文章目录
- 本篇摘要
- [一.什么是LRU Cache](#一.什么是LRU Cache)
- [二、为什么需要LRU Cache?](#二、为什么需要LRU Cache?)
-
-
- [1. 缓存的核心价值](#1. 缓存的核心价值)
- [2. 缓存的容量瓶颈](#2. 缓存的容量瓶颈)
- [3. 淘汰策略的关键作用](#3. 淘汰策略的关键作用)
-
- [三.实现简易版的LRU Cache](#三.实现简易版的LRU Cache)
- 四.简单测试效果
- 五、LRU的应用场景
-
-
- [1. 操作系统](#1. 操作系统)
- [2. 数据库系统](#2. 数据库系统)
- [3. 网络与Web服务](#3. 网络与Web服务)
- [4. 编程与算法](#4. 编程与算法)
-
- 六、LRU的变种与改进
- 七、总结
- 八.本篇小结

本篇摘要
本篇将讲解LRU(最近最少使用)是经典缓存淘汰策略,通过双向链表+哈希表实现O(1)高效存取,优先保留高频数据、淘汰最久未使用数据,并模拟实现简单版本的LRU Cache,它广泛应用于操作系统、数据库、网络服务等场景,是缓存设计的核心技术。
一.什么是LRU Cache
LRU 是 Least Recently Used (最近最少使用) 的缩写;它是一种 Cache替换算法,即当Cache空间不足时,决定淘汰哪些数据的策略。
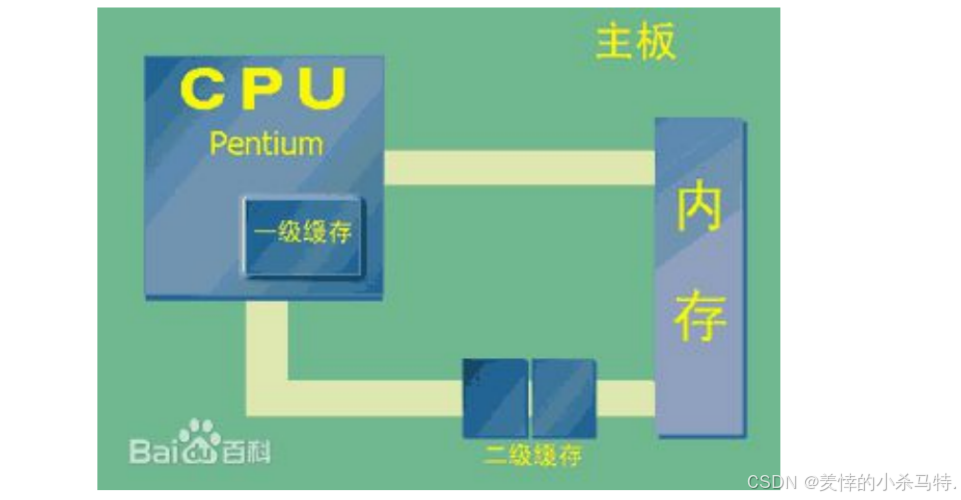
什么是Cache (狭义):
- 指的是位于 CPU和主存 (内存) 之间的
快速RAM。 - 与系统主存(通常使用DRAM技术)不同,Cache通常使用 昂贵但更快的SRAM技术。
什么是Cache (广义):
- 指的是位于 速度相差较大的两种硬件之间 ,用于 协调两者数据传输速度差异 的结构。
Cache的其他应用场景:
- 内存与硬盘 之间存在Cache。
- 硬盘与网络 之间也存在某种意义上的Cache,例如:Internet临时文件夹 或 网络内容缓存 等。
Cache容量有限,存满后需淘汰旧内容以容纳新内容;淘汰"最近最少使用"(即最久未使用)的内容;"LRU"直译为"最近最少使用",但"最久未使用"更直观,强调淘汰长时间未被访问的数据;通过优先保留高频访问数据,优化缓存效率。
二、为什么需要LRU Cache?
1. 缓存的核心价值
- 加速访问:缓存存放高频访问数据的副本,避免每次从低速存储(如磁盘、网络)中读取,显著降低延迟(例如内存访问速度比磁盘快百万倍)。
- 降低后端负载:减少对数据库、磁盘I/O或远程服务的直接请求,保护后端系统稳定性。
- 提升吞吐量:通过快速响应高频请求,提高系统整体处理能力。
2. 缓存的容量瓶颈
缓存的物理载体(如内存)通常容量有限但速度快(例如服务器内存几十GB,而需缓存的数据可能达TB级)。当缓存空间被占满时,必须通过淘汰策略清理部分数据,为新数据腾出空间。
3. 淘汰策略的关键作用
若无合理策略,缓存可能被低频或无效数据占满,导致高频数据无法留存,频繁触发从低速存储加载(即"缓存失效"),反而拖慢系统性能。LRU通过"优先淘汰最久未使用的数据"这一逻辑,平衡了空间利用率与访问效率。
三.实现简易版的LRU Cache
一开始可能会想到如果用对应map/哈希等来实现但是确实可以O(1)时间复杂度进行查询以及插入,但是LRU Cache的初衷(满额就淘汰不常使用的),因此需要时刻保持对应的热点数据与冷数据位置的更新维护,因此需要专门的维护它而且还要保证O(1)时间复杂度(也就是相对难的一点)。
实现LRU有很多版本或者模式:
- 经典链表 + 哈希表版:双向链表管访问顺序,头是新/热数据,尾是旧/冷数据;哈希表快速找节点,缓存满删尾插头,O(1)完成操作。
- 有序字典版:利用语言自带有序字典(如Python OrderedDict),自动按访问顺序排数据,缓存满时删最老项,代码简洁。
- 时间戳版:给每个缓存项记最后访问时间,要淘汰时遍历找最久没访问的(效率稍低,适合简单场景)。
但是如果实现出十分高效的也是十分困难的,下面就用C++实现一个经典LRU Cache的话,还是选择对应的list+unordered_map组合来实现;而基于std::list(双向链表)和std::unordered_map(哈希表)实现,代码简洁高效,是C++最常见的工业级实现方式;双向链表能在任意位置O(1)完成插入、删除;哈希表本身增删查改也都是O(1),俩搭配起来刚好满足需求。
实现LRU Cache:
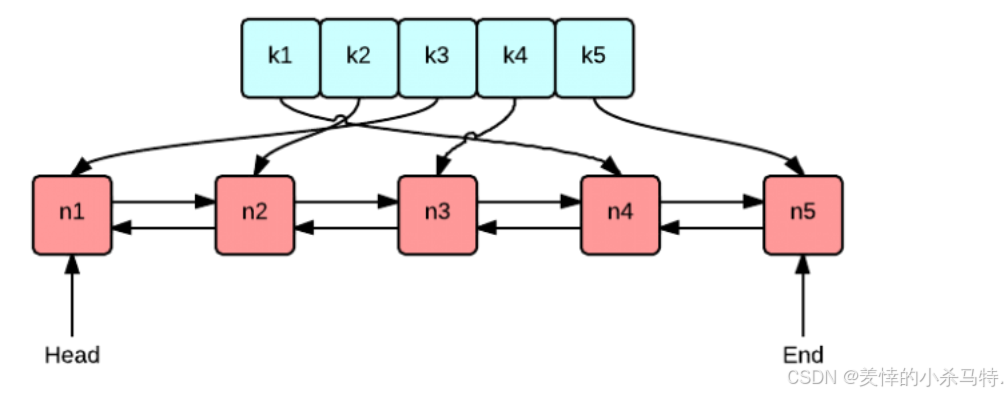
首先看下它们两个整合起来的数据结构。(上面哈希,下面双向链表,然后把对应常访问的数据按照顺序放在链表开头,不常用的按照顺序放在链表尾部)。
整体设计:
- 对应哈希中value保存的不是对应数据节点而是对应节点的在list中的迭代器(因为这样才能完成O(1)查找+添加+更新热点数据,来快速操作哈希与list)。
- 那么此时的list保存的不是简单的value,而还需要保存对应的key(比如删除对应冷数据的时候,list可以快速删除,那哈希如何快速删除(根本不知道对应的key),因此需要通过list尾部不仅能删除,冷数据而且还能获取对应key方便哈希进行指定节点数据删除)。
下面模拟提供对应的put与get接口进行对应访问:
1·get设计:
- 从LRU Cache中获取对应数据,首先数据是以节点的形式保存在这个list中,如果做到O(1)时间复杂度获取,也就是使用对应hash获取到对应链表对应数据节点位置,并且做到热点数据更新(也就是进行头插list)。
- LRU Cache中没有对应数据就返回对应没有的标记即可。
2·put设计:
- 进行数据插入,存在对应key值就进行覆盖插入并且更新热点数据维护,如果不存在直接构建整个数据(key-value)进行插入,还有中情况就是不存在但是容量满了,此时就用到LRU Cache的特色(删除冷数据进行空间增充)。
注意:
- 在进行热点数据更新的时候也就是维护这个list即把新访问或者新添加的数据搞到list的头部(热点维护在头部,冷点就默认自动跑到对应尾部了),此时就涉及到迭代器失效问题,也就是如果使用了erase的话对应节点的地址等就都被删除了(即迭代器在访问就会出问题,也就是hash保存的迭代器就会出问题)。
- 因此可以erase结合push_front一起使用,也就是进行热点数据更新的时候,先保存节点信息,然后erase,然后新构建节点插入对应信息进行push_front,然后再更新hash的value(迭代器)。
此时可以在更新热点数据的操作上优化一下,使用splice直接重连节点,这样可以不再造成对应析构构建重复操作,以及避免了迭代器失效问题:
splice是 C++ std::list提供的一个成员函数,用于 将一个链表中的元素(或单个元素)移动到另一个链表的指定位置,或者在本链表内移动元素,而且这个过程是 O(1) 时间复杂度、不需要拷贝或移动对象本身,只是修改指针链接关系。
cpp
_list.splice(_list.begin(), _list, it->second);解释这行代码的含义:
_list:当前维护的 LRU 双向链表,链表中每个节点是一个 pair<int, int>,表示 key-value。_list.begin():目标位置,表示要把某个节点移动到链表的最前面(即最近使用)。_list:源链表,也就是当前这个链表本身。
it->second:是一个 list<pair<int,int>>::iterator,指向链表中某个具体的节点(即你要移动的那个节点)。
那么为啥splice不会造成迭代器失效:
- 这里splice底层就是简单的进行节点的前后指针重新连接问题,就比如哈希保存的还是对应迭代器(可以理解成保存了对应lsit对应节点位置的指针),此时list进行splice完成头插后,然后哈希正常拿着对应value解引用还是能访问到对应原数据,只不过迭代器加减移动操作就不准确了(而通过哈希只是为了拿到一对应数据,这里不涉及对应迭代器加减操作)故此时使用splice是个很好的选择。
以int类型为例(这里简单版就不在实现模版话化了)的LRU Cache对象类:
cpp
#include<iostream>
#include<unordered_map>
#include<list>
using namespace std;
class LRUCache {
public:
using list_iter = list<pair<int, int>>::iterator;
LRUCache(int capacity) :_capacity(capacity) {
}
int get(int key) {
auto it = _hashmap.find(key);
if (it == _hashmap.end()) return -1;
else {
//如果存在直接返回,还要更新最近最少访问的链表:
//这里如果erase操作最后迭代器会失效,因此需要使用注意(删除节点后重新头插并更新map的记录)
// auto pair =*(it->second);
// _list.erase(it->second);
// _list.push_front(pair);
// _hashmap[pair.first]=_list.begin();
// return pair.second;
//这里是直接通过改变前后指针指向完成的,不涉及对应位置节点析构也就是erase迭代器失效问题
_list.splice(_list.begin(), _list, it->second);
return it->second->second;
}
}
void put(int key, int value) {
auto it = _hashmap.find(key);
if (it == _hashmap.end()) {
//进行插入:
if (_hashmap.size() >= _capacity) {
//满了进行删除不常用的再次插入(也就是尾删)
auto back = _list.back();
_list.pop_back();
_hashmap.erase(back.first);
}
//进行插入新数据
_list.push_front(make_pair(key, value));
_hashmap[key] = _list.begin();
}
else {
//进行更新:
it->second->second = value;
//这里如果erase操作最后迭代器会失效,因此需要使用注意(删除节点后重新头插并更新map的记录)
// auto pair =*(it->second);
// _list.erase(it->second);
// _list.push_front(pair);
// _hashmap[pair.first]=_list.begin();
_list.splice(_list.begin(), _list, it->second);
}
}
unordered_map<int, list_iter> _hashmap;//达o(1)复杂度快速找到节点+依据lru机制更新缓存中节点的哈希表
list<pair<int, int>> _list;//记录lru节点的链表
int _capacity;
};四.简单测试效果
1.基础功能 & LRU 淘汰机制:
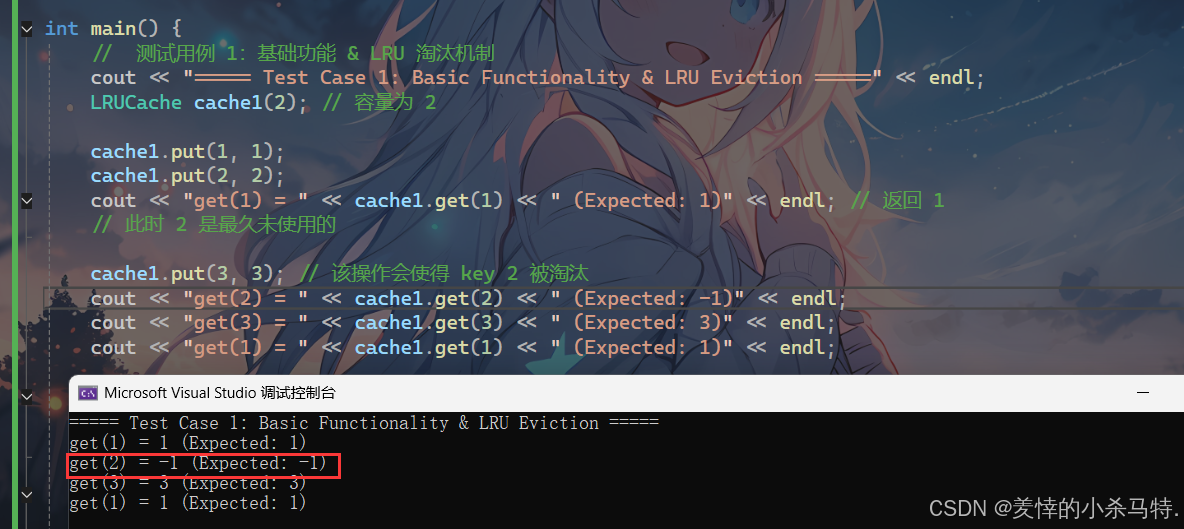
- 这里通过LRU的满额度的冷数据淘汰机制的显示,导致2被淘汰删除了。
2.更新已有 key 的值 & 移动到最近使用:
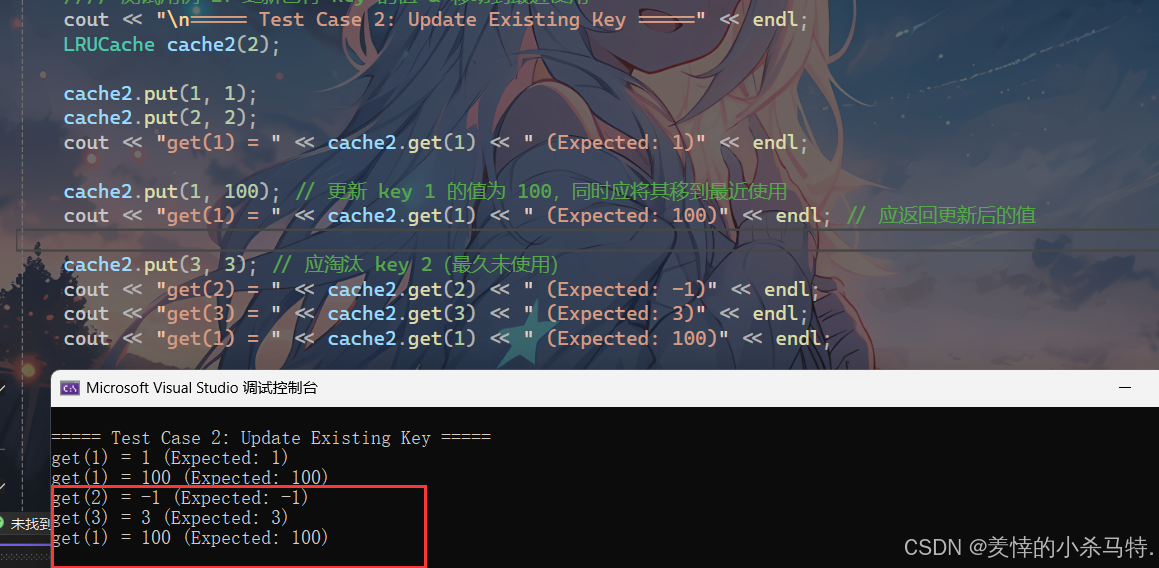
- 更新最新数据(存在key的模式)。
3.反复访问同一个 key的淘汰顺序:
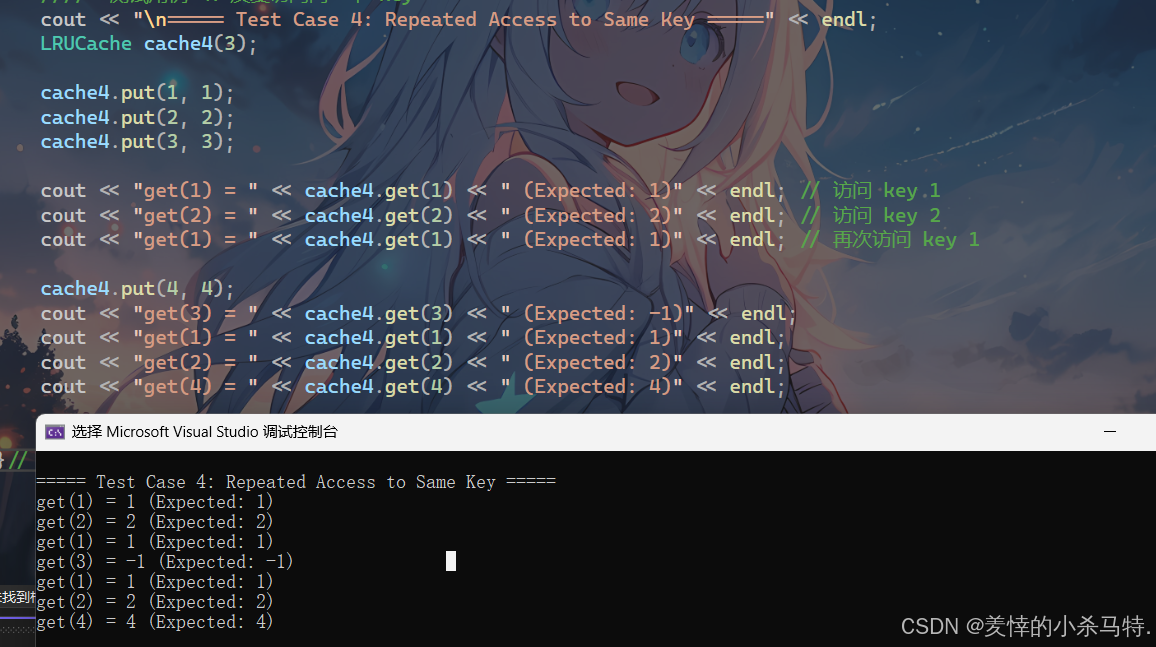
- 应淘汰 key 3(最久未使用:3 -> 2 -> 1 -> 4)。
五、LRU的应用场景
LRU是计算机科学中最经典的缓存策略之一,广泛应用于以下领域:
1. 操作系统
- 页面置换算法:当物理内存不足时,操作系统需将部分内存页换出到磁盘(如虚拟内存机制)。LRU及其变种(如LRU-K)常用于选择"最久未被访问的页面"换出,减少后续缺页中断概率。
- 文件系统缓存:缓存频繁访问的磁盘块或文件元数据,优先保留热点数据。
2. 数据库系统
- 缓冲池(Buffer Pool)管理:数据库(如MySQL、PostgreSQL)将磁盘数据页加载到内存缓冲池中,LRU用于决定哪些数据页保留、哪些淘汰,确保热点数据常驻内存。
- 查询结果缓存:缓存频繁执行的查询结果,加速重复查询响应。
3. 网络与Web服务
- 浏览器缓存:缓存用户访问过的网页资源(如HTML、CSS、JS、图片),优先保留最近浏览的内容,淘汰长期未访问的资源。
- CDN节点缓存:内容分发网络(CDN)的边缘节点缓存静态资源(如图片、视频),LRU管理节点存储空间,确保热门内容快速响应。
- 代理服务器缓存:企业级代理服务器(如Nginx)缓存后端服务响应,优化重复请求的处理效率。
4. 编程与算法
- 面试经典题目:LRU Cache是算法题中的高频考点(如LeetCode 146题),考察对哈希表、链表等数据结构的综合运用能力。
- 应用级缓存:开发者自实现的本地缓存(如用户会话信息、配置项)常采用LRU策略管理容量。
六、LRU的变种与改进
尽管LRU简单高效,但在某些特殊场景下可能存在局限性(例如突发访问模式导致"抖动"问题)。研究者提出了多种改进版本:
- LRU-K :不仅考虑最近一次访问,而是
记录最近K次访问的时间戳(例如LRU-2关注最近两次访问),通过更复杂的统计模型预测数据的未来访问概率。 - LFU(Least Frequently Used):淘汰访问频率最低的数据,适合长期热点数据稳定的场景(如经典歌曲、常用工具)。
- ARC(Adaptive Replacement Cache):动态结合LRU和LFU的优点,自动调整缓存策略以适应访问模式的变化。
- FIFO(First In First Out) :按数据进入缓存的顺序淘汰
最早进入的数据(简单但通常效果不如LRU)。
七、总结
LRU(最近最少使用)是一种以"访问时间"为核心判断依据的缓存淘汰策略,通过优先保留最近被访问的数据、淘汰最久未被使用的数据,在有限缓存容量下最大化访问命中率。它起源于操作系统页面置换的需求,现已成为数据库、网络服务、编程实践等领域的基础设施级技术,是理解缓存设计、系统性能优化与数据结构应用的核心知识点之一。
八.本篇小结
本文将带你学习LRU原理与C++实现(链表维护顺序、哈希表加速查找),展示put/get接口设计及splice优化技巧,结合测试案例与变种对比,带你走入LRU的世界。