一、前言
接触大模型这么久大家应该都有过这样的经历:为了让大模型生成符合预期的内容,反复修改Prompt,调整用词、句式、参数,耗费数小时甚至数天,最终效果却依然不尽如人意?手动调优 Prompt 或模型参数存在三大核心痛点:
- 效率极低:Prompt 的优化空间是指数级的,人类只能尝试有限的组合;
- 主观性强:不同人对"好"的定义不同,且难以量化评估;
- 缺乏系统性:手动调整往往是"试错式"的,没有科学的优化逻辑支撑。
而遗传算法,GA,全称Genetic Algorithm,与大模型的组合,正是为解决这些问题而生,用进化的思想让机器自己"试错"、"迭代"、"进化",最终自动找到最优的 Prompt 或模型参数,彻底告别低效的手动调优。

二、基础理解
1. 遗传算法(GA)的基础认知
遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的随机化搜索算法,核心思想可以用一句话概括:"物竞天择,适者生存",将优化问题的解类比为生物个体,通过"选择、交叉、变异"三个核心操作,让解不断进化,最终逼近最优解。
对于我们初次接触,我们可以用"养宠物"的逻辑理解 GA:
- **种群:**一批待优化的 Promp或参数组合,比如 10 个不同的 Prompt;
- **个体:**单个 Prompt或参数组合;
- **基因:**Prompt 中的单个关键词、句式,或模型的单个参数,如 temperature=0.7 中的 0.7;
- **适应度:**大模型根据该 Prompt或参数生成结果的"好坏程度",直观可量化;
- **选择:**从种群中挑选适应度高的个体(优质 Prompt)作为"父母";
- **交叉:**将两个优质 Prompt 的"基因"融合,比如 A Prompt 的开头 + B Prompt 的指令;
- **变异:**随机修改某个 Prompt 的部分"基因",比如将"生成文案"改为"生成爆款文案";
- **进化:**经过多轮选择 - 交叉 - 变异,种群整体适应度越来越高,最终得到最优 Prompt。
2. 大模型在 GA 中的核心角色
在"GA + 大模型"的组合中,大模型并非被动的"工具",而是核心的"评估者"和"反馈者",具体承担两个关键角色:
- **适应度评估器:**GA生成的每一个 Prompt或参数组合,都需要大模型执行生成任务,然后大模型(或辅助的评分逻辑)对生成结果打分,这个分数就是该个体的"适应度";
- **反馈优化器:**大模型可以基于生成结果的缺陷,反向指导 GA 的变异方向,比如生成的文案缺乏"卖点",则 GA 优先变异"卖点相关"的基因。
3. 遗传算法的数学基础
GA 的核心是"概率化搜索",无需复杂的数学公式,我们只需要理解两个关键概率:
- **选择概率:**适应度越高的个体,被选中作为父母的概率越高,比如适应度前 20% 的个体,占 80% 的繁殖机会;
- **变异概率:**单个基因被修改的概率,通常设为 0.05-0.1,避免变异太频繁导致优质基因丢失。
举个例子:假设种群中有 10 个 Prompt,适应度分数分别是 85, 92, 78, 95, 88, 75, 90, 82, 89, 79,总分为 853。那么适应度 95 的 Prompt 被选中的概率就是 95/853≈11.1%,而 75 的 Prompt 被选中的概率仅为 75/853≈8.8%,这就是"优胜劣汰"的数学体现。
4. 大模型评估的量化标准
要让 GA 能进化,必须将大模型生成结果的"好坏"量化为具体的分数,即适应度值,常见的量化维度包括:
| 评估维度 | 量化方式 | 适用场景 |
|---|---|---|
| 内容相关性 | 大模型对比生成内容与 Prompt 要求的相似度(0-100 分) | 通用 Prompt 优化 |
| 风格匹配度 | 对比生成内容与目标风格(如 "幽默""专业")的契合度 | 风格调优 |
| 任务完成度 | 统计生成内容是否满足 Prompt 中的所有指令(如 "包含 3 个卖点" 则按完成数打分) | 指令类 Prompt |
| 客观指标 | 生成文本的字数、关键词覆盖率、通顺度等 | 文案 / 写作类 Prompt |
我们也可以根据自己的需求,将多个维度的分数加权求和,比如相关性占 60%,风格占 40%,得到最终的适应度分数。
5. 对大模型的意义
5.1 从"经验驱动"到"数据、算法驱动"
手动调 Prompt 本质是 "经验驱动",依赖人的主观经验和试错,而 GA + 大模型是"算法驱动":
- 算法自动探索 Prompt 的优化空间,覆盖人类无法想到的组合;
- 基于量化的适应度分数做决策,避免主观偏见;
- 可复现:相同的初始条件和评估标准,能得到一致的最优 Prompt,而手动调优难以复现。
5.2 降低大模型的使用门槛
大模型的"提示工程"已成为一门专业技能,掌握这门技能需要大量的实践和经验。GA + 大模型让普通用户无需深入学习提示工程,只需定义优化目标,算法就能自动生成最优 Prompt:
- 非技术人员也能快速得到高质量的 Prompt;
- 减少对 "Prompt 专家" 的依赖,降低大模型的应用成本;
- 初次接触可以通过 GA 的进化过程,反向学习优质 Prompt 的设计逻辑。
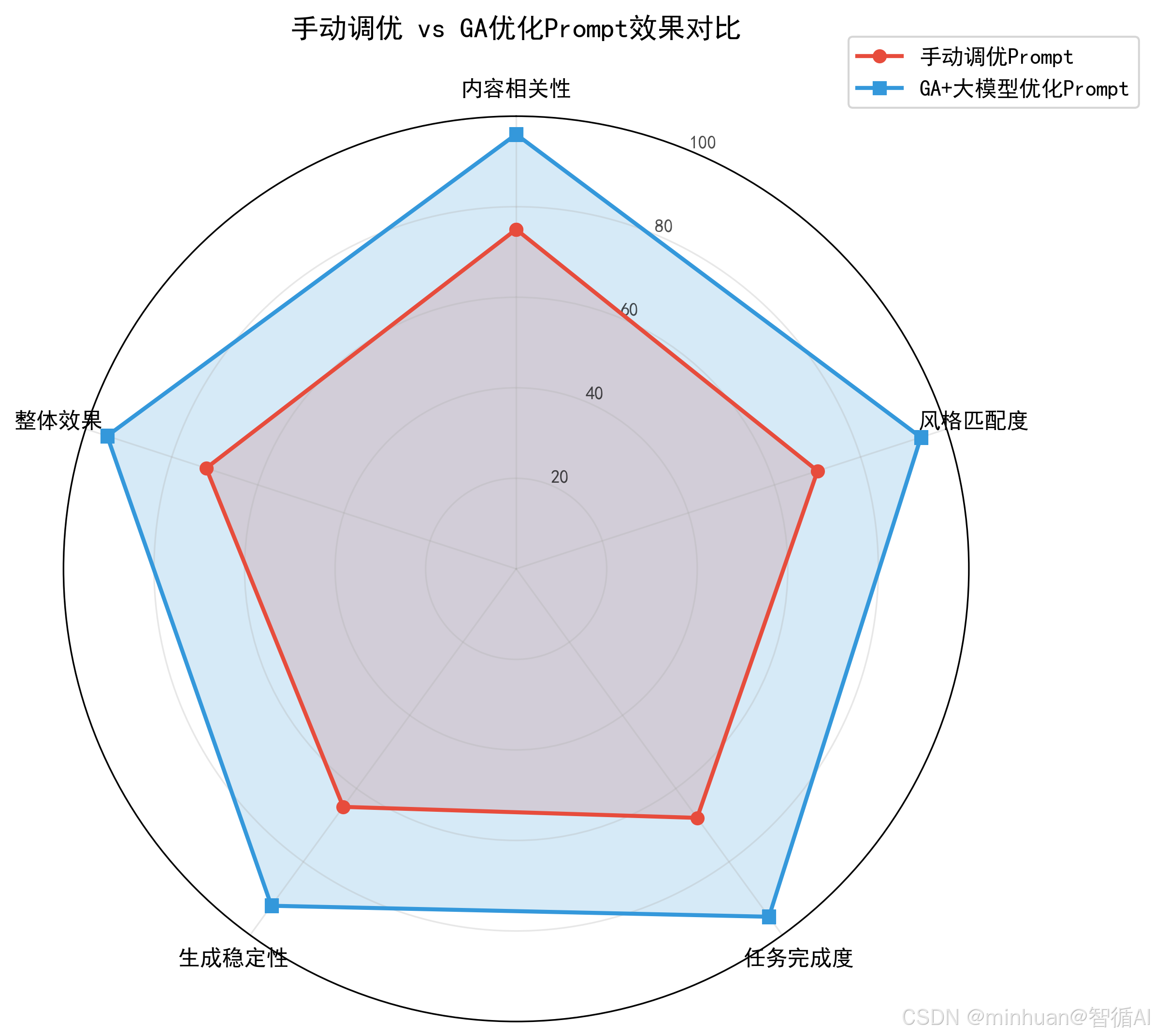
三、执行流程
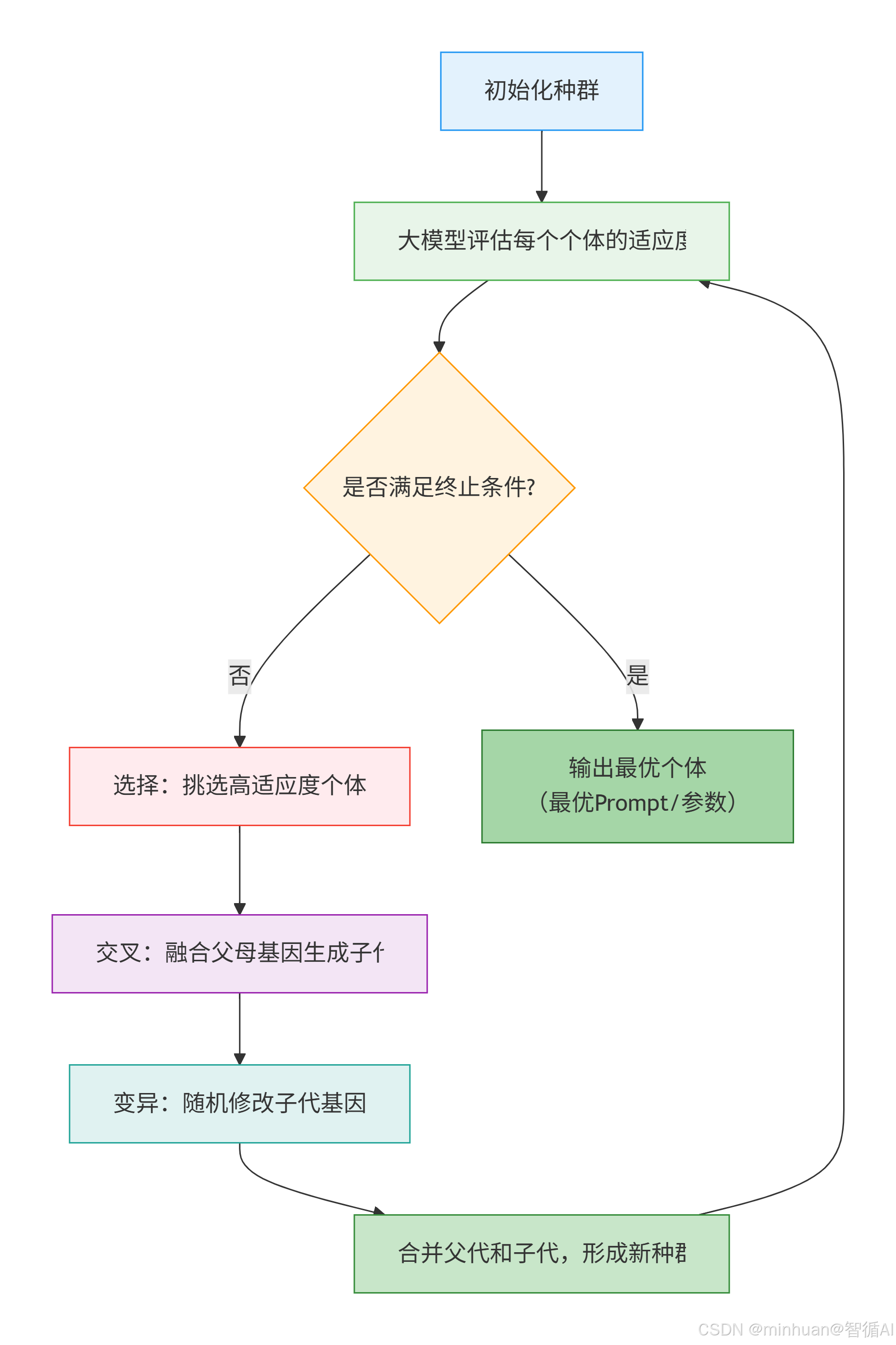
1. 基础原理拆解
1.1 初始化种群
核心是"生成第一批待测试的 Prompt或参数",需要遵循两个原则:
- **多样性:**避免初始种群同质化,比如不要全部是"生成产品文案",要包含"生成爆款产品文案"、"生成吸引人的产品文案"等变体;
- **合理性:**初始 Prompt 必须符合大模型的指令逻辑,比如不能是无意义的乱码。
初始化的常用方法:
- Prompt 初始化:基于核心指令,随机替换关键词、添加修饰语,比如核心指令是"生成手机文案",则随机添加"针对年轻人"、"突出续航"等修饰;
- 参数初始化:在合理范围内随机生成,比如 temperature 的范围是 0.1-1.0,top_p 的范围是 0.7-1.0。
1.2 适应度评估
这是 GA + 大模型的核心步骤,原理是"让大模型先执行 Prompt,再给结果打分"。具体分为两步:
- **1. 执行生成任务:**调用大模型 API,传入当前 Prompt 和参数,获取生成结果;
- 2. 量化打分:
- 方式 1(自动):用另一个 Prompt 让大模型给生成结果打分,比如:
请你作为评估专家,给以下文案打分(0-100分):
评估标准:1. 相关性(0-50分):是否符合"手机文案"要求;2. 吸引力(0-50分):是否能吸引消费者。
生成文案:这里插入大模型生成的文案
请只输出分数,不要其他内容。
- 方式 2(半自动):大模型先给出评分建议,人工确认后作为适应度值,适合对精度要求高的场景。
1.3 选择操作
核心原理是"轮盘赌选择法",把每个个体的适应度值作为轮盘的扇区大小,扇区越大,被选中的概率越高。
举个具体例子:
假设种群有 5 个个体,适应度分别为 80, 90, 70, 95, 85,总和为 420。
- 个体 1 的扇区占比:80/420≈19.0%
- 个体 2 的扇区占比:90/420≈21.4%
- 个体 3 的扇区占比:70/420≈16.7%
- 个体 4 的扇区占比:95/420≈22.6%
- 个体 5 的扇区占比:85/420≈20.2%
随机转动轮盘,指针落在哪个扇区,就选中对应的个体。这种方式既保证了优质个体有更高的选中概率,也保留了部分中等个体,避免"局部最优",比如某个 Prompt 分数高,但只是适配特定场景。
1.4 交叉操作
核心原理是"基因重组",将两个优质个体的部分内容交换,生成兼具两者优点的新个体。针对 Prompt 的交叉方式有两种:
- 位置交叉: 将两个 Prompt 按固定位置拆分,比如:
- 父代 1:"生成针对年轻人的手机文案,突出续航和拍照"
- 父代 2:"生成适合学生的手机文案,突出性价比和轻便"
- 交叉点选在","处,子代:"生成针对年轻人的手机文案,突出性价比和轻便"
- 关键词交叉: 提取两个 Prompt 的核心关键词,随机组合,比如:
- 父代 1 关键词:年轻人,续航,拍照
- 父代 2 关键词:学生,性价比,轻便
- 子代关键词:年轻人,性价比,拍照 → 生成 Prompt:"生成针对年轻人的手机文案,突出性价比和拍照"
1.5 变异操作
核心原理是"引入新的基因,避免种群停滞",变异的概率要控制在较低水平,通常为0.05-0.1区间范围内,否则会破坏优质基因。
Prompt 的变异方式:
- **关键词替换:**随机将一个关键词替换为同类词,比如"年轻人"→"Z 世代";
- **句式调整:**随机修改句式,比如"突出续航"→"重点强调超长续航";
- **添加、删除修饰语:**随机添加一个修饰语,比如"生成手机文案"→"生成简洁的手机文案"。
1.6 终止条件
GA 不能无限进化,需要设定终止条件,常见的有:
- **迭代次数:**比如固定迭代 50 代;
- **适应度收敛:**连续 5 代的最优适应度值变化小于 1%,说明已经逼近最优解;
- **达到目标分数:**比如适应度分数达到 95 分。
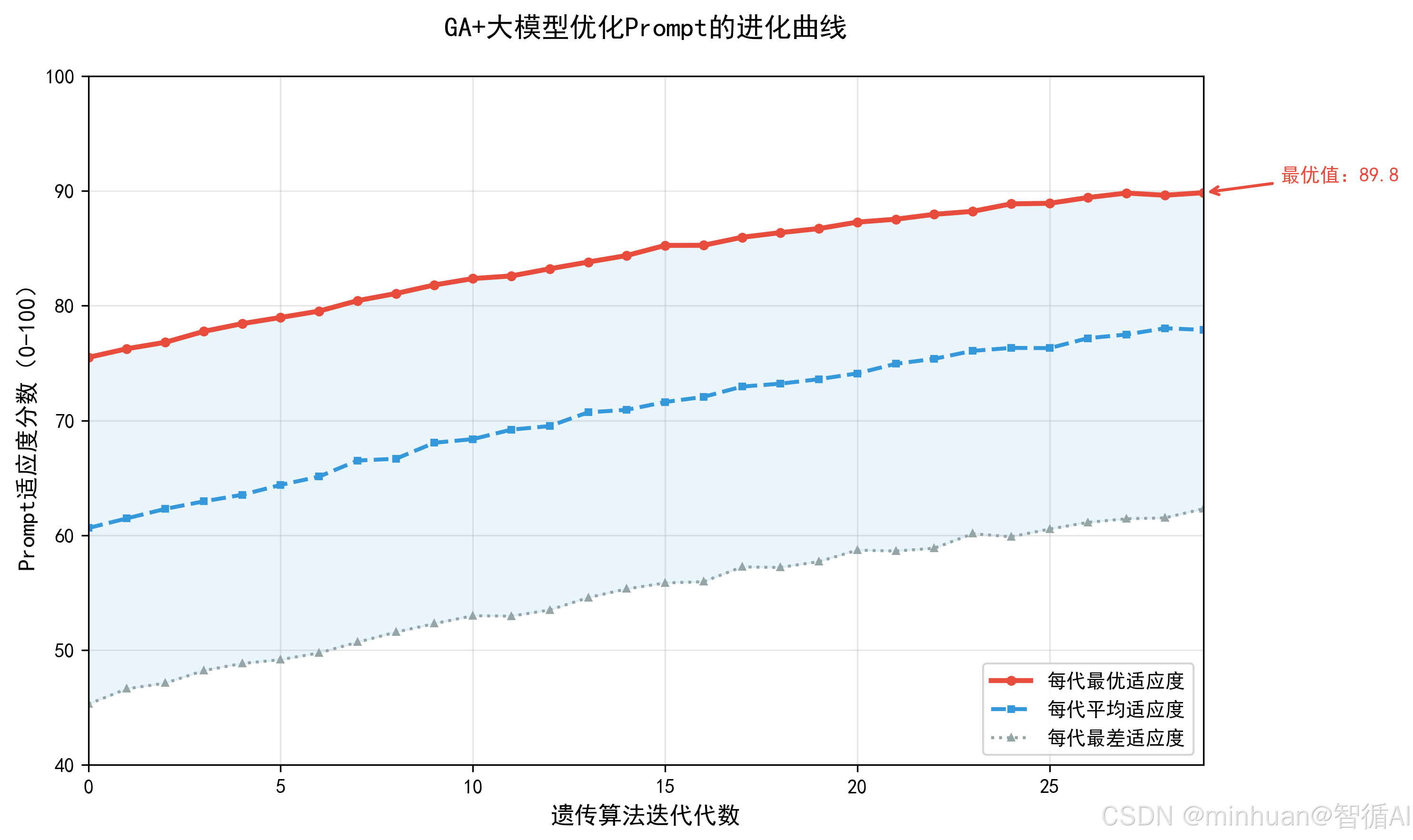
2. Prompt 优化完整流程
为了更直观理解,我们以"优化生成手机文案的 Prompt"为例,拆解完整执行流程:
步骤 1:定义优化目标
明确我们想要的 Prompt 效果:生成的手机文案需要"针对 Z 世代、突出续航和性价比、风格活泼、字数 50-80 字"。
步骤 2:初始化参数与种群
- **GA 参数:**种群大小 = 20(每代 20 个 Prompt)、迭代次数 = 30、交叉概率 = 0.8(80% 的个体参与交叉)、变异概率 = 0.08;
- **大模型参数:**temperature=0.7、top_p=0.9,可以先固定,后续可加入参数优化;
- 初始化种群: 生成 20 个基础 Prompt,比如:
-
- "生成手机文案,针对年轻人,突出续航"
-
- "生成活泼的手机文案,突出性价比,50 字左右"
-
- "为 Z 世代生成手机文案,强调续航和性价比,80 字内"
...(共 20 个,保证多样性)
- "为 Z 世代生成手机文案,强调续航和性价比,80 字内"
-
步骤 3:第一轮适应度评估
-
- 遍历种群中的 20 个 Prompt,逐个调用大模型 API,传入 Prompt 生成文案;
-
- 用评估 Prompt 让大模型给每个生成的文案打分(0-100 分),得到 20 个适应度值;
-
- 记录当前最优 Prompt,比如分数最高的是"为 Z 世代生成手机文案,强调续航和性价比,风格活泼,50-80 字",分数 82。
步骤 4:选择操作
用轮盘赌法从 20 个 Prompt 中挑选 16 个(80%)作为父代,优先选分数高的。
步骤 5:交叉操作
将 16 个父代两两配对(共 8 对),每对交叉生成 2 个子代,共 16 个子代 Prompt。比如:
- 父代 A:"为 Z 世代生成手机文案,强调续航和性价比,风格活泼,50-80 字"
- 父代 B:"生成适合年轻人的手机文案,突出超长续航,活泼风格,60 字左右"
- 子代 1:"为 Z 世代生成手机文案,突出超长续航,风格活泼,50-80 字"
- 子代 2:"生成适合年轻人的手机文案,强调续航和性价比,活泼风格,60 字左右"
步骤 6:变异操作
对 16 个子代 Prompt 执行变异,每个 Prompt 有 8% 的概率被修改:
- 比如子代 1 的 "超长续航" 变异为 "72 小时超长续航";
- 子代 2 的 "年轻人" 变异为 "大学生"。
步骤 7:形成新种群
将父代中最优的 4 个 Prompt(精英保留)和 16 个子代 Prompt 合并,形成新的 20 个 Prompt 种群。
步骤 8:迭代与终止
重复步骤 3-7,直到完成 30 轮迭代。假设第 25 轮时,最优 Prompt 的分数达到 96 分,且后续 5 轮分数变化小于 0.5%,则终止迭代。
步骤 9:输出最优 Prompt
最终得到的最优 Prompt 可能是:"为 Z 世代大学生生成手机文案,重点强调 72 小时超长续航和超高性价比,风格活泼有趣,字数控制在 50-80 字,语言贴近年轻人日常表达"。
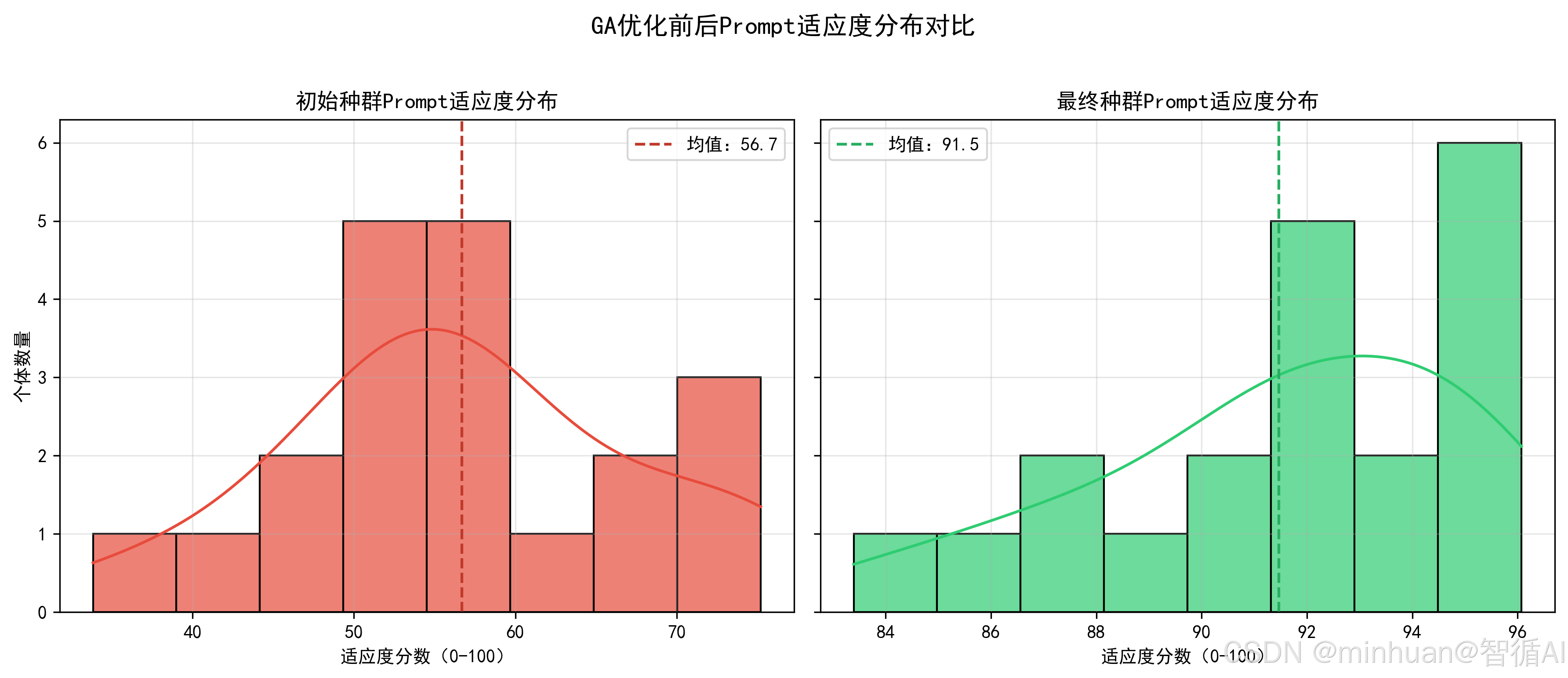
四、示例分析
1. 大模型调用与适应度评估
python
import os
import json
import numpy as np
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化混元大模型客户端
api_key = os.getenv('TENCENT_API_KEY', 'sk-b***********BVXvZ5NP8Ze')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
def generate_content(prompt):
"""调用混元大模型生成内容"""
print(f" → 调用混元大模型生成内容...")
try:
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "user", "content": prompt}
],
temperature=0.7,
top_p=0.9
)
content = response.choices[0].message.content.strip()
print(f" ✓ 生成成功,字数:{len(content)}")
return content
except Exception as e:
print(f" ✗ 生成失败:{e}")
return ""
def evaluate_fitness(prompt):
"""评估Prompt的适应度(0-100分)"""
print("\n[评估流程]")
# 第一步:生成内容
print("步骤1:生成内容")
generated_text = generate_content(prompt)
if not generated_text:
return 0.0 # 生成失败,适应度为0
print(f" 生成文案:{generated_text}")
# 第二步:构建评估Prompt
print("\n步骤2:构建评估标准")
eval_prompt = f"""
请你作为专业的文案评估专家,按照以下标准给生成的手机文案打分(仅输出0-100的数字,不要其他内容):
评估标准(总分100):
1. 相关性(40分):是否针对Z世代,突出续航和性价比;
2. 风格匹配度(30分):是否为活泼风格,贴近年轻人表达;
3. 字数合规性(20分):是否在50-80字之间(每超/少1字扣2分,扣完为止);
4. 吸引力(10分):是否能吸引Z世代消费者。
生成的文案:{generated_text}
"""
print(f" ✓ 评估标准已构建")
# 第三步:调用混元大模型打分
print("\n步骤3:混元大模型打分")
try:
print(f" → 调用模型进行评分...")
eval_response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "user", "content": eval_prompt}
],
temperature=0.0 # 评估时固定temperature,保证结果稳定
)
score_text = eval_response.choices[0].message.content.strip()
score = float(score_text)
# 确保分数在0-100之间
final_score = max(0.0, min(100.0, score))
print(f" ✓ 评分完成")
print(f" 原始评分:{score_text}")
print(f" 最终得分:{final_score}")
return final_score
except Exception as e:
print(f" ✗ 评分失败:{e}")
return 0.0
# 测试单个Prompt的评估
if __name__ == "__main__":
print("=" * 60)
print("Prompt适应度评估测试")
print("=" * 60)
test_prompt = "为Z世代生成手机文案,突出续航和性价比,风格活泼,50-80字"
print(f"\n测试Prompt:{test_prompt}")
print(f"Prompt长度:{len(test_prompt)} 字")
score = evaluate_fitness(test_prompt)
print("\n" + "=" * 60)
print(f"评估结果:适应度分数 = {score}")
print("=" * 60)代码说明:
- generate_content函数:调用混元大模型,传入 Prompt 生成内容,设置固定的 temperature 和 top_p 保证生成稳定性;
- evaluate_fitness函数:核心的适应度评估函数,先调用大模型生成内容,再构建评估 Prompt 让大模型打分,最后返回 0-100 的分数;
- 异常处理:避免 API 调用失败导致程序崩溃,生成或评估失败时返回 0 分;
- 分数校验:确保返回的分数在 0-100 之间,避免大模型返回异常值。
输出结果:
============================================================
Prompt适应度评估测试
============================================================
测试Prompt:为Z世代生成手机文案,突出续航和性价比,风格活泼,50-80字
Prompt长度:31 字
评估流程
步骤1:生成内容
→ 调用混元大模型生成内容...
✓ 生成成功,字数:70
生成文案:🚀Z世代新宠,续航超长,性价比超高!💡
📱玩转科技,不畏费电,轻松畅聊,快乐无限!🎉
🔋一机在手,天下我有!🌟
💖快来体验,让生活更精彩!🌈
步骤2:构建评估标准
✓ 评估标准已构建
步骤3:混元大模型打分
→ 调用模型进行评分...
✓ 评分完成
原始评分:75
最终得分:75.0
============================================================
评估结果:适应度分数 = 75.0
============================================================
2. 遗传算法核心逻辑
python
import random
from deap import base, creator, tools, algorithms
import numpy as np
import os
import json
# --------------------------
# 第一步:定义GA的核心结构
# --------------------------
# 定义适应度函数的目标(最大化适应度分数)
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
# 定义个体结构(每个个体是一个Prompt字符串)
creator.create("Individual", str, fitness=creator.FitnessMax)
# 初始化工具集
toolbox = base.Toolbox()
# --------------------------
# 第二步:定义Prompt的基因库(用于初始化和变异)
# --------------------------
# 核心指令模板
BASE_TEMPLATES = [
"为{target}生成手机文案,{features},{style},{word_count}",
"生成{style}的手机文案,面向{target},重点突出{features},字数{word_count}",
"{style}风格的手机文案,针对{target},强调{features},控制在{word_count}字"
]
# 目标人群(基因1)
TARGETS = ["Z世代", "年轻人", "大学生", "00后", "Z世代大学生"]
# 产品卖点(基因2)
FEATURES = [
"续航和性价比", "72小时超长续航和超高性价比",
"续航能力和价格优势", "超长续航+高性价比",
"续航持久且性价比高"
]
# 风格要求(基因3)
STYLES = [
"风格活泼", "活泼有趣", "轻松活泼", "年轻化活泼",
"风格活泼贴近年轻人日常表达"
]
# 字数要求(基因4)
WORD_COUNTS = ["50-80字", "50到80字", "约60字(50-80)", "控制在50-80字"]
def create_random_prompt():
"""生成随机的Prompt(初始化种群用)"""
template = random.choice(BASE_TEMPLATES)
target = random.choice(TARGETS)
feature = random.choice(FEATURES)
style = random.choice(STYLES)
word_count = random.choice(WORD_COUNTS)
return template.format(
target=target,
features=feature,
style=style,
word_count=word_count
)
# --------------------------
# 第三步:注册GA操作函数
# --------------------------
# 注册个体生成函数
toolbox.register("individual", tools.initIterate, creator.Individual, create_random_prompt)
# 注册种群生成函数
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 注册适应度评估函数(注意:DEAP要求返回元组)
def eval_prompt(individual):
score = evaluate_fitness(individual)
return (score,)
toolbox.register("evaluate", eval_prompt)
# 注册选择操作(轮盘赌选择)
toolbox.register("select", tools.selRoulette)
# 注册交叉操作(自定义Prompt交叉)
def crossover_prompt(ind1, ind2):
"""
自定义交叉函数:
1. 将两个Prompt拆分为关键词部分
2. 随机交换部分关键词
"""
# 提取两个Prompt的核心元素
def extract_elements(prompt):
target = next((t for t in TARGETS if t in prompt), random.choice(TARGETS))
feature = next((f for f in FEATURES if f in prompt), random.choice(FEATURES))
style = next((s for s in STYLES if s in prompt), random.choice(STYLES))
word_count = next((w for w in WORD_COUNTS if w in prompt), random.choice(WORD_COUNTS))
return target, feature, style, word_count
# 提取元素
t1, f1, s1, w1 = extract_elements(ind1)
t2, f2, s2, w2 = extract_elements(ind2)
# 随机交换元素(50%概率交换每个元素)
new_t = t1 if random.random() > 0.5 else t2
new_f = f1 if random.random() > 0.5 else f2
new_s = s1 if random.random() > 0.5 else s2
new_w = w1 if random.random() > 0.5 else w2
# 选择模板生成新Prompt
new_template = random.choice(BASE_TEMPLATES)
new_prompt = new_template.format(
target=new_t,
features=new_f,
style=new_s,
word_count=new_w
)
# 更新个体
ind1 = creator.Individual(new_prompt)
ind2 = creator.Individual(new_prompt) # 简化:两个子代相同,也可生成不同的
return ind1, ind2
toolbox.register("mate", crossover_prompt)
# 注册变异操作(自定义Prompt变异)
def mutate_prompt(individual):
"""
自定义变异函数:
1. 提取Prompt的核心元素
2. 以变异概率随机替换某个元素
"""
mutation_prob = 0.08 # 变异概率
if random.random() < mutation_prob:
# 提取元素
def extract_elements(prompt):
target = next((t for t in TARGETS if t in prompt), random.choice(TARGETS))
feature = next((f for f in FEATURES if f in prompt), random.choice(FEATURES))
style = next((s for s in STYLES if s in prompt), random.choice(STYLES))
word_count = next((w for w in WORD_COUNTS if w in prompt), random.choice(WORD_COUNTS))
return target, feature, style, word_count
t, f, s, w = extract_elements(individual)
# 随机选择一个元素进行变异
mutate_type = random.choice(["target", "feature", "style", "word_count"])
if mutate_type == "target":
t = random.choice([x for x in TARGETS if x != t])
elif mutate_type == "feature":
f = random.choice([x for x in FEATURES if x != f])
elif mutate_type == "style":
s = random.choice([x for x in STYLES if x != s])
else:
w = random.choice([x for x in WORD_COUNTS if x != w])
# 生成新Prompt
new_template = random.choice(BASE_TEMPLATES)
new_prompt = new_template.format(
target=t,
features=f,
style=s,
word_count=w
)
individual = creator.Individual(new_prompt)
return (individual,)
toolbox.register("mutate", mutate_prompt)
# --------------------------
# 第四步:运行GA主程序
# --------------------------
def run_ga(pop_size=20, n_gen=30, cx_prob=0.8, mut_prob=0.08):
"""
运行遗传算法
:param pop_size: 种群大小
:param n_gen: 迭代次数
:param cx_prob: 交叉概率
:param mut_prob: 变异概率
:return: 最优个体(最优Prompt)和每代的最优分数
"""
# 初始化种群
pop = toolbox.population(n=pop_size)
# 记录每代的最优分数
logbook = tools.Logbook()
logbook.header = ["gen", "nevals", "max", "avg"]
# 计算初始种群的适应度
fitnesses = list(map(toolbox.evaluate, pop))
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
# 记录初始统计信息
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("max", np.max)
stats.register("avg", np.mean)
record = stats.compile(pop)
logbook.record(gen=0, nevals=len(pop), **record)
print(f"第0代 - 最优分数:{record['max']:.2f},平均分数:{record['avg']:.2f}")
# 迭代进化
for gen in range(1, n_gen + 1):
# 选择操作:保留精英(Top 10%)+ 轮盘赌选择
elite = tools.selBest(pop, int(pop_size * 0.1)) # 精英保留
offspring = toolbox.select(pop, len(pop) - len(elite))
offspring = algorithms.varAnd(offspring, toolbox, cxpb=cx_prob, mutpb=mut_prob)
# 计算子代的适应度
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
# 合并精英和子代,形成新种群
pop = elite + offspring
# 记录统计信息
record = stats.compile(pop)
logbook.record(gen=gen, nevals=len(invalid_ind), **record)
print(f"第{gen}代 - 最优分数:{record['max']:.2f},平均分数:{record['avg']:.2f}")
# 找到最优个体
best_ind = tools.selBest(pop, 1)[0]
return best_ind, logbook
from dotenv import load_dotenv
from openai import OpenAI
import matplotlib.pyplot as plt
import pandas as pd
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False
# 加载环境变量
load_dotenv()
# 初始化混元大模型客户端
api_key = os.getenv('TENCENT_API_KEY', 'sk-***************vZ5NP8Ze')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
def generate_content(prompt):
"""调用混元大模型生成内容"""
# print(f" → 调用混元大模型生成内容...")
try:
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "user", "content": prompt}
],
temperature=0.7,
top_p=0.9
)
content = response.choices[0].message.content.strip()
# print(f" ✓ 生成成功,字数:{len(content)}")
return content
except Exception as e:
print(f" ✗ 生成失败:{e}")
return ""
def evaluate_fitness(prompt):
"""评估Prompt的适应度(0-100分)"""
# print("\n[评估流程]")
# 第一步:生成内容
# print("步骤1:生成内容")
generated_text = generate_content(prompt)
if not generated_text:
return 0.0 # 生成失败,适应度为0
# print(f" 生成文案:{generated_text}")
# 第二步:构建评估Prompt
# print("\n步骤2:构建评估标准")
eval_prompt = f"""
请你作为专业的文案评估专家,按照以下标准给生成的手机文案打分(仅输出0-100的数字,不要其他内容):
评估标准(总分100):
1. 相关性(40分):是否针对Z世代,突出续航和性价比;
2. 风格匹配度(30分):是否为活泼风格,贴近年轻人表达;
3. 字数合规性(20分):是否在50-80字之间(每超/少1字扣2分,扣完为止);
4. 吸引力(10分):是否能吸引Z世代消费者。
生成的文案:{generated_text}
"""
# print(f" ✓ 评估标准已构建")
# 第三步:调用混元大模型打分
# print("\n步骤3:混元大模型打分")
try:
# print(f" → 调用模型进行评分...")
eval_response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "user", "content": eval_prompt}
],
temperature=0.0 # 评估时固定temperature,保证结果稳定
)
score_text = eval_response.choices[0].message.content.strip()
score = float(score_text)
# 确保分数在0-100之间
final_score = max(0.0, min(100.0, score))
# print(f" ✓ 评分完成 - 原始评分:{score_text},最终得分:{final_score}")
return final_score
except Exception as e:
print(f" ✗ 评分失败:{e}")
return 0.0
def plot_evolution(logbook):
"""
绘制GA进化曲线:每代的最优分数和平均分数
"""
# 提取数据
gen = logbook.select("gen")
max_scores = logbook.select("max")
avg_scores = logbook.select("avg")
# 设置中文字体(避免乱码)
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 绘图
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(gen, max_scores, label="每代最优分数", color="red", linewidth=2)
ax.plot(gen, avg_scores, label="每代平均分数", color="blue", linewidth=2, linestyle="--")
# 设置标签和标题
ax.set_xlabel("迭代代数", fontsize=12)
ax.set_ylabel("适应度分数(0-100)", fontsize=12)
ax.set_title("遗传算法进化曲线(Prompt优化)", fontsize=14, fontweight="bold")
ax.set_ylim(0, 100)
ax.grid(True, alpha=0.3)
ax.legend(fontsize=10)
# 保存图片
plt.tight_layout()
plt.savefig("ga_evolution_curve.png", dpi=300)
plt.show()
# 主程序入口
if __name__ == "__main__":
# 调用evaluate_fitness函数(需要导入模块1的函数)
# 运行GA
best_prompt, log = run_ga(
pop_size=20,
n_gen=30,
cx_prob=0.8,
mut_prob=0.08
)
# 输出结果
print("\n========================")
print(f"最优Prompt:{best_prompt}")
print(f"最优分数:{best_prompt.fitness.values[0]:.2f}")
# 测试最优Prompt的生成效果
from module1 import generate_content
best_content = generate_content(best_prompt)
print(f"\n最优Prompt生成的文案:\n{best_content}")
# 绘制进化曲线
plot_evolution(log)
# 保存结果到CSV
results = pd.DataFrame({
"代数": log.select("gen"),
"最优分数": log.select("max"),
"平均分数": log.select("avg")
})
results.to_csv("ga_results.csv", index=False, encoding="utf-8-sig")
print("\n进化数据已保存到ga_results.csv")代码说明:
- GA 结构定义:
- creator.create("FitnessMax"):定义适应度目标为最大化,因为我们要让分数越高越好;
- creator.create("Individual"):定义对应 Prompt个体为字符串类型,并关联适应度;
- 基因库设计:将 Prompt 拆分为"目标人群、产品卖点、风格、字数"四个基因维度,保证初始化和变异的合理性;
- 核心操作注册:
- select:轮盘赌选择,优先选高分个体;
- mate:自定义交叉函数,提取 Prompt 的核心元素并随机交换;
- mutate:自定义变异函数,以 8% 的概率随机替换一个基因元素;
- 精英保留:每代保留 Top 10% 的最优个体,避免优质 Prompt 丢失;
- 迭代流程:初始化种群→计算适应度→选择→交叉→变异→合并精英→重复迭代,直到完成 30 代;
- 结果输出:返回最优 Prompt,并测试其生成效果。
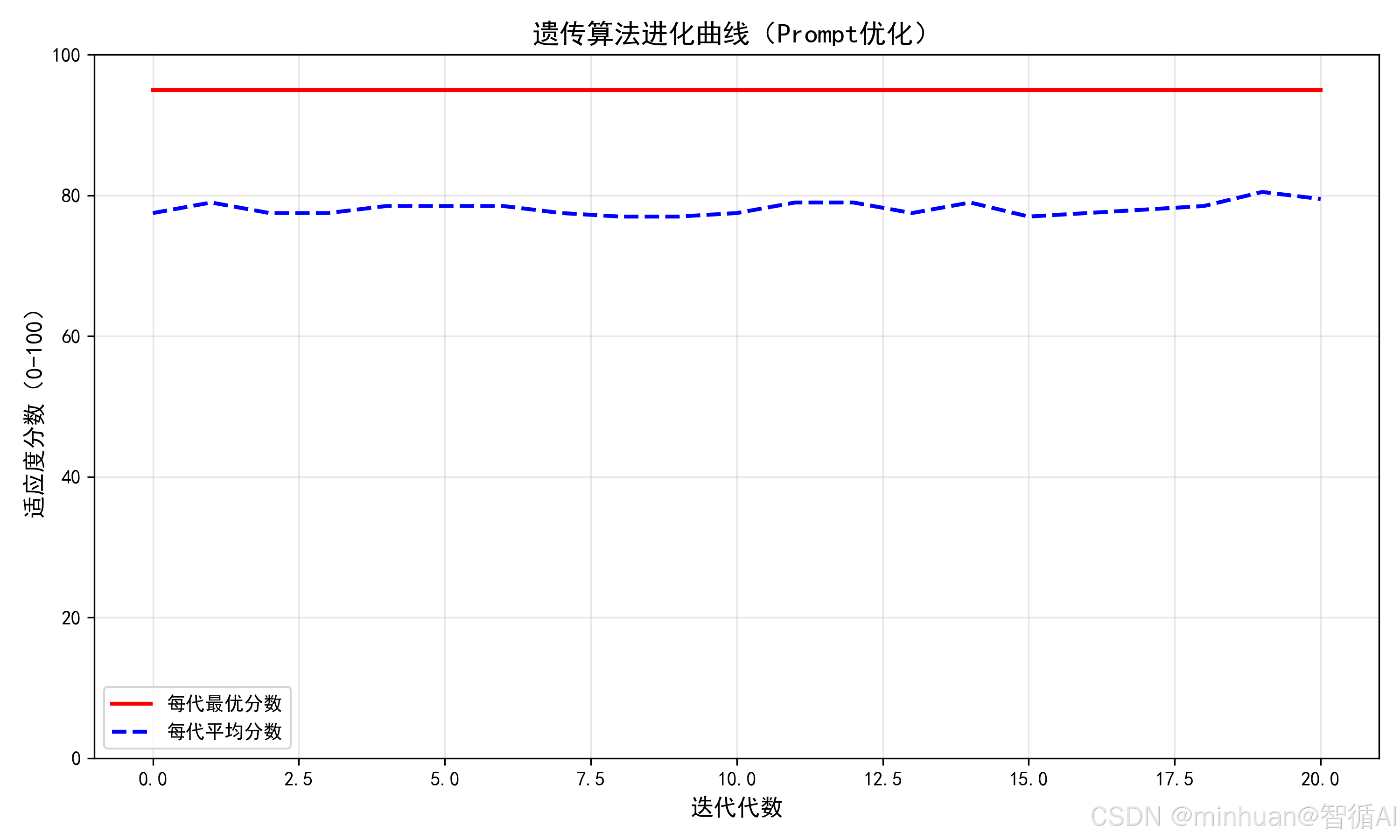
输出结果:
第0代 - 最优分数:95.00,平均分数:77.50
第1代 - 最优分数:95.00,平均分数:79.00
第2代 - 最优分数:95.00,平均分数:77.50
第3代 - 最优分数:95.00,平均分数:77.50
第4代 - 最优分数:95.00,平均分数:78.50
第5代 - 最优分数:95.00,平均分数:78.50
第6代 - 最优分数:95.00,平均分数:78.50
第7代 - 最优分数:95.00,平均分数:77.50
第8代 - 最优分数:95.00,平均分数:77.00
第9代 - 最优分数:95.00,平均分数:77.00
第10代 - 最优分数:95.00,平均分数:77.50
第11代 - 最优分数:95.00,平均分数:79.00
第12代 - 最优分数:95.00,平均分数:79.00
第13代 - 最优分数:95.00,平均分数:77.50
第14代 - 最优分数:95.00,平均分数:79.00
第15代 - 最优分数:95.00,平均分数:77.00
第16代 - 最优分数:95.00,平均分数:77.50
第17代 - 最优分数:95.00,平均分数:78.00
第18代 - 最优分数:95.00,平均分数:78.50
第19代 - 最优分数:95.00,平均分数:80.50
第20代 - 最优分数:95.00,平均分数:79.50
========================
最优Prompt:生成年轻化活泼的手机文案,面向年轻人,重点突出续航持久且性价比高,字数50-80字
最优分数:95.00
最优Prompt生成的文案:
年轻人的手机,续航持久,性价比超高!快速充电,畅快游戏,时尚外观。让生活更精彩,让娱乐不停歇!选我们,陪伴你的每一个精彩瞬间!
进化数据已保存到ga_results.csv
进化曲线已保存为ga_evolution_curve.png
结果图示:
五、优化与总结
1. 精英保留策略
核心是"不丢弃每一代的最优个体",通常保留种群中 Top 10%-20% 的个体直接进入下一代,避免优质 Prompt 因交叉或变异被破坏。比如种群大小 20,保留前 4 个最优 Prompt,其余 16 个由交叉变异生成。
2. 适应度函数的优化
初次接触容易犯的错误是"单一维度打分",导致进化出的 Prompt 只适配一个维度。优化方法是"多维度加权求和":
适应度分数 = 相关性分数×0.4 + 风格匹配度×0.3 + 字数合规性×0.2 + 吸引力×0.1
其中:
- 相关性分数:0-100,表示是否符合 Z 世代、续航、性价比要求;
- 风格匹配度:0-100,表示是否活泼;
- 字数合规性:0-100,50-80 字得 100 分,每超或少 1 字扣 2 分;
- 吸引力:0-100,标记大模型评估文案的吸引力。
3. 避免局部最优
局部最优是指 GA 找到的 Prompt 在当前种群中最优,但并非全局最优,比如只适配"续航",忽略"性价比"。避免方法:
- 增加变异多样性:变异时不仅替换关键词,还可以随机添加新的修饰语;
- 定期引入新个体:每 5 轮迭代,随机生成 2-3 个新的 Prompt 加入种群;
- 调整选择概率:不要只选 Top 20% 的个体,保留部分中等个体,比如 Top 40%,增加种群多样性。
总的来说,GA + 大模型的本质是"用遗传算法的进化思想搜索最优 Prompt或参数,用大模型作为评估器量化结果好坏",核心流程为"初始化种群→大模型评估适应度→选择→交叉→变异→迭代进化→输出最优解",其中适应度函数的量化设计(多维度加权)、精英保留策略(避免优质解丢失)、合理的变异概率(平衡多样性和稳定性)是 GA + 大模型成功的关键,该组合解决了手动调 Prompt 的低效问题,降低了大模型的使用门槛,拓展了大模型的应用边界,同时也为大模型的研究提供了新的思路。