前言:
首先我们得了解的是:MySQL 中的"库",本质上就是 Linux 文件系统中的一个"目录"
一:创建数据库
语法:create database if not exists db_name
说明:加上 if not exists 是一种防御性编程思维,防止脚本因为重复创建而报错中断
底层逻辑:执行后,在 /var/lib/mysql/ 目录下会同步生成一个同名目录 。

二:字符集和校验规则
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集 :utf8,校验规则 是:utf8_ general_ ci
1.字符集 (Charset):决定数据如何"存"。比如 UTF-8 或 GBK 。
2.校验集 (Collation):决定数据如何"比"。
3.匹配原则:如果建库时没指定,就继承 my.cnf 配置文件的全局设置;如果手动指定了,就以 SQL 语句为准 。
一些操作:
-
查看系统默认字符集以及校验规则:
show variables like 'character_set_database';
show variables like 'collation_database';
-
查看数据库支持的字符集
show charset;
-
查看数据库支持的字符集校验规则
show collation;
三:操纵数据库
1.查看数据库:
show databases;
2.显示创建语句:
show create database 数据库名;

/*!40100 default... */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
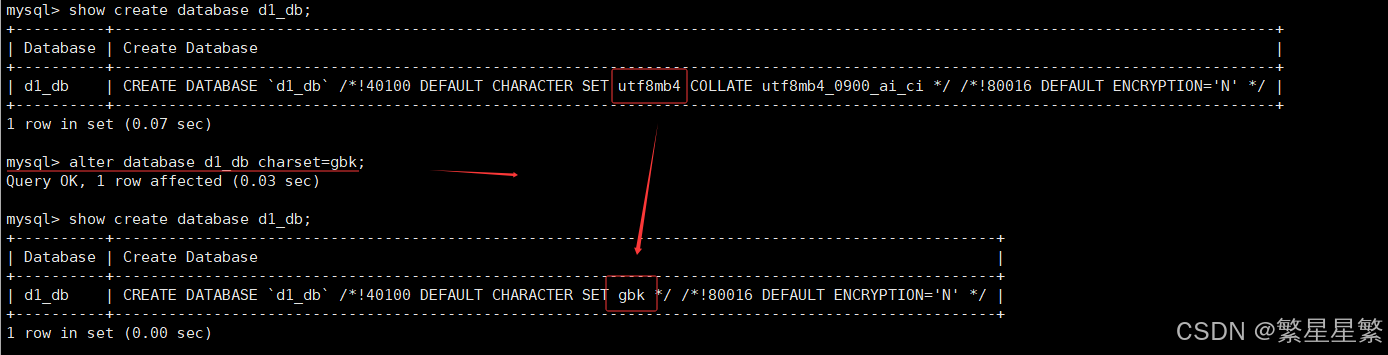
3.修改数据库
说明:对数据库的修改主要 指的是修改数据库的字符集,校验规则
alter database 数据库名称 charset=你想要改变的字符集
lter database d1_db charset=你想要改变的字符集 collate=校验规则;
4.数据库删除
语法:drop database if exists db_name
注意:删库等于 Linux 里的 rm -rf。数据无价,操作前必须备份,永远不要在生产环境盲目敲下这个词
5.备份
原理:备份的原理其实就是它备份的不是数据本身,而是**"重建这个库的所有历史 SQL 语句"**,使用 source 命令引入备份文件,本质是把历史 SQL 重新在服务器跑一遍,实现数据复现 。
cpp
# mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径参数解释:
1.mysqldump :这是客户端工具。它不是在"拷贝文件",而是通过 SQL 协议连接数据库,查出所有表结构和数据,然后生成对应的 CREATE TABLE 和 INSERT 语句。
2-P:.指定数据库实例的端口号
注意:大写的 P 是端口(Port),小写的 p 是密码(Password)。如果你的数据库监听的是默认端口 3306,这个参数可以省略
3.-u:指定的用户名字
4.-p:密码
注意 :在命令行里直接写 -p123456(注意 -p 和密码之间不能有空格)虽然方便,但很不安全。因为 ps -ef 命令(可以查看日志)可以看到你的明文密码。
5.-B:指定要备份的数据库名。
特殊作用:加上 -B 后,导出的 SQL 脚本中会包含 CREATE DATABASE IF NOT EXISTS 和 USE 语句。
优点:在恢复数据时,你不需要手动去 CREATE 一个空库,直接 source 脚本就行。
6.>:标准输出重定向,mysqldump 默认把生成的 SQL 内容打印到控制台(stdout)。通过 >,我们将这些字符流写入到指定的物理文件中。
操纵过程:

注意;这里不是在mysql里面,而是在外部
如果是备份一张表
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
6.还原
source /root/test.sql
7.查看连接情况
show processlist;
