
作者:Anton Borisov
开源无国界,在本期「StarRocks 全球用户精选案例」中,我们走进 Fresha------全球领先的美业、健康与自我护理行业一站式平台,服务于全球数以百万计的消费者与商家。
随着业务规模的快速增长,Fresha 曾面临典型的架构失配挑战:Postgres 频繁因 OLAP 需求过载,而 Snowflake 在应对高频准实时分析时又面临成本与时效性限制。为此,Fresha 引入了 StarRocks,在保持 Lakehouse 为唯一事实源的前提下,构建了兼具"联邦查询"与"内部表加速"的混合架构。
自 2025 年春季上线以来,Fresha 成为英国最早在生产环境规模化落地 StarRocks 的先行者之一。本文将深度拆解其选型逻辑、落地架构以及性能优化等方面的实战经验。
现状与挑战
到 2024 年中期,Fresha 的数据平台呈现出一种极其矛盾的状态:虽然原有的技术栈勉强能跑通,但每个组件都在承担着超出其设计初衷的工作:
-
Postgres (OLTP):原本用于支撑面向用户的业务系统,却承担了大量的 Ad-hoc 和产品仪表盘需求。宽表 Join 和重度聚合导致了 Head-of-line blocking 和 Noisy neighbor 效应,甚至偶尔会引发"为什么下单接口变慢了?"这种生产事故。
-
Snowflake (BI/数据导出):虽然能很好地处理传统 BI 看板和大规模数据导出,但在应对高频交互、准实时的产品及运营分析时,无论在成本还是响应速度上都难以为继。
这种架构失配导致高峰期系统响应变慢、仪表盘延迟波动。我们意识到,必须寻找一个能够同时填补两个缺口的分析引擎:
-
在不消耗 Postgres 资源的前提下,能够高效处理海量历史数据。
-
支持标准协议以降低迁移成本,且随着业务增长,性能与扩展性需保持高度可预测。
核心诉求:填补拼图的缺口
为此,我们为理想的分析工具划定了几个硬性约束:
-
将历史分析需求从 OLTP 路径中剥离。
-
坚持开放格式优先(基于对象存储的 Iceberg/Paimon),将 Lakehouse 作为唯一事实源,在不增加 Postgres 存储负担的前提下处理历史数据。
-
支持 MySQL 协议、标准驱动,尽量减少改造与工具替换成本。
-
扩展能力可预期:能从容应对流量高峰,而非耗费数天进行容量规划。
-
核心链路达到秒级至分钟级时延,其余链路保持分钟级。
-
低运维复杂度:减少定制化管道与额外系统。
为什么选择 StarRocks?
基于上述要求,StarRocks 凭借其混合查询模式脱颖而出:它既能通过外部 Catalog 实现对开放格式数据的联邦查询(保证广度),又支持将时序敏感的指标直接接入内部列存表(保证深度与性能)。
-
**原生列式存储:**支持支持明细、聚合及主键模型,并支持高吞吐写入(如 Flink 或 Routine Load)。这是实现核心指标"准实时"可用的最短路径。
-
**湖仓加速能力:**通过 Catalog 直接读 Iceberg / Paimon / Hive 等开放表格式,并将 Filter 与 Projection 下推以减少对象存储扫描开销------这是处理大规模历史数据的理想方案。
-
**物化视图自动查询改写:**可定义增量汇总或预关联,优化器会自动将符合条件的查询改写为命中对应的物化视图。
-
**存算分离架构:**计算资源可按需弹性扩缩,无需在节点间重新平衡数据,确保了业务高峰期成本与时延的可预测性。
-
MySQL 协议与生态兼容:与常见 BI 工具及主流客户端库开箱即用,工程师可以快速接入与落地。
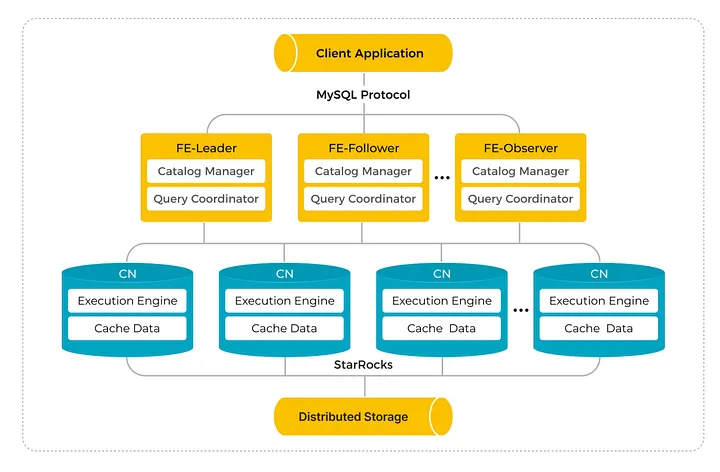
(StarRocks 采用存算分离架构:客户端通过 MySQL 协议连接到 FE 节点(Leader、Follower/Observer),由 FE 负责 Catalog 管理与查询协调;CN 节点承担实际查询执行并进行数据缓存。持久化数据存放在分布式存储中,因此扩展算力时只需要新增 CN 节点,无需对存储数据做重分布。)
新架构一览
你可以将整个平台想象成一条统一的数据摄取主干,并延伸出三条链 路:一条是进入 StarRocks 内部表的实时链路 ,一条是进入 Iceberg/Paimon 的历史链路 ,以及一条进入 Elasticsearch 的搜索链路 。StarRocks 居中作为统一的 SQL 入口 。工程师通过标准的 MySQL 协议接入,即可实现跨三条链路的关联查询,而无需关注数据的存储位置。
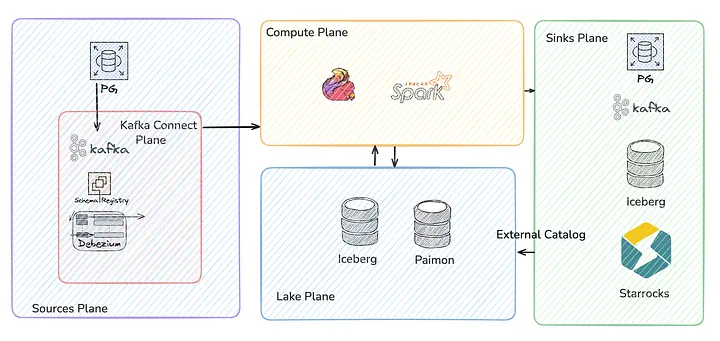
(Fresha 的高层数据流如下:以 Postgres 为主的数据源通过 Debezium + Schema Registry 接入 Kafka;计算层使用 Flink 与 Spark;湖仓层采用 Iceberg + Paimon;下游由多个 Sink 承接,其中 StarRocks 作为统一的 SQL 查询入口。StarRocks 通过外部 Catalog 访问湖仓数据,计算层则分别服务实时与历史链路,对湖仓进行读写。)
1. 写入主干(Ingestion spine)。 它实时捕获 Postgres 的 CDC 变更事件并流向 Kafka,同时配合 Schema Registry 使用 Avro 格式进行序列化。这为我们提供了一个强类型、可平滑演进的事件封装层,既满足了 CDC 需求,也为下游消费者构建了一个单一、可靠的数据主干。
Kafka 在这里承担了扇出点(Fan-out point)的角色:Flink 与 Spark 从同一个事实源获取数据,并根据不同的访问模式,将数据写入到最适合的存储引擎中。
2. 实时链路(StarRocks 内部表)。针对时效性达"秒级"、且用户体验极度依赖尾部延迟(Tail Latency)稳定性的场景,Flink 会将数据直接写入 StarRocks 的内部列存表。
在表模型选择上,我们针对不同业务场景进行了适配:主键模型(Primary Key)用于承载需要实时保新的变更流;聚合模型(Aggregate Key)用于执行指标预计算(如 Sum/Count/Min/Max);而明细模型(Duplicate Key)则负责接收那些后续需要进行 Compaction 或异步汇总的流式数据。
这种设计刻意压缩了数据路径:即"Kafka → Flink → StarRocks → Dashboard/API"的极短链路。通过将对象存储从核心路径中剥离,我们能够依靠 StarRocks 的横向扩展来应对流量峰值,而不必受限于远程存储的 List 或 Get 请求。
在这些内部表之上,我们为常用的聚合与预关联定义了物化视图。StarRocks 的优化器会自动将符合条件的原始查询透明改写,使其直接命中这些物化视图。这使得我们的研发团队只需编写最基础的 SQL 即可。
**3. 历史链路(Iceberg/Paimon)。**并非所有查询都具有极高的紧迫性,而且几乎没有哪类查询仅关注"当下"。我们将业务侧 CDC 数据落地到 Paimon;同时,Flink 和 Spark 负责将长期的事实表与缓慢变化维(SCD)写入对象存储上的 Iceberg。其中,Spark 处理更为繁重的工作: backfill、repair、compaction ,以及生成跨大跨度时间范围的一致性快照。
这种模式为我们提供了低成本且持久的历史存储,并支持完善的 Schema 演进和分区机制;同时也确保了 Lakehouse 作为唯一事实源的地位。StarRocks 通过外部 Catalog 直接接入 Iceberg 和 Paimon,使得历史查询能够在不迁移数据的情况下,直接在开放格式上进行联邦查询。当回灌数据落地后,我们可以重建或刷新 StarRocks 内部相关的物化视图,使历史数据的查询体验尽可能接近实时链路。
4. 搜索链路(Elasticsearch)。部分工作负载并非严格的关系型数据,例如:模糊匹配、前缀/后缀搜索、分词以及相关性评分。我们利用 Flink 或 Spark,从相同的 Kafka/Lakehouse 事实源中将这类数据索引至 Elasticsearch,随后通过 StarRocks 的 experimental Elasticsearch Catalog 将其暴露给开发人员。
这一方案的核心价值不在于引入了 ES,而在于开发人员不再需要直接调用 ES 接口。从他们的视角来看,一个搜索密集型的索引仅仅是另一张可以被 SQL 关联查询的"表",且使用的仍是原有的分析连接。这种设计降低了认知负荷,同时也实现了基础设施接入层的集中化。
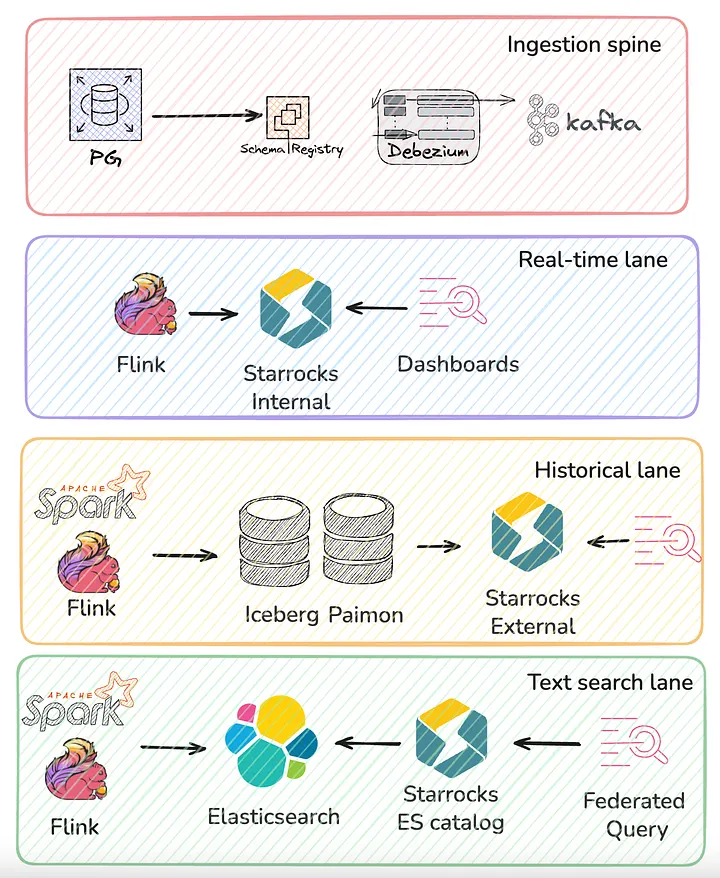
(以 Kafka 为中心的"写入主干"由 Debezium + Schema Registry 提供强类型的 CDC 数据,并向外分为三条链路:实时链路(Flink → StarRocks 内部表 + MV → Dashboard/API);历史链路(Flink → Paimon;Spark/Flink → Iceberg;StarRocks 通过外部 Catalog 联邦查询并按需刷新 MV);搜索链路(Spark/Flink → Elasticsearch;通过 ES Catalog 以 SQL 方式进行关联查询)。)
StarRocks 作为统一入口,通过一个 MySQL 端点,实现了热数据、历史数据与搜索链路的统一:时延最敏感的数据切片落在内部列式表;长期事实与维度数据保留在 Iceberg/Paimon;文本密集型数据写入 Elasticsearch。StarRocks 通过外部 Catalog 统一接入这三类存储,因此工程师只需编写标准的 SQL,无需关注数据的具体存放位置。
StarRocks 的优化器与物化视图改写机制会自动规划最优查询路径:优先命中内部表或物化视图,必要时则下推至 Lakehouse 或 Elasticsearch 执行。我们采用存算分离模式,实现了计算与存储解耦,在应对业务高峰扩缩容时无需重分布数据,保障了尾部延迟的稳定与运维的极简。数据回灌统一落入 Lakehouse,并通过联邦查询或物化视图刷新实现感知。这种架构确保了底层数据演进的同时,上层查询接口也能保持稳定。
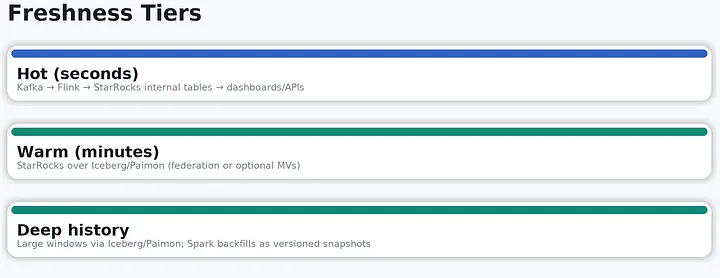
(在生产环境中按数据新鲜度做了分层:Hot(秒级)通过 Kafka → Flink → StarRocks 内部表;Warm(分钟级)由 StarRocks 直接查询 Iceberg/Paimon(联邦查询,必要时配合 MV 加速);Deep history(深度历史)保留在 Iceberg/Paimon 中,由 Spark 以版本化快照方式进行回灌与补齐。)
案例:首页分析查询性能优化
我们的首页承载着面向客户的分析功能------包括"优秀员工"(双月对比)、"热门服务"以及实时销售动态。起初这些功能由 Postgres 支撑,在小客户场景下表现尚可,但在大客户侧却遭遇了性能瓶颈:页面加载动辄 15-20 秒甚至直接超时,还对 OLTP 业务造成了严重的连带伤害
这是典型的失效模式:一次冷启动查询击穿了 buffer cache;首个请求在拖回海量数据页的过程中超时,后续请求虽能"侥幸"成功,却已污染了内存空间,进一步拖慢其他无关的事务。
我们决定将这些视图迁移至 StarRocks,并提出了一个硬性要求:分钟级的数据时延。用户不能在完成一笔交易后,因为看不到实时反馈而产生困惑。我们最初尝试使用 Iceberg,功能上没问题但运行层面不稳定------高频写入产生的大量小文件和 Compaction 压力,使分钟级时延难以持续保证。于是,热点链路切换至 StarRocks 内部表,并将 Iceberg/Paimon 继续作为历史数据的长期记录。
关键点在于,我们并未直接使用物化视图,而是基于内部表构建了分层 SQL 视图。这样开发者可以复用业务语义,而无需重复定义。整体架构如下:
-
由 Flink 写入的基础表 rt_sales(Debezium → Kafka → Flink → StarRocks);
-
作为统一语义层的 vw_sales_enriched 视图,用于补全业务关联并应用状态口径;
-
用于定义"最近成交"的 vw_recent_sales 视图(包含时间窗口与可计入的状态范围);
-
在其之上构建的高层视图,例如 vw_top_employees_2m 、vw_top_services,均基于前述层级组合计算得到。
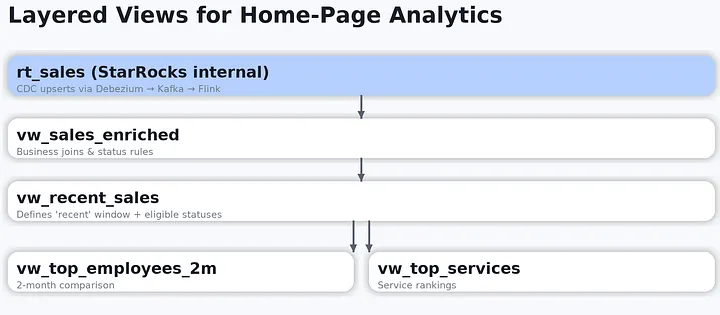
(首页分层视图示例:rt_sales (CDC upsert 写入)→ vw_sales_enriched (业务关联、状态口径、分区过滤条件,以及衍生字段/过滤字段,例如 day、is_eligible、provider_bucket)→ vw_recent_sales → vw_top_*。)
由于业务语义都封装在视图里,产品团队只需要查询 vw_top_* 和 vw_recent_*;不必记住哪些状态需要计入、"recent"具体怎么定义,或或者销售数据如何关联补全。与此同时,StarRocks 的优化器会将过滤条件与列裁剪下推至整个视图栈,在无需维护物化视图刷新任务的前提下,依然获得高质量的执行计划质量。
**最终成效:**即使在最复杂的过滤与聚合条件下,首页分析查询的响应时间也缩短至 200 毫秒左右,并达到了用户预期的分钟级时效性。Postgres 不再被当作"临时缓存"来透支,确保了 OLTP 事务的响应速度,而首页产生的分析性并发压力则由 StarRocks 承接。
深度历史数据依然保留在 Lakehouse 中(通过 Spark 回灌至 Iceberg/Paimon),而这套分层视图可以根据需要进行跨源联邦查询,从而覆盖更长的时间窗口。这意味着我们无需为不同场景开发多套代码,仅需维护一套可复用的语义定义。
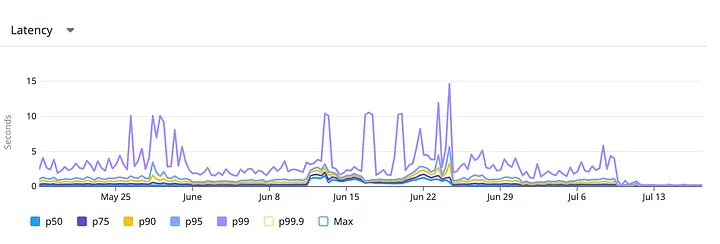
(启用 StarRocks 查询链路(通过 feature flag)前后的延迟分位对比:左图为旧的 Postgres 方案,查询经常出现多秒级峰值;右图为开启 StarRocks 后,p95 降至接近 1 秒以内,并且长尾(p99/p99.9)的峰值基本消失。)
实践中的问题与解决方案
实现无误的 DDL 迁移
我们构建了一套 ActiveRecord 风格的迁移工具:采用层级命名规范,为每项变更编写显式的 up/down SQL,并在 StarRocks 中维护一个声明式的 Schema 版本号(这是一个原子递增的单一事实源)。
由于 StarRocks 的许多 DDL 操作是异步执行的,该工具会持续轮询变更状态,直到所有后台任务达到最终的 FINISHED 状态后才会更新版本号;一旦失败,它将通过配对的 down SQL 进行回滚。最终效果是:实现了一套与 StarRocks 语义对齐、可逆且支持协作安全的 Schema 演进流程。
查询性能分析
我们统一使用 EXPLAIN ANALYZE 生成的 Profile,并梳理出一套符合常识的核心指标(扫描字节数、命中的分区数量、Join 类型、P50/P95)。这让所有人对"什么变慢了"拥有了一致的判断框架:是分区过多、Join 策略不合适,还是由于过滤条件无法下推。
分区策略:不向业务代码"泄露"底层细节
我们按时间进行分区,并按业务键(例如 provider_id)进行分桶。为了防止开发人员因疏忽导致全表扫描,我们将过滤谓词封装在视图内部。
例如,vw_recent_sales 视图中直接定义了"Recent"的时间范围及合规状态,更高级别的视图则基于此构建。Planner 依然能将过滤条件透传至底层引擎,但调用者无需再记忆复杂的分区计算逻辑。
维度关联:避免大规模 Shuffle
大事实表与小维度表的关联采用 Broadcast 模式;大事实表与大维度表之间的关联则优先使用 Colocate 模式(通过对齐分桶键与分桶数实现),在无法满足 Colocate 条件时则退而求其次使用 Bucket-shuffle。
我们对维度表进行版本化管理,并尽可能精简字段(Narrow Tables)以适配 Broadcast;当某个维度表规模增长到不再适合 Broadcast 时,我们会将其提升至 Colocate Group 中,并调整其分桶策略以匹配主事实表。
数据跳读与索引取舍
为了降低范围查询和点查的成本,我们充分利用了 StarRocks 的 Zone Map(每个 Segment 的最大/最小值过滤)以及基于排序列的 prefix/short-key index。此外,我们仅在能产生实质性收益(Move the needle)的场景下,有选择性地添加 Bloom Filter 或 Bitmap 索引。
我们的原则是:在添加索引前,必须通过 Profile 证明其确实减少了扫描字节数;同时,定期清理不再使用的旧索引。
Schema 演进
所有 Schema 变更都始于 Avro Schema Registry 的兼容性检查;数据写入方(Writers)最后才进行发布。内部表遵循"仅增量"原则,优先添加新列;视图层则采用版本化定义(如 vw_sales_enriched_v2),并配合一个名为 vw_sales_enriched 的视图指针,待数据 Backfill 完成后再进行原子切换。Flink Sink 均具备幂等性或通过主键(PK)进行数据对齐。此外,CI 环节会拦截任何可能导致下游模型失效的变更。
总结
StarRocks 正逐渐成为我们日常分析中可靠的核心工具:它提供了统一的 SQL 接入层,将实时链路、历史链路与搜索链路有机统一;在存算分离架构下,性能稳定可靠;同时具备开发者友好的易用性,让团队能够通过平实的标准 SQL 快速交付业务,而非陷入复杂的定制化管道中。
通过这一套架构,我们实现了预期的工程目标:内部表上的准实时读取、开放格式上的历史数据联邦查询,以及通过 ES Catalog 实现的搜索关联查询。更重要的是,在实现这一切的同时,我们依然保持了 Lakehouse 作为唯一事实源的架构地位。