作者:岳元浩(顾城)、汪诚愚(熊兮)、黄俊(临在)
背景
近年来,多模态人工智能技术迅猛发展,推动了视觉、语言、语音等多种模态信息的深度融合与理解。尤其在多模态深度推理任务中, GPT-4V 等前沿模型通过模拟人类的链式思维过程,展现出强大的跨模态推理能力。然而,当前的多模态大模型在实际应用中仍面临两个关键问题:首先,能力较强的SOTA模型往往参数规模庞大、计算资源消耗高,导致部署成本高昂,难以在资源受限的场景中落地。其次,现有开源社区缺乏大规模高质量的多模态长思考数据集,致使多模态推理模型的训练过程难以复现,也制约了开源社区多模态推理模型的性能提升。
基于阿里云人工智能平台(PAI)的蒸馏工具包 EasyDistill(github.com/modelscope/... OmniThoughtV。OmniThoughtV不仅填补了开源社区在多模态复杂推理数据方面的空白,还通过一套透明、可复现的数据蒸馏机制,实现了对多模态思维链的高效提取与结构化组织。该数据集融合了精细化标注、多阶段过滤机制与针对多模态推理优化的蒸馏策略,显著提升了小模型在保持逻辑连贯性的同时,降低推理冗余、加快响应速度,并增强了在开放场景中的鲁棒性与泛化能力。特别地,基于蒸馏的OmniThoughtV数据集得到的Qwen3-VL-4B小模型在下游任务上接近或超越了参数量为其两倍的基座模型(Qwen3-VL-8B),实现了参数量50%的压缩效果,其结果如下:
模型/评测数据集
4B模型(蒸馏前)
4B模型(蒸馏后)
8B模型(蒸馏前)
AI2D
0.7134
0.8164
0.8096
MMMU ProStandard
0.4133
0.4694
0.4688
MMMUval
0.5667
0.6033
0.6000
MathVista
0.7070
0.7400
0.7250
MathVersetestmini
0.3640
0.5315
0.3820
MMBench
0.8204
0.8273
0.8256
本文将重点解析基于 EasyDistill 框架构建 OmniThoughtV 数据集的核心方法,评测其在多模态深度推理任务中的实际效果,并介绍该数据集及配套蒸馏模型在开源社区和 PAI 平台上的使用方式和各个场景的应用,为推动开源多模态大模型迈向人类水平的系统性思考能力提供坚实基础。
OmniThoughtV数据集构建
开源社区现有的多模态指令微调数据集往往只包含简单直接的回答,缺乏复杂的推理过程,难以支持模型学习如何"看图深度思考"。例如,在回答"免费试用用户的总数是多少?"这类问题时,模型不仅需要定位图表中的关键视觉元素,还需理解其语义、排除干扰信息,并逐步推导出结论。然而,现有数据集通常仅提供最终答案,缺失中间可解释的推理链。为弥补这一空白,我们构建了 OmniThoughtV, 首个大规模、面向多模态深度推理的高质量长思考数据集。我们的模型思考不仅涵盖数学、逻辑等推理,还包括对图像中物体、空间等信息的理解与推理。
多模态数据集示例
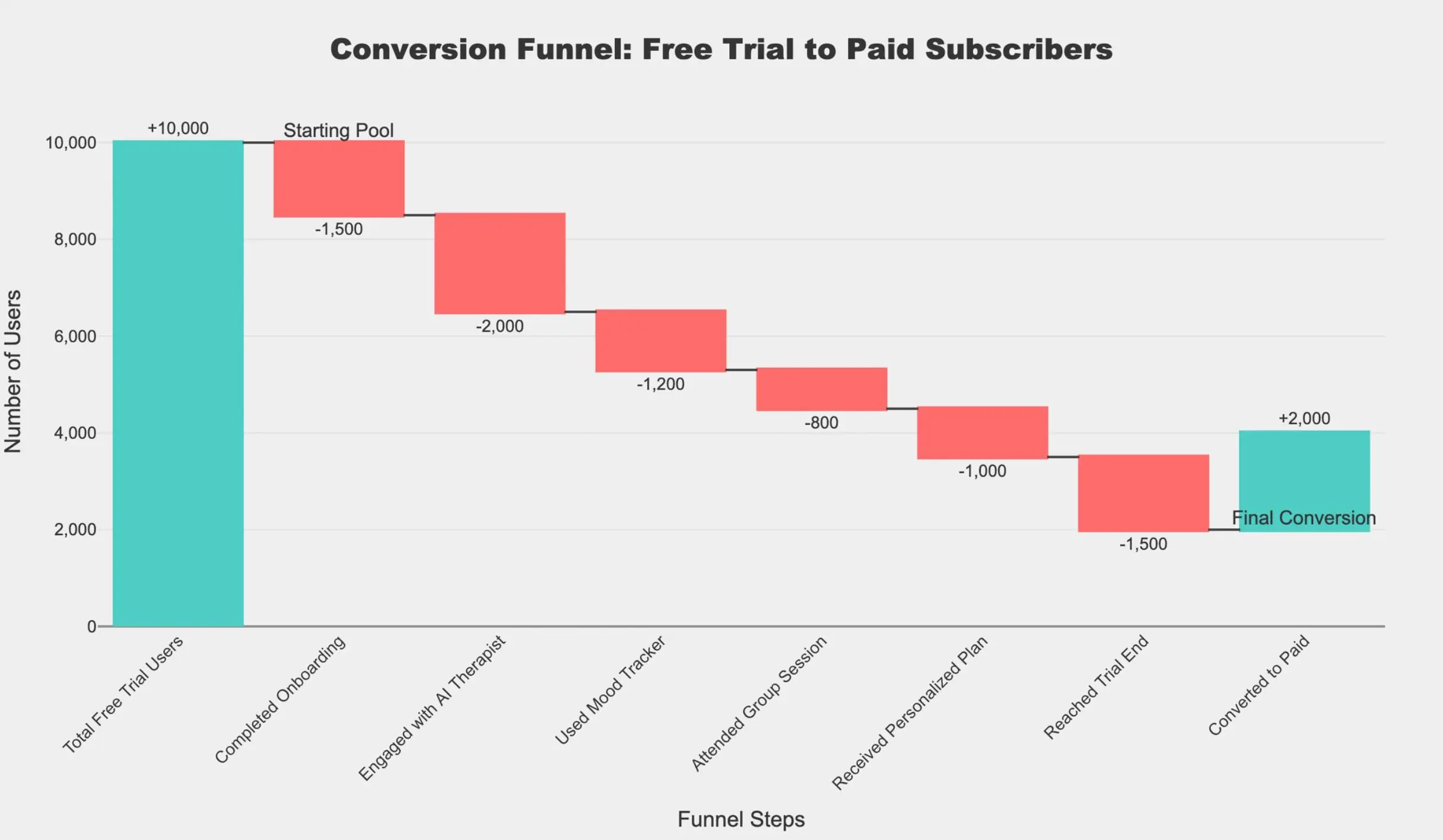
问题:免费试用用户的总数是多少?
原回答标注
免费试用用户的总数在图表开头的"Total Free Trial Users"(总免费试用用户数)下方标明。
答案:10,000
长思考标注
为了确定免费试用用户的总数,我需要查看漏斗图中标有"Total Free Trial Users"(总免费试用用户数)的第一个柱状条。该柱状条代表了开始免费试用的初始用户群体。
从图表中可以看出:
-
第一个柱状条的高度对应 10,000 名用户。
-
该柱状条上的标签明确标示为"+10,000",表明这是免费试用用户的起始人数。
无需进一步计算,因为图表已直接提供了免费试用用户的总数。
因此,免费试用用户的总数为 10,000。
10,000
我们从 HuggingFace 的 FineVision 数据集中抽取了 180 万条英文图文指令,全面覆盖其全部子数据集与数据来源,从而构建了一个多样化、高覆盖度的初始多模态问题池。在此基础上,我们利用当前性能领先的多模态大模型 Qwen3-VL-Max,为每一条样本生成结构化、可解释、多步骤的长思考推理过程,涵盖视觉信息定位、跨模态语义对齐、逻辑推导与答案验证等关键认知环节。其中,我们使用如下Prompt模版从 Qwen3-VL-Max蒸馏得到上述长思考推理过程:
ini
SYSTEM_PROMPT="You are a helpful assistant to think step by step. Provide your reasoning steps within <think></think> tags and give your final answer within <answer></answer> tags."
QUERY=f"""
<image>
### Question
{question}
### Output Format (Strictly Enforced)
<think>
Clearly explain your reasoning step by step. Describe how you arrived at the conclusion.
The reasoning process MUST BE enclosed within <think> </think> tags.
</think>
<answer>
Your final answer to the user's question.
</answer>
"""最终,我们构建了一个包含约 0.8B Tokens 的高质量多模态长思考蒸馏数据集,为训练具备深度推理能力的小型多模态模型奠定了坚实的数据基础。该数据集不仅规模庞大,更在推理深度、逻辑连贯性与任务多样性等方面显著超越现有开源多模态指令微调数据集。
OmniThoughtV思维链评估指标
在完成对 180 万条英文图文指令的蒸馏标注后,我们对生成的长思考数据进行了系统性质量清洗,以确保数据的难度和标注准确性。数据清洗与过滤主要基于两个维度:规则过滤和模型打分。 在规则层面,我们设计了三类启发式规则:除了剔除不符合...<\think>...<\answer>思考链格式的数据外,我们还过滤掉模型回答长度过长的数据,通常这类数据对应极为复杂的问题,模型在思考过程中难以找到有效答案。此外,我们还剔除了回答中出现模型自我反复纠错的样本,例如包含"Wait, ....."等自我纠错模板的数据,这类数据通常也是极难问题,模型无法做出准确推理。 在模型打分方面,我们使用 Qwen3-VL-Flash 对数据进行打分,分别标注了数据的质量、难度以及开放式任务标签,具体定义如下:
分数
级别
描述
难度评分
1
非常简单
明显存在的物体、简单的颜色/形状识别
2
简单
清晰可见物品的基本计数、简单的空间关系
3
中等
需要简短推理、识别常见动作或属性
4
困难
多步推理、细微的视觉线索、或不常见的概念
5
非常困难
抽象推理、复杂的场景理解、或模糊不清的上下文
质量评分
1
非常低
完全错误或无关的回答
2
低
大部分错误,仅含少量正确元素
3
中
部分正确,但遗漏关键细节或包含错误
4
高
基本正确,仅有轻微不准确或遗漏
5
非常高
完全准确、精确且完整的回答
此外,模型会为每个问题分配 3 到 6 个简洁、相关、开放式任务标签,描述问题的性质(例如:"counting"、"color"、"spatial"、"action"、"object"、"attribute"、"reasoning"、"scene"、"text"、"math" 等)。为了保证语义的清晰性,我们仅使用常见、通用的标签。
OmniThoughtV数据集的标注统计结果如下:
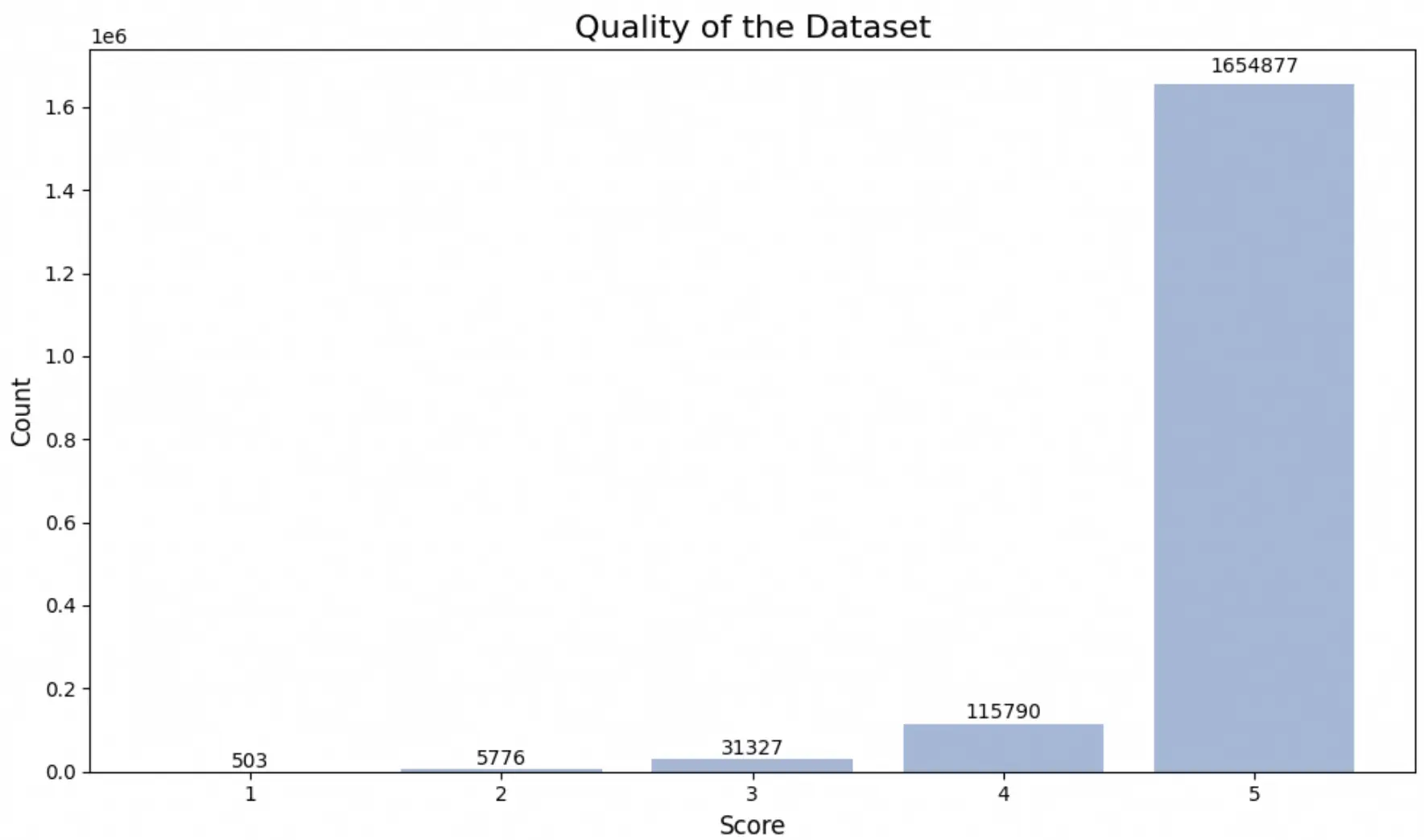
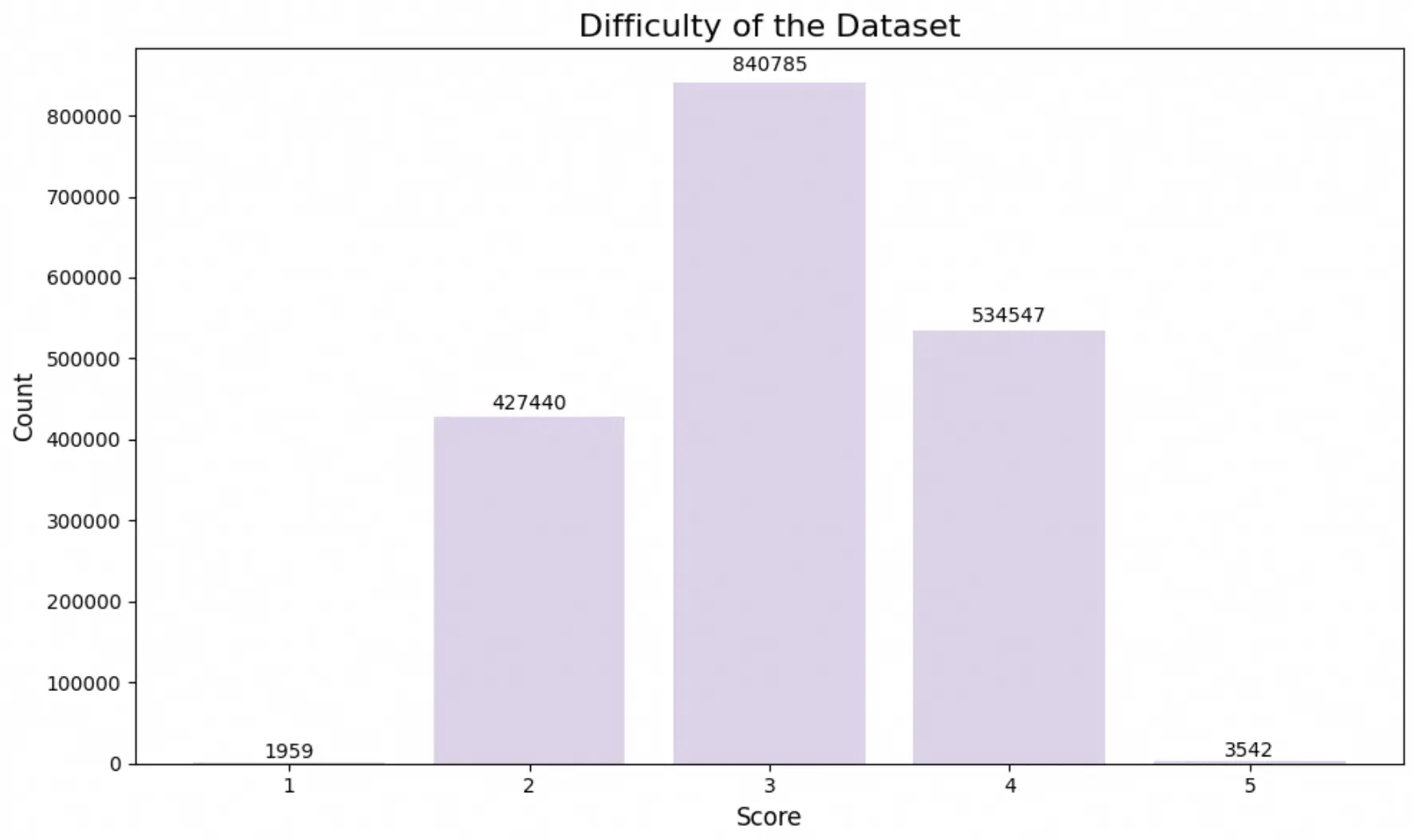
可以看出,绝大多数OmniThoughtV数据集中的思维链质量极高,在难度上明显呈现近似正态分布。我们进一步使用词云统计了任务标签:
从数据标签统计可以看出该数据集覆盖广泛的领域主题和任务类型,包括但不限于:
- 视觉理解 :如对象识别(
object)、属性解析(attribute)、场景理解(scene); - 空间推理 :如位置关系(
spatial、position、layout)、方向(direction)与坐标(coordinate); - 图表解读 :涵盖多种可视化形式(
chart、graph、table、bar chart、pie chart、scatter plot)及其元信息(axis、legend、label、caption); - 逻辑推理 :包括计数(
count)、比较(comparison)、数学计算(math、algebra、geometry)以及统计概念(percentage、ratio、average); - 领域知识 :涉及科学(
physics、chemistry、biology)、技术(code、algorithm、electronics)、人文(history、politics、literature)等多个领域; - 反思能力 :强调事实核查(
verification、fact-check)、误差识别(error、discrepancy)与细节敏感性(precision、detail)。
实验效果评测
为了系统性地寻找最优训练超参数,我们采用不同的超参数组合,对 Qwen2.5-VL-3B-Instruct 模型在视觉推理任务上的表现进行了训练与评测。首先,我们在 MMMU_pro_vision Benchmark 上开展了一系列微调超参数的实验。该基准能够全面、深入地衡量模型在复杂图像理解与多步逻辑推理方面的综合能力。在未进行任何微调的情况下,原始的 Qwen2.5-VL-3B-Instruct 模型在该基准上的得分仅为 0.2130。我们使用的Prompt模版如下图所示。
ini
SYSTEM_PROMPT="You are a helpful assistant to think step by step. Provide your reasoning steps within <thinking></thinking> tags and give your final answer within <answer></answer> tags. Final answer requirement: Answer with the option letter from the given choices directly."
QUERY_PROMPT=f"""
### Question
{question}
### Output Format (Strictly Enforced)
<thinking>
Clearly explain your reasoning step by step. Describe how you arrived at the conclusion.
The reasoning process MUST BE enclosed within <thinking> </thinking> tags.
</thinking>
<answer>
Your final answer to the user's question.
Answer with the option letter from the given choices directly.
</answer>
"""随后,我们围绕学习率和训练轮次(Epoch)这两个核心超参数,设计了多组对比实验,以探索它们对模型最终性能的影响。具体而言,我们测试了四种不同的学习率(5e-6、1e-5、2e-5、4e-5),并分别在 1 至 5 个训练轮次下观察模型得分的变化趋势。实验结果显示,不同超参数组合对模型性能有着显著影响:例如,当学习率为 5e-6,且训练 4 个 Epoch 时,模型取得了 0.3220 的最佳分数;而较高的学习率(如 4e-5)则普遍导致性能下降,表明过高的学习率可能不利于模型稳定收敛。最终,我们选用了 5e-6 的学习率,训练 4 个 Epoch 作为后续实验的微调训练参数。
学习率/Epoch
1 Epoch
2 Epochs
3 Epochs
4 Epochs
5 Epochs
5e-6
0.2815
0.2936
0.3116
0.3220
0.3087
1e-5
0.2931
0.3017
0.3093
0.3104
0.3098
2e-5
0.2722
0.2919
0.2977
0.2959
0.3000
4e-5
0.2566
0.2515
0.2671
0.2688
0.2798
为了深入探究数据筛选策略对模型微调效果的影响,我们系统性地测试了"质量"(Quality)与"难度"(Difficulty)指标的数据过滤条件,并在前述实验的最佳超参数设置下评估其训练性能。每组过滤条件对应的微调数据集均统一为 10 万条。实验结果表明,单纯依赖标注质量指标进行过滤(如仅保留 Quality ≥ 5 的数据)反而会导致模型性能轻微下降(得分 0.2948),甚至低于未经过过滤的原始数据集(得分 0.3093)。这说明高标注质量数据未必等同于高有效性,有时可能因过于简单或同质化而削弱模型的学习能力。 相反,当引入"难度"指标作为核心过滤条件时,模型表现显著提升:在仅要求 Difficulty ≥ 4 的条件下,模型得分跃升至 0.3156;而将高质量与高难度相结合(Quality ≥ 5 且 Difficulty ≥ 4)时,模型得分也达到了 0.3139,同样优于无过滤基线。由此验证了我们提出的"难度"与"标注质量"联合过滤的有效性。同时也得出结论,在当前任务场景下,以"难度"为核心的过滤机制比单纯依赖"标注质量"的过滤策略更为有效,因为它能更精准地筛选出既能挑战模型、又能促进其推理能力提升的关键样本,从而更高效地驱动模型性能的提升。
过滤条件
分数
无过滤
0.3093
Quality>=5; Difficulty>=0
0.2948
Quality>=0; Difficulty>=4
0.3156
Quality>=5; Difficulty>=4
0.3139
我们基于 Quality ≥ 5,Difficulty ≥ 4 的过滤条件,筛选得到约 50 万条数据,并对 Qwen3-VL 2B、4B、8B 版本进行了微调。我们使用 LMMs-Eval 框架进行评测。由于不同 Prompt 评测模板会对测评结果产生影响,我们在评测过程中统一固定了一套推理 Prompt。实验结果如下表所示。 我们成功验证了数据集的有效性,通过构建了约 50 万条高质量、高难度的训练数据,以此微调 Qwen3-VL 系列不同规模的模型(2B、4B、8B)的实验数据显示,无论是在通用视觉理解能力 benchmark(如 AI2D、MMStar),还是在对推理能力更敏感的 benchmark(如 MMMU_Pro_standard、MMMU_Pro_vision、 MathVerse、 MathVision)上,所有经过微调的模型均实现了性能提升,在强调推理能力的 benchmark 上提升尤为显著。这充分证明了高质量数据的蒸馏、筛选与规模扩展对模型推理能力提升的有效性。
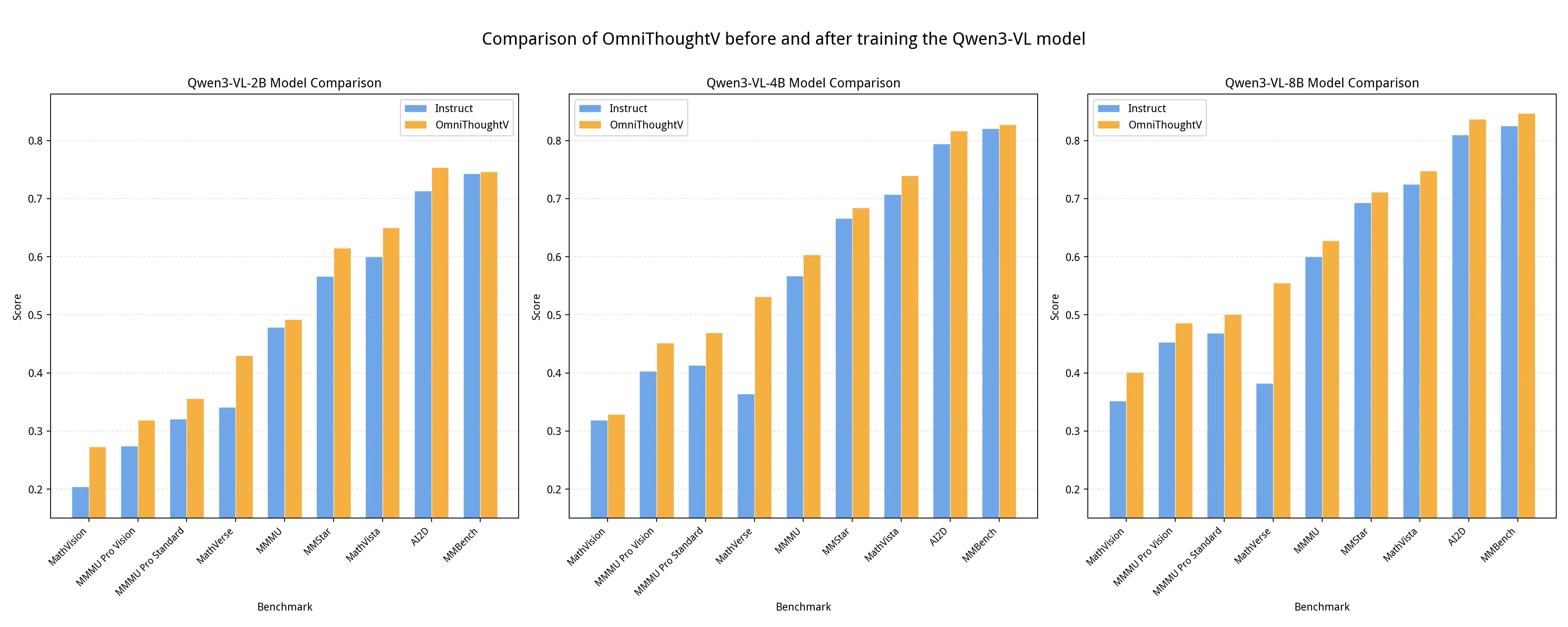
综上而言,OmniThoughtV 数据集的构建流程不仅验证了长思考思维链数据不仅能提升模型在视觉推理等任务上的推理能力,也验证了模型"看图深度思考"能力的提升也能提高模型的通用视觉理解能力。OmniThoughtV 数据集很好弥补了开源社区中大规模多模态长思考数据集的匮乏,也通过系统化的数据工程,提供了全流程清晰、可复现的工具和技术路线。
资源下载和使用
在EasyDistill框架的使用教程
通过使用阿里云人工智能平台(PAI)推出的开源工具包EasyDistill ,用户可以轻松实现实现多模态思维链数据的蒸馏、对思维链数据打分。
- 克隆代码库,并安装相关依赖:
bash
git clone https://github.com/modelscope/easydistill
cd EasyDistill
pip install -r requirements.txt- 可以使用各种配置文件生成训练数据,以思维链数据生成为例,配置文件如下:
json
{
"job_type": "mmkd_black_box_api",
"dataset": {
"instruction_path": "data/mllm_demo.json",
"labeled_path": "data/mllm_demo_distill.json",
"seed": 42
},
"inference":{
"base_url": "ENDPOINT",
"api_key": "TOKEN",
"system_prompt" : "You are a helpful assistant.",
"max_new_tokens": 512
},
"models": {
"student": "student/Qwen/Qwen3-VL-2B-Instruct/"
},
"training": {
"output_dir": "./result/",
"num_train_epochs": 3,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"max_length": 512,
"save_steps": 1000,
"logging_steps": 1,
"learning_rate": 2e-5,
"weight_decay": 0.05,
"warmup_ratio": 0.1,
"lr_scheduler_type": "cosine"
}
}- 完成思维链数据生成后,可以使用思维链评价打分功能,配置文件如下:
json
{
"job_type": "mmcot_eval_api",
"dataset": {
"input_path": "cot_input.json",
"output_path": "cot_output.json"
},
"inference":{
"base_url": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"api_key": "YOUR KEY",
"max_new_tokens": 8196
}
}运行下面的命令,即可完成对cot数据质量的评价打分:
arduino
export JUDGE_MODEL=qwen3-vl-plus
easydistill --config mmcot_eval_api.json详细用法可以参考 github.com/modelscope/...
从HuggingFace/ModelScope下载资源
我们的公开的数据约180万条原始数据集和50万条筛选后的数据集。每一条数据都带有评分。筛选后的数据集是难度大于等于4分,质量大于等于5分的数据。数据集中的图像采用base64编码储存。
数据集
HuggingFace
ModelScope
OmmiThoughtV_Raw_1.8M
OmniThoughtV_Filter_0.5M
可以参考以下代码读取数据集:
ini
from datasets import load_dataset
data_path='...YOUR_PATH_To.../OmmiThoughtV_Raw_1.8M/'
OmmiThoughtV=load_dataset(data_path, streaming=True)场景化应用
除了典型的多模态任务,我们提出的蒸馏方法可以有效应用于各种实际场景中,以下我们给出多个多模态深度思考任务的典型应用。
自动驾驶
问题:你需要右转,请基于当前图像中的道路环境和交通状况,请分析并规划你(自动驾驶车辆)下一步的最优驾驶策略。

markdown
<thinking>
1. **评估道路环境**:图像显示了一条多车道的城市道路,交通繁忙,前方有大型绿色自卸卡车和一辆白色轿车。道路两侧有高层建筑,表明这是一个密集的城市区域。道路由黄色隔离栏分隔,表明车流受到管控。
2. **识别当前车道及交通流**:车辆位于中间车道,该车道似乎是直行车道。图像中未见明显的右转车道或转弯信号指示,因此右转并不立即可行。相邻车道有大型卡车,表明转弯时需谨慎操作以避免碰撞。
3. **评估右转可行性**:前方道路看起来是直行的,未见明显的右转车道或转弯信号标志。相邻车道的大型卡车表明,若要转弯,需要小心操作以避免碰撞。黄色隔离栏表明道路为分隔式设计,转弯可能需要驶离当前车道。
4. **考虑交通法规与安全性**:图像中显示了一个"40"的限速标志,表明限速为40公里/小时。大型卡车的存在提示车辆应保持安全车距,避免突然变道或转向。黄色隔离栏进一步说明道路为分隔设计,转弯可能需提前变道。
5. **规划最优驾驶策略**:基于当前的道路环境和交通状况,作为自动驾驶车辆,下一步的最优驾驶策略应为:
- **保持当前车道**,继续直行,直到到达指定的右转车道或交叉路口。
- **持续监测交通状况**,确保有足够空间安全完成右转。
- **利用车辆的传感器和摄像头**,探测周围环境中可能存在的障碍物或危险。
- **遵守交通法规**,与其他车辆保持安全距离。
- **仅在安全且合法的情况下执行右转**,确保不阻碍其他车辆正常通行。
6. **结论**:作为自动驾驶车辆,下一步的最优驾驶策略是保持当前车道继续直行,直至到达指定的右转车道或交叉路口,同时密切观察交通状况,确保有充足空间安全完成右转。
</thinking>
<answer>
保持当前车道继续直行,直至到达指定的右转车道或交叉路口,同时监测交通状况并确保有足够空间安全完成右转。
</answer>文物讲解
假如你是博物馆讲解员,分析此陶器历史背景。

xml
<thinking>
第一步:分析该陶器的视觉特征。器物拥有细长的颈部和圆鼓的腹部,这种器型在东亚陶瓷传统中十分常见。器表装饰有风格化的鱼纹和花卉图案,表明其用途更偏向象征性或装饰性,而非日常实用。
第二步:考察釉面与表面质感。釉色呈柔和的土色调,略带斑驳或砂质感,这表明它很可能采用天然陶土,并以低温或半烧制工艺制成------这在古代朝鲜陶瓷中颇为典型。釉面呈灰蓝色调,说明使用了含铁量较高的陶土,并采用了还原焰烧制工艺,这种技法在朝鲜陶器中常用于营造含蓄而典雅的视觉效果。
第三步:推测历史时期。具备此类特征(鱼纹、砂质感、灰蓝釉)的陶器,与高丽王朝(918--1392年)尤其是晚期(12至13世纪)的朝鲜陶器风格相符。这一时期,朝鲜陶工发展出独具特色的风格,包括著名的"粉青沙器"(buncheong或powder-blue ware),常饰以精巧的手绘纹样和柔和半透明的釉面。鱼纹可能象征富足、多产或与自然和谐共处,这些主题在朝鲜艺术中十分常见。
第四步:考虑文化背景。此器物的设计与工艺表明,它很可能用于礼仪或祭祀场合,例如盛装酒或水,也可能是贵族家庭中的陈设品。鱼与花卉元素的结合,反映了当时朝鲜社会崇尚平衡、和谐以及自然崇拜的文化价值观。
第五步:结合博物馆语境。该文物被置于玻璃展柜中陈列,说明其具有重要的历史与文化价值。其保存状态与展示方式表明,它是朝鲜丰富陶瓷遗产中的一件珍贵代表,很可能制作于高丽王朝晚期。
结论:综合其视觉特征与历史背景,这件陶器很可能是一件高丽王朝晚期的作品,采用传统朝鲜制陶技艺制作而成,并饰有象征性的纹样,体现了当时朝鲜陶工在陶瓷艺术上的高度成就与文化内涵。
</thinking>
<answer>
这件陶器很可能源自朝鲜高丽王朝晚期(918--1392年),该时期以精致的陶瓷艺术著称。器物细颈鼓腹的造型,辅以风格化的鱼纹与花卉图案,表明其用途偏向礼仪性或装饰性。其砂质肌理与灰蓝色釉面,反映出当时朝鲜陶工采用含铁陶土及传统还原焰烧制工艺的典型技法。鱼纹可能象征富足或与自然的和谐,体现了当时的主流文化价值观。此器被博物馆珍藏并展出,彰显了它作为朝鲜陶瓷艺术瑰宝的重要历史与文化意义。
</answer>自动商品审核
这是用户发来的商品图,并申请了自动退款,请审核是否满足退款要求。

xml
<thinking>
图片显示了一盒橙子,其中一个橙子表面明显长有霉菌(灰绿色斑块)。水果上出现霉菌是变质的明确标志,通常被视为缺陷,会使该产品不符合新鲜且安全食用的标准。
大多数线上或零售购买的标准退款政策都包含针对变质、损坏或与描述不符商品的条款。由于霉菌清晰可见,影响了产品的质量和安全性,因此符合典型消费者保护政策下的退款条件。
因此,应批准退款请求。
</thinking>
<answer>
是的,退款条件已满足,因为橙子表面可见霉菌,表明其已变质,不再符合新鲜且安全食用的标准。
</answer> 小结
本文介绍了OmniThoughtV数据集,这是首个开源的大规模多模态长思考蒸馏数据集。我们完整构建了一套透明、可复现、高质量的多模态数据蒸馏与筛选流程,并系统验证了其在提升多模态大模型视觉推理能力方面的关键作用。我们通过严谨的消融实验,首次明确指出"难度"指标在数据筛选中的核心价值:相较于单纯依赖标注质量评分,引入高难度样本能更有效地驱动模型学习复杂推理逻辑,从而显著提升泛化性能。基于这一发现,我们设计了完整的数据过滤标准,从原始数据集中精准提炼出约50万条兼具挑战性与代表性的训练样本,并成功提升了Qwen3-VL系列的性能表现。实验结果表明,该数据流程不仅使各模型在多个权威评测集上实现稳定且显著的能力跃升,更展现出良好的模型规模扩展性。本工作填补了当前开源社区在结构化、可复现、面向推理能力提升的多模态数据蒸馏上的空白;在未来,我们会继续深入探索大模型的蒸馏和训练技术,推动大模型在各个场景的落地。
参考工作
EasyDistill系列相关论文
-
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
-
Yuanjie Lyu, Chengyu Wang, Jun Huang, Tong Xu. From Correction to Mastery: Reinforced Distillation of Large Language Model Agents. arXiv preprint
-
Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang. EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. EMNLP 2025
-
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Thinking with DistilQwen: A Tale of Four Distilled Reasoning and Reward Model Series. EMNLP 2025
-
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Enhancing Reasoning Abilities of Small LLMs with Cognitive Alignment. EMNLP 2025
-
Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
-
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024