Data Dependency
evils of redundancy 冗余的弊端
冗余是关系模式诸多问题的根源:
存储冗余
更新异常:插入异常、删除异常
事务吞吐量低(low transaction throughput):冗余度越高,若要保证事务无异常,需锁定更多对象,导致冲突加剧、吞吐量下降
因此 可以通过通过模式分解消除异常
属性间存在的依赖关系,主要包括:
a.函数依赖(FD):最基础的数据依赖,指一个或一组属性的值可唯一确定其他属性的值,是数据库设计中最重要的依赖类型。
b.多值依赖(MVD):某一属性的值可确定另一组属性的多个值。
c.连接依赖(JD):无损连接分解的约束条件。
Function dependency (FD) 函数依赖
设 A、B 为关系 R 的属性集,若对关系 R 中任意两个元组 t₁和 t₂,当 t₁A = t₂A 时,必有 t₁B = t₂B,则称 "A 函数确定 B",记为 A→B,A→B 即为函数依赖。
超键:A set of attributes that determines the entire tuple is a superkey.(如 {学号,姓名}、{学号,姓名,年龄} 均为学生表的超键)
候选键:. A minimal set of attributes that determines the entire type is a candidate key.能确定整条元组的最小属性集
主键:多个候选键中选定的一个。
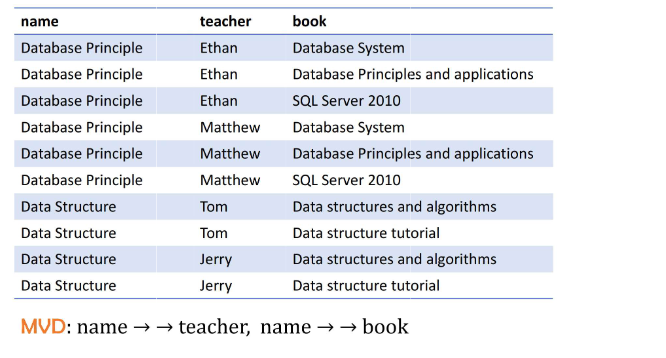
MULTI-VALUE DEPENDENCE 多值依赖
设关系模式 R (U),U 为属性集,X、Y、Z 为 U 的子集,且 Z=U-X-Y。关系模式 R (U) 中多值依赖 X→→Y 成立的充要条件为:
1.R 中每个元组在 X、Y 上均有一组值 (x,y);
2.给定 X 的一个值 x,Y 的一组值仅由 x 决定,与 Z 的值无关。
核心:X 值相同的元组,其 Y 值可互换。
JOIN DEPENDENCY 连接依赖

若通过自然连接 SP、SJ、PJ 可重构原关系 SPJ,则该分解为无损连接分解;否则为有损连接分解
连接依赖定义
设 X₁、X₂、...、Xₙ为关系 R 属性集 U 的子集,且∪ⁿᵢ₌₁Xᵢ=U;R X₁、R X₂、...、R Xₙ 为 R 在 X₁、X₂、...、Xₙ上的投影。若对 R 中每个元组 r,均满足 r = r X₁⋈r X₂⋈...⋈r Xₙ,则称 R 存在连接依赖,记为⋈(X₁,X₂,...,Xₙ)。
如何获得优良设计?
DB gurus have also discussed trade-offs among normal forms.
范式与依赖的对应关系
基于函数依赖(FD):1NF、2NF、3NF、BCNF
基于多值依赖(MVD):4NF
基于连接依赖(JD):5NF
1NF
属性类型必须原子化(不可再分)
Types must be atomic
2NF
关系 R 满足 1NF;
每个非主属性完全函数依赖于 R 的某个候选键(不允许部分函数依赖)。
例子:关系 SC(学号,姓名,年龄,地址,课程号,成绩)
完全函数依赖:(学号,课程号)→成绩(成绩需由学号和课程号共同确定);
部分函数依赖:姓名、年龄、地址仅由学号即可确定,无需课程。
结论:关系 SC 违反 2NF。
非2NF的问题:
插入异常:无法插入未选课学生的信息;
删除异常:学生退选所有课程时,其基本信息会丢失;
更新困难:冗余导致更新时难以保持元组间的一致性。
3NF
关系 R 满足 2NF;
每个非主属性不传递函数依赖于 R 的某个候选键。
传递依赖例子:
员工表 EMP(员工编号,薪资等级,薪资):员工编号→薪资等级,薪资等级→薪资;
学生表 STU(学号,院系名称,院系主任):学号→院系名称,院系名称→院系主任。
非3NF问题
插入异常:未确定员工薪资等级前,无法录入薪资等级与薪资的对应关系;
删除异常:若某薪资等级仅对应一名员工,删除该员工会丢失该薪资等级与薪资的对应关系;
更新困难:冗余导致更新时难以保持一致性。
BCNF
BCNF 在 3NF 基础上,消除了主属性对候选键的部分函数依赖和传递函数依赖,要求:
1.所有非主属性完全函数依赖于每个候选键(满足 2NF);
2.所有主属性完全函数依赖于不包含该主属性的每个候选键;
3.主属性间不存在传递函数依赖;
4.无属性完全函数依赖于非主属性。
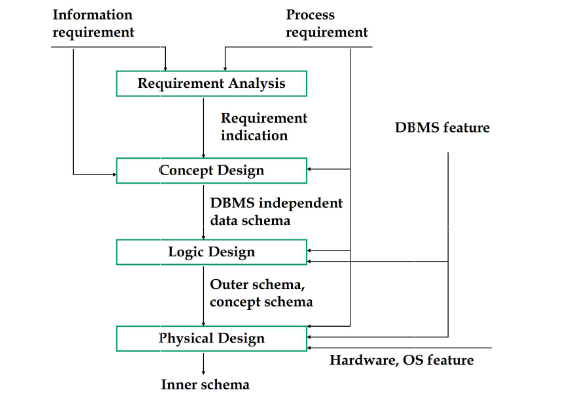
数据库设计方法
面向过程方法Procedure oriented method
核心:以业务流程为中心,直接依据业务中的凭证、单据、报表等设计数据库模式;
特点:项目初期速度快,但未深入分析数据及数据间内在关系,难以保证软件质量,适配未来需求和环境变化的能力弱;
适用场景:不适用于大型复杂系统开发。
面向数据方法Data oriented method
核心:以数据为中心,深入分析业务流程涉及的数据及数据间关系,设计数据库模式;
特点:既能满足当前需求,也能适配潜在需求,易于应对未来需求和环境变化;
适用场景:推荐用于大型复杂系统开发
流程