MiMo-V2-Flash 是一款采用专家混合架构(MoE)的语言模型,总参数量达3090亿 ,激活参数量为150亿。该模型专为高速推理和智能体工作流设计,通过创新的混合注意力架构与多令牌预测技术(MTP),在实现顶尖性能的同时显著降低推理成本。
1. 简介
MiMo-V2-Flash在长上下文建模能力和推理效率之间实现了新的平衡。主要特性包括:
- 混合注意力架构 :以5:1的比例交错使用滑动窗口注意力(SWA)和全局注意力(GA),并采用激进的128词元窗口。通过可学习的注意力汇聚偏置,在保持长上下文性能的同时,将KV缓存存储降低近6倍。
- 多词元预测(MTP):配备轻量级MTP模块(0.33B参数/块),使用密集前馈网络。推理时输出速度提升3倍,并有助于加速强化学习训练中的推演过程。
- 高效预训练:使用FP8混合精度和原生32k序列长度,在27T词元上完成训练。上下文窗口支持高达256k的长度。
- 智能体能力 :训练后采用多教师策略蒸馏(MOPD)和大规模智能体强化学习,在SWE-Bench和复杂推理任务中表现卓越。
2. 模型下载
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 下载 |
|---|---|---|---|---|
| MiMo-V2-Flash-Base | 309B | 15B | 256k | 🤗 HuggingFace |
| MiMo-V2-Flash | 309B | 15B | 256k | 🤗 HuggingFace |
!重要
我们还开源了3层MTP权重,以促进社区研究。
3. 评估结果
基础模型评估
MiMo-V2-Flash-Base 在标准基准测试中展现出强劲性能,超越了参数量显著更大的模型。
| Category | Benchmark | Setting/Length | MiMo-V2-Flash Base | Kimi-K2 Base | DeepSeek-V3.1 Base | DeepSeek-V3.2 Exp Base |
|---|---|---|---|---|---|---|
| Params | #Activated / #Total | - | 15B / 309B | 32B / 1043B | 37B / 671B | 37B / 671B |
| General | BBH | 3-shot | 88.5 | 88.7 | 88.2 | 88.7 |
| MMLU | 5-shot | 86.7 | 87.8 | 87.4 | 87.8 | |
| MMLU-Redux | 5-shot | 90.6 | 90.2 | 90.0 | 90.4 | |
| MMLU-Pro | 5-shot | 73.2 | 69.2 | 58.8 | 62.1 | |
| DROP | 3-shot | 84.7 | 83.6 | 86.3 | 86.6 | |
| ARC-Challenge | 25-shot | 95.9 | 96.2 | 95.6 | 95.5 | |
| HellaSwag | 10-shot | 88.5 | 94.6 | 89.2 | 89.4 | |
| WinoGrande | 5-shot | 83.8 | 85.3 | 85.9 | 85.6 | |
| TriviaQA | 5-shot | 80.3 | 85.1 | 83.5 | 83.9 | |
| GPQA-Diamond | 5-shot | 55.1 | 48.1 | 51.0 | 52.0 | |
| SuperGPQA | 5-shot | 41.1 | 44.7 | 42.3 | 43.6 | |
| SimpleQA | 5-shot | 20.6 | 35.3 | 26.3 | 27.0 | |
| Math | GSM8K | 8-shot | 92.3 | 92.1 | 91.4 | 91.1 |
| MATH | 4-shot | 71.0 | 70.2 | 62.6 | 62.5 | |
| AIME 24&25 | 2-shot | 35.3 | 31.6 | 21.6 | 24.8 | |
| Code | HumanEval+ | 1-shot | 70.7 | 84.8 | 64.6 | 67.7 |
| MBPP+ | 3-shot | 71.4 | 73.8 | 72.2 | 69.8 | |
| CRUXEval-I | 1-shot | 67.5 | 74.0 | 62.1 | 63.9 | |
| CRUXEval-O | 1-shot | 79.1 | 83.5 | 76.4 | 74.9 | |
| MultiPL-E HumanEval | 0-shot | 59.5 | 60.5 | 45.9 | 45.7 | |
| MultiPL-E MBPP | 0-shot | 56.7 | 58.8 | 52.5 | 50.6 | |
| BigCodeBench | 0-shot | 70.1 | 61.7 | 63.0 | 62.9 | |
| LiveCodeBench v6 | 1-shot | 30.8 | 26.3 | 24.8 | 24.9 | |
| SWE-Bench (AgentLess) | 3-shot | 30.8 | 28.2 | 24.8 | 9.4* | |
| Chinese | C-Eval | 5-shot | 87.9 | 92.5 | 90.0 | 91.0 |
| CMMLU | 5-shot | 87.4 | 90.9 | 88.8 | 88.9 | |
| C-SimpleQA | 5-shot | 61.5 | 77.6 | 70.9 | 68.0 | |
| Multilingual | GlobalMMLU | 5-shot | 76.6 | 80.7 | 81.9 | 82.0 |
| INCLUDE | 5-shot | 71.4 | 75.3 | 77.2 | 77.2 | |
| Long Context | NIAH-Multi | 32K | 99.3 | 99.8 | 99.7 | 85.6* |
| 64K | 99.9 | 100.0 | 98.6 | 85.9* | ||
| 128K | 98.6 | 99.5 | 97.2 | 94.3* | ||
| 256K | 96.7 | - | - | - | ||
| GSM-Infinite Hard | 16K | 37.7 | 34.6 | 41.5 | 50.4 | |
| 32K | 33.7 | 26.1 | 38.8 | 45.2 | ||
| 64K | 31.5 | 16.0 | 34.7 | 32.6 | ||
| 128K | 29.0 | 8.8 | 28.7 | 25.7 |
* 表示模型可能无法遵循提示或格式。
训练后模型评估
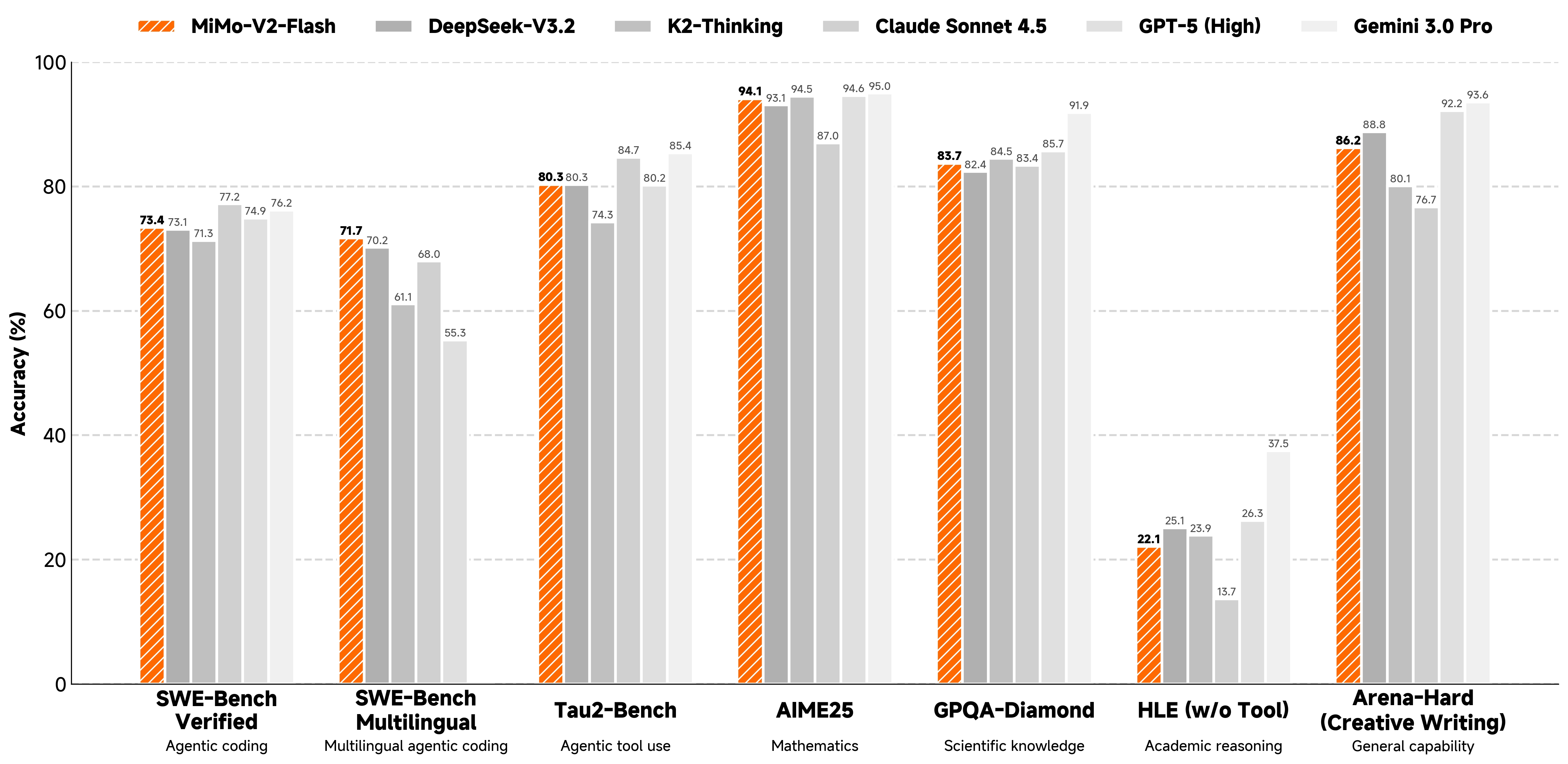
采用MOPD与智能体强化学习的训练后范式,该模型实现了最先进的推理与智能体性能。
| Benchmark | MiMo-V2 Flash | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | Gemini-3.0 Pro | Claude Sonnet 4.5 | GPT-5 High |
|---|---|---|---|---|---|---|
| Reasoning | ||||||
| MMLU-Pro | 84.9 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 |
| GPQA-Diamond | 83.7 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 |
| HLE (no tools) | 22.1 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 |
| AIME 2025 | 94.1 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 |
| HMMT Feb. 2025 | 84.4 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 |
| LiveCodeBench-v6 | 80.6 | 83.1 | 83.3 | 90.7 | 64.0 | 84.5 |
| General Writing | ||||||
| Arena-Hard (Hard Prompt) | 54.1 | 71.9 | 53.4 | 72.6 | 63.3 | 71.9 |
| Arena-Hard (Creative Writing) | 86.2 | 80.1 | 88.8 | 93.6 | 76.7 | 92.2 |
| Long Context | ||||||
| LongBench V2 | 60.6 | 45.1 | 58.4 | 65.6 | 61.8 | - |
| MRCR | 45.7 | 44.2 | 55.5 | 89.7 | 55.4 | - |
| Code Agent | ||||||
| SWE-Bench Verified | 73.4 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 |
| SWE-Bench Multilingual | 71.7 | 61.1 | 70.2 | - | 68.0 | 55.3 |
| Terminal-Bench Hard | 30.5 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 |
| Terminal-Bench 2.0 | 38.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 |
| General Agent | ||||||
| BrowseComp | 45.4 | - | 51.4 | - | 24.1 | 54.9 |
| BrowseComp (w/ Context Manage) | 58.3 | 60.2 | 67.6 | 59.2 | - | - |
| \(\tau^2\)-Bench | 80.3 | 74.3 | 80.3 | 85.4 | 84.7 | 80.2 |
4. 模型架构
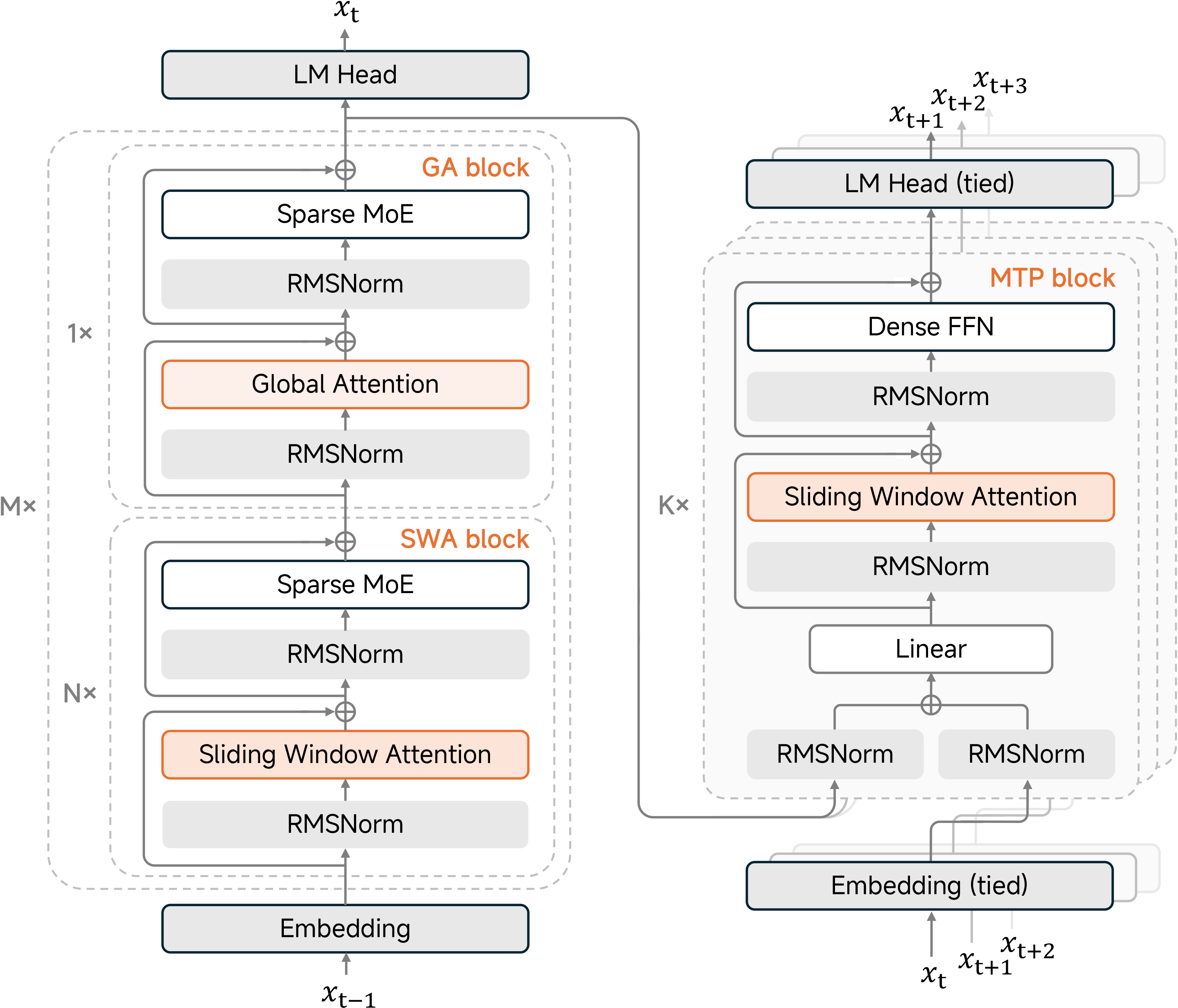
混合滑动窗口注意力
MiMo-V2-Flash通过交替使用局部滑动窗口注意力(SWA)和全局注意力(GA)来解决长上下文的二次方复杂度问题。
- 配置:采用 \(M=8\) 个混合块堆叠结构。每个块包含 \(N=5\) 个SWA层和1个GA层。
- 效率:SWA层采用128个词元的窗口大小,显著减少KV缓存占用。
- 沉没偏置:应用可学习的注意力沉没偏置,确保在激进窗口尺寸下仍保持性能。
轻量级多词元预测(MTP)
不同于传统推测解码技术,我们的MTP模块原生集成于训练和推理流程。
- 结构:使用稠密前馈网络(替代MoE)和SWA(替代GA),使每模块参数量控制在0.33B。
- 性能:支持自推测解码,生成速度提升三倍,缓解小批量强化学习训练时的GPU闲置问题。
5. 训练后技术亮点
MiMo-V2-Flash采用创新的蒸馏和强化学习策略,通过精心设计的训练后流程最大化推理和智能体能力。
5.1 多教师同策略蒸馏(MOPD)
我们提出**多教师同策略蒸馏(MOPD)**这一新范式,将知识蒸馏构建为强化学习过程:
- 密集令牌级指导:不同于依赖稀疏序列级反馈的方法,MOPD利用领域专家模型(教师)在每个令牌位置提供监督
- 同策略优化:学生模型从自身生成的响应中学习,而非固定数据集。这消除了曝光偏差,确保更小更稳定的梯度更新
- 内在奖励鲁棒性:奖励源自学生与教师间的分布差异,使该过程天然抵抗奖励破解
5.2 规模化智能体强化学习
我们大幅扩展了智能体训练环境以提升智能水平和泛化能力:
- 海量代码智能体环境:利用真实GitHub工单创建超10万个可验证任务。自动化流水线维护的Kubernetes集群可运行超1万个并发Pod,环境搭建成功率达70%。
- 网页开发多模态验证器:针对网页开发任务,采用基于视觉的验证器通过录制视频(非静态截图)评估代码执行,减少视觉幻觉并确保功能正确性。
- 跨领域泛化能力:实验表明,代码智能体的大规模强化学习训练能有效迁移至数学和通用智能体领域,显著提升相关任务表现。
5.3 先进强化学习基础设施
为支持大规模混合专家模型的高吞吐强化学习训练,我们在SGLang和Megatron-LM基础上实现多项基础设施优化:
- 轨迹路由回放(R3):解决推理与训练阶段MoE路由数值精度不一致问题。R3复用轨迹阶段的精确专家路由,确保一致性且开销可忽略。
- 请求级前缀缓存:在多轮智能体训练中缓存先前对话轮的KV状态和路由专家,避免重复计算并保证跨轮采样一致性。
- 细粒度数据调度器:扩展轨迹引擎以调度细粒度序列(替代微批次),结合部分轨迹执行,显著减少长尾延迟造成的GPU闲置。
- 工具箱双层管理器:采用Ray执行器池的两层设计处理资源竞争,消除工具执行的冷启动延迟,实现任务逻辑与系统策略解耦。
6. 推理与部署
MiMo-V2-Flash支持FP8混合精度推理,推荐使用SGLang获得最佳性能。
参数建议:采样参数推荐设为temperature=0.8, top_p=0.95。
SGLang快速入门
bash
pip install sglang
# Launch server
python3 -m sglang.launch_server \
--model-path XiaomiMiMo/MiMo-V2-Flash \
--served-model-name mimo-v2-flash \
--pp-size 1 \
--dp-size 2 \
--enable-dp-attention \
--tp-size 8 \
--moe-a2a-backend deepep \
--page-size 1 \
--host 0.0.0.0 \
--port 9001 \
--trust-remote-code \
--mem-fraction-static 0.75 \
--max-running-requests 128 \
--chunked-prefill-size 16384 \
--reasoning-parser qwen3 \
--tool-call-parser mimo \
--context-length 262144 \
--attention-backend fa3 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--enable-mtp
# Send request
curl -i http://localhost:9001/v1/chat/completions \
-H 'Content-Type:application/json' \
-d '{
"messages" : [{
"role": "user",
"content": "Nice to meet you MiMo"
}],
"model": "mimo-v2-flash",
"max_tokens": 4096,
"temperature": 0.8,
"top_p": 0.95,
"stream": true,
"chat_template_kwargs": {
"enable_thinking": true
}
}'重要通知
!IMPORTANT
在支持多轮工具调用的思考模式下,模型会同时返回
reasoning_content字段和tool_calls字段。要继续对话,用户必须在后续每个请求的messages数组中保留所有历史reasoning_content。!IMPORTANT
强烈推荐使用以下系统提示语,请从英文和中文版本中选择。
英语
plaintext
You are MiMo, an AI assistant developed by Xiaomi.
Today's date: {date} {week}. Your knowledge cutoff date is December 2024.中文
plaintext
你是MiMo(中文名称也是MiMo),是小米公司研发的AI智能助手。
今天的日期:{date} {week},你的知识截止日期是2024年12月。