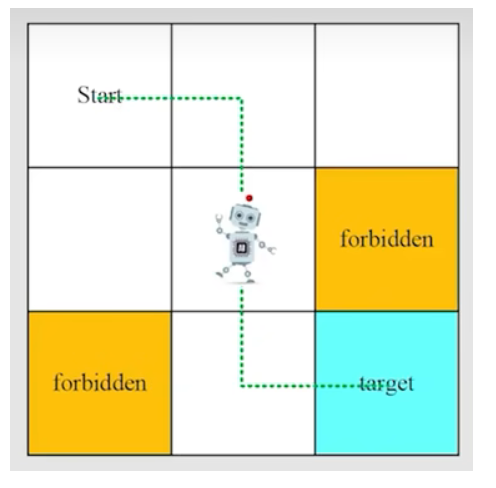
状态:智能体相对环境的状态 如:s1
状态空间:也就是所有的状态和 记作 S={s1,s2....s9}
动作:s1->s2,这个行为就是动作 上下左右保持不动等5个动作
动作空间: 不同状态下的不同动作的总和 如 s1 的动作空间为 As1=它可以执行的动作
状态转移:意思是状态经过动作后进入下一个状态,可以记做 s1----a2--->s2
策略:
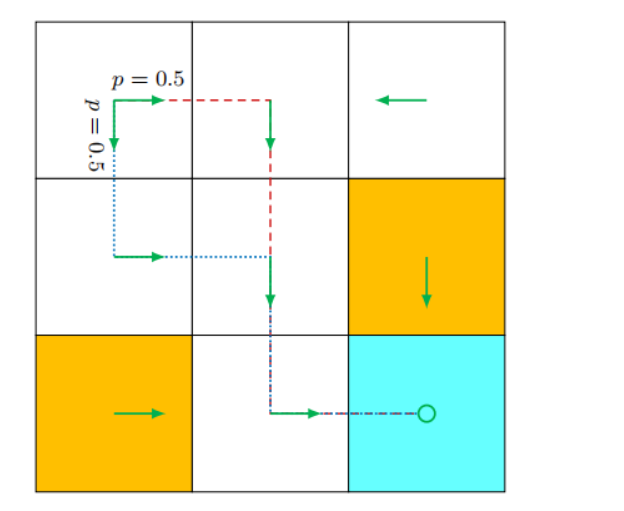
策略:整个表格 各个状态 动作的 整体条件概率
专业说法 强化学习术语 :"策略 π 可以表示为一个状态-动作值表(或矩阵),其元素 π(a|s) 定义了在状态 s 下选择动作 a 的概率。"
奖励:
在网格世界的例子中,奖励设计如下:
- 如果智能体试图越过边界,设 rboundary=−1。
- 如果智能体试图进入禁止的格子,设 rforbidden=−1。
- 如果智能体到达目标状态,设 rtarget=+1。
- 否则,智能体获得 rother=0 的奖励。
在某个状态执行一个动作后,智能体获得一个奖励(记为 r)作为来自环境的反馈。奖励是状态 s 和动作 a 的函数。因此,它也记为 r(s,a)。它的值可以是正数、负数或零。不同的奖励对智能体最终学到的策略有不同的影响。一般来说,通过正奖励,我们鼓励智能体采取相应的动作。通过负奖励,我们阻止智能体采取该动作。
在某个状态执行一个动作后,智能体获得一个奖励(记为 r)作为来自环境的反馈