prompt
Prompt定义
Prompt 就是你发给大模型的指令,比如编写某个故事、讲个笑话、写份报告等。
貌似简单,但意义非凡
- prompt 是 AGI 时代的编程语言。
- prompt 工程是 AGI 时代的软件工程。
- prompt 工程师是 AGI 时代的程序员。
学会 prompt 工程门槛低,天花板高,所以有人戏称 prompt 为咒语。
prompt 调优
找到好的 prompt 是个持续迭代的构成,需要不断调优。
如果知道训练数据是怎样的,参考训练数据来构造 prompt 是最好的。
- 把 AI 当人看: 你知道ta爱度西游记,就和ta聊西游记。
- 不知道训练数据怎么办? 看ta是否主动告诉你。例如 OpenAI 的 GPT 对 Markdown 格式友好
- 还有一种方法就是不断尝试。有时一字之差,对token生成概率的影响都可能是很大的,也可能毫无影响。
试是常用方法,确实有运气因素,所以门槛低、天花板高。
高质量 prompt 核心要点:指令具体、信息丰富、尽量少歧义
prompt的典型构成
不要固守模版。模版的价值是提醒我们别漏掉什么,而不是必须遵守才行。
- 角色:给AI定义一个最匹配任务的角色,比如:你是一位 Python 大师
- 指示:对任务进行描述
- 上下文:给出与任务相关的其他背景信息(尤其在多轮交互中)
- 例子:必要时给出距离,学术中成为 one-shot learninig, few-shot learninig 或 in-context learninig;实践证明其对输出正确性有很大帮助
- 输入:任务的输入信息;在提示词中明确的标识出输入。
- 输出:输出的格式描述,以便后续模块自动解析模型的输出结果,比如(JSON、XML)
大模型对prompt开头和结尾的内容更敏感,先定义角色,其实就是在开头把问题域收窄,减少二义性。
LangChain 开发框架
LangChain 定义
LangChain 是一个开源框架,旨在帮助开发者利用大语言模型(LLM)构建智能应用程序
它通过提供模块化的工具和组件,使得开发者能够轻松集成外部数据、上下文记忆和工具调用,从而增强LLM的能力。
截止2024年4月,LangChain 的最新版本为 v0.3。该框架支持 Python 和 JavaScript 两种主要编程语言,官方文档地址以为: https://python.langchain.com/docs/introduction/
LCEL 定义
LCEL(LangChain Expression Language,LangChain 表达式语言)是 LangChain 框架中的一种声明式语音,最初被称为 "chain",用于简化和灵活地组合 LLM 的调用流程。
它通过定义一系列操作步骤(称为链,chain),将输入处理、模型调用和输出生成整合为一个可配置的管道。LCEL 的主要特点包括:
- 支持流式输出: 允许实时处理和输出结果,适用于需要低延迟的场景。
- 异步支持: 提供异步执行能力,提升大规模任务的效率。
- 优化的并行执行: 支持多个任务同时运行,较少等待时间。
- 重试和回退: 内置错误处理机制,确保链的鲁棒性。
- 访问中间结果: 开发者可以在链的任意阶段获取中间输出,便于调试和优化
- 输入和输出模式: 支持定义严格的输入和输出格式,确保一致性
- 无缝LangSmith跟踪集成: 与LangSmith平台紧密结合,便于监控和评估
- 无缝LangServe部署集成: 支持将链部署为 REST API,简化生成环境集成
LCEL 的设计目的是让开发者能够以生命的方式快速构建复杂的 LLM 工作流,同时保持高度的可定执行和可扩展性。
LangSmith
LangChain 不仅仅是一个独立的框架,它还与一系列相关工具(如 LangSmith、LangServe和LangGraph)共同构成了一个完整的开发生态系统。
这些工具相互协作,覆盖了从开发、调试到部署的整个生命周期,进一步提升了基于大语音模型(LLM)的应用程序构建效率。
LangSmith是一个专门为生产级LLM应用程序设计的平台,旨在帮助开发者监控、调试和优化基于LangChain的应用,官方文档地址: https://docs.smith.langchain.com 。
LangSmith的主要功能包括:
- 实时监控:实时跟踪 LLM 的输入、输出和性能指标
- 评估工具:提供测试和基准工具,帮助开发者评估模型的准确性和可靠性
- 调试支持:记录中间步骤和日志,便于定位问题
- 版本管理:支持对模型和链的版本控制,便于迭代开发
- 协作功能:允许多人团队共同管理和优化应用
LangSmith 与 LangChain 和 LCEL 无缝集成,是构建健壮、可扩展 LLM 应用的重要工具,尤其适用于需要上线部署和持续优化的场景。
Gradio
Gradio 是一个开源的 Python 库,旨在简化大模型应用程序的部署和演示。它提供了一个用户友好的界面,使开发者能够快速构建和分享交互式应用。
官网地址: https://www.gradio.app
以下是 Gradio 的一些主要特点:
- 简单易用:Gradio 的 API 设计非常直观,用户可以用几行代码创建应用,无需前段开发经验。
- 支持多种输入输出:Gradio 支持多种类型的输入(文本、图形、音频、视频等)和输出,方便用户与模型交互。
- 实时预览:用户可以实时查看模型的输出,方便调试和展示。
- 分享和部署:生成的应用可以通过链接共享,甚至可以在本地服务器上运行,使团队合作和用户反馈变得更加简单。
- 集成友好:Gradio 可以与多种机器学习框架(如 TensorFlow、Pytorch、Scikit-Learn 等)轻松集成,支持将已有模型快速转换为交互式应用。
- 自定义界面:用户可以通过Gradio 的组件自定义界面,调整布局和样式,以满足特定需求
通过 Gradio ,开发者能够快速展示他们的大模型应用,收集用户反馈,从而更好地优化和改进模型。
思维链
什么是思维链
思维链是一种大模型在处理复杂问题时,通过显式地分解问题、逐步推理,最终得出答案的推理能力。它的核心在于让模型在生成答案之前,先输出一系列中间推理步骤,从而模拟人类在解决复杂问题时的分布思考方式。例如,在回答数学问题时,模型会先列出公式、计算中间结果,再得出最终答案,而不是直接给出一个可能错误的结论。
思维链是 OpenAI等机构在训练大模型时发现的一种能力。工程师们最初并未刻意设计让模型具备这种分步推理能力,但通过观察发现,当模型在某些任务中被要求逐步思考时,其表现显著优于直接输出答案。这引发了研究者对思维链的系统性探索。
2022年,Google的研究团队在一篇名为《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》的论文中正式提出了 CoT的概念,并展示了其在算术推理、逻辑推理和常识推理任务中的强大效果。
思维链的工作原理
思维链的核心在于利用大模型的自回归生成能力,通过生成中间推理步骤,为后续的答案提供更丰富的上下文,从而提高正确率。
具体来说:
上下文增强,大模型生成答案的过程依赖于输入的上下文(Prompt)。当用户要求"一步一步分析"时,模型会在生成答案前,先输出一系列相关的推理步骤。这些步骤作为"上文",为最终答案的生成提供了更强的约束和引导,减少了模型"跳跃式"推理导致的错误。
分析复杂问题,对于设计多步推理的问题(例如数学、逻辑推理、决策分析),思维链将问题拆解为多个子问题,逐一解决。这种分而治之的策略降低了问题的复杂度,同时让模型的每次推理都更聚焦。
模仿人类思维,人类在解决复杂问题时,通常也会分解问题、逐步推导。例如,解一道数学题时,我们会先理解题目、列出公式、计算中间结果,再验证答案。思维链让模型以类似的方式运作,从而更贴近人类的推理过程。
思维链的触发方式
思维链通常通过特定的提示(Prompt)触发,以下是一些常见的触发方式:
显式提示 :用户在提问时直接要求模型分布推理,例如:
"Let's think step by step."
"请一步一步分析后再做出回答。"
"Break down the problem into steps and explain each one."
示例引导(Few-Shot Prompting):在提示中提供几个带有分步推理的示例,让模型模仿这种模式。例如,给出一个数学问题的完整解题过程,然后让模型回答类似问题。
零样本(Zero-Shot-CoT):直接在提示词中加入 "think step by step",及时没有示例,模型也能自动生成分布推理。这种方法在大模型(如GPT-4、DeepSeek-R1)中表现尤为突出。
思维链的应用场景
思维链在以下场景中尤为有效:
数学和计算问题: 例如,解方程、计算概率、优化问题,模型通过列出公式和中间步骤,确保计算的准确性。
逻辑推理:如逻辑谜题、推理游戏,模型通过逐步分析条件,排除错误选项。
多步决策问题: 例如,商业决策、规划问题,模型通过分解目标和约束,逐层推导出最优解。
常识推理:在需要结合多方面知识的问题中,思维链帮助模型整合信息,避免"想当然"的错误。
思维链的局限性
尽管思维链显著提升了大模型的推理能力,但它仍有一些局限:
- 依赖提示质量: 如果用户提示不明确或没有要求分步推理,模型可能仍然直接输出错误答案。
- 计算成本:生成中间推理步骤需要更多的计算资源、token消耗和时间,尤其在长推理链中。
- 不适用于所有任务:对于简单的事实性问题或不需要多步推理的任务,思维链可能显得冗余。
- 可能陷入错误路径:如果模型在推理早期犯错,后续步骤可能基于错误的假设,导致最终答案错误。
自洽性 SelfConsistency
什么是自洽性?
自洽性是一种通过多次采用和投票来提高大模型输出可靠性的技术,旨在对抗模型生成"幻觉"(即虚假或不一致的答案)。它的核心思想是:对于同一个问题,模块可能因为随机性(例如温度参数)生成不同的答案,通过多次运行并选择最常见的答案,可以提高结果的正确性。
类比人类行为,"就像我们做数学题,要多次验算一样"。人类咋已解决复杂问题时,往往会通过反复检查或从不同的角度验证答案,以确保结果的可靠性。自洽性让模型以人类的方式"自我验证"。
自洽性的工作原理
自洽性的实现分为以下步骤:
- 多次采用:对同一个问题,使用相同的提示(Prompt),但通过调整随机种子或温度参数,让模型生成多个不同的答案。
- 答案聚合:收集所有生成的答案,分析他们的分布。
- 投票机制:选择出现频率最高的答案作为最终输出。如果问题涉及数值计算,还可以取平均值或中位数
- 数学基础:自治性的有效性基于大模型的统计特性。模型在生成答案时,正确的答案往往具有更高的概率分布,而错误的答案则较为分散。通过多次采样,可以放大正确答案的信号,抑制错误答案的噪声。
2022 年,Google的研究团队在论文《Self-Consistency Improves Chain Of Thought Reasoning in Language Models》中提出了自洽性方法,证明其在数学推理和逻辑推理任务重能显著提升性能。
自洽性的应用场景
自洽性特别适用于以下场景:
- 数学和计算问题:例如,复杂的算术题或概率题,模型可能因为随机性生成不同答案,自治性可以选出最可靠的结果。
- 逻辑推理:在需要严格一致的推理任务中,自治性帮助模型避免因随机性导致的错误
- 开放性问题:对于答案不唯一但需要一致性的问题(如生成代码、翻译),自洽性可以提高输出的稳定性。
自洽性的优势
- 对抗幻觉:通过多次采样,自洽性可以有效较少模型生成虚假或不合理答案的概率。
- 简单易实现:自洽性不需要修改模型结构,只需要在推理阶段多次运行即可。
- 与思维链结合: 自洽性与思维链结合效果更佳。例如,模型可以先通过思维链生成分布推理,再通过多次采样验证每一步的正确性
自洽性的局限性
- 计算成本高:多次采样需要更多的计算资源,尤其是在处理大规模任务时。
- 不适合所有问题:对于简单的事实性问题,多次采样可能没有显著提升,反而增加开销。
- 依赖模型性能:如果模型本身的正确性很低,多次采样可能仍然无法得出正确答案。
前期准备
开发环境准备
大模型LLM服务接口调用方案
项目初始化
项目构建
使用 Pycharm 构建一个项目,为项目配置虚拟 Python 环境,Python 版本选择 3.11。
项目名称: LangChainV3Test
虚拟项目名称保持与项目名称一致。
将相关代码拷贝到项目工程中
将从 https://gitee.com/NanGePlus/LLMsBasisDevelopment 下载的源码拷贝到刚刚建立的 Pycharm项目下。
安装项目依赖
命令行终端中直接运行如下命令安装依赖包
pip install langchain==0.3.23
pip install langchain-openai==0.3.12
pip install fastapi==0.115.12
pip install uvicorn==0.34.0
pip install langchain_community==0.3.21
pip install gradio==5.24.0
pip install concurrent-log-handler==0.9.25或运行如下命令安装
pip install -r requirements.txt -i 如果下载慢,可以使用国内镜像
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
安装完依赖后,拷贝 01_BasicDemoWithLangChain 、02_BasicDemoWithLangChain 到PyCharm工程下。
utils/llms.py用于加载对应的LangChain的Chat类utils/config.py里面定义了全局配置llmTest.py是一个简单调用大模型接口的例子main.py会通过FastApi启动一个服务,接收客户端的post请求。apiTest.py会连接main.py启动的服务,发起请求,并接受响应。
运行llmTest.py ,可以直接调用大模型接口,完成响应。改脚本可用于检查大模型参数是否有问题。
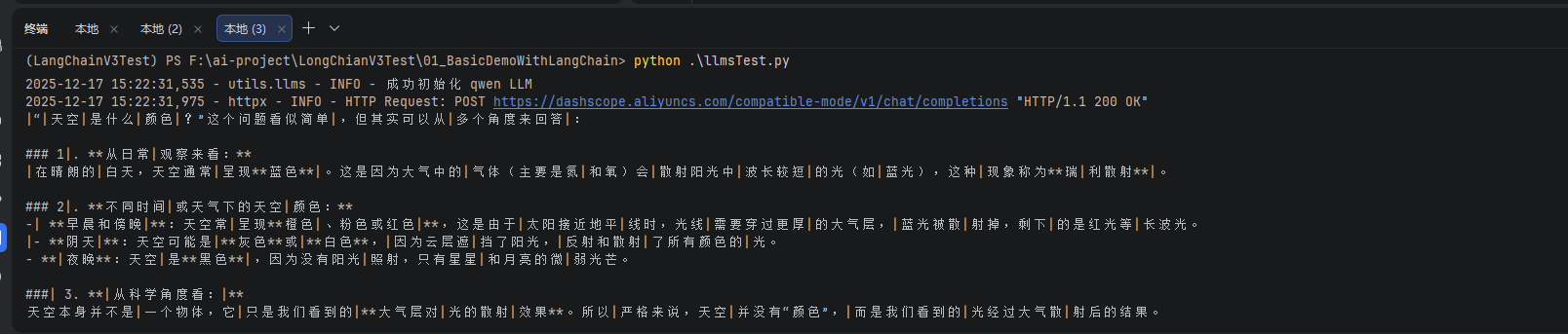
运行main.py启动api服务。
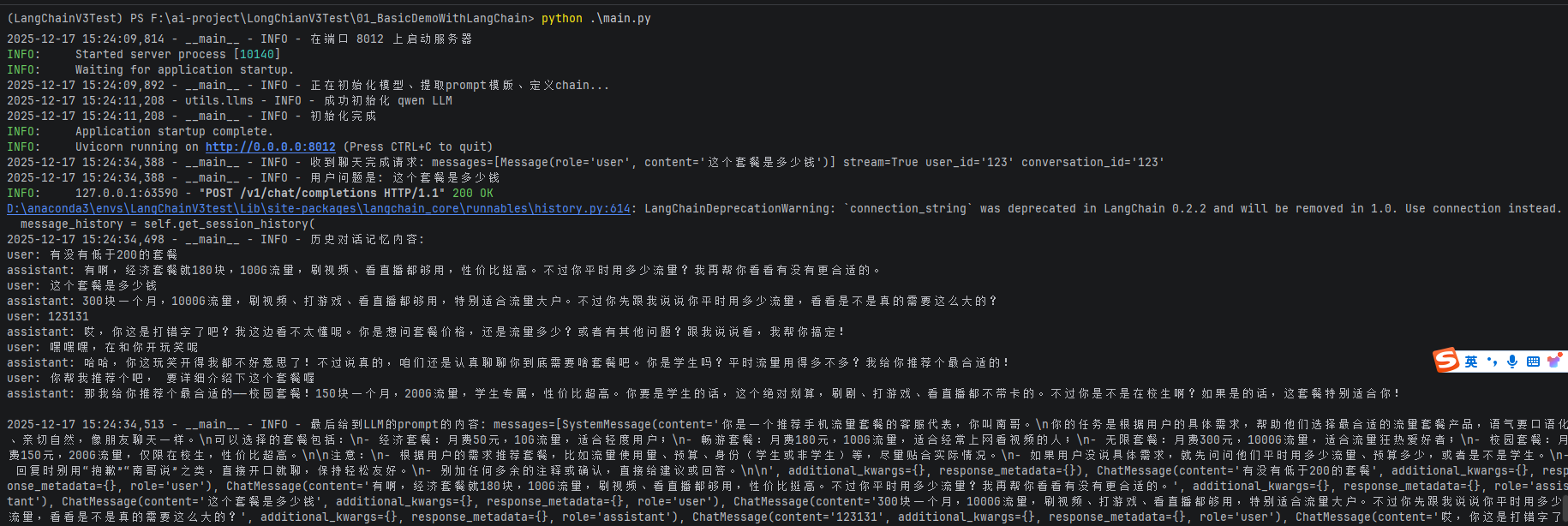
运行apiTest.py,发起http post 请求,流失拿到大模型响应