摘要/引言
Zookeeper是分布式系统的"神经中枢"------它管着服务发现、配置同步、分布式锁,甚至K8s集群的etcd早期都借鉴了它的设计。但正是这种核心地位,让Zookeeper的稳定性直接决定了整个架构的生死:
- 要是连接数爆了,新服务根本注册不上
- 要是请求延迟突然飙升,分布式锁会变成"死锁制造者"
- 要是Leader节点宕机还没选举成功,整个集群都会陷入瘫痪
可现实中,很多开发者对Zookeeper的监控还停留在zkServer.sh status的层面------只能看个"活着没",根本不知道"健康吗?""要崩了吗?"。更头疼的是,就算想监控,也不清楚该盯哪些指标,或者怎么用主流工具(Prometheus+Grafana)搭一套可视化系统。
这篇文章就是要解决这些问题:
- 先讲"为什么":拆解Zookeeper的核心指标,告诉你每个指标背后的系统状态
- 再教"怎么做":从零开始用Prometheus采集指标、Grafana做可视化,搭一套能落地的监控系统
- 最后给"避坑指南":告诉你实践中会踩的坑,以及如何优化性能、配置告警
读完这篇,你能精准判断Zookeeper的健康状态,快速定位故障根源,甚至提前预防问题发生------让你的分布式系统"神经中枢"永远稳如老狗。
Zookeeper监控的核心逻辑:为什么这些指标重要?
在讲具体指标前,我们得先想清楚:监控Zookeeper到底要监控什么?
Zookeeper的本质是"高可用的分布式协调服务",它的核心能力是快速处理客户端请求+保持集群一致性。所以监控的核心逻辑就是:
客户端层面:能不能正常连接?请求是不是够快?
集群层面:Leader是不是稳定?数据同步有没有延迟?
资源层面:内存/CPU/磁盘是不是要爆了?
反过来想,如果这些维度出了问题,会直接导致Zookeeper"失效":
- 连接数满了→新客户端无法接入
- 请求延迟高→分布式锁超时→业务报错
- Leader频繁切换→集群无法处理写请求
- 内存OOM→Zookeeper进程崩溃→整个协调服务宕机
所以,我们的监控指标必须覆盖这三个维度------这也是接下来要讲的核心指标分类的依据。
核心概念扫盲:Zookeeper指标分类与Prometheus基础
在开始实战前,先统一一下"语言"------避免你看到指标时一脸懵。
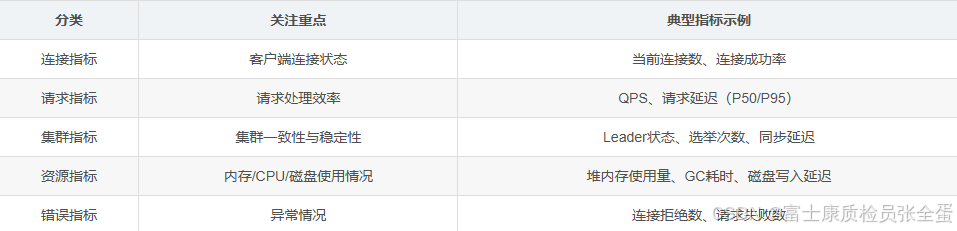
1. Zookeeper的指标分类
Zookeeper的指标可以分为5大类(对应监控的核心逻辑):
2. Prometheus的关键概念
Prometheus是一套开源的监控&告警系统,核心是"拉取(Pull)"指标------从目标服务的Exporter接口拿数据,然后存储、查询、告警。
你需要记住这几个概念:
Exporter:暴露指标的程序(Zookeeper 3.6.0+内置了Prometheus Exporter,不用额外装)
Target:要监控的目标(比如每个Zookeeper节点的Exporter地址:zk1:7000)
Job:一组Target的集合(比如"zookeeper集群"这个Job包含3个节点)
Metric类型:
Gauge(仪表盘):可以上下波动的指标(比如当前连接数)
Counter(计数器):只增不减的指标(比如总请求数)
Histogram(直方图):统计分布的指标(比如请求延迟的分布)
Summary(摘要):类似Histogram,但直接给出百分位数(比如P95延迟)
3. Grafana的核心作用
Grafana是可视化工具------它能把Prometheus里的"冰冷数字"变成"直观图表",比如:
- 用折线图看连接数的趋势;
- 用柱状图看不同请求类型的占比;
- 用仪表盘看堆内存的使用率。
环境准备:从Zookeeper到Prometheus+Grafana
先列一下需要安装的软件和版本(选稳定版就行):

分步实战:搭建Zookeeper监控系统
终于到了实战环节!我们分4步走:启用Exporter→采集指标→可视化→验证。
Step1:启用Zookeeper内置Prometheus Exporter
Zookeeper 3.6.0+最香的功能就是内置了Prometheus Exporter------不用再装第三方插件(比如jolokia+prometheus-jmx-exporter),直接改配置就行。
操作步骤:修改Zookeeper配置文件:
编辑/opt/zookeeper/conf/zoo.cfg,添加以下内容(开启Exporter并设置端口):
# 启用Prometheus指标暴露
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
# Exporter的HTTP端口(选个没被占用的,比如7000)
metricsProvider.httpPort=7000
# (可选)开启请求延迟统计(默认开启)
requestLatencyTrackingEnabled=true重启Zookeeper:
/opt/zookeeper/bin/zkServer.sh restart验证Exporter是否正常 :
用curl访问Exporter端口,能拿到指标说明成功:
curl http://localhost:7000/metrics会返回类似这样的结果(部分):
# HELP zookeeper_connections_current Current number of client connections
# TYPE zookeeper_connections_current gauge
zookeeper_connections_current 1
# HELP zookeeper_requests_total Total number of requests processed
# TYPE zookeeper_requests_total counter
zookeeper_requests_total{method="create"} 0
zookeeper_requests_total{method="get"} 12Step2:配置Prometheus采集Zookeeper指标
Prometheus的核心是prometheus.yml配置文件------我们需要告诉它"从哪里拉取指标"。
操作步骤:编辑Prometheus配置文件:打开/opt/prometheus/prometheus.yml,在scrape_configs下添加一个Job:
global:
scrape_interval: 15s # 每15秒采集一次指标(默认)
evaluation_interval: 15s # 每15秒评估一次告警规则(默认)
scrape_configs:
# 新增一个Job,名字叫"zookeeper"
- job_name: "zookeeper"
static_configs:
# 这里填Zookeeper节点的Exporter地址(多个节点用逗号分隔)
- targets: ["zk1:7000", "zk2:7000", "zk3:7000"]
# (可选)给这个Job的指标加个集群标签,方便多集群监控
labels:
cluster: "my-zookeeper-cluster"zk版本低于3.6.0监控指标采集
可以通过 zookeeper-exporter 下载zookeeper-exporter的安装包,并进行配置。
进程启动配置
./zookeeper-exporter -listen 0.0.0.0:7000 -zk-hosts Master:2181,Slave1:2181,Slave2:2181
nohup ./zookeeper-exporter -listen 0.0.0.0:7000 -zk-hosts 10.19.46.55:2181,10.19.46.56:2181,10.19.46.57:2181 > nohup.out 2>&1 &指标的暴露接口是7000,完成配置并重启zk后可以获取对应的指标。
curl localhost:7000/metrics
导入Zookeeper Dashboard
Grafana社区有很多现成的Zookeeper Dashboard,不用自己从零开始画。推荐用官方维护的Dashboard(ID:10465):
点左侧菜单栏的【Dashboards】→【Browse】→【Import】;在【Import via grafana.com】里输入10465,点【Load】;选择刚才配置的Prometheus数据源,点【Import】;导入成功后,就能看到完整的Zookeeper监控Dashboard了!
验证监控数据
现在,我们来模拟几个场景,看看监控系统能不能正常工作:
场景1:增加客户端连接数
用zkCli.sh连接Zookeeper,多开几个窗口:
/opt/zookeeper/bin/zkCli.sh -server localhost:2181然后看Grafana的"Current Connections"面板------连接数会跟着增加。
场景2:模拟高并发请求
用zkBench.sh(Zookeeper自带的压测工具)发请求:
/opt/zookeeper/bin/zkBench.sh -zookeeper localhost:2181 -operation get -count 10000看Grafana的"Requests per Second"(QPS)面板------QPS会飙升;再看"Request Latency (P95)"------延迟会跟着上升。
场景3:模拟Leader节点宕机
如果是集群环境,停掉Leader节点:
/opt/zookeeper/bin/zkServer.sh stop看Grafana的"Cluster Leader"面板------原来的Leader会变成0,新的Leader会变成1(集群会自动选举)。
关键指标深度解析:每个指标背后的"系统密码"
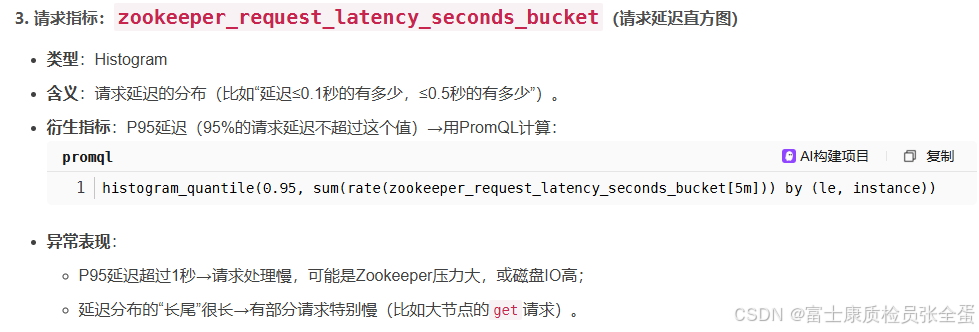
导入Dashboard后,你会看到很多指标,但不是每个都要盯------只需要关注"能反映系统状态的核心指标"。下面我挑10个最关键的指标,逐一解释它们的含义、异常表现和解决方法。





性能优化与最佳实践
搭建完监控系统后,还要做一些优化,让它更稳定、更好用。
1. 指标采集的优化
- 调整scrape间隔:默认15秒足够,不要太短(比如5秒)------会增加Zookeeper和Prometheus的压力;
- 过滤无用指标:如果某些指标你用不到,可以在Prometheus的Job配置里加metric_relabel_configs过滤(比如过滤掉zookeeper_gc_collection_seconds_total的Young GC指标);
- 用标签区分集群:如果有多个Zookeeper集群,给每个Job加cluster标签(比如cluster: "prod-zookeeper"),方便在Grafana里切换。
2. 监控系统的高可用
- Prometheus高可用:用Prometheus的联邦集群(Federation)------多个Prometheus实例采集同一组Target,然后把数据汇总到一个中心Prometheus;
- Grafana高可用:用Grafana的集群模式(Cluster Mode)------多个Grafana实例共享同一个数据库(比如PostgreSQL),保证单点故障不影响可视化。
然后创建alerting_rules.yml,添加Zookeeper的告警规则(示例):
groups:
- name: zookeeper_alerts
rules:
# 连接数过高(超过maxClientCnxns的80%)
- alert: ZookeeperHighConnectionCount
expr: zookeeper_connections_current > 800
for: 1m
labels:
severity: warning
annotations:
summary: "Zookeeper节点 {{ $labels.instance }} 连接数过高"
description: "{{ $labels.instance }} 的当前连接数为 {{ $value }},超过阈值800"
# 请求延迟过高(P95>1秒)
- alert: ZookeeperHighRequestLatency
expr: histogram_quantile(0.95, sum(rate(zookeeper_request_latency_seconds_bucket[5m])) by (le, instance)) > 1
for: 1m
labels:
severity: critical
annotations:
summary: "Zookeeper节点 {{ $labels.instance }} 请求延迟过高"
description: "{{ $labels.instance }} 的请求延迟P95为 {{ $value | humanizeDuration }},超过阈值1秒"
# 集群没有Leader
- alert: ZookeeperLeaderDown
expr: sum(zookeeper_cluster_leader) == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Zookeeper集群没有Leader"
description: "Zookeeper集群 {{ $labels.cluster }} 没有Leader,可能发生了选举故障"
alert: ZooKeeper server is down
expr: up == 0
for: 1m
labels:常见问题排查:踩过的坑都帮你填了

