Qwen2 VL visual encoder
Qwen2 VL中在patch size的基础上还会通过MLP 做一个2*2的merge,进一步减小viusal token输,并加上start 和 end token。
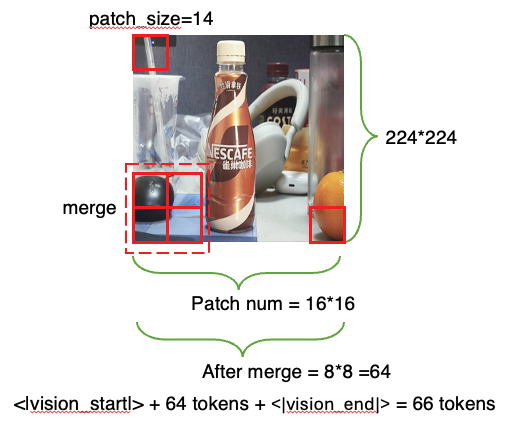
注意:在Qwen2VL以及Qwen2.5/3VL中,单张图像都是视为2张同样的帧作为输入的,因此在通过image_processor时,一个patch的pixel shape是14*14*3(RGB)* 2(视为相同2帧)= 1176

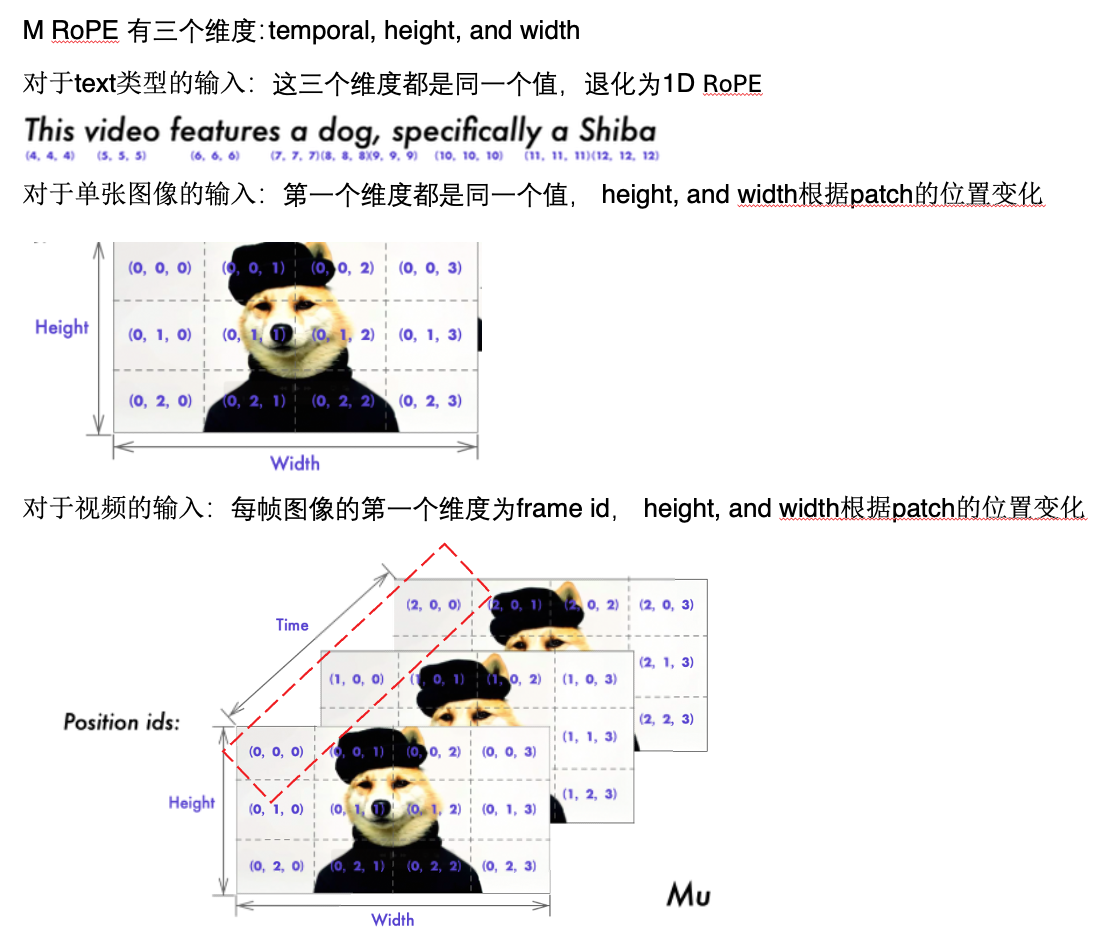
M-RoPE: MultimodalRotaryPositionEmbedding
Qwen2 VL做2D grounding还是采取的类似Qwen1 VL的特殊token的表示形式:
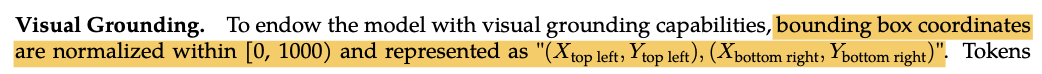


Qwen1 VL visual encoder
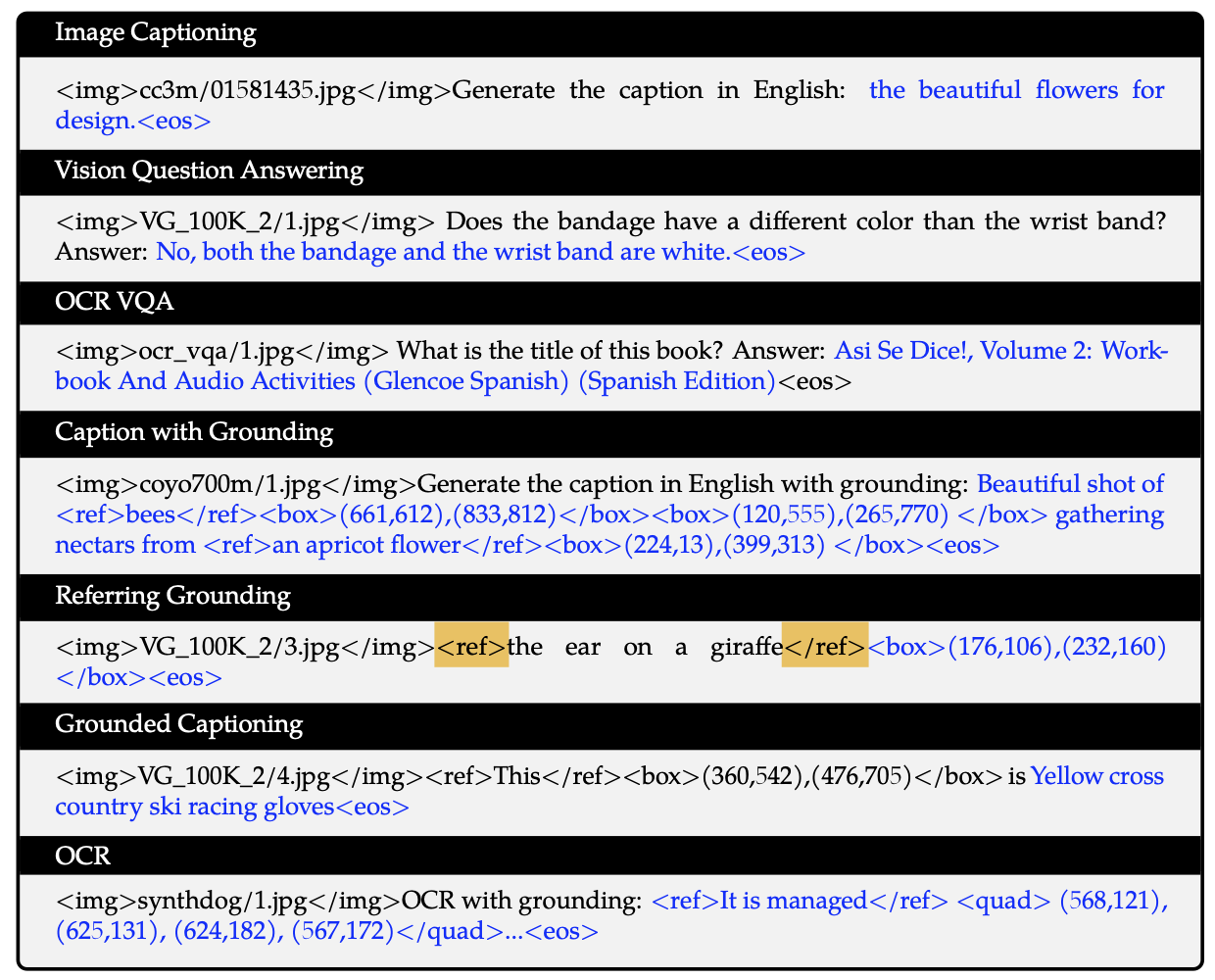
Qwen1 VL的visual encoder 其实是一个Q -former的架构,通过256个可学习的token来表示图像,并且这个版本中还不支持视频输入。只支持输出2D normaliezd 的bbox。范围是归一化到0,1000的图像grid空间。表示方式是文本,并通过<ref> ,和<box>的方式指代物体和对应的box。