The Architecture of DBMS
The components of DBMS core
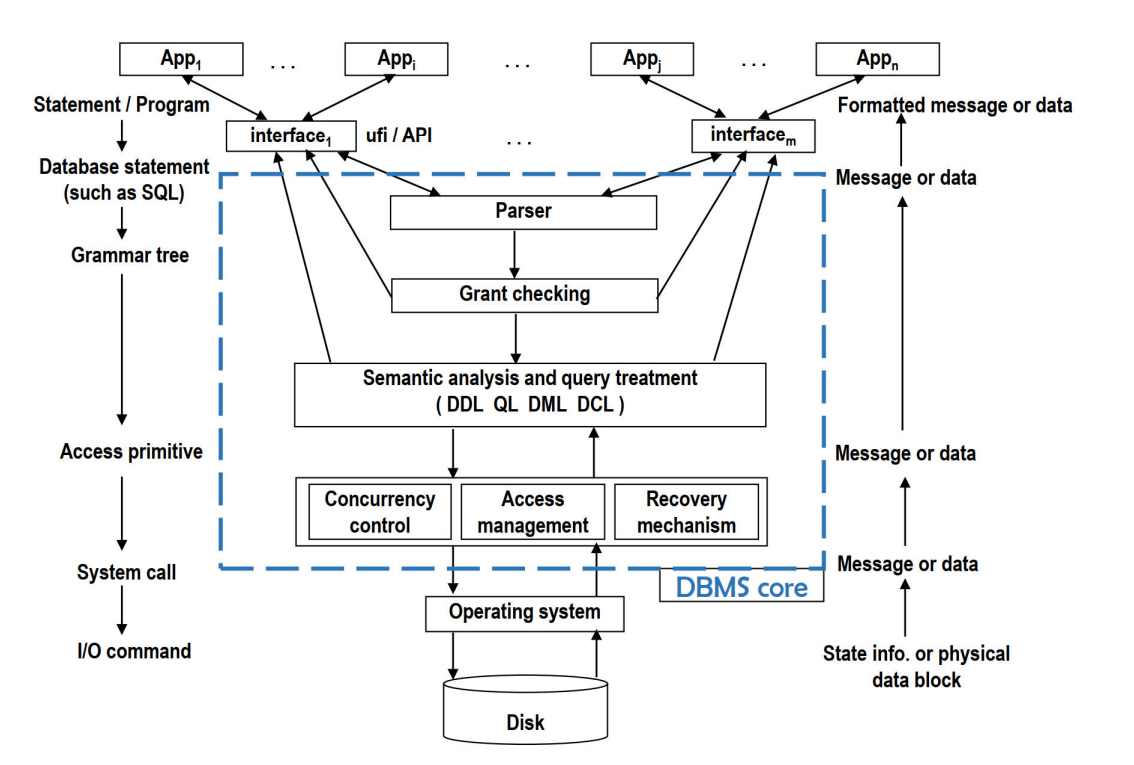
The process structure of DBMS
DBMS 包含 4 种进程结构:
a.单进程结构
应用程序与 DBMS 核心编译为单个可执行文件(.exe),以单个进程运行。
例如:微软 Visual FoxPro
应用程序代码 → SQL 语句 → DBMS 核心(作为函数)→ 结果 → 可执行文件
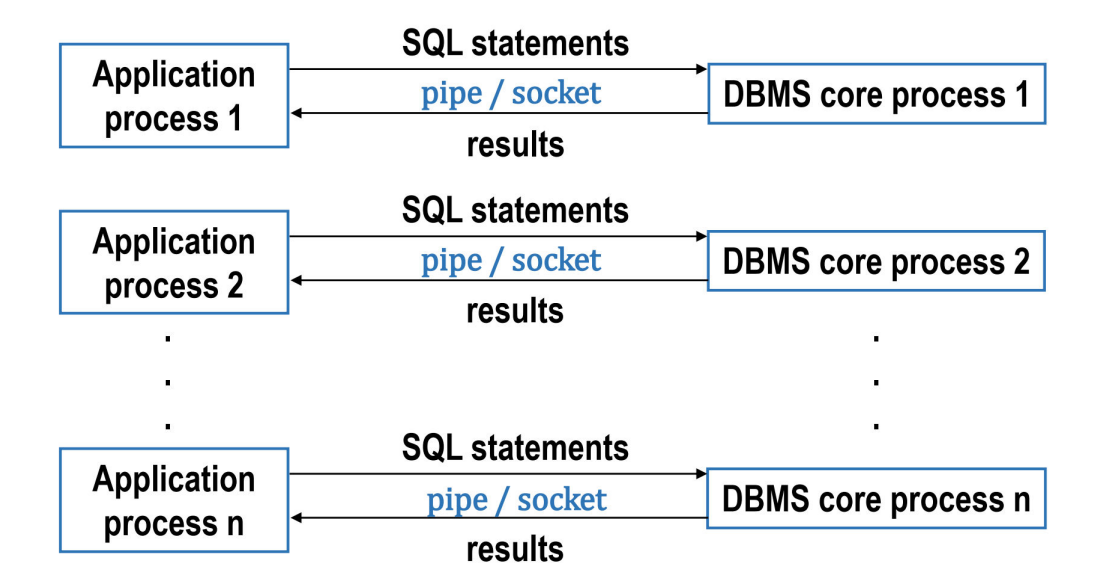
b.多进程结构
一个应用进程对应一个 DBMS 核心进程。
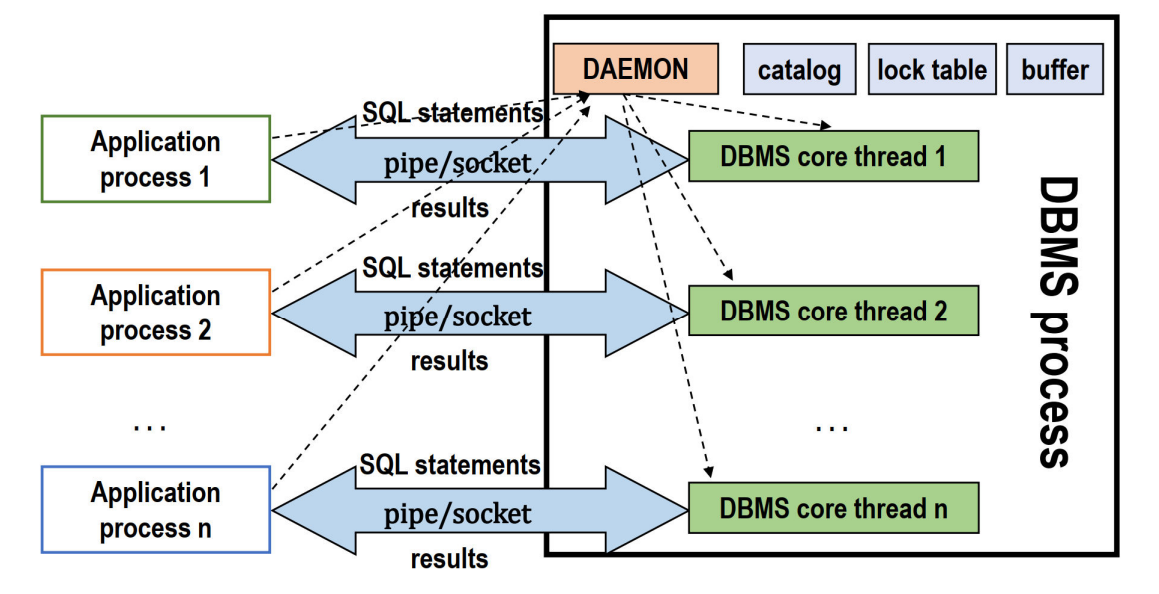
c.多线程结构
仅存在一个 DBMS 进程,每个应用进程对应一个 DBMS 核心线程。
d.进程 / 线程间通信协议
应用程序通过 DBMS 提供的应用程序接口(API)或嵌入式 SQL 访问数据库,依据通信协议实现同步控制。
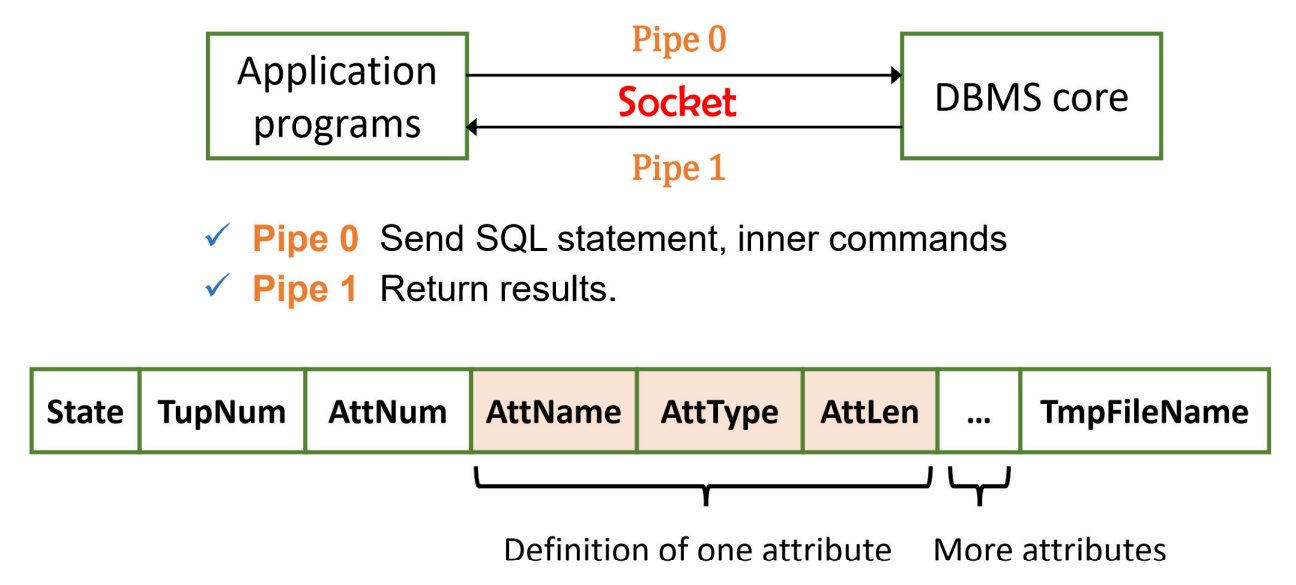 状态(State):0 - 错误;1 - 插入 / 删除 / 更新成功;2 - 查询成功(需进一步处理结果)
状态(State):0 - 错误;1 - 插入 / 删除 / 更新成功;2 - 查询成功(需进一步处理结果)
元组数量(TupNum):结果中的元组个数
属性数量(AttNum):结果表中的属性个数
属性名(AttName):属性名称
属性类型(AttType):属性类型
属性长度(AttLen):当前属性的字节数
临时文件名(TmpFileName):存储结果数据的临时文件名
DATABASE ACCESS MANAGEMENT
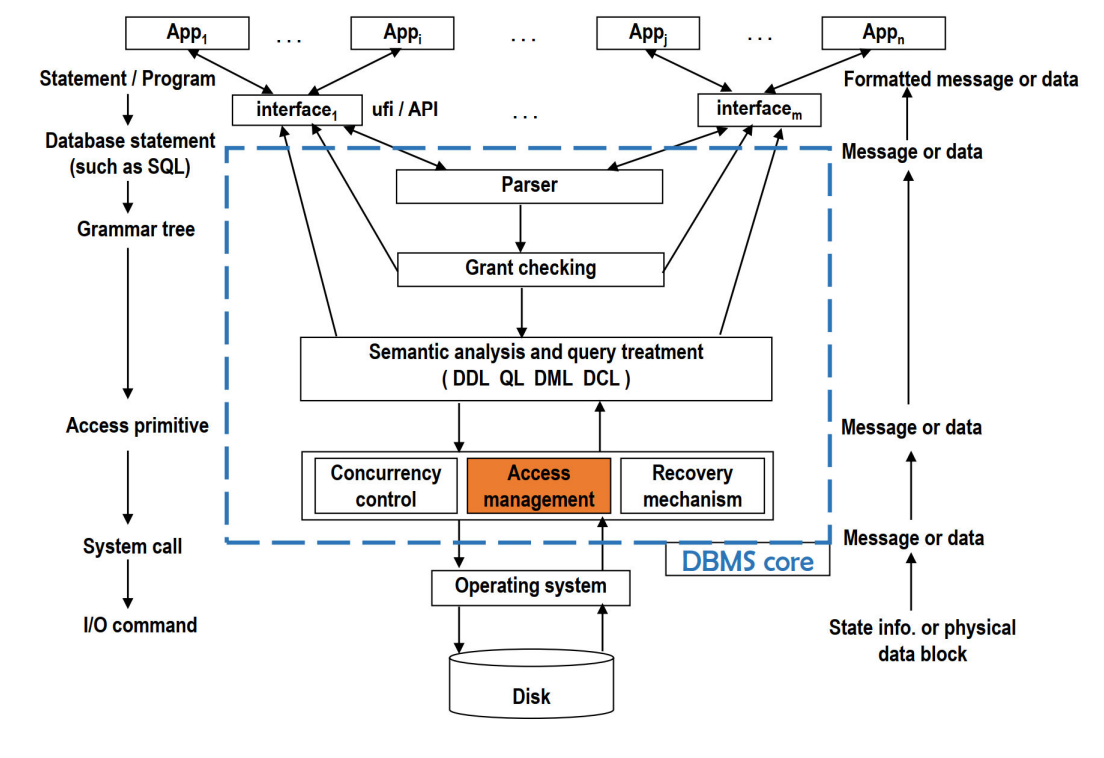
数据库访问最终转化为对操作系统文件的操作,文件结构及访问路径直接影响数据访问速度,且不存在适用于所有数据访问场景的通用文件结构。
解决方案
1.访问类型Access types
2.文件组织File organization
3.索引技术Index technique
4.访问原语Access primitives
数据库访问类型
数据库管理系统面临的访问类型包括:
查询文件中全部或大部分记录(>15%)
查询特定记录
查询部分记录(<15%)
范围查询(例如:年龄在 18 至 20 岁之间)
更新(写入数据库)
文件组织
1.堆文件(Heap file):记录按插入顺序存储,采用顺序检索,是最基础、通用的文件组织形式。Heap file: records stored according to their inserted order and retrieved sequentially. This is the most basic and general form of file organization.
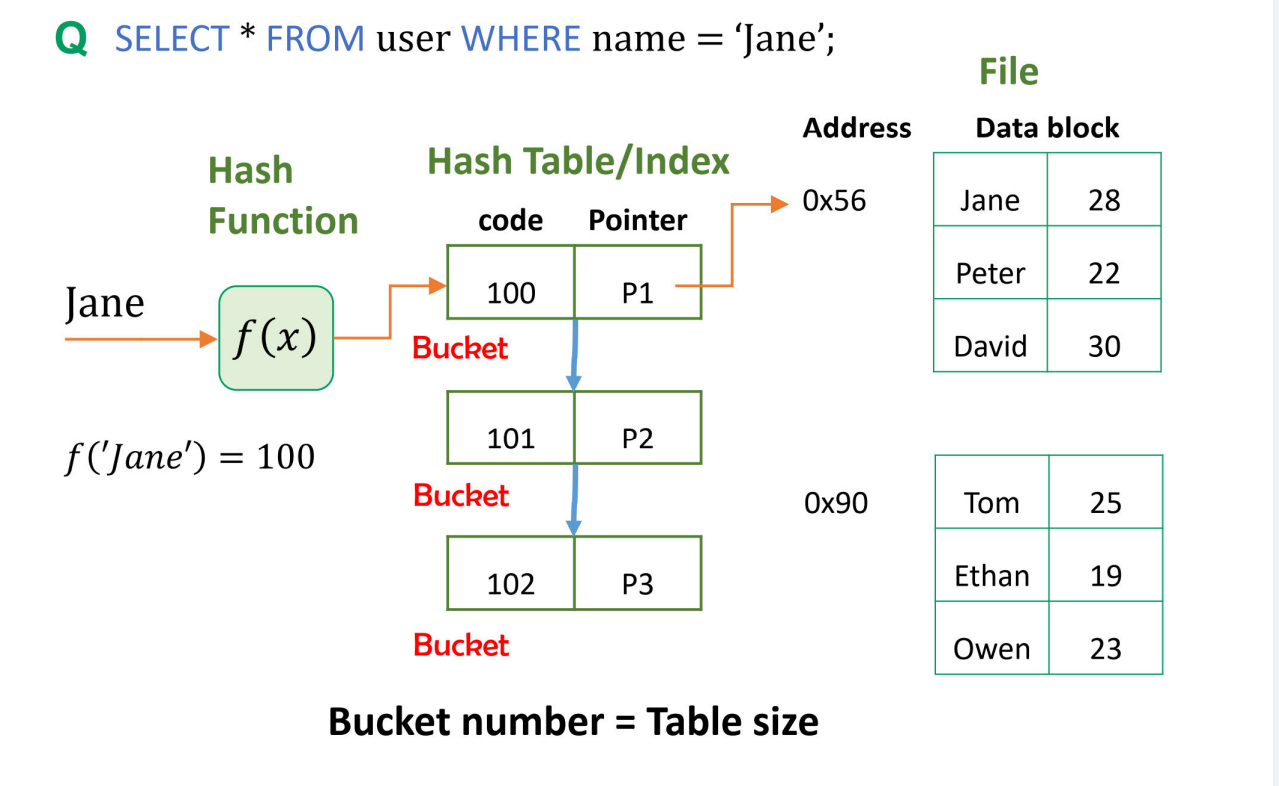
2.直接文件(Direct file):根据某属性值通过哈希函数映射记录地址。Direct file: the record address is mapped through hash function according to some attribute's value.
3.动态哈希(Dynamic hashing):哈希函数的映射空间可变。. Dynamic hashing: the mapping space of hash function is variable
4.索引文件(Indexed file):索引 + 堆文件 / 簇。
5.裸磁盘(Raw disk):注意文件逻辑块与物理块的区别,可通过裸磁盘在操作系统中控制物理块。
6.网格结构文件(Grid structure file):适用于多属性查询。
哈希技术
B + 树索引(基于堆文件)
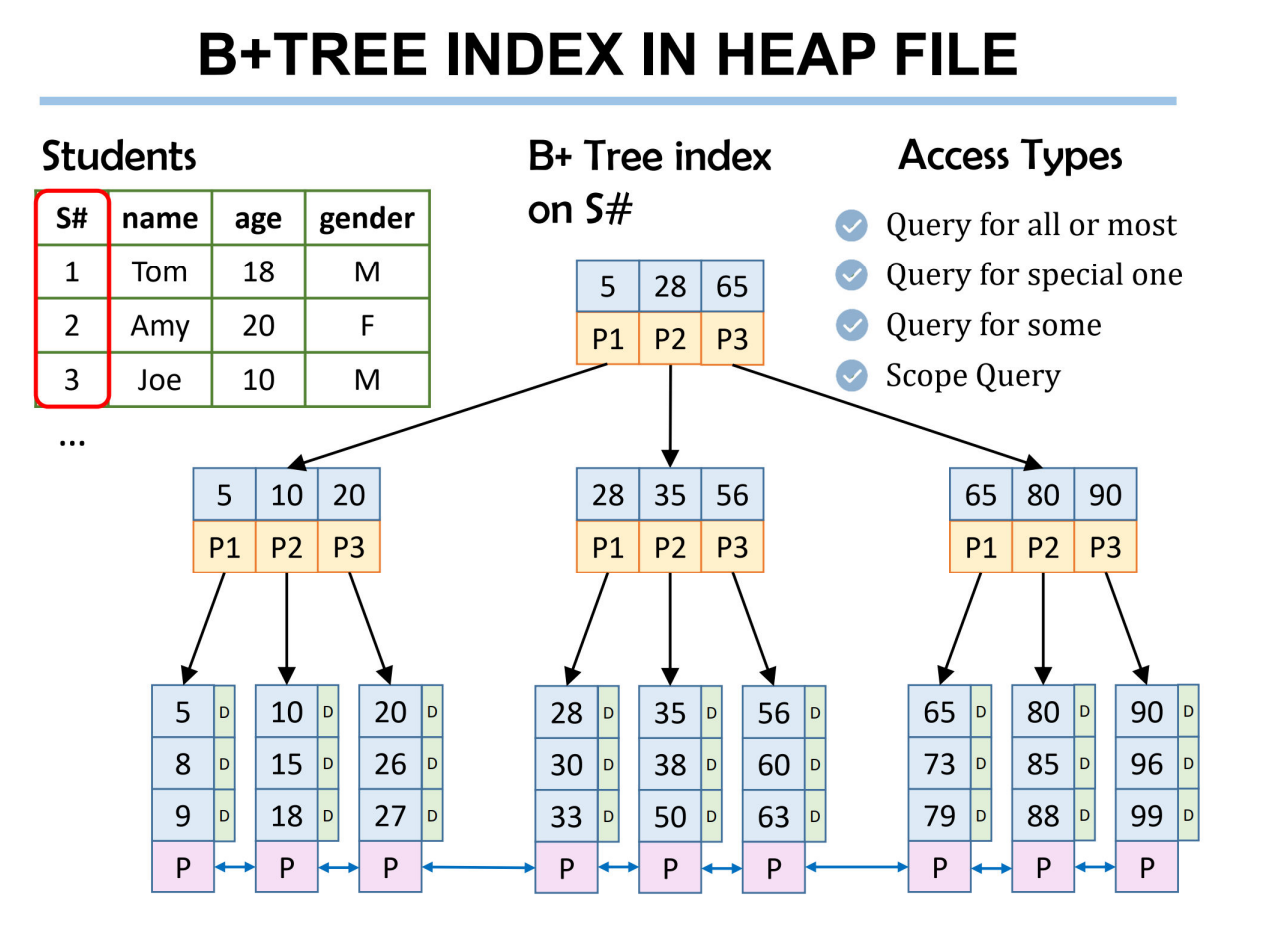
B + 树索引能高效支持 4 类查询:
a.全量 / 大部分数据查询:通过叶子节点的链表遍历,快速获取大量数据;
b.单条数据查询:从根节点逐层定位到叶子节点,直接找到目标S#;
c.部分数据查询:定位到目标范围的叶子节点,遍历链表获取部分数据;
d.范围查询:同样利用叶子节点的链表,快速获取某一区间内的S#数据。
裸磁盘
硬盘结构:盘片 1 → 磁道 → 扇区 → 读写磁头 → 簇(聚集索引)
聚集索引:数据块在磁盘上的物理顺序与关系表中元组按某属性的逻辑顺序一致。
索引分类
通用方案:堆文件 + 聚集索引 + B + 树索引
按存储结构:B 树 / B + 树索引、哈希索引、位图索引、全文索引
按应用层级:普通索引、唯一索引、复合索引
按数据物理存储顺序与关键字逻辑顺序的关系:聚集索引、非聚集索引
访问原语

QUERY OPTIMIZATION查询优化
为何需要查询优化?
目标:以最低成本、最短时间获取用户查询结果。
DBMS 的查询优化操作
1.代数优化:先重写用户提交的查询语句
2.操作优化:确定获取结果的最有效操作方式和步骤
优化例子:
S表:存储供应商信息(SNUM供应商编号、SNAME名称、CITY城市);
P表:存储产品信息(PNUM产品编号、PNAME名称、WEIGHT重量、SIZE尺寸);
SP表:存储 "供应商 - 产品" 的供货关系(SNUM关联 S 表、PNUM关联 P 表、QUAN供货数量)。
需求是:查询 "位于南京、供应了 1000 件以上'螺栓(Bolt)'产品" 的供应商名称。
S(SNUM, SNAME, CITY)
P(PNUM, PNAME, WEIGHT, SIZE)
SP(SNUM, PNUM, QUAN)
SELECT SNAME
FROM S, SP, P
WHERE S.SNUM=SP.SNUM AND
SP.PNUM=P.PNUM AND
S.CITY='Nanjing AND
P.PNAME='Bolt' AND
SP.QUAN>1000;
step1:关系代数转语法树
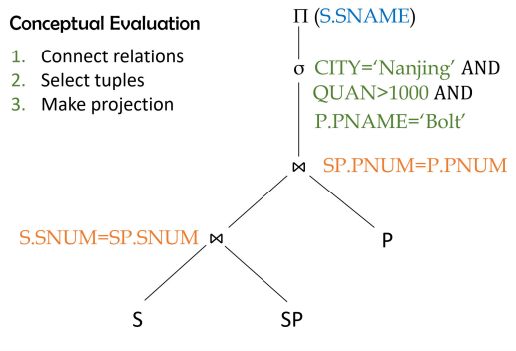
step2 可下移的选择语句下移
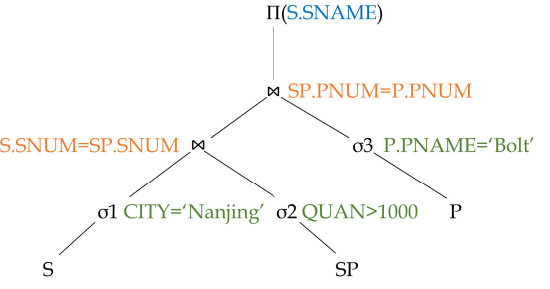
step3 去除不需要的列投影
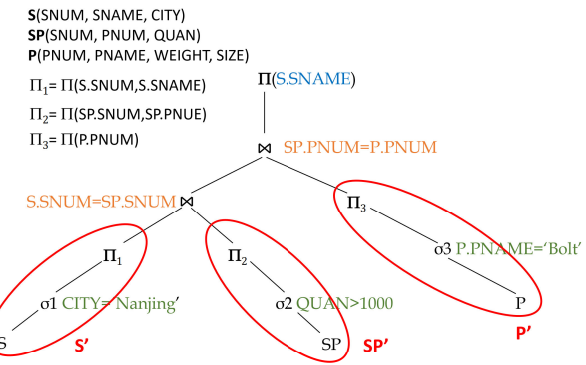
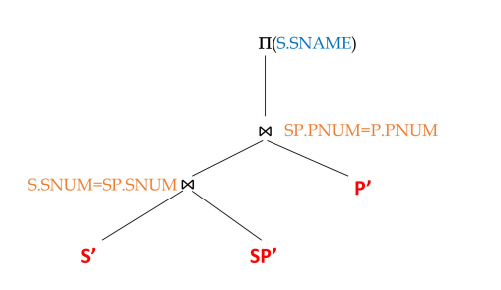
基本原则
代数优化的目标是最小化二元操作的操作数规模:
尽可能将一元操作下推
查找并合并公共子表达式
连接操作优化
1.嵌套循环(Nest Loop):一个关系作为外层循环关系(O),另一个作为内层循环关系(I)。外层关系的每个元组都需扫描一次内层关系以检查连接条件。
优化方式:利用块缓冲区提升效率。对于(R \bowtie S)(R 为外层,S 为内层),(b_R)为 R 的物理块数,(b_S)为 S 的物理块数,系统有(n_B)个块缓冲区((n_B≥2)),其中(n_B-1)个用于外层,1 个用于内层,则总磁盘访问次数为:(b_R + \lceil b_R / (n_B - 1) \rceil × b_S)
2.归并扫描(Merge Scan):预先对关系 R 和 S 排序,按顺序比较元组,每个关系仅需扫描一次。若未预先排序,需考虑排序成本是否值得。
3.利用索引或哈希查找映射元组:在嵌套循环中,若内层关系(I)有合适的访问路径(如 B + 树索引),可替代顺序扫描;连接属性上有聚集索引或哈希时效果最佳。
4.哈希连接(Hash Join):因 R 和 S 的连接属性域相同,可通过同一哈希函数将两者哈希到同一哈希文件,再基于该文件计算连接。
Transaction Management
Recovery恢复机制
DBMS 中恢复机制的主要作用:
降低故障发生的可能性(预防)
故障后恢复(解决):将数据库恢复到一致状态
实现这两个目标的关键:
1.冗余是必要的Redundancy is necessary.
2.需排查所有可能的故障Should inspect all possible failures.
3.恢复的通用方法:
定期转储(Periodical dumping)
备份 + 日志(Backup+Log)
定期转储(Periodical dumping)
周期性地将数据库的全部 / 部分数据复制到备份存储(如磁带、磁盘),当数据库故障(如数据损坏、丢失)时,可通过备份恢复数据。
常见类型:
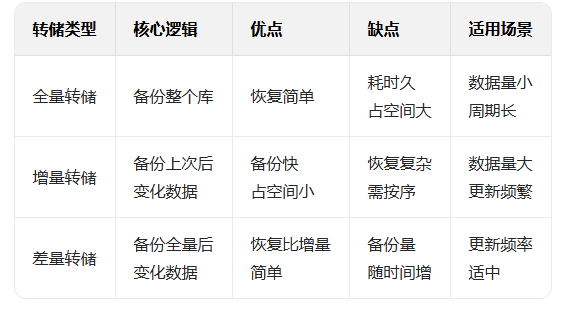
备份加日志
备份:提供数据库的基础状态(比如凌晨 2 点的全量备份),相当于恢复的 "起点"。
日志:记录备份之后所有的数据库操作(增删改查),比如redo日志(重做已提交事务)和undo日志(回滚未提交事务),相当于恢复的 "增量操作记录"。
优势
恢复精度高:不仅能恢复到备份点,还能恢复到故障前的最新状态;
减少备份频率:不用频繁做全量备份,靠日志补充即可,节省存储和时间。
TRANSACTIONS事务
事务(T)是数据库上的有限操作序列,具有以下特性(ACID):
A:原子性(Atomic action):要么全部执行,要么全部不执行(非此即彼)
C:一致性(Consistency preservation):使数据库从一个一致状态转换到另一个一致状态
I:隔离性(Isolation):并发事务的执行应相互独立,互不干扰
D:持久性(Durability):成功完成的事务效果永久反映在数据库中,即使后续发生故障也可恢复
事务的 ACID 特性由 DBMS 提供保障。

SOME STUCTURES TO SUPPORT RECOVERY支持恢复的相关结构
这些信息(如日志)需存储在非易失性存储(如磁盘)里,不能存在内存(断电丢失),是恢复的 "依据"。
1.提交列表(Commit list) :已提交事务的事务标识(TID)
作用:故障后,能快速识别哪些事务是完成的,需要保留这些事务的修改结果。
2.活动列表(Active list) :记录故障发生时正在执行、还没提交的事务 ID。
作用:系统恢复时,这些未完成的事务需要被回滚(撤销所有已做的修改),避免数据不一致。
3.日志(Log) :数据库的 "操作账本",每一条日志记录事务对数据的修改细节,核心包含两个关键数据版本:
前像(Before Image, B.I) :数据被修改之前的原始值。
用途:事务需要回滚时,用前像把数据恢复到修改前的状态(undo 操作)。
后像(After Image, A.I) :数据被修改之后的新值。
用途:系统崩溃后,用后像重新执行已提交事务的修改(redo 操作)。
执行规则:
1.提交规则(Commit Rule)
要求:事务正式提交前,必须把该事务的所有后像(A.I)写入非易失性存储的日志中。
原理:只有后像安全落地到磁盘日志,才能确认事务的修改有记录。否则如果提交后日志还在内存,崩溃后就没法恢复这个事务的修改。
2.日志先行规则(Log Ahead Rule)
要求:如果要把后像(A.I)直接写入数据库的物理数据区,必须先把对应的前像(B.I)写入日志。
原理:这是 "先记旧值,再改新值" 的逻辑。万一修改数据的过程中系统崩溃,能通过日志里的前像回滚,避免数据变成 "半修改" 的错误状态。
举例:
事务 T1 要把数据 X 的值从 10 改成 20:
1.先把 X 的前像(10) 写入日志(遵守日志先行规则);
2.修改数据库中的 X 为 20(生成后像 20);
3.把 X 的后像(20) 写入日志;
4.把 T1 加入提交列表(遵守提交规则);
5.若此时系统崩溃,恢复时会通过日志重做 T1 的修改,X 最终是 20;
6.若步骤 3 没完成就崩溃,T1 在活动列表里,会用前像 10 回滚 X 的值。
更新策略
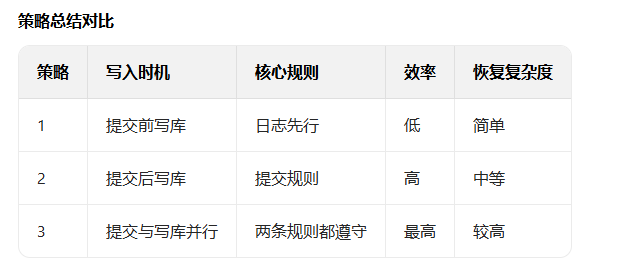
事务提交前 / 后将变更写入数据库的策略:
策略一:提交前将后像(A.I)写入数据库
事务正式提交前,就把修改后的新值(A.I)写入数据库物理存储,全程严格遵守日志先行规则(先写 B.I 到日志,再改数据库)。
流程:
事务启动,生成TID并加入活动列表(标记为 "执行中");
把数据原始值(B.I)写入日志(日志先行规则);
把新值(A.I)写入数据库;
把TID加入提交列表(标记为 "已提交");
从活动列表删除TID,事务结束。
故障恢复处理
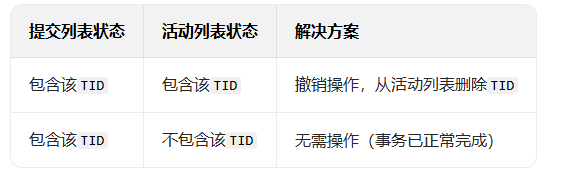 提交前就写库,若故障时TID同时在两个列表,说明 "写库完成但事务状态未清理",需撤销避免数据残留。
提交前就写库,若故障时TID同时在两个列表,说明 "写库完成但事务状态未清理",需撤销避免数据残留。
策略 2:提交后将后像(A.I)写入数据库
事务先完成提交(TID加入提交列表),再把 A.I 写入数据库,全程遵守提交规则(提交前必须把 A.I 写入日志)。
执行流程
事务启动,TID加入活动列表;
把新值(A.I)写入日志(满足提交规则);
把TID加入提交列表(事务提交);
把 A.I 写入数据库;
从活动列表删除TID,事务结束。
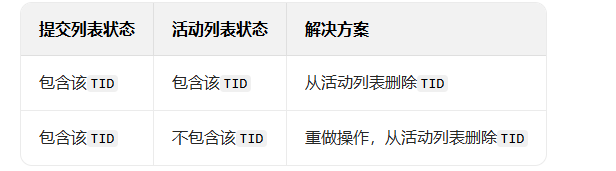
恢复逻辑:提交后才写库,若故障时TID在提交列表但活动列表无记录,说明 "事务提交但写库未完成",需用日志重做写库操作。
数据库写入操作集中执行,减少磁盘 I/O 的分散调用,效率比策略 1 更高。
策略 3:提交与 A.I 写入数据库并行执行
事务启动,TID加入活动列表;
同时把 B.I 和 A.I 写入日志(满足两条规则);
并行执行两个操作:① 把TID加入提交列表;② 把 A.I 写入数据库(允许部分完成);
等待数据库写入完全完成后,从活动列表删除TID。
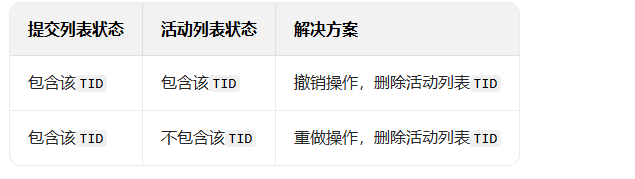
恢复逻辑:并行操作可能导致 "提交完成但写库部分完成" 或 "写库完成但提交状态未更新",因此需要根据列表状态选择撤销或重做。
并发控制
多用户 DBMS 允许多个事务并发访问数据库。
支持并发的原因
提高系统利用率和响应速度
不同事务可能访问数据库的不同部分
并发执行引发的问题
脏读(Dirty Read)
不可重复读(Non Repeatable Read)
幻读(Phantom Read)
丢失更新(Lost Update)
可串行化(SERIALIZATION)------ 并发一致性准则
串行执行:事务一个接一个来,前一个做完,后一个才能开始。
比如有两个事务 T1 和 T2,串行执行只有两种可能:T1→T2 或 T2→T1。
并发调度:多个事务 "同时" 执行(实际是 CPU 快速切换执行,看起来并行),操作可能交叉。
比如 T1 改数据的同时,T2 读数据,此时就需要判断这个交叉执行的结果是否符合 "串行标准"。
并发调度的结果,只要和 任意一个串行执行顺序 的结果相同,就是可串行化的。
封锁协议(LOCKING PROTOCAL)
1. X 锁(排他锁)
仅一种锁类型,同时用于读和写操作。
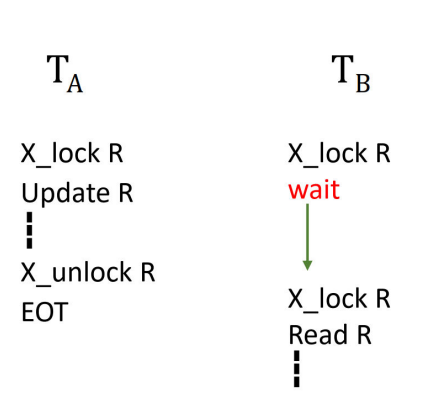
2. 两阶段封锁(TWO PHASE LOCKING)
定义 1:若事务中所有加锁操作都在解锁操作之前完成,则该事务为两阶段事务,此限制称为两阶段封锁协议。
定义 2:若事务在操作对象前先获取其锁,则该事务为结构良好的事务。
定理:若调度 S 由结构良好且遵循两阶段封锁协议的事务组成,则 S 是可串行化的。、
两阶段封锁总结
结构良好 + 两阶段封锁 → 可串行化
结构良好 + 两阶段封锁 + 事务结束时解锁更新锁 → 可串行化且可恢复(无多米诺现象)
结构良好 + 两阶段封锁 + 事务结束前持有所有锁 → 严格两阶段封锁事务
死锁与活锁(DEADLOCK & LIVE LOCK)
死锁(Deadlock)
事务循环等待,均无法获取完成所需的全部资源。示例:
事务 TA:X 锁(R1)→ 等待 X 锁(R2)
事务 TB:X 锁(R2)→ 等待 X 锁(R1)
活锁(Livelock)
其他事务在有限时间内释放资源,但某事务长时间无法获取所需资源。示例:
事务 T1:S 锁(R)
事务 T2:S 锁(R)
事务 T3:X 锁(R)→ 等待 → T1 解锁 → T2 解锁 → T1 再次加 S 锁 → T3 持续等待