使其输出的密集特征更具空间定位性 cite: 17。
- SFR迁移: SFR需要一个初始的密集预测(如粗略边界框、语义热图等)作为反馈。在目标检测任务中,可以使用区域提议网络(RPN)或自生成的粗略边界框作为"语义反馈",然后用SFR的机制去调整注意力,使特征提取更聚焦于边界框内的语义一致区域。
6. 总结
a) 用一句话概括这个方法的核心思想(不超过20字)。
融合中间层定位注意力,并以语义反馈细化最后一层注意力的免训练方法。
b) 给出一个"速记版pipeline"(使用3-5个关键步骤)。
- 初始预测: CLIP用余弦相似度做粗略的语义分割。
- 定位增强(RCS): 将中间层有定位能力的注意力图平均后,残差融合到最后一层的注意力中。
- 语义细化(SFR): 使用粗略分割结果 作为指导,增强注意力对相同语义 和邻近区域的关注。
- 最终预测: 使用融合了定位与语义的新注意力重新计算特征,生成精细分割图。