In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation
作者将OVSS的过程解耦了两个独立的过程,首先使用Ncut算法迭代生成多个二分图 ,这个过程是纯视觉任务,完全不需要类名称。
使用DINO的相似度图生成Ncut的权重
有点类似MaskFormer,就是生成一些与类别无关的掩码。
迭代生成多个二分图的过程作者称之为类别掩码发现(Object Mask Discovery) 。
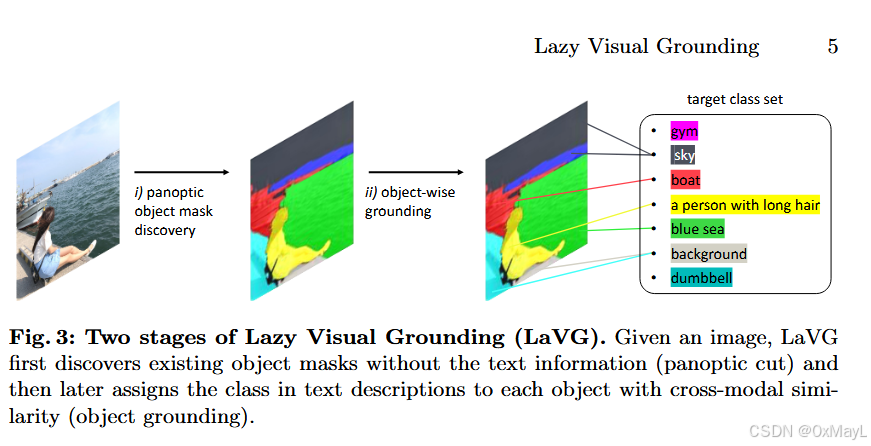
对于每一个二分掩码,作者是需要使用CLIP/SCLIP提取视觉特征,最后区域内所有特征求平均,得到类别原型 ,然后与文本嵌入匹配就行。

GPT
下面基于论文 《In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation》 (Kang & Cho, 2024)对方法部分做"动机→设计→对比→实验→复现建议→总结"的深度解析,并在关键处引用原文内容。
0. 摘要翻译(Abstract)
作者提出 Lazy Visual Grounding (LaVG) :一种用于开放词汇语义分割(OVSeg)的两阶段 方法:
(1) 无监督 发现对象级 mask;(2) 再把文本标签"晚交互"地分配到这些对象上。大量已有方法把 OVSeg 当作像素到文本的分类 (pixel-to-text classification),依赖预训练视觉-语言模型的图文对齐能力,但缺乏对象级理解。作者认为:分割本质是视觉任务,"对象"在没有文本先验时也能凭视觉被区分。LaVG 先用迭代 Normalized Cuts 覆盖整张图的对象 mask(作者称为 Panoptic cut ),再对每个对象做文本匹配。全流程无需额外训练,在 Pascal VOC/Context、COCO-Object/Stuff、ADE20K 上表现强,且边界更精细。
1. 方法动机
a) 为什么提出这个方法(驱动力)
- 作者的核心不满是:现有训练自由(training-free)的 OVSeg 往往"懂词不懂物"------利用 CLIP 类模型对齐 patch-text,但输出 mask 边界粗糙、噪声多,且容易产生"像素级伪相关"。论文图 1 直观对比了像素式方法(如 SCLIP)与其对象式方法的边界差异。
- 作者回到一个经典直觉:**"先分割出视觉上可分的对象,再去命名"**更符合分割的本质(先有物体形状与边界,再有语义归类)。引言中明确提出"分割本质是视觉任务,不需要先知道名字也能分割"。
b) 现有方法痛点/不足(具体局限)
论文主要把对手概括为两类,并指出痛点:
-
像素-文本分类式 OVSeg(pixel grounding)
-
直接对每个像素/patch 与文本做相似度分类,缺少对象级约束,导致:
- 轮廓不齐、边界"糊"、区域破碎;
- 容易出现 spurious correlation(把不该属于某类的纹理/背景误分过去)。
-
-
可训练的 class-agnostic mask + grounding
- 需要额外训练 MaskFormer 等(作者在 related work 提到),训练成本高,不符合"训练自由"的目标。
c) 研究假设/直觉(一句话)
- 对象的可分性主要来自视觉线索(边缘/纹理/显著性),文本先验不是分割的必要条件;文本更适合在对象级别"晚绑定"。
2. 方法设计(核心:非常细致的 pipeline)
LaVG = Stage 1:Panoptic cut(视觉-only 的对象/背景分割) + Stage 2:Object grounding(对象级别文本匹配)。图 3 给了两阶段示意。
2a) 逐步 Pipeline:输入 → 处理 → 输出(细到可复现)
Stage 1:Panoptic Object Mask Discovery with Normalized Cut(作者称 Panoptic cut)
输入: 一张图像 I
输出: 一组互不重叠、尽量覆盖全图的 mask 集合(对象 + 剩余背景)
Step 1.1:用 DINO ViT 提取"适合分割"的密集特征/注意力线索
- 图像输入预训练自监督 ViT(DINO ViT-B/8)。作者强调用的是 ViT 前向过程的"中间副产物"作为 dense feature,因为它经验上更突出前景显著区域。
Step 1.2:构图(Graph construction):patch token 为节点,相似度为边权
- 在最后一层,作者用 key token 的余弦相似度 构造 affinity matrix:
W_{xx'}=\\frac{K_x\^\\top K_{x'}}{\|K_x\|*2\|K* {x'}\|_2}
这里每个位置 x 的 key embedding 是一个节点;W 是 N×N 的权重矩阵(N=patch 数)。
Step 1.3:Normalized Cut 求解二分割(bipartition)
- 经典 Ncut 目标:避免最小割产生"切出很小一块"的坏解,通过 assoc 归一化平衡子图。
- 通过广义特征值问题求解:
(D-W)x=\\lambda Dx
取第二小特征值对应特征向量(Fiedler vector),再用"高于均值/否则"的规则把节点分到 A/B 两边完成二分割。
Step 1.4:判断哪一半是"前景对象"(foreground selection heuristics)
-
作者借鉴 MaskCut 的启发式:
- A 若包含特征向量 z 的最大绝对值位置;
- 且 A 不应覆盖矩阵的两个角(避免把大背景角落当对象)。
满足则把 A 视作对象;另一半作为待继续切的"背景集合"。
Step 1.5:迭代切割,直到覆盖语义分割需要的"全像素"(panoptic-like)
-
与传统"只找前景对象"的无监督发现不同,作者要的是语义分割/全像素分类,所以迭代对剩余区域继续做 Ncut:
- 终止条件:剩余节点过少 或 达到最大迭代次数(实现中 max iter=16)。
- 未被发现的区域最后标为 background。
Step 1.6:mask 后处理(边界清理)
-
观察到 raw cut 会有孔洞、椒盐噪声(图 4),于是:
- 填洞 + DenseCRF refinement;
- 再 resize 回原图大小。
Stage 1 小结: 这一步完全不看文本,只靠 DINO 特征 + 图割把图像切成对象/背景块,尽量让 mask 覆盖全图(因此叫 Panoptic cut)。
Stage 2:Object Grounding with Class Descriptions in Text(对象级文本对齐)
输入:
- Stage 1 的每个对象 mask ( \mathcal{M} )
- 文本类别集合 {class description}(可含 background queries)
- 一套视觉-语言编码器(作者用 SCLIP/CLIP)
输出: 每个 mask 的类别标签(从文本集合中选)
Step 2.1:文本编码
- 将 Y 个类别描述输入 CLIP text encoder,得到 ({c_y}_{y=1}^Y)。
- 如果 benchmark 需要 background 类,作者不直接用"background"这个模糊词,而是用 wall/sky 等背景查询集合(沿用 SCLIP 的设置)。
Step 2.2:图像编码(dense patch features)
- 输入图像到 SCLIP image encoder,得到每个位置的特征 (f_x)。
Step 2.3:对象原型(object prototype)= mask 区域内特征平均
- 对每个 mask (\mathcal{M}),把落在 mask 内的 patch 特征做平均,形成对象级表示(原型思想)。
Step 2.4:对象-文本相似度打分,得到类别分布
- 用对象原型与各文本 embedding 做余弦相似度/点积,公式写成:
p(,f_{x\\in\\mathcal{M}}\\mid y)\\propto \\frac{1}{\|\\mathcal{M}\|}\\sum_{x'\\in\\mathcal{M}} f_{x'}\^\\top c_y
- 取相似度最高的 y 作为该对象的类别(object-wise grounding)。
Step 2.5:生成最终分割图
- 把每个对象 mask 填上预测类别;logit map 插值回原图;若用了 background query 集合,把对应 logits 合并为 background。
2b) 模块结构与协同
- DINO ViT(视觉-only):提供可用于"对象显著性/边缘纹理"的 dense 表征,适合图割产生干净边界(作者也在附录实验中比较了用 DINO vs 用 SCLIP 来做 cut,DINO 更好)。
- Normalized Cut / Panoptic cut(图算法模块):把 dense token graph 切成对象级区域,并通过迭代覆盖全图。
- SCLIP/CLIP(跨模态对齐模块):只在第二阶段使用,用来给"已经成形的对象 mask"贴标签,避免像素级对齐带来的噪声扩散。
2c) 关键公式/算法的通俗解释(它们在方法中的角色)
- Ncut 目标:不是只要"切断的边最少",还要防止把图切成"1 个点 vs 剩下全部"这种无意义分割,所以用 assoc 做归一化平衡。
- 广义特征值问题 (D−W)x=λDx:把"最好的二分割"转成求第二小特征向量;该向量的正负/高低把节点天然分两簇。
- 对象原型平均(Eq.8):把对象内部所有 patch 的跨模态语义"汇总",用对象级别的表示去跟文本比,而不是逐像素硬比,从而更稳。
3. 与其他方法对比
a) 本质不同点
- 像素 grounding(主流 training-free):先把每个像素/patch 与文本对齐 → 再得到分割。
- LaVG(作者) :先视觉分割出对象(不看文本)→ 再在对象级别做文本匹配(晚交互)。作者将其称为 late text interaction / lazy grounding。
b) 创新点与贡献度(明确列点)
- 两阶段"先物后名"的训练自由 OVSeg(Lazy Visual Grounding)。
- Panoptic cut:把 Ncut 用于 DINO token graph,并"迭代到覆盖全像素"的语义分割版本(区别于只找前景的 object discovery)。
- 0 训练成本:不需要额外训练就能在多个数据集上取得 SOTA 量化表现。
- 边界质量显著更好:强调"视觉上更讨好/更干净的 mask",虽然 mIoU 未必完全体现这种优势(作者在局限性里也承认)。
c) 更适用的场景(适用范围)
- 需要对象级边界精细、且希望训练成本为 0 的开放词汇分割/grounding:比如快速部署、算力/数据不足、或对"轮廓质量"更敏感的下游(作者结论也强调适合需要精确边界的 grounding 任务)。
- 不太适合:超大分辨率密集推理/强实时要求(图割开销大);或闭集专业领域(医学/工业)若 CLIP 语义不匹配,需要换领域编码器。
d) 表格总结:方法对比(优点/缺点/改进点)
| 方法范式 | 代表 | 核心机制 | 优点 | 缺点/风险 | LaVG 相对改进点 |
|---|---|---|---|---|---|
| 像素→文本分类(pixel grounding) | CLIP, SCLIP 等 | 每像素/patch与文本相似度分类 | 简单、推理快 | 边界糊、噪声、伪相关;缺对象级约束 | 先对象分割再贴标签,明显减少像素噪声与边界不齐 |
| 可训练 mask + grounding | MaskFormer系/弱监督OVSeg | 训练得到类无关 mask,再与文本对齐 | 端到端可学,指标潜力高 | 需要额外训练数据/算力 | LaVG 完全免训练仍能达到/超过部分训练法 |
| 扩散/生成式 training-free | DiffSegmenter 等 | 借助扩散模型/生成能力做分割 | 免训练、可用大模型先验 | 参数大、计算重 | LaVG 用更轻 backbone,但图割迭代引入较慢推理 |
| LaVG(本文) | LaVG | DINO+Ncut 发现对象;SCLIP 对象级匹配 | 免训练;边界质量高;SOTA mIoU | 推理慢;图割内存压力;偶发误分类 | 用"晚交互"避免像素级噪声扩散;Panoptic cut 覆盖全像素 |
4. 实验表现与优势
a) 作者如何验证有效性(实验设计/设置)
-
数据集:VOC、Context、COCO-Object、COCO-Stuff、ADE20K;并设置"带背景查询"的 VOC21/Context60 等(表 1)。
-
指标:mIoU。
-
实现要点:
- Panoptic cut 用 DINO ViT-B/8;Ncut 的特征值问题用 PyTorch
lobpcg(GPU 可跑);max iter=16;mask 用 DenseCRF 精炼。 - 视觉-语言用 CLIP ViT-B/16 + SCLIP patch feature;高分辨率用 sliding-window(短边 336,窗口 224,stride 112)并对 logits 平均。
- Panoptic cut 用 DINO ViT-B/8;Ncut 的特征值问题用 PyTorch
b) 关键数据:超越哪些方法(代表性结论)
-
Table 2(七个 benchmark):LaVG 在 VOC21/Context60/COCO-Obj/VOC20/Context59 上均高于 SCLIP,并总体优于多种训练自由与部分训练法。比如:
- VOC21:LaVG 62.1 vs SCLIP 59.1
- COCO-Obj:34.2 vs 30.5
- VOC20:82.5 vs 80.4
(同表也对比 MaskCLIP、TCL、GroupViT 等)。
c) 哪些场景优势最明显(证据)
-
质化优势极明显:Figure 5/6 展示了更干净的对象轮廓、更少孔洞、更少错边界;作者特别强调"视觉效果更好、边界更 crisp"。
-
组件消融证据(Table 3/4):
- Panoptic cut 迭代从 4→16 次带来约 0.5~1.3 mIoU 增益,并趋于饱和。
- 对象 embedding 方案中,"mask 内特征平均原型(Eq.8)"比 O-masked attention / 模糊背景等更好且更省一次次前向。
d) 局限性(论文承认/隐含)
作者专门列了限制(4.4):
- 计算/内存重:N×N affinity 矩阵导致图割开销大;高分辨率直接切会 OOM,只能在下采样 token 图上做。
- mIoU 不完全反映边界质量:虽然边界显著更好,但像素级 mIoU 对"轮廓干净"不敏感;偶发误分类会拉低 mIoU。
- 滑窗带来 part-whole ambiguity:局部 crop 可能把"云/天"等纹理区域混淆。
- CLIP 领域适配问题 :在医学/工业等专业闭集领域可能不合适,但"lazy grounding 思想"可迁移到领域 encoder。
另外从 Table 5 看:LaVG 训练时间为 0 ,但推理时间明显更长(12.59s),这是很现实的 trade-off。
5. 学习与应用(复现/实现建议)
a) 是否开源?
论文首页给了项目页链接(作者实验室页面)。我在离线环境下无法直接验证仓库状态,但论文明确提供了项目主页入口。
b) 复现关键步骤(落地视角)
按"最小可用复现"排序:
-
实现 Panoptic cut
- 提取 DINO ViT-B/8 的 patch key 特征或作者用的中间 dense feature;
- 构造 W(patch-token cosine similarity);
lobpcg解第二小特征向量;按均值阈值二分;按启发式确定前景;- 迭代切割剩余区域到 max_iter=16;未覆盖区域作为 background;
- DenseCRF + fill holes 后处理。
-
实现对象级 grounding(Eq.8)
- 用 SCLIP 得到每个 patch 特征 (f_x);
- 每个 mask 内做平均得到 prototype;
- 与文本 embedding 计算相似度并 argmax。
-
高分辨率 sliding-window 推理(强烈建议开)
- 短边 resize 到 336;window=224,stride=112;对窗口 logits 平均融合;这在消融(Table 7)中对性能提升非常大。
c) 超参数/预处理/训练细节注意点(实现建议)
- max_iter=16:作者显示 16 已接近饱和,32 提升很小。
- 图割分辨率:不要在原图像素级建图,会 OOM;应在 token 网格上做(本质是用 ViT patch 数 N 控制复杂度)。
- CRF 强度:论文没展开 CRF 超参,但从图 4 的"去椒盐/补洞"效果看,这是边界质量关键一环。
- 背景类处理:不要用"background"单词,使用 wall/sky 等背景 query 集合(作者沿用 SCLIP 的 set)。
- backbone 分工:作者明确比较了"用 SCLIP 做 cut"会变差,建议坚持 DINO 做 cut、SCLIP 做 grounding。
d) 能否迁移到其他任务?如何迁移?
可以,且迁移路径很清晰:
- 开放词汇实例分割/对象级 grounding:把 Stage1 产出的对象 mask 当作"候选实例",Stage2 做文本匹配即可;作者在结论里也提到这可能打开训练自由 open-vocab instance segmentation 的方向。
- 领域专用分割:保留"先对象分割后语义绑定"的框架,把 Stage2 的 CLIP 换成领域图文/文本-视觉 encoder(作者在局限性里也这么建议)。
6. 总结
a) 20 字内核心思想
先视觉分对象,再对象级贴文本标签。
b) "速记版 pipeline"(3--5 步,尽量自明、少术语)
- 用自监督视觉特征把图像变成网格表示
- 用图划分反复把网格切成多个区域,直到覆盖整图
- 对每个区域把内部特征做平均得到"区域表示"
- 把区域表示与文本类别逐个算相似度并选最大
- 把选中的类别写回对应区域得到分割图
如果你希望我再进一步:我可以把 Panoptic cut 的迭代流程画成更"实现导向"的伪代码(含数据结构、张量形状、复杂度瓶颈位置),以及结合 Table 5 讨论如何在工程上降推理时间(例如稀疏图/近邻图替代全连接 W、分层切割等),都可以继续在这篇论文范围内展开。