-
论文标题:HiMaCon: Discovering Hierarchical Manipulation Concepts from Unlabeled Multi-Modal Data
-
作者:Ruizhe Liu, Pei Zhou, Qian Luo, Li Sun, Jun Cen, Yibing Song, Yanchao Yang
-
机构:The University of Hong Kong; DAMO Academy, Alibaba Group; Transcengram
-
作者简介:
本文第一作者为香港大学InfoBodied AI实验室博士生刘瑞哲,合作者包括周佩、罗谦(同属忆生科技)和孙力。通讯作者为香港大学数据科学研究院及电机电子工程系助理教授杨言超,以及阿里巴巴达摩院研究员岑俊和宋奕兵。InfoBodied AI实验室在CVPR、ICML、NeurIPS、ICLR等顶会持续发表代表性成果,与国内外知名高校,科研机构广泛开展合作。
原文链接:NeurIPS'25 | 港大×达摩院HiMaCon:泛化失败不在于策略学习不足,而在于缺乏"操作概念"
1 机器人为何需要「概念」?
机器人操作模型常在训练环境表现优异,却在分布外场景失败。例如,能稳定完成"将杯子放入容器"的策略,仅需改变物体颜色、调整位置或增加隔板,就可能彻底失效。
港大与阿里达摩院联合提出的HiMaCon指出:泛化失败的根源不在于策略学习不足,而在于缺乏"操作概念"这一认知层。
人类执行任务时,会自然形成"对齐物体"、"抓取目标"、"规避障碍"等可复用的抽象概念,这些概念能跨物体、场景和视觉变化保持稳定。传统机器人系统仅以像素和关节状态为输入,缺乏概念结构作为中间表征,难以真正泛化。
现有端到端方法直接从视频-动作对学习策略,容易过拟合场景外观和统计偏置,而非任务本质。以"放入容器"为例,无论容器如何变化,核心逻辑始终一致:识别区域 → 规划路径 → 避免碰撞 → 完成放置。
HiMaCon的核心理念:机器人要实现泛化,必须像人类一样先学"概念",再学"动作"。具体而言,让机器人从多模态演示数据中自动发现类人的层级操作概念,完全无需人工标注。
2 HiMaCon:完全自监督地发现多层级操作概念
如图1所示,HiMaCon通过自监督学习,将多模态演示数据编码为等长的操作概念序列。
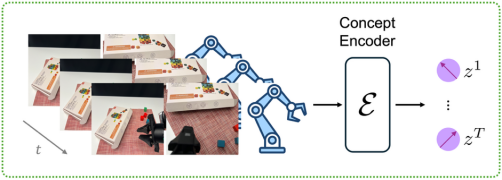
HiMaCon的核心创新来自两大自监督机制:
2.1 跨模态关联:捕获不变的关联而非表面特征
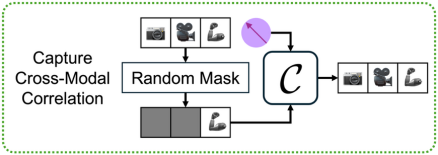
机器人演示包含多视角RGB、本体感知等多模态数据。不同模态在任务执行中呈现高度一致的变化规律------例如,"开启容器"任务中,视觉上的盖子旋转、力反馈和听觉提示之间的关联模式在不同容器间保持一致。这些跨模态相关结构是高价值的泛化信号。
**HiMaCon引入跨模态关联网络(图2):**随机遮挡部分模态,强制模型仅用剩余模态+概念表征重建全部模态。这迫使概念表征编码模态间的物理依赖关系,而非易变的颜色、纹理等表面特征。
2.2 多时域子目标结构:让操作概念自动形成「层级」
机器人任务具有天然层级性。以"将碗收入橱柜"为例,可分解为粗粒度"开启抽屉、放入碗",中等粒度"抓取碗、拉开抽屉",以及细粒度"手爪对齐、微调位姿"。
HiMaCon设计多时域未来预测器(图3):
- 根据概念latent的球面距离,自动分割出不同时域长度的子阶段(无需人工标注)
- 训练网络预测每个子阶段的终止状态,使概念表征编码多时域的进度信息
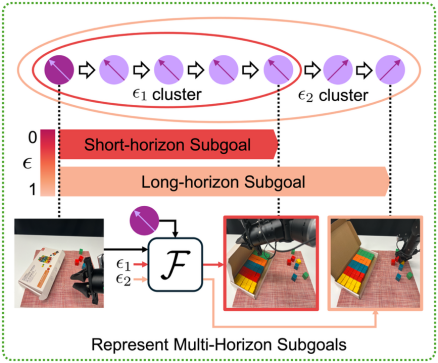
如图4所示,通过这种方式,概念表征自然涌现出涵盖不同时域尺度的层级化聚类结构。

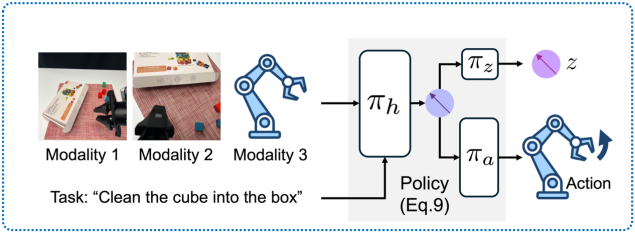
3与任意策略兼容
HiMaCon作为概念表征增强模块,可直接作用于策略模型中间特征。通过联合预测机制,策略网络同时输出动作和HiMaCon发现的概念表征(图5),在学习动作的同时学习相关概念结构,无需修改策略整体架构。
3.1 模拟器实验
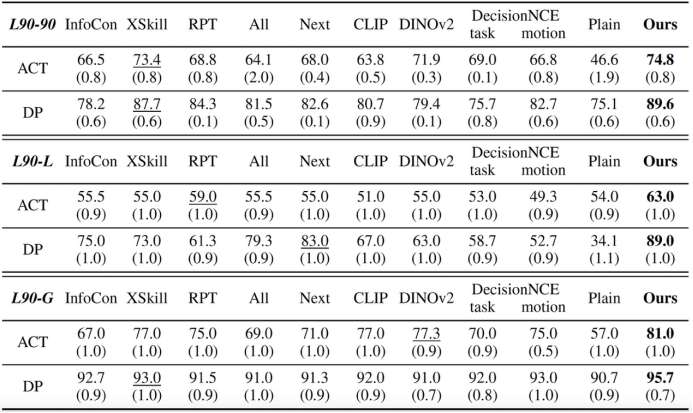
在LIBERO1基准上的三项评估:(1)LIBERO-90(90个训练任务);(2)LIBERO-10(长时序组合任务);(3)LIBERO-GOAL(分布外环境任务)。所有操作概念仅从LIBERO-90的多模态演示中发现。
如表1所示,相较于不使用概念及其他概念学习方法,HiMaCon在分布内任务、长时序组合任务和分布外任务上均显著提升成功率,证明其良好泛化能力。
3.2 真实机器人实验:泛化性验证
在Mobile ALOHA4平台上设计六类难度递增的杯子收纳场景:新摆放位置、新颜色组合、全新物体、遮挡、障碍物、同时抓取两杯。
如表2所示,尽管概念编码器和策略仅在简单场景训练,HiMaCon增强策略在所有测试场景均显著提升性能。
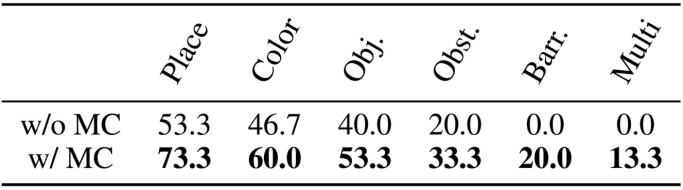
特别在"障碍物"和"同时抓取两杯"等训练中从未出现的复杂情况(图6),概念增强策略成功完成任务,而基线完全失败,充分证明所学概念的泛化能力。
3.3 提升VLA数据效率
HiMaCon显著提升视觉-语言-动作模型(VLA)的数据效率。作者将操作概念集成到OpenVLA-OFT5中,在LIBERO-10任务上仅使用原研究50%的训练数据进行微调实验。如图6所示,在整个训练过程中,集成操作概念的VLA始终保持更高的成功率。值得注意的是,原始OpenVLA-OFT使用100%数据达到94.5%成功率,而HiMaCon增强的VLA 仅用50%数据即达到接近性能,数据效率提升显著。
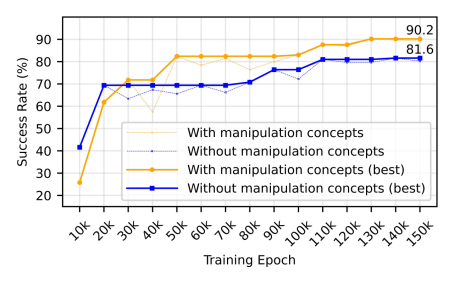
这一提升源于HiMaCon在多个抽象层级捕获操作动态的能力。学习到的概念提供了连接高层任务指令与低层控制动作的中间表征,为VLA提供结构化的操作知识,减轻了从头学习复杂感知-运动模式的负担。
4 总结
HiMaCon实现了从无标注数据中自动发现可解释、可组合的分层操作概念,这些概念具备类人的层级结构,显著提升泛化和迁移能力。核心创新包括:(1)跨模态不变性学习使概念更稳定可迁移;(2)多时域预测机制使概念自然涌现层级结构;(3)通用增强模块可应用于各类模仿学习策略。更重要的是,HiMaCon证明了机器人仅凭自身多模态数据,无需人类标注或语言描述,就能学会类人的操作概念结构------这为开发真正适应现实世界的泛化型机器人迈出了关键一步。
5. 参考文献
1. Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., & Stone, P. (2023). Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36, 44776-44791.
2. Zhao, T. Z., Kumar, V., Levine, S., & Finn, C. (2023). Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705.
3. Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., ... & Song, S. (2025). Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11), 1684-1704.
4. Fu, Z., Zhao, T. Z., & Finn, C. (2024). Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. arXiv preprint arXiv:2401.02117.
5. Kim, M. J., Finn, C., & Liang, P. (2025). Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645.
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?