千问介绍
Qwen(通义千问)是阿里巴巴 Qwen 团队研发的开源大语言与多模态模型系列,主打中文优化、全尺寸覆盖与多模态能力,当前最新稳定版为 Qwen3,面向通用与垂直场景的全栈模型,支持文本、图像、音频、工具调用、智能体等任务,中文表现突出,同时覆盖多语言Qwen
核心能力
- 文本能力:理解、生成、翻译(100 + 语言)、对话、逻辑推理Qwen。
- 多模态能力:图像理解(Qwen‑VL)、音频处理、代码生成(支持 200 + 语言)。
- 长上下文:最新版本支持超长上下文(最高 1000 万 tokens),适配长文档处理。
- Agent 与工具调用:双模式切换,复杂任务工具集成能力突出Qwen
部署与开源生态
- 开源与获取:全系列模型开源(含 MoE),可通过 Hugging Face 等平台下载,支持商用(需遵循许可协议)。
- 部署方式
- 本地部署:适配 GPU/CPU,支持 LoRA 微调。
- 云端服务:阿里云通义千问 API / 服务,低代码集成。
- 工具链:支持 Transformers、vLLM、LangChain 等主流框架。
- 应用场景:企业服务(金融、医疗、教育等)、智能助手、内容生成、代码辅助(通义灵码)等。
大模型下载:
ollama pull xxx
我们可以从ollama上下载,也可以从modelscope下载,也可以从huggingface下载对应的千问大模型
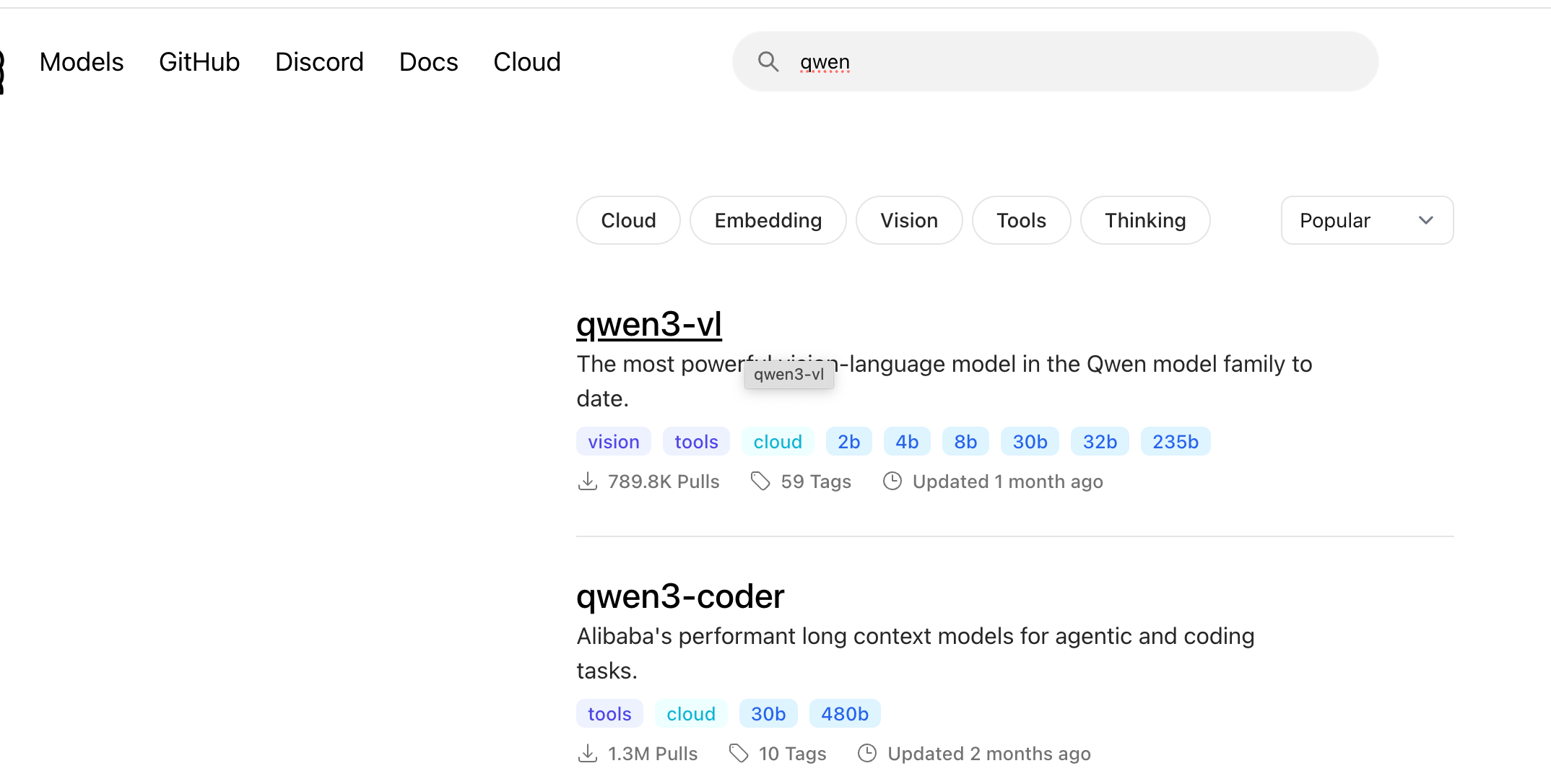
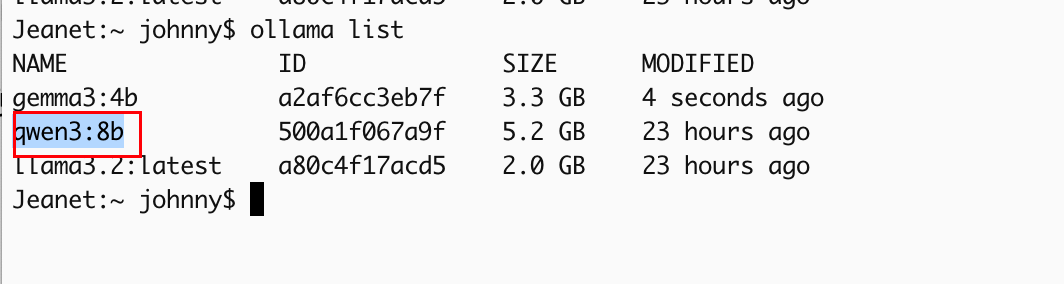 视觉大模型Qwen-VL:
视觉大模型Qwen-VL:
文本理解与生成、视觉内容感知与推理、长上下文支持、空间关系及动态视频理解,以及与人工智能代理的交互能力等
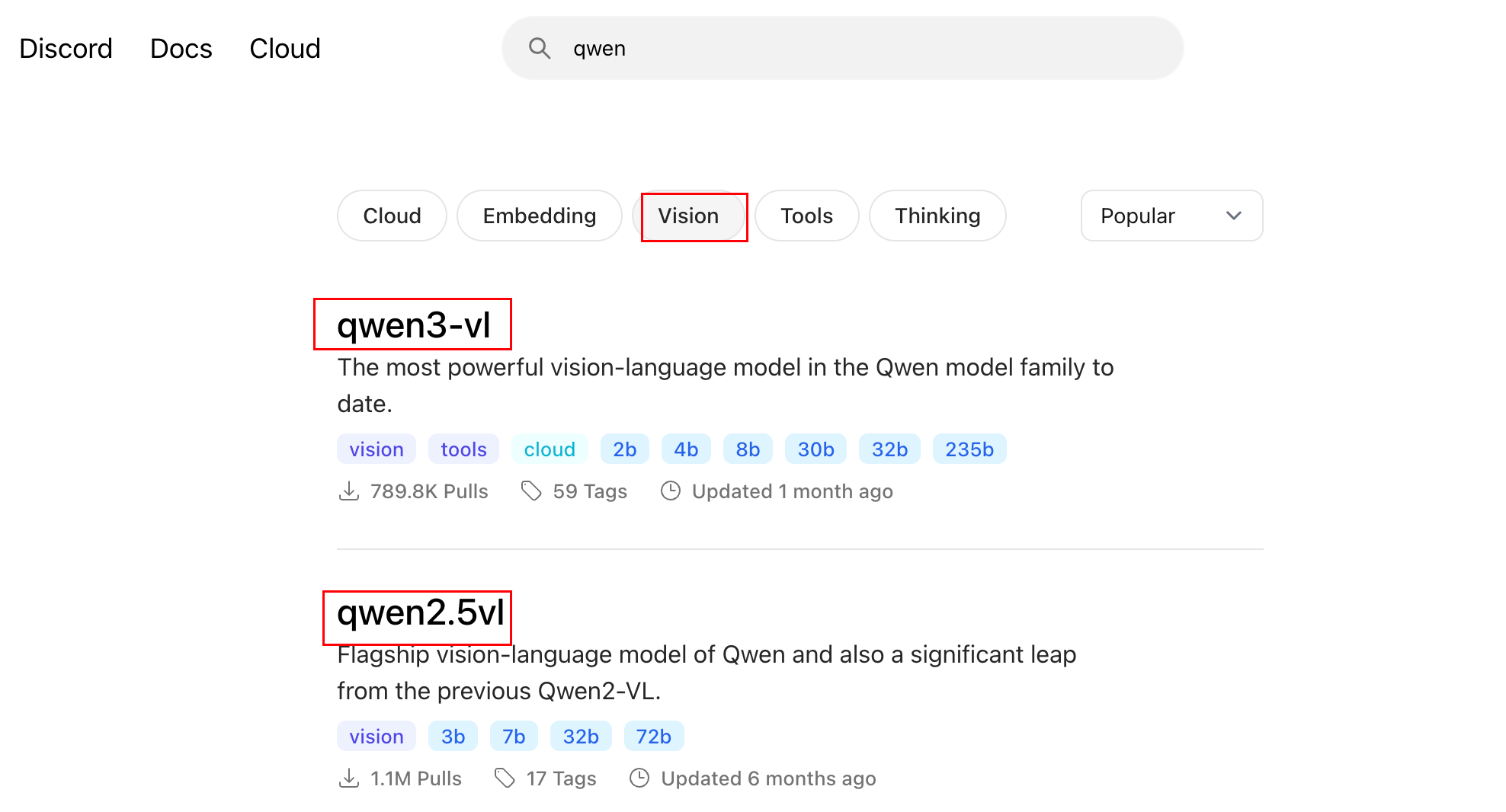

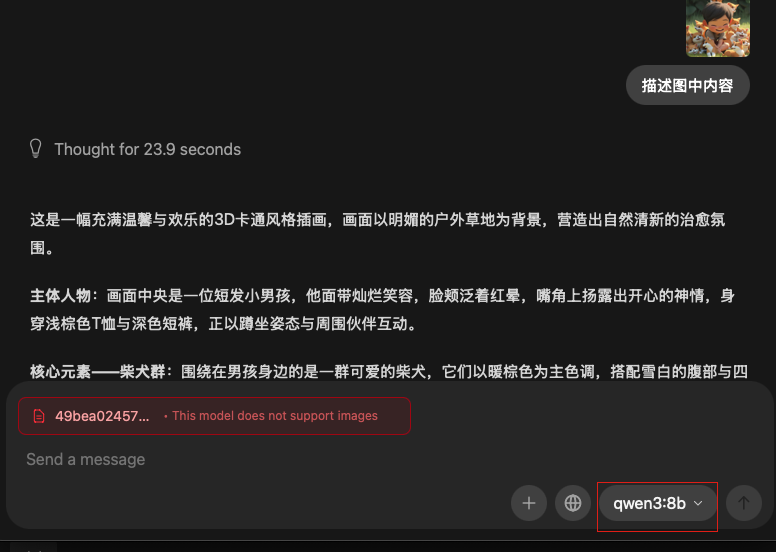
让qwen-vl模型识别图片:
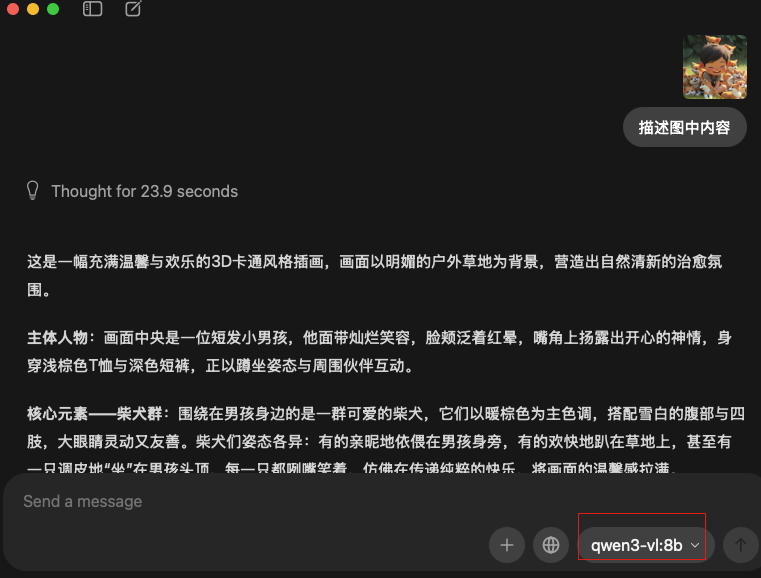
让非vl模型识别图片:提示模型不支持
编程调用vl视觉大模型:
python
from langchain_ollama import ChatOllama
from langchain_core.messages import SystemMessage, HumanMessage
def test_qwen_vl():
llm = ChatOllama(
model="qwen3-vl:8b",
base_url="http://localhost:11434", # Ollama 默认服务地址
temperature=0,
)
messages = [
# 可选:系统指令,定义模型行为
SystemMessage(content="你是一个专业的多模态分析助手,需精准识别图片内容并按要求回答。"),
HumanMessage(
content=[
{"type": "text", "text": SystemMessage},
{
"type": "image_url",
"image_url": {"url": "/Users/johnny/Desktop/duoradream.png"} # 适配 Ollama 图片格式
}
]
)
]
# 调用模型并返回结果
try:
response = llm.invoke(messages)
return response.content
except Exception as e:
return f"调用失败:{str(e)}"
if __name__ == '__main__':
print(test_qwen_vl())
输出:
图片中展示的是日本经典动漫《哆啦A梦》中的主角**哆啦A梦**。它有着标志性的蓝色身体、白色脸部、红色鼻子和铃铛项圈,此刻正坐在开满粉色与白色花朵的花丛中,闭着眼睛露出满足的微笑。周围飘落着粉色花瓣,背景是晴朗的蓝天与蓬松的白云,整体画面充满春日的生机与梦幻感,营造出温馨治愈的氛围。