在学习 C 语言的过程中,printf 应该是我们打交道最多的函数了。但你是否思考过下面的问题:普通的函数参数个数都是固定 的,为什么 printf 可以接受无限个参数?编译器又是怎么知道我们传了几个参数的?为什么 %c 明明是打印字符,底层却要按 int 类型来处理?
在这篇文章,我们就从零手写一个 my_printf,彻底弄懂 C 语言 变参函数 和 函数调用栈 的底层原理。
1. 核心原理
1.1 编译器
对于我们比较常见的普通函数,他们的参数类型和数量一般是固定的,像这样:
c
void func(int a, int b);这种情况下,编译器在编译时非常清楚,调用这个函数需要传递 2 个 int。
我们再来看看printf函数的声明:

1.1.1 restrict 的作用
在进入咱们的正题之前,我们先需要了解一下图中的restrict 到底是起了什么作用。restrict 是 C99 标准引入的关键字,通俗一点来说,它的作用是告诉编译器:这个 const char * 指针是访问它所指向内存的唯一入口,除此之外,别无其他指针,从而使得编译器可以放心大胆地去优化代码。
仅仅这样语言描述一下,可能还是有点不够形象,为了帮助大家理解,我下面举个例子:
编译器在优化代码时,其实是非常保守的,因为它非常害怕两个不同的指针实际上指向同一块内存(指针别名) 。请看下面的代码:
c
void add(int *a, int *b, int *val)
{
*a += *val;
*b += *val;
}这个add函数接收三个int *类型的参数,分别是a,b,val,然后将val所指向内存的值分别加到a和b所指向内存中的值。
上面其实也提到了,编译器优化代码时是很保守 的。我们来梳理一下这个过程,编译器在第一步会读取 * val 的值,然后加到 * a中去,第二步,再次读取 * val 的值,然后将读取到的 * val的值加到 * b中去。
可能有人这样想:第一步不是已经读取了 * val 的值了吗?为什么第二步还要再读取一遍呢?直接使用第一步读取到的值不行吗?
而编译器是这样想的:如果在传参数是 a 和 val 指向的是同一个地址 怎么办?第一步的操作改变了 * a 的值,同时也改变了 * val 的值,如果还使用改变之前的 * val 的值,那计算不是出错了吗?因此,在编译器不能确保两个指针指向的不是同一块内存时,它在使用这块内存中的值之前都会去内存里面重新读取一下,以防计算发生错误。
而如果我们加上restrict,像下面这样:
c
void add_2(int *a, int *b, int *restrict val) {
*a += *val;
*b += *val;
}这就相当于告诉编译器,* val 的值绝对不会被 a 或 b 修改,这样编译器在第一次读取了 * val 的值后,第二步时直接就能使用,省得再回内存里面去查。这样也会带来相应的性能提升。
1.1.2 restrict 案例分析
为了让大家能够更清晰地看到这个现象,我进行了下面的实验:
c
void add(int *a, int *b, int *val)
{
*a += *val;
*b += *val;
}
void add_2(int *a, int *b, int *restrict val)
{
*a += *val;
*b += *val;
}
这段代码add函数的 val 我没加restrict,而add_2函数我加了。然后可以使用下面的命令,将这段代码编译成汇编代码:
bash
gcc -O2 -S demo.c -o demo.s-O2 选项是开启编译器优化,-S是生成汇编代码。
下面是我截取的部分汇编代码:
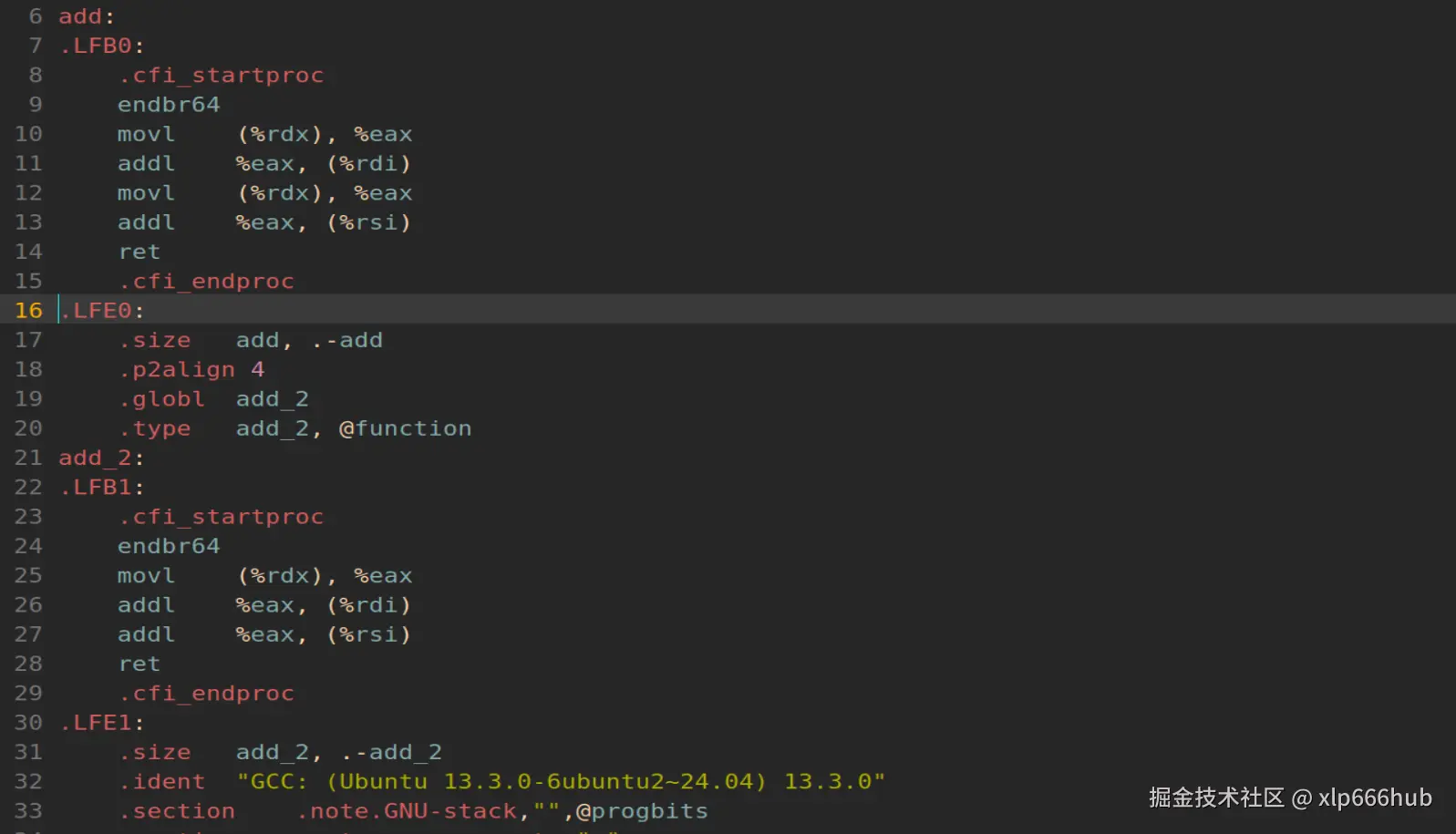
生成的汇编代码中,我们只需要看关键部分,对于add函数,我们需要看第 10-13 行,对于add_2函数,我们需要看 25-27 行。
在我使用的 64 位 Linux 系统中,函数参数是通过寄存器传递 的,有固定的顺序 。第一个参数 a 放在寄存器 %rdi 中,第二个参数 b 放在寄存器 %rsi 中,第三个参数 val 存放在寄存器 %rdx 中。而 %eax 是一个通用寄存器,用于临时存放数据。
在了解了一些必备的知识后,我们先来看函数add的关键部分。第10行,movl (%rdx), %eax ,去val指向的内存地址 %rdx ,把里面的数字取出来放到 %eax 中。第11行,addl %eax, (%rdi),将 %eax 中的数加到a指向的内存地址 %rdi 中去。在看第12行,又去val指向的 %rdx ,把里面的值取出来放到 %eax 中,第13行,addl %eax, (%rsi),把 %eax 中的数加到 %rsi 中去。在我们看来,第二次再去读 * val 的值是多此一举的,但是编译器害怕旧值被修改,就只能再去读一次,拿到最新的值。
再来看函数 add_2 ,这里的val加了restrict关键字,我们看看情况是否有所不同。第25行依然是去val指向的内存,将值取出来放到 %eax 中,第26行将 %eax 中的值加到a所指向的内存地址 %rdi 中去。而到了第27行,它没有再去读一遍 * val 的值,而是直接使用旧的 * val 的值直接加到b指向的内存 %rsi 中去。
到这里相信大家已经很清晰了。内存是慢速设备,而寄存器速度是极快 的,加上restrict关键词,我们节省了一次去内存读取的开销。
1.1.3 小结
在了解了restrict之后,新的问题有浮出水面了。回过头去看printf函数的声明,编译器只能知道有一个固定参数 format,他不知道后面还有没有参数,更不知道后面参数是什么类型的。既然编译器不知道,那么printf是怎样正确的打印出内容的呢?答案藏在下一章的内容里面。
1.2 函数调用栈
假如我们在32位系统下调用下面的代码:
c
my_printf("Num:%d", 100);此时,我们来看一下函数调用栈的布局:

注:现代 x64 或 ARM 架构通常优先使用寄存器传参(上面汇编的解释中提到过),但 stdarg.h 的封装让我们在逻辑上还是可以像操作栈一样去处理它们,核心思想是不变的。
首先,我们要知道,栈是从高地址向低地址生长的。可以仔细观察一下图中左边函数调用栈的布局,最上面的是之前的栈帧。
其次,我们还要知道,函数参数的入栈顺序是从右向左 的。在我举的这个例子里面,最右边的参数100 先入栈,它紧贴着之前的栈帧,然后它左边的参数(也就是 "Num:%d" 的所在的地址)入栈,紧贴着参数100存放。最后函数的返回地址入栈。
理解了这张图,那一切就都明了了。虽然编译器只知道第一个固定参数 ,而不知道它后面有什么,但根据 C 语言的调用约定,变参一定紧紧挨着固定参数存放,并且位于更高的地址。
下面我们来顺一下整个流程,参数format的类型是const char *,也就是说它本身是一个指针 ,真正的字符串内容 "Num:%d" 存放在只读数据区(.rodata) ,在32为系统下它的大小是 4 个字节 ,而本身存放 format 的地址我们也是知道的。我们要做的,是拿到format变量本身在栈上的地址,然后加上format的大小,也就是4个字节,这样指针就跳过了format占据的地址,从而能够得到变参(100)的地址。同理,就算后面还有其他变参,我们也能通过地址偏移的方法找到他。
如果使用的是64位系统 ,那么format的大小就会改变为 8 个字节,但是原理还是这样的。
这也就是为什么编译器并不知道format后面的参数是什么,而printf却能正确打印出来的原因。
1.3 变参宏的本质
理论上,我们确实可以手动通过 (char*)&format + 4 来找到下一个参数。
这里先简要提一下为什么取format的地址后要转为char *类型,这就涉及到C语言中一个基础知识点------指针运算 。在C语言中,指针加减的单位不是字节,而是它指向的数据类型的大小 。我把指针转为char *类型,是为了能够让它以字节为单位移动。在转换类型之后,(char*)&format的数据类型为char *,它指向的是char类型,长度为 1 个字节,所以(char*)&format + 4,指针就会精确的移动4个字节,刚好跳过format变量。如果不转的话,&format 的类型是 char**,它指向的是 char* (指针,在32位系统里面大小为 4 ),再给他加上 4 ,那么这个指针就会移动16个字节,已经错过了我们要找的变参。
但直接写硬编码 的数字(+4)是非常危险 的。因为在 64 位系统上它应该是 +8,在某些特殊架构上对齐方式可能更复杂。因此,为了解决跨平台问题,C 语言在 <stdarg.h> 中封装了一套标准宏。
为了弄懂这些宏执行的操作和我上面描述的是否一致,我查看了现代Linux环境下<stdarg.h>的源码。结果发现GCC的<stdarg.h>的实现如下:

这里要简单补充一下,普通的头文件(如 stdio.h)通常由 C 标准库提供,放在 /usr/include。但 stdarg.h 非常特殊,它涉及参数传递的底层细节(如寄存器使用、栈帧布局),这些是依赖编译器实现 的。因此,GCC 不会使用系统默认的 stdarg.h,而是会优先使用自己私有目录下的版本。
因此我们要使用下面的命令去查看:
bash
vim $(gcc -print-file-name=include/stdarg.h)为什么要使用这条命令呢?因为gcc安装目录版本众多,路径随版本变化,而这条命令能获得gcc实际使用的文件并使用vim编辑器打开它。
现在我们来看一下<stdarg.h>的源码,全是 __builtin_ 开头的函数。这是因为现代 CPU 架构(如 x86-64)的参数传递非常复杂(优先使用寄存器,寄存器用完了才压栈 ),单纯的指针加减法已经无法搞定了。编译器为了极致的性能优化,选择把这些操作直接内置在编译器内部。
为了能够让大家看到实际的C语言实现,我翻出了 Linux 0.11 内核源码 ,我把源码的内容直接放在下面的代码块中(注:原汁原味,我一点没改):
c
#ifndef _STDARG_H
#define _STDARG_H
typedef char *va_list;
/* Amount of space required in an argument list for an arg of type TYPE.
TYPE may alternatively be an expression whose type is used. */
#define __va_rounded_size(TYPE) \
(((sizeof (TYPE) + sizeof (int) - 1) / sizeof (int)) * sizeof (int))
#ifndef __sparc__
#define va_start(AP, LASTARG) \
(AP = ((char *) &(LASTARG) + __va_rounded_size (LASTARG)))
#else
#define va_start(AP, LASTARG) \
(__builtin_saveregs (), \
AP = ((char *) &(LASTARG) + __va_rounded_size (LASTARG)))
#endif
void va_end (va_list); /* Defined in gnulib */
#define va_end(AP)
#define va_arg(AP, TYPE) \
(AP += __va_rounded_size (TYPE), \
*((TYPE *) (AP - __va_rounded_size (TYPE))))
#endif /* _STDARG_H */源码第 9,10 行定义了一个宏 __va_rounded_size,这行代码看着复杂,其实只做一件事,就是向上取整到 int 的倍数 。也就是说如果你传char,算出来是 4,如果你传int,算出来还是 4,如果你传double,算出来就是 8 。这也解释了为什么我们在手动推导时,默认步长是 4 的原因,本质上是为了保证栈上的内存对齐。
然后请看源码第 13 行,相信大家已经看到了char *强转,&LASTARG 取出的是固定参数的地址,如果不转成 char *,指针加法会按照该类型的步长移动,转成 char * 后,加法就变成了字节级 的移动。这也证实了必须要将指针转为单字节步长 ,才能精确跨过固定参数,指向变参的第一个元素。
再看源码第 24 行,这里的操作非常有意思,它利用了 C 语言的 逗号表达式 :(A, B)。规则是:先执行 A,再执行 B,并且整个表达式的值等于 B 的值。 在逗号前,游标 AP 直接向前移动 ,跨过了当前这个参数,指向了下一个参数 的起点。逗号后,用新的参数起始地址减去当前参数的大小,就是当前参数的起始地址,把这个地址强转为TYPE *,再解引用,最后拿到数据。最后这个宏的值就是拿到的数据 。至于逗号后面为什么要强转为TYPE *然后再解引用,这是因为解引用后取出数据的长度是根据被解引用的这个东西的数据类型决定 的,如果这个数据类型不是TYPE *,那么解引用取出的数据长度自然就不符合我们的预期。
2. 默认参数提升
搞懂了底层的宏定义,我们终于可以开始写代码了。但在动手之前,必须先讲一个大家可能会踩的坑。
我们在实现 my_printf 处理 %c字符时,如果没有了解过这个细节,直觉上会这样写:
c
char c = va_arg(ap, char); //错误写法这样写会导致指针偏移量出现错误,甚至读到乱码。
2.1 为什么不能直接取char
不知道大家对我们 1.3 节中提到的__va_rounded_size这个宏还有印象吗。无论你传入的数据类型多小,栈上的槽位最小也是 sizeof(int)。在 C 语言的变参函数调用约定 中,有一条默认参数提升规则:
char、short 在入栈前会自动升级为 int。
float 在入栈前会自动升级为 double。
2.2 原理分析
如果你写 va_arg(ap, char): 宏计算出的步长是 sizeof(char) = 1 字节。游标 AP 只往后移了 1 个字节。但实际上,栈里那个字符占了 4 个字节。
结果就是指针错位 ,后面的所有参数读取全乱套。
那么怎样写才是正确的呢?既然编译器把 char 变成了 int 塞进栈里,那我们取的时候,也必须按 int 去取,然后再强转回来。想下面这样:
c
int val = va_arg(ap, int); // 按照 int 的步长去栈里捞数据
my_putchar((char)val); // 强转回 char 使用3. 核心代码实现
理论现在已经了解的差不多了,我们现在来直接使用系统调用write实现一个my_printf。
3.1 基础函数编写
printf 的核心难点在于把整数转换成字符串 ,例如把整数 123 变成字符数组 {'1', '2', '3', '\0'}。标准库有 itoa,但我们要自己写一个。请看下面代码:
c
#include <unistd.h>
#include <stdarg.h>
//往屏幕写一个字符
void my_putchar(char c)
{
write(1, &c, 1);
}
//往屏幕写字符串
void my_putstr(const char *str)
{
int i = 0;
while(str[i]) my_putchar(str[i++]);
}
//将整数 value 转换为字符串并打印
//base表示 10 进制或 16 进制
void my_itoa(int value, int base)
{
char buffer[32];
int i = 0, is_neg = 0;
// 0 是特殊情况,单独处理
if (value == 0)
{
my_putchar('0');
return;
}
//处理负数 (这里只处理十进制)
if (value < 0 && base == 10)
{
is_neg = 1;
value = -value;
}
//循环取模,把 value 的各位数从后往前依次存在 buffer 中
while (value != 0)
{
int rem = value % base;
buffer[i++] = (rem > 9) ? (rem - 10) + 'a' : rem + '0';//如果是十六进制,要处理 a-f
value /= base;
}
//如果是负数,给 buffer 最后再补个负号
if (is_neg) buffer[i++] = '-';
//逆序打印,把 buffer 的内容从后往前依次打印
while (i > 0) my_putchar(buffer[--i]);
}虽然上面的注释已经很完善了,但我还是想简单解释一下上面代码的实现。我们假设传进去的数字是 123 。
计算机不认识 123 这个整体,它只认识二进制。为了把它变成字符 '1', '2', '3',我们需要从个位 开始剥离,请结合while循环中的代码理解下面过程:
value % base :拿到最后一位数字,例如 123 % 10 = 3 。
然后将它放在buffer[0],然后 i 变成 1 。
value / base :去掉最后一位,例如 123 / 10 = 12 。
就这样循环 3 次,buffer[] = {3, 2, 1},这时 i 为 3 。
因为它不是负数,下一步就可以循环打印了。打印的时候,i 先减 1,变成 2 ,这时打印出buffer[2]也就是 1,依次类推,最终打印出 1,2,3 三个字符。
3.2 主要逻辑
有了 my_itoa 和标准宏,我们就可以编写主函数逻辑了。
c
int my_printf(const char *format, ...)
{
va_list ap;
va_start(ap, format); //初始化,让 ap 指向第一个变参
const char *p = format;
while (*p != '\0')
{
if (*p == '%')
{
p++; // 跳过 '%'
switch (*p)
{
case 'd': // 十进制整数
{
int val = va_arg(ap, int); // 从栈里取出一个 int
my_itoa(val, 10);
break;
}
case 'x': // 十六进制整数
{
int val = va_arg(ap, int);
my_putstr("0x"); // 加个前缀
my_itoa(val, 16);
break;
}
case 'c': // 字符
{
int val = va_arg(ap, int);
my_putchar((char)val);
break;
}
case 's': // 字符串
{
// 字符串本质是 char* 指针,指针不需要提升
char *str = va_arg(ap, char*);
my_putstr(str);
break;
}
default: // 如果不是上面的几种,原样打印
my_putchar('%');//记得先把跳过的那个 % 打印了
my_putchar(*p);
break;
}
} else
{
// 普通字符
my_putchar(*p);
}
p++; // 继续扫描下一个字符
}
va_end(ap); //将 ap 置空,防止野指针
return 0; //这里简化版返回 0,标准库通常返回打印的字符数
}这段代码的主要逻辑是:如果遇到普通字符,那就直接输出。如果遇到 %,暂停输出,查看下一个字符是什么再决定去栈里取什么数据。
理解了主要逻辑,我们再看一下几个关键细节:
c
va_start(ap, format);执行完这句,指针 ap 就已经跳过了 format 字符串本身,停在了第一个变参的内存起始位置,准备随时被调用。
然后是switch-case逻辑,根据 % 后面的字母,决定用什么类型去取栈里的数据 。如果是%d,调用 va_arg(ap, int)。编译器会生成指令,从当前栈位置复制 4 个字节,解释为 int,然后调用我们写好的 my_itoa 转成字符打印。如果是%x,逻辑和上面相同,但我手动打印了 "0x" 前缀,这样能与十进制有所区别。如果是 %s ,调用va_arg(ap, char*)。注意这里取出的只是一个指针 ,真正的字符串内容存储在常量区或堆区,我们把这个地址交给 my_putstr 去遍历打印。然后就是那个反直觉的 %c ,虽然我们要打印的是 char,但在 va_arg 里必须写 int,正如第二章所述,C 语言的默认参数提升 规则,char 在入栈时已经被强转为 int 了,因此我们取的时候也要按照int来取。
最后va_end(ap),调用它来将指针置空。
4. 测试与验证
为了验证我们的 my_printf 是否经得起考验,我编写了一个 main 函数,覆盖了整数、十六进制、字符串,和最关键的字符提升。
c
int main()
{
my_putstr("=== My Printf Test ===\n");
my_printf("Integer: %d\n", 12345);
my_printf("Negative: %d\n", -6789);
my_printf("Hex: %x\n", 255);
my_printf("String: %s\n", "Hello World");
my_printf("Char: %c\n", 'A');
my_printf("Mix: %d + %c = %s\n", 1, '2', "Three");
return 0;
}运行结果如下,大家可以看到,各种类型都能正常打印。包括涉及到参数提升的char型,也能正常打印。

5. 总结
写到这里,我们的 my_printf 已经跑通了。但说实话,这不到 100 行的代码本身并不重要,毕竟在实际应用中,我们永远会去用标准库那个经过千锤百炼的 printf。
而这个手写 printf 真正的价值,在于它是我们探索底层原理的一个引导。
通过这几章的分析,我们收获的不是一个粗糙的打印函数,而是对 C 语言运行机制的深刻理解。
我们亲手证明了 <stdarg.h> 里那些看似高深的宏,剥去它光鲜亮丽的外壳后,不过是朴实无华的指针加减法。
我们深刻体会到了默认参数提升的存在。这不是书本上的死记硬背,而是为了让 CPU 跑得更快、内存对齐更方便而设计的硬件妥协。
我们还知道参数在内存里是挨着放的,拿到一个参数就能顺藤摸瓜拿到其他的参数。
好了,这篇文章到这里就结束了。最后我还想说两句私房话,我真心希望这篇文章能帮助到大家,如果大家觉得看完这篇文章有所收获的话,并且你自己也愿意的话,希望你能留下一个关注,我在这里先说一声感谢,后面我还会再发这种能帮助大家深入理解底层原理的文章。