LLaMA-Factory 部署与 DeepSeek-R1-Distill-Qwen 模型乱码问题解决全记录
摘要:本文记录了在远程 A100 服务器上部署 LLaMA-Factory,并加载 DeepSeek-R1-Distill-Qwen 系列模型时遇到的输出乱码问题。通过强制指定 Qwen2Tokenizer,最终完美解决。全过程包括环境配置、CUDA 版本协调、模型下载、问题排查与修复。
0、一点小废话
请注意AI环境版本迭代很快,本文编辑和实验时间2026年7月2日,您看到此文章时LLaMA-Factory框架、PyTorch、CUDA版本可能会有变动,请以三者官网公布最新的适配版本为准进行配置。
一、环境概览
- 本地:VSCode + Remote-SSH 插件
- 服务器:Ubuntu 24.04.3 LTS (NVIDIA A100)
- 目标框架:LLaMA-Factory
- 测试模型 :
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B及 1.5B 版本 - 最终稳定模型 :
Qwen/Qwen2.5-1.5B-Instruct(验证正常)
二、LLaMA-Factory 安装步骤
1. 克隆仓库
bash
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory2. 准备 Conda 环境(推荐)
若未安装 Miniconda:
bash
# 进入你的家目录
cd ~
# 下载最新 Miniconda 安装包(Linux x86_64)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 执行安装(按提示操作:空格翻页,yes 接受协议,回车确认安装位置)
bash Miniconda3-latest-Linux-x86_64.sh
# 安装完成后,关闭并重新打开终端,或者执行:
source ~/.bashrc⚠️ 若为 root 用户,建议将 conda 缓存和 envs 目录挂载到数据盘(如
/root/autodl-tmp/conda)避免占满系统盘。
参考挂载指令
bash
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/conda/envs
conda config --add envs_dirs /root/autodl-tmp/conda/envs3. 创建虚拟环境
bash
conda create -n llama-factory python=3.13.5 # 也可换为 3.11
conda activate llama-factory4. 安装 LLaMA-Factory 及其依赖
bash
pip install -e ".[torch,metrics]"5. 检验安装
bash
llamafactory-cli version若无报错,则基础安装完成。
三、CUDA 与 PyTorch 版本协调(重要)
安装后执行 llamafactory-cli version 可能出现警告:
CUDA version mismatch,因为默认安装的 PyTorch 编译时使用的 CUDA 版本与系统驱动不一致。
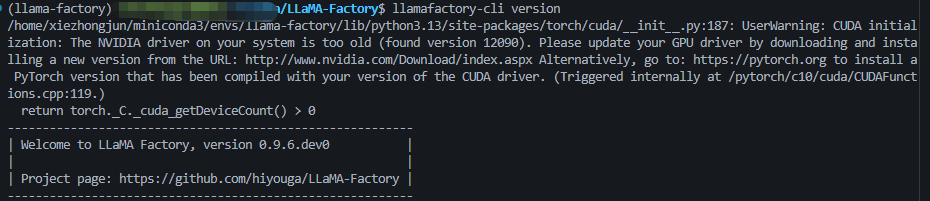
服务器 CUDA 版本 :12.9
默认 PyTorch 编译版本:13.0(不兼容)
解决方案:
-
查看当前 PyTorch 信息:
pythonpython -c "import torch; print('PyTorch version:', torch.__version__); print('CUDA compiled version:', torch.version.cuda)"

-
卸载默认 PyTorch:
bashpip uninstall -y torch torchvision torchaudio -
安装与 CUDA 12.9 兼容的 PyTorch(推荐 CUDA 12.6 版本):
查询PyTorch官网了解到目前适配12大版本CUDA的对应稳定版本是CU126:
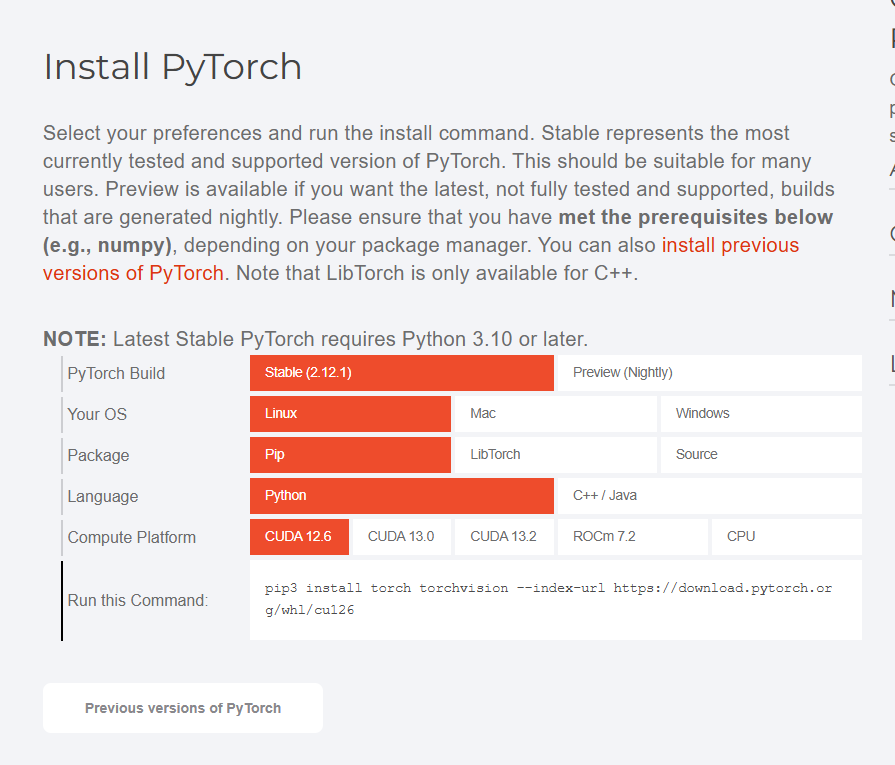
安装指令参考官网的版本
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126出现了三个报错,主要是有两个包版本过高需要降级,还有torchaudio漏装了,下面进行修复
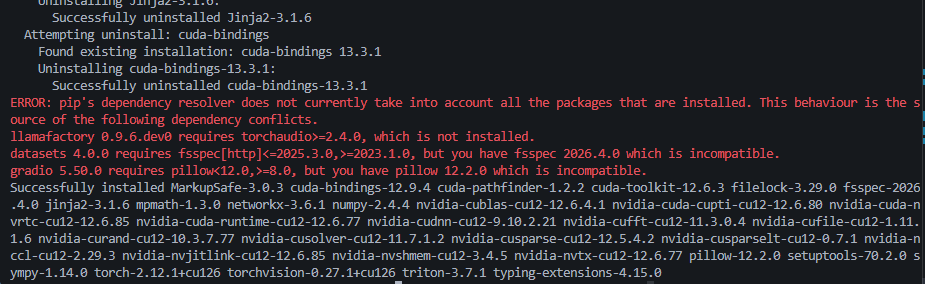
-
若
torchaudio未装,补装:bashpip install torchaudio --index-url https://download.pytorch.org/whl/cu126 -
降级冲突包(如
fsspec,pillow):bashpip install fsspec==2025.3.0 pillow==11.3.0
✅ 也可直接新建 conda 环境,先装Python和 PyTorch 全家桶,再装 LLaMA-Factory,避免依赖冲突,然后再把出错的conda环境删掉:
bashconda create -n llama-factory-311 python=3.11 -y conda activate llama-factory-311 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 cd ~/LLaMA-Factory pip install -e ".[torch,metrics]"
最终验证:
bash
python -c "import torch; print(torch.cuda.is_available()); print(torch.version.cuda)"
# 应输出 True 和 12.6别忘了确认llamafactory环境是否正常
bash
llamafactory-cli version如下图所示,没有出现警告,说明安装成功。

四、下载 HuggingFace 模型
记得先新建一条路径用来存储待会下载的模型,可以参考下面的代码

1. 设置下载目录与镜像(可选)
如下指令只会在当前会话生效,若需要长期生效可以写入配置文件。
你的文件路径大概率和我的不同,请将下面的路径配置为你自己准备下载模型的路径。
bash
export HF_HOME=/your/data/path/Hugging-Face # 请替换为你的实际路径
export HF_ENDPOINT=https://hf-mirror.com # 镜像加速
# 下面两条指令用于验证上面的临时环境变量是否配置成功
echo $HF_ENDPOINT
echo $HF_HOME2. 安装 huggingface_hub
使用官方的下载器来下载
bash
pip install -U huggingface_hub3. 下载目标模型
bash
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-7B模型会被保存至 $HF_HOME/hub/ 下的 snapshot 目录。
上述指令中使用的模型名字可以通过Huggingface官网直接找到你想要的模型后复制完整的名字
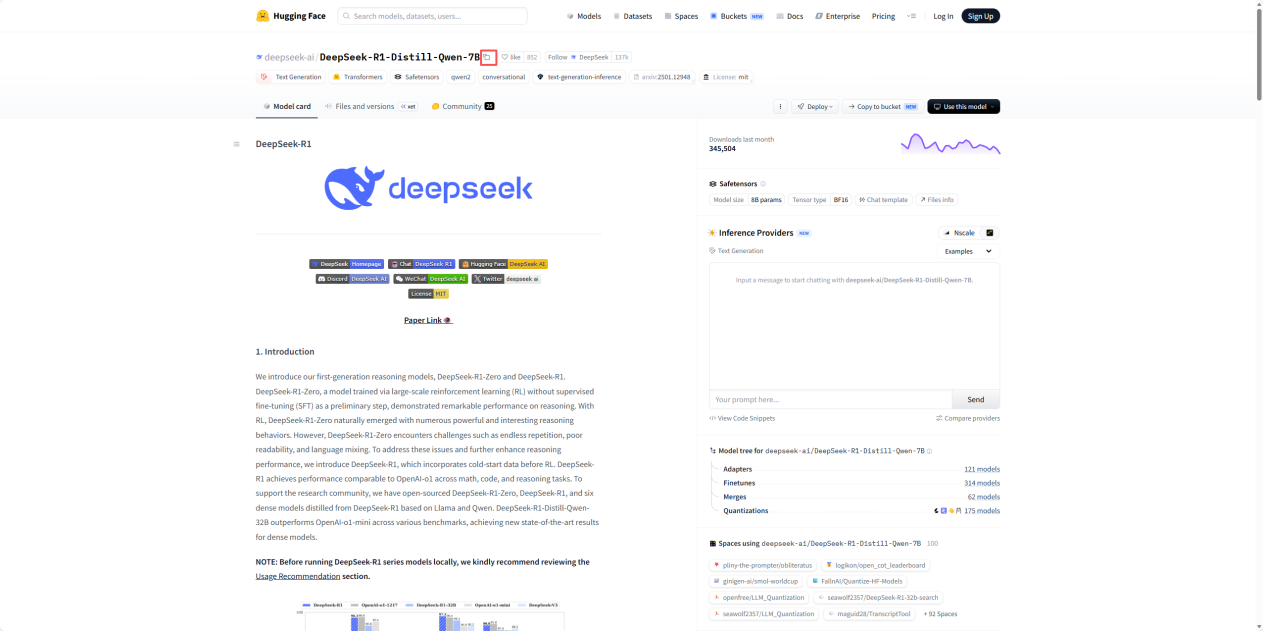
五、运行llama-factory验证模型是否可用
1.启动webui
powershell
llamafactory-cli webui2.选择模型名称
先选择模型名称为DeepSeek-R1-Distill-Qwen-7B
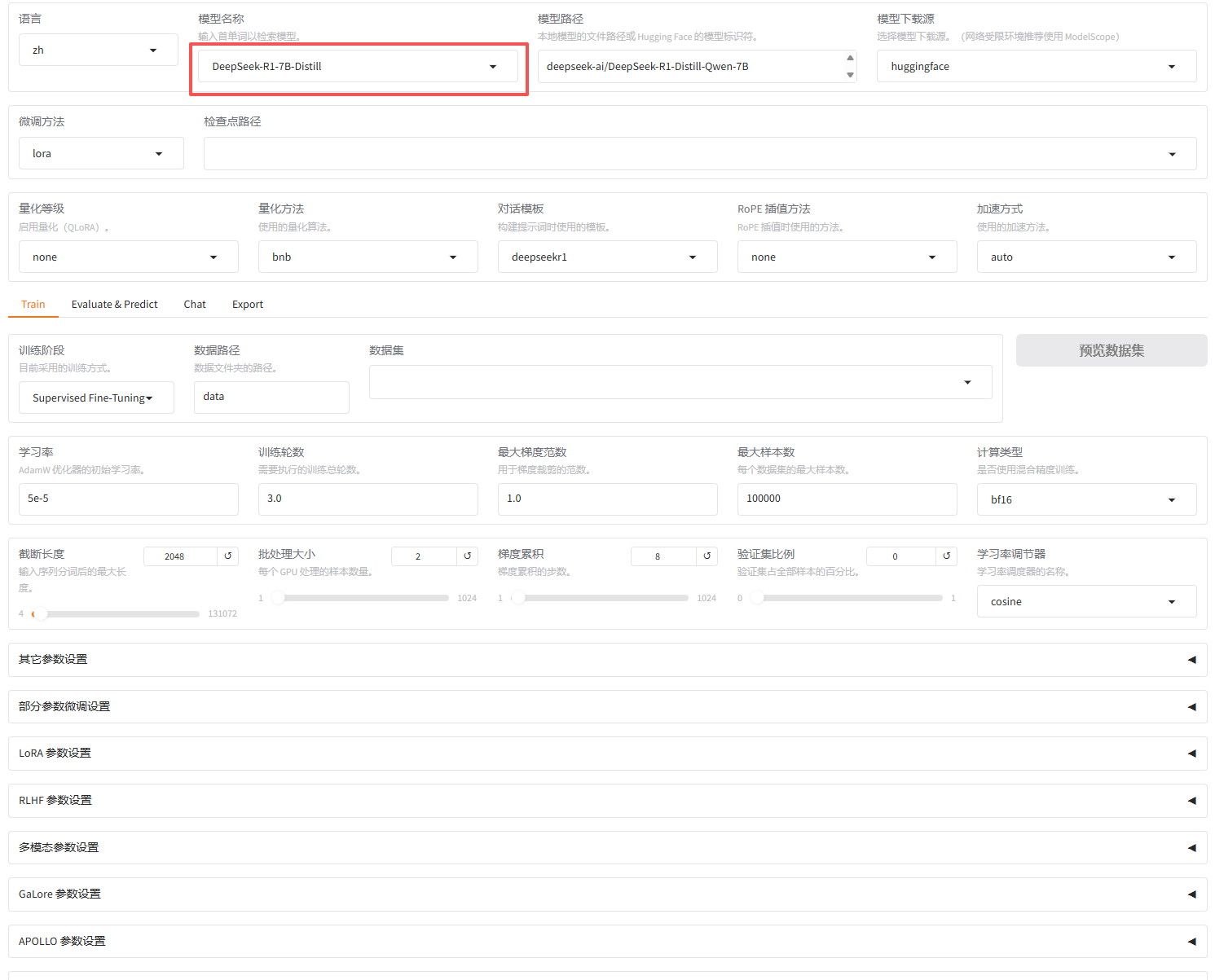
3.替换模型路径
找到下载的模型文件快照目录下对应的唯一哈希值命名的文件夹,复制该路径
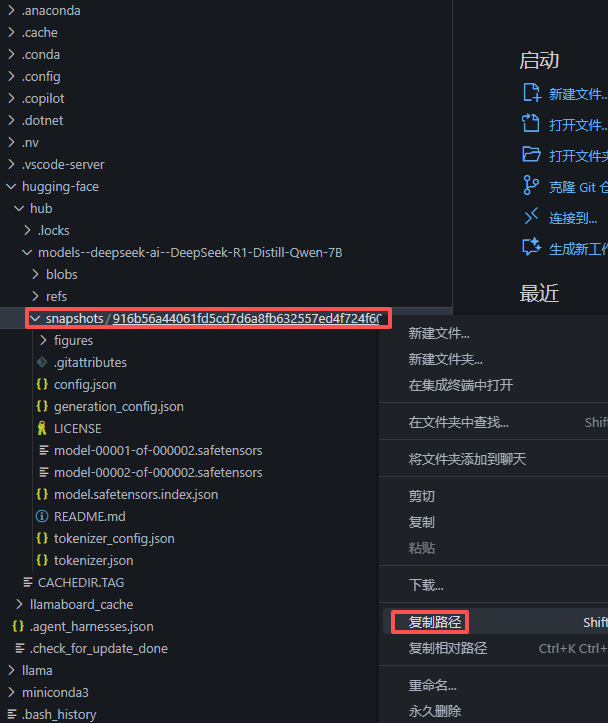
4.设置模型路径并加载
设置模型路径后在chat页面下选择加载模型,等待加载完成
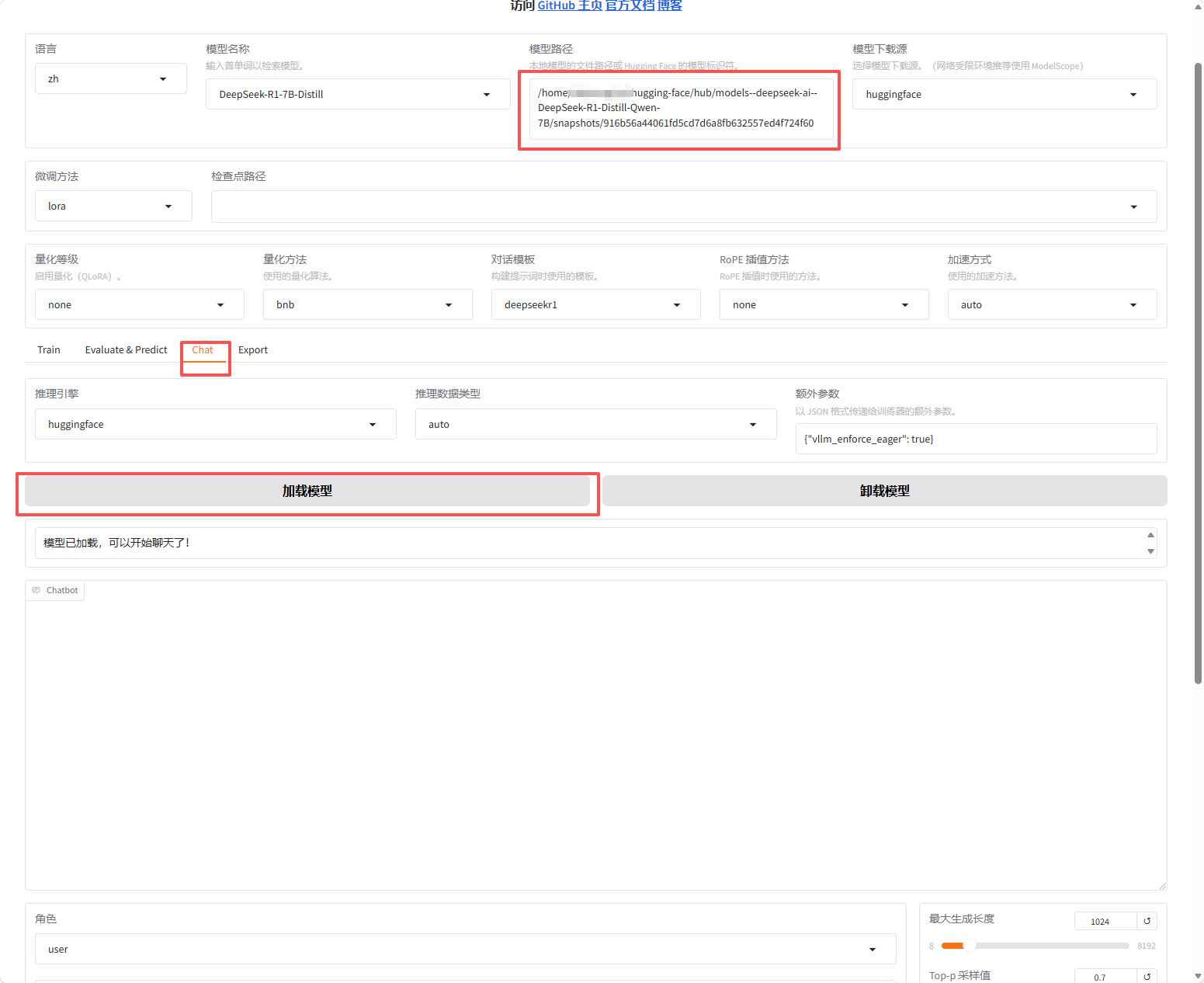
5.尝试进行模型对话
发现对话中参入了很多乱码
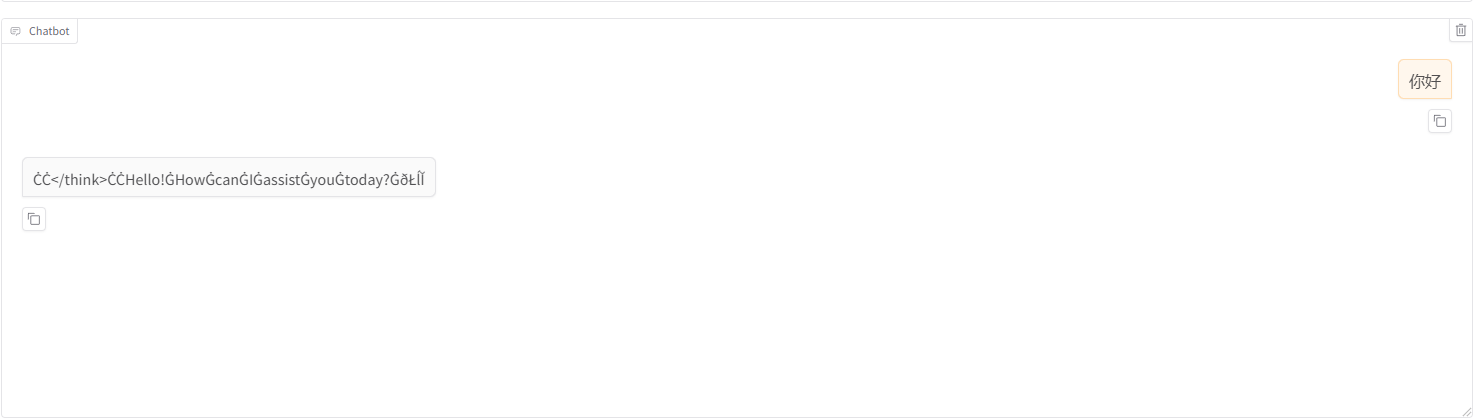
六、问题:模型输出乱码
现象描述
在 LLaMA-Factory WebUI 中加载 DeepSeek-R1-Distill-Qwen-7B(或 1.5B)后,对话输出出现大量不可读字符,例如:
Hello! How can I assist you today? ðŁĺĬ或出现 C\Git、大量 G 和 Ġ 等符号。
初步尝试
- 更换模型版本(7B → 1.5B)------ 无效
- 更换 Python 版本(3.13 → 3.11)------ 无效
- 重装 PyTorch 不同 CUDA 版本 ------ 无效
- 手动清理
Ġ和Ċ占位符 ------ 残留其他乱码(如 EMJ)
根本原因
AutoTokenizer 默认加载了 LlamaTokenizer 而非该模型所需的 Qwen2Tokenizer 。
原因是模型目录下的 tokenizer_config.json 中 "tokenizer_class" 缺失或错误,导致 Transformers 库回退到错误的分词器,造成 token ID 与词表不匹配。
七、最终解决方案:强制指定 Qwen2Tokenizer
1. 编写 Python 脚本测试
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, Qwen2Tokenizer
MODEL_PATH = "/home/xiezhongjun/hugging-face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a44061fd5cd7d6a8fb632557ed4f724f60"
print("正在加载模型...")
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
dtype=torch.bfloat16,
device_map="auto"
)
# 关键修复:强制使用 Qwen2Tokenizer,并添加 trust_remote_code=True
tokenizer = Qwen2Tokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
use_fast=True # Qwen2 必须用 fast 版本
)
# 验证是否修复成功(打印词表大小,Qwen2-7B 应为 151643 左右)
print(f"词表大小验证: {len(tokenizer)}") # 如果输出是 32000 或 50000,说明加载依然错误
print("模型加载完成。输入 'quit' 退出。")
while True:
user_input = input("\n你: ")
if user_input.lower() == 'quit':
break
messages = [{"role": "user", "content": user_input}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.6,
top_p=0.95,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
# 获取新生成的 token ids(去掉输入部分)
output_ids = outputs[0][inputs.input_ids.shape[1]:]
# 使用标准解码
response = tokenizer.decode(
output_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True # 这一句是关键,让分词器自行处理空格
)
# 手动修复字节级占位符(将 Ġ 替换为空格,Ċ 替换为换行)
#response = response.replace('Ġ', ' ').replace('Ċ', '\n')
# 移除思维链
if '</think>' in response:
response = response.split('</think>')[-1]
# 可选:压缩多余空白
#response = '\n'.join(line.strip() for line in response.splitlines() if line.strip())
print(f"模型: {response}")运行该脚本,输出正常,无乱码。

2. 在 LLaMA-Factory WebUI 中应用
WebUI 无法直接修改代码,需通过修正模型配置文件来让 AutoTokenizer 自动选中正确类。
操作步骤:
-
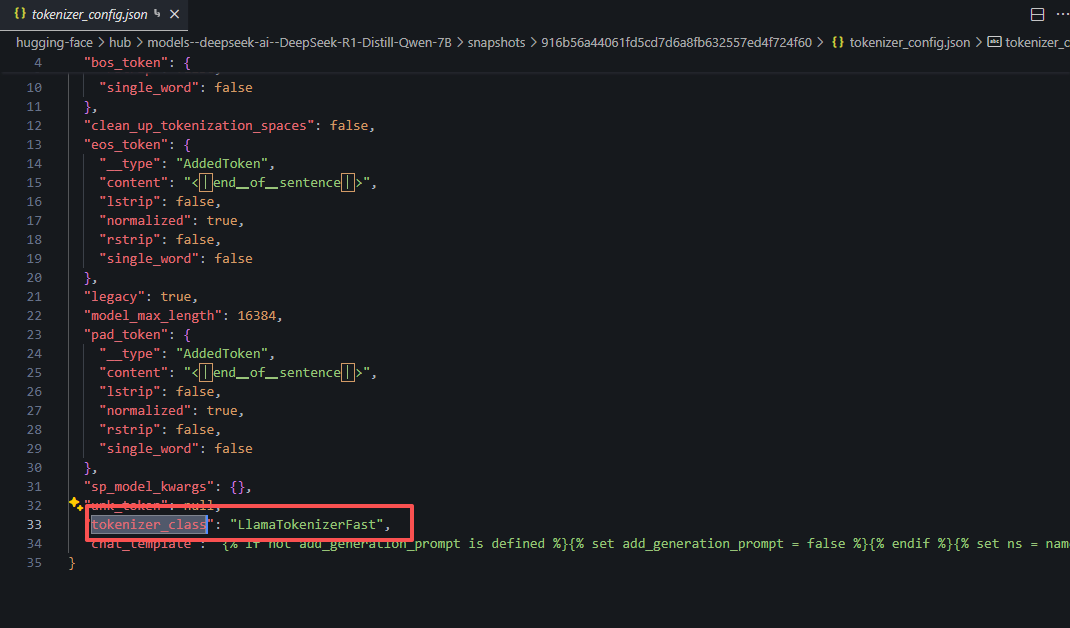
进入模型 snapshot 目录:
bashcd /your/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a... -
查看
tokenizer_config.json的tokenizer_class字段,将其修改为Qwen2Tokenizer
-
重启 LLaMA-Factory WebUI,重新加载模型即可正常对话。
powershell
llamafactory-cli webui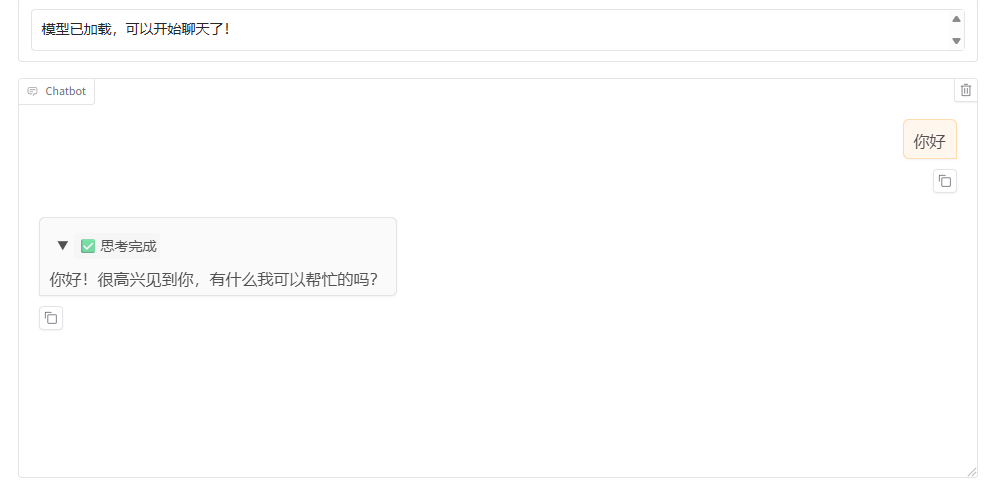
八、验证与对比
| 模型 | 分词器加载 | 输出结果 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B/1.5B(默认) | LlamaTokenizer(错误) | 乱码(含 Ġ, Ċ, 特殊字符) |
| DeepSeek-R1-Distill-Qwen-7B/1.5B(强制 Qwen2Tokenizer) | Qwen2Tokenizer(正确) | 正常中文/英文 |
| Qwen/Qwen2.5-1.5B-Instruct | AutoTokenizer 自动正确 | 正常(无需修改) |
结论:该模型本质是基于 Qwen 架构,分词器必须使用
Qwen2Tokenizer。
九、经验总结
- 分词器不匹配是导致解码乱码的常见原因,尤其是基于 Qwen 的衍生模型。
- 当
AutoTokenizer加载错误时,应检查tokenizer_config.json中的tokenizer_class字段。 - 若 WebUI 无法手动指定分词器类,可直接修正配置文件或使用脚本方式调用。
- 安装 LLaMA-Factory 时注意 CUDA 与 PyTorch 版本兼容性,推荐使用 conda 隔离环境。
十、参考资料
- LLaMA-Factory GitHub
- HuggingFace 模型下载
- PyTorch 官网
- Bilibili堂吉诃德拉曼查的英豪 -- -- LoRA 算法论文解读 & 开发人员如何微调大模型并暴露可调用接口
最终测试:在修复后的环境下,DeepSeek-R1-Distill-Qwen-7B/1.5B 以及Qwen/Qwen2.5-1.5B-Instruct均可正常进行中文对话,输出流畅、无乱码。问题圆满解决。