1. 论文信息
论文标题 :Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者 :Zihan Qiu, Zekun Wang, Bo Zheng 等
会议 :NeurIPS 2025(Oral Presentation,入选前1.5%)
论文链接 :https://arxiv.org/abs/2505.06708
代码仓库 :https://github.com/qiuzh20/gated_attention
模型链接:https://huggingface.co/QwQZh/gated_attention
这项研究对注意力机制进行了系统性探索,证明了在标准softmax注意力中添加一个简单的门控机制可以显著提升模型性能、训练稳定性和长上下文处理能力。其核心发现已被阿里巴巴Qwen团队采纳,成为下一代大语言模型的关键技术创新之一。
2. 创新点
本研究的核心创新在于对门控机制在注意力层中作用的系统性分析。与以往工作不同,该研究严格解耦了门控机制与其他架构因素,揭示了其独立价值。主要创新点包括:
-
门控位置的重要性:首次全面比较了在注意力计算流程中不同位置添加门控的效果,发现SDPA(缩放点积注意力)输出处的门控最有效。
-
双机制解释:揭示了有效门控机制的两个关键因素:
- 非线性增强 :在值(WvW_vWv)和输出(WoW_oWo)投影这两个连续线性层之间引入非线性,增强低秩映射的表达能力
- 输入依赖稀疏性:通过查询依赖的稀疏门控分数,为SDPA输出引入动态稀疏性
-
注意力沉没消除:证明了在SDPA输出处应用头特定的稀疏门控可以完全消除"注意力沉没"现象,即第一个token不成比例地主导注意力分数的问题。
-
训练稳定性提升:展示了门控机制如何显著减少训练过程中的损失尖峰,使模型能够容忍更大的学习率,增强可扩展性。
-
长上下文泛化能力:首次证明了消除注意力沉没可以显著提升模型在长上下文任务中的表现,尤其在上下文扩展场景下。
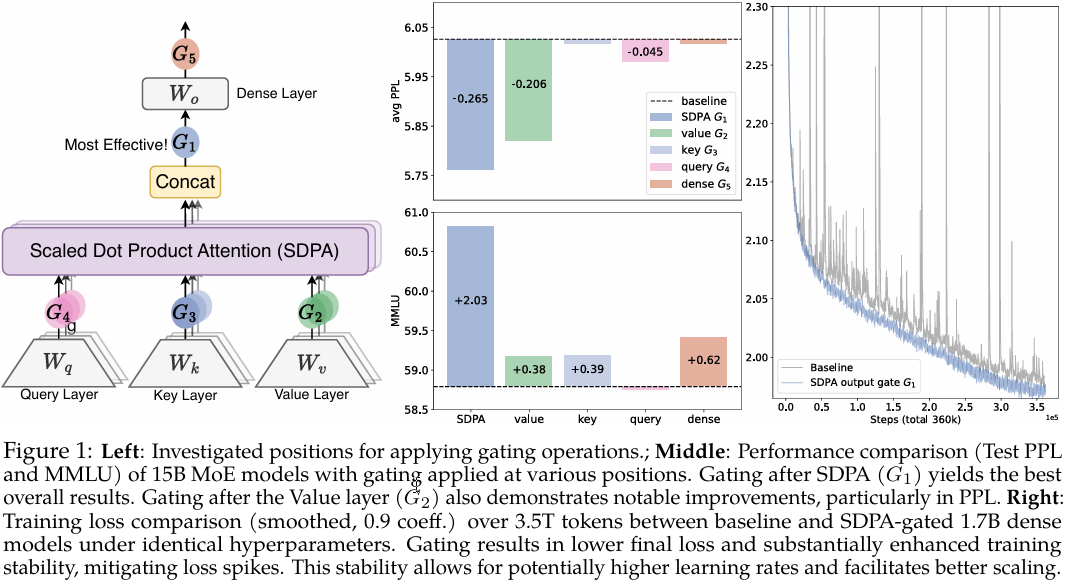
图1:在注意力计算的不同位置(G1-G5)添加门控机制的示意图。研究发现G1位置(SDPA输出后)的门控效果最佳。
3. 方法
3.1 门控机制设计
研究系统性地探索了门控机制的多个维度:
-
位置:研究了5个关键位置(如图1所示):
- G4/G3/G2:查询/键/值投影后
- G1:SDPA输出后
- G5:最终输出层后
-
粒度:
- 逐头门控(Headwise) :每个注意力头有单独的门控标量,应用公式:Y′=Y⊙σ(XWθ)Y' = Y \odot \sigma(XW_{\theta})Y′=Y⊙σ(XWθ)
- 元素级门控(Elementwise):每个维度有单独的门控值,提供更细粒度的控制
-
参数共享:
- 头特定(Head-specific):每个头有独立的门控参数
- 头共享(Head-shared):所有头共享同一组门控参数
-
门控类型:
- 乘性门控 :Y′=Y⊙σ(XWθ)Y' = Y \odot \sigma(XW_{\theta})Y′=Y⊙σ(XWθ)
- 加性门控 :Y′=Y+σ(XWθ)Y' = Y + \sigma(XW_{\theta})Y′=Y+σ(XWθ)
研究确定最有效的配置是在SDPA输出后(G1位置)应用头特定、乘性门控,使用sigmoid激活函数。
3.2 代码实现
以下代码展示了如何在Qwen3模型中实现这种门控机制。主要修改位于Qwen3Attention类中,特别是添加了两种门控机制:
python
class Qwen3Attention(nn.Module):
def __init__(
self,
hidden_size: int,
num_attention_heads: int,
num_key_value_heads: int,
# ... 其他参数 ...
use_qk_norm: bool = False,
headwise_attn_output_gate: bool = False, # 头级别门控
elementwise_attn_output_gate: bool = False, # 元素级别门控
qkv_bias: bool = False,
layer_idx: Optional[int] = None
):
# ... 初始化代码 ...
# 根据门控类型初始化Q投影
if self.headwise_attn_output_gate:
# 头级别门控:为每个头添加一个门控参数
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim + self.num_heads, bias=qkv_bias)
elif self.elementwise_attn_output_gate:
# 元素级别门控:为每个元素添加一个门控参数
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim * 2, bias=qkv_bias)
else:
# 标准Q投影
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim, bias=qkv_bias)核心门控逻辑在前向传播中实现:
python
def forward(self, hidden_states: torch.Tensor, ...):
# ... 前面的代码 ...
# 处理门控机制
gate_score = None
if self.headwise_attn_output_gate:
# 头级别门控:将最后一个维度拆分为head_dim和1
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim + 1)
query_states, gate_score = torch.split(query_states, [self.head_dim, 1], dim=-1)
query_states = query_states.transpose(1, 2) # [batch_size, num_heads, seq_len, head_dim]
gate_score = gate_score.transpose(1, 2) # [batch_size, num_heads, seq_len, 1]
elif self.elementwise_attn_output_gate:
# 元素级别门控:拆分为两个相等的部分
query_states = query_states.view(bsz, q_len, self.num_key_value_heads, -1)
query_states, gate_score = torch.split(query_states, [self.head_dim * self.num_key_value_groups,
self.head_dim * self.num_key_value_groups], dim=-1)
gate_score = gate_score.reshape(bsz, q_len, -1, self.head_dim).transpose(1, 2)
query_states = query_states.reshape(bsz, q_len, -1, self.head_dim).transpose(1, 2)
# ... 中间计算 ...
# 计算注意力输出
attn_output = torch.matmul(attn_weights, value_states)
# 应用门控(如果启用)
if gate_score is not None:
attn_output = attn_output * torch.sigmoid(gate_score)
# ... 后续代码 ...这种实现方式非常高效,门控机制引入的参数和计算开销很小,实际延迟增加不到2%。
4. 实验结果
4.1 模型性能提升
研究在两个主要实验设置下进行了全面评估:
-
15B MoE模型(15A2B):
- 在3.5T token数据集上训练
- 使用SDPA输出门控,PPL降低0.2以上
- MMLU分数提升2分
- 几乎消除了训练过程中的损失尖峰,显著提高训练稳定性
-
1.7B稠密模型:
- 在各种配置和超参数设置下,SDPA输出门控持续带来性能提升
- 支持使用更大的学习率(8e-3)和批次大小(2048),而基线模型在相同设置下无法收敛
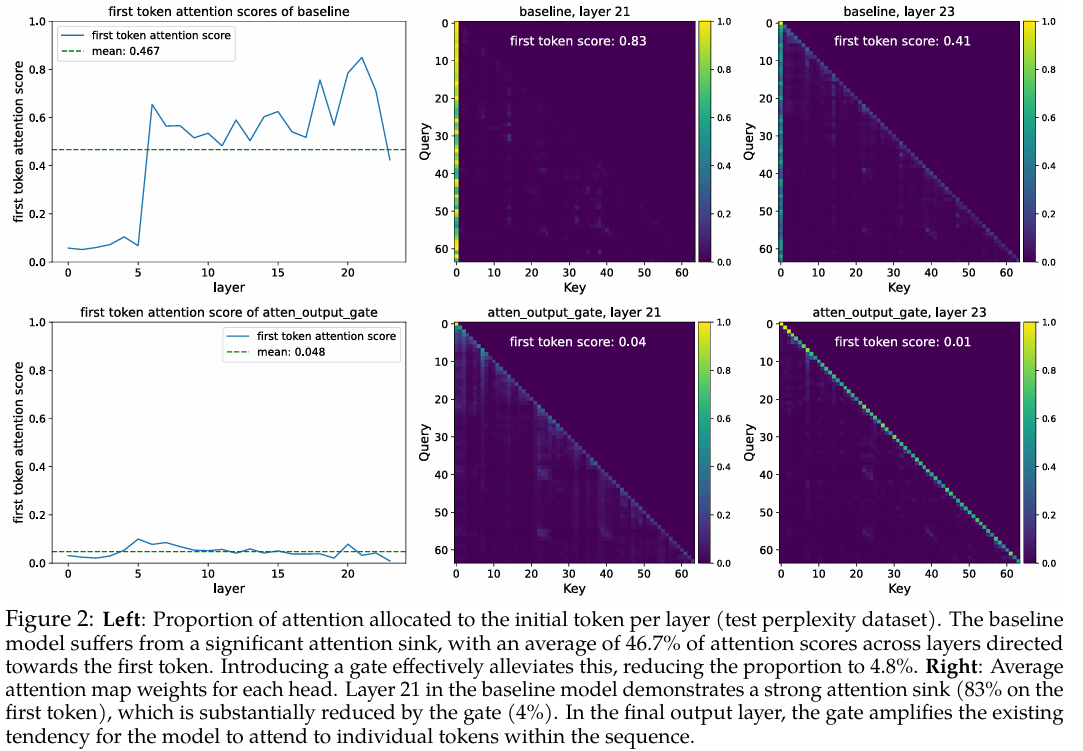
图2:不同层和不同门控类型下的注意力模式。基线模型(左侧)显示出强烈的"注意力沉没"现象(第一个token获得不成比例的高注意力分数),而门控模型(中间和右侧)成功消除了这一现象,使注意力分布更加合理。
4.2 门控机制分析
研究深入分析了门控机制的工作原理,主要发现:
-
稀疏性是关键:最有效的门控(SDPA输出处)表现出最低的平均门控分数(0.12-0.16),表明强稀疏性是其成功的关键。
-
头特定性重要:强制头共享门控分数会提高整体门控分数并削弱性能增益,证明不同注意力头需要不同的稀疏程度。
-
查询依赖性至关重要:值门控(G2)的分数高于SDPA输出门控,且性能更差,表明门控分数应该是查询依赖的,以过滤与当前查询无关的上下文。
4.3 长上下文扩展能力
研究在RULER基准上评估了模型的长上下文能力:
- 训练长度内(32k):带门控模型略优于基线
- 扩展到64k/128k:带门控模型显著优于基线,获得超过10分的提升
这表明无注意力沉没的模型对上下文长度变化更具鲁棒性,因为它们不依赖于特定的注意力分布模式。
5. 完整代码
python
import math
from typing import Optional, Tuple, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
class Qwen3RMSNorm(nn.Module):
"""RMS Normalization layer.
RMSNorm (Root Mean Square Layer Normalization) 是一种轻量级的归一化方法,
相比LayerNorm不需要计算均值,只计算均方根,计算效率更高。
公式: x = x * (1 / sqrt(E[x^2] + ε)) * weight
"""
def __init__(self, hidden_size: int, eps: float = 1e-6):
"""
Args:
hidden_size (int): 隐藏层大小,即特征维度
eps (float, optional): 防止除零的小常数. Defaults to 1e-6.
"""
super().__init__()
# 可学习的缩放参数,初始化为1
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
"""
前向传播,对输入进行RMS归一化
Args:
hidden_states (torch.Tensor): 输入张量,形状为[batch_size, seq_len, hidden_size]
Returns:
torch.Tensor: 归一化后的张量,形状与输入相同
"""
# 保存输入数据类型,用于最后恢复
input_dtype = hidden_states.dtype
# 转换为float32以保证计算精度
hidden_states = hidden_states.to(torch.float32)
# 计算每个token的方差: E[x^2]
variance = hidden_states.pow(2).mean(-1, keepdim=True)
# 计算归一化因子: 1 / sqrt(variance + ε)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# 应用可学习的缩放参数并恢复数据类型
return self.weight * hidden_states.to(input_dtype)
def rotate_half(x: torch.Tensor) -> torch.Tensor:
"""Rotates half the hidden dims of the input.
将输入张量的后半部分取负号并与前半部分交换位置,这是RoPE的核心操作。
例如: [a, b, c, d] -> [-c, -d, a, b]
Args:
x (torch.Tensor): 输入张量,最后一维需要是偶数
Returns:
torch.Tensor: 旋转后的张量
"""
# 将最后一维分成两半
x1 = x[..., :x.shape[-1] // 2] # 前半部分
x2 = x[..., x.shape[-1] // 2:] # 后半部分
# 将后半部分取负号,然后与前半部分拼接: [-x2, x1]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor,
unsqueeze_dim: int = 1) -> Tuple[torch.Tensor, torch.Tensor]:
"""Apply rotary positional embeddings to query and key tensors.
将旋转位置编码应用到query和key张量上。
公式: x_embed = x * cos + rotate_half(x) * sin
Args:
q (torch.Tensor): query张量,形状为[batch_size, num_heads, seq_len, head_dim]
k (torch.Tensor): key张量,形状为[batch_size, num_heads, seq_len, head_dim]
cos (torch.Tensor): 余弦值,形状为[batch_size, seq_len, head_dim]
sin (torch.Tensor): 正弦值,形状为[batch_size, seq_len, head_dim]
unsqueeze_dim (int, optional): 需要扩展的维度. Defaults to 1.
Returns:
Tuple[torch.Tensor, torch.Tensor]: 应用位置编码后的(q_embed, k_embed)
"""
# 在指定维度上扩展cos和sin的维度,以匹配q和k的形状
cos = cos.unsqueeze(unsqueeze_dim) # [batch_size, 1, seq_len, head_dim]
sin = sin.unsqueeze(unsqueeze_dim) # [batch_size, 1, seq_len, head_dim]
# 应用旋转位置编码
# q_embed = q * cos + rotate_half(q) * sin
q_embed = (q * cos) + (rotate_half(q) * sin)
# k_embed = k * cos + rotate_half(k) * sin
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""Repeat key/value heads to match the number of query heads.
当key/value头数少于query头数时,重复key/value头以匹配query头数。
例如: GQA (Grouped Query Attention) 中常用此操作。
Args:
hidden_states (torch.Tensor): 输入张量,形状为[batch_size, num_key_value_heads, seq_len, head_dim]
n_rep (int): 重复次数,等于 num_query_heads / num_key_value_heads
Returns:
torch.Tensor: 重复后的张量,形状为[batch_size, num_query_heads, seq_len, head_dim]
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
# 扩展维度: [batch, num_key_value_heads, 1, slen, head_dim]
# -> [batch, num_key_value_heads, n_rep, slen, head_dim]
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
# 重塑为: [batch, num_key_value_heads * n_rep, slen, head_dim]
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class Qwen3MLP(nn.Module):
"""Multi-Layer Perceptron for Qwen3.
Qwen3模型中的前馈神经网络层,使用SiLU/GELU/ReLU激活函数。
结构: x -> gate_proj -> SiLU -> (x -> up_proj) -> 逐元素相乘 -> down_proj -> 输出
"""
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str = "silu"
):
"""
Args:
hidden_size (int): 隐藏层大小(输入/输出维度)
intermediate_size (int): 中间层大小(MLP扩展维度)
hidden_act (str, optional): 激活函数类型. Defaults to "silu".
支持: "silu", "gelu", "relu"
"""
super().__init__()
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
# 定义激活函数
if hidden_act == "silu":
self.act_fn = nn.SiLU() # SiLU (Swish) 激活函数
elif hidden_act == "gelu":
self.act_fn = nn.GELU() # GELU 激活函数
elif hidden_act == "relu":
self.act_fn = nn.ReLU() # ReLU 激活函数
else:
raise ValueError(f"Unsupported activation: {hidden_act}")
# 三个线性投影层
# gate_proj: 用于生成门控信号
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
# up_proj: 用于上投影
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
# down_proj: 用于下投影回原始维度
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
"""
前向传播
Args:
hidden_state (torch.Tensor): 输入张量,形状为[batch_size, seq_len, hidden_size]
Returns:
torch.Tensor: 输出张量,形状与输入相同
"""
# 计算门控信号: SiLU(gate_proj(x))
gate = self.act_fn(self.gate_proj(hidden_state))
# 计算上投影: up_proj(x)
up = self.up_proj(hidden_state)
# 逐元素相乘后下投影: down_proj(gate * up)
return self.down_proj(gate * up)
class Qwen3RotaryEmbedding(nn.Module):
"""Rotary positional embedding.
旋转位置编码(RoPE)模块,为Transformer提供位置信息。
通过在频域中旋转向量来编码位置信息,具有良好的外推性能。
"""
def __init__(
self,
dim: int,
max_position_embeddings: int = 2048,
base: float = 10000.0,
device: Optional[torch.device] = None,
scaling_factor: float = 1.0,
rope_type: str = "default"
):
"""
Args:
dim (int): 位置编码的维度(通常是head_dim)
max_position_embeddings (int, optional): 最大位置编码长度. Defaults to 2048.
base (float, optional): RoPE的基数,控制频率范围. Defaults to 10000.0.
device (Optional[torch.device], optional): 设备. Defaults to None.
scaling_factor (float, optional): 缩放因子,用于位置插值. Defaults to 1.0.
rope_type (str, optional): RoPE类型. Defaults to "default".
"""
super().__init__()
self.rope_type = rope_type
self.max_seq_len_cached = max_position_embeddings
self.original_max_seq_len = max_position_embeddings
self.scaling_factor = scaling_factor
self.dim = dim
self.base = base
self.attention_scaling = 1.0 # 注意力缩放因子
# 计算逆频率: 1 / (base^(i/dim)),其中i为偶数索引
# 创建频率向量,用于生成旋转矩阵
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
# 注册为buffer,不参与梯度更新
self.register_buffer("inv_freq", inv_freq, persistent=False)
@torch.no_grad()
def forward(self, x: torch.Tensor, position_ids: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""
生成旋转位置编码的cos和sin值
Args:
x (torch.Tensor): 输入张量,用于确定数据类型和设备
position_ids (torch.Tensor): 位置ID,形状为[batch_size, seq_len]
Returns:
Tuple[torch.Tensor, torch.Tensor]: (cos, sin)张量,形状均为[batch_size, seq_len, dim]
"""
# 核心RoPE计算块
# 扩展inv_freq维度: [dim/2] -> [batch_size, dim/2, 1]
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
# 扩展position_ids维度: [batch_size, seq_len] -> [batch_size, 1, seq_len]
position_ids_expanded = position_ids[:, None, :].float()
# 为精度考虑,强制使用float32计算
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
# 计算频率: [batch_size, dim/2, seq_len] = [batch_size, dim/2, 1] @ [batch_size, 1, seq_len]
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
# 将频率复制一份以形成完整的旋转矩阵
emb = torch.cat((freqs, freqs), dim=-1) # [batch_size, seq_len, dim]
# 计算cos和sin
cos = emb.cos()
sin = emb.sin()
# 应用注意力缩放
cos = cos * self.attention_scaling
sin = sin * self.attention_scaling
# 转换回输入数据类型
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
class Qwen3Attention(nn.Module):
"""Multi-headed attention module.
Qwen3模型的多头注意力模块,支持多种变体:
- 标准多头注意力
- GQA (Grouped Query Attention)
- QK归一化
- 头级别/元素级别门控机制
- RoPE位置编码
"""
def __init__(
self,
hidden_size: int,
num_attention_heads: int,
num_key_value_heads: int,
max_position_embeddings: int = 32768,
rope_theta: float = 10000.0,
attention_dropout: float = 0.0,
use_qk_norm: bool = False,
headwise_attn_output_gate: bool = False,
elementwise_attn_output_gate: bool = False,
qkv_bias: bool = False,
layer_idx: Optional[int] = None
):
"""
Args:
hidden_size (int): 隐藏层大小
num_attention_heads (int): 注意力头数(query头数)
num_key_value_heads (int): key/value头数,支持GQA
max_position_embeddings (int, optional): 最大位置编码长度. Defaults to 32768.
rope_theta (float, optional): RoPE的基数. Defaults to 10000.0.
attention_dropout (float, optional): 注意力dropout率. Defaults to 0.0.
use_qk_norm (bool, optional): 是否使用QK归一化. Defaults to False.
headwise_attn_output_gate (bool, optional): 是否使用头级别门控. Defaults to False.
elementwise_attn_output_gate (bool, optional): 是否使用元素级别门控. Defaults to False.
qkv_bias (bool, optional): QKV投影是否使用偏置. Defaults to False.
layer_idx (Optional[int], optional): 层索引,用于缓存. Defaults to None.
"""
super().__init__()
self.layer_idx = layer_idx
self.hidden_size = hidden_size
self.num_heads = num_attention_heads
self.head_dim = hidden_size // num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads # 每组的头数
self.max_position_embeddings = max_position_embeddings
self.rope_theta = rope_theta
self.is_causal = True # 是否为因果注意力(decoder模式)
self.attention_dropout = attention_dropout
self.use_qk_norm = use_qk_norm
self.headwise_attn_output_gate = headwise_attn_output_gate
self.elementwise_attn_output_gate = elementwise_attn_output_gate
# 根据门控类型初始化Q投影
if self.headwise_attn_output_gate:
# 头级别门控:为每个头添加一个门控参数
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim + self.num_heads, bias=qkv_bias)
elif self.elementwise_attn_output_gate:
# 元素级别门控:为每个元素添加一个门控参数
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim * 2, bias=qkv_bias)
else:
# 标准Q投影
self.q_proj = nn.Linear(hidden_size, self.num_heads * self.head_dim, bias=qkv_bias)
# K和V投影
self.k_proj = nn.Linear(hidden_size, self.num_key_value_heads * self.head_dim, bias=qkv_bias)
self.v_proj = nn.Linear(hidden_size, self.num_key_value_heads * self.head_dim, bias=qkv_bias)
# 输出投影
self.o_proj = nn.Linear(self.num_heads * self.head_dim, hidden_size, bias=qkv_bias)
# 可选的QK归一化
if self.use_qk_norm:
self.q_norm = Qwen3RMSNorm(self.head_dim, eps=1e-6)
self.k_norm = Qwen3RMSNorm(self.head_dim, eps=1e-6)
# 旋转位置编码
self.rotary_emb = Qwen3RotaryEmbedding(
dim=self.head_dim,
max_position_embeddings=self.max_position_embeddings,
base=self.rope_theta
)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[tuple] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple]]:
"""
前向传播
Args:
hidden_states (torch.Tensor): 输入张量,形状为[batch_size, seq_len, hidden_size]
attention_mask (Optional[torch.Tensor], optional): 注意力掩码. Defaults to None.
position_ids (Optional[torch.LongTensor], optional): 位置ID. Defaults to None.
past_key_value (Optional[tuple], optional): 缓存的key/value状态. Defaults to None.
output_attentions (bool, optional): 是否输出注意力权重. Defaults to False.
use_cache (bool, optional): 是否使用缓存. Defaults to False.
cache_position (Optional[torch.LongTensor], optional): 缓存位置. Defaults to None.
position_embeddings (Optional[Tuple[torch.Tensor, torch.Tensor]], optional): 预计算的位置编码. Defaults to None.
Returns:
Tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple]]:
- attn_output: 注意力输出,形状为[batch_size, seq_len, hidden_size]
- attn_weights: 注意力权重(如果output_attentions=True)
- present_key_value: 当前key/value状态(如果use_cache=True)
"""
bsz, q_len, _ = hidden_states.size()
# 线性投影
query_states = self.q_proj(hidden_states) # [batch_size, seq_len, num_heads * head_dim + ...]
key_states = self.k_proj(hidden_states) # [batch_size, seq_len, num_key_value_heads * head_dim]
value_states = self.v_proj(hidden_states) # [batch_size, seq_len, num_key_value_heads * head_dim]
# 处理门控机制
gate_score = None
if self.headwise_attn_output_gate:
# 头级别门控:将最后一个维度拆分为head_dim和1
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim + 1)
query_states, gate_score = torch.split(query_states, [self.head_dim, 1], dim=-1)
query_states = query_states.transpose(1, 2) # [batch_size, num_heads, seq_len, head_dim]
gate_score = gate_score.transpose(1, 2) # [batch_size, num_heads, seq_len, 1]
elif self.elementwise_attn_output_gate:
# 元素级别门控:拆分为两个相等的部分
query_states = query_states.view(bsz, q_len, self.num_key_value_heads, -1)
query_states, gate_score = torch.split(query_states, [self.head_dim * self.num_key_value_groups,
self.head_dim * self.num_key_value_groups], dim=-1)
gate_score = gate_score.reshape(bsz, q_len, -1, self.head_dim).transpose(1,
2) # [batch_size, num_heads, seq_len, head_dim]
query_states = query_states.reshape(bsz, q_len, -1, self.head_dim).transpose(1, 2)
else:
# 标准形状转换
query_states = query_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
# 转换K和V的形状
key_states = key_states.view(bsz, q_len, -1, self.head_dim).transpose(1,
2) # [batch_size, num_key_value_heads, seq_len, head_dim]
value_states = value_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
# 应用QK归一化(如果启用)
if self.use_qk_norm:
query_states = self.q_norm(query_states)
key_states = self.k_norm(key_states)
# 获取旋转位置编码
if position_embeddings is None:
cos, sin = self.rotary_emb(value_states.transpose(1, 2), position_ids)
else:
cos, sin = position_embeddings
# 应用旋转位置编码
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
# 处理过去key/value缓存(用于生成任务)
if past_key_value is not None and use_cache:
if len(past_key_value) > self.layer_idx:
# 更新缓存
past_key, past_value = past_key_value[self.layer_idx]
# 拼接新的key/value到缓存
key_states = torch.cat([past_key, key_states], dim=2)
value_states = torch.cat([past_value, value_states], dim=2)
# 更新缓存
past_key_value = past_key_value[:self.layer_idx] + ((key_states, value_states),) + past_key_value[
self.layer_idx + 1:]
# 重复key/value头以匹配query头数(GQA)
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# 计算注意力权重
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
# 应用注意力掩码
if attention_mask is not None:
attn_weights = attn_weights + attention_mask
# 应用softmax和dropout
attn_weights = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = F.dropout(attn_weights, p=self.attention_dropout, training=self.training)
# 计算注意力输出
attn_output = torch.matmul(attn_weights, value_states)
# 应用门控(如果启用)
if gate_score is not None:
attn_output = attn_output * torch.sigmoid(gate_score)
# 重塑输出形状
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, -1)
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights if output_attentions else None, past_key_value
class Qwen3Block(nn.Module):
"""Standalone Qwen3 decoder block.
Qwen3模型的单个解码器块,包含:
1. 自注意力层 + RMSNorm
2. MLP层 + RMSNorm
3. 残差连接
"""
def __init__(
self,
hidden_size: int = 4096,
num_attention_heads: int = 32,
num_key_value_heads: int = 32,
intermediate_size: int = 11008,
hidden_act: str = "silu",
rms_norm_eps: float = 1e-6,
attention_dropout: float = 0.0,
max_position_embeddings: int = 32768,
rope_theta: float = 10000.0,
use_qk_norm: bool = False,
headwise_attn_output_gate: bool = False,
elementwise_attn_output_gate: bool = False,
qkv_bias: bool = False,
layer_idx: int = 0
):
"""
Args:
hidden_size (int, optional): 隐藏层大小. Defaults to 4096.
num_attention_heads (int, optional): 注意力头数. Defaults to 32.
num_key_value_heads (int, optional): key/value头数. Defaults to 32.
intermediate_size (int, optional): MLP中间层大小. Defaults to 11008.
hidden_act (str, optional): 激活函数. Defaults to "silu".
rms_norm_eps (float, optional): RMSNorm的epsilon. Defaults to 1e-6.
attention_dropout (float, optional): 注意力dropout. Defaults to 0.0.
max_position_embeddings (int, optional): 最大位置编码长度. Defaults to 32768.
rope_theta (float, optional): RoPE基数. Defaults to 10000.0.
use_qk_norm (bool, optional): 是否使用QK归一化. Defaults to False.
headwise_attn_output_gate (bool, optional): 是否使用头级别门控. Defaults to False.
elementwise_attn_output_gate (bool, optional): 是否使用元素级别门控. Defaults to False.
qkv_bias (bool, optional): QKV投影是否使用偏置. Defaults to False.
layer_idx (int, optional): 层索引. Defaults to 0.
"""
super().__init__()
self.hidden_size = hidden_size
self.layer_idx = layer_idx
# 自注意力模块
self.self_attn = Qwen3Attention(
hidden_size=hidden_size,
num_attention_heads=num_attention_heads,
num_key_value_heads=num_key_value_heads,
max_position_embeddings=max_position_embeddings,
rope_theta=rope_theta,
attention_dropout=attention_dropout,
use_qk_norm=use_qk_norm,
headwise_attn_output_gate=headwise_attn_output_gate,
elementwise_attn_output_gate=elementwise_attn_output_gate,
qkv_bias=qkv_bias,
layer_idx=layer_idx
)
# MLP模块
self.mlp = Qwen3MLP(
hidden_size=hidden_size,
intermediate_size=intermediate_size,
hidden_act=hidden_act
)
# 层归一化
self.input_layernorm = Qwen3RMSNorm(hidden_size, eps=rms_norm_eps) # 注意力前的归一化
self.post_attention_layernorm = Qwen3RMSNorm(hidden_size, eps=rms_norm_eps) # MLP前的归一化
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[tuple] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
) -> tuple:
"""
Forward pass for the Qwen3 block.
Args:
hidden_states: Input tensor of shape (batch, seq_len, hidden_size)
attention_mask: Optional attention mask
position_ids: Optional position indices
past_key_value: Optional cached key/value states
output_attentions: Whether to output attention weights
use_cache: Whether to use caching
cache_position: Optional cache position indices
position_embeddings: Optional pre-computed positional embeddings
Returns:
Tuple containing:
- Output hidden states
- Attention weights (if output_attentions=True)
- Present key/value states (if use_cache=True)
"""
residual = hidden_states
# 预层归一化
hidden_states = self.input_layernorm(hidden_states)
# 自注意力层
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
)
# 残差连接
hidden_states = residual + hidden_states
# 第二个残差块
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
# 准备输出
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights,)
if use_cache:
outputs += (present_key_value,)
return outputs
# ===================== 调用示例 =====================
def example_usage():
"""示例用法"""
print("=== Qwen3Block 使用示例 ===")
# 设置随机种子以便结果可重现
torch.manual_seed(42)
# 创建一个简单的block实例
block = Qwen3Block(
hidden_size=768, # 隐藏层大小
num_attention_heads=12, # 注意力头数
num_key_value_heads=12, # KV头数
intermediate_size=3072, # MLP中间层大小
hidden_act="silu", # 激活函数
rms_norm_eps=1e-6, # RMSNorm的epsilon
attention_dropout=0.1, # 注意力dropout
max_position_embeddings=2048, # 最大位置编码
rope_theta=10000.0, # RoPE theta
use_qk_norm=False, # 是否使用QK归一化
headwise_attn_output_gate=False, # 是否使用头级别门控
elementwise_attn_output_gate=False, # 是否使用元素级别门控
qkv_bias=False, # 是否使用QKV偏置
layer_idx=0 # 层索引
)
# 创建随机输入数据
batch_size = 2
seq_length = 128
hidden_states = torch.randn(batch_size, seq_length, block.hidden_size)
# 创建位置ID
position_ids = torch.arange(seq_length).unsqueeze(0).expand(batch_size, -1)
print(f"输入形状: {hidden_states.shape}")
# 基本前向传播
print("\n--- 基本前向传播 ---")
outputs = block(hidden_states, position_ids=position_ids)
output_hidden_states = outputs[0]
print(f"输出形状: {output_hidden_states.shape}")
# 带注意力权重的前向传播
print("\n--- 带注意力权重的前向传播 ---")
outputs = block(hidden_states, position_ids=position_ids, output_attentions=True)
output_hidden_states, attn_weights = outputs[0], outputs[1]
print(f"输出形状: {output_hidden_states.shape}")
print(f"注意力权重形状: {attn_weights.shape if attn_weights is not None else None}")
# 带缓存的前向传播(用于生成)
print("\n--- 带缓存的前向传播 ---")
# 第一次前向传播
outputs1 = block(hidden_states, position_ids=position_ids, use_cache=True)
output1, past_key_value = outputs1[0], outputs1[1]
print(f"第一次输出形状: {output1.shape}")
print(f"缓存键值对数量: {len(past_key_value) if past_key_value is not None else 0}")
# 使用缓存进行第二次前向传播(假设我们有一个新的token)
new_hidden_states = torch.randn(batch_size, 1, block.hidden_size)
new_position_ids = torch.tensor([[seq_length]]).expand(batch_size, -1)
outputs2 = block(
new_hidden_states,
position_ids=new_position_ids,
past_key_value=past_key_value,
use_cache=True
)
output2, new_past_key_value = outputs2[0], outputs2[1]
print(f"第二次输出形状: {output2.shape}")
print(f"更新后的缓存键值对数量: {len(new_past_key_value) if new_past_key_value is not None else 0}")
# 带自定义位置编码的前向传播
print("\n--- 带自定义位置编码的前向传播 ---")
rotary_emb = Qwen3RotaryEmbedding(
dim=block.hidden_size // block.self_attn.num_heads,
max_position_embeddings=2048,
base=block.self_attn.rope_theta
)
cos, sin = rotary_emb(hidden_states, position_ids)
outputs = block(
hidden_states,
position_ids=position_ids,
position_embeddings=(cos, sin)
)
print(f"带自定义位置编码的输出形状: {outputs[0].shape}")
def example_with_different_configs():
"""不同配置的示例"""
print("\n=== 不同配置的Qwen3Block示例 ===")
# 小型配置
small_block = Qwen3Block(
hidden_size=256,
num_attention_heads=4,
num_key_value_heads=4,
intermediate_size=1024,
hidden_act="gelu"
)
# 中型配置
medium_block = Qwen3Block(
hidden_size=512,
num_attention_heads=8,
num_key_value_heads=8,
intermediate_size=2048,
hidden_act="silu",
use_qk_norm=True
)
# 大型配置(启用门控机制)
large_block = Qwen3Block(
hidden_size=1024,
num_attention_heads=16,
num_key_value_heads=16,
intermediate_size=4096,
hidden_act="silu",
headwise_attn_output_gate=True # 启用头级别门控
)
batch_size = 1
seq_length = 64
x = torch.randn(batch_size, seq_length, 256)
position_ids = torch.arange(seq_length).unsqueeze(0)
# 测试小型配置
small_output = small_block(x, position_ids=position_ids)[0]
print(f"小型配置输出形状: {small_output.shape}")
# 测试中型配置
x_medium = torch.randn(batch_size, seq_length, 512)
medium_output = medium_block(x_medium, position_ids=position_ids)[0]
print(f"中型配置输出形状: {medium_output.shape}")
# 测试大型配置
x_large = torch.randn(batch_size, seq_length, 1024)
large_output = large_block(x_large, position_ids=position_ids)[0]
print(f"大型配置(带门控)输出形状: {large_output.shape}")
if __name__ == "__main__":
example_usage()
example_with_different_configs()