一、层次式架构理论及实践
1.1、软件架构的重要性
软件架构贯穿于软件研发的整个生命周期内,具有三方面的重要影响:
1)利益相关人员之间的交流:架构图是通用的语言。不管是针对用户(看逻辑视图)、程序员(看实现视图)还是运维(看部署视图),架构都能让大家在同一个频道对话。
2)系统设计的【前期决策 】:架构一旦定型(比如选了 C/S 还是 B/S,选了 Java 还是 Go),后期想改的成本是巨大的。所以它是最关键的早期决策。
3)可传递的【系统级抽象 】:就像"分层架构"这个概念,你在 A 项目用了,在 B 项目还能用。它是一种可以复用的高层模式。
1.2、层次式架构的运行机制
1.2.1、结构逻辑
上层 (Upper Layer): 作为 下层的客户 (Client) 。它发起 调用 (Call)。
下层 (Lower Layer): 为 上层提供服务 (Service) 。它 返回 (Return) 结果。
1.2.2、交互方式
层与层之间通过 接口 进行通信,遵循 "调用 / 返回" 机制。
1.3、层次式架构的核心约束
1.3.1、严格分层
每一层最多只影响两层 【严格分层的情况下】
定义: 在严格分层中,第 N 层 只能 调用第 N-1 层,不能 跳过 N-1 层去调用 N-2 层(禁止跨层调用)。
好处: 降低耦合度。如果第 N-1 层变了,只有第 N 层需要知道,N+1 层完全不受影响。这就是"把影响限制在相邻层"。
坏处(考点): 性能损耗(穿透效应)。如果顶层只需要底层的一个简单数据,也必须层层转发,效率较低。
1.3.2、实现独立性
允许每层用不同方法实现
接口与实现分离: 只要接口定义好了,上层根本不关心下层是用 Java 写的还是 C++ 写的,是用 SQL 数据库还是文件存储。
支持标准化: 这使得我们可以定义标准的 OSI 七层网络模型,或者标准的 JDBC 接口。
二、C/S 与 B/S 架构演化
2.1、架构演化历程
两层 C/S ⟶ \longrightarrow ⟶ 三层 C/S ⟶ \longrightarrow ⟶ 三层 B/S
2.2、两层 C/S 架构
胖客户端 (Fat Client): 包含 【客户应用程序】。因为业务逻辑(Business Logic)和界面显示(Presentation)都堆在客户端电脑上。客户端软件体积大,功能重。
瘦服务器 (Thin Server): 包含 【数据库服务器】。
连接方式: 【网络】。通常是局域网。
优点: 响应速度快,界面交互丰富(鼠标右键、快捷键等),数据安全强。
**缺点:**升级维护困难,如果你有 1000 个用户,业务逻辑改了一行代码,你需要去 1000 台电脑上重新安装软件。这对运维来说是噩梦。
典型代表: 早期的 VB, Delphi 开发的局域网软件。
2.3、三层 C/S 架构
瘦客户端 (Thin Client): 包含 【表示层】。只负责画界面(瘦了)。
应用服务器 (Application Server): 包含 【功能层】。负责算工资、算利息等核心业务(从客户端挪到了服务器)。
数据库服务器 (Database Server): 包含 【数据层】。负责存取数据。
核心变革: 引入了中间的 应用服务器。
**优点:**业务逻辑变化不再需要更新客户端。如果业务逻辑变了(比如利息算法变了),只需要在"应用服务器"上改代码,客户端不需要重新安装,因为它只负责显示结果。
2.4、三层 B/S 架构
零客户端 (Zero Client): 包含 【Web浏览器/表示层】。不需要安装任何专门的软件,只要有 浏览器 (Browser) 就能用。
WEB应用服务器 (Web Application Server): 包含 【功能层/数据访问层】。
数据库服务器 (Database Server): 包含 【数据层】。
优点: 零安装,维护极其简单(改服务器就行),跨平台好(有浏览器就能跑)。
缺点: 交互体验不如原生软件流畅(虽然现在有 Ajax/Vue/React 改善),安全性相对较弱(Web 漏洞多)。
三、通用N 层架构模式
3.1、核心定义与地位
N 层架构模式是 最通用的架构 ,常作为 初始架构。
当你接手一个新项目,需求还不太明确,不知道选什么架构时,选"分层架构"通常不会错。它是架构界的"万金油"或"保底方案"。
【关注分离】 每层只负责本层的工作。这样每层都能独立演化,互不干扰。
3.2、经典四层结构
1)表现层:包含组件,封闭 。接收 Request。
2)中间层 / 业务逻辑层:包含组件,封闭。
3)访问层 / 数据访问层:包含组件,封闭。
4)数据层:包含数据库,封闭。
封闭原则: 第 N 层只能调用第 N-1 层。请求必须一层一层往下传,不能跳跃。
好处: 依赖清晰,可维护性高。
坏处: 性能损耗(这就引出了下面的"污水池反模式")。
3.3、层内设计模式
3.3.1、表现层设计模式
1)MVC (Model-View-Controller)
特点: 控制器 (Controller) 是核心中枢。
缺点: View 和 Model 之间还有直接联系,耦合度较高。
2)MVP (Model-View-Presenter)
特点: 进化版。Presenter 彻底切断了 View 和 Model 的联系。View 变得很"笨"(被动视图),逻辑全在 Presenter 里。
3)MVVM (Model-View-ViewModel)
特点: 现代前端主流 (Vue/React/Angular)。核心是 双向绑定。View 变了,ViewModel 自动变;数据变了,界面自动刷新。
3.3.2、访问层
1)ORM
把数据库表映射成对象(如 Java 中的 Hibernate/MyBatis),让程序员不用写复杂的 SQL。
3.4、污水池反模式
定义: 请求 简单穿透多层 ,但 没做业务逻辑。
场景: 假设你只是想从数据库查一个用户的名字显示在界面上。
正常流程: Controller → \rightarrow → Service → \rightarrow → DAO → \rightarrow → DB → \rightarrow → DAO → \rightarrow → Service → \rightarrow → Controller。
问题: Service 层和 DAO 层可能除了转发数据,什么逻辑都没干(Pass-through)。
为什么叫污水池? 因为请求像水一样流过这些层,却没产生任何价值,反而浪费了性能(层层转发的开销)。
怎么解决? 允许 "开放 (Open)" 某些层。即允许上层 跳过 中间层,直接调用底层(放宽分层约束)。
3.5、应用庞大
分层架构可能会让应用【变得庞大】。
因为即便是一个很简单的功能(比如"Hello World"),在分层架构里你也得写 Controller、Service、Repository、Entity、DTO 等一堆类。这就是所谓的 "样板代码 (Boilerplate Code)" 太多,导致项目臃肿。
四、MVC架构实践
4.1、核心组件定义
Model (模型): 应用程序的主体部分。模型表示 业务数据和业务逻辑 。一个模型能为多个视图提供数据。提高应用的可重用性。
View (视图): 用户看到并与之交互的界面。接收用户输入数据,向用户展示数据。
Controller (控制器): 用户界面与 Model 的接口。解释视图的输入,将其解释为系统能够理解的对象,同时识别用户运作,将其解释为对模型特定方法的调用。处理来自于模型的事件和模型逻辑执行的结果,调用适当的视图为用户提供反馈。
4.2、核心思想
关注点分离 (Separation of Concerns)。
Model 只管数据和逻辑,不关心怎么显示。
View 只管画界面,不关心数据怎么存。
Controller 是协调者,负责转发请求。
"一个模型为多个视图提供数据"的意义: 比如同一份股票数据(Model),既可以用柱状图显示(View A),也可以用表格显示(View B)。数据源只有一份,视图可以多样化,这就是复用。
4.3、J2EE 体系结构中的 MVC 映射
视图 (View): JSP,负责生成 HTML 页面,即视图。
控制 (Controller): Servlet,Java 类,负责接收 HTTP 请求,处理调度,即控制器。
模型 (Model): Entity Bean (实体 Bean) 对应数据库表的一行记录(数据)。Session Bean (会话 Bean) 处理具体的业务逻辑计算(逻辑)。
4.4、MVC 交互流程图
业务处理 选择视图 状态查询 通知新数据更新 把用户输入数据传给 【控制器 Controller】
接收用户请求
调用模型响应用户请求
选择视图显示响应结果 【视图 View】
显示模型状态
接受数据更新请求
把用户输入数据传给
控制器 【模型 Model】
代表应用程序状态
响应状态查询
处理业务流程
通知视图业务状态更新
主动流程(实线): 用户请求 → \rightarrow → Controller → \rightarrow → 调用 Model 业务处理 → \rightarrow → Model 更新。
被动/反馈流程(虚线):
- 选择视图: Controller 处理完后,决定显示哪个 View。
- 状态查询: View 直接向 Model 拿数据来渲染。
- 通知更新: Model 数据变了,主动通知 View 刷新(这是 观察者模式 的体现)。
4.5、优缺点辨析
优点: 耦合性低(View和Model分离)、重用性高、生命周期成本低、部署快。
缺点: 增加了系统结构和实现的复杂性(简单界面没必要用 MVC)、视图对模型数据的访问效率可能较低。
五、MVP 架构实践
5.1、核心定义与优缺点
MVP是MVC的变种,其优点包括:
1)模型与视图完全分离,可以修改视图而不影响模型。
2)可以更高效地使用模型,因为所有交互都发生在一个地方【Presenter】内部。
3)可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑
4)可测试性 (Testability): 如果把逻辑放在Presenter中,就可以脱离用户接口来测试这些逻辑(单元测试)
5)多视图复用: 比如一个"股票行情 Presenter",可以同时服务于"PC端表格视图"和"手机端图表视图",因为逻辑是一样的。
6)
5.2、优化点
MVC 的痛点: 在传统的 MVC 中,View 经常直接读取 Model(比如 JSP 直接读取 JavaBean),导致 View 和 Model 产生耦合。如果要换一套界面(比如从网页换成手机 App),Model 里的很多代码可能要改。
MVP 的解法: MVP 把 Controller 改名为 Presenter(派发器/主持人)。
1)切断联系: Presenter 彻底切断了 View 和 Model 的联系。View 变成了"哑巴"(Passive View),它只负责显示,任何逻辑都交给 Presenter 处理。
2)双向交互: View 和 Presenter 之间、Presenter 和 Model 之间都是双向交互的。
单元测试的神器: 以前测 GUI(界面)很难,需要人工点点点。现在逻辑都在 Presenter 里(这就只是一个普通的 Java 类),写 JUnit 单元测试非常容易。
5.3、MVP 交互流程图
MVP 交互闭环 1: 发起操作 2: 动作通知 3: 更新模型 4: 获取更新数据 5: 模型变更通知 6: 渲染指令 7: 呈现输出 视图 View 派发器 Presenter 模型 Model 用户 User
注意点:
1)Step 2 (View → \to → Presenter): View 接收到用户点击后,不自己处理,而是说:"Presenter,有人点我了,你看着办。"
2)Step 5/6 (Presenter → \to → View): Presenter 拿到 Model 的新数据后,通过接口命令 View:"把文本框 A 的内容改成 X,把按钮 B 变灰。" View 只是听以此执行。
总结: Presenter 是绝对的核心指挥官。
5.4、MVC vs MVP 辨析(必考)
看到 "完全分离" 、"切断 View 和 Model 联系" → \rightarrow → 选 MVP。
看到 "单元测试" 、"脱离用户接口测试" → \rightarrow → 选 MVP。
看到 "Controller" → \rightarrow → 选 MVC ;看到 "Presenter" → \rightarrow → 选 MVP。
六、MVVM 架构实践
6.1、架构组件定义
1)视图、观察者 (View)
2)视图模型 (ViewModel)
3)模型、被观察者 (Model)
6.2、核心进化和区别
MVVM 是从 MVP 进化而来的。
区别是 MVVM 最大的特点是 自动化。
在 MVP 中,Presenter 需要手动调用 View 的接口去更新界面(view.setText(data))。
在 MVVM 中,View 和 ViewModel 之间通过 数据绑定 (DataBinding) 自动关联。ViewModel 的数据变了,View 自动变,不需要写代码去更新 UI。
6.3、MVVM 交互架构图
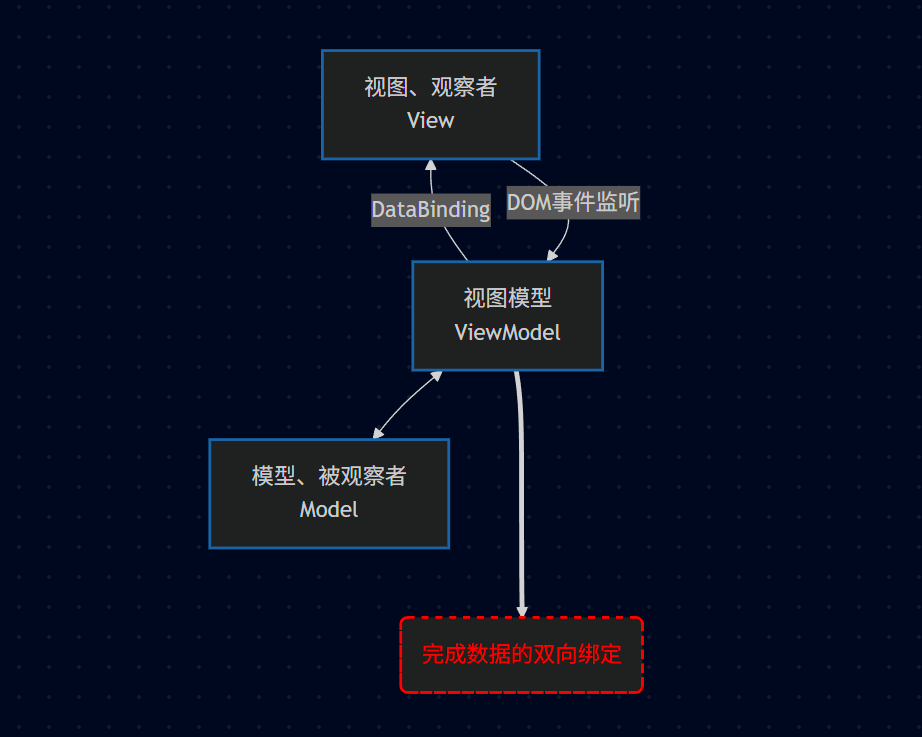
6.4、核心机制
6.4.1、View ↔ \leftrightarrow ↔ ViewModel
DOM事件监听: View 将用户的操作(如点击、输入)传给 ViewModel。
DataBinding: ViewModel 的数据变化自动反映到 View 上。
6.4.2、ViewModel ↔ \leftrightarrow ↔ Model
两者之间进行双向的数据交互和业务处理。
6.4.3、核心目标
完成数据的双向绑定
1)方向 1 (数据 → \to → 视图): 当 Model (或 ViewModel)中的数据发生变化时,View 会自动更新(例如:后台收到新消息,界面自动弹出气泡)。
2)方向 2 (视图 → \to → 数据): 当用户在 View 中进行输入(例如:在输入框打字)时,ViewModel 中的数据变量会自动更新。
典型框架: Vue.js (v-model), React (通过 State 管理), Angular。
七、RIA 架构实践
7.1、RIA 的诞生历程
C/S ⟶ \longrightarrow ⟶ B/S ⟶ \longrightarrow ⟶ RIA (富互联网)
7.2、三种架构模式的客户端对比
1)C/S (Client/Server):【胖】客户端
2)B/S (Browser/Server):【零】客户端
3)RIA (富互联网):【富】客户端,临时下载客户端
7.3、"富"在哪里?
RIA 结合了 C/S 和 B/S 的优点。
像 C/S 一样:有丰富的数据模型和交互体验(拖拽、右键菜单、局部刷新)。
像 B/S 一样:容易部署,通过浏览器访问。
7.4、"临时下载客户端"机制
以前的 RIA 技术(如 Flash/Flex, Silverlight)在用户第一次访问网页时,会下载一个"运行时引擎 (Runtime)"插件。
现在的 RIA(如 React/Vue 单页应用 SPA)则是下载 JavaScript 脚本包,在浏览器里跑出一个"应用"。
7.5、RIA 的核心技术栈
1)Ajax:RIA 的鼻祖技术。实现了"页面不刷新就能更新数据",极大提升了体验。
2)Flex / Flash: 曾经的王者,现已淘汰(Adobe已停止支持)。
3)HTML5: 现在的绝对主流。Canvas、WebSocket、Local Storage 等新特性让网页能做成跟原生 App 一样强大。
4)小程序: 中国特色的 RIA 实现(微信/支付宝小程序),本质上也是基于 Web 技术的变种。
7.6、RIA 的优点
反应速度快: 因为数据传输变少了(只传 JSON 数据,不传整个 HTML 页面),且大部分逻辑在客户端执行(利用了用户电脑的 CPU)。
易于传播: 给个 URL 链接就能用,不需要去应用商店下载安装包。
交互性强: 能够提供接近桌面软件(Desktop Software)的操作体验。
八、UIP框架及动态表现层实践
8.1、UIP 框架
User Interface Components:原来的表现层,用户看到的和进行交互都是这个组件。
User Interface Process Components:这个组件用于协调用户界面的各部分,使其配合后台的活动,例如导航和工作流控制,以及状态和视图的管理。用户看不到这一组件,但是这些组件为 User Interface Components 提供了重要的支持功能。
8.2、核心痛点&解决方案
在复杂的企业级应用中,界面的跳转逻辑(如:购物车的下一步、审批流程的流转)往往非常复杂。如果把这些逻辑写在 View(视图)代码里,代码会乱成一团麻。
解决方案: 剥离控制权。
对应模式: 这其实是 MVC 或 Application Controller 模式的深化应用。
1)Components (视图/View): 只负责"显示"和"接收点击"。
2)Process Components (控制器/Controller): 负责"大脑"。它决定点完按钮后跳到哪一页,当前界面处于什么状态。
8.3、表现层动态生成设计思想
基于 XML界面管理技术 ,包括 【界面配置】 、【界面动态生成】 和 【界面定制】 三部分。
核心理念: 配置优于编码 (Configuration over Coding)。
工作原理: 界面不是程序员一行行代码敲死的,而是存在 XML 配置文件里的。系统运行时,一个"引擎"读取 XML,自动把界面"画"出来。
优势: 修改界面布局、字段标签时,不需要重新编译代码,改 XML 文件即可,灵活性极高。
8.4、架构实践图
可执行文件 界面定制模块(动态) 界面动态生成模块 数据存取类 DOM API 界面配置模块(静态) 数据库 XML配置文件
1)DOM API 的作用: 它是解析 XML 的工具。无论是"动态生成模块"还是"静态配置模块",都需要通过 DOM API 去读取底层的 XML 配置文件。
2)动静分离:
① 静态配置: 这是基础,定义了界面长什么样(XML)。
② 动态定制: 这是扩展,允许在运行时对界面进行微调(Customization)。
3)数据与界面分离: 左边的 数据存取类 负责查 DB,右边的 DOM API 负责查界面配置。两者在 界面动态生成模块 处汇合,最终组装成用户看到的画面。
九、中间层-工作流实践
9.1、核心价值
为什么要用工作流?为了 将业务流程逻辑从代码中剥离出来。流程变了(比如审批多加一级),只需要改流程图(接口1),不需要改代码(接口2/3)。
9.2、核心模块定义
工作流引擎: 创建和管理流程定义。
工作流引擎: 为流程实例提供运行环境,解释执行实例的软件模块。(虚拟机风格)
它是中间层的"心脏"。类似于操作系统调度进程,工作流引擎负责调度业务流程(如:请假审批、订单处理)。
它读取流程定义(XML/JSON),决定下一步该谁处理,状态怎么变。
9.3、五大接口标准
9.3.1、过程定义导入/导出接口
作用:设计图纸怎么传给引擎?(XML/XPDL)。
转换格式和API调用,支持过程定义信息间的互相转换。
连接对象: 过程定义工具 ↔ \leftrightarrow ↔ 工作流引擎。
9.3.2、客户端应用程序接口
用户怎么点"同意/驳回"?
通过这个接口工作流机可以与任务表处理器交互,代表用户资源来组织任务,然后由任务表处理器负责,从任务表中选择、推进任务项,由任务表处理器或者终端用户来控制应用工具的活动。
连接对象: 工作流客户端应用 ↔ \leftrightarrow ↔ 工作流引擎。
9.3.3、应用程序调用接口
流程怎么自动发邮件、写数据库?
允许工作流机直接激活一个应用工具,来执行一个活动。
连接对象: 相关应用 ↔ \leftrightarrow ↔ 工作流引擎。
9.3.4、工作流机协作接口
A公司的引擎怎么把任务转给 B公司的引擎?
使不同开发商 的工作流系统产品相互间能够进行无缝的任务项传递。
连接对象: 其他工作流设置服务器 ↔ \leftrightarrow ↔ 工作流引擎。
9.3.5、管理和监视接口
管理员怎么看流程卡在哪里了?
提供的功能包括用户管理、角色管理、审查管理、资源控制、过程管理和过程状态处理器等。
连接对象: 管理监控工具 ↔ \leftrightarrow ↔ 工作流引擎。
9.3.6、工作流架构图
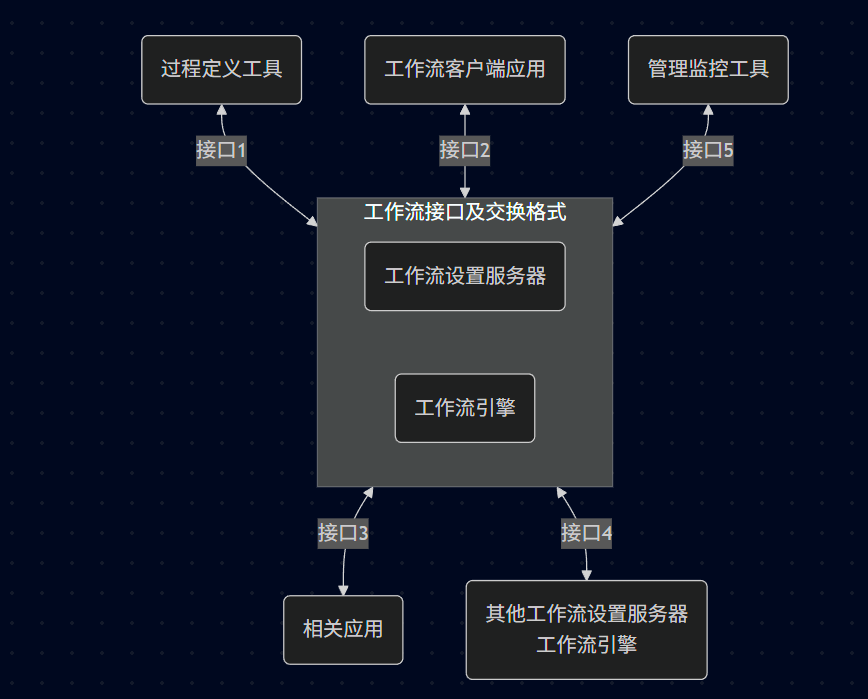
中心化结构: 工作流引擎位于正中心,通过 5 个标准接口连接外部世界(定义工具、客户端、外部应用、其他引擎、监控工具)。
接口4的重要性: 它是解决 异构系统互操作 的关键。如果你的公司收购了另一家公司,两套工作流系统要打通,就靠接口4。
接口2 vs 接口3:接口2 是 人 用的(客户端界面)。接口3 是 机器 用的(自动调用外部程序)。
十、业务逻辑层架构实践
10.1、整体架构分层
整个架构从上至下分为四层流向:
1)表示层: 包含 JSP 、Servlet 、Java应用 、其它客户端。
2)业务层: 核心是 业务容器。
3)持久层 (隐含): 分为 DAO界面 和 DAO执行。
4)数据层: 数据库。
表示层 → 业务需求 \xrightarrow{业务需求} 业务需求 业务层 → \rightarrow → DAO界面 → \rightarrow → DAO执行 → \rightarrow → 数据库
10.2、业务容器内部结构
业务容器 中包含三大核心组件,且存在双向交互关系:
1)DomainModel (领域模型):是核心数据与逻辑的载体。
2)Service (服务):与 DomainModel 和 Control 交互。
3)Control (控制):与 DomainModel 和 Service 交互。
Service ↔ \leftrightarrow ↔ Control: 服务层接收外部请求后,可能需要调用控制层来协调复杂的业务流程;控制层也可能回调服务层的通用接口。
Service/Control ↔ \leftrightarrow ↔ DomainModel: 无论是服务还是控制逻辑,最终都需要操作领域模型(Entity)来完成数据的计算或状态的变更。这是一切业务的核心。
10.3、DAO 层的实践细节
DAO界面 (DAO Interface): 定义了"我们要存取什么数据",但不关心怎么存。业务层只依赖这个接口。
DAO执行 (DAO Implementation): 负责具体的 SQL 语句或 ORM 映射逻辑。
好处: 如果以后换数据库(比如从 MySQL 换到 Oracle),只需要换"DAO执行"层,上面的业务层和 DAO 界面层完全不用动。
10.4、业务逻辑层框架全景图
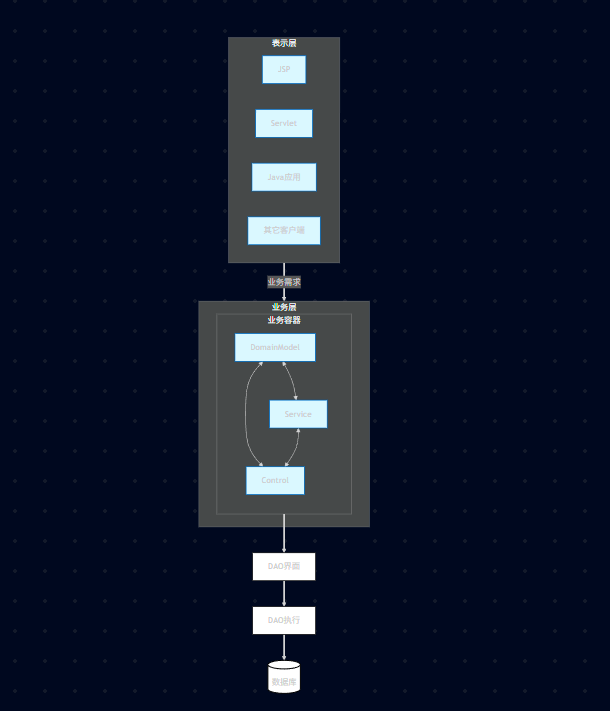
10.5、核心考点
DomainModel (领域模型) 是业务逻辑的核心,不能丢。
Service 和 Control 的分离是为了解耦"接口定义"和"业务流程控制"。
DAO 界面 和 DAO 执行 的分离是为了实现 持久层的独立性(方便换数据库)。
如果在考试的 案例分析题 中看到类似的图:上层是 JSP/Servlet,中间有个容器装着 DomainModel/Service/Control,下面是 DAO 和 数据库 。这是一个典型的 J2EE 分层架构 或 业务逻辑层框架 设计。
十一、5种数据访问模式
11.1、在线访问
特点: 每个数据库操作都会通过数据库连接不断地与后台的数据源进行交互。
场景: 传统的 JDBC 直连模式。
优点: 实时性最强,拿到的永远是最新数据。
缺点: 数据库连接是昂贵资源,如果每个操作都开连接,并发一高,数据库很容易被压垮。通常需要配合 连接池 (Connection Pool) 使用。
11.2、Data Access Object (DAO)
特点: 底层数据访问操作 与 高层业务逻辑 分离。
核心价值: 解耦。
解释: 业务逻辑层(Service)不应该知道你在用 Oracle 还是 MySQL,也不应该看到 SQL 语句。所有这些脏活累活都封装在 DAO 层里。
代码体现: UserDao.findUserById(1)。Service 层只要调用这个方法,不用管里面是 SELECT * FROM 还是调用的存储过程。
11.3、Data Transfer Object (DTO)
特点: 跨不同的进程或是网络的边界来传输数据。
场景: 分布式系统(如 EJB, 微服务)。
痛点: 远程调用(RPC)很慢。如果你要查一个用户的姓名、年龄、地址,不要调三次远程接口 getName(), getAge(), getAddr()。
解法: 在服务端把这些数据打包成一个 DTO 对象 (比如 UserDTO),一次性传给客户端。减少网络调用次数,提升性能。
11.4、离线数据模式
特点: 从数据源获取数据后,存放到本地处理。
典型代表: ADO.NET 中的 DataSet / DataTable,或者现代前端的本地缓存(Local Storage)。
工作流: 连一下数据库 → \rightarrow → 把一堆数据拉到内存里 → \rightarrow → 断开连接 → \rightarrow → 在内存里慢慢改 → \rightarrow → 再连上数据库 → \rightarrow → 批量提交更改。
优点: 减轻数据库连接压力,支持断网操作。
11.5、对象 / 关系映射 (ORM)
特点: 应用系统中的对象与数据库中的数据表形成映射关系。
核心: 解决 阻抗不匹配。
解释: 自动把 Java/C# 对象保存成数据库的行,或者把行转成对象。
通俗理解: 数据库只认"表",代码只认"对象"。ORM 就是一个自动翻译官,让你不用写 INSERT INTO...,直接调用 save(user) 就能存数据。
框架: Hibernate, MyBatis, Entity Framework。它是目前最主流的数据访问模式,通常封装在 DAO 内部使用。
十二、ORM实践
12.1、核心定义
ORM (Object Relational Mapping): 对象与关系数据之间的映射。
12.2、映射关系表
| 面向对象 (Object-Oriented) | <----> | 关系数据库 (Relational Database) |
|---|---|---|
| 类 (class) | ⟷ \longleftrightarrow ⟷ | 数据库的表 (table) |
| 对象 (object) | ⟷ \longleftrightarrow ⟷ | 记录 (record, 行数据) |
| 对象的属性 (attribute) | ⟷ \longleftrightarrow ⟷ | 字段 (field) |
12.3、实现技术对比表
| 维度 | Hibernate | MyBatis (iBatis) |
|---|---|---|
| 简单对比 | 强大,复杂,间接,SQL无关 | 小巧,简单,直接,SQL相关 |
| 可移植性 | 好 (不关心具体数据库) | 差 (根据数据库SQL编写) |
| 复杂多表关联 | 不支持 | 支持 |
Hibernate (全自动 ORM):开发快,甚至一行 SQL 都不用写。适合标准的 CRUD 操作。这是一个黑盒,想优化 SQL 很难。如果你要进行非常复杂的报表统计(多表关联),Hibernate 会很痛苦。
MyBatis (半自动 ORM):SQL 是程序员自己写的(写在 XML 里),完全可控。适合对性能要求高、逻辑复杂的互联网业务。要手写 SQL,换数据库(如 MySQL 切到 Oracle)可能需要改 SQL 语法(移植性差)。
12.4、Hibernate 架构图
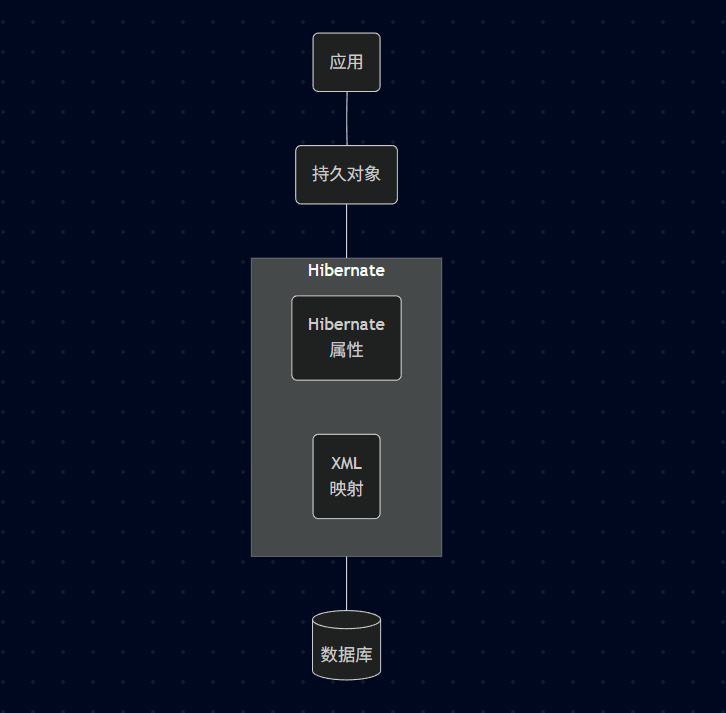
持久对象 (Persistent Object): 就是我们在代码里 new 出来的对象,但在 Hibernate 的管理下,它与数据库的一行记录保持同步状态。
XML 映射 / Hibernate 属性: 这是 ORM 的"字典"和"说明书"。
XML 映射: 告诉框架 User 类对应 t_user 表。
属性: 配置连接哪个数据库、用户名密码等。
12.5、MyBatis 核心架构图
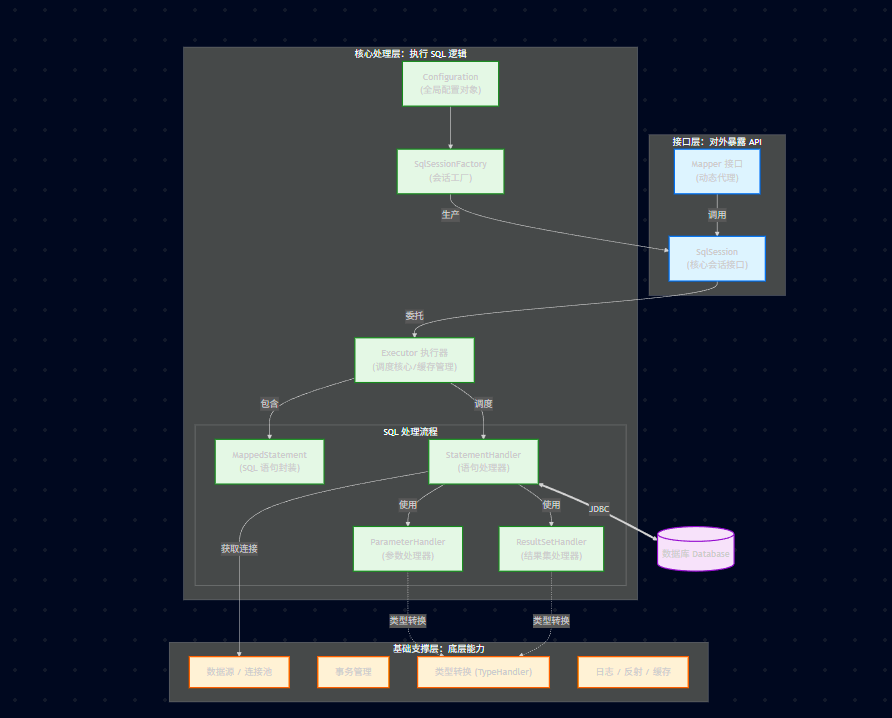
12.5.1、接口层
这是开发者直接交互的层面。
1)SqlSession: MyBatis 对外提供的核心接口。你通过它来执行命令(selectOne, insert, delete 等)、获取 Mapper 和管理事务。
注意: SqlSession 是 非线程安全 的,通常每次 HTTP 请求创建一个,用完即销毁。
2)Mapper (Interface): 开发者编写的 DAO 接口。MyBatis 通过 JDK 动态代理 为这些接口生成代理对象,拦截方法调用并转发给 SqlSession。
12.5.2、核心处理层
这是 MyBatis 的引擎,负责具体的 SQL 解析、执行和结果映射。
1)SqlSessionFactory: 负责创建 SqlSession 的工厂。它是线程安全的,通常一个应用只需要一个单例。
2)Executor (执行器): 最重要的组件。它负责 SQL 语句的生成和查询缓存(一级/二级缓存)的维护。
① SimpleExecutor: 默认执行器,每次执行新建 Statement。
② ReuseExecutor: 重用 JDBC 的 Statement。
③ BatchExecutor: 批量执行。
3)MappedStatement: 每一个 <select>、<insert> 标签(或注解)在内存中就对应一个 MappedStatement 对象。它封装了 SQL 语句、输入参数类型、输出结果映射等信息。
4)**三大 Handler:**底层干活的。
① StatementHandler: 负责创建 JDBC 的 Statement 对象(如 PreparedStatement),是真正与 JDBC API 打交道的组件。
② ParameterHandler: 负责把用户传递的参数转换成 JDBC 能够识别的参数(即负责 SQL 中的 ? 占位符赋值)。
③ ResultSetHandler: 负责把 JDBC 返回的 ResultSet 结果集转换成 Java 对象(List, Map, POJO)。
12.5.3、基础支撑层
这是"后勤部门",提供通用的基础服务。
TypeHandler: 负责 Java 类型(如 java.lang.String)与 JDBC 类型(如 VARCHAR)之间的互转。
DataSource / Transaction: 集成数据源(连接池)和事务管理机制。
Binding: 绑定模块,负责将 Mapper 接口与 SQL 映射文件关联起来。
12.5.4、MyBatis 执行流程总结
1)加载配置: 读取 mybatis-config.xml,构建全局 Configuration 对象。
2)创建工厂: 使用 Configuration 创建 SqlSessionFactory。
3)开启会话: 通过工厂创建 SqlSession。
4)代理调用: 获取 Mapper 接口的动态代理对象,调用接口方法。
5)查询执行:
SqlSession将请求转发给Executor。Executor获取MappedStatement(SQL信息)。StatementHandler创建 JDBC Statement。ParameterHandler设置参数。- 执行 SQL。
ResultSetHandler处理结果集,返回 Java 对象。
6)关闭会话: 释放连接资源。
十三、物联网分层架构实践
13.1、核心架构分层
应用层: 解决信息处理和人机交互问题,应用服务,智能终端。就像人的具体行为。负责具体的业务逻辑(智能家居 App、智慧农业大屏)。
平台层: 操作系统,软件开发,设备管理平台,连接管理平台。就像人的大脑皮层。负责初步处理、设备接入管理(OneNET, AWS IoT)。
网络层: 传递信息和处理信息,网络,通信标准/协议。就像人的神经系统。负责把数据传到大脑(4G/5G, NB-IoT, LoRa)。
感知层: 解决数据获取问题,传感器,芯片,通信模组。就像人的五官(眼睛、耳朵)。负责采集数据(温度、湿度、位置)。
13.2、物联网分层架构实践图
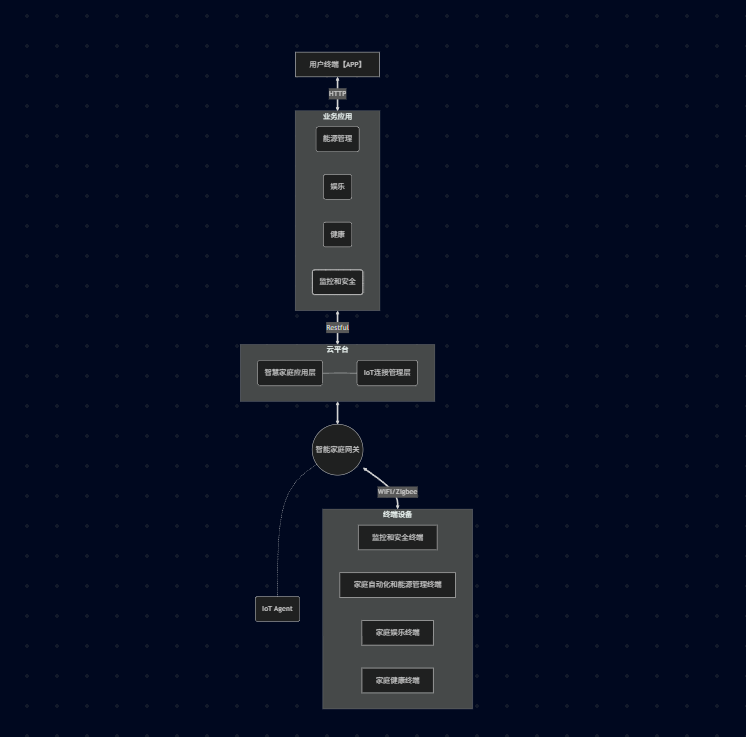
1)通信协议栈
① HTTP: 用于 用户终端 (手机App) 和 业务后台 之间的通信,这是互联网的标准协议。
② Restful: 用于 业务应用 和 IoT 云平台 之间的接口调用。
③ WiFi/Zigbee: 用于 网关 和 底层设备 之间的局域网通信。这是物联网特有的短距离无线通信协议。
2)**智能家庭网关:**它是 感知层 和 网络层 的枢纽。家里的灯泡、门锁(Zigbee设备)不能直接连外网,必须通过网关转换协议。
3)IoT Agent: 部署在网关或设备端的代理程序,负责与云端保持心跳、上传数据、接收指令。
十四、大数据架构实践
14.1、数据应用层
业务应用: 营销支撑、客户洞察(给用户打标签(画像),用于精准推荐)、风险管控(银行查信用卡欺诈、电商查刷单)、运营优化、历史数据查询。
分析应用: 指标应用、报表应用、主题分析、专题分析。
定位: 这是给老板和业务人员看的一层。所有的技术最终都要变成这些"应用"才能产生商业价值。
14.2、数据接口层
分析服务: 基础分析、多维分析、数据挖掘、实时分析、自助分析、数据共享(打通不同部门的数据孤岛)。
技术实现: 数据统一服务和开放 SQL、FTP、WS (Web Service)、MDX (用于 OLAP 多维分析的标准查询语言)、API...
定位: 这是给应用层开发者用的一层。应用层不需要直接连数据库,而是调用这一层的接口。
14.3、数据层
数据仓库: 存的是结构化、清洗后的历史数据(如 Oracle, Teradata, Greenplum)。主要用于做报表(离线分析)。
Hadoop 平台: 存的是海量、非结构化 的数据(日志、图片)。组件: HDFS (存文件), MapReduce/Spark (算数据), Hive (查数据)。
分布式数据库: 解决单机存不下的问题(如 HBase, Cassandra, TiDB)。
14.4、数据采集层
核心功能: 数据采集(数据探头、流数据处理、爬虫)。
批量采集: 对应结构化数据源。Sqoop (数据库 ↔ \leftrightarrow ↔ Hadoop), Kettle (ETL 工具)。
实时采集: 对应半结构化/非结构化数据源。Flume (日志采集), Kafka (消息队列缓冲), Flink/Spark Streaming (流处理)。
爬虫: 从互联网抓取竞对数据。
14.5、数据源
结构化数据 (Structured Data): 核心系统、信贷系统、网上银行、国际结算、其他系统。
半结构化、非结构化数据 (Semi-structured/Unstructured): 外部互联网数据、第三方数据、内部影像、语音。
结构化: Excel 能打开的表(行+列),存在关系数据库里。
半结构化: JSON, XML, HTML, 日志文件。
非结构化: 图片、视频、音频。这是大数据体量最大的一部分。
十五、基于服务的架构 (SOA)
15.1、服务的定义
服务 是一种为了满足某项业务需求的操作、规则 等的逻辑组合,它包含一系列 有序活动 的交互,为实现用户目标提供支持。
核心关键词: 业务需求 。SOA 中的"服务"不是指服务器,而是指 "业务功能"(例如:核对信用卡、预订机票)。
有序活动: 服务不仅仅是一个函数调用,它可能包含一连串的步骤(如:验证 → \to → 扣款 → \to → 发通知)。
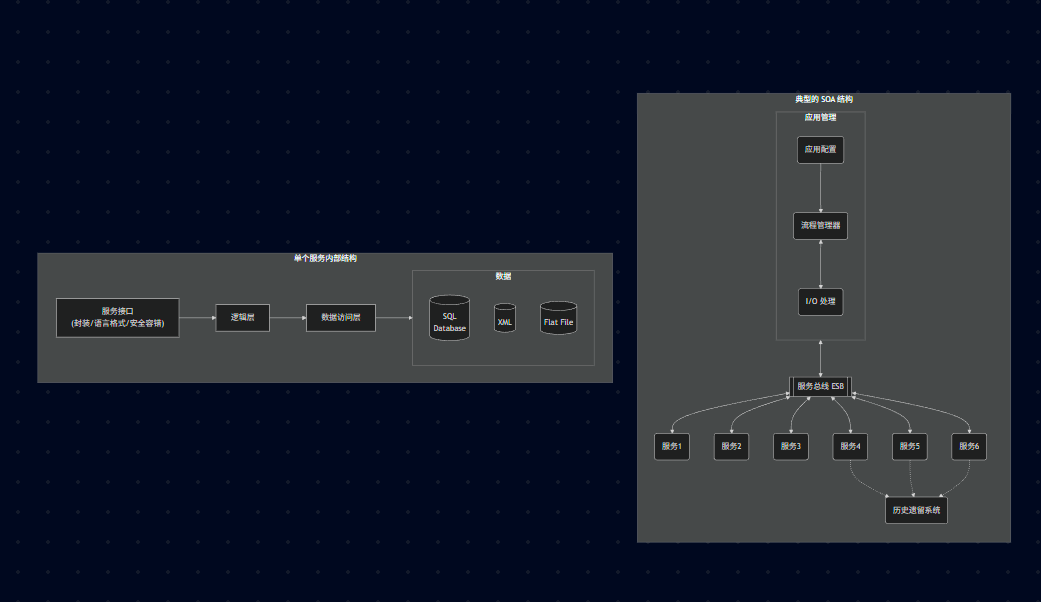
15.2、典型的 SOA 结构
服务总线 (ESB): 核心中枢,连接所有服务。它是 SOA 的心脏。就像电脑的主板总线一样,它负责让不同语言、不同协议的服务互相通信(消息转换、路由、协议适配)。
服务 (Service): 挂载在总线上。
**应用管理:**应用配置、流程管理器、I/O 处理。
历史遗留系统 (Legacy Systems): 被封装成服务接入总线。SOA 的一大功绩就是能把公司里跑了10年的老系统(如 COBOL 主机)包装一下,变成一个现代化的"服务",继续发光发热。
15.3、单个服务内部结构
1)服务接口:共同的封装、共同的语言格式、共同的安全和容错处理
2)逻辑层
3)数据访问层
4)数据 (Data): SQL Database, XML, Flat File。
接口标准化: 这是 SOA 的灵魂。不管内部是用 Java 还是 C# 写的,对外的接口必须是标准的(通常是 WSDL / SOAP)。
黑盒特性: 外部调用者只看到"服务接口",完全不知道里面有逻辑层和数据层。
15.4、SOA 架构图
15.5、SOA 核心特征
15.5.1、SOA 的三大特征
1)松散耦合 (Loose Coupling)
2)粗粒度 (Coarse Grained)
3)标准化接口 (Standardized Interface)
15.5.2、服务 vs 构件 vs 对象
对象 被包裹在 构件 中,构件 被包裹在 服务 中。
✓ \checkmark ✓ 服务构件粗粒度,传统构件细粒度居多。
✓ \checkmark ✓ 服务构件的接口是标准的 ,主要是 WSDL接口,传统构件常以具体API形式出现。
✓ \checkmark ✓ 服务构件的实现与语言无关,传统构件绑定某种特定语言。
✓ \checkmark ✓ 服务构件可以通过构件容器提供QoS的服务,传统构件完全由程序代码直接控制。
| 维度 | 对象 (Object) | 构件 (Component) | 服务 (Service / SOA) |
|---|---|---|---|
| 粒度 | 细 (代码级) | 中 (模块级) | 粗 (业务级) |
| 耦合度 | 紧密 | 较松 | 松散 (Loose) |
| 接口 | 特定语言API | 特定平台API | 标准网络接口 (WSDL/HTTP) |
| 语言相关性 | 绑定 (Java/C++) | 绑定 (EJB/.NET) | 无关 (跨语言) |
十六、Web Service实践
16.1、核心架构
经典的三角色交互模型:
1)服务注册中心 (Service Registry):就像"电话黄页"或"中介"。
2)服务提供者 (Service Provider):就像"修水管的师傅",他把自己的电话(服务地址)登记在黄页上。
3)服务请求者 (Service Requestor):就像"你"。你家水管坏了,你去查黄页,找到师傅的电话,然后直接打电话给他。
16.2、交互动作
1)发布: 服务提供者 → 通过UDDI发布 \xrightarrow{\text{通过UDDI发布}} 通过UDDI发布 服务注册中心
2)查找: 服务请求者 → 通过UDDI查找 \xrightarrow{\text{通过UDDI查找}} 通过UDDI查找 服务注册中心
3)连接/绑定: 服务请求者 ↔ 通过SOAP连接 \xleftrightarrow{\text{通过SOAP连接}} 通过SOAP连接 服务提供者
4)描述: 交互过程中使用 WSDL描述 服务。
16.3、交互流程图
通过UDDI发布 通过UDDI查找 通过SOAP连接
用WSDL描述 服务注册中心 服务提供者 服务请求者
16.4、协议栈
| 功能 | 协议 |
|---|---|
| 发现服务 | UDDI、DISCO |
| 描述服务 | WSDL、XML Schema |
| 消息格式层 | SOAP 、REST |
| 编码格式层 | XML (DOM, SAX) |
| 传输协议层 | HTTP、TCP/IP、SMTP等 |
16.5、UDDI
统一描述、发现和集成协议:负责 "找服务"。目录服务标准。
16.6、WSDL
Web服务描述语言:WSDL 就是 WebService 接口对应的 WSDL 文件。
该文件通过 xml格式 说明如何调用。
可以看作 WebService 的 接口文档(使用说明书)。
**通俗理解:**负责 "懂服务"。它是一个 XML 文件,告诉你这个服务有哪些方法(Method)、入参是什么、返回值是什么。
16.7、SOAP
简单对象访问协议:负责 "传数据"。它是基于 XML 的消息传输协议,比较重(Header + Body)。
16.8、REST (表述性状态转移)
16.8.1、核心定义
REST (Representational State Transfer, 表述性状态转移) 是一种通常使用 HTTP 和 XML 进行基于 Web 通信的技术。
可以 降低开发的复杂性 ,提高系统的可伸缩性。
现代修正: 虽然历史由 XML 起始,但在现代 RESTful API 中,JSON 才是绝对的主流格式,因为它比 XML 更轻量,解析更快。
16.8.2、为什么叫 REST?
资源 (Resource): 网络上的一个实体(如:一张图片、一个用户)。
表述 (Representation): 资源呈现的样子(XML, JSON, HTML)。
状态转移 (State Transfer): 客户端通过 HTTP 动词(GET/POST)让服务器端的资源发生状态变化。
16.8.3、RPC vs REST
传统风格 (面向动作):URL 里包含动词 (addUser, delUser)。HTTP 方法通常只用 GET 或 POST。这使得 URL 很乱,且无法利用 HTTP 协议本身的语义。
添加用户 GET /xisai_api/addUser
删除用户 GET /xisai_api/delUser
修改用户 GET /xisai_api/updateUser
⟶ \qquad\qquad\Huge{\longrightarrow} ⟶ 演进
REST 风格 (面向资源):URL 里只有名词 (User),即资源。动作由 HTTP Method (POST, DELETE, PUT, GET) 来表示。接口统一,URL 简洁,便于缓存(GET 请求可以被 CDN 缓存)。
添加用户 POST /xisai_api/User
删除用户 DELETE /xisai_api/User
修改用户 PUT /xisai_api/User
16.8.4、四大核心概念
资源: 如订单。
表述: 资源某一时间的 状态 ,呈现形式有 HTML、JSON、XML。
状态转移: 使用 GET、POST 等方法。
超链接: 通过超链接可与其它资源联系。这对应一个高大上的术语 ------ HATEOAS (Hypermedia as the Engine of Application State)。通俗理解就是服务器返回的数据里不仅有数据,还应该包含"下一步能做什么"的链接。比如你查了一个订单,返回的 JSON 里应该包含"支付链接"或"取消链接"。
16.8.6、REST 的 5 个原则
1)网络上的 所有事物都被抽象为资源。
2)每个资源对应一个唯一的资源标识 (反过来不成立)。即 URI (统一资源标识符) 。例如 http://api.com/users/1001 就是 ID 为 1001 的用户的唯一标识。
3)通过 通用的连接件接口 对资源进行操作。指的就是 HTTP 标准方法 (GET, POST, PUT, DELETE)。不管操作什么资源,增删改查的方法都是统一的,不需要像 SOAP 那样定义各种复杂的接口。
4)对资源的 各种操作不会改变资源标识。
5)所有的操作都是 无状态的 。 服务器不保存客户端的会话信息(Session)。每次请求都必须带上所有必要信息(如 Token)。这使得服务器可以无限横向扩展(Scalability)。
16.8.7、REST 映射图
读取状态 发送新状态 替换状态 销毁状态 /xisai_api/User
(统一资源标识) GET POST PUT DELETE 查询/获取 创建/添加 修改/更新 删除
十七、ESB (企业服务总线)
17.1、ESB 核心架构图
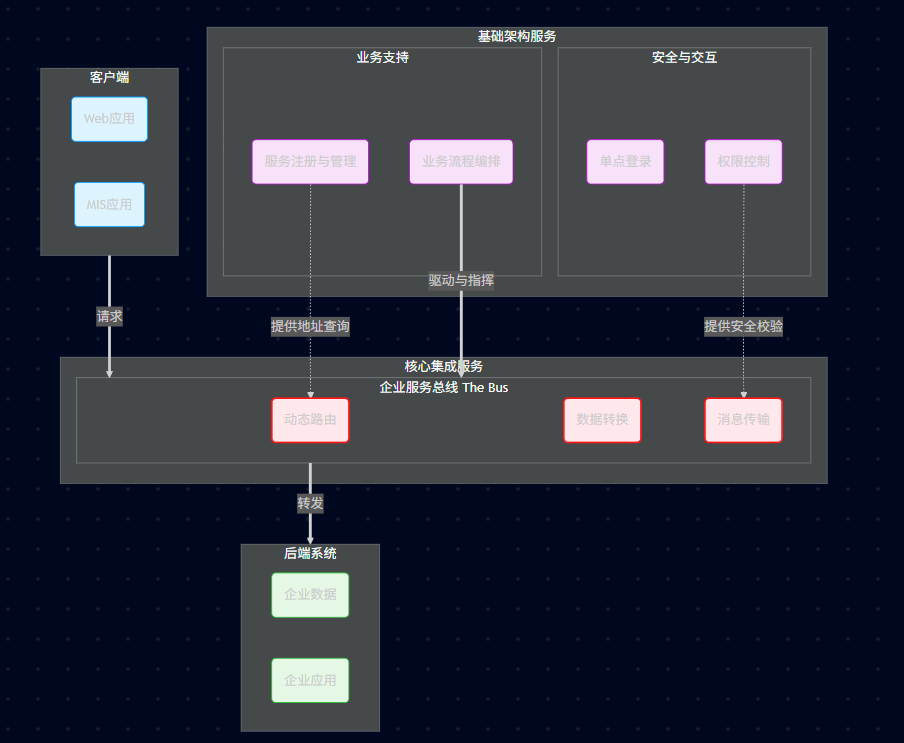
Orchestration (编排) → \to → Bus (总线): 这是一个"指挥"关系。业务流程编排器决定了消息下一步该去哪,它控制着总线中的路由和传输逻辑。
Registry (注册) → \to → Routing (路由): 这是一个"查询"关系。动态路由模块不知道具体的 IP 地址,它必须去询问服务注册中心。
Auth (权限) → \to → Transport (传输): 这是一个"门卫"关系。消息传输之前,必须通过权限验证。
17.2、ESB 的核心功能
✓ \checkmark ✓ 提供 位置透明性的消息路由和寻址服务
✓ \checkmark ✓ 提供 服务注册和命名的管理功能
✓ \checkmark ✓ 支持 多种的消息传递范型
✓ \checkmark ✓ 支持 多种可以广泛使用的传输协议
✓ \checkmark ✓ 支持 多种数据格式及其相互转换
✓ \checkmark ✓ 提供 日志和监控功能
17.3、核心设计目标
服务请求者与服务提供者之间解耦
17.4、关键能力解读
位置透明性: 我(调用者)不需要知道你(服务提供者)的 IP 地址是 192.168.1.1,我只要喊一声"我要查库存",ESB 知道去哪里找。
协议转换: 这是 ESB 的看家本领。客户端发的是 HTTP 请求,后端老系统只支持 Socket 或 FTP?没关系,ESB 帮你转。
**数据格式转换:**客户端发的是 JSON ,后端要 XML?ESB 负责中间的解析和转换。
17.5、ESB vs 微服务网关 (API Gateway)
ESB (SOA时代): 也就是图中的架构。它是 重型 的,逻辑很复杂(包含业务流程编排),强调集中管理。
API 网关 (微服务时代): 它是 轻量 的,主要做路由和鉴权,不包含复杂的业务逻辑(业务逻辑下沉到微服务内部)。
演化: 现在的架构趋势是 去 ESB 化(去中心化),但在很多传统大企业(银行、电信)中,ESB 依然是核心骨架。
十八、微服务实践
18.1、微服务的定义
【微服务】 顾名思义,就是很小的服务,所以它属于 面向服务架构 (SOA) 的一种。
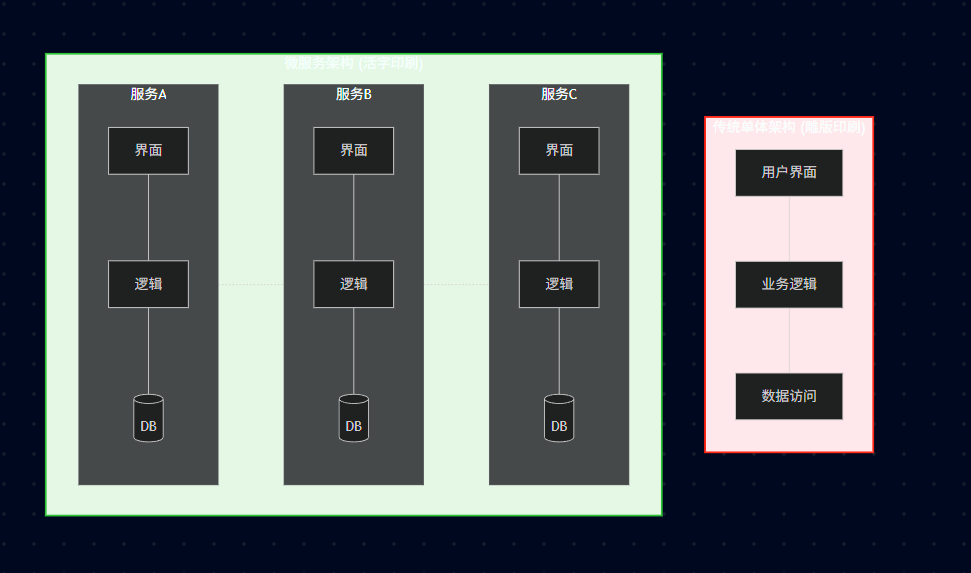
比喻: 雕版印刷 (传统单体架构) VS 活字印刷 (微服务架构)。
活字印刷的精髓: 字(服务)是独立的。如果一个字坏了(服务故障),只需要换这一个字,不需要重刻整版(重启整个系统)。如果某个字用得多(高并发),可以多造几个这个字(独立扩展/副本数增加)。
18.2、架构演进
18.3、微服务 vs SOA (核心辨析)
| 维度 | 微服务 (Microservices) | SOA (面向服务架构) |
|---|---|---|
| 拆分原则 | 能拆分的就拆分 | 是 整体的,服务能放一起的都放一起 |
| 划分方式 | 纵向业务划分 (垂直切分) | 是 水平分多层 (水平切分) |
| 组织架构 | 由单一组织负责 (全栈小团队) | 按层级划分不同部门的组织负责 |
| 粒度 | 细粒度 | 粗粒度 |
| 定义复杂度 | 两句话可以解释明白 | 几百字只相当于 SOA 的目录 |
| 业务形态 | 独立的子公司 | 类似大公司里面划分了一些业务单元 (BU) |
| 组件规模 | 组件小 | 存在较复杂的组件 |
| 逻辑位置 | 业务逻辑存在于每一个服务中 | 业务逻辑横跨多个业务领域 |
| 通信方式 | 使用 轻量级 的通信方式,如 HTTP | 企业服务总线 (ESB) 充当了服务之间通信的角色 |
| 数据治理 | 微服务 提倡 Database per Service (一个服务一个数据库) | SOA 往往共享一个大数据库 |
18.4、去中心化 vs 中心化
SOA 依赖 ESB (企业服务总线) 这个"聪明管道",做路由、转换、编排,很重。
微服务 提倡 "Smart endpoints and dumb pipes" (聪明的端点,愚蠢的管道)。管道只负责传 HTTP 包,业务逻辑都在服务内部。
18.5、微服务的优缺点
18.5.1、优点
1)【复杂应用解耦】: 小服务(且专注于做一件事情),化整为零,易于小团队开发。
2)【独立】: 独立开发、独立测试及 独立部署 (简单部署)、独立运行 (每个服务独立在其独立进程中)。
3)【技术选型灵活】: 支持异构 (如:每个服务使用不同数据库)。
4)【容错】: 故障被隔离在单个服务中,通过重试、平稳退化等机制实现应用层容错。
5)【松耦合,易扩展】: 可根据需求独立扩展。
18.5.2、问题与挑战
1)分布式环境下的 数据一致性 【更复杂】,这是微服务的最大痛点。因为不能用本地事务了,必须引入 CAP 定理 和 BASE 理论。
解决方案: TCC (Try-Confirm-Cancel)、Saga 模式、消息队列最终一致性。
2)测试的复杂性 【服务间依赖测试】
3)运维的复杂性,服务从 1 个变成了 100 个,人管不过来了。
解决方案: 必须引入 DevOps 、容器化 (Docker/K8s) 、服务治理 (Spring Cloud/Istio) 、全链路监控 (SkyWalking)。
18.6、微服务架构模式方案
18.6.1、聚合器微服务
前端一个请求需要调用后端多个服务的数据,为了减少网络交互,由一个"聚合器"统一调用后返回。
客户端 API 网关 聚合器 微服务 A 微服务 B 微服务 C
18.6.2、链式微服务
业务逻辑有严格的顺序依赖。比如:下单 → \to → 扣减库存 → \to → 生成发票。
注意: 链条太长会导致性能下降,且一个环节断了全断(可用性降低)。
客户端 API 网关 微服务 A 微服务 B 微服务 C
18.6.3、数据共享微服务
这是一个反模式 (Anti-pattern) 或 过渡模式。
在纯粹的微服务理论中,尽量避免多个服务读写同一个数据库,因为这造成了紧耦合。通常只在重构遗留系统时暂时使用。
读/写 读/写 读/写 微服务 A 数据库 微服务 B 微服务 C
18.6.4、异步消息传递微服务
流量削峰、解耦。比如:用户注册后,发个消息到队列,积分服务慢慢消费加积分,邮件服务慢慢消费发邮件。
特点: 强一致性转为 最终一致性。
微服务 A 消息队列
Kafka/RabbitMQ 微服务 B
18.7、微服务设计约束
18.7.1、微服务个体约束
每个微服务都是独立的,修改一个微服务不能影响另一个微服务
核心原则: 松耦合 (Loose Coupling) 和 高内聚 (High Cohesion)。
落地技术:独立进程/容器,每个服务跑在自己的 Docker 容器里,互不抢占 CPU/内存。独立代码库,不要搞 Shared Library(共享依赖库)地狱,避免"改一个公共类,炸翻全系统"。
反模式 (考点): 如果你修改服务 A 的代码,被迫必须同时重新部署服务 B,说明违背了此约束。
18.7.2、微服务与微服务之间的横向关系
通过第三方服务注册中心来满足服务的可发现性
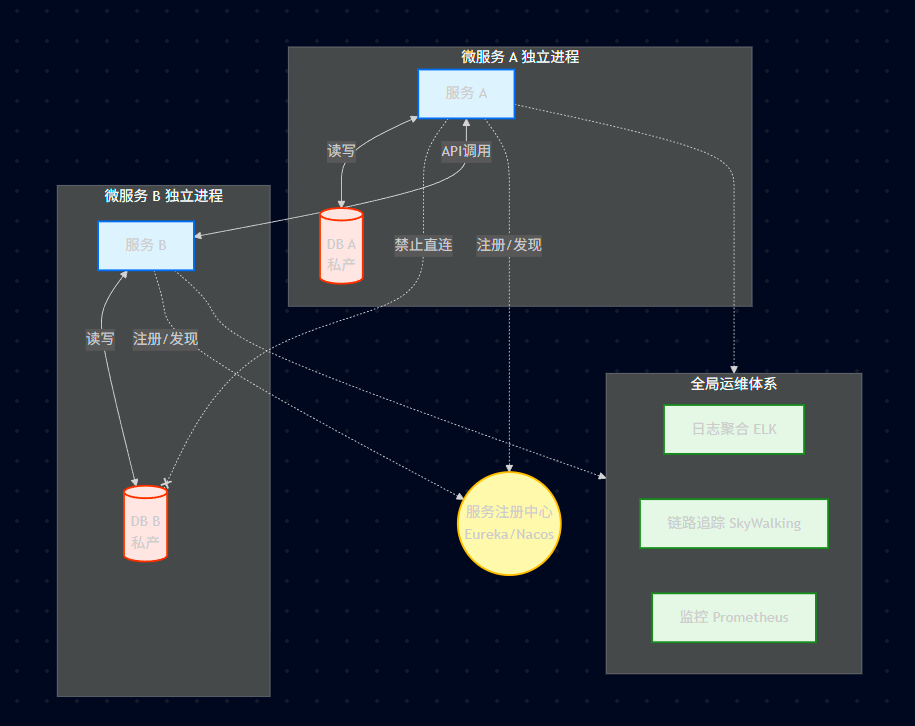
核心机制: 服务注册与发现 (Service Discovery)。
在分布式环境里,服务的 IP 地址是动态变化的(因为扩缩容、故障漂移),不能写死 IP。
架构组件:注册中心 (Registry),比如 Eureka, Nacos, Consul, Zookeeper。心跳机制,服务每隔几秒告诉注册中心"我还活着"。
客户端负载均衡 (Ribbon) 通常配合注册中心使用,从注册表拉取地址列表,然后轮询调用。
18.7.3、微服务与数据层之间的纵向约束
数据是微服务的"私产",访问时需要通过微服务
核心原则: Database-per-Service (一个服务一个数据库)。
严禁行为: 严禁服务 A 直接去连服务 B 的数据库表进行 SQL 查询!这是微服务架构的大忌(数据耦合)。
正确做法: 服务 A 必须调用服务 B 提供的 API 接口 来获取数据。
挑战: 这会导致跨表查询(Join)变难。
解决方案: API 组合 (API Composition) 或 CQRS (命令查询职责分离)。
18.7.4、全局视角下的微服务分布式约束
高效运维整个系统
核心理念: 自动化运维 (Automated Operations)。
技术全家桶 (考点):
1)CI/CD: 自动化构建发布 (Jenkins, GitLab CI)。
2)可观测性:日志聚合 ELK (Elasticsearch, Logstash, Kibana)、链路追踪 SkyWalking, Zipkin、监控报警Prometheus + Grafana。
18.8、微服务架构图
十九、云计算架构
19.1、云计算核心概念
【云计算】 是集合了大量计算设备和资源,对用户屏蔽底层差异的分布式处理架构,其用户与提供实际服务的计算资源是相分离的。
【云计算优点】 超大规模、虚拟化、高可靠性、高可伸缩性、按需服务、成本低【前期投入低、综合使用成本也低】。
核心特征: 看到 "按需自助"、"宽带接入"、"资源池化"、"快速弹性"、"可计量服务" → \rightarrow → 选 云计算。
虚拟化 (Virtualization): 这是云计算的技术基石。没有虚拟化(把一台物理机拆成十台虚拟机),就没有云计算的资源池化。
19.2、服务类型分类
| 类型 | 名称 | 定义/特点 |
|---|---|---|
| SaaS | 【软件即服务】 | 基于多租户技术实现,直接提供 应用程序 |
| PaaS | 【平台即服务】 | 虚拟中间件服务器、运行环境和操作系统 |
| IaaS | 【基础设施即服务】 | 包括 服务器、存储和网络等服务 |
IaaS (买面粉自己做): 云厂商提供机房、服务器、网络(厨房和煤气)。你需要自己装系统、装数据库、部署应用。(比如:阿里云 ECS, AWS EC2)。
PaaS (买速冻披萨自己烤): 云厂商提供操作系统、数据库、开发环境(烤箱)。你只需要写代码(披萨)放上去跑。(比如:Google App Engine, 阿里云 RDS)。
SaaS (去必胜客吃): 云厂商什么都做好了,你直接用软件。(比如:Office 365, CRM 系统, 网盘)。
19.3、部署方式分类
公有云: 面向互联网用户需求,通过开放网络提供云计算服务。
私有云: 面向企业内部提供云计算服务。
混合云: 兼顾以上两种情况的云计算服务。
19.3、混合云典型场景
核心数据(如银行账务) 放在 私有云(为了安全)。
Web 前端/秒杀流量 放在 公有云(为了弹性抗压)。
两者通过专线打通。这是目前大中型企业的主流选择。
19.4、云计算架构图
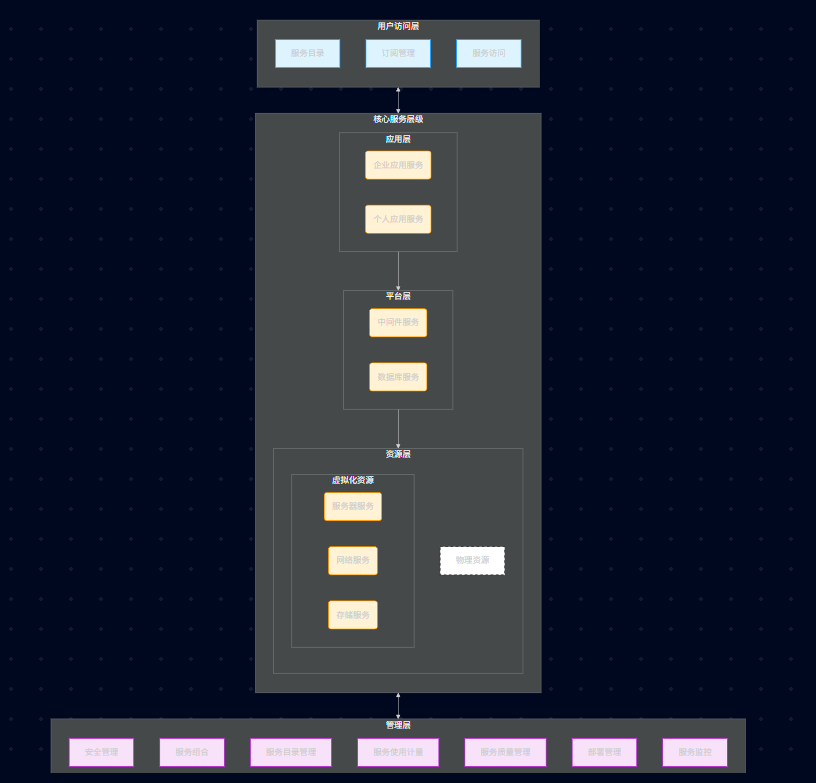
1)管理层 (Management Layer) 的重要性:它是云计算的大脑。没有它,云就是一堆散乱的服务器。云计算像水电一样按量计费,全靠这个模块。保证云服务 99.99% 可用性的关键。
2)资源层 (Resource Layer):核心技术是 Hypervisor (虚拟机监视器),如 KVM, Xen, VMware ESXi。它负责把物理资源抽象成虚拟资源。
二十、云原生
20.1、云原生概念
20.1.1、核心定义
云原生 (Cloud Native)一开始就是基于云环境、专门为云端特性而设计,可充分利用和发挥 云平台的弹性 + 分布式 优势,最大化释放云计算生产力。
20.1.2、本质
本质是 Oncloud ⇒ \Rightarrow ⇒ Incloud
20.1.3、核心公式
云原生 = 微服务 + DevOps + 持续交付 + 容器 ( + 服务网格 Service Mesh)
20.1.4、Oncloud vs Incloud
Oncloud (搬站上云): 只是把传统应用搬到云服务器上运行,没有利用云的弹性(还在用 IP 找机器,手动部署)。
Incloud (生于云长于云): 应用架构天生就是分布式的,利用云的 API 自动扩缩容,容忍基础设施故障。
20.1.5、关键技术四驾马车
微服务: 模块化。
容器 (Docker): 打包与隔离。
DevOps: 开发运维一体化。
持续交付 (CD): 快速迭代。
20.2、云原生操作系统类比
传统: 硬件 → \to → 内核 → \to → 系统服务 → \to → 工具 → \to → 应用。
云原生: IaaS → \to → Kubernetes Core → \to → K8s Resources → \to → 拓展服务 → \to → 云原生应用。
核心观点: Kubernetes (K8s) 就是云时代的操作系统内核 。
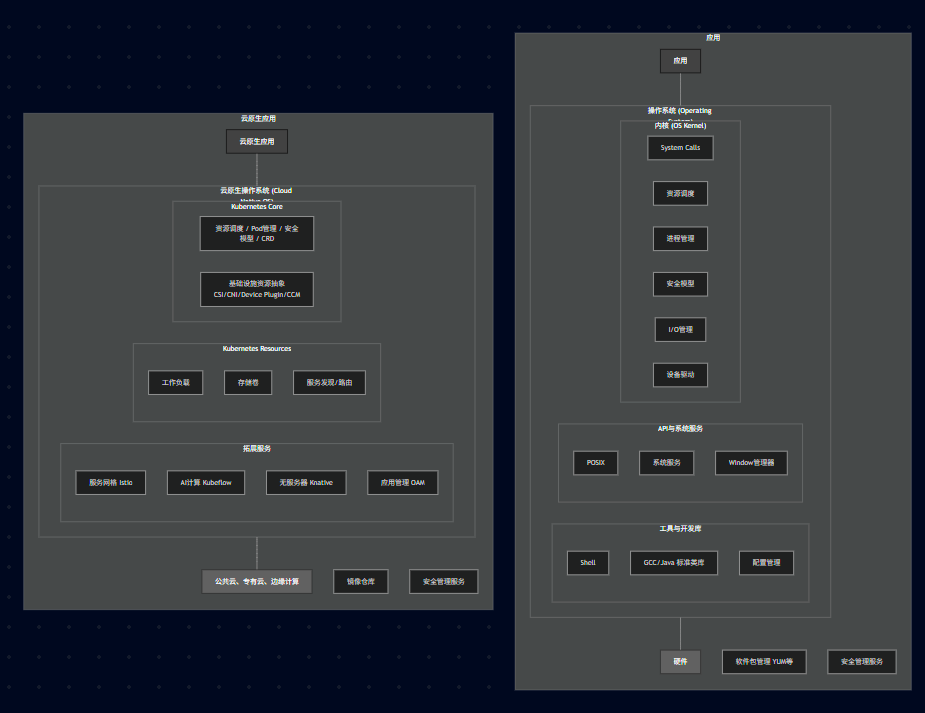
Kubernetes 的地位: 它向下屏蔽了底层硬件(AWS, 阿里云, 物理机)的差异,向上给应用提供统一的 API(Pod, Service, Ingress)。
资源抽象:
1)CSI (Container Storage Interface): 存储接口。
2)CNI (Container Network Interface): 网络接口。
3)这使得 K8s 可以对接任何厂商的存储和网络。
20.3、传统开发 vs 云原生架构
| 维度 | 传统开发 | 云原生开发 |
|---|---|---|
| 开发模式 | 瀑布模式,串行开发 (设计 → \to →开发 → \to →测试 → \to →部署) | 水平切分,并行开发,更敏捷 (DevOps) |
| 技术架构 | 单体架构,耦合性强,灵活性差 (JSP/MVC/Java/Spring) | 纵向切分微服务,横向前后端分离,灵活性高 (Vue/MVVM/SpringBoot) |
| 团队协作 | 一个团队前后端搞定 | 前后端两个团队,约定接口,独立开发 |
| 部署 | 服务器安装部署全部自己搞,耗时费力,容易出错 | 服务开通即用,部署更快,稳定性高,省时省力 |
| 运维 | 实体定位比较明确,对运维技能要求一般 | SDX (软件定义一切),比较抽象,对运维技能要求高 |
SDX (Software Defined X): 软件定义网络(SDN)、软件定义存储(SDS)。云原生环境下,一切基础设施都是代码 (Infrastructure as Code, IaC)。
20.4、云原生架构设计原则
服务化原则: 使用微服务。
弹性原则: 可根据业务变化自动伸缩。
可观测原则: 通过日志、链路跟踪和度量。
韧性原则: 面对异常的 防御能力 。韧性是出了故障能快速恢复 (自带降级、熔断、重试)。和可靠性 不一样,可靠性是不出故障。
所有过程自动化原则: 自动化交付工具。
零信任原则: 默认不信任网络内部和外部的任何人/设备/系统。传统的安全是"边界防御"(外网防住,内网随便跑)。云原生环境 IP 是动态的,必须"永不信任,始终验证",服务A调服务B也要鉴权(如 mTLS)。
架构持续演进原则: 业务高速迭代情况下的架构与业务平衡。
20.5、架构模式演进:从微服务到 Mesh 到 Serverless
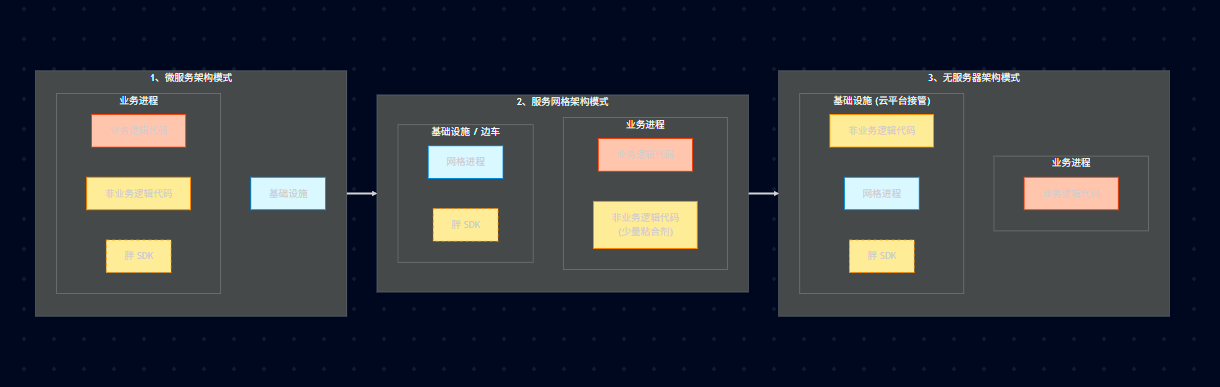
微服务时代 (Fat SDK): 你的代码里引入了大量的 jar 包(Eureka, Ribbon, Hystrix)来处理熔断、服务发现。业务代码和治理代码耦合。
Service Mesh 时代 (Sidecar): 把治理代码剥离出来,做一个独立的代理进程(Sidecar),和业务进程部署在一起。业务代码变轻了。
Serverless 时代: 连 Sidecar 都不用你管了,底层基础设施完全接管,你只写 Function (业务逻辑)。
20.6、云原生架构模式全景
服务化架构模式: 典型代表 【微服务】,服务拆分使维护压力大增。
Mesh 化架构模式: 把中间件框架 (RPC、缓存、异步消息) 从业务进程中分离,由 Mesh 进程完成。
Serverless 模式: 非常适合于事件驱动的数据计算任务。
存储计算分离模式: 各类暂态数据 (如 session) 用云服务保存。
分布式事务模式: 解决微服务模式中多数据源事务问题 (Saga/TCC)。
可观测架构: 包括 Logging, Tracing, Metrics 三个方面。
事件驱动架构 (EDA): 本质上是一种应用/组件间的集成架构模式。
20.7、云原生架构反模式
1)庞大的单体应用:
- 需要多人开发的业务模块,考虑通过服务化进行拆分,并让 组织与架构匹配 (康威定律)。
2)单体应用"硬拆"为微服务 (服务拆分要适度):
- 小规模软件的服务拆分 (为拆而拆)、数据依赖 (服务间数据依赖)、性能降低。
3)缺乏自动化能力的微服务:
- 手动维护大量微服务是不现实的。
分布式单体 (Distributed Monolith): 指的是把代码拆开了,但数据库没拆,或者服务之间耦合极紧,必须要一起部署。这是最糟糕的架构------既没有单体的简单,又没有微服务的灵活,还背上了分布式的性能开销。
二十一、容器技术与 Kubernetes
21.1、容器技术的演进与定义
Docker容器 基于 操作系统虚拟化技术,共享操作系统内核、轻量、没有资源损耗、秒级启动,极大提升了系统的应用部署密度和弹性。
21.2、部署模式演进对比图
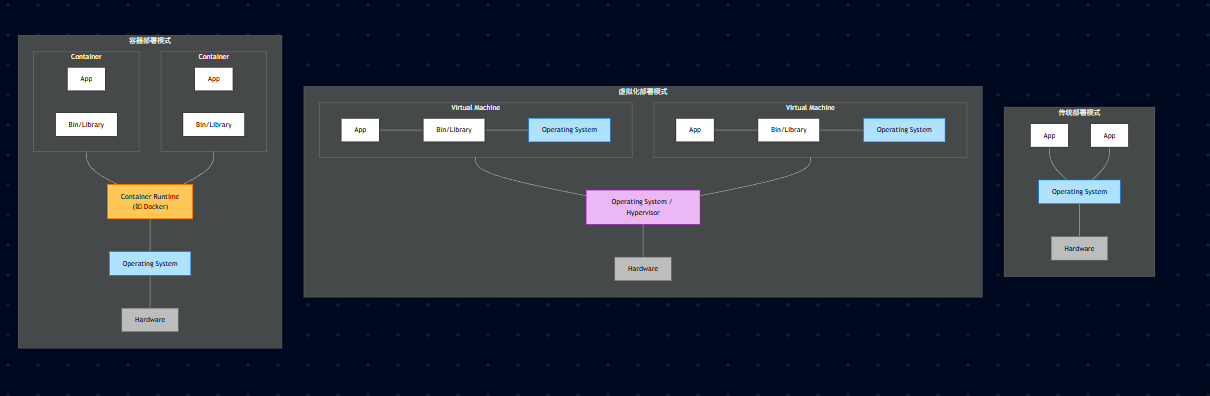
21.3、本质区别
虚拟机 (VM): 是 Hypervisor 层面的虚拟化。每个 VM 都有一个完整的 Guest OS(客户操作系统),所以重、启动慢。
容器 (Container): 是 内核 (Kernel) 层面的虚拟化。所有容器共享宿主机的 OS 内核,只是通过 Namespace (命名空间) 做隔离,通过 Cgroups (控制组) 做资源限制。
启动为什么快? 容器启动本质上就是启动一个进程,不需要像虚拟机那样经历 BIOS 自检、Bootloader 加载、内核初始化等漫长过程。
21.4、镜像分层
Docker 镜像采用分层存储(Union FS),多个容器可以共享底层的只读层,节省存储空间。
21.5、虚拟机技术 vs 容器技术
| 对比项 | 虚拟机技术 | 容器技术 |
|---|---|---|
| 镜像大小 | 包含GuestOS,G量级以上 | 仅包含运行的 Bin/Lib,M量级 |
| 资源要求 | CPU与内存按核、按G分配 | CPU与内存按单核、低于G量级分配 |
| 启动时间 | 分钟级 | 毫秒级 |
| 可持续性 | 跨物理机迁移 | 跨操作系统平台迁移 (Write Once, Run Anywhere) |
| 弹性伸缩 | VM伸缩,CPU/内存手动伸缩 | 实例自动伸缩、CPU内存自动在线伸缩 |
| 隔离策略 | 操作系统、系统级别 (强隔离) | Cgroups,进程级别 (软隔离) |
21.6、隔离性差异
虚拟机拥有独立的内核,隔离性更强,安全性更高(适合公有云多租户)。
容器共享内核,如果内核崩溃,所有容器都会挂掉;且存在容器逃逸风险(适合公司内部微服务)。
21.7、Kubernetes (K8s) 核心能力
Kubernetes 提供了分布式应用管理的核心能力。
1)【资源调度】 根据请求 资源量 在集群中选择 合适的节点 来运行应用。
2)【应用部署与管理】 支持应用的 自动发布 与应用的 回滚。
3)【自动修复】 当宿主机或者OS出现故障,节点健康检查 会 自动进行应用迁移 (Reschedule)。
4)【服务发现与负载均衡】 结合 DNS 和负载均衡机制,支持容器化应用之间的相互通信。
5)【弹性伸缩】 可以对这个业务进行 自动扩容 (HPA)。
6)【声明式 API】 开发者可以关注于应用自身,而非系统执行细节。
通俗理解:"我期望这个服务有 3 个副本" (K8s 自己去对比现状,自动调整)。这是 K8s 自动化的基石。
命令式则是需要指定明确命令比如"把这个服务扩容到 3 个副本" (如果现在是 2,加 1;如果现在是 4,减 1)。
7)【可扩展性架构】 所有 K8s 组件都是基于一致的、开放的 API 实现和交互。
K8s 为了不被特定厂商绑定,定义了标准接口。
① CNI: 网络插件 (Calico, Flannel)。
② CSI: 存储插件 (Ceph, NFS, AWS EBS)。
③ CRI: 容器运行时接口 (Docker, Containerd)。
8)【可移植性】 K8s 通过一系列抽象如 Load Balance Service (负载均衡服务)、CNI (容器网络接口)、CSI (容器存储接口),帮助业务应用可以屏蔽底层基础设施的实现差异,实现容器灵活迁移的设计目标。
9)**【Pod】**最小调度单位, K8s 调度的原子单位不是容器,而是 Pod。一个 Pod 可以包含多个容器(Sidecar 模式的基础)。
二十二、边缘计算
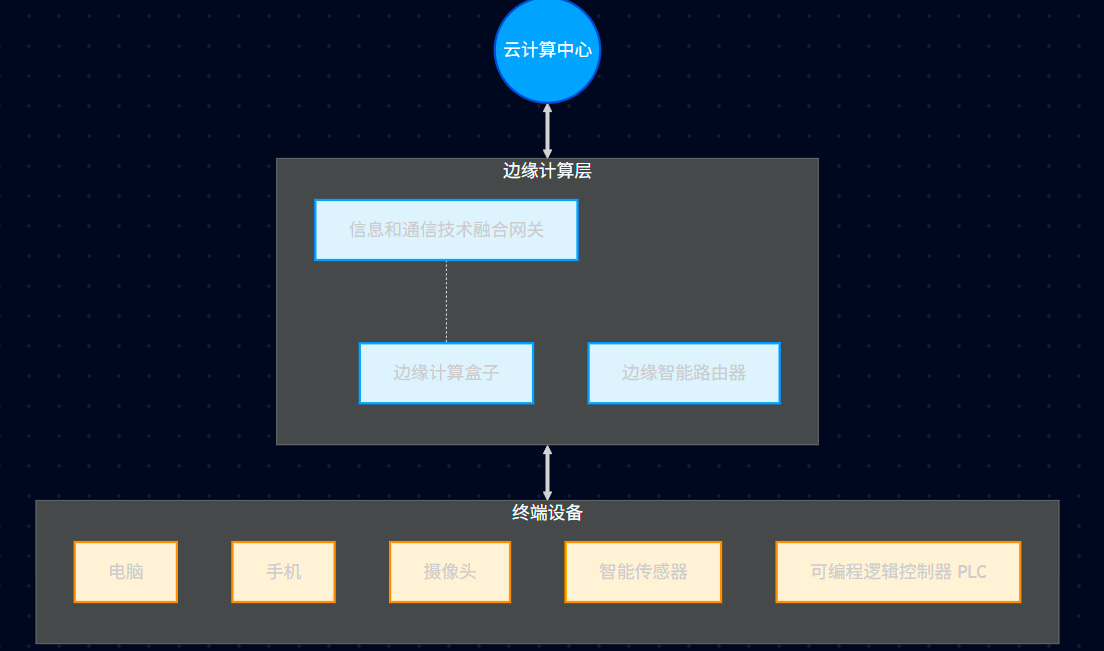
22.1、边缘计算的定义
【边缘计算】 是指在靠近 物或数据源头 的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。
【边缘计算的本质】 计算处理职能的本地化。
22.2、边缘计算类型
【云边缘】 云服务在边缘侧的延伸。
【边缘云】 在边缘侧构建中小规模云服务能力。
【边缘网关】 以云化技术与能力重构原有嵌入式网关系统。
22.3、边缘计算生态架构图
22.4、解决核心痛点&方案
如果所有数据(如自动驾驶的实时路况、工厂的高清监控)都传到云端处理,会有两个致命问题:
1)延迟 (Latency): 数据传输距离太远,来不及刹车。
2)带宽 (Bandwidth): 海量视频数据会把网络塞爆。
解决方案: 让数据在"家门口"(边缘网关/边缘服务器)就处理掉,只把结果传给云端。
22.5、云-边-端 三层架构
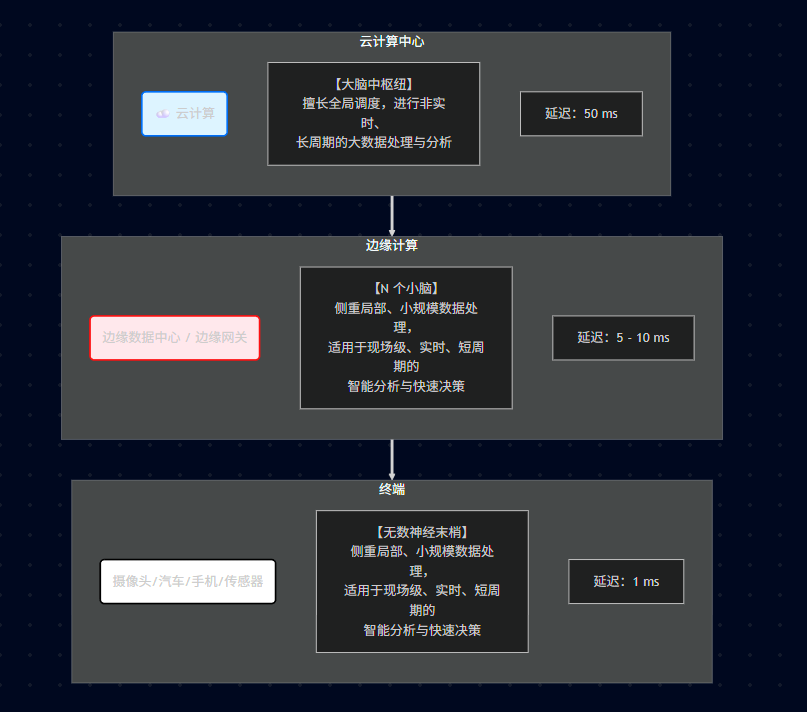
22.6、边云协同的六大分类
【资源协同】 边缘节点有 基础设施资源 的调度管理能力,可与云端协同。
【数据协同】 边缘节点采集 数据 并初步分析,再发给云端做进一步处理。
【智能协同】 分布式智能,云端做 集中式模型训练,再将模型下发到边缘节点。
1)云端 (训练 Training): 使用海量历史数据,利用强大的 GPU 集群训练出一个 AI 模型(比如人脸识别模型)。
2)边缘端 (推理 Inference): 摄像头或边缘盒子里装着这个训练好的模型,实时识别路过的人脸。
3)闭环: 边缘端遇到识别不准的图片,上传回云端,云端重新训练优化模型,再推送到边缘端更新。这就是智能协同。
【应用管理协同】 边缘节点提供应用 部署与运行环境 ,云端主要提供应用 开发、测试环境。
【业务管理协同】 边缘节点提供模块化、微服务化的应用/数字孪生/网络等 应用实例 ;云端主要提供按照客户需求实现应用/数字孪生/网络等的 业务编排能力。
【服务协同】 边缘节点按照云端策略实现部分 ECSaaS 服务,通过 ECSaaS 与云端 SaaS 的协同实现面向客户的按需 SaaS 服务;云端主要提供 SaaS 服务在云端和边缘节点的服务分布策略,以及云端承担的 SaaS 服务能力。
二十三、大型网站系统架构演化
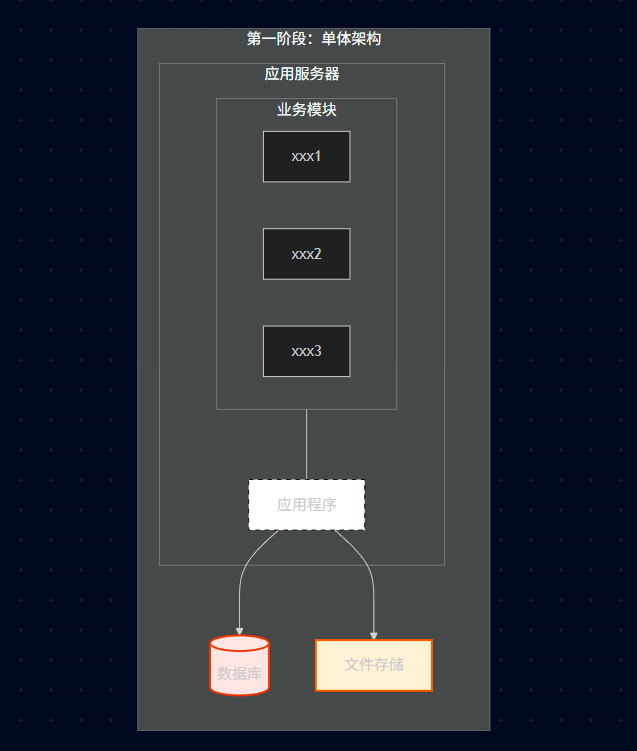
23.1、第一阶段:单体架构
23.1.1、架构特征
应用服务器:包含所有业务模块。
数据库:单一数据库存储所有表。
文件服务器:存储文件。
关键点: 应用程序、数据库、文件都在一个"大盒子"里或者紧密耦合。
23.1.2、单体架构图
23.1.3、适用场景
创业初期,流量小,开发人员少(1-3人)。
23.1.4、优点
开发简单: 所有代码在一个项目里,IDE 打开直接干。
部署简单: 只要把一个 WAR/JAR 包扔到 Tomcat 里就完事了。
测试简单: 不需要模拟网络延迟,没有分布式事务烦恼。
23.1.5、缺点 (演化的动力)
耦合度太高: 改一个"xxx1模块"的小 Bug,可能导致"xxx2模块"挂掉。
扩展性差: 只能整体扩容(垂直扩展),不能只扩容"xxx1模块"。
技术栈受限: 必须用同一种语言(全家桶)。
23.2、第二阶段:垂直架构
23.2.1、架构特征
应用服务器:独立部署。
数据库服务器:独立部署。
文件服务器:独立部署。
23.2.2、垂直架构图
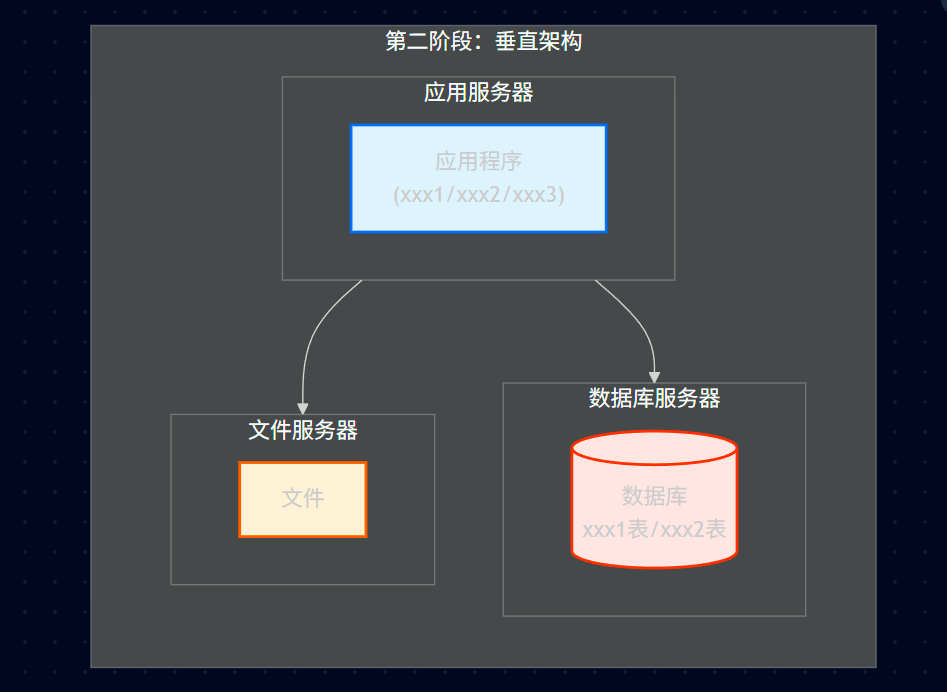
演化核心: 物理分离 (Physical Separation)。
23.2.3、解决痛点
资源争用: 以前应用跑满 CPU,数据库就没 CPU 用了。现在应用吃 CPU,数据库吃内存/磁盘 I/O,互不干扰。
单点故障风险降低: 虽然应用挂了还是全挂,但至少数据库不会因为应用内存溢出而被拖死。
23.2.4、缺点(演化的动力)
随着用户量增加,单台 应用服务器 处理不过来了(并发连接数瓶颈)。
单台 数据库服务器 读写压力太大了(I/O 瓶颈)。
23.3、第三阶段:引入缓存
23.3.1、核心变化
在应用服务器和数据库之间,加了一层(或多层)缓存。
23.3.2、缓存位置
本地缓存: 存在于应用服务器内存中。
分布式缓存服务器: 独立的服务器集群(分布式缓存服务器1...n)。
23.3.3、缓存融合架构图
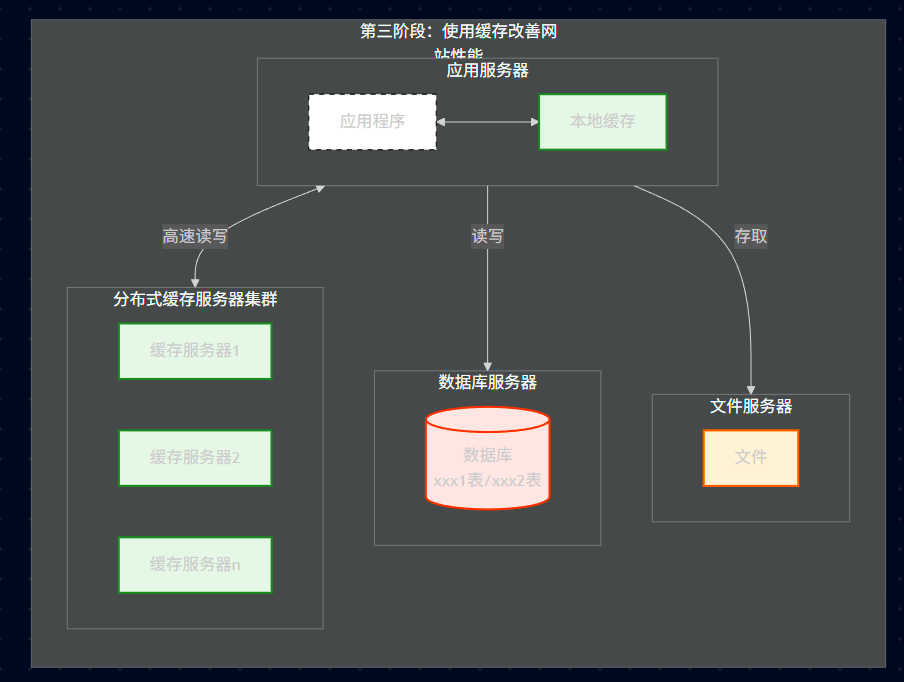
为什么要加缓存?
依据 "二八定律",80% 的业务访问集中在 20% 的热点数据上(如首页热帖、热门商品)。
策略: 把这 20% 的热点数据放在内存(缓存)里,数据库只承担剩下的冷数据查询和写操作,性能瞬间提升几倍甚至几十倍。
23.3.4、常见缓存技术选型
MemCache: Memcache是一个高性能的分布式的内存对象缓存系统,用于动态Web应用以减轻数据库负载。Memcache通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。
Redis: Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Squid: Squid是一个高性能的代理缓存服务器,Squid支持FTP、gopher、HTTPS和HTTP协议。
23.3.5、缓存读写与数据一致性
23.3.5.1、数据读取流程
1)根据 key 从 缓存读取。
2)若缓存中没有,则根据 key 在 数据库 中查找。
3)读取到"值"之后,更新缓存 。
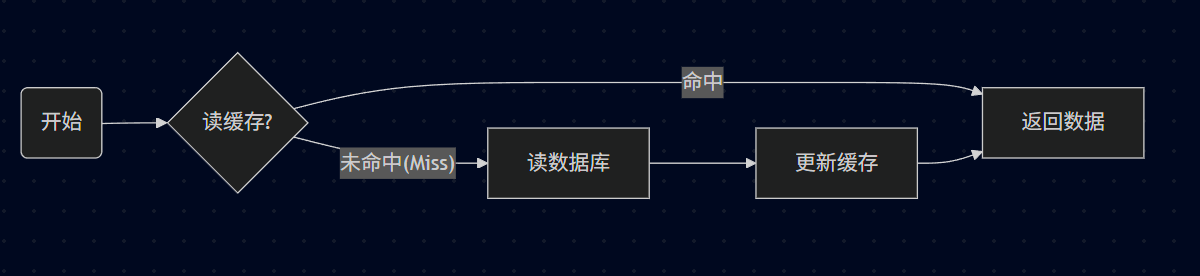
23.3.5.2、数据写入流程
1)根据 key 值 写数据库。
2)根据 key 更新缓存 【或删除缓存】。
先删缓存: A删了缓存 → \to → B来读(发现没缓存,读旧DB,写回旧缓存) → \to → A改新DB。结果:缓存里永远是旧数据。
先改DB: A改DB → \to → A删缓存。虽然中间有极短时间不一致,但最终一致性更有保障。
23.3.5.3、更新缓存 vs 删除缓存
选删除,如果你每次改数据库都去更新缓存,万一你改了10次数据库,但期间一次读请求都没有,那前9次计算缓存都是浪费。而且并发写时,"更新"容易导致脏数据。直接"删除",下次读取时自然会回填最新数据(懒加载)。
23.3.5.4、延时双删
先删缓存 → \to → 改DB → \to → 休眠 1秒 → \to → 再删缓存。
23.3.6、MemCache vs Redis
| 对比维度 | MemCache | Redis |
|---|---|---|
| 数据类型 | 简单 Key/Value 结构 | 丰富的数据结构 (String, List, Hash, Set, ZSet) |
| 持久性 | 不支持 (断电即失) | 支持 (RDB 快照 / AOF 日志) |
| 分布式存储 | 客户端哈希分片 / 一致性哈希 (服务端彼此不通信) | 多种方式:主从 (Master-Slave)、哨兵 (Sentinel)、集群 (Cluster) 等 |
| 多线程支持 | 支持 (多线程架构,适合多核 CPU) | 支持 (注:Redis 5.0 及以前版本核心是单线程,6.0 引入多线程 I/O) |
| 内存管理 | 私有内存池 / 内存池 (Slab Allocation) | 无 (主要依赖系统 malloc/free,常用 jemalloc) |
| 事务支持 | 不支持 | 有限支持 (通过 MULTI/EXEC 实现,非强 ACID) |
| 数据容灾 | 不支持,不能做数据恢复 | 支持,可以在灾难发生时恢复数据 |
1)MemCache
是真正的多线程。它使用"主线程监听 + Worker 子线程处理"的模式。
优势: 可以充分利用多核 CPU 的计算能力,在存储极小数据(<100字节)的高并发场景下,吞吐量可能比 Redis 更高。
劣势: 存在锁竞争。
Memcached 的分布式是"伪分布式": 服务器端之间互不通信。全是客户端在忙活(客户端算好 Key 对应的服务器 IP,直接连过去)。
缺点: 扩容时如果用简单的取模哈希,命中率会暴跌(所以要用一致性哈希)。
2)Redis
核心逻辑是单线程的: 命令执行(读写内存)永远串行,所以没有锁竞争,原子性好,开发简单。
I/O 是多线程的 (Redis 6.0+): 指 Redis 6.0 以后引入了多线程来处理网络 I/O (读写 Socket),因为 Redis 的瓶颈通常在网络带宽而非 CPU 计算。
Redis Cluster 是"真分布式": 服务端之间通过 Gossip 协议 互相通信,交换状态。客户端连任何一个节点,如果不归这个节点管,它会告诉你"去连 IP:Port,那个数据在它那儿"。
23.3.7、Redis 分布式存储方案
23.3.7.1、三种方案核心特点对比
| 分布式存储方案 | 核心特点 |
|---|---|
| 主从 (Master/Slave) 模式 | 一主多从,故障时手动切换 |
| 哨兵 (Sentinel) 模式 | 有哨兵的一主多从,主节点故障自动选择新的主节点 |
| 集群 (Cluster) 模式 | 分节点对等集群,分 slots,不同 slots 的信息存储到不同节点。 |
23.3.7.2、主从 (Master/Slave) 模式架构
主从 (Master/Slave) 模式 Web 集群 写/同步 读 读 异步复制 异步复制 Master Slave Slave Web
集群
主从模式 解决了什么?解决了读写分离 和数据备份。Master 负责写,Slave 负责读。
缺点: Master 挂了,整个集群就不能写了,需要人肉运维去把 Slave 提拔成 Master,可用性低。
复制机制: Redis 默认采用异步复制。Master 收到写命令后,先自己执行,再发送给 Slave,不等 Slave 确认就给客户端返回 OK。这意味着如果 Master 突然宕机,可能会丢失少量数据。
23.3.7.3、哨兵 (Sentinel) 模式架构
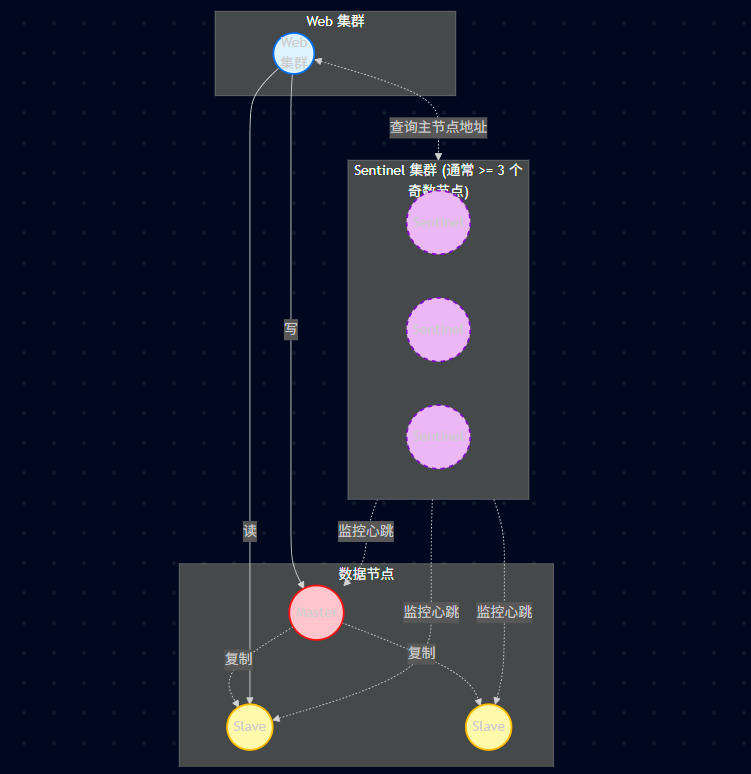
客户端连接谁? 客户端不直接连 Master,而是连接 Sentinel 集群。先问 Sentinel:"谁是现在的 Master?",拿到 IP 后再连 Master。这样当故障切换后,客户端能感知到新的 Master。
哨兵节点数量: 必须是奇数个(至少 3 个),以满足 Raft 协议的多数派投票机制,防止"脑裂"导致无法选主。
哨兵模式 解决了什么?解决了主从模式的自动化故障转移 (Failover) 。引入了"哨兵"这个第三方观察员,盯着 Master,挂了就自动选个新的。是高可用 (HA) 方案。
缺点: 写操作的性能瓶颈还在单一的 Master 上,不能实现水平写扩展。
23.3.7.4、集群 (Cluster) 模式架构
集群 (Cluster) 模式 分片 1 (Slots 0-5460) 分片 2 (Slots 5461-10922) 分片 3 (Slots 10923-16383) Web 集群 写/读 (根据 CRC16(key) 路由) Node3
Master Slave Node2
Master Slave Node1
Master Slave Web
集群
Slot (槽): Redis Cluster 把所有数据划分为 16384 个 slot。
数据路由算法: slot = CRC16(key) % 16384。客户端算出 key 属于哪个 slot,然后直接连接负责该 slot 的 Master 节点进行操作。
- 集群模式 解决了什么?解决了哨兵模式的写瓶颈,实现了水平扩展 (Scale Out)。数据分片存在不同的节点上,多个节点可以同时提供写服务。
23.3.8、Redis 集群切片(分片)方式
23.3.8.1、客户端分片
原理: 还没出门(发请求),就在自家(客户端 SDK)算好了该去哪。
特点: Redis 实例之间互不认识。
Redis 服务器组 Hash(key) % 3 = 0 Hash(key) % 3 = 1 Hash(key) % 3 = 2 Redis 1 Redis 2 Redis 3 客户端 App
23.3.8.2、中间件分片
原理: 找个中介(Proxy)。客户端只管发给中介,中介负责分发。
特点: 客户端觉得后面只有一个巨大的 Redis。
Twemproxy (推特开源):轻量级,但不支持在线平滑扩容(加节点需要重启,或者很麻烦)。
Codis (豌豆荚开源):在Twemproxy基础上增加了 GUI 界面,支持在线动态扩容(这是它当年打败 Twemproxy 的杀手锏)。
Redis 服务器组 所有请求 路由 路由 路由 Redis 1 Redis 2 Redis 3 客户端 App 中间件 Proxy
(Twemproxy/Codis)
23.3.8.3、服务端协作分片
原理: 到了服务端,发现走错了,服务端给你指路(Redirect)。
特点: 官方原生方案,去中心化。
Redis Cluster 官方标准实现 其实使用的是 Hash Slot (哈希槽)。
槽数量: 16384 个 (0 ~ 16383)。
分片算法: Slot = CRC16(key) % 16384。
为什么是 16384?
因为 Redis 节点间通过 Gossip 协议交换状态,心跳包头如果不压缩,使用 bitmap 表示 16384 个槽需要 2KB 大小,这个大小在局域网内是合理的。如果槽太多(比如 65536),心跳包太大,会造成网络拥堵。
去中心化: 集群中每个节点都是平等的,都知道整个集群的 slot 分布情况。客户端连任意一个节点,如果 key 不归它管,它会返回一个 MOVED 错误,告诉客户端正确的节点地址。
MOVED 错误: 永久重定向。意思是"这个槽以后都归 Node B 管了,你以后直接找它,别来烦我"。(客户端会更新本地的 Slot 映射表)。
ASK 错误: 临时重定向 。意思是"这个槽正在迁移中,数据可能在 Node B,你先去 Node B 问问,但下次如果不确定还在不在,还是先来问我"。(客户端不会更新本地映射表)。
Redis Cluster 1、Set Key (CRC=100) 2、Set Key (CRC=8000) 3、MOVED 8000 NodeB 4、重定向到 NodeB Node A
Slot: 0-5000 Node B
Slot: 5001-10000 客户端 App
23.3.9、Redis 数据分片方式
23.3.9.1、三种核心分片算法对比
| 分片方案 | 分片方式 | 说明 |
|---|---|---|
| 范围分片 (Range Partitioning) | 按数据范围值来做分片 | 例:按用户编号分片,0-999999 映射到实例A ;1000000-1999999 映射到实例B。 |
| 哈希分片 (Hash Partitioning) | 通过对key进行hash运算分片 | 可以把数据分配到不同实例,这类似于 取余操作 ,余数相同的,放在一个实例上。 |
| 一致性哈希分片 (Consistent Hashing) | 哈希分片的改进 | 利于扩展结点,可以有效解决重新分配节点带来的无法命中问题。 |
23.3.9.2、范围分片
【定义】 按照数据范围值来做分片。
【核心逻辑】 就像查字典或电话簿,数据是有序排列的。系统维护一张全局的路由表,记录每台服务器负责的 ID 范围。
范围分片示意图 存储节点 路由规则: 根据 ID 大小范围分发 User ID: 500 User ID: 150000 User ID: 999999 Node_0
ID < 100000 Node_1
ID < 200000 Node_2
ID < 300000 Node_3
其它 / >300000
典型场景: 课件中举例"按用户编号分片"。实际应用中,还常用于按时间范围分片(如:1月的日志存 Node A,2月的日志存 Node B)。
支持范围查询 (Range Scan): 如果业务经常查"ID 1000 到 2000 之间的所有用户",这种方案极快,因为它们大概率在同一台机器上,不需要跨机器聚合。
扩容简单: 只需要添加新节点负责新的范围(如 Node 4 负责 ID > 400000),旧数据不需要迁移。
数据热点 (Hotspot): 如果 ID 是自增的,那么最近注册的用户(ID 最大)读写最频繁,所有压力都会打在最后一个节点上,其他节点围观。
23.3.9.3、哈希分片
【定义】 通过对 key 进行 hash 运算分片。
【核心逻辑】 就像发扑克牌。把数据分配到不同实例,这类似于 取余操作,余数相同的,放在一个实例上。
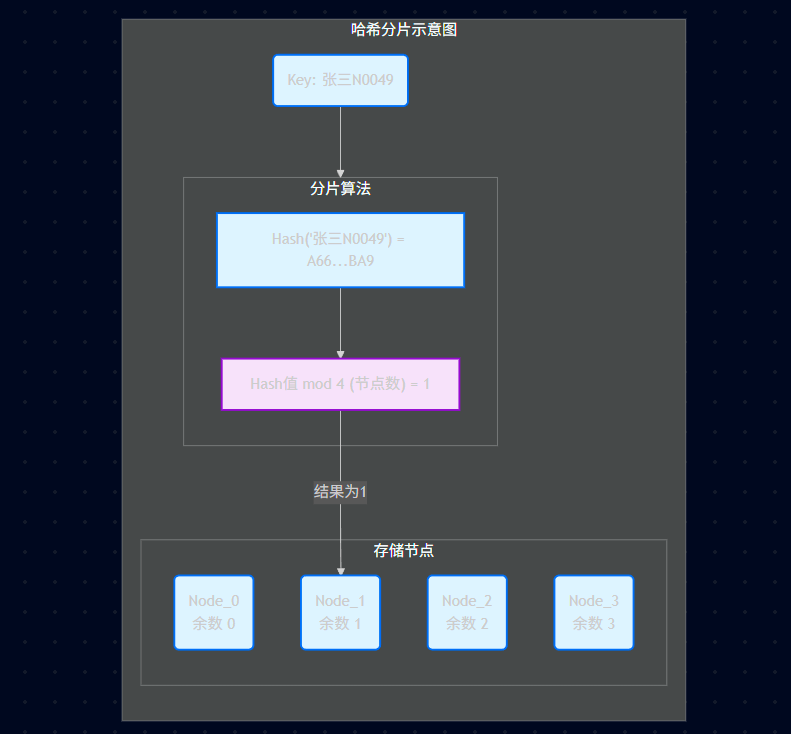
典型场景: 的例子 Hash("张三N0049") mod 4 = 1。这是大多数分布式缓存(如 Redis, Memcached)默认的数据分布方式。
数据极度均匀: 只要 Hash 算法够好,数据就会像散弹枪一样均匀打在所有节点上。
解决热点问题: 即使是连续的 ID,经过 Hash 后也会被打散到不同机器,所有机器一起抗压力。
扩容是灾难: 也就是课件提到的"重新分配节点带来的无法命中问题"。一旦从 3 台扩容到 4 台,模数从 3 变成 4,结果全变了,大约 75% 的数据需要迁移。
不支持范围查询: 你想找 ID 1000 到 2000 的数据?对不起,它们可能分布在天涯海角,你得把所有节点都查一遍。
23.3.9.4、一致性哈希分片
哈希环: 把 0 到 2 64 − 1 2^{64}-1 264−1 的数字空间想象成一个首尾相接的圆环。
把 节点 (Node) 哈希到环上。
把 数据 (Data) 哈希到环上。
数据顺时针找最近的节点。
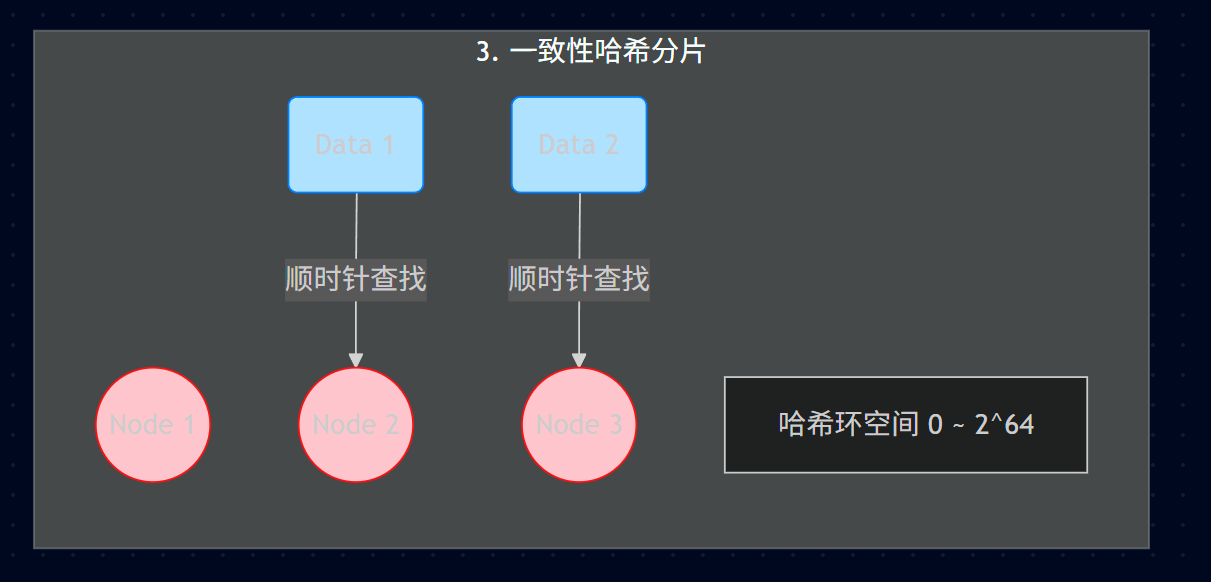
解决了什么问题?
解决了普通哈希分片 扩容导致数据大规模迁移 的问题。
在一致性哈希中,如果增加一个 Node 4(放在 Node 1 和 Node 2 之间),只影响 Node 4 逆时针方向到 Node 1 之间的那部分数据。其他数据不受影响。迁移量极小。
问题: 如果节点太少(比如只有 2 个),环上节点分布不均匀,可能导致 Node A 负责 90% 的数据,Node B 只负责 10%。
解法 (考试常考): 引入 虚拟节点 。把 Node A 变成 Node A#1, Node A#2... Node A#100,均匀撒在环上。数据命中虚拟节点后,最终路由回真实的 Node A。
23.3.10、Redis 核心数据类型
| 类型 | 特点 (原课件文字) | 示例 / 场景 |
|---|---|---|
| String (字符串) | 存储二进制,任何类型数据,最大512MB | 缓存,计数,共享Session |
| Hash (字典) | 无序字典,数组+链表,适合存对象 Key对应一个HashMap。针对一组数据 | 存储、读取、修改用户属性 (如 User:1 -> name:jack, age:38) |
| List (列表) | Linked List: 双向链表,有序,增删快,查询慢 Array List: 数组方式,有序,增删慢,查询快 | 消息队列,文章列表 记录前N个最新登录的用户ID列表 |
| Set (集合) | 键值对无序,唯一 增删查复杂度均为O(1),支持交/并/差集操作 | 独立IP,共同爱好,标签 |
| Sorted Set (Zset) (有序集合) | 键值对有序,唯一,自带按权重排序效果 | 排行榜 |
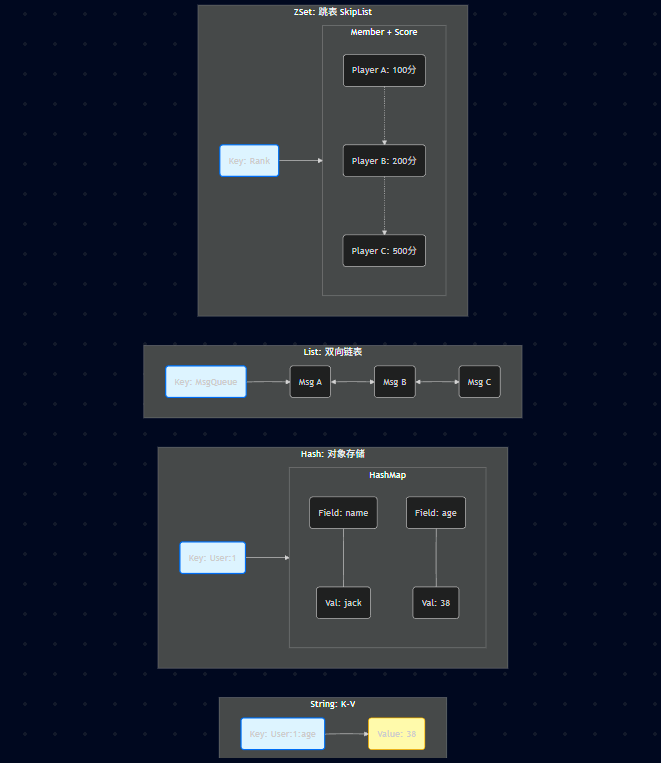
23.3.10.1、String (字符串)
底层实现: SDS (Simple Dynamic String,简单动态字符串)。
二进制安全: 因为 SDS 记录了长度,不依赖 \0 终止符,所以可以存图片、视频的二进制流。
原子性: INCR 和 DECR 操作是原子的,非常适合做分布式锁 、限流器 、全局计数器。
23.3.10.2、Hash (哈希)
底层实现: 数据少时用 ziplist (压缩列表) ,数据多时转为 hashtable (Redis 7.0后使用 listpack)。
局部更新能力: 相比于 String 存储 JSON 字符串,Hash 可以只修改对象的某个字段(如只改 age),节省网络流量,避免并发修改整个 JSON 时的覆盖问题。
23.3.10.3、List (列表)
底层实现: quicklist (双向链表,节点内部是 ziplist)。
组合命令实现数据结构
栈 (Stack): LPUSH + LPOP (先进后出)
队列 (Queue): LPUSH + RPOP (先进先出)
阻塞队列 (Blocking MQ): LPUSH + BLPOP (没消息时阻塞等待,实现简单的消息队列)
23.3.10.4、Set (集合)
底层实现: intset (整数集合) 或 hashtable。
共同关注/共同爱好: 使用 SINTER (求交集)。
可能认识的人: 使用 SDIFF (求差集)。
所有粉丝: 使用 SUNION (求并集)。
23.3.10.5、Sorted Set / ZSet (有序集合)
底层实现 (高频考点): ziplist 或 SkipList (跳表) + Dictionary。
为什么用跳表不用红黑树? 跳表实现简单,范围查找效率极高,并发场景下锁粒度更容易控制。
排行榜: 游戏积分榜、热搜榜(Score 是热度值)。
延时队列: 把 Score 设置为"执行时间戳",然后轮询获取 Score < 当前时间的任务。
23.3.11、Redis 数据淘汰算法
23.3.11.1、核心淘汰策略详解
| 淘汰作用范围 | 机制名 (Policy Name) | 策略说明 (Strategy) |
|---|---|---|
| 不淘汰 | noeviction | 禁止驱逐数据 ,内存不足以容纳新入数据时,新写入操作就会报错。系统默认的一种淘汰策略。 |
| 设置了过期时间的键空间 (Expires) | volatile-random | 随机移除某个 key |
| volatile-lru | 优先移除最近未使用的 key (Least Recently Used) | |
| volatile-ttl | ttl值小的 key 优先移除 (即:快要过期的先删掉) | |
| 全键空间 (All Keys) | allkeys-random | 随机移除某个 key |
| allkeys-lru | 优先移除最近未使用的 key (Least Recently Used) |
23.3.11.2、淘汰决策逻辑流程图
noeviction allkeys-* lru random lfu volatile-* lru random ttl lfu 内存不足时 配置的 maxmemory-policy? ❌ 报错 OOM Error
(只读不写) 范围: 所有 Key
(包括持久化的和临时的) allkeys-lru
删最近最少使用的 allkeys-random
随机删 allkeys-lfu
删使用频率最低的 范围: 设置了 Expiration 的 Key
(只在带过期时间的池子里挑) volatile-lru
删最近最少使用的 volatile-random
随机删 volatile-ttl
删剩余寿命最短的 volatile-lfu
删使用频率最低的
23.3.11.3、过期删除 vs 内存淘汰
过期删除 (Expiration): Key 的 TTL 到了(比如设置了 500秒,500秒后)。
策略: 惰性删除 (访问时检查) + 定期删除 (后台定时任务扫描)。
内存淘汰 (Eviction): Key 还没过期,但 Redis 内存满了 (超过 maxmemory)。
策略: 触发淘汰算法 (如 LRU, Random)。
23.3.11.4、LRU vs LFU
LRU (Least Recently Used): 看时间。很久没动过的数据,删掉。
缺点: 如果一个冷数据刚刚被扫全表查询偶然访问了一次,LRU 就会认为它是热数据,不仅没删它,反而把真正的热数据挤走了。
LFU (Least Frequently Used): 看频率。过去一段时间访问次数最少的数据,删掉。
优点: 解决了 LRU 的"偶然访问"问题,更精准地保留热点数据。
23.3.11.5、常用场景选型
场景 A:Redis 用作纯缓存 (Cache),后端有 DB 兜底。
选型: allkeys-lru 。理由: 既然是缓存,满了就删掉最近不用的,不管有没有设置过期时间,把空间腾给热点数据。
场景 B:Redis 既做缓存,又做持久化存储 (部分 Key 绝对不能删)。
选型: volatile-lru 。理由: 重要的 Key 不设置过期时间(永久保存),缓存的 Key 设置过期时间。Redis 只会从带过期时间的 Key 里踢人,绝对安全。
场景 C:需要精确控制谁先死。
选型: volatile-ttl 。理由: 业务层通过控制 TTL 长短来人为控制数据的生命周期优先级。
23.3.12、Redis 持久化
23.3.12.1、核心定义
Redis的持久化主要有两种方式:RDB和AOF。
RDB: 传统数据库中 快照的思想,指定时间间隔将数据进行快照存储。
AOF: 传统数据库中 日志的思想,把每条改变数据集的命令追加到AOF文件末尾,这样出问题了,可以重新执行AOF文件中的命令来重建数据集。
23.3.12.2、RDB vs AOF 深度对比
| 对比维度 | RDB 持久化 (快照) | AOF 持久化 (追加日志) |
|---|---|---|
| 备份量 | 重量级的全量备份,保存整个数据库 | 轻量级增量备份 ,一次只保存 一个修改命令 |
| 保存间隔时间 | 保存间隔时间长 | 保存间隔时间短,默认1秒 |
| 还原速度 | 数据还原速度快 (直接加载二进制文件) | 数据还原速度慢 (需要一条条重放命令) |
| 阻塞情况 | save会阻塞 ,但 bgsave或者自动不会阻塞 | 无论是平时还是AOF重写,都不会阻塞 |
| 数据体积 | 同等数据体积:小 (二进制压缩) | 同等数据体积:大 (纯文本协议) |
| 安全性 | 数据安全性:低,容易丢数据 (两次快照之间的数据会丢) | 数据安全性:高,根据策略决定 (最多丢1秒) |
23.3.12.3、持久化原理逻辑图
AOF: 日志模式 Append Only File RDB: 快照模式 Snapshots 父进程继续服务 子进程 everysec 追加到 AOF 缓冲区 客户端写命令
SET k v 刷盘策略
fsync 磁盘: appendonly.aof 文件
(文本协议格式) AOF 重写
BGREWRITEAOF 压缩后的新 AOF Fork 子进程 触发条件
save 900 1 ... 将内存数据写入 dump.rdb 磁盘: dump.rdb 文件
(二进制紧凑格式) Redis 内存数据
23.3.13.4、RDB 的 Copy-On-Write (写时复制) 技术
考点: 为什么 RDB bgsave 做全量备份时,Redis 还能处理写请求?
原理: Redis 调用系统 fork() 创建子进程。子进程并不立即复制物理内存,而是与父进程共享内存。只有当父进程要修改某块内存数据时,操作系统才会把这块内存复制一份副本给父进程修改(Copy-On-Write)。
风险: 如果在备份期间写操作极其频繁,内存占用可能会瞬间翻倍。
23.3.13.5、AOF 的三种刷盘策略 (fsync)
always: 每次写命令都刷盘。数据最安全,但性能极差(磁盘 I/O 瓶颈)。
everysec (默认): 每秒刷盘一次。折中方案,最多丢 1 秒数据。
no: 不主动刷盘,交给操作系统心情。性能最好,但安全性未知。
23.3.13.6、AOF 重写 (Rewrite) 机制
问题: AOF 文件会无限膨胀。比如你对 count 加了 100 次 1,AOF 里就有 100 条记录,但其实只要一条 SET count 100 就够了。
解决: Redis 后台自动触发重写,创建一个新的 AOF 文件,只保留构建当前数据集所需的最小命令集合。
23.3.13.7、混合持久化 (Redis 4.0+ 新特性)
背景: RDB 恢复快但丢数据多,AOF 丢数据少但恢复慢。能不能成年人全都要?
方案: AOF 文件的前半部分是 RDB 格式 (存全量数据),后半部分是 AOF 格式 (存增量命令)。
优点: 既能像 RDB 一样秒级启动恢复,又能像 AOF 一样保证数据不丢失。
23.3.13、缓存雪崩
23.3.13.1、核心定义与现象
定义: 大部分缓存失效 -> 数据库崩溃。
现象描述: 当缓存层(Redis)中大量的 Key 在同一时刻失效,或者 Redis 服务直接挂掉,导致原本应该访问缓存的海量请求,瞬间全部打到了后端的数据库(MySQL)上,导致数据库因为无法承受巨大的 I/O 压力而崩溃(Crash)。
23.3.13.2、故障流程图
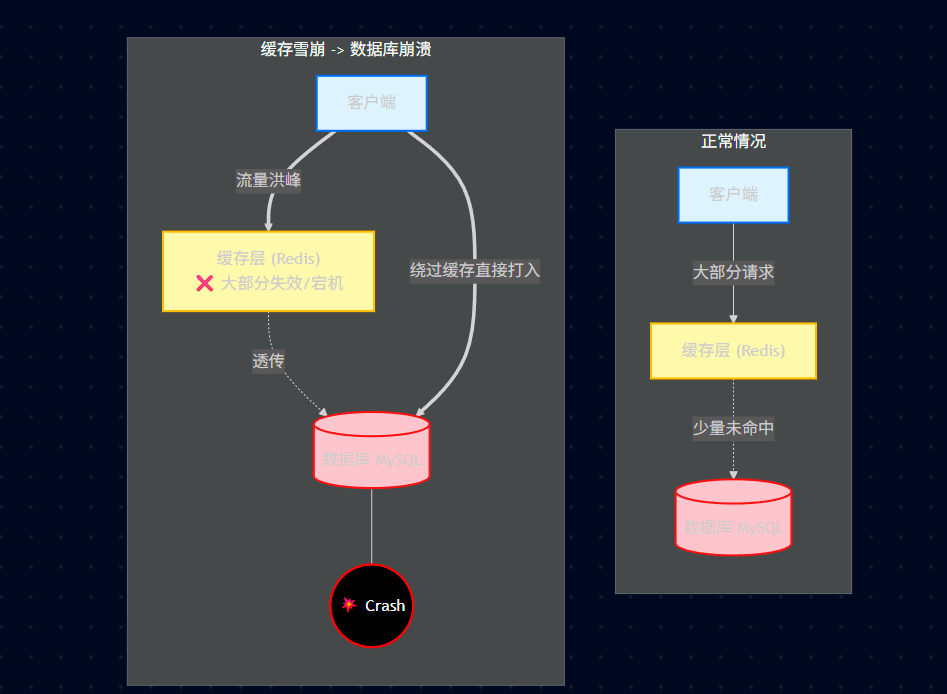
23.3.13.3、使用锁或队列
保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。
其实就是限流 (Rate Limiting) 或 排队 。比如用 Semaphore 或 Redis 的 SETNX 互斥锁。当缓存失效时,只放一个线程进去查数据库构建缓存,其他线程等待或降级。
23.3.13.4、为key设置不同的缓存失效时间
在固定的一个缓存时间的基础上 + 随机一个时间 作为缓存失效时间。
这是最简单有效的预防手段。
公式: TTL = Base_Time + Random(0, 300s)。这样就把集中过期的"波峰"削平成了"波浪"。
23.3.13.5、二级缓存
设置一个有时间限制的缓存 + 一个无时间限制的缓存。避免大规模访问数据库。
L1 (本地缓存/Guava): 短期,抗高并发。
L2 (Redis): 长期,作为兜底。或者:Redis 中存两份,一份正常的(带过期),一份备份的(永久),当正常的过期时,代码逻辑先返回备份的旧数据,后台异步去更新。
23.3.14、缓存穿透与布隆过滤器
23.3.14.1、缓存穿透定义
定义: 查询无数据返回 -> 直接查数据库。
现象: 客户端查询一个根本不存在的数据(比如 ID = -1 或 UUID),缓存中肯定没有,导致请求直接穿透缓存层,打到数据库上。数据库也没有,所以无法写入缓存。下次同样的查询还是会打到数据库。如果是恶意攻击,数据库瞬间就会崩掉。
23.3.14.2、故障流程图
恶意循环 1、查询不存在的Key (ID=-1) 2、未命中 (Miss) 3、查询结果为空 缓存层失效
请求直达数据库 客户端 缓存层 数据库
23.3.14.3、布隆过滤器的优缺点
| 优点 (Pros) | 缺点 (Cons) |
|---|---|
| 占用内存小 (只存 0/1,不存原始数据) | 有一定的误判率 (即存在假阳性,不能准确判断元素是否在集合中) |
| 查询效率高 (O(k) 时间复杂度,k为哈希函数个数) | 一般情况下 不能从布隆过滤器中删除元素 (因为一位可能被多个元素对应) |
| 不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势 | 不能获取元素本身 |
1)为什么会有误判?
原理: 因为位数组长度有限,不同的字符串经过 Hash 后可能会落在同一个位置(Hash 碰撞)。
布隆过滤器说 "不存在" ,那一定 不存在。✅ (拦截率 100%)
布隆过滤器说 "存在" ,那 可能不存在。⚠️ (有误判)
所以它非常适合用来做"黑名单"或"前置拦截"。
2)为什么不能删除?
原理: 如上面的 Mermaid 图所示,位置 B7 既被"xxx1"标记了,也被"xxx2"标记了。如果你为了删除"xxx1"把 B7 置为 0,那么"xxx2"再去查的时候,发现 B7 是 0,就会误判自己也不存在了。
进阶: 如果非要支持删除,可以使用 计数布隆过滤器 (Counting Bloom Filter),把 Bit 变成 Counter(计数器),但内存占用会翻倍。
23.3.15、缓存击穿
23.3.15.1、核心定义
定义: 指缓存中 没有 但数据库中 有 的热点数据(一般是缓存时间到期)。
热点 Key (Hot Key): 这个 Key 访问量巨大(比如微博热搜第一)。
并发量大: 在这个 Key 过期的瞬间,几万个请求同时涌入。
结果: 缓存没拿到,所有请求同时打到数据库,数据库瞬间压力过大倒地。
23.3.15.2、缓存击穿示意图
缓存层 查询普通 Key 1、几万个线程查热点 Key 2、缓存过期没数据 (Miss) 普通 Key 🔥 热点 Key
(刚刚过期!) 高并发客户端 数据库
23.3.15.3、解决方案
对于缓存击穿,我们不能像"雪崩"那样随机设置过期时间(因为这就是一个 Key 的事),也不能像"穿透"那样布隆过滤(因为数据是真的存在的)。
核心思路只有两个:"锁" 和 "永不过期"。
1)方案一:互斥锁 (Mutex Lock) ------ 强一致性
原理: 当缓存失效时,不是所有线程都去查数据库。而是让大家 "抢锁"。
抢到锁的那 1个 线程,去查数据库,写回缓存。没抢到锁的 N-1个 线程,睡觉(Sleep) 几十毫秒,醒来再去查缓存(那时候肯定已经有了)。
有 无 没抢到 抢到了 请求进来 缓存有吗? 返回数据 抢互斥锁
SETNX? 休眠 50ms
重试 查数据库 写入缓存 释放锁
2)方案二:逻辑过期 (Logical Expiration) ------ 高可用性
原理: Redis 里的 Key 不设置 TTL (物理永不过期)。
我们在 Value 内部存一个时间戳(比如 {"data": "xyz", "expire": 12:00})。
请求拿出来一看,发现当前时间 12:01 已经超过了 expire。
不等待: 线程直接把这个"旧数据"返回给用户(牺牲一点一致性)。
异步更新: 偷偷启动一个后台线程,去数据库查新数据,把缓存更新成 {"data": "new", "expire": 12:10}。
适用场景: 秒杀活动、首页热点(用户看一眼旧数据没关系,系统不能卡)。
23.3.16、缓存预热
定义: 系统上线后,将相关需要缓存数据直接加到缓存系统中。
1)直接写个缓存刷新页面,上线时手工操作。
2)数据量不大时,可以在项目启动的时候自动进行加载。
3)定时刷新缓存。
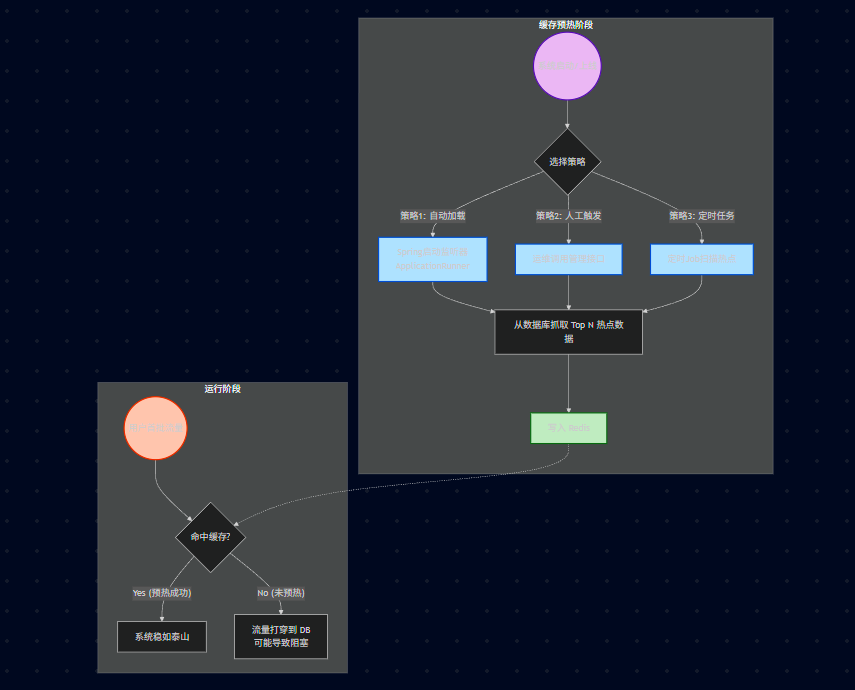
如果不预热会怎样? 系统重启后,缓存是空的。早高峰第一波流量进来,会瞬间全部击穿到数据库,虽然不是 Redis 故障导致的雪崩,但效果一样,数据库会瞬间 CPU 100%。
预热什么数据? 不要预热全量数据(内存不够)。通常利用大数据分析(昨天的 Access Log),找出访问频率最高的 Top 1000 Key 进行预热。
23.3.17、缓存更新-懒加载更新模式
除 Redis 系统自带的缓存失效策略,常见采用以下两种:
1)定时清理过期的缓存。适用于对数据一致性要求极高的场景。
2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。缺点是第一次查的人响应慢。可以主动更新,比如商品价格修改,后台管理系统改完数据库后,立刻发消息给 Redis 进行更新。适用于对数据一致性要求极高的场景。
YES (命中) NO (过期/不存在) 用户请求 Key 逻辑判断:
缓存存在且未过期? 返回缓存数据 1、读取底层数据库 2、写入缓存 + 设置新 TTL
23.3.18、缓存降级
目的: 降级的目的是保证核心服务可用,即使是有损的。
注意点: 而且有些服务是无法降级的(如电商的购物流程等);在进行降级之前要对系统进行梳理,从而梳理出哪些必须保护,哪些可降级。
核心业务
(支付/下单) 非核心业务
(评论/推荐/日志) ⚠️ 报警:
Redis 宕机 或
数据库 CPU > 90% 判断业务类型 🛡️ 必须保护 熔断非核心依赖
只保留最简流程 📉 实施降级 返回默认值
(Default Value) 返回空数据
(Null) 返回静态提示
(系统繁忙)
降级是"丢卒保帅": 当雪崩发生时,或者双11流量太大时,为了保住"下单"和"支付",我们会把"查看评论"、"物流查询"、"个性化推荐"这些服务关掉(降级),让它们直接返回"暂无数据",从而释放资源给核心业务。
自动降级: 结合 Hystrix / Sentinel,当超时率或错误率达到阈值自动触发。
人工降级: 也就是传说中的 "开关" 。大促当晚,运维在配置中心把 enable_comment = false,瞬间切断非核心流量。
23.4、第四阶段:服务集群
23.4.1、核心目标
使用服务集群改善网站并发处理能力。
23.4.2、架构特征
应用服务器集群: 不再是一台服务器,而是 应用服务器1、应用服务器2 ... 应用服务器n 组成的一个集群。
周边配套: 依然保留了之前的 本地缓存 、数据库服务器 、文件服务器 和 分布式缓存服务器集群。
关键点: 所有的应用服务器运行的代码是完全一样的。
23.4.3、集群架构图
后端资源层 应用服务器集群 数据库服务器 文件服务器 分布式缓存服务器集群 应用服务器 1 应用服务器 2 应用服务器 n 本地缓存 本地缓存 用户请求 负载均衡调度
(隐式层)
23.4.4、两大核心问题
1)用户的请求由谁来转发到具体的应用服务器?
解决方案:负载均衡 (Load Balance)
2)用户如果每次访问到的服务器不一样,那么如何维护 session 的一致性?
解决方案:有状态与无状态问题 (Session Consistency)
问题2: Session 不一致 第1次请求 第2次请求 问题1: 流量分发 登录 (Login) 生成 Session A 购买 (Buy) 查找 Session? 未登录! Server 2 内存: 空 Server 1 用户 内存: Session A ??? 用户 Server A Server B
23.4.5、负载均衡
23.4.5.1、负载均衡分类图
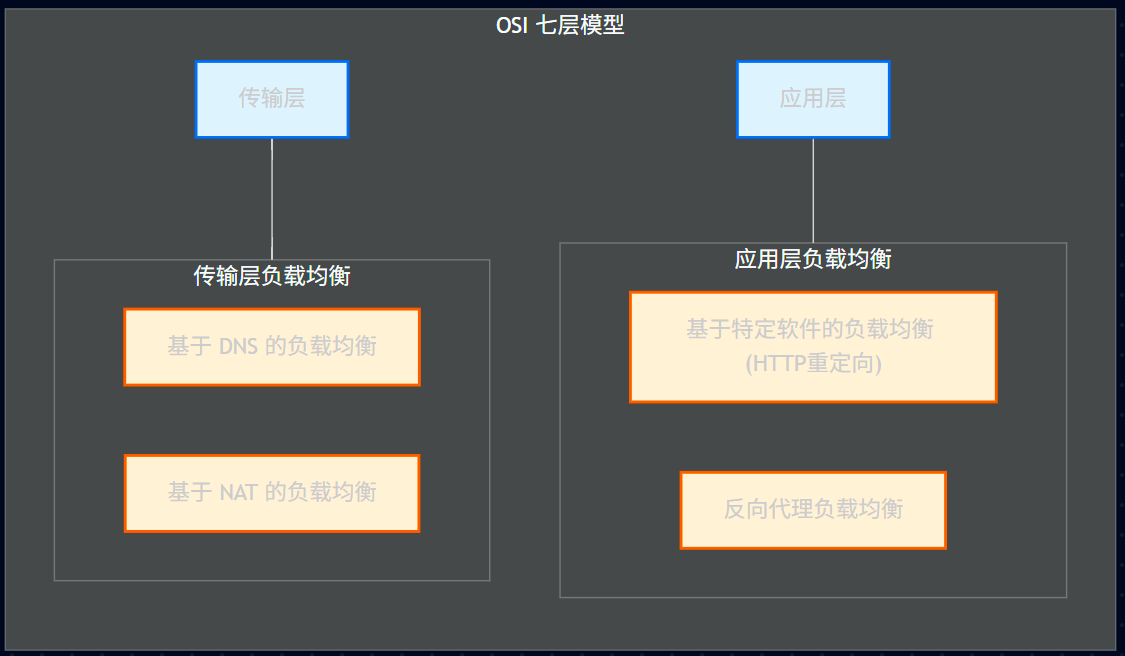
23.4.5.2、应用层负载均衡 (L7)
1)HTTP 重定向
定义: HTTP重定向就是应用层的请求转发。用户的请求其实已经到了HTTP重定向负载均衡服务器,服务器根据算法要求用户重定向,用户收到重定向请求后,再次请求真正的集群。
特点: 实现简单,但性能较差。
2)反向代理服务器
定义: 在用户的请求到达反向代理服务器时(已经到达网站机房),由反向代理服务器根据算法转发到具体的服务器。常用的 apache、nginx 都可以充当反向代理服务器。
特点: 部署简单,但代理服务器可能成为性能的瓶颈。
23.4.5.3、传输层负载均衡 (L4)
1)DNS 域名解析负载均衡
定义: 在用户请求 DNS 服务器,获取域名对应的 IP 地址时,DNS 服务器直接给出负载均衡后的服务器 IP。
特点: 效率比 HTTP 重定向高,减少维护负载均衡服务器成本。但一个应用服务器故障,不能及时通知 DNS,而且 DNS 负载均衡的控制权在域名服务商那里,网站无法做更多的改善和更强大的管理。
2)基于 NAT 的负载均衡
定义: 基于 NAT 的负载均衡将一个外部 IP 地址映射为多个 IP 地址,对每次连接请求动态地转换为一个内部节点的地址。
特点: 技术较为成熟,一般在网关位置,可以通过硬件实现。像四层交换机一般就采用了这种技术。
示例:
① LVS (Linux Virtual Server): 典型的 L4 (传输层) 负载均衡。
特点: 性能极高 (只改 IP/MAC,不看内容),抗负载能力强。
场景: 作为整个网站的最前端入口。
② Nginx / HAProxy: 典型的 L7 (应用层) 负载均衡。
特点: 灵活,可以根据 URL、浏览器 User-Agent 分发请求。
场景: 作为 LVS 后面的具体业务集群分发器。
23.4.5.4、负载均衡算法
1)静态算法
轮转算法 (Round Robin): 轮流将服务请求(任务)调度给不同的节点。
加权轮转算法 (Weighted Round Robin): 考虑不同节点处理能力的差异。
源地址哈希散列算法 (Source IP Hash): 根据请求的源 IP 地址,作为散列键从静态分配的散列表找出对应的节点。
目标地址哈希散列算法: 根据请求目标 IP 做散列找出对应节点。
随机算法 (Random): 随机分配,简单,但不可控。
2)动态算法
最小连接数算法 (Least Connections): 新请求分配给当前活动请求数量最少的节点。
加权最小连接数算法: 考虑节点处理能力不同,按最小连接数分配。
加权百分比算法: 考虑了节点的利用率、硬盘速率、进程个数等,使用利用率来表现剩余处理能力。
3)算法选择场景题
场景: 机器配置完全一样。 → \rightarrow → 轮询 (Round Robin)。
场景: 机器有的新有的旧,性能参差不齐。 → \rightarrow → 加权轮询 (Weighted Round Robin)。
场景: 需要保证同一个用户的请求永远落在同一台机器上 (Session Sticky)。 → \rightarrow → 源地址哈希 (Source IP Hash)。
23.4.6、Session 共享机制
23.4.6.1、有状态
有状态服务 (Stateful Service): 它会在自身保存一些数据,先后的请求是有关联的。
23.4.6.2、无状态
无状态服务 (Stateless Service): 对单次请求的处理,不依赖其他请求,也就是说,处理一次请求所需的全部信息,要么都包含在这个请求里,要么可以从外部获取到(比如说数据库),服务器本身不存储任何信息。
23.4.6.3、Session 共享架构图
解决集群环境下 Session 不一致(用户在 A 登录,请求被转发到 B,B 没 Session 导致用户退出)的三种经典方案。
方案3: Centralized Storage 方案2: Server Sync 方案1: Client Side 携带 Session 的 Cookie 服务器间同步 Session 将 Session 存入 从 Redis 读取 Redis 应用服务器 2 应用服务器 1 客户端 负载均衡器
23.4.6.4、方案优缺点深度对比
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 方案 1: Cookie 携带 | 将 Session 数据加密后存在客户端 Cookie 中 | 服务器零负担,无状态,扩展性极好 | 安全性差 (容易被篡改/劫持);Cookie 大小受限 (4KB);每次请求网络开销大 |
| 方案 2: Session 同步 | Tomcat 等容器自带的 Session 广播复制 | 对应用透明,无需改代码 | 广播风暴,节点多了网络带宽会被吃光;内存利用率低 (每台机器都存一份) |
| 方案 3: Redis 集中存储 | (架构师推荐) 所有 Session 存 Redis | 支持水平扩展,服务器无状态;Session 数据安全可靠 | 引入了新组件 (Redis),Redis 挂了会导致全站不能登录 (需要做 Redis 高可用) |
23.4.6.5、Session 方案选型
一般互联网应用: 坚决选 方案 3 (Redis)。
极小型内部应用: 可以选 方案 2 (同步)。
不敏感数据且追求极致性能: 可以选 方案 1 (Cookie),但现在很少用了。
23.5、第五阶段:数据库读写分离
这是架构演化中解决存储性能瓶颈的第一把手术刀。当缓存(第三阶段)和集群(第四阶段)都上了,应用服务器没压力了,压力全到了数据库身上。这时就要对数据库进行"分工"。
23.5.1、核心思想
数据库读写分离。
应用层: 增加了 数据访问模块 (Data Access Module),负责决定 SQL 是发给主库还是从库。
存储层: 数据库分裂为 主库 (Master) 和 从库 (Slave)。
23.5.2、辅助手段
用缓存缓解读库的压力。
23.5.3、读写分离架构图
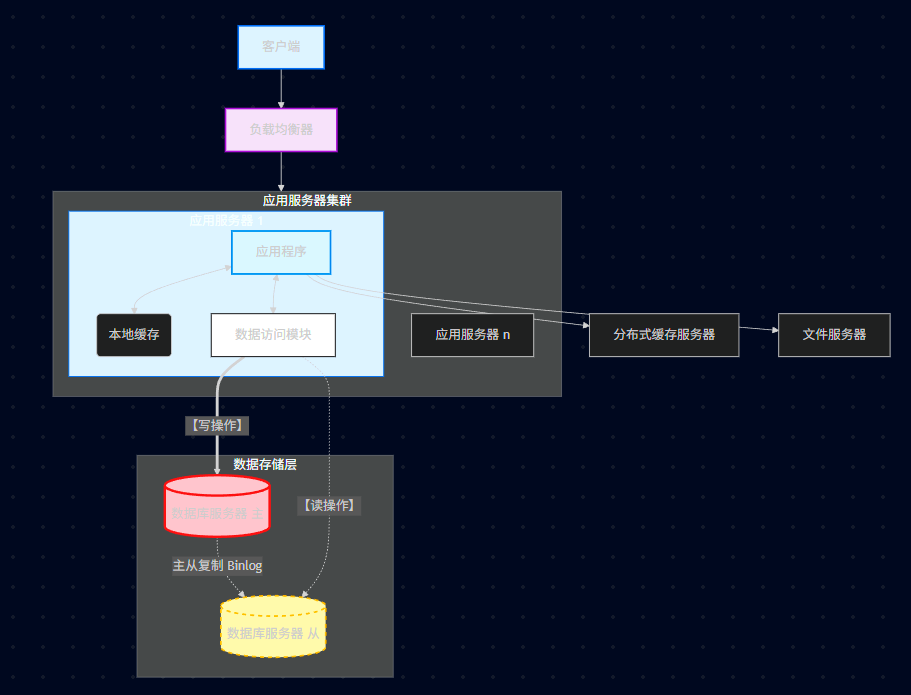
23.5.4、主从数据库结构特点
一般: 一主多从,也可以多主多从。
分工: 主库做写操作,从库做读操作。
23.5.5、主从复制原理
1)主库 (Master) 更新数据完成前 ,将操作写 binlog 日志文件。
2)从库 (Slave) 打开 I/O 线程与主库连接,做 binlog dump process ,并将事件写入 中继日志 (relay log)。
3)从库执行中继日志事件,保持与主库一致。
从库 Slave 主库 Master 3、重放执行 网络传输 (Dump) IO 线程 2、写入 Relay Log
(中继日志) SQL 线程 数据落盘 1、写入 Binlog 写操作
23.5.6、读写分离的价值
绝大多数互联网业务都是 "读多写少" 的(比例通常在 10:1 甚至更高)。
让一台主库专门负责"写",多台从库负责"读",通过加从库就能线性提升系统的"读性能"。
23.5.7、读写分离带来的核心问题
最主要的问题就是 数据延迟。
现象: 刚注册完用户(写主库),立刻登录(读从库),提示"用户名不存在"。因为主从复制有毫秒级甚至秒级的延迟。
解决方案:
1)写后读一致性 (Read-your-writes): 在代码层(数据访问模块)做判断,如果是用户自己查自己的刚写入的数据,强制路由到主库。
2)二次读取: 从库读不到,再回主库读一次(慎用,容易把主库打挂)。
3)关键业务读主库: 比如订单支付、金额扣减,必须读主库。
23.5.8、数据访问模块 (DAL)落地方案
1)客户端中间件
代表: Sharding-JDBC (ShardingSphere), TDDL。
位置: 集成在 Jar 包里,随应用启动。
优点: 性能好,无额外运维成本。
2)服务端中间件
代表: MyCAT, Sharding-Proxy。
位置: 在应用和数据库之间独立部署一个代理服务。
优点: 对应用透明,应用觉得后面就是一个 MySQL。
23.6、第六阶段:反向代理和 CDN 加速网站
这是架构演化中**解决"网络传输延迟"和"响应速度"**的关键一步。前几个阶段我们都在折腾服务器内部(缓存、集群、DB分离),这一阶段我们开始走出机房,去优化用户到机房的这段路。
23.6.1、核心架构演变
在用户和负载均衡器之间,新增了两层"护法":
1)CDN 服务器 (最外层,离用户最近)。
2)反向代理服务器 (机房边缘,保护内网)。
23.6.2、核心架构图
后端资源层 应用服务器集群 加速层 主从复制 【写操作】 【读操作】 数据库 主 数据库 从 文件服务器 分布式缓存服务器 应用服务器 1
含: 本地缓存 + 数据访问模块 应用服务器 n CDN 服务器集群 反向代理服务器集群 客户端 负载均衡器
23.6.3、CDN (内容分发网络) 详解
23.6.3.1、核心概念
全称: CDN的全称是Content Delivery Network,即内容分发网络。
基本思路: 尽可能避开互联网上可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输得更快、更稳定。
拓扑结构: 源站点(如北京)将内容分发到全国各地的 CDN 节点(新疆、成都、长沙、广州、上海...),用户就近访问。
23.6.3.2、CDN 加速的原理
1)GSLB (全局负载均衡): 当你访问 www.taobao.com 时,DNS 不会直接给你源站 IP,而是给你一个 CNAME。
2)智能调度: CDN 的 DNS 服务器会根据你的 源 IP 地址(比如你在上海),把你解析到上海的 CDN 节点 IP。
23.6.3.3、CDN 适合存什么
静态资源 (Static Content): 图片、CSS、JS、小视频、HTML 静态页。
特点: 读多写少,几乎不修改。
不适合: 用户的订单数据、库存数据、个性化推荐(这些是动态的,还得回源站)。
23.6.3.4、缓存一致性问题
问题: 如果源站更新了图片,CDN 还在给用户发旧图片怎么办?
解法:
1)被动失效: 设置 TTL (Time To Live),比如 1 小时。过期后 CDN 自动回源去取新的。
2)主动刷新 (Push): 运维手动调用 CDN 厂商接口,强制刷新某个 URL。
3)版本号控制 (最佳实践): 文件名带哈希值,如 logo_v2.png,更新时直接改名。
23.6.4、反向代理 (Reverse Proxy) 详解
23.6.4.1、核心概念
位于 CDN 和 负载均衡器 之间,属于机房的第一道大门。
| 类型 | 代理对象 | 谁知道真相? | 典型例子 | 作用 |
|---|---|---|---|---|
| 正向代理 (Forward) | 代理客户端 | 服务器不知道客户端是谁 | VPN (翻墙) | 突破访问限制、隐藏客户端 IP |
| 反向代理 (Reverse) | 代理服务器 | 客户端不知道服务器是谁 | Nginx | 负载均衡、安全防护、缓存 |
一句话总结: 正向代理帮你去访问 别人;反向代理帮别人来访问你。
23.6.4.2、核心作用
既然有了 CDN 和 负载均衡,为什么中间还要插一个反向代理(如 Nginx)?
1)安全屏障: 隐藏内网真实的 IP 结构,外网只能看到 Nginx 的 IP。
2)SSL 卸载 (Offloading): HTTPS 加解密非常消耗 CPU,通常在反向代理层统一解密,内网走 HTTP 明文传输,给应用服务器减负。
3)动态数据的"微缓存": 对于一些有时效性的动态数据(如热门文章列表,1分钟变一次),CDN 可能不收,但可以在反向代理层缓存 30 秒,抵挡热点流量。
4)压缩 (Gzip): 统一对响应内容进行压缩,节省带宽。
23.7、第七阶段:分布式部署文件系统/数据库
这是架构演化中解决海量数据存储瓶颈的关键阶段。当前面的读写分离(第五阶段)和 CDN 加速(第六阶段)都实施后,如果网站业务继续爆发,单台主库写不下了,单台文件服务器存不下了,我们就必须对存储层进行彻底的"拆分"。
23.7.1、核心架构演变
架构变化: 也就是俗称的"数据拆分"。
应用层: 应用服务器内增加了 "统一数据访问模块",负责路由(决定数据去哪找)。
数据库层: 从"主从复制"演变为 "分布式数据库服务器" ,并明确标注了 "业务分库"。
文件层: 单台文件服务器演变为 "分布式文件服务器"。
缓存层: 继续使用 "远程分布式缓存"。
23.7.2、架构拓扑图
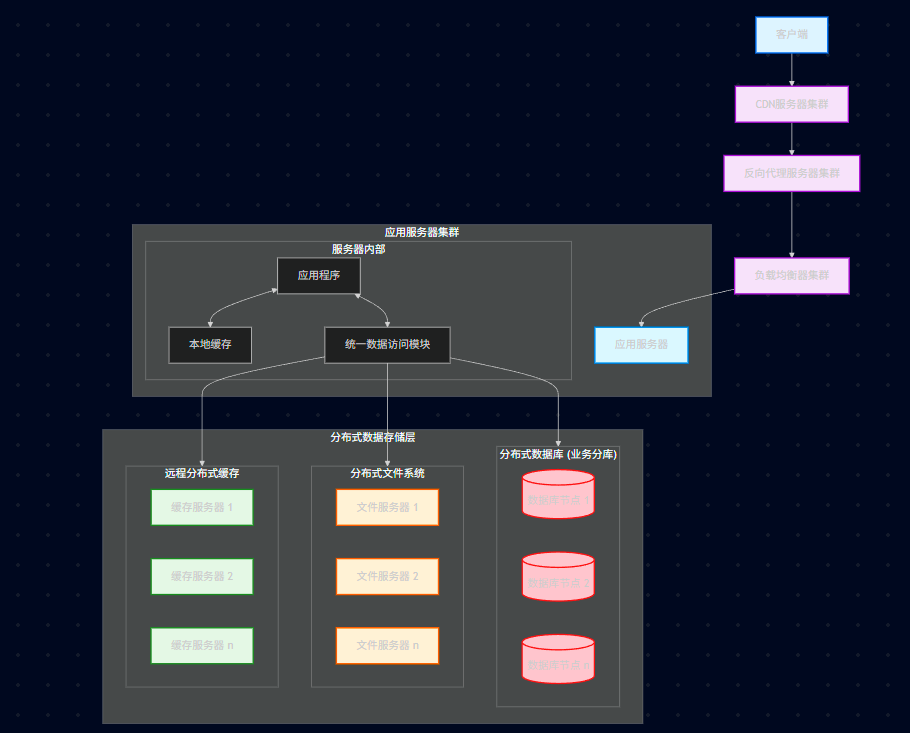
23.7.3、统一数据访问模块
应用程序不直接连接具体的数据库 IP,而是通过这个模块。应用层只需要说"我要查订单",这个模块负责解析"订单在 DB2 服务器上",然后发起连接。
23.7.4、业务分库
23.7.4.1、垂直拆分
做法: 把全站的表,按业务模块拆开。不同业务模块的数据(如用户数据、商品数据、订单数据)被存放到不同的数据库服务器中。
优点: 解决了单机容量问题,不同业务互不影响。
考点/缺点: 表关联 (Join) 变难了。数据库不支持跨库 Join。需要在**应用层(统一数据访问模块)**分别查出来,然后在内存里拼装。
23.7.4.2、水平拆分
做法: 当"订单表"一张表就有 10 亿数据时,业务分库也扛不住了。需要把一张大表拆成 100 张小表(如 order_01 ... order_99)。
术语: 这就是俗称的 "分库分表" (Sharding)。
23.7.5、分布式文件系统 (DFS)
核心原理: 通常包含 NameNode (元数据服务器) 记录文件在哪,和 DataNode (存储服务器) 真正存文件。应用先问 NameNode,再找 DataNode。
单机文件服务器满了怎么办?不能简单的加硬盘,要上 DFS。
HDFS (Hadoop): 适合存大文件,离线分析。
FastDFS / TFS (淘宝): 适合存海量小文件(如商品图、头像),互联网架构首选。
Ceph: 统一存储,性能强。
23.7.6、分布式存储带来的新挑战
场景: 用户下单(写 Order 库)并扣库存(写 Product 库)。
问题: 如果 Order 库写成功了,Product 库写失败了,数据就不一致了。
解决: 需要引入 分布式事务 (2PC/TCC/Seata) 或 最终一致性 (消息队列) 方案。
23.8、第八阶段:使用 NoSQL 和搜索引擎
这是架构演化中**应对"海量数据复杂查询"与"非结构化数据存储"**的里程碑。
随着网站业务越来越复杂,我们发现关系型数据库(MySQL/Oracle)虽然擅长处理事务(ACID),但在面对海量数据的全文检索 (如搜索商品)和非结构化数据 (如评论、日志、社交关系)时,表现得力不从心。于是,我们引入了"核武器"------NoSQL 和 搜索引擎。
23.8.1、核心架构演变
架构变化: 数据存储层变得极其丰富,形成了"存储矩阵"。
应用层: 统一数据访问模块 的路由逻辑变得更复杂了,它不仅要分库分表,还要根据数据类型决定是去 MySQL,还是去 NoSQL,或者是去搜索引擎。
存储层:新增搜索引擎服务器: 专门负责复杂的搜索查询。新增NoSQL 服务器: 专门负责非结构化、高并发读写的数据。
23.8.2、架构拓扑图
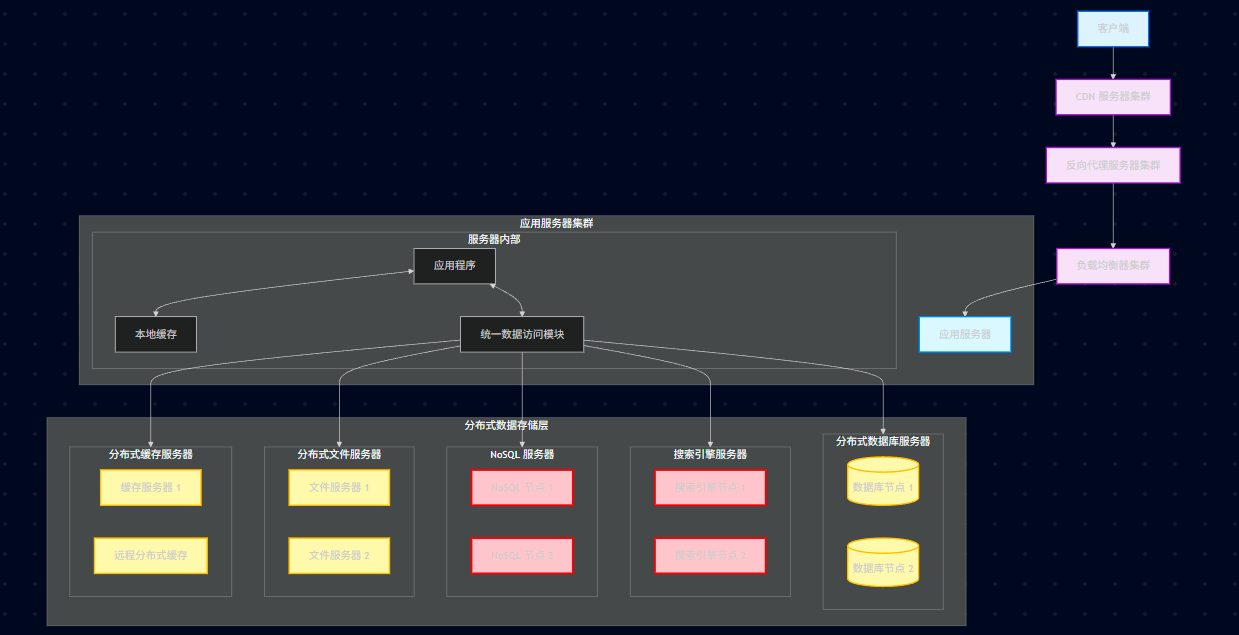
23.8.3、搜索引擎
23.8.3.1、为什么 MySQL 不行?
MySQL 做模糊查询 (LIKE '%关键词%') 效率极低,因为无法利用索引,必须全表扫描。
MySQL 无法解决分词问题(比如搜"苹果手机",要能搜出"iPhone"和"Apple")。
23.8.3.2、主流技术
Lucene: Java 开发的底层搜索引擎库(单机)。
Elasticsearch (ES): 基于 Lucene 的分布式搜索引擎,目前互联网事实标准。
Solr: 老牌的搜索引擎,现在用得比 ES 少。
23.8.3.3、核心原理:倒排索引
正排索引: ID → \rightarrow → 内容 (MySQL 的方式)。
倒排索引: 关键词 → \rightarrow → 哪些文档包含它 (搜索引擎的方式)。
例子: 搜 "Java",索引直接告诉你:文章 ID 1, 5, 9 包含 "Java",速度飞快。
23.8.4、NoSQL
23.8.4.1、为什么需要 NoSQL?
关系型数据库 Schema(表结构)太死板,难以存储社交关系、评论树、日志等非结构化数据。
海量数据的高并发写性能,MySQL 即使分库分表也难以招架。
23.8.4.2、NoSQL 四大金刚
1)键值存储 (Key-Value): Redis, Memcached。
场景: 缓存、Session、计数器。
2)文档存储 (Document): MongoDB。
场景: 存日志、评论、商品详情(JSON 格式)。特点是表结构可变 (Schema-free)。
3)列式存储 (Column-family): HBase, Cassandra。
场景: 存海量数据(几十亿行)、历史订单、大数据分析。
4)图存储 (Graph): Neo4j。
场景: 社交网络(谁关注了谁)、推荐系统、知识图谱。
23.8.5、数据一致性挑战
当架构中同时存在 MySQL (主数据) 和 Elasticsearch (搜索数据) 时,最头疼的问题是:我在 MySQL 改了用户信息,ES 里怎么还没变?
23.8.5.1、方案 A:双写 (Dual Write)
代码里先写 MySQL,再写 ES。
缺点: 容易不一致(MySQL 成功了,ES 写入超时失败了怎么办?)。
23.8.5.2、方案 B:异步队列 (MQ)
写 MySQL 成功后,发个消息给 MQ,消费者去更新 ES。
缺点: 有延迟,代码侵入性大。
23.8.5.3、方案 C:Binlog 订阅 (Canal)
应用只管写 MySQL。
使用中间件(如 Alibaba Canal)伪装成 MySQL Slave,监听 Binlog 日志,解析出数据变更,自动同步给 ES。
优点: 代码完全解耦,对业务无侵入。
23.8.6、CAP 定理的权衡
必须面对 CAP 定理(Consistency 一致性、Availability 可用性、Partition Tolerance 分区容错性)
MySQL: 追求 CA 或 CP(强一致性,ACID)。
NoSQL/ES: 通常追求 AP(最终一致性,BASE 理论)。允许短暂的数据不一致,换取极高的可用性和吞吐量。
23.9、第九阶段:业务拆分
这是架构演化中**从"大单体"迈向"分布式/微服务"**的关键转折点。
在之前的阶段,虽然我们把数据库、文件、缓存都拆出去了,但应用服务器(代码)依然是一坨巨大的"单体应用"。随着业务越来越复杂,几百个工程师在一个项目里改代码,上线极其痛苦,耦合度极高。于是,业务拆分和消息队列登场了。
23.9.1、核心架构演变
业务拆分(将一个大应用拆成多个小应用)。
应用层分裂: 不再是统一的"应用服务器",而是拆分成了 "A应用服务器" (如核心业务)和 "B应用服务器"(如边缘业务或独立业务)。
引入中间件: 新增了 "消息队列服务器" (Message Queue Server)。
通信方式变化:B应用 将数据写入 消息队列 。A应用 从 消息队列 读取消息。这意味着应用之间开始了 异步解耦 的协作。
23.9.2、架构拓扑图
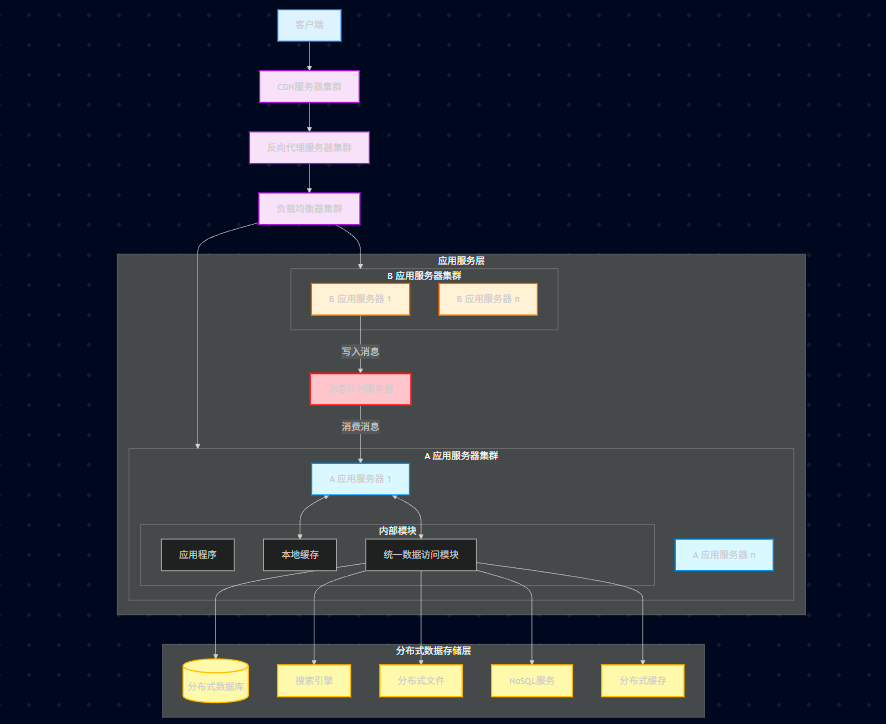
23.9.3、拆分的价值
开发效率低: 一个 WAR 包几百兆,启动要 5 分钟,代码冲突不断。
故障隔离差: "积分模块"的一个 Bug 导致内存溢出,把"下单模块"也带崩了。
23.9.4、拆分的方法
纵向拆分 (Vertical Splitting): 按照业务线拆分。例如拆成"首页系统"、"交易系统"、"用户系统"、"论坛系统"。
核心与非核心分离: 如图中所示,A 可能是核心交易系统(直接连库),B 可能是非核心或上游系统,通过 MQ 异步请求 A。
23.9.5、拆分工具-消息队列
解耦 (Decoupling): B 系统只需要把消息丢给 MQ,不需要关心 A 系统是不是挂了,也不需要依赖 A 的接口定义。
异步 (Asynchrony): B 系统处理完自己的逻辑直接返回用户,不需要等 A 处理完(比如:注册成功后,异步发送邮件)。提升响应速度。
削峰 (Peak Shaving): 双 11 秒杀流量洪峰进来,先把请求堆在 MQ 里,A 系统按照自己的处理能力慢慢拉取消费,防止数据库被瞬间打死。
23.9.6、MQ选型
RabbitMQ: 延时低,功能全,Erlang 开发。
RocketMQ (阿里): 吞吐量高,适合电商业务,Java 开发。
Kafka: 吞吐量极高,适合日志采集和大数据流处理。
23.9.7、拆分后的挑战 ------ 分布式事务
以前在一个系统里,User 表和 Order 表在同一个事务里 commit 就行。现在拆成了 A 系统和 B 系统,还跨了 MQ。
问题: B 系统发了消息给 MQ,但还没存数据库就挂了;或者 MQ 发给了 A,A 执行失败了,B 怎么回滚?
最终一致性 (Base): 只要保证消息不丢,A 最终能处理成功即可。
可靠消息投递: 使用 MQ 的"事务消息"功能(如 RocketMQ)或 本地消息表方案。
23.9.8、接口管理与调用
业务拆分后,系统间不能直接 new Class() 调用了,必须通过网络通信。
初期: 可能通过 HttpClient 直接调 HTTP 接口。
后期 (下一阶段伏笔): 接口太多了,IP 记不住,这就催生了 分布式服务框架 (Dubbo/Spring Cloud) 和 服务治理 的需求。
23.10、第十阶段:分布式服务
这是大型网站架构演化的终极形态之一 。在第九阶段我们将业务拆分成了 A 应用和 B 应用,但随之而来的问题是:A 应用和 B 应用中可能有大量重复的代码(比如用户查询、积分计算)。
为了解决代码复用和管理问题,我们将共用的业务逻辑提取出来,独立部署,形成了**"分布式服务层"**。
23.10.1、核心架构演变
分布式服务(将核心业务逻辑独立为服务)。
应用层分层: 架构在垂直拆分(A/B应用)的基础上,进行了水平分层。
1)前端应用层 (Web Tier): 图中的 "A应用服务器" 和 "B应用服务器"。它们变得很薄,主要负责处理页面展示和用户交互,不再直接连接数据库。
2)服务层 (Service Tier): 图中新增的 "分布式服务 i 服务器"。这里封装了核心业务逻辑。
数据访问下沉: "统一数据访问模块" 已经被移动到了 "分布式服务" 内部。这意味着只有服务层能直接接触数据库,Web 层必须调用服务层。
调用关系: A应用/B应用 → \rightarrow → 调用 → \rightarrow → 分布式服务 → \rightarrow → 访问 → \rightarrow → 数据库/缓存/文件。
23.10.2、架构拓扑图
数据存储层 分布式服务层 分布式服务 i 服务器集群 服务器内部 Web 应用层 分布式数据库服务器 搜索引擎服务器 文件服务器 NoSQL 服务器 分布式缓存服务器 分布式服务 i 服务器 1 分布式服务 i 服务器 2 应用程序 本地缓存 统一数据访问模块 B 应用服务器 1 A 应用服务器 1 消息队列服务器 1 客户端 CDN服务器1 反向代理服务器1 负载均衡器1
23.10.3、分布式服务价值
问题: 如果每个模块都要查询用户,代码重复,数据库连接数爆炸,业务逻辑不统一。
解决: 也就是本阶段的架构。把"用户管理"独立成一个 Service。谁要查用户,远程调用这个 Service,不要自己连数据库。
23.10.4、关键技术:RPC
跨服务器的调用通常不直接用 HTTP,而是用性能更高的 RPC。
Dubbo (阿里): Java 领域高性能 RPC 框架,架构师考试必考。
Spring Cloud: 基于 HTTP RESTful 的微服务全家桶。
gRPC (Google): 跨语言的高性能 RPC。
23.10.5、服务治理
当服务从 10 个变成 1000 个,A 应用怎么知道"分布式服务 i"的 IP 地址是啥?如果服务挂了怎么办?这就需要引入服务治理。
23.10.5.1、服务注册与发现
服务启动时,把自己的 IP 写到 Zookeeper / Nacos / Eureka 里。
A 应用调用时,去注册中心查"服务 i 在哪"。
23.10.5.2、负载均衡
A 应用拿到服务 i 的 10 个 IP,自己决定连哪一个(如 Ribbon)。
23.10.5.3、熔断与降级
如果服务 i 响应太慢,A 应用直接切断调用,防止自己被拖死(如 Sentinel / Hystrix)。
二十四、Web应用服务器
虽然现在云原生和微服务盛行,但理解这些经典服务器的定位(是处理静态网页的?还是处理 Java 业务逻辑的?是轻量级还是重量级?)对于架构选型至关重要。
24.1、核心定义
24.1.1、WEB服务器
其职能较为单一,就是把浏览器发过来的 Request 请求,返回 Html 页面。
核心关注: HTTP 协议 、静态资源 (图片/CSS/JS/HTML)、I/O 吞吐量。
代表: Nginx, Apache HTTP Server, IIS。
特点: 处理并发能力强,但不具备执行 Java/PHP/Python 代码的能力(通常需要通过 CGI/FastCGI/Proxy 转交给后端)。
24.1.2、应用服务器
进行业务逻辑的处理。
核心关注: 业务逻辑 、事务管理 、数据库连接 、动态页面生成。
代表: Tomcat, WebLogic, JBoss。
特点: 能够运行具体的业务代码(如 Servlet, EJB, Spring Bean)。
24.2、常见服务器技术
| 服务器名称 | 核心描述 (原课件文字) | 类型归类 (助教注) |
|---|---|---|
| Apache | Web服务器,市场占有率60%左右。它可以运行在几乎所有的Unix、Windows、Linux系统平台上。 | Web 服务器 (静态) |
| IIS | 早期Web服务器,目前小规模站点仍有应用。 | Web 服务器 (微软系) |
| Tomcat | 开源 、运行servlet和JSP Web应用软件的基于Java的Web应用软件容器。 | 轻量级应用服务器 (Servlet 容器) |
| JBOSS | JBOSS是基于J2EE的开放源代码的应用服务器。一般与Tomcat或Jetty绑定使用。 | 中/重量级应用服务器 |
| WebSphere | 一种功能完善、开放的Web应用程序服务器,它是基于Java的应用环境,用于建立、部署和管理Internet和Intranet Web应用程序。 | 重量级应用服务器 (IBM, 商用) |
| WebLogic | BEA WebLogic Server是一种多功能、基于标准的web应用服务器,为企业构建自己的应用提供了坚实的基础。 | 重量级应用服务器 (Oracle, 商用) |
| Jetty | Jetty 是一个开源的servlet容器,它为基于Java的web容器。 | 轻量级应用服务器 (Servlet 容器) |
1)轻量级
能力: 只支持 Servlet/JSP 标准,不支持 EJB、JTA(分布式事务)等复杂的 Java EE 全套规范。
现状: 目前的主流。 随着 Spring 框架的崛起,Spring 在代码层面接管了事务和依赖注入,不再依赖服务器容器,所以 Tomcat 这种轻量级容器配合 Spring Boot 成为了微服务的标配。
2)重量级
能力: 支持完整的 Java EE (Jakarta EE) 规范,自带分布式事务管理、EJB 容器、强大的管理控制台。
现状: 逐渐式微。 价格昂贵,启动极慢,臃肿。通常只在银行、保险等传统核心系统(且使用了 EJB 技术)中还能见到。
24.3、Apache vs Nginx
Apache: 进程/线程模型。稳定,功能模块极其丰富,适合处理动态 PHP 请求。但抗高并发能力不如 Nginx。
Nginx: 事件驱动 (Event-driven) 异步非阻塞模型。优势: 极高的并发处理能力(单机轻松数万连接),内存消耗极低。定位: 现代架构中,通常用 Nginx 做反向代理 和负载均衡,挡在 Tomcat 前面。
二十五、JWT
这是现代 Web 架构(特别是微服务和前后端分离架构)中最核心的身份认证标准 。在架构师考试中,它通常出现在关于无状态认证 、单点登录 (SSO) 和 API 安全 的考题中。
25.1、核心定义
JWT (JSON Web Token) 是一种用于身份验证和授权的开放标准。它是一种轻量级的、基于JSON的令牌,可以在客户端和服务器之间传递信息。
不需要服务器端存储状态,安全地传递【非敏感信息】。
25.2、JWT 的结构组成
JWT 由三部分组成,中间用点(.)分隔:Header.Payload.Signature
25.2.1、头部 (Header)
包含令牌类型和所使用的算法。
json
{
"alg": "HS256",
"typ": "JWT"
}这部分经过 Base64Url 编码后成为 JWT 的第一部分
25.2.2、载荷 (Payload)
包含用户信息和其他元数据。
json
{
"sub": "1234567890",
"name": "xisaiwang",
"iat": 1516239022
}这部分经过 Base64Url 编码后成为 JWT 的第二部分
25.2.3、签名 (Signature)
用于验证令牌的完整性和真实性。
生成逻辑: 使用 Header 中指定的算法(如 HMAC SHA256),将编码后的 Header 和 Payload,加上服务器持有的密钥 (Secret) 进行加密签名。
25.3、JWT 的应用场景
【信息交换】: 安全地在各方之间传输信息。因为有签名,可以确信发送方是谁,且信息未被篡改。
【授权】: 这是最常见的场景。用户登录后,后续每个请求都包含 JWT,允许用户访问该令牌允许的路由、服务和资源。
25.4、JWT vs Session
| 特性 | Session 认证 | JWT 认证 |
|---|---|---|
| 状态存储 | 有状态 (Stateful)。服务端内存或 Redis 必须存 Session ID。 | 无状态 (Stateless)。服务端不存任何信息,只负责验签。 |
| 扩展性 | 差。集群环境下需要做 Session 共享(如 Redis)。 | 极好。因为无状态,扩容服务器无需任何数据同步。 |
| 跨域支持 | 难。Cookie 基于域名,跨域(Cross-origin)处理麻烦。 | 容易 。Token 放在 HTTP Header (Authorization: Bearer <token>) 中,天然支持跨域。 |
| 安全性 | 依赖 Cookie,容易受 CSRF (跨站请求伪造) 攻击。 | 不依赖 Cookie (存 LocalStorage),免疫 CSRF,但需防范 XSS。 |
| 注销 (Logout) | 容易。服务端删掉 Session 就行。 | 难。Token 一旦签发,在过期前一直有效。无法在服务端强制"失效"。(解决办法:黑名单机制,但又变回有状态了)。 |
25.5、安全隐患与最佳实践
1)不要放敏感数据: 特别强调了传递 【非敏感信息】。
原因: Header 和 Payload 只是 Base64 编码,没有加密 !任何人拿到 Token 都能解码看到里面的 sub 或 name。绝对不能放密码!
2)签名密钥 (Secret) 保护
Signature 的安全性全靠这个 Secret。如果泄露,黑客可以伪造任何用户的 Token。
3)加密算法选择
HS256 (对称加密): 只有服务器知道密钥,性能快。
RS256 (非对称加密): 认证中心用私钥签名,业务服务用公钥验签。适合微服务架构(认证中心发证,各微服务只管验票,无需共享密钥)。
25.6、刷新机制 (Refresh Token)
由于 JWT 无法撤销,为了安全,通常将 JWT 的有效期设得很短(如 15 分钟)。为了不让用户频繁登录,架构上通常引入 Refresh Token (长效令牌):
1)Access Token (JWT): 有效期 15 分钟,用于请求接口。
2)Refresh Token: 有效期 7 天,存在数据库/Redis。
3)流程: 当 Access Token 过期,前端用 Refresh Token 去换一个新的 Access Token。如果用户注销,服务端只需删除 Refresh Token 即可阻断后续续期。
二十六、响应式 Web 设计
这是前端架构设计和移动互联网时代最基础的概念。在软考架构师或系分考试中,通常出现在关于用户体验设计 (UX) 、移动端适配方案 或者 Web 表现层架构 的考题中。
26.1、核心理念
响应式WEB设计是一种网络页面设计布局,其理念是:集中创建页面的图片排版大小,可以智能地根据用户行为以及使用的设备环境进行相对的布局。
本质: 一套代码 (One Codebase),跑遍所有设备 (Desktop, Tablet, Mobile)。
核心优势: 相比于为手机专门做一个 m.domain.com 网站,响应式设计维护成本更低,SEO(搜索引擎优化)更友好,因为 URL 是唯一的。
三要素 (架构师必背): 响应式设计 = 流式网格 (Fluid Grids) + 弹性图片 (Flexible Images) + 媒体查询 (Media Queries)。
26.2、布局策略
采用流式布局和弹性化设计:使用相对单位,设定百分比而非具体值的方式设置页面元素的大小。
相对单位: 抛弃固定的像素 px。
1)% (百分比):基于父容器的宽度。
2)em / rem:基于字体大小(rem 基于根元素 HTML 的字体大小)。
3)vw / vh:基于视口 (Viewport) 的宽度/高度。
流式布局 (Fluid Grid): 无论屏幕多宽,布局都能像水流一样铺满容器。
26.3、图片策略
响应式图片:不仅要同比的缩放图片,还要在小设备上降低图片自身的分辨率。
同比缩放: CSS 中通常使用 max-width: 100%; height: auto; 让图片随容器缩小,但不会超过原始尺寸。
降低分辨率 (带宽优化): 这是一个重要的性能优化考点。如果手机屏幕只有 300px 宽,通过 4G 网络加载一张 1920px 的高清大图是极大的浪费。
技术实现: 使用 HTML5 的 <picture> 标签或 srcset 属性,让浏览器根据屏幕宽度按需加载不同大小的图片文件。
26.4、响应式处理流程
核心技术支撑 宽度 > 1200px 宽度 768px ~ 1200px 宽度 < 768px CSS3 Media Queries
媒体查询 Fluid Grid
流式网格 Flexible Images
弹性图片 用户访问网页 浏览器加载 HTML/CSS 检测视口宽度
(Viewport Width) 加载 PC 端布局
(三栏显示) 加载 平板 端布局
(两栏显示) 加载 手机 端布局
(单栏堆叠)
26.4.1、CSS3 媒体查询(根本)
语法: @media screen and (max-width: 768px) { ... }
断点 (Breakpoints): 设计师定义的界限(如 768px, 992px, 1200px),当屏幕宽度跨越这些界限时,CSS 样式会发生突变(比如菜单栏变成了汉堡包按钮)。
26.4.2、移动优先 vs 桌面优先
1)移动优先 (推荐): 先写针对手机的 CSS(默认样式),然后通过 @media (min-width: ...) 为大屏幕增加样式。
优点: 手机端加载的 CSS 代码最少,性能最好。符合当前移动互联网趋势。
2)桌面优先: 先写 PC 端样式,再通过 @media (max-width: ...) 去适配小屏幕。
缺点: 手机端往往下载了冗余的 PC 端样式代码。
26.5、Viewport Meta 标签
这是响应式网页的起手式。如果不加这就不是响应式。
html
<meta name="viewport" content="width=device-width, initial-scale=1.0">解释: 告诉浏览器,不要把网页按照"缩小的 PC 网页"来渲染,而是让视口宽度等于设备物理宽度,初始缩放比例为 1:1。
二十七、中台架构
27.1、中台的核心定义与起源
定义: 中台是一套结合互联网技术和行业特性,将企业核心能力以共享服务 形式沉淀,形成 "大中台、小前台" 的组织和业务机制,供企业快速低成本的创新。
本质: 都是对企业通用进行业务创新的企业架构能力在不同层面的沉淀,并对外能力开放。
Supercell: 芬兰移动游戏巨头(部落冲突、皇室战争),员工仅200多人,具有小团队快速开发能力(依靠中台资源支持),后被腾讯收购。
阿里: 2015年参观 Supercell,而后推行中台战略。
27.2、大中台、小前台
痛点(烟囱式架构): 以前做淘宝、天猫、聚划算,每个部门都自己写一套"用户登录"、"订单处理"、"支付接口"。这叫"重复造轮子",且数据不互通(数据孤岛)。
小前台(Agile Front-end): 前线业务部门(如抖音、头条)要轻量级,只负责业务创新和用户交互,能够快速试错,随时调整。
大中台(Stable Middle-end): 后方火力支援要强大。把通用的"用户中心"、"支付中心"下沉到中台,像积木一样提供给前台。前台想做一个新APP,直接调接口就行,不用从头写。
27.3、阿里中台演进之路
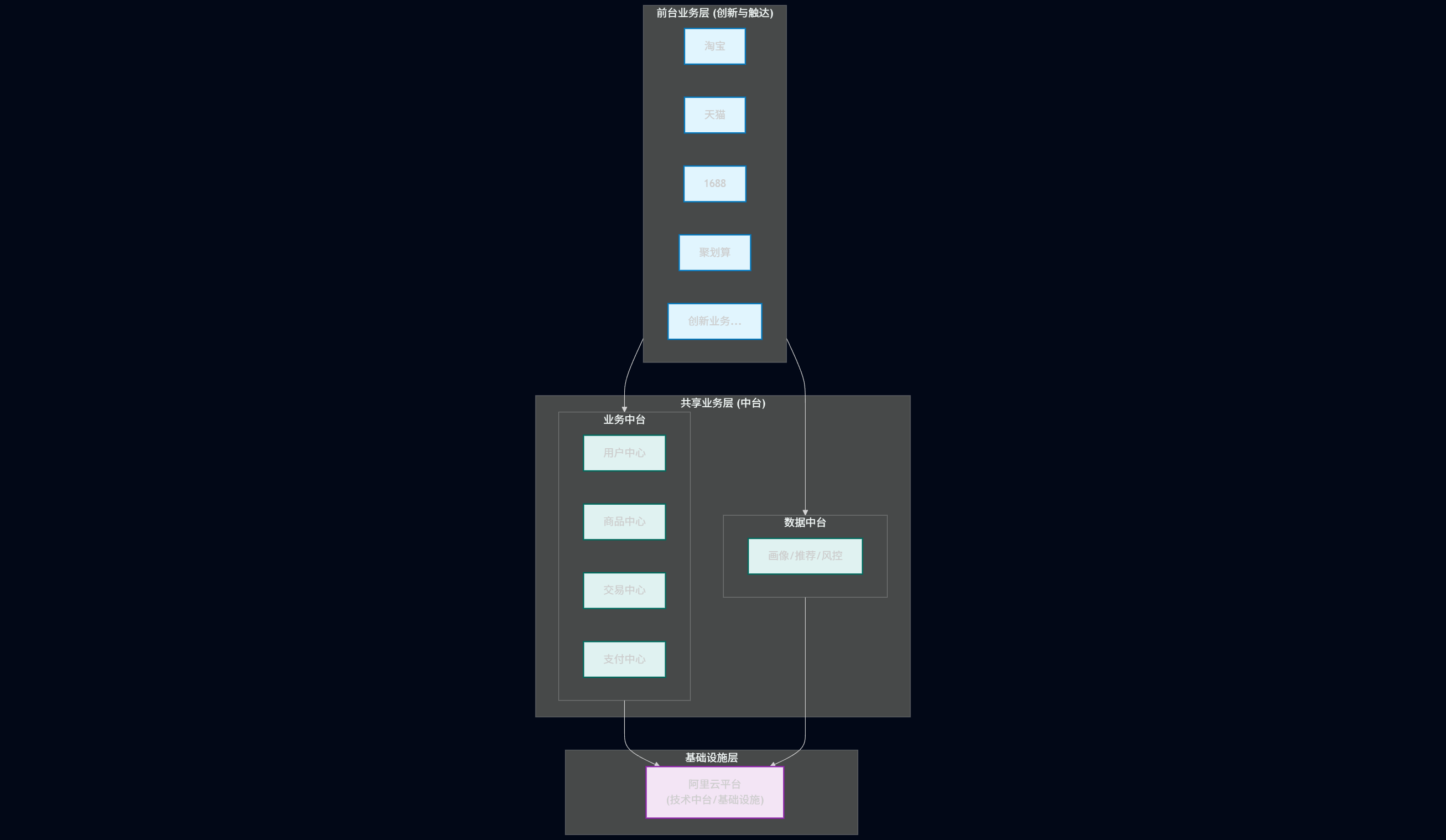
淘宝 (单体/独立)
淘宝 + 天猫 (出现重复建设)
淘宝 + 天猫 + 共享业务事业部 (开始抽取公共部分)
前台(淘宝/天猫/1688...) + 共享业务(中台) + 阿里云平台 (成熟的中台架构)
27.4、中台的三大分类
| 中台类型 | 定义 (原课件) | 示例功能 |
|---|---|---|
| 业务中台 | 提供重用服务,例如学员中心 、课程中心 之类的开箱即用可重用能力。 | 订单中心、支付中心、用户中心。 |
| 数据中台 | 提供数据整合分析能力,帮助企业从数据中学习改进,调整方向。 | 用户画像、精准推荐、销量预测。 |
| 技术中台 | 提供技术重用组件能力,帮助解决基础技术平台的复用。 | 中间件、分布式存储、AI、负载均衡。 |
27.5、业务中台详解
关注点: 在线业务处理。
场景: "多个电商渠道使用一个下单服务"、"将多个支付通道抽象建立成一个支付API"。
关键词: 统一接口、业务复用、实时性。
27.6、数据中台
关注点: 数据价值挖掘。
场景: "根据一个用户的手机号,获取对应的画像、用户的标签"、"通过一个订单编号,获取可能的商品推荐清单,从而做到交叉销售"。
关键词: 汇聚整合、标签化、辅助决策。
27.7、数据中台的核心能力
27.7.1、数据汇聚整合能力
把散落在各个系统的 Excel、MySQL、Log 日志全收集起来(ETL、Data Lake)。
27.7.2、数据提纯加工能力
脏数据清洗、统一数据标准(OneData)、建立数据模型。
27.7.3、数据服务可视化
数据不能只躺在库里,要变成 API 接口或报表(BI),让业务系统能看懂、能调用。
27.7.4、价值变现方面
数据必须赋能业务(如提升了点击率、降低了坏账率),产生 ROI。