简介
自研NoteBook如何高效地管理 Jupyter Kernel 的生命周期、处理代码执行请求,以及实现实时的消息推送,是其中的核心。本文将分享一套基于微服务架构的 Jupyter 内核管理系统的设计思路和实现方案。
租户Jupyter服务管理
1.使用miniforge管理python的依赖包
2.每个租户单独启动一个pod启动对应的jupyter服务,启动命令如下
bash
/local/.miniforge3/bin/jupyter labextension disable @jupyterlab/docmanager-extension:download &&
/local/.miniforge3/bin/jupyter labextension disable @jupyterlab/filebrowser-extension:download &&
/local/.miniforge3/bin/jupyter labextension disable @jupyterlab/docmanager-extension:open-browser-tab &&
/local/.miniforge3/bin/jupyter labextension disable @jupyterlab/filebrowser-extension:open-browser-tab &&
//local/.miniforge3/bin/jupyter-lab --ServerApp.ip="*" --ServerApp.password="" --ServerApp.token="" --no-browser --allow-root --port=8888 --NotebookApp.base_url="/web/${IDE_CR_NAME}/jupyter" --NotebookApp.disable_check_xsrf=True整体架构
系统采用微服务架构,将功能拆分为多个独立的服务模块,各司其职,
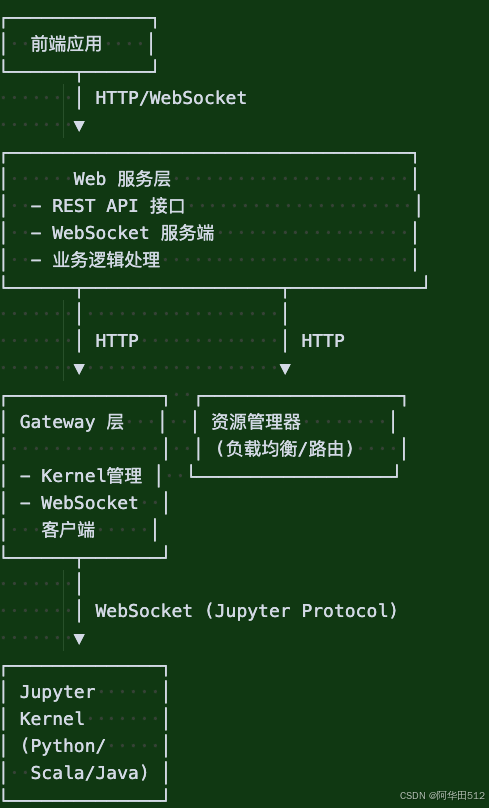
核心组件职责
-
- **Web 服务层**: 提供 REST API 和 WebSocket 服务,处理前端请求,管理用户会话
-
- **Gateway 层**: 作为中间层,管理内核连接池,转发消息,实现与 Jupyter Server 的解耦
-
- **资源管理器**: 负责内核的路由和负载均衡,决定将请求分发到哪个 Gateway 实例
-
- **Jupyter Kernel**: 实际执行代码的计算内核,一个pod部署一套jupyter服务
技术选型
-
- **后端框架**: Spring Boot
-
- **数据持久化**: MyBatis + MySQL
-
- **实时通信**: WebSocket (JSR-356)
-
- **消息中间件**: Redis Pub/Sub
-
- **协议标准**: Jupyter Messaging Protocol 5.2
概念解释
1.Kernel (内核)
Kernel 是 Jupyter 生态系统的核心,它是一个独立的进程,负责执行用户提交的代码。每个 Kernel 都运行在独立的进程中,拥有自己的内存空间和执行环境。
Kernel 的特点:
-
- **语言特定**: 每个 Kernel 对应一种编程语言,如 Python Kernel、Scala Kernel、Java Kernel 等
-
- **状态保持**: Kernel 在运行期间会保持执行状态,变量、函数、导入的模块等都会保留在内存中
-
- **独立进程**: 每个 Kernel 都是独立的进程,互不干扰,一个 Kernel 崩溃不会影响其他 Kernel
-
- **生命周期管理**: Kernel 可以被创建、启动、停止、重启和删除
Kernel 的状态:
-
- `idle`: 空闲状态,等待执行代码
-
- `busy`: 正在执行代码
-
- `starting`: 正在启动中
-
- `dead`: 已停止或崩溃
**示例场景**:
bash
```python
# 在 Python Kernel 中执行
x = 10
y = 20
print(x + y) # 输出: 30
# 变量 x 和 y 仍然保留在 Kernel 的内存中
# 后续的代码可以继续使用这些变量Session (会话)
Session 在 Jupyter 中有两层含义:
-
**WebSocket Session**: 客户端与服务器之间的 WebSocket 连接会话
-
**Jupyter Session**: Jupyter 协议中的会话标识,用于关联请求和响应
WebSocket Session:
-
**连接会话**: 前端通过 WebSocket 与后端建立的长连接
-
**双向通信**: 支持客户端和服务器之间的双向实时通信
-
**状态管理**: 每个 Session 都有唯一的标识符,用于管理连接状态
-
**生命周期**: Session 从连接建立开始,到连接关闭结束
Jupyter Session:
-
**消息关联**: Jupyter 协议中,每个消息都有一个 `session` 字段,用于将请求和响应关联起来
-
**执行上下文**: 通常使用 Cell ID 作为 Session ID,这样可以将执行结果与特定的代码单元关联
-
**消息追踪**: 通过 Session ID 可以追踪一次代码执行的所有相关消息
**Session 的作用**:
```
前端发送执行请求
↓
消息头中包含 session: "cell-123"
↓
Kernel 执行代码并返回结果
↓
响应消息中也包含相同的 session: "cell-123"
↓
前端可以根据 session 将结果匹配到对应的代码单元
```
Cell (代码单元)
**什么是 Cell?**
Cell 是 Notebook 中的基本组成单位,是用户编写和执行代码的容器。
**Cell 的类型**:
-
**Code Cell**: 代码单元,包含可执行的代码
-
**Markdown Cell**: 文档单元,用于编写说明文档
-
**Raw Cell**: 原始文本单元,不会被执行
**Cell 的生命周期**:
```
创建 Cell
↓
编辑代码内容
↓
执行 Cell (发送到 Kernel)
↓
Kernel 执行代码
↓
返回执行结果
↓
显示结果 (输出、错误、状态等)
↓
保存执行历史
```
Cell 的执行状态:
-
- `idle`: 未执行或执行完成
-
- `running`: 正在执行中
-
- `queued`: 等待执行
-
- `error`: 执行出错
Cell 与 Kernel 的关系
-
一个 Notebook 可以绑定一个 Kernel
-
一个 Kernel 可以执行多个 Cell 的代码
-
Cell 的执行是顺序的,但可以通过异步机制实现并发
-
所有 Cell 共享同一个 Kernel 的执行环境(变量、函数等)
**示例**:
```python
Cell 1
import pandas as pd
df = pd.DataFrame({'A': 1, 2, 3})
Cell 2 (可以访问 Cell 1 中定义的变量)
print(df.head()) # 输出 DataFrame 的前几行
内核创建流程详解
完整请求流程

关键设计点
内核创建接口
**接口设计**:
bash
```http POST /api/kernel/bind
Content-Type: application/json
{
"kernelName": "python3",
"notebookId": "notebook-uuid"
}
```**响应示例**:
bash
```json
{
"code": 0,
"data": {
"kernelId": "kernel-uuid",
"status": "idle"
}
}
```2.2.2 内核规格查询
系统支持查询可用的内核类型,前端可以根据此信息展示内核选择界面
bash
```http
GET /api/kernel/specs
```返回所有已注册的内核规格,包括 Python、Scala、Java 等。
Session 管理机制
3.1 双层 Session 架构
系统采用双层 Session 管理,将用户会话和内核会话分离:
3.1.1 用户级 WebSocket Session
**连接端点**: `ws://host/api/user/{userId}`
**职责**:
-
用户级别的消息推送通道
-
接收前端发送的业务请求
-
通过 Redis Pub/Sub 接收系统推送的消息
**Session 管理**:
```java
// 使用线程安全的 Map 存储活跃的 WebSocket Session
private static final Map<String, Session> SESSIONS_MAP = new ConcurrentHashMap<>();
// 在线用户计数
private static final AtomicInteger ONLINE_COUNT = new AtomicInteger(0);
```
**关键特性**:
-
**自动订阅**: 连接建立时自动订阅用户专属的 Redis Channel
-
**心跳检测**: 支持心跳机制,保持连接活跃
-
**优雅关闭**: 连接关闭时自动清理资源和监听器
3.1.2 内核级 WebSocket Session
**连接端点**: `ws://host/api/kernel/{kernelId}`
**职责**:
-
内核级别的消息推送通道
-
接收内核执行结果的实时推送
-
每个内核有独立的订阅通道
Gateway 层连接池管理
Gateway 层维护一个 WebSocket 连接池,管理所有与 Jupyter Kernel 的连接:
java
@Service
public class WebSocketPool {
// 内核ID -> WebSocket连接的映射
private final static Map<String, WebSocketConnection> connectionMap =
new ConcurrentHashMap<>();
public void addConnection(String kernelId, WebSocketConnection connection) {
connectionMap.put(kernelId, connection);
}
public WebSocketConnection getConnection(String kernelId) {
return connectionMap.get(kernelId);
}
public static void removeConnection(String kernelId) {
connectionMap.remove(kernelId);
}核心 API 设计
内核管理 API
- | `/api/kernel/specs` | GET | 获取可用内核列表 |
- | `/api/kernel/list` | GET | 获取运行中的内核列表 |
- | `/api/kernel/bind` | POST | 创建并绑定内核到 Notebook |
- | `/api/kernel/delete` | DELETE | 删除内核 |
代码执行 API
- | `/api/cell/add` | POST | 添加新的代码单元 |
- | `/api/cell/save` | POST | 保存代码单元内容 |
- | `/api/cell/run` | POST | 执行代码单元 |
- | `/api/cell/result` | GET | 获取执行结果 |
Gateway 层 API
- | `/api/gateway/kernel/create` | POST | 创建内核实例 |
- | `/api/gateway/kernel/connect` | POST | 建立 WebSocket 连接 |
- | `/api/gateway/message/send` | POST | 发送代码执行请求 |
- | `/api/gateway/kernel/status` | GET | 检查内核状态 |
连接池管理
Gateway 层维护 WebSocket 连接池,避免重复创建连接:
java
```java
// 获取连接,如果不存在则创建
WebSocketConnection connection = pool.getConnection(kernelId);
if (connection == null) {
connection = new WebSocketConnection(kernelId, endpoint);
pool.addConnection(kernelId, connection);
}
```数据模型设计
7.1 核心数据表
内核信息表 (kernel_info)
| 字段 | 类型 | 说明 |
|-----|------|------|
| id | BIGINT | 主键 |
| kernel_id | VARCHAR | 内核ID (Jupyter生成) |
| kernel_name | VARCHAR | 内核名称 |
| kernel_status | VARCHAR | 内核状态 |
| gateway_host | VARCHAR | Gateway 主机地址 |
| manager | VARCHAR | 管理者用户ID |
| kernel_endpoint | VARCHAR | Jupyter Server 地址 |