《A Deep Reinforcement Learning Approach Using Asymmetric Self-Play for Robust Multirobot Flocking》2025年发表在IEEE Transactions on Industrial Informatics
一、文章背景
多机器人集群控制(简单说就是让一群机器人协同移动)在物流、搜救这些实际场景里很有用,核心是让机器人凑在一起不碰撞,还能顺利到达目标地。但现实环境没那么简单,不仅有固定障碍物,还有会主动干扰的 "敌对机器人"(比如故意撞过来破坏队形),而且机器人之间还不能通信,只能靠自己看到的局部信息做决策。
现有方法存在明显局限:传统集群控制方法(如人工势场法、模型预测控制)依赖对环境和智能体的精确、全面建模,导致实际应用成本高,在复杂动态场景中可行性受限,无法应对未预定义的对抗性干扰;近年来兴起的深度强化学习(DRL)方法虽凭借强特征提取和决策能力成为替代方案,但现有 DRL-based 集群框架大多仅能处理静态障碍物或行为固定、路径简单的动态障碍物,缺乏对环境不确定性的鲁棒性,且难以扩展到任意数量的机器人集群,未充分考虑对抗性环境中 "智能体 - 干扰体" 的动态交互,策略泛化能力不足。
为了解决传统方法的不足 文章提出来了基于不对称自玩 的 DRL 框架,核心思路就是让机器人在对抗中练本事:
用不对称自玩:让集群机器人和可学习的敌对干扰体一起训练,干扰体越练越聪明,机器人也能跟着提升应对复杂干扰的能力,比单纯面对固定规则的干扰更有效。
分两阶段训练:第一阶段让两者同步练,积累不同水平的干扰策略;第二阶段让机器人对着这些积累的干扰策略再练,提升泛化能力,避免只会应对一种干扰。
加辅助训练模块:让机器人学会预测下一步的环境变化,减少对未知环境的迷茫,提升适应力。
用注意力机制:不管机器人数量多少,都能快速聚焦关键信息(比如哪个队友近、哪个干扰体威胁大),解决了机器人数量变化带来的适配问题。
二、核心方案
文章的核心技术方案是ASFC(Asymmetric Self-play-empowered Flocking Control)框架,基于深度强化学习(DRL),融合不对称自玩、注意力机制和辅助训练模块,针对性解决动态对抗环境下的多机器人集群控制问题。
ASFC 遵循 "集中式训练、分布式执行" 范式,核心目标是让无通信能力的机器人仅通过局部观测,在静态障碍物 + 动态对抗干扰体的环境中,实现 "避碰、队形保持、高效抵达目标" 三大任务。技术方案围绕 "提升鲁棒性、泛化性、扩展性" 展开,分为五大核心模块。
1)两阶段不对称自玩训练
通过 "机器人与可学习干扰体的对抗训练" 提升策略智能,分两阶段实现鲁棒性与泛化性的双重优化:
设计目的:让机器人在 "不断升级的对抗压力" 中学习,避免仅适应单一干扰模式,同时积累多样化干扰策略以提升泛化能力。
阶段 1:同步训练(干扰体智能提升)
机器人集群与干扰体集群同步训练,两者目标对立:机器人需保持队形避碰,干扰体主动撞击机器人以破坏集群。
每间隔个训练回合,将当前干扰体的网络参数(策略)保存到 "干扰体模型池 W",积累不同智能水平的干扰策略。
训练环境:15m×15m 场景,5 个机器人 + 5 个干扰体 + 2 个静态障碍物,机器人初始化于边缘区域,目标为场景中心对称点。
阶段 2:对抗模型池(泛化能力强化)
机器人不再与实时训练的干扰体对抗,而是从模型池 W 中采样干扰体策略组成 "对抗团队" 进行训练。
采样机制:① 智能体级采样: 个干扰体可组合
种干扰团队
为模型池数量,提升环境多样性;② 加权采样:根据干扰体模型的历史累积奖励调整采样概率,优先选择更强的干扰策略,实现 "课程学习"(从易到难)。
训练环境:扩展为 25m×25m 场景,8 个机器人 + 6 个干扰体 + 5 个静态障碍物,进一步提升任务复杂度。
核心优势:相比单一阶段训练,机器人能适应 "不同强度、不同模式" 的动态干扰,泛化能力显著提升。
2) 动作与价值学习(网络核心架构)
采用双注意力机制解决 "机器人数量扩展性" 和 "局部 - 全局信息融合" 问题,分为动作生成(演员网络)和价值评估(评论家网络)两部分:
设计目的:让框架适配任意数量的机器人集群,同时让机器人在无通信条件下,间接利用全局信息优化决策。
(1)动作学习(特征级注意力)
输入:机器人的局部观测(自身状态、目标相对位置
、三通道局部网格图
、周边机器人 / 干扰体状态
)。
具体流程:
特征嵌入:通过卷积神经网络(CNN)处理局部网格图 ,多层感知机(MLP)处理向量型输入,拼接得到 "自身特征"。
特征级注意力聚合:以 为查询(Query),对周边机器人特征
和干扰体特征
计算注意力权重,聚合关键信息:
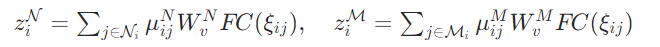
其中 是归一化注意力权重(通过 Softmax 计算),用于聚焦 "威胁最大的干扰体" 或 "距离最近的队友"。
动作生成:将 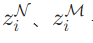 与
与 拼接为特征
,输入两层 MLP 组成的演员网络,通过 Softmax 采样离散动作(线性 + 角速度组合)。
干扰体动作学习:网络架构与机器人一致,但观测范围为全局(可获取所有机器人 / 干扰体状态),动作空间略调整(线性速度上限 0.38m/s,机器人为 0.5m/s)。
(2)价值学习(智能体级注意力)
设计目的:在执行阶段无通信,但训练阶段让机器人聚合全局信息,提升价值评估的准确性。
具体流程:
局部总特征:机器人 i 的局部特征 与集群特征
(自身与集群中心的相对距离 / 角度)拼接为
。
全局信息聚合:通过智能体级注意力计算其他机器人 j 的特征重要性,聚合全局信息:
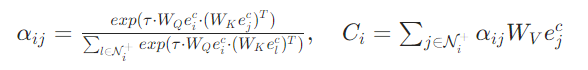
价值生成:将 与
拼接,输入两层 MLP 组成的评论家网络,输出状态价值
。
优化算法:采用 PPO(Proximal Policy Optimization)算法,分别优化演员网络和评论家网络(学习率)。
3)辅助训练模块(环境动态学习)
设计目的:让机器人学习环境状态转移规律,减少对未知环境的不确定性,提升适应能力。
核心功能:基于当前局部特征和执行动作
,预测下一时刻的局部网格图
。
实现方式:
解码器结构:由 MLP + 多层反卷积层组成,输入为 和
,输出为预测的三通道网格图(尺寸与输入一致)。
监督信号:由模拟器提供真实的下一时刻网格图,采用交叉熵损失
优化预测精度:
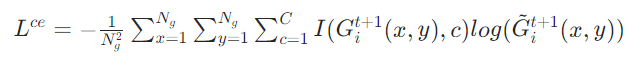
总损失融合:将辅助损失与 PPO 的策略损失、价值损失
、熵损失
加权融合,联合优化:
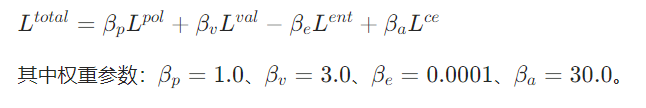
4)奖励函数设计(任务导向优化)
通过差异化奖励引导机器人与干扰体的行为,确保任务目标达成:
(1)机器人奖励函数
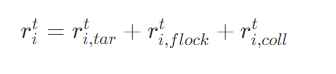
目标抵达奖励:鼓励机器人向目标移动,抵达目标区域(距离 )获得固定奖励
;未抵达时,根据距离变化给予增量奖励
。
队形保持奖励:仅当机器人与集群中心距离 < 且航向偏差 <
时,给予组合奖励(中心保持奖励+ 航向一致奖励)。
避碰惩罚:碰撞时给予强惩罚;与干扰体距离 <
或与障碍物距离 <
时,按距离平方的倒数给予梯度惩罚。
(2)干扰体奖励函数

核心逻辑:鼓励干扰体主动接近并碰撞机器人,同时避免自身碰撞无关物体。
5)观察与动作空间设计(基础环境交互)
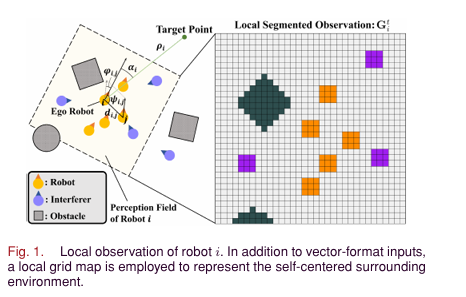
(1)观察空间
机器人观察(局部范围):自身状态(线性 / 角速度)、目标相对位置(距离 / 角度)、三通道局部网格图(近 3 个时刻,分别标记自由空间 / 静态障碍物 / 机器人 / 干扰体)、周边机器人 / 干扰体的相对状态(距离 / 角度 / 航向差)。
干扰体观察(全局范围):自身状态、全局网格图、所有机器人 / 干扰体的全局状态,观测维度高于机器人。
(2)动作空间
离散化设计:动作由 "线性速度 + 角速度" 组合而成,共 36 种可选动作。
机器人:线性速度 {0, 0.15, 0.3, 0.5} m/s,角速度 {-2, -1.2, -0.8, -0.3, 0, 0.3, 0.8, 1.2, 2} rad/s。
干扰体:线性速度 {0, 0.15, 0.3, 0.38} m/s,角速度与机器人一致。
三、实验结果
以下为论文中的实验图表
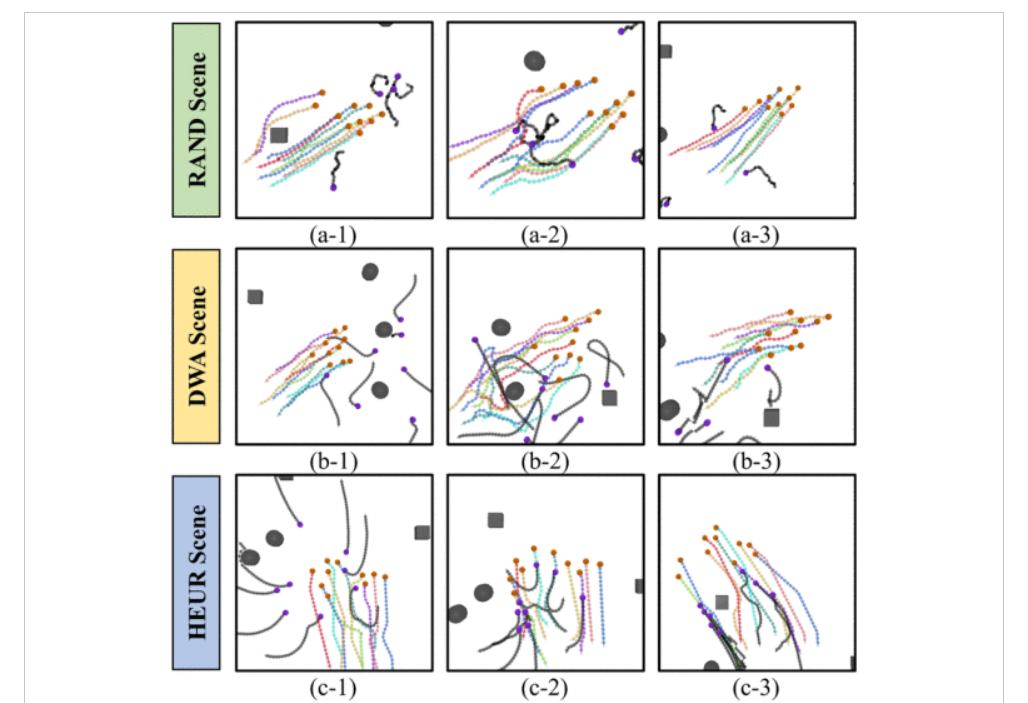
实验结果中的ASFC的采样行为还证明了机器人能够在保持预期群聚行为的同时,避开各种干扰体的影响。
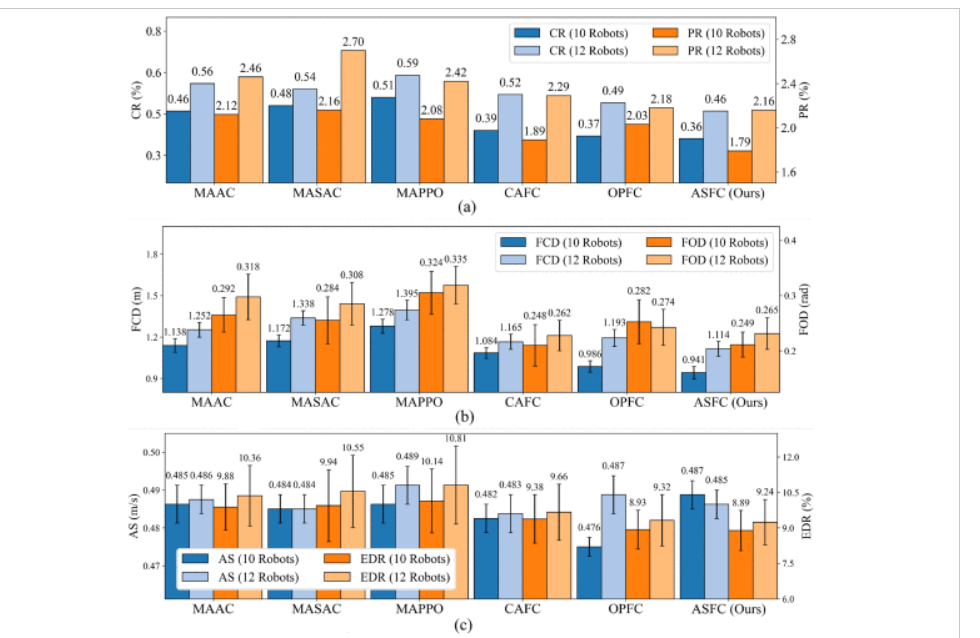
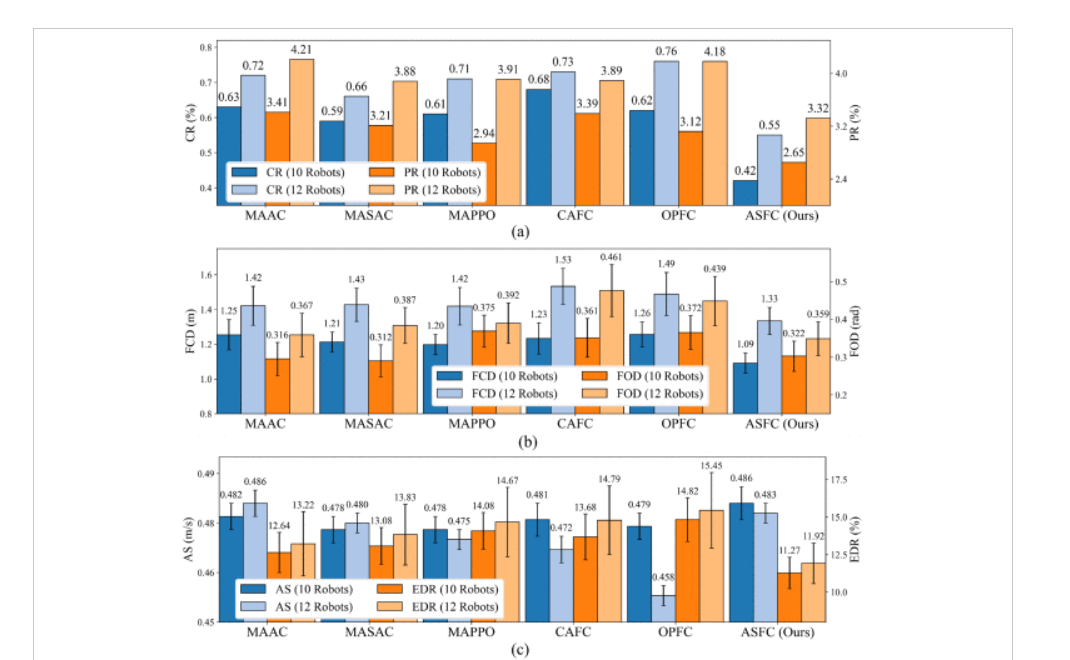
这是ASFC和基线方法在三种不同场景中的表现 体现了ASFC更优越的泛化能力
四、总结
论文主要提出两阶段不对称自玩范式提升鲁棒性,设计双注意力机制保障扩展性,通过辅助模块降低环境不确定性,且经仿真与物理实验验证了框架的优越性。
论文采用方法达到了以下效果:
避碰能力强:能躲开固定障碍物和主动干扰的敌对机器人;
队形稳:能保持集群中心、和队友方向一致;
效率高:少走弯路,快速到达目标地;
适配性好:不管机器人数量怎么变都能用;
泛化性强:面对不同类型的干扰(随机动、有策略动等)都能应对,还能在真实机器人上落地使用,不是只停留在模拟里。