在计算机系统中,不同的设备(如 CPU、内存、显卡、存储设备等)之间的 数据交换 需要通过 总线 来实现。
在同一个机器内,PCIe 负责 CPU 与 GPU 之间的通信,NVlink 负责 GPU 与 GPU 之间的通信。机器间的通信可通过 TCP/IP 网络协议或 RDMA 网络协议(InfiniBand、iWARP、RoCE)进行。
PCI总线(Perpheral Component Interconnect)
1. PCI 总线的背景
在 早期计算机 中,设备数量相对较少,且速度差距不大,因此 PCI 总线 被设计为一个 共享并行总线,可以让多个设备连接到同一条总线上并共享带宽。
-
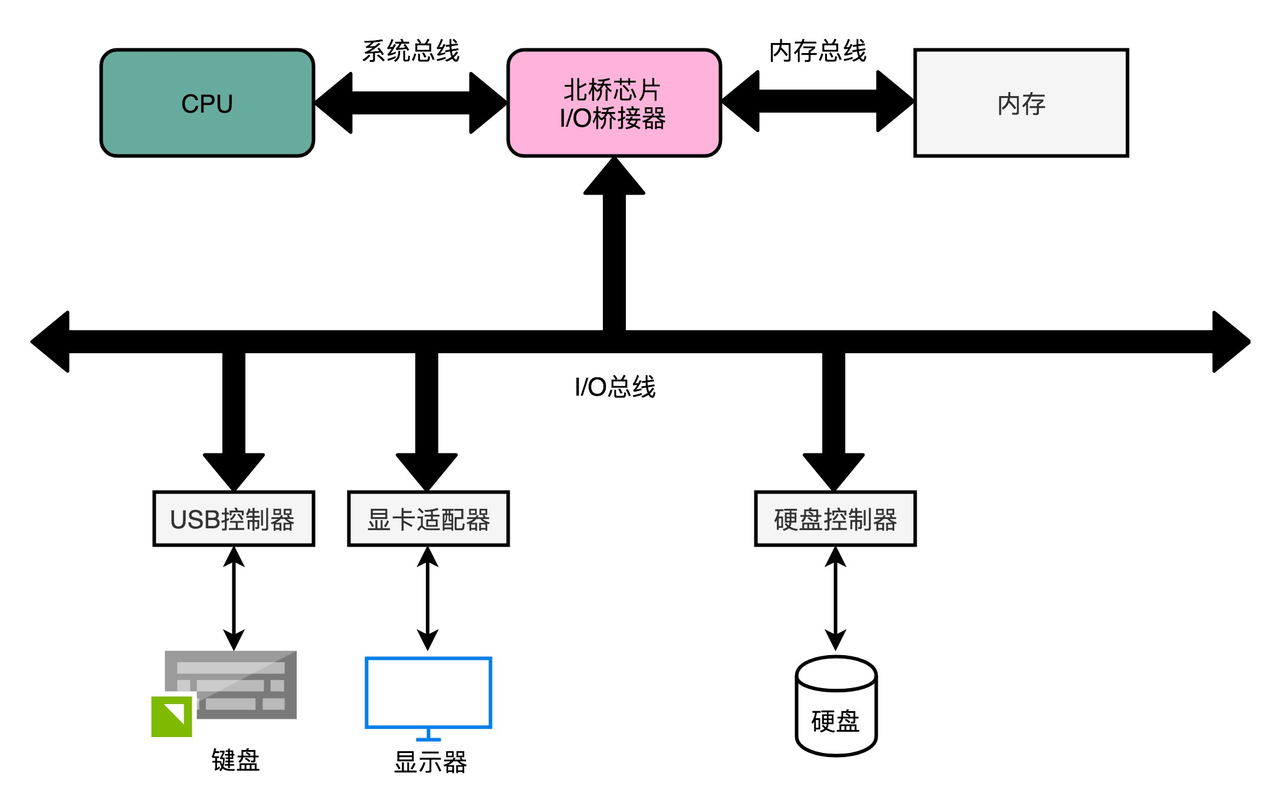
PCI 总线 是一种典型的 I/O 总线,主要用于将外设与 CPU 和内存连接。
-
在这种架构中,多个设备会通过 PCI 总线 共享相同的带宽进行数据传输。
2. PCI 总线的连接方式
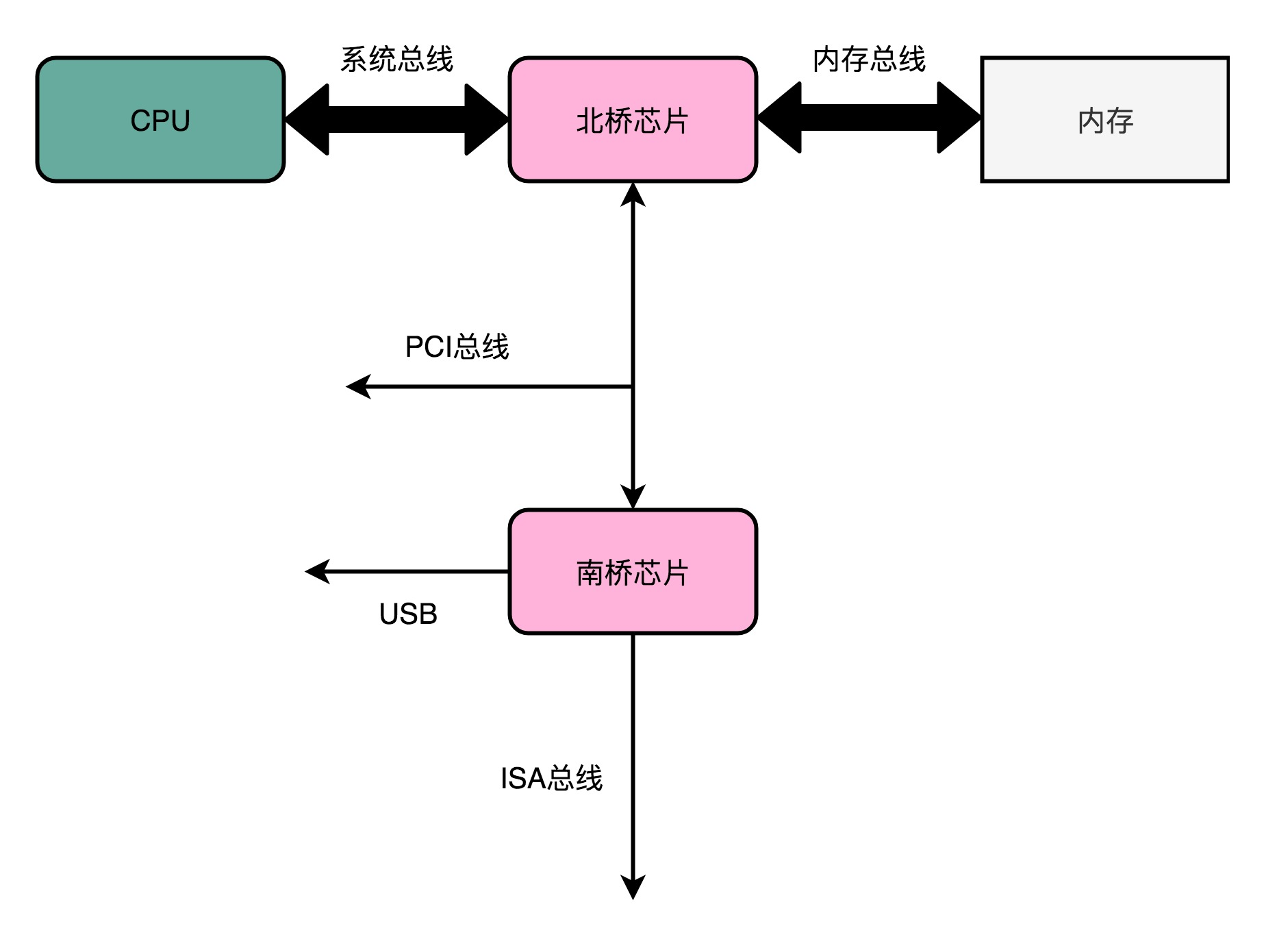
在传统的计算机架构中,PCI 总线 与 北桥(Northbridge) 和 南桥(Southbridge) 配合工作:
-
北桥 (Northbridge):负责 高速数据传输 ,并直接与 CPU 和 内存 进行交互。它处理 内存访问、显卡(如 AGP、PCIe)以及 高速总线(如 FSB)的数据传输。
-
南桥 (Southbridge):主要处理较慢的外设,如 硬盘、USB 端口、音频设备、网络适配器、PCI 总线 及其他 I/O 设备 。南桥与 CPU 通过 北桥 连接。
在 CPU 内部,北桥 起到了重要作用,将前端总线分为两个部分:
-
本地总线(与高速缓存进行高速通信)
-
前端总线(与主内存和外部设备进行通信)
3. PCI 总线的特点与限制
-
共享总线 :所有设备共享同一条总线带宽,因此 带宽竞争 是问题之一。某些低速设备可能会导致 带宽瓶颈,影响整个系统的性能。
-
并行传输 :由于采用并行传输,多个信号会在同一时刻通过多根线路传输。这种方式容易出现 信号同步问题,并且存在 电磁干扰(EMI) 和 串扰,使得传输稳定性降低。
-
不适合高速设备 :PCI 总线的 带宽有限,尤其是对 显卡、SSD 等高带宽需求的设备来说,PCI 总线 的性能无法满足其需求。
由于这些限制,PCI 总线 被逐渐淘汰,PCIe(PCI Express)成为了主流的替代方案。
PCIe (PCI Express)
1. PCIe 的出现与发展
随着计算机硬件的快速发展,传统的 PCI 总线 在 带宽 和 延迟 上逐渐无法满足现代高速设备的需求,尤其是 显卡、SSD(固态硬盘)和 网络适配器 等设备对高速数据传输的要求不断提升。因此,PCIe(PCI Express)应运而生,成为现代计算机系统中 高速设备连接的标准。
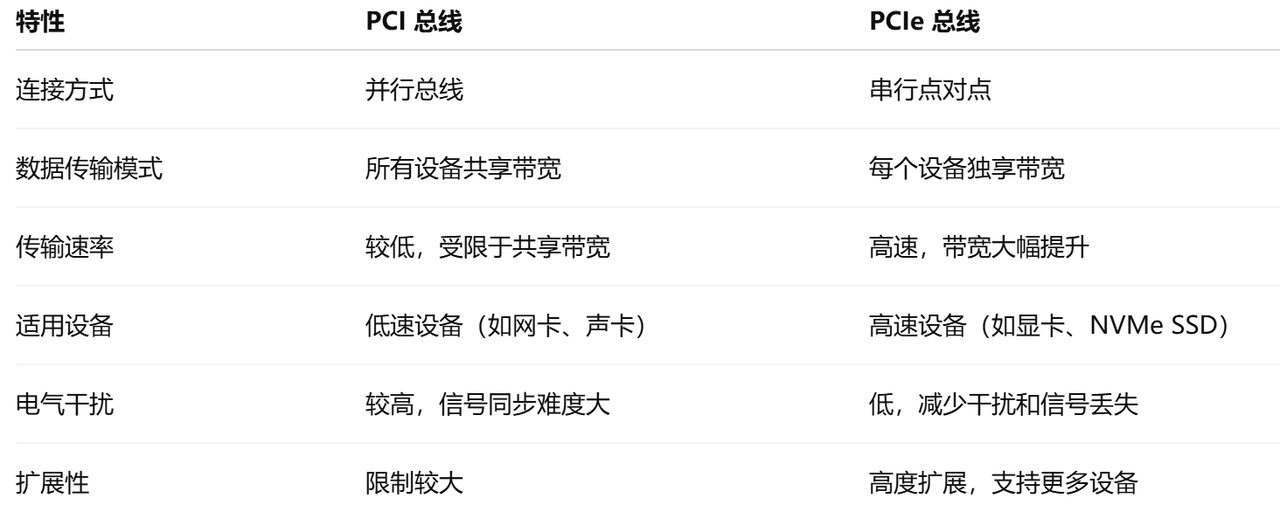
PCIe 与传统的 PCI 总线 相比,采用了 串行点对点 连接模式,极大地提高了 带宽 和 稳定性,并解决了并行总线带来的 同步问题 和 电磁干扰。
2. PCIe 与传统 PCI 总线的主要区别
3. PCIe 的工作原理
PCIe 采用 串行数据传输 和 点对点连接 。每个设备通过独立的 通道(Lane) 与主板上的 根复杂 (Root Complex) 进行通信。每个通道由一对发送和接收信号组成,通常有以下几种配置:x1 (1 个通道)、x4 (4 个通道)、x8 (8 个通道)、x16(16 个通道)
PCIe 通道的带宽会随着通道数的增加而提高。例如,PCIe 3.0 x16 的理论最大带宽为 16 GT/s,即 16 吉比特每秒,而 PCIe 4.0 x16 则可以提供 32 GT/s 的带宽。
PCIe Root Complex 是 CPU 或 PCH(平台控制器集线器)内部的一个组件,负责管理所有的 PCIe 通道,协调数据的传输。
4. PCIe 总线架构图
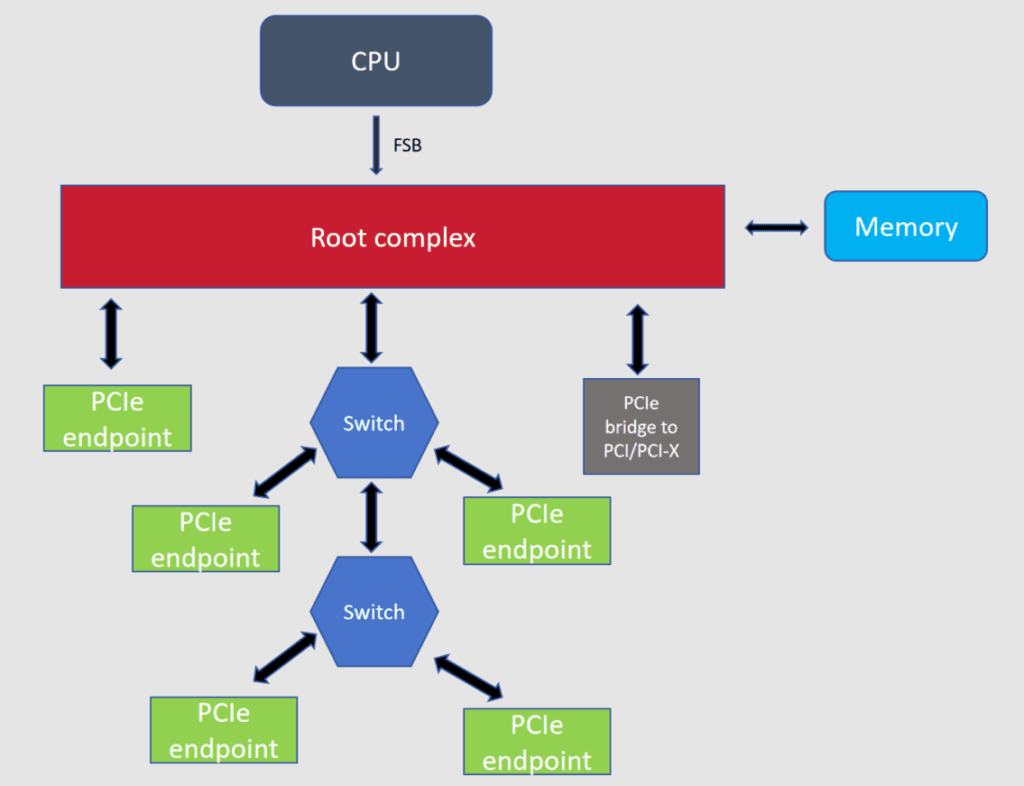
-
CPU:整个系统的计算核心,通过 FSB (前端总线)连接 Root Complex(根复合体)。
-
Root Complex:是 PCIe 总线的根节点,负责连接 CPU、内存和所有 PCIe 设备。承担 CPU 与 PCIe 设备之间、PCIe 设备与内存之间的数据转发。
-
PCIe Switch:作用是扩展 PCIe 总线的端口数量,让一个上游链路可以连接多个下游设备。交换机支持级联,进一步扩展了设备接入能力。
-
PCIe Endpoint(PCIe端点设备):常说的 PCIe 外设,比如 GPU、网卡、NVMe SSD、RAID 卡等。他们通过PCIe链路与根复合体或交换机通信,是实际提供功能的硬件。
-
PCIe bridge to PCI/PCI-X(PCIe桥接器):兼容性组件,用于连接旧版的PCI/PCI-X设备,让他们可以接入 PCIe 总线。
数据传输逻辑:
-
CPU 通过 FSB 将指令和数据发送个 Root Complex。
-
Root Complex 负责将数据路由到目标设备:可以直接发给连接在它总线上的 Endpoint 或桥接器;也可以通过 PCIe Switch 转发给更多下游的 Endpoint 设备。
-
设备处理完数据后,同样通过这条路径将结果返回给CPU或写入内存。
5. PCIe 的优势
-
高带宽 :PCIe 3.0 和 PCIe 4.0 提供了显著高于传统 PCI 总线的带宽,特别适合 显卡、存储设备(如 NVMe SSD)、网络卡 等需要高速数据传输的设备。
-
低延迟 :通过 点对点连接 ,数据可以直接从 设备 到 CPU 或 内存,大大减少了数据传输的延迟,尤其对于需要实时数据处理的应用(如视频处理、游戏)至关重要。
-
灵活性与扩展性:PCIe 支持多种设备和配置,支持多种 插槽类型,从 x1 到 x16,并且支持 热插拔 和 即插即用(Plug and Play)。
-
高效能:PCIe 支持 全双工通信(同时进行数据传输和接收),进一步提升了带宽效率。
在现代计算机架构中,PCIe 被用来连接各种高速设备 ,成为 显卡、存储设备、网络适配器 等重要硬件的主力连接标准。特别是在 Intel 和 AMD 处理器系统中,PCIe 控制器 常常集成到 CPU 内部,或者通过 PCH(平台控制器集线器) 管理。这种设计简化了计算机的架构,减少了传统 南桥 或 北桥 的作用。同时,PCIe 为现代 NVMe SSD 提供了直接连接的途径,实现了更快的读写速度,不再需要经过 芯片组 或 南桥 等中介设备的传输。
串行点对点
在串行传输 中,数据以 一个比特接一个比特 的方式通过 单根信号线 进行传输,而不是像并行传输那样通过多根信号线同时传送多个比特。
-
并行传输:多个比特通过多根信号线同时传输。例如,在 PCI 总线中,数据通过多条并行信号线同时传输多个比特。
-
串行传输 :每次传输一个比特,数据流以 比特串 的形式按顺序传输。例如,在 PCIe 中,数据以一个比特接一个比特的方式传输。
点对点传输 表示在 通信链路中 ,每个设备之间有独立的连接。每个设备通过单独的链路与目标设备进行直接通信,而不是通过一个共享的总线。
-
共享总线 :例如,传统的 PCI 总线 是一个共享的并行总线,多个设备连接到同一总线上,它们争夺带宽,所有设备共享同一信号通道。
-
点对点传输 :例如,在 PCIe 中,每个设备都有与 根复杂(Root Complex) 或 其他设备 的独立连接,每个设备都拥有独立的通信通道。
PCIe Switch
PCIe Switch 是一种硬件设备,在 PCIe 总线中扮演着交通枢纽的角色。打破了传统的一对一连接方式,允许多个设备通过单个 PCIe 接口接入,还能实现设备间的数据交换和通信。
主要组成部分
Upstream Port(上游端口): 上游端口连接到 Root Complex 或 上游设备 ,用于接收来自 主机系统(CPU 或 PCH) 的数据。它是 PCIe Switch 的输入端,负责接收数据并将其转发到多个下游端口。作用是 提供 带宽 和 数据路径 从 CPU 或 内存 到多个 下游设备,管理上游到下游的数据传输。
Downstream Ports(下游端口): 下游端口连接到实际的 PCIe 设备 (如显卡、存储设备、网络卡等)。每个下游端口与连接的 PCIe 设备 之间形成数据通信通道。作用是 负责将上游端口传来的数据转发到连接的 端点设备 ,并接收从端点设备返回的数据。一个 PCIe Switch 可以有多个下游端口,支持多个 PCIe 设备 的并行工作。
Switching Fabric(交换矩阵): 交换矩阵是 PCIe Switch 内部用于连接上游端口和下游端口的核心部分。它决定了++数据如何从上游端口传递到正确的下游端口++ 。作用是 交换矩阵管理数据的路由和流量控制,确保每个端口的数据正确地转发到目标设备。它通过内部的连接路径来处理不同端口之间的通信。特点 :现代 PCIe Switch 的交换矩阵支持 多通道并行处理,并且在数据传输时能够有效避免带宽瓶颈。
PCIe Switch 的工作流程
数据请求:
-
当一个 端点设备 (如显卡)需要数据时,它通过 下游端口 向 PCIe Switch 发送请求。
-
PCIe Switch 通过 交换矩阵 将数据请求转发到 上游端口 ,并通过 Root Complex 或 上游设备 获取数据。
数据传输:
- 从 Root Complex 或 内存 获取到数据后,PCIe Switch 会将数据通过 交换矩阵 转发到目标的 下游端口,然后由目标设备接收并处理数据。
返回数据:
- 当设备处理完数据后,它会将结果通过相同的路径返回给 CPU 或 内存,最终完成数据传输。
NVLink
NVLink 是 NVIDIA 提出的 GPU-GPU 高速互联技术,旨在加快 GPU 与 GPU 之间的数据传输速度,提高系统性能。特点是:带宽远高于 PCIe,延迟更低,针对 GPU 间大规模数据交换进行了优化。
NVLink高速互联的两种形式:直连、NVSwitch。
直连 :两个 GPU 之间 通过 直接的物理 NVLink 链路 ,即 NVLink Bridge 这个硬件连接器来实现。通常安装在两张 GPU 的顶部接口上。没有NVLink Bridge,NVLink 就无法启用。
NVSwitch (网络交换):是一种更复杂的交换网络结构,允许多个 GPU 通过一个共享的交换机进行连接。是一个高带宽的 交换硬件,它负责将数据从一个 GPU 转发到另一个 GPU。每个 NVSwitch 设备可以连接多个 GPU,并通过 NVLink 提供带宽和低延迟的互联。
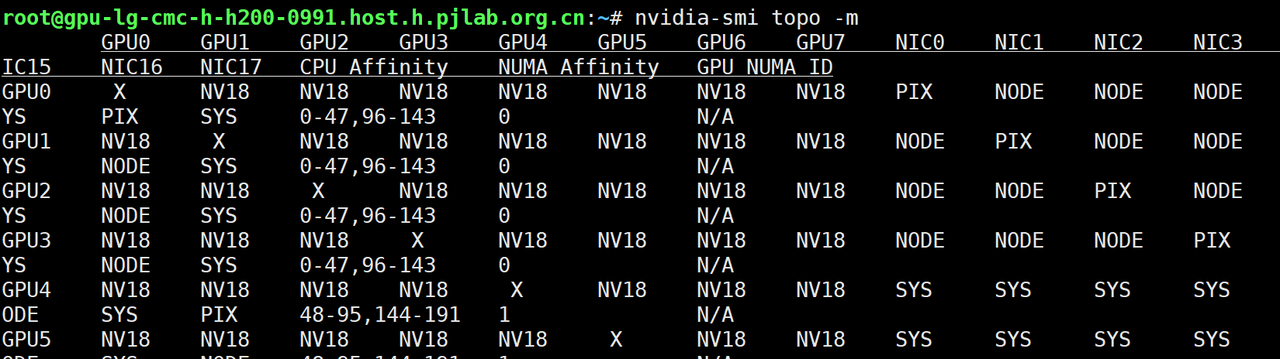
可以使用 nvidia-smi topo 查看GPU之间的连接方式:
-
NV18:表示GPU之间存在 NVLink 连接,18是NVLink链路数量。
-
PCIe:表示 GPU 之间通过 PCIe 通信。
-
X:表示 GPU 自身。