一.搭建环境
安装conda
可以是anaconda也可以是miniconda
第一步
1.1、创建虚拟环境
# 创建环境:名称 yolov11_cpu,Python 3.9(Ultralytics 推荐版本)
conda create -n yolov11_cpu python=3.9 -y
#yolov11_cpu自己想的名称,可以按照自己想要的更改这个名称1.2、激活虚拟环境
conda activate yolov11_cpu1.3、配置 Conda 清华源
# 创建 Conda 配置文件
mkdir -p ~/.condarc
cat > ~/.condarc << EOF
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
EOF执行以下命令查看配置内容,确认清华源已写入:
cat ~/.condarc前面执行的时候若显示文件已存在也没关系,上面步骤执行完执行下面这个
#清理 Conda 缓存(可选,避免旧源干扰)
conda clean -i -y第二步:安装核心依赖(CPU 版本,无 CUDA 依赖)
2.1、安装版本匹配的 CPU 版依赖(清华源 + 官方源)
pip3 install torch==2.3.1+cpu torchvision==0.18.1+cpu torchaudio==2.3.1+cpu \
--index-url https://download.pytorch.org/whl/cpu \
--extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple \
--trusted-host download.pytorch.org \
--trusted-host pypi.tuna.tsinghua.edu.cn验证是否安装成功
python3 -c 'import torch, torchvision, torchaudio; print("="*60); print(f"PyTorch 版本: {torch.__version__} (CPU版: 是)" if "cpu" in torch.__version__ else f"PyTorch 版本: {torch.__version__} (CPU版: 否)"); print(f"torchvision 版本: {torchvision.__version__} (匹配: 是)" if torchvision.__version__ == "0.18.1+cpu" else f"torchvision 版本: {torchvision.__version__} (匹配: 否)"); print(f"torchaudio 版本: {torchaudio.__version__} (匹配: 是)" if torchaudio.__version__ == "2.3.1+cpu" else f"torchaudio 版本: {torchaudio.__version__} (匹配: 否)"); print(f"CUDA 可用: 否 (CPU模式)" if not torch.cuda.is_available() else "CUDA 可用: 是 (异常)"); print("="*60)'输出:
============================================================
PyTorch 版本: 2.3.1+cpu (CPU版: 是)
torchvision 版本: 0.18.1+cpu (匹配: 是)
torchaudio 版本: 2.3.1+cpu (匹配: 是)
CUDA 可用: 否 (CPU模式)
============================================================2.2、 安装 Ultralytics(YOLOv11 核心库)
pip3 install ultralytics --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple要想知道路径:用 pip 直接查询安装路径(最准确)
在激活 yolov11_cpu 环境的终端执行:
pip3 show ultralytics2.3 安装辅助依赖(避免后续报错)
pip3 install numpy pillow matplotlib opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple2.4、验证环境(关键!确保无问题)
python3 -c "import torch, torchvision, torchaudio, ultralytics; print('PyTorch:', torch.__version__); print('torchvision:', torchvision.__version__); print('torchaudio:', torchaudio.__version__); print('Ultralytics:', ultralytics.__version__); print('CUDA可用:', torch.cuda.is_available())"输出:
PyTorch: 2.3.1+cpu
torchvision: 0.18.1+cpu
torchaudio: 2.3.1+cpu
Ultralytics: 8.3.237
CUDA可用: False/*之前yolov11_conda配置的先安装python,然后使用pip install安装pytorch2.4.0和torchvision0.19.0
然后安装yolo环境
pip install ultralytics*/
二.构建数据集
第一步,使用labelme标注图片,将标注好的json转换成txt
在激活前面创建的环境下,执行json转txt的文件,我的是json_to_txt.py,它的内容就是下面的代码,注意要将root_path = r"/home/ikun/12.13"修改成自己数据的位置。
python
#执行转换,这个位置就是你放json_to_txt.py的位置
(yolov11_cpu) ikun@ikun:~$ python3 json_to_txt.py
python
# 导入必要的库
import cv2 # OpenCV,本代码未直接使用,但为后续扩展预留(如读取图片验证尺寸)
import os # 操作系统路径/文件夹操作核心库
import json # 解析JSON标注文件的核心库
import glob # 批量匹配文件路径(如所有.json文件)
import numpy as np # 数值计算库,用于坐标归一化(避免浮点精度问题)
def convert_json_label_to_yolov_seg_label():
"""
核心功能:将LabelMe格式的JSON分割标注文件,转换为YOLOv11分割任务所需的TXT标签格式
关键步骤:
1. 遍历所有JSON文件,统计所有唯一标签并分配连续ID(按字母序)
2. 按YOLO分割格式要求,将每个目标的轮廓坐标归一化并写入TXT
3. 输出结果:每个JSON对应一个TXT,保存在同级labels文件夹下
"""
# ===================== 核心路径配置(可根据实际环境修改)=====================
# 根路径:存放PNG图片和JSON标注文件的目录(Linux绝对路径)
root_path = r"/home/ikun/12.13"
# 批量匹配根路径下所有.json文件(glob.glob返回符合条件的文件路径列表)
json_files = glob.glob(os.path.join(root_path, "*.json"))
# 输出TXT标签的文件夹路径(创建在根路径下的labels目录)
output_folder = os.path.join(root_path, "labels")
# ===================== 第一步:统计所有唯一标签,生成标签-ID映射 ===================
print("开始统计所有标签...")
all_labels = set() # 用集合(set)存储标签,自动去重(避免重复标签多次统计)
# 遍历所有JSON文件,提取标签
for json_file in json_files:
try:
# 以只读模式打开JSON文件,指定编码为utf-8(避免中文标签乱码)
with open(json_file, 'r', encoding='utf-8') as f:
# 加载JSON文件内容为Python字典(LabelMe的JSON是键值对结构)
json_info = json.load(f)
# 遍历JSON中"shapes"字段(LabelMe标注的目标轮廓/标签都存在这里)
for shape in json_info.get("shapes", []):
# 提取当前目标的标签(如"person"/"car")
label = shape.get("label", "")
if label: # 跳过空标签(避免无效数据)
all_labels.add(label) # 将有效标签加入集合去重
# 捕获解析单个JSON文件的异常(如文件损坏、格式错误),不中断整体流程
except Exception as e:
print(f"警告:解析文件 {json_file} 时出错,跳过!错误信息:{e}")
continue # 跳过当前错误文件,处理下一个
# 生成标签-ID映射字典:按字母排序后分配ID(ID从0开始,YOLO要求类别ID为连续整数)
label_map = {label: idx for idx, label in enumerate(sorted(all_labels))}
#enumerate(sorted(all_labels)):
#sorted(all_labels) → ["管道", "气泡羽流", "水面"](按中文拼音 /unicode 排序);
#enumerate(...) → (0, "管道"), (1, "气泡羽流"), (2, "水面");
#{label: idx for idx, label in ...}
#label_map = {}
#for idx, label in ...:
# label_map[label] = idx
# 打印标签-ID映射表(方便用户核对)
print("\n===== 标签-ID映射表 =====")
for label, idx in label_map.items():
print(f"{label} → {idx}")
print("========================\n")
# ===================== 第二步:创建输出文件夹(若不存在)=====================
# os.path.exists判断文件夹是否存在,不存在则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder) # 递归创建文件夹(即使上级目录不存在也能创建)
print(f"创建输出文件夹:{output_folder}")
# ===================== 第三步:遍历JSON,转换为YOLO分割TXT格式 =====================
print("开始转换JSON标签为YOLO TXT格式...")
success_count = 0 # 统计成功转换的文件数(用于最终汇总)
# 遍历每个JSON文件,逐个转换
for json_file in json_files:
try:
# 1. 读取当前JSON文件内容
with open(json_file, 'r', encoding='utf-8') as f:
json_info = json.load(f)
# 2. 获取图片原始尺寸(LabelMe的JSON会记录imageWidth/imageHeight,关键!)
# 归一化必须基于原始尺寸,不能用固定值(否则坐标比例错误)
image_width = json_info.get("imageWidth", 0) # 获取宽度,默认值0
image_height = json_info.get("imageHeight", 0) # 获取高度,默认值0
# 校验尺寸有效性:宽度/高度≤0说明JSON文件损坏,跳过
if image_width <= 0 or image_height <= 0:
print(f"警告:文件 {json_file} 中未找到有效图像尺寸,跳过!")
continue
# 3. 定义输出TXT文件路径
# 提取JSON文件名(如"img1.json" → "img1"),替换后缀为.txt
txt_filename = os.path.basename(json_file).replace(".json", ".txt")
# 拼接输出路径:labels文件夹 + 同名TXT文件
txt_file = os.path.join(output_folder, txt_filename)
# 4. 写入YOLO分割格式的TXT内容
with open(txt_file, "w", encoding='utf-8') as f:
# 遍历JSON中每个目标的shapes(每个shape对应一个分割目标)
for shape in json_info.get("shapes", []):
# 4.1 提取当前目标的标签
label = shape.get("label", "")
# 校验标签是否在映射表中(避免未统计的标签导致ID错误)
if label not in label_map:
print(f"警告:文件 {json_file} 中发现未统计的标签 '{label}',跳过该目标!")
continue
# 4.2 提取分割轮廓的坐标点(LabelMe的points是[[x1,y1],[x2,y2],...]格式)
points = shape.get("points", [])
# 校验轮廓点数量:分割任务至少需要3个点(构成闭合轮廓),否则无效
if len(points) < 3:
print(f"警告:文件 {json_file} 中标签 '{label}' 的轮廓点数量不足,跳过!")
continue
# 4.3 坐标归一化(YOLO要求坐标为0-1之间的相对值)
# 将points转为numpy数组(方便批量计算),类型为float32(避免精度丢失)
np_points = np.array(points, np.float32)
# 构建尺寸数组([[宽度, 高度]]),用于广播除法
np_w_h = np.array([[image_width, image_height]], np.float32)
# 归一化:每个坐标点(x,y) / (宽度, 高度) → 转为0-1区间
norm_points = np_points / np_w_h
# 4.4 构建YOLO分割标签行
# ① 获取当前标签对应的ID(YOLO第一列是类别ID)
category_id = label_map[label]
# ② 将归一化后的坐标转为字符串(保留6位小数,平衡精度和文件大小)
points_str = " ".join([f"{x:.6f} {y:.6f}" for x, y in norm_points])
#join():字符串方法,将列表中的元素用「空格」连接成一个完整字符串;
# ③ 拼接YOLO格式行:类别ID + 空格分隔的坐标串 + 换行
txt_line = f"{category_id} {points_str}\n"
# ④ 写入TXT文件
f.write(txt_line)
# 5. 统计成功转换的文件数
success_count += 1
print(f"成功转换:{json_file} → {txt_file}")
# 捕获单个文件转换的异常(如坐标格式错误、权限问题)
except Exception as e:
print(f"错误:处理文件 {json_file} 时失败!错误信息:{e}")
continue # 跳过当前错误文件
# ===================== 转换完成:输出汇总信息 =====================
total_files = len(json_files) # 总JSON文件数
fail_count = total_files - success_count # 失败数
print(f"\n转换完成!总计找到 {total_files} 个JSON文件,成功转换 {success_count} 个,失败 {fail_count} 个。")
print(f"转换后的TXT标签已保存至:{output_folder}")
# 程序入口:只有直接运行该脚本时,才执行转换函数
if __name__ == "__main__":
convert_json_label_to_yolov_seg_label()第二步,划分数据集

执行划分数据集的.py文件
python
(yolov11_cpu) ikun@ikun:~$ python3 data_par.py
python
# 导入必要的库
import shutil # 用于文件复制(核心功能:shutil.copyfile)
import random # 用于随机划分数据集(核心功能:random.sample)
import os # 用于路径/文件夹操作(核心功能:os.makedirs、os.path.exists等)
# ===================== 核心路径配置(用户需根据实际环境修改)=====================
# 原始PNG图片存放路径(所有待分割的图片都在这里)
image_original_path = "/home/ikun/12.13/"
# 原始TXT标签存放路径(由之前的JSON转换脚本生成,与图片一一对应)
label_original_path = "/home/ikun/12.13/labels/"
# 分割后数据集的根目录(脚本会自动在该目录下创建images/labels的train/val/test子目录)
dataset_root = "/home/ikun/12.13/datasets/"
# ===================== 数据集比例配置(可按需调整)=====================
train_percent = 0.8 # 训练集占比80%
val_percent = 0.1 # 验证集占比10%
test_percent = 0.1 # 测试集占比10%(兜底计算:1 - train_percent - val_percent)
# ===================== 自动推导子目录路径(无需修改)=====================
# 训练集图片路径:datasets/images/train/
train_image_path = os.path.join(dataset_root, "images/train/")
# 训练集标签路径:datasets/labels/train/
train_label_path = os.path.join(dataset_root, "labels/train/")
# 验证集图片路径:datasets/images/val/
val_image_path = os.path.join(dataset_root, "images/val/")
# 验证集标签路径:datasets/labels/val/
val_label_path = os.path.join(dataset_root, "labels/val/")
# 测试集图片路径:datasets/images/test/
test_image_path = os.path.join(dataset_root, "images/test/")
# 测试集标签路径:datasets/labels/test/
test_label_path = os.path.join(dataset_root, "labels/test/")
# 数据集列表文件路径(记录各集合的文件路径,可选功能,用于部分框架加载数据)
list_train = os.path.join(dataset_root, "train.txt") # 训练集文件列表
list_val = os.path.join(dataset_root, "val.txt") # 验证集文件列表
list_test = os.path.join(dataset_root, "test.txt") # 测试集文件列表
def clear_folder(path):
"""
自定义函数:清空指定文件夹内的所有文件(保留文件夹本身)
防止旧数据残留导致数据集污染
"""
# 判断文件夹是否存在(不存在则无需清空)
if os.path.exists(path):
# 遍历文件夹内的所有文件/子目录
for file_name in os.listdir(path):
# 拼接文件的完整路径
file_path = os.path.join(path, file_name)
try:
# 判断是否为文件(跳过子目录,只删除文件)
if os.path.isfile(file_path):
os.remove(file_path) # 删除文件
# 捕获删除文件的异常(如文件被占用、权限不足)
except Exception as e:
print(f"警告:删除文件 {file_path} 失败 - {e}")
def mkdir():
"""
自定义函数:创建数据集所需的所有目录,若目录已存在则清空其中的文件
保证每次运行脚本都是全新的数据集
"""
# 1. 处理训练集目录
# os.makedirs:递归创建目录(如datasets/images/train/,即使datasets/不存在也会自动创建)
# exist_ok=True:目录已存在时不报错
os.makedirs(train_image_path, exist_ok=True)
clear_folder(train_image_path) # 清空训练集图片目录旧文件
os.makedirs(train_label_path, exist_ok=True)
clear_folder(train_label_path) # 清空训练集标签目录旧文件
# 2. 处理验证集目录
os.makedirs(val_image_path, exist_ok=True)
clear_folder(val_image_path)
os.makedirs(val_label_path, exist_ok=True)
clear_folder(val_label_path)
# 3. 处理测试集目录
os.makedirs(test_image_path, exist_ok=True)
clear_folder(test_image_path)
os.makedirs(test_label_path, exist_ok=True)
clear_folder(test_label_path)
def clearfile():
"""
自定义函数:删除旧的数据集列表文件(train.txt/val.txt/test.txt)
避免旧列表文件与新数据集不匹配
"""
# 遍历所有列表文件路径
for file_path in [list_train, list_val, list_test]:
# 判断文件是否存在
if os.path.exists(file_path):
try:
os.remove(file_path) # 删除旧文件
except Exception as e:
print(f"警告:删除列表文件 {file_path} 失败 - {e}")
def main():
"""
主函数:数据集分割的核心逻辑
流程:初始化目录 → 读取标签文件 → 随机划分 → 复制文件 → 生成列表
"""
# 第一步:初始化目录(创建新目录/清空旧数据)
mkdir() # 创建并清空数据集目录
clearfile() # 删除旧的列表文件
# 第二步:打开列表文件,准备写入各集合的文件路径(追加模式w,覆盖旧内容)
file_train = open(list_train, 'w', encoding='utf-8')
file_val = open(list_val, 'w', encoding='utf-8')
file_test = open(list_test, 'w', encoding='utf-8')
# 第三步:获取所有TXT标签文件(以标签文件为基准,保证图片和标签一一对应)
# os.listdir(label_original_path):列出标签目录下的所有文件
# 列表推导式:筛选出后缀为.txt的文件(排除其他无关文件)
total_txt = [f for f in os.listdir(label_original_path) if f.endswith('.txt')]
# 统计标签文件总数(即数据集总样本数)
num_txt = len(total_txt)
# 校验:若没有标签文件,直接终止程序(无数据可分割)
if num_txt == 0:
print("错误:未在 {} 找到任何TXT标签文件!".format(label_original_path))
return # 退出main函数
# 第四步:生成索引列表(用于随机划分,避免直接操作文件名)
# list(range(num_txt)):生成0到num_txt-1的整数列表,每个数对应一个标签文件的索引
list_all_txt = list(range(num_txt))
# 第五步:计算各数据集的样本数量
num_train = int(num_txt * train_percent) # 训练集数量:总样本数×80%
num_val = int(num_txt * val_percent) # 验证集数量:总样本数×10%
num_test = num_txt - num_train - num_val # 测试集数量:兜底计算(避免比例求和不为1)
# 第六步:随机划分数据集(核心逻辑)
random.seed(42) # 设置随机种子(固定值42),保证每次运行划分结果完全一致(可复现)
# random.sample(list_all_txt, num_train):从索引列表中随机选取num_train个元素(不重复),作为训练集索引
train_idx = random.sample(list_all_txt, num_train)
# 剩余索引:总索引 - 训练集索引 = 验证集+测试集索引
val_test_idx = [i for i in list_all_txt if i not in train_idx]
# 从剩余索引中随机选取num_val个元素,作为验证集索引
val_idx = random.sample(val_test_idx, num_val)
# 最后剩余的索引作为测试集索引
test_idx = [i for i in val_test_idx if i not in val_idx]
# 打印划分信息(方便用户核对)
print("="*50)
print(f"总数据量:{num_txt}")
print(f"训练集数目:{len(train_idx)}, 验证集数目:{len(val_idx)}, 测试集数目:{len(test_idx)}")
print("="*50)
# 第七步:遍历所有数据,根据划分结果复制文件到对应目录
for i in list_all_txt:
# 获取当前索引对应的标签文件名(如"img1.txt")
txt_name = total_txt[i]
# 提取文件名(不含后缀):os.path.splitext(txt_name)[0] → "img1"
# 替代传统的txt_name[:-4],兼容后缀长度不同的情况(如.txt/.json)
name = os.path.splitext(txt_name)[0]
# 拼接原始图片和标签的完整路径(图片为.png,标签为.txt)
src_image = os.path.join(image_original_path, f"{name}.png") # 原始图片路径
src_label = os.path.join(label_original_path, f"{name}.txt") # 原始标签路径
# 校验:图片或标签不存在则跳过该样本(避免复制失败)
if not os.path.exists(src_image):
print(f"警告:图片 {src_image} 不存在,跳过该数据!")
continue # 跳过当前循环,处理下一个样本
if not os.path.exists(src_label):
print(f"警告:标签 {src_label} 不存在,跳过该数据!")
continue
# 根据索引所属集合,复制文件到对应目录
if i in train_idx:
# 训练集目标路径
dst_img = os.path.join(train_image_path, f"{name}.png")
dst_lbl = os.path.join(train_label_path, f"{name}.txt")
# shutil.copyfile:复制文件(从源路径到目标路径)
shutil.copyfile(src_image, dst_img)
shutil.copyfile(src_label, dst_lbl)
# 写入训练集列表文件(记录图片路径,换行符\n)
file_train.write(dst_img + '\n')
elif i in val_idx:
# 验证集目标路径
dst_img = os.path.join(val_image_path, f"{name}.png")
dst_lbl = os.path.join(val_label_path, f"{name}.txt")
shutil.copyfile(src_image, dst_img)
shutil.copyfile(src_label, dst_lbl)
file_val.write(dst_img + '\n')
else:
# 测试集目标路径
dst_img = os.path.join(test_image_path, f"{name}.png")
dst_lbl = os.path.join(test_label_path, f"{name}.txt")
shutil.copyfile(src_image, dst_img)
shutil.copyfile(src_label, dst_lbl)
file_test.write(dst_img + '\n')
# 第八步:关闭列表文件(释放资源,避免文件损坏)
file_train.close()
file_val.close()
file_test.close()
# 打印完成信息
print("\n数据集划分完成!")
print(f"分割后数据集保存至:{dataset_root}")
# 程序入口:只有直接运行该脚本时,才执行main函数
if __name__ == "__main__":
main()
第三步,修改配置文件
修改data.yaml和yolo11-seg.yaml
需要修改data.yaml中的路径,ID以及标签名
需要将data.yaml放入到你存放数据的位置,比如我的12.17文件夹
python
# data.yaml - 适配/home/ikun/12.13/datasets数据集
path: /home/ikun/12.13/datasets # 数据集根目录(核心路径,其他路径基于此拼接)
train: images/train # 训练集图片路径(path + train = /home/ikun/12.13/datasets/images/train)
val: images/val # 验证集图片路径
test: images/test # 测试集图片路径
# 类别名称(关键:需替换为你实际的标签!)
# 格式:ID: 标签名(ID要和之前JSON转TXT时自动统计的label_map一致)
names:
0: Beam-slab-joint
1: Leakage-and-efflorescence
2: Longitudinal-crack
3: Repair-block
4: Transverse-crack然后修改yolo11-seg.yaml,修改nc为标签数量
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11-seg instance segmentation model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/segment
# Parameters
nc: 5 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n-seg.yaml' will call yolo11-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 203 layers, 2876848 parameters, 2876832 gradients, 10.5 GFLOPs
s: [0.50, 0.50, 1024] # summary: 203 layers, 10113248 parameters, 10113232 gradients, 35.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 253 layers, 22420896 parameters, 22420880 gradients, 123.9 GFLOPs
l: [1.00, 1.00, 512] # summary: 379 layers, 27678368 parameters, 27678352 gradients, 143.0 GFLOPs
x: [1.00, 1.50, 512] # summary: 379 layers, 62142656 parameters, 62142640 gradients, 320.2 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)第四步.训练模型

需要对下面的yolo11-seg.yaml和data.yaml修改到其对应的位置
python
yolo task=segment mode=train model=ultralytics/cfg/models/11/yolo11-seg.yaml data=data.yaml batch=32 epochs=300 imgsz=640 workers=10 device=0比如我的:和上面对比一下
python
(yolov11_cpu) ikun@ikun:~/ultralytics-main$ yolo task=segment mode=train model=/home/ikun/ultralytics-main/yolo11-seg.yaml data=/home/ikun/12.17/data.yaml batch=1 epochs=50 imgsz=416 workers=0 device=cpu amp=False name=yolov11_seg_cpu patience=5
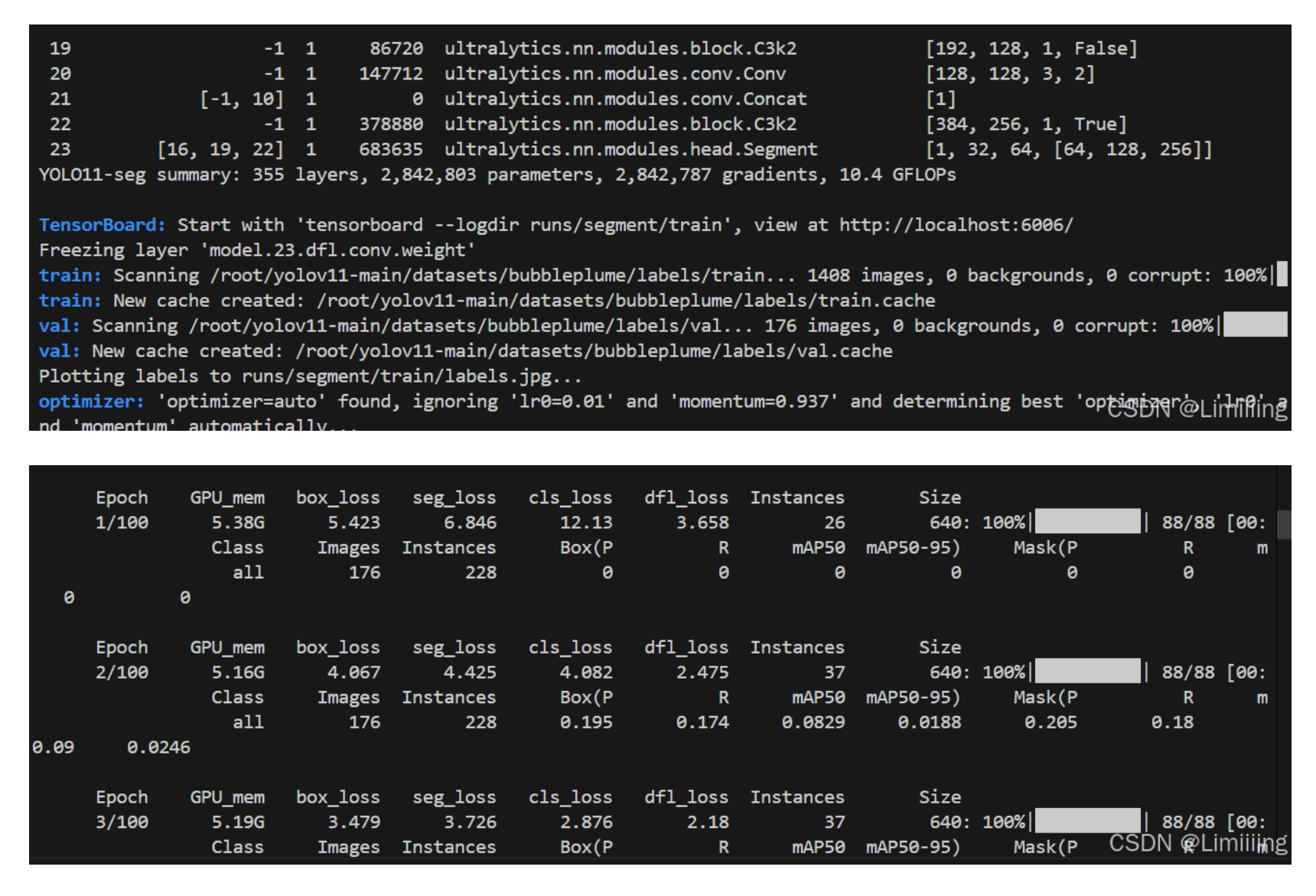
训练情况
第五步、结果所在位置
/home/ikun/ultralytics-main/runs/segment