目录
[3.1 视觉处理和感知器重采样器](#3.1 视觉处理和感知器重采样器)
[3.1.1 视觉编码器:从像素到特征](#3.1.1 视觉编码器:从像素到特征)
[3.1.2 感知器重采样器:从不同大小的大型特征映射到少数视觉token](#3.1.2 感知器重采样器:从不同大小的大型特征映射到少数视觉token)
[3.2 使用视觉表征作为冻结LM模型的条件控制](#3.2 使用视觉表征作为冻结LM模型的条件控制)
[3.2.1 门控GATED XATTN-DENSE层](#3.2.1 门控GATED XATTN-DENSE层)
[3.2.2 不同的模型尺寸](#3.2.2 不同的模型尺寸)
[3.3 支持多视觉输入:每个图像/视频的注意力mask](#3.3 支持多视觉输入:每个图像/视频的注意力mask)
[3.4 在视觉和语言混合数据集上进行训练](#3.4 在视觉和语言混合数据集上进行训练)
[3.5 基于few-shot的任务自适应上下文学习](#3.5 基于few-shot的任务自适应上下文学习)
论文:https://arxiv.org/pdf/2204.14198

1、摘要
通过构建少量标注示例使得模型能够迅速适应新任务,这是多模态机器学习研究中的一项开放性挑战。 我们推出了 Flamingo 这一系列具备这种能力的视觉语言模型(VLM)。我们提出了关键的结构创新:
(i)将强大的预训练纯视觉模型和纯语言模型相连接;
(ii)处理任意交错的视觉和文本数据序列;
(iii)无缝地将图像或视频作为输入。
得益于其灵活性,Flamingo 模型能够在包含任意交错文本和图像的大规模多模态网络语料库上进行训练,这是赋它们在上下文中few-shot学习能力的关键。我们对我们的模型进行了全面评估,探索并衡量了它们迅速适应各种图像和视频任务的能力。这些任务包括:
- 开放式任务,如视觉问答,即模型被提示一个问题并需要回答;
- 描述任务,用于评估描述场景或事件的能力;
- 以及封闭式任务,如多项选择的视觉问答。
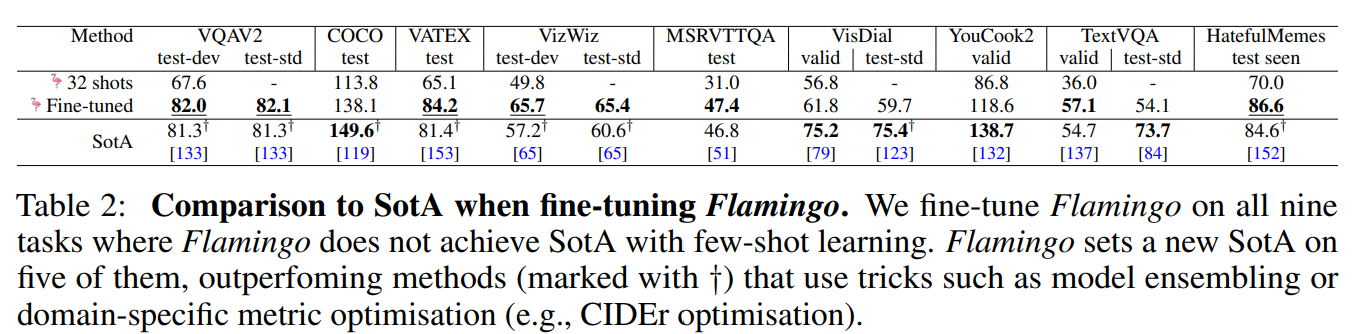
对于这个范围内的任何任务,只需用特定任务的示例提示 Flamingo 模型,它都可以通过few-shot学习实现新的SOTA。在众多基准测试中,Flamingo 的表现优于在数千倍特定任务数据上进行微调的模型。
2、引言
智能的一个关键在于,能够根据简短的指令迅速学会执行新任务。虽然在计算机视觉方面已经取得了类似的初步进展,但最广泛使用的范例仍然是首先在大量监督数据上进行预训练,然后再针对感兴趣的特定任务对模型进行微调。然而,成功的微调通常需要数千个标注数据点。此外,它往往需要针对每个任务进行细致的超参数调整,并且资源消耗也很大。最近,通过对比目标训练的多模态视觉语言模型实现了对新任务的zero-shot适应,无需进行微调。然而,由于这些模型只是提供文本和图像之间的相似度得分,它们只能处理有限的用例,比如事先提供有限结果集的分类任务。它们缺少的关键性能力是语言生成,这使得它们不太适合诸如图像描述或视觉问答等更开放的任务。其他人也探索了视觉条件下的语言生成,但在低数据量的情况下尚未展现出良好的性能。
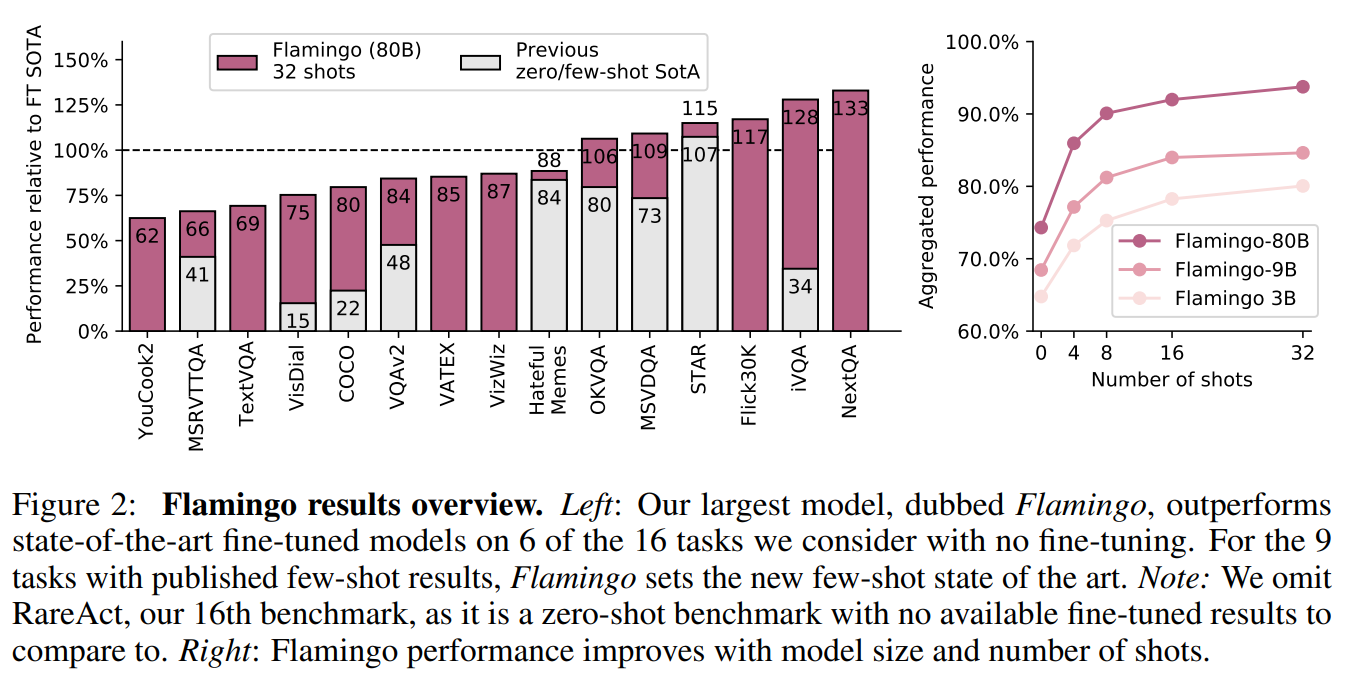
我们推出了 Flamingo,这是一个视觉语言模型(VLM),仅通过几个输入/输出示例的提示,就在广泛的开放式视觉和语言任务的few-shot学习中取得了SOTA。在我们考虑的16个任务中,Flamingo在6个任务上超越了经过微调的现有最佳水平,尽管它使用的特定任务训练数据要少几个数量级(参见图2)。
为了实现这一目标,Flamingo从最近的大型语言模型(LMs)研究中汲取灵感,这些模型是出色的 few-shot学习器。单个大型语言模型仅通过其文本接口就能在许多任务上取得出色表现:向模型提供任务的几个示例作为提示,再附上查询输入,模型生成该查询的预测输出。对于图像和视频理解任务,比如分类、描述或问答之类的,也可以采用同样的方法:这些任务可以被看作是带有视觉输入条件的文本预测问题 。与语言模型的不同之处在于该模型必须能够处理多模态提示,包含与文字交错的图像和/或视频。Flamingo 模型具备这种能力------它们是视觉条件下的自回归文本生成模型,能够处理文本标记与图像和/或视频交错的序列,并生成文本作为输出。Flamingo 模型利用了两个互补的预训练且冻结的模型:一个能够"感知"视觉场景的视觉模型和一个执行基本推理形式的大语言模型。并在这些模型之间添加了新的结构组件以连接视觉模型和大语言模型,以保存它们在预训练阶段学习到的知识。
我们的贡献如下:
- (i)我们引入了 Flamingo 系列视觉语言模型,它们仅通过少量的输入/输出示例就能执行各种多模态任务(例如图像描述、视觉对话或视觉问答)。得益于架构创新,Flamingo 模型能够高效地接受任意交错的视觉数据和文本作为输入,并以开放式的模式生成文本。
- (ii)我们定量评估了 Flamingo 模型如何通过少样本学习适应各种任务。我们特别保留了一大组未用于验证任何设计决策或超参数的基准测试集。我们使用这些基准测试集来估计无偏的少样本性能。
- (iii)Flamingo在 16 项多模态语言和图像/视频理解任务的少样本学习方面都取得了SOTA的成绩。在其中 6 项任务中,尽管仅使用了 32 个任务特定示例(约为现有最佳模型的 1000 分之一),Flamingo的表现仍优于经过微调的现有最佳模型。
3、方法
Flamingo的关键结构组件如图3所示,它被用来有效的桥接预训练的视觉和语言模型。
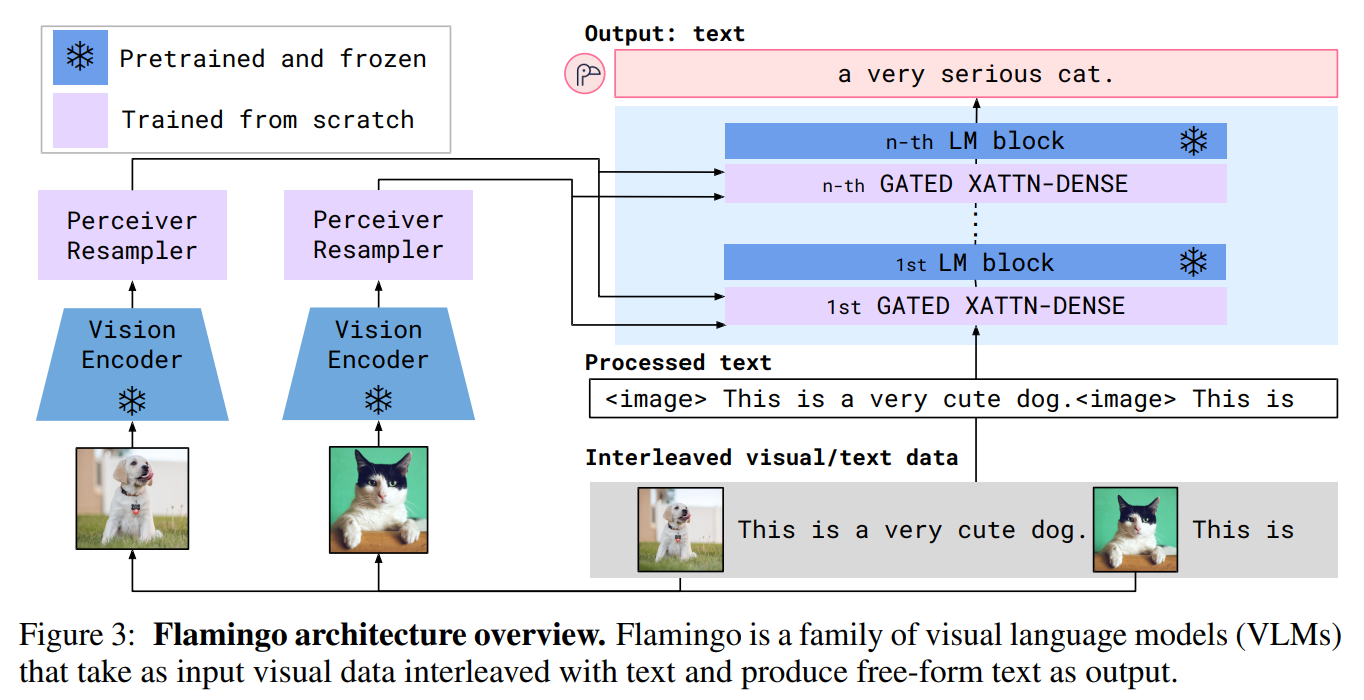
首先,感知器重新采样器从视觉编码器(从图像或视频中获得)接收时空特征,并输出固定数量的视觉token。其次,在LM层中使用新初始化的交叉注意力层,把这些视觉token作为条件,来调节冻结的LM。这些新层为LM提供了一种表达方式,对下一个token进行预测的任务中融合视觉信息(LM大都是自回归的形式,文字接龙)。图片或者视频用x来表示,文本用y来表示,Flamingo是在已知x的条件下,对y的可能性进行建模,如下所示:
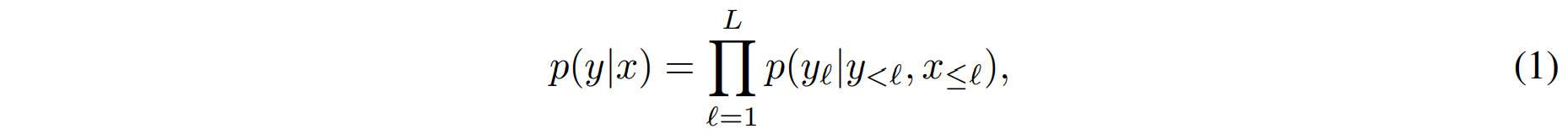
yℓ是是输入文本的第ℓ个语言token,y<ℓ是前面token的集合,x≤r为交错序列中标记yℓ之前的图像/视频集合,p由Flamingo模型参数化。
3.1 视觉处理和感知器重采样器
3.1.1 视觉编码器:从像素到特征
我们的视觉编码器是一个预训练,且参数冻结的NormalizerFree ResNet (NFNet) -我们使用F6模型。我们使用Radford等人的two-term contrastive loss,在图像和文本对的数据集上使用对比目标预训练视觉编码器。我们使用最后阶段的输出,并将一个二维空间网格的特征啦平为一维序列。对于视频输入,以每秒 1 帧的速率进行采样,并独立编码以获得一个 3D 空间 - 时间特征网格,然后向其中添加学习到的时间嵌入。然后特征被拉平为一维,然后被馈送到感知器重采样器。
3.1.2 感知器重采样器:从不同大小的大型特征映射到少数视觉token
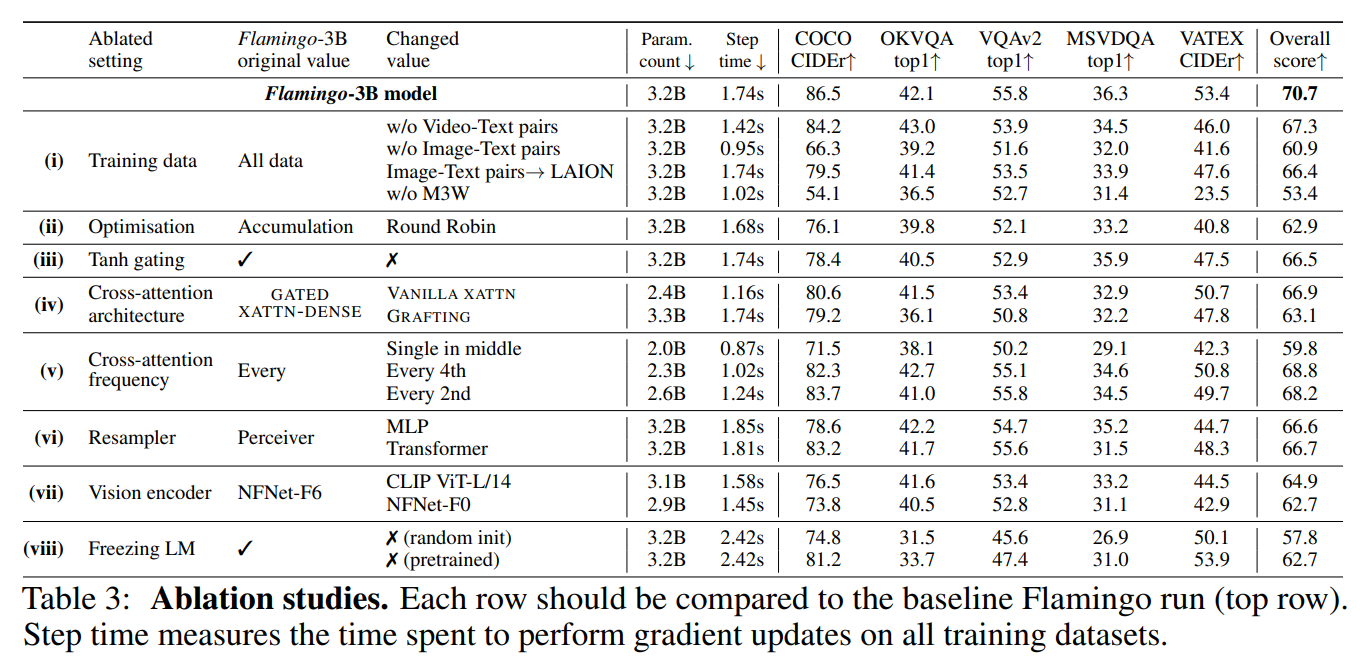
该模块将视觉编码器连接到图3所示的参数冻结的语言模型。它将来自视觉编码器的可变数量的图像或视频特征作为输入,并产生固定数量的视觉输出(64个),从而降低了视觉-文本交叉注意的计算复杂度。与Perceiver和DETR类似,我们学习预定义数量的潜在输入查询,这些查询被馈送到Transformer中,通过交叉注意力引入视觉特征。我们通过消融实验,验证了使用这种视觉语言重采样器模块优于只使用Transformer和MLP。
3.2 使用视觉表征作为冻结LM模型的条件控制
文本生成由一个Transformer解码器执行,由感知器重采样器产生的视觉表示作为条件。我们将预训练和冻结参数的纯文本LM块与从头开始训练的交叉注意力层来处理来自感知器重采样器的视觉输出。
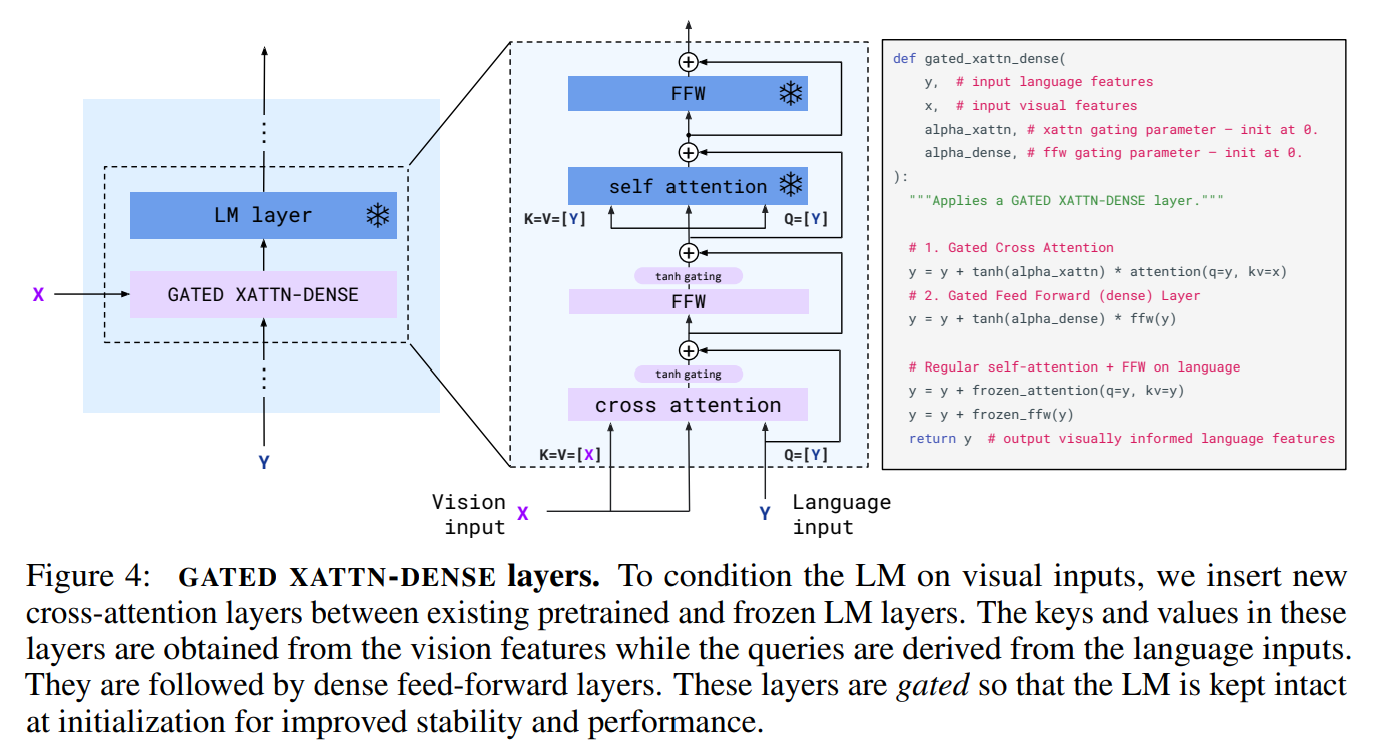
3.2.1 门控GATED XATTN-DENSE层
我们冻结预训练的LM块,并在原始层之间插入从头开始训练的门控交叉注意密集块(图4)。为了确保在初始化时,条件模型产生与原始语言模型相同的结果,我们使用了tanh-gating机制。这将新添加层的输出乘以tanh(α),然后将其添加到残差连接的输入表示中,其中α是初始化为0的特定层的可学习标量α。因此,在初始化时,模型输出与预训练LM的输出相匹配,提高了训练稳定性和最终表现。在消融研究中,我们将提出的门控XATTN-DENSE层与最近的替代方案进行了比较,并探讨了插入这些附加层的频率对效率和表达性之间权衡的影响。
3.2.2 不同的模型尺寸
我们在1.4B、7B和70B参数Chinchilla模型上进行了三种模型尺寸的实验,分别称为 Flamingo-3B, Flamingo-9B 和 Flamingo-80B。为简洁起见,我们将最后一个称为Flamingo。在增加冻结LM和可训练的视觉文本门控XATTN-DENSE模块的参数计数的同时,我们在不同的模型中保持固定大小的冻结视觉编码器和可训练的感知器重采样器(相对于完整的模型尺寸较小)。
3.3 支持多视觉输入:每个图像/视频的注意力mask
方程(1)中引入的图像因果模型是通过mask完整的文本到图像交叉注意矩阵获得的,这限制了模型在每个文本标记处看到的视觉token。对于给定的文本token,模型关注在交错序列中出现在它之前的图像的视觉标记,而不是之前的所有图像。虽然模型一次只直接关注一个图像,但对所有先前图像的依赖仍然通过LM中的自关注保持。重要的是,这种单图像交叉注意方案允许模型无缝地泛化到任何数量的视觉输入,而不管在训练期间使用了多少。特别是,当我们在交错数据集上训练时,每个序列最多只使用5张图像,但是在评估时,我们的模型能够从多达32对(或"shots")图像/视频和相应文本的序列中受益。
3.4 在视觉和语言混合数据集上进行训练
我们在三种数据集的混合上训练Flamingo模型,这些数据集都是网络数据:来自网页的交错图像和文本数据集,图像-文本对和视频-文本对。
3.5 基于few-shot的任务自适应上下文学习
一旦Flamingo被训练,我们就用它来处理一个视觉任务,通过多模态交错提示来控制它。我们评估了我们的模型使用上下文学习快速适应新任务的能力,类似于GPT-3,通过支持(图像,文本)或(视频,文本)形式的交错示例对,然后是查询视觉输入,以构建提示。我们通过使用来自任务的两个纯文本示例来提示模型,而没有相应的图像来探索zero-shot泛化能力。
4、结果