1. 代码效果
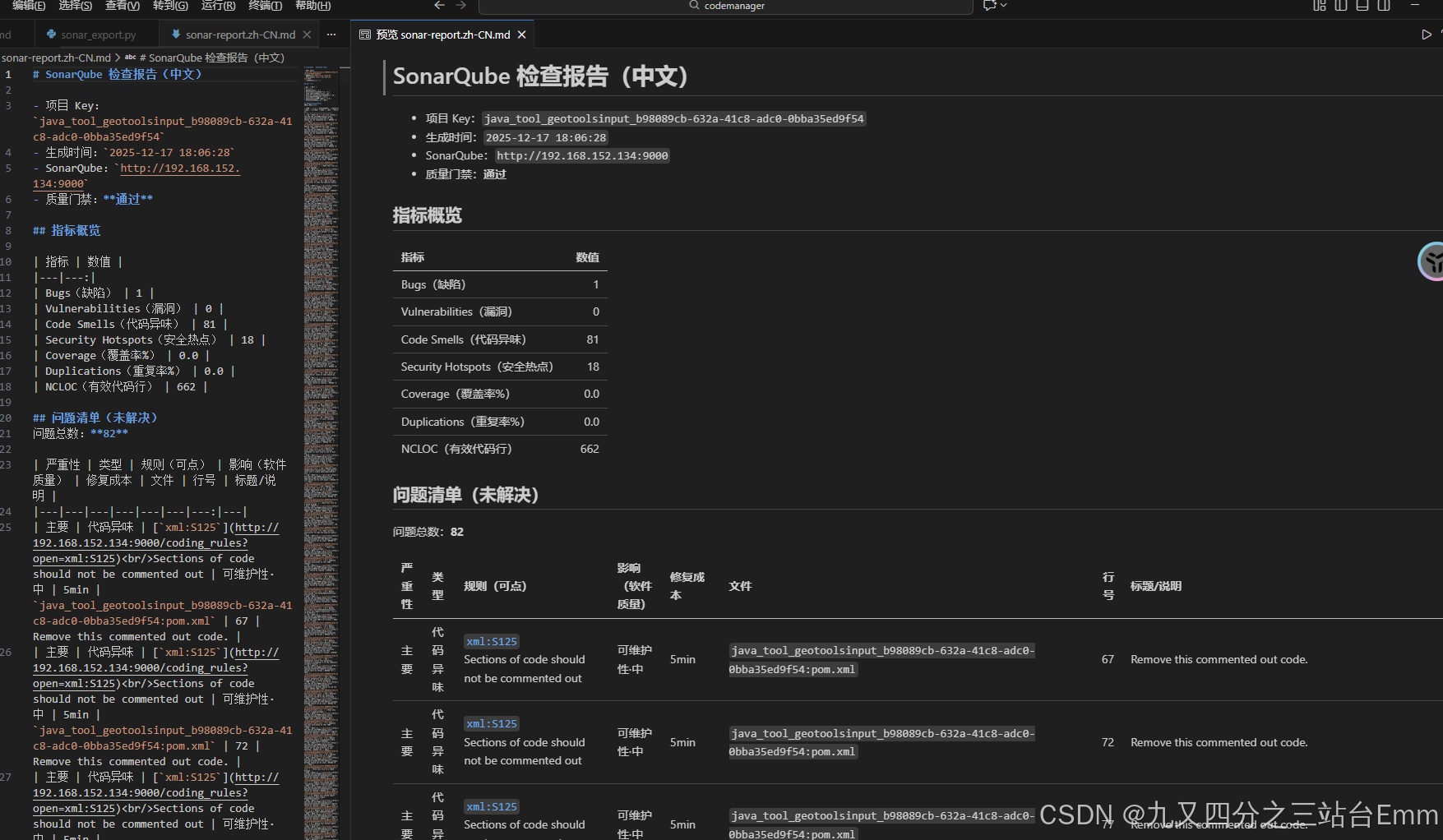
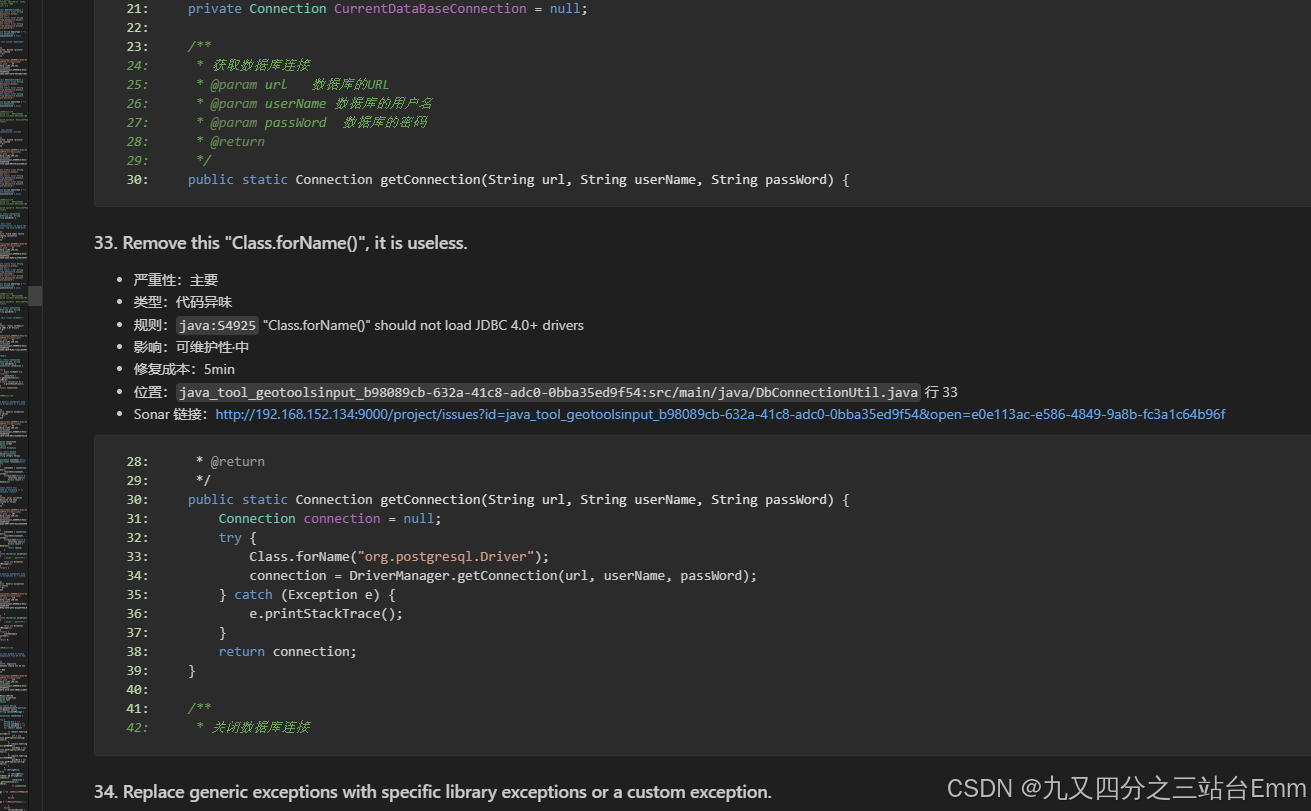
2. 代码处理过程
2.1. 流程图
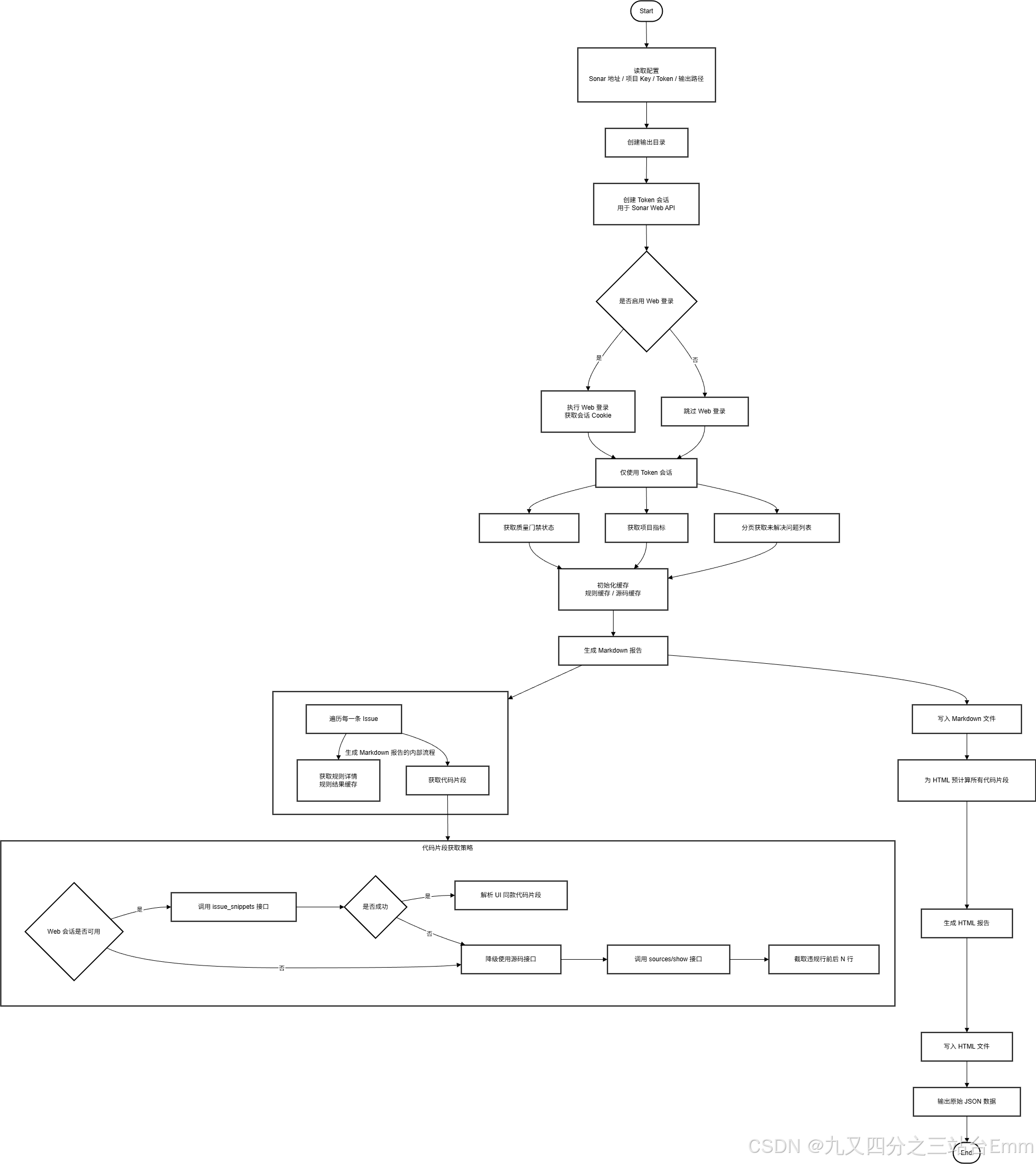
2.2. 流程图的Mermaid
flowchart TD
A([Start])
A --> B[读取配置<br/>Sonar 地址 / 项目 Key / Token / 输出路径]
B --> C[创建输出目录]
C --> D[创建 Token 会话<br/>用于 Sonar Web API]
D --> E{是否启用 Web 登录}
E -->|是| F[执行 Web 登录<br/>获取会话 Cookie]
E -->|否| G[跳过 Web 登录]
F --> H[Web 会话可用]
G --> H[仅使用 Token 会话]
H --> I[获取质量门禁状态]
H --> J[获取项目指标]
H --> K[分页获取未解决问题列表]
I --> L[初始化缓存<br/>规则缓存 / 源码缓存]
J --> L
K --> L
L --> M[生成 Markdown 报告]
M --> N[写入 Markdown 文件]
%% ========== Markdown 内部 ==========
subgraph S1[生成 Markdown 报告的内部流程]
S1a[遍历每一条 Issue]
S1a --> S1b[获取规则详情<br/>规则结果缓存]
S1a --> S1c[获取代码片段]
end
M --> S1
%% ========== 代码片段策略 ==========
subgraph S2[代码片段获取策略]
T1{Web 会话是否可用}
T1 -->|是| T2[调用 issue_snippets 接口]
T2 --> T3{是否成功}
T3 -->|是| T4[解析 UI 同款代码片段]
T3 -->|否| T5[降级使用源码接口]
T1 -->|否| T5
T5 --> T6[调用 sources/show 接口]
T6 --> T7[截取违规行前后 N 行]
end
S1c --> S2
N --> P[为 HTML 预计算所有代码片段]
P --> Q[生成 HTML 报告]
Q --> R[写入 HTML 文件]
R --> S[输出原始 JSON 数据]
S --> Z([End])3. 代码内容
3.1. 注意事项
- 注意修改
- SONAR_HOST = "http://192.168.152.134:9000"
- SONAR_USER = "admin"
- SONAR_PASS = "admin123456"
- PROJECT_KEY = "java_tool_geotoolsinput_b98089cb-632a-41c8-adc0-0bba35ed9f54"
- BRANCH = None # 如需分支: "main"
- SONAR_TOKEN = "sqp_437d1cb4b65080bad63f49a4ae244c82b4ba1390"
3.2. 代码内容
python
# -*- coding: utf-8 -*-
import math
import json
import html
import re
from html import unescape
from datetime import datetime
from pathlib import Path
from typing import Dict, List, Optional, Any, Tuple
import requests
# ======================================================
# 配置(⚠️ 技术可研:暂时写死)
# ======================================================
SONAR_HOST = "http://192.168.152.134:9000"
# ✅ Web 登录(用于拉 UI 同款 issue_snippets)
SONAR_USER = "admin"
SONAR_PASS = "admin123456"
PROJECT_KEY = "java_tool_geotoolsinput_b98089cb-632a-41c8-adc0-0bba35ed9f54"
BRANCH = None # 如需分支: "main"
# ✅ Token 通道(稳定,可拉指标/问题/规则等)
SONAR_TOKEN = "sqp_437d1cb4b65080bad63f49a4ae244c82b4ba1390"
OUT_DIR = Path(".")
MD_PATH = OUT_DIR / "sonar-report.zh-CN.md"
HTML_PATH = OUT_DIR / "sonar-report.zh-CN.html"
JSON_PATH = OUT_DIR / "sonar-report.raw.json"
# 代码片段上下文行数:违规行前后 N 行(你要的 ±5)
SNIPPET_CONTEXT = 5
# ======================================================
# 中文映射
# ======================================================
SEVERITY_CN = {
"BLOCKER": "阻断",
"CRITICAL": "严重",
"MAJOR": "主要",
"MINOR": "次要",
"INFO": "提示",
}
TYPE_CN = {
"BUG": "缺陷",
"VULNERABILITY": "漏洞",
"CODE_SMELL": "代码异味",
"SECURITY_HOTSPOT": "安全热点",
}
QUALITY_CN = {
"RELIABILITY": "可靠性",
"SECURITY": "安全性",
"MAINTAINABILITY": "可维护性",
"reliability": "可靠性",
"security": "安全性",
"maintainability": "可维护性",
}
IMPACT_LEVEL_CN = {
"LOW": "低",
"MEDIUM": "中",
"HIGH": "高",
"low": "低",
"medium": "中",
"high": "高",
}
# ======================================================
# Snippet HTML 处理(issue_snippets 返回的 code 带 <span> + HTML entity)
# ======================================================
SPAN_TAG_RE = re.compile(r"</?span[^>]*>")
def snippet_html_to_plain(text: str) -> str:
if not text:
return ""
text = SPAN_TAG_RE.sub("", text)
text = unescape(text)
return text
# ======================================================
# HTTP 基础
# ======================================================
def api_get(session: requests.Session, path: str, params: Optional[dict] = None) -> dict:
url = f"{SONAR_HOST}{path}"
r = session.get(url, params=params, timeout=60)
if r.status_code in (401, 403):
raise RuntimeError(f"[ERROR] GET 鉴权失败({r.status_code}):{url}\n{r.text[:500]}")
r.raise_for_status()
return r.json()
def get_cookie(session: requests.Session, name: str) -> Optional[str]:
for c in session.cookies:
if c.name == name:
return c.value
return None
# ======================================================
# Token 通道 API(稳定)
# ======================================================
def fetch_quality_gate(session: requests.Session) -> dict:
params = {"projectKey": PROJECT_KEY}
if BRANCH:
params["branch"] = BRANCH
return api_get(session, "/api/qualitygates/project_status", params)
def fetch_measures(session: requests.Session) -> dict:
metrics = ",".join(
[
"bugs",
"vulnerabilities",
"code_smells",
"security_hotspots",
"coverage",
"duplicated_lines_density",
"ncloc",
"reliability_rating",
"security_rating",
"sqale_rating",
]
)
params = {"component": PROJECT_KEY, "metricKeys": metrics}
if BRANCH:
params["branch"] = BRANCH
return api_get(session, "/api/measures/component", params)
def fetch_all_issues(session: requests.Session) -> List[dict]:
issues: List[dict] = []
params = {
"componentKeys": PROJECT_KEY,
"resolved": "false",
"ps": 500,
"p": 1,
}
if BRANCH:
params["branch"] = BRANCH
first = api_get(session, "/api/issues/search", params)
total = int(first.get("total", 0))
issues.extend(first.get("issues", []))
pages = max(1, math.ceil(total / 500))
for p in range(2, pages + 1):
params["p"] = p
data = api_get(session, "/api/issues/search", params)
issues.extend(data.get("issues", []))
return issues
def fetch_rule_detail(session: requests.Session, rule_key: str, cache: Dict[str, dict]) -> dict:
if rule_key in cache:
return cache[rule_key]
data = api_get(session, "/api/rules/show", {"key": rule_key})
rule = data.get("rule", {}) or {}
cache[rule_key] = rule
return rule
# sources/show:降级方案(拿纯源码行)
def fetch_sources_lines(session: requests.Session, component_key: str, cache: Dict[str, List[dict]]) -> List[dict]:
if not component_key:
return []
if component_key in cache:
return cache[component_key]
try:
data = api_get(session, "/api/sources/show", {"component": component_key})
lines = data.get("sources", []) or []
cache[component_key] = lines
return lines
except Exception:
cache[component_key] = []
return []
def fetch_code_snippet_by_sources_show(
session: requests.Session,
component_key: str,
line: Optional[int],
context: int,
sources_cache: Dict[str, List[dict]],
) -> str:
if not component_key or not line:
return ""
sources = fetch_sources_lines(session, component_key, sources_cache)
if not sources:
return ""
start = max(1, int(line) - context)
end = int(line) + context
snippet_lines = []
for s in sources:
ln = s.get("line")
code = s.get("code", "")
if ln is None:
continue
ln = int(ln)
if start <= ln <= end:
prefix = ">>" if ln == int(line) else " "
snippet_lines.append(f"{prefix}{ln:4d}: {code}")
return "\n".join(snippet_lines)
# ======================================================
# Web 登录 + issue_snippets(UI 同款代码块)
# ======================================================
def sonar_login_web(web_session: requests.Session) -> None:
url = f"{SONAR_HOST}/api/authentication/login"
headers = {
"Accept": "application/json",
"Content-Type": "application/x-www-form-urlencoded",
}
data = {"login": SONAR_USER, "password": SONAR_PASS}
r = web_session.post(url, headers=headers, data=data, timeout=60)
if r.status_code not in (200, 204):
raise RuntimeError(f"登录失败: HTTP {r.status_code}, body={r.text[:300]}")
jwt = get_cookie(web_session, "JWT-SESSION")
if not jwt:
raise RuntimeError("登录后未拿到 JWT-SESSION Cookie(可能登录失败或被策略拦截)")
# XSRF 有时会一起下发;没有的话,后续也许仍能用,或者你可先 GET 一次页面触发
xsrf = get_cookie(web_session, "XSRF-TOKEN")
if not xsrf:
# 触发一下页面,某些环境会在这里补发 XSRF
try:
web_session.get(f"{SONAR_HOST}/sessions/new", timeout=30)
except Exception:
pass
def fetch_issue_snippets_web(web_session: requests.Session, issue_key: str) -> Dict[str, Any]:
url = f"{SONAR_HOST}/api/sources/issue_snippets"
params = {"issueKey": issue_key}
xsrf = get_cookie(web_session, "XSRF-TOKEN") or ""
headers = {"Accept": "application/json"}
if xsrf:
headers["X-Xsrf-Token"] = xsrf
r = web_session.get(url, params=params, headers=headers, timeout=60)
if r.status_code == 403:
raise RuntimeError("403 Forbidden:issue_snippets 需要 Cookie 会话 + XSRF,或权限不足。")
r.raise_for_status()
return r.json()
def issue_snippets_payload_to_text_block(payload: Dict[str, Any]) -> Tuple[str, str]:
"""
把 issue_snippets 单文件 payload 转成纯文本代码块(含行号)
返回:(path, code_text)
"""
comp = payload.get("component", {}) or {}
path = comp.get("path") or comp.get("name") or (comp.get("key") or "")
lines = []
for row in payload.get("sources", []) or []:
ln = row.get("line")
code_html = row.get("code", "")
code_plain = snippet_html_to_plain(code_html)
if isinstance(ln, int):
lines.append(f"{ln:4d}: {code_plain}")
else:
lines.append(code_plain)
return path, "\n".join(lines)
# ======================================================
# Snippet 统一入口:优先 issue_snippets,失败降级 sources/show
# ======================================================
def guess_code_lang(component_key: str) -> str:
ck = (component_key or "").lower()
if ck.endswith(".java"):
return "java"
if ck.endswith(".xml"):
return "xml"
if ck.endswith(".yml") or ck.endswith(".yaml"):
return "yaml"
if ck.endswith(".sql"):
return "sql"
return ""
def get_issue_code_snippet(
issue: dict,
web_session: Optional[requests.Session],
token_session: requests.Session,
sources_cache: Dict[str, List[dict]],
) -> Tuple[str, str]:
"""
返回 (lang, snippet_text)
- 优先:issue_snippets(web_session)
- 降级:sources/show(token_session,±SNIPPET_CONTEXT)
"""
component = issue.get("component", "") or ""
line_no = issue.get("line")
issue_key = issue.get("key", "") or ""
# 1) 优先 issue_snippets(UI 同款)
if web_session is not None and issue_key:
try:
snips = fetch_issue_snippets_web(web_session, issue_key)
# 返回结构:{ "<componentKey>": {component:{...}, sources:[...]} }
# 通常只有一个 key;取第一个即可
for _k, payload in snips.items():
path, code_text = issue_snippets_payload_to_text_block(payload)
# issue_snippets 自带"范围行",通常已经类似截图内容
lang = guess_code_lang(path)
return lang, code_text
except Exception:
# 静默降级
pass
# 2) 降级 sources/show(前后 N 行)
if component and line_no:
code = fetch_code_snippet_by_sources_show(
session=token_session,
component_key=component,
line=int(line_no),
context=SNIPPET_CONTEXT,
sources_cache=sources_cache,
)
lang = guess_code_lang(component)
return lang, code
return "", ""
# ======================================================
# 格式化工具
# ======================================================
def cn_quality_gate(status: str) -> str:
if status == "OK":
return "通过"
if status == "ERROR":
return "未通过"
return status or "未知"
def safe_md(text: str) -> str:
if text is None:
return ""
return str(text).replace("\n", " ").replace("|", "\\|").strip()
def safe_html(text: str) -> str:
return html.escape("" if text is None else str(text))
def issue_ui_link(issue_key: str) -> str:
return f"{SONAR_HOST}/project/issues?id={PROJECT_KEY}&open={issue_key}"
def rule_ui_link(rule_key: str) -> str:
return f"{SONAR_HOST}/coding_rules?open={rule_key}"
def format_impacts(rule: dict) -> str:
impacts = rule.get("impacts")
if not impacts:
return "---"
parts = []
if isinstance(impacts, dict):
for k, v in impacts.items():
q = QUALITY_CN.get(k, str(k) or "")
lv = IMPACT_LEVEL_CN.get(v, str(v) or "")
if q:
parts.append(f"{q}·{lv}")
return "、".join(parts) if parts else "---"
if isinstance(impacts, list):
for item in impacts:
if not isinstance(item, dict):
continue
qk = item.get("softwareQuality") or item.get("quality") or item.get("key")
lv = item.get("severity") or item.get("level") or item.get("impact")
q = QUALITY_CN.get(qk, str(qk) if qk else "")
lv_cn = IMPACT_LEVEL_CN.get(lv, str(lv) if lv else "")
if q:
parts.append(f"{q}·{lv_cn}")
return "、".join(parts) if parts else "---"
return "---"
def format_remediation(rule: dict) -> str:
base = rule.get("remFnBaseEffort")
rtype = rule.get("remFnType")
gap = rule.get("remFnGapMultiplier")
coeff = rule.get("debtRemFnCoeff")
if base:
return f"{base}"
if isinstance(coeff, str) and coeff.strip():
return coeff.strip()
if rtype or gap:
return f"{rtype or ''}{(' / ' + gap) if gap else ''}".strip(" /")
return "---"
def strip_html_to_text(s: str) -> str:
if not s:
return ""
s = re.sub(r"<br\s*/?>", " ", s, flags=re.IGNORECASE)
s = re.sub(r"</p\s*>", " ", s, flags=re.IGNORECASE)
s = re.sub(r"<[^>]+>", "", s)
return re.sub(r"\s+", " ", s).strip()
# ======================================================
# Markdown 报告
# ======================================================
def build_markdown_report(
qg: dict,
measures: dict,
issues: List[dict],
rule_cache: Dict[str, dict],
token_session: requests.Session,
web_session: Optional[requests.Session],
sources_cache: Dict[str, List[dict]],
) -> str:
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
qg_status = qg.get("projectStatus", {}).get("status", "UNKNOWN")
metric_map = {}
for m in measures.get("component", {}).get("measures", []) or []:
metric_map[m.get("metric")] = m.get("value")
def mv(k: str) -> str:
return str(metric_map.get(k, ""))
lines = []
lines.append("# SonarQube 检查报告(中文)")
lines.append("")
lines.append(f"- 项目 Key:`{PROJECT_KEY}`")
if BRANCH:
lines.append(f"- 分支:`{BRANCH}`")
lines.append(f"- 生成时间:`{now}`")
lines.append(f"- SonarQube:`{SONAR_HOST}`")
lines.append(f"- 质量门禁:**{cn_quality_gate(qg_status)}**")
lines.append("")
lines.append("## 指标概览")
lines.append("")
lines.append("| 指标 | 数值 |")
lines.append("|---|---:|")
lines.append(f"| Bugs(缺陷) | {mv('bugs')} |")
lines.append(f"| Vulnerabilities(漏洞) | {mv('vulnerabilities')} |")
lines.append(f"| Code Smells(代码异味) | {mv('code_smells')} |")
lines.append(f"| Security Hotspots(安全热点) | {mv('security_hotspots')} |")
lines.append(f"| Coverage(覆盖率%) | {mv('coverage')} |")
lines.append(f"| Duplications(重复率%) | {mv('duplicated_lines_density')} |")
lines.append(f"| NCLOC(有效代码行) | {mv('ncloc')} |")
lines.append("")
conds = qg.get("projectStatus", {}).get("conditions", []) or []
if conds:
lines.append("## 质量门禁条件(Quality Gate Conditions)")
lines.append("")
lines.append("| 指标 | 条件 | 阈值 | 实际值 | 状态 |")
lines.append("|---|---|---:|---:|---|")
for c in conds:
metric = c.get("metricKey", "")
op = c.get("operator", "")
thr = c.get("errorThreshold", "")
actual = c.get("actualValue", "")
st = c.get("status", "")
lines.append(f"| {metric} | {op} | {thr} | {actual} | {st} |")
lines.append("")
lines.append("## 问题清单(未解决)")
lines.append(f"问题总数:**{len(issues)}**")
lines.append("")
lines.append("| 严重性 | 类型 | 规则(可点) | 影响(软件质量) | 修复成本 | 文件 | 行号 | 标题/说明 |")
lines.append("|---|---|---|---|---|---|---:|---|")
for it in issues:
rule_key = it.get("rule", "")
rule = fetch_rule_detail(token_session, rule_key, rule_cache) if rule_key else {}
severity_cn = SEVERITY_CN.get(it.get("severity"), it.get("severity") or "")
type_cn = TYPE_CN.get(it.get("type"), it.get("type") or "")
rule_name = rule.get("name", "") or ""
impacts_cn = format_impacts(rule)
remediation = format_remediation(rule)
component = it.get("component", "") or ""
line_no = it.get("line") or ""
message = it.get("message", "") or ""
rule_link = rule_ui_link(rule_key) if rule_key else ""
rule_cell = f"[`{safe_md(rule_key)}`]({rule_link})"
if rule_name:
rule_cell += f"<br/>{safe_md(rule_name)}"
lines.append(
"| {sev} | {typ} | {rule} | {imp} | {rem} | `{file}` | {line} | {msg} |".format(
sev=safe_md(severity_cn),
typ=safe_md(type_cn),
rule=rule_cell,
imp=safe_md(impacts_cn),
rem=safe_md(remediation),
file=safe_md(component),
line=safe_md(line_no),
msg=safe_md(message),
)
)
lines.append("")
lines.append(f"## 问题详情(含代码片段:优先 UI 同款,否则降级为前后 {SNIPPET_CONTEXT} 行)")
lines.append("")
for idx, it in enumerate(issues, start=1):
rule_key = it.get("rule", "")
rule = fetch_rule_detail(token_session, rule_key, rule_cache) if rule_key else {}
severity_cn = SEVERITY_CN.get(it.get("severity"), it.get("severity") or "")
type_cn = TYPE_CN.get(it.get("type"), it.get("type") or "")
rule_name = rule.get("name", "") or ""
impacts_cn = format_impacts(rule)
remediation = format_remediation(rule)
component = it.get("component", "") or ""
line_no = it.get("line")
message = it.get("message", "") or ""
issue_key = it.get("key", "") or ""
lines.append(f"### {idx}. {safe_md(message)}")
lines.append(f"- 严重性:{safe_md(severity_cn)}")
lines.append(f"- 类型:{safe_md(type_cn)}")
lines.append(f"- 规则:`{safe_md(rule_key)}` {safe_md(rule_name)}")
lines.append(f"- 影响:{safe_md(impacts_cn)}")
lines.append(f"- 修复成本:{safe_md(remediation)}")
lines.append(f"- 位置:`{safe_md(component)}` 行 {line_no if line_no else ''}")
if issue_key:
lines.append(f"- Sonar 链接:{issue_ui_link(issue_key)}")
lines.append("")
lang, snippet = get_issue_code_snippet(it, web_session, token_session, sources_cache)
if snippet:
# issue_snippets 通常范围更大;sources/show 是 ±N 行并带 >> 标记
lines.append(f"```{lang}".rstrip())
lines.append(snippet)
lines.append("```")
else:
lines.append("> (无法获取源码片段:可能权限不足,或分析未保存源码。)")
lines.append("")
lines.append("## 规则说明(抽取本次用到的规则)")
lines.append("")
used_rules = sorted({it.get("rule") for it in issues if it.get("rule")})
for rk in used_rules:
rule = fetch_rule_detail(token_session, rk, rule_cache)
name = rule.get("name", "") or ""
impacts_cn = format_impacts(rule)
remediation = format_remediation(rule)
desc = strip_html_to_text(rule.get("htmlDesc", "") or "")
desc_short = (desc[:220] + "...") if len(desc) > 220 else desc
lines.append(f"### `{rk}` {name}")
lines.append(f"- 影响:{impacts_cn}")
lines.append(f"- 修复成本:{remediation}")
if desc_short:
lines.append(f"- 说明:{safe_md(desc_short)}")
lines.append(f"- 规则链接:{rule_ui_link(rk)}")
lines.append("")
return "\n".join(lines)
# ======================================================
# HTML 报告(表格 + 内嵌代码片段)
# ======================================================
def build_html_report(md_text: str, issues: List[dict], rule_cache: Dict[str, dict], issue_snippets: Dict[str, str]) -> str:
rows = []
for it in issues:
rule_key = it.get("rule", "") or ""
rule = rule_cache.get(rule_key, {}) if rule_key else {}
sev = SEVERITY_CN.get(it.get("severity"), it.get("severity") or "")
typ = TYPE_CN.get(it.get("type"), it.get("type") or "")
rule_name = rule.get("name", "") or ""
impacts_cn = format_impacts(rule)
remediation = format_remediation(rule)
component = it.get("component", "") or ""
line_no = it.get("line") or ""
message = it.get("message", "") or ""
issue_key = it.get("key", "") or ""
issue_link = issue_ui_link(issue_key) if issue_key else ""
rule_link = rule_ui_link(rule_key) if rule_key else ""
rule_name_html = f"<div class='sub'>{safe_html(rule_name)}</div>" if rule_name else ""
open_html = f"<a href='{safe_html(issue_link)}' target='_blank'>打开</a>" if issue_link else "---"
code_block = issue_snippets.get(issue_key, "")
code_html = f"<pre class='code'>{safe_html(code_block)}</pre>" if code_block else "<div class='small'>(无源码片段)</div>"
row = (
"<tr>"
f"<td>{safe_html(sev)}</td>"
f"<td>{safe_html(typ)}</td>"
f"<td><a href='{safe_html(rule_link)}' target='_blank'>{safe_html(rule_key)}</a>{rule_name_html}</td>"
f"<td>{safe_html(impacts_cn)}</td>"
f"<td>{safe_html(remediation)}</td>"
f"<td><code>{safe_html(component)}</code></td>"
f"<td class='num'>{safe_html(line_no)}</td>"
f"<td>{safe_html(message)}{code_html}</td>"
f"<td>{open_html}</td>"
"</tr>"
)
rows.append(row)
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
branch_html = f" 分支:<code>{safe_html(BRANCH)}</code>" if BRANCH else ""
return f"""<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1"/>
<title>SonarQube 检查报告(中文)</title>
<style>
body {{ font-family: system-ui, -apple-system, "Segoe UI", Arial, sans-serif; margin: 24px; color: #111; }}
h1 {{ margin: 0 0 8px 0; }}
.meta {{ color:#555; margin: 0 0 16px 0; line-height: 1.6; }}
table {{ border-collapse: collapse; width: 100%; }}
th, td {{ border: 1px solid #e5e7eb; padding: 10px; vertical-align: top; }}
th {{ background: #f8fafc; text-align: left; }}
td.num {{ text-align: right; white-space: nowrap; }}
.sub {{ color:#555; margin-top: 4px; font-size: 12px; line-height: 1.4; }}
.small {{ font-size: 12px; color:#666; }}
.hr {{ height:1px; background:#eee; margin: 18px 0; }}
details pre {{ white-space: pre-wrap; word-wrap: break-word; background:#f6f8fa; padding: 12px; border-radius: 10px; }}
code {{ font-family: ui-monospace, SFMono-Regular, Menlo, Consolas, "Liberation Mono", monospace; font-size: 12px; }}
pre.code {{
white-space: pre-wrap;
word-wrap: break-word;
background:#0b1020;
color:#e6edf3;
padding: 10px;
border-radius: 10px;
margin-top: 8px;
font-size: 12px;
line-height: 1.45;
}}
</style>
</head>
<body>
<h1>SonarQube 检查报告(中文)</h1>
<div class="meta">
<div>生成时间:<code>{safe_html(now)}</code></div>
<div>项目 Key:<code>{safe_html(PROJECT_KEY)}</code>{branch_html}</div>
<div>SonarQube:<code>{safe_html(SONAR_HOST)}</code></div>
<div class="small">说明:本报告自动内嵌每条问题的源码片段(优先 UI issue_snippets,否则降级为 sources/show 前后 {SNIPPET_CONTEXT} 行)。</div>
</div>
<div class="hr"></div>
<h2>问题清单(未解决)</h2>
<div class="small">总计:{len(issues)} 条</div>
<br/>
<table>
<thead>
<tr>
<th>严重性</th>
<th>类型</th>
<th>规则</th>
<th>影响(软件质量)</th>
<th>修复成本</th>
<th>文件</th>
<th>行号</th>
<th>标题/说明(含代码片段)</th>
<th>打开</th>
</tr>
</thead>
<tbody>
{''.join(rows) if rows else '<tr><td colspan="9">无未解决问题</td></tr>'}
</tbody>
</table>
<div class="hr"></div>
<details>
<summary>展开:Markdown 原文(便于复制到 Obsidian)</summary>
<pre>{safe_html(md_text)}</pre>
</details>
</body>
</html>
"""
# ======================================================
# main
# ======================================================
def main():
OUT_DIR.mkdir(parents=True, exist_ok=True)
# 1) Token Session(稳定)
token_session = requests.Session()
token_session.auth = (SONAR_TOKEN, "")
# 2) Web Session(用于 issue_snippets,可失败,失败则只用 token 降级)
web_session: Optional[requests.Session] = None
try:
ws = requests.Session()
sonar_login_web(ws)
web_session = ws
print("[INFO] Web 登录成功:将启用 issue_snippets 代码片段。")
except Exception as e:
print(f"[WARN] Web 登录失败,将降级仅用 Token 通道获取代码片段(sources/show):{e}")
# 3) 拉取数据
qg = fetch_quality_gate(token_session)
measures = fetch_measures(token_session)
issues = fetch_all_issues(token_session)
rule_cache: Dict[str, dict] = {}
sources_cache: Dict[str, List[dict]] = {}
# 4) 生成 Markdown(内部会为每条 issue 拉 snippet)
md = build_markdown_report(
qg=qg,
measures=measures,
issues=issues,
rule_cache=rule_cache,
token_session=token_session,
web_session=web_session,
sources_cache=sources_cache,
)
MD_PATH.write_text(md, encoding="utf-8")
# 5) 为 HTML 预计算每条 issue 的 snippet(按 issue_key 存)
issue_snippets: Dict[str, str] = {}
for it in issues:
issue_key = it.get("key", "") or ""
if not issue_key:
continue
lang, snippet = get_issue_code_snippet(it, web_session, token_session, sources_cache)
if snippet:
issue_snippets[issue_key] = snippet
html_doc = build_html_report(md, issues, rule_cache, issue_snippets)
HTML_PATH.write_text(html_doc, encoding="utf-8")
# 6) Raw JSON
JSON_PATH.write_text(
json.dumps(
{
"projectKey": PROJECT_KEY,
"branch": BRANCH,
"sonarHost": SONAR_HOST,
"qualityGate": qg,
"measures": measures,
"issues": issues,
"rules": rule_cache,
"snippetsContext": SNIPPET_CONTEXT,
"snippetsSource": "issue_snippets(web) preferred, fallback sources/show(token)",
},
ensure_ascii=False,
indent=2,
),
encoding="utf-8",
)
print("✔ 报告生成完成:")
print(f" - {MD_PATH.name}")
print(f" - {HTML_PATH.name}")
print(f" - {JSON_PATH.name}")
if __name__ == "__main__":
main()