Python 一键拆分 PDF:按"目录/章节"建文件夹 + 每页单独导出(支持书签识别&正文识别)
文章目录
- [Python 一键拆分 PDF:按"目录/章节"建文件夹 + 每页单独导出(支持书签识别&正文识别)](#Python 一键拆分 PDF:按“目录/章节”建文件夹 + 每页单独导出(支持书签识别&正文识别))
-
- [1. 我写这个工具的原因](#1. 我写这个工具的原因)
- [2. 最终效果长什么样(我想要的输出)](#2. 最终效果长什么样(我想要的输出))
- [3. 使用方法(我实际是这样跑的)](#3. 使用方法(我实际是这样跑的))
-
- [3.1 我做的第 1 步:选择 PDF 文件](#3.1 我做的第 1 步:选择 PDF 文件)
- [3.2 我做的第 2 步:选择输出位置并开始拆分](#3.2 我做的第 2 步:选择输出位置并开始拆分)
- [4. 环境与依赖(我用的配置)](#4. 环境与依赖(我用的配置))
- [5. 我在代码里做了什么(原理简述)](#5. 我在代码里做了什么(原理简述))
-
- [5.1 优先方案:从 PDF 书签(outline)识别章节](#5.1 优先方案:从 PDF 书签(outline)识别章节)
- [5.2 备用方案:扫描正文文本猜章节起始页](#5.2 备用方案:扫描正文文本猜章节起始页)
- [6. 我可以调的关键参数(想改行为就看这里)](#6. 我可以调的关键参数(想改行为就看这里))
- [7. 常见问题(我自己踩过的坑)](#7. 常见问题(我自己踩过的坑))
- [8. 完整代码(可直接复制运行)](#8. 完整代码(可直接复制运行))
1. 我写这个工具的原因
我经常会把电子书交给 AI 做总结/问答,但很多 PDF 体积大、页数多,如果我想按章节拆开再喂给 AI,手动操作会非常耗时间。
所以我用 Python 写了一个小工具,实现了:
- 自动识别"第X章"标题(优先书签,没书签再扫正文)
- 按章节自动创建文件夹(文件夹命名带序号,方便排序)
- 支持整章导出 + 单页导出(每页单独 PDF,便于上传/AI 处理)
2. 最终效果长什么样(我想要的输出)
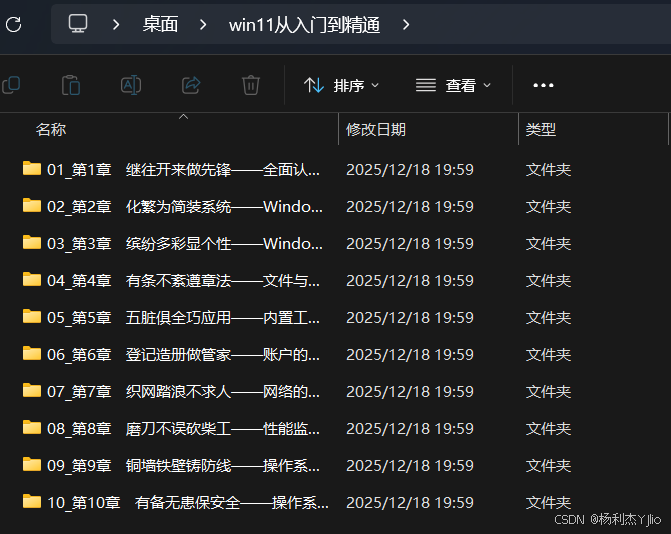
我拆分后的输出结构大概是这样:
-
输出目录
-
01_第1章_xxx/01_第1章_xxx.pdf(整章)p0001.pdf p0002.pdf ...(单页)
-
02_第2章_xxx/02_第2章_xxx.pdfp00xx.pdf ...
-
一句话:我既保留"整章",也能拿到"每一页"。
3. 使用方法(我实际是这样跑的)
我把脚本直接丢进 PyCharm(你原文写的 ptcharm 我这里统一写成 PyCharm)运行即可。
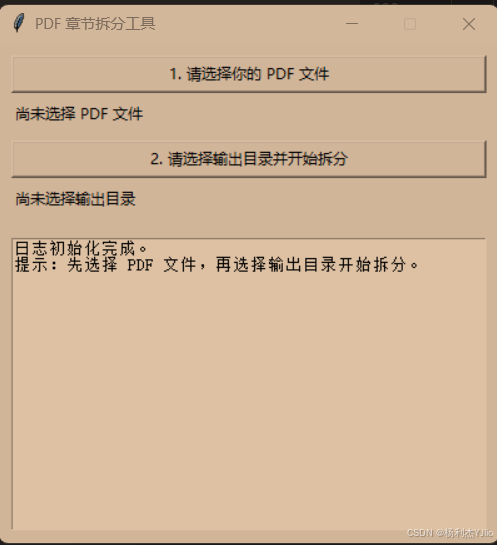
3.1 我做的第 1 步:选择 PDF 文件
我点击按钮 「1. 请选择你的 PDF 文件」,选中要处理的 PDF。
3.2 我做的第 2 步:选择输出位置并开始拆分
我点击 「2. 请选择输出目录并开始拆分」,选择一个输出文件夹,工具就会开始处理,并在下方日志区域输出进度。
你原来的两张图建议保留在这里(效果最直观)
4. 环境与依赖(我用的配置)
- Windows 10/11 均可
- Python 3.x(建议 3.8+)
- 依赖库:
pypdf
我安装依赖的方式:
bash
pip install pypdf**注意:**如果 PDF 是扫描版图片(没有可提取的文字),正文识别可能会失败,这种情况需要先 OCR,否则工具无法"读到章节标题"。
5. 我在代码里做了什么(原理简述)
为了让工具对不同 PDF 更"稳",我设计了两套识别策略:
5.1 优先方案:从 PDF 书签(outline)识别章节
如果 PDF 自带书签(目录),我就直接读取书签并找出匹配 "第X章" 的标题,然后拿到对应页码作为章节起点。
**优点:**速度快、准确率高。
5.2 备用方案:扫描正文文本猜章节起始页
如果没有书签,我会逐页提取文本,然后用正则匹配 第X章,并做了两层过滤:
- 过滤"目录页"(包含 目录/Contents 等)
- 过滤类似
标题......页码的目录行
**优点:**即使没书签,只要正文可提取文字,也能拆分。
6. 我可以调的关键参数(想改行为就看这里)
代码最上面配置区我留了两个重点:
CHAPTER_PATTERN:章节匹配正则(默认支持:第1章 / 第 1 章 / 第一章 / 第十四章)EXPORT_SINGLE_PAGES:是否导出单页 PDF(默认 True)
如果你不想生成单页 PDF,把 EXPORT_SINGLE_PAGES = False 就行。
7. 常见问题(我自己踩过的坑)
Q1:提示"未识别到任何章节标题"
通常是三类原因:
- PDF 没书签 + 正文提取不到文本(扫描版)
- 章节标题不是"第X章"这种格式(需要改正则)
- 章节标题出现在页面太靠后(正文识别里有阈值
m.start() > 400)
**解决思路:**我会先确认 PDF 是不是可复制文字;不行就 OCR;标题格式不一致就改正则。
Q2:为什么我的章节起始页不准?
如果 PDF 正文排版很特殊(比如章标题不在页首、页眉重复干扰),可能会误判。
这种情况我会优先找"带书签"的版本,或者适当调整正文识别的阈值。
Q3:输出文件名为什么会有下划线?
我在 sanitize_filename() 里把 Windows 不允许的字符替换成 _,避免出现"无法创建文件"的问题。
8. 完整代码(可直接复制运行)
我把完整代码放在这里,复制到 PyCharm 直接运行即可。
python
# -*- coding: utf-8 -*-
import re
from pathlib import Path
from pypdf import PdfReader, PdfWriter
import tkinter as tk
from tkinter import filedialog, messagebox
# ================= 配置区域 =================
# 章节标题匹配规则(适合:第1章 / 第 1 章 / 第一章 / 第十四章 等)
CHAPTER_PATTERN = re.compile(
r"第\s*[一二三四五六七八九十百千0-9]+\s*章[^\n\r]*"
)
# 是否额外按"页"拆成单页 PDF
EXPORT_SINGLE_PAGES = True
# ==========================================
# GUI 全局对象占位
root = None
log_text = None
def sanitize_filename(name: str) -> str:
"""
去掉 Windows 不支持的文件名字符。
"""
return re.sub(r'[\\/:*?"<>|]', "_", name)
# ---------- 方案一:优先从 PDF 书签(outline) 中找章节 ----------
def find_chapters_from_outline(reader: PdfReader):
"""
从 PDF 书签(outline) 中找出章节:
- 遍历所有书签
- 标题里匹配 CHAPTER_PATTERN(第X章......)
- 获取对应页码
返回: [{title: '第1章 xxx', start: 0}, ...]
"""
chapters = []
# 兼容不同版本的 pypdf:有的叫 outline,有的叫 outlines
try:
outlines = reader.outline
except Exception:
try:
outlines = reader.outlines
except Exception:
outlines = None
if not outlines:
return []
def walk(items):
for item in items:
# 子列表:继续递归
if isinstance(item, list):
walk(item)
else:
# 尝试拿书签标题
try:
title = item.title
except AttributeError:
title = str(item)
if not isinstance(title, str):
title = str(title)
# 标题里不含"第X章"就跳过
if not CHAPTER_PATTERN.search(title):
continue
# 拿到书签指向的页码
try:
page_num = reader.get_destination_page_number(item)
except Exception:
continue
chapters.append({"title": title.strip(), "start": page_num})
walk(outlines)
# 去重、排序(同一页只保留一个章节)
unique = {}
for ch in chapters:
if ch["start"] not in unique:
unique[ch["start"]] = ch
chapters = sorted(unique.values(), key=lambda c: c["start"])
return chapters
# ---------- 方案二:从正文文本中猜章节(备用) ----------
def find_chapters_from_text(reader: PdfReader):
"""
扫描整个 PDF 正文,猜每一章的"起始页"以及章节标题。
规则大致是:
- 排除"目录/contents"页面
- 一页内允许有多个"第X章",逐个判断
- 只要某个匹配出现在页面较前面,且所在行不像目录行(标题 + ...... + 页码) 就认为是章节开始
返回: [{title: '第1章 xxx', start: 0}, ...]
"""
chapters = []
num_pages = len(reader.pages)
for i in range(num_pages):
page = reader.pages[i]
text = page.extract_text() or ""
if not text.strip():
continue
# 跳过目录页(粗略判断即可)
head = text[:100]
if "目录" in head or "Contents" in head or "CONTENTS" in head:
continue
# 遍历此页所有匹配 "第X章"
for m in CHAPTER_PATTERN.finditer(text):
# 要求标题出现在页面比较靠前的位置
if m.start() > 400: # 这个阈值可以按需要微调
continue
# 找到这一行的文本内容
lines = text.splitlines()
line_of_match = ""
char_pos = 0
for line in lines:
next_pos = char_pos + len(line) + 1 # 粗略算上换行
if m.start() < next_pos:
line_of_match = line
break
char_pos = next_pos
# 目录行一般是:标题 + 一串点 + 页码
# 例如:第1章 人际关系的构成..................1
if re.search(r"[\.·...]{3,}\s*\d+\s*$", line_of_match):
# 像目录的行,忽略
continue
title = m.group(0).strip()
# 同一页只认一个章节起点
if not any(ch["start"] == i for ch in chapters):
chapters.append({"title": title, "start": i})
break # 当前页已经找到一个章节了,后面不再找
return chapters
# ---------- 包一层:带 logger 的 find_chapters ----------
def find_chapters(reader: PdfReader, logger=print):
chapters = find_chapters_from_outline(reader)
if chapters:
logger("✅ 使用 PDF 书签识别章节")
return chapters
logger("⚠️ 此 PDF 没有可用书签,改用正文文本识别章节")
chapters = find_chapters_from_text(reader)
return chapters
def fill_chapter_ranges(chapters, num_pages):
"""
根据 start 页自动计算每章的 end 页。
修改 chapters 列表,增加 end 字段。
"""
for idx, ch in enumerate(chapters):
start = ch["start"]
if idx < len(chapters) - 1:
end = chapters[idx + 1]["start"] - 1
else:
end = num_pages - 1
ch["end"] = end
return chapters
def split_pdf_by_chapters(pdf_path, output_root, logger=None):
"""
真正拆分 PDF 的函数,所有信息通过 logger 输出到日志区域
"""
if logger is None:
logger = print
pdf_path = Path(pdf_path)
output_root = Path(output_root)
if not pdf_path.exists():
msg = f"PDF 文件不存在: {pdf_path}"
logger(msg)
raise FileNotFoundError(msg)
reader = PdfReader(str(pdf_path))
num_pages = len(reader.pages)
book_name = pdf_path.name
logger(f"开始处理:{book_name}")
logger(f"总页数:{num_pages}")
# 1. 找章节
chapters = find_chapters(reader, logger=logger)
if not chapters:
msg = "未识别到任何章节标题,请检查:PDF 是否有书签/正文是否能提取文字/正则是否合适。"
logger(msg)
raise ValueError(msg)
logger(f"共识别到 {len(chapters)} 章:")
for idx, ch in enumerate(chapters, start=1):
logger(f" 第{idx}章 → {ch['title']}(起始页:{ch['start'] + 1})")
# 2. 填充每章的结束页
chapters = fill_chapter_ranges(chapters, num_pages)
# 3. 创建输出根目录
output_root.mkdir(parents=True, exist_ok=True)
logger(f"输出目录:{output_root}")
# 4. 按章节导出
for idx, ch in enumerate(chapters, start=1):
title = ch["title"]
start_page = ch["start"] # 0-based
end_page = ch["end"] # 0-based
page_count = end_page - start_page + 1
safe_title = sanitize_filename(title)
chapter_dir = output_root / f"{idx:02d}_{safe_title}"
chapter_dir.mkdir(parents=True, exist_ok=True)
logger("")
logger(f"==== 处理章节 {idx}: {title} ====")
logger(f"页码范围: {start_page + 1} - {end_page + 1}(共 {page_count} 页)")
logger(f"章节输出目录: {chapter_dir}")
# 4.1 导出"整章一个 PDF"
chapter_writer = PdfWriter()
for p in range(start_page, end_page + 1):
chapter_writer.add_page(reader.pages[p])
chapter_pdf_path = chapter_dir / f"{idx:02d}_{safe_title}.pdf"
with open(chapter_pdf_path, "wb") as f:
chapter_writer.write(f)
logger(f" ✅ 已生成整章 PDF: {chapter_pdf_path.name}")
# 4.2 可选:每一页单独导出
if EXPORT_SINGLE_PAGES:
for p in range(start_page, end_page + 1):
writer = PdfWriter()
writer.add_page(reader.pages[p])
# 页码用 1 开始,且补零对齐,例如 p0001.pdf
page_label = f"p{p + 1:04d}.pdf"
single_page_path = chapter_dir / page_label
with open(single_page_path, "wb") as f:
writer.write(f)
logger(" ✅ 已生成单页 PDF 文件(按页命名)")
logger("")
logger("🎉 拆分完成!")
# ========= GUI 部分(两个按钮 + 日志框) =========
selected_pdf_file = ""
selected_output_dir = ""
def append_log(msg: str):
"""写日志到 Text,并自动滚动"""
if log_text is None:
print(msg)
return
log_text.config(state="normal")
log_text.insert(tk.END, msg + "\n")
log_text.see(tk.END)
log_text.config(state="disabled")
# 刷新一下界面,让日志滚动更及时
if root is not None:
root.update_idletasks()
def choose_pdf():
"""按钮1:选择 PDF 文件"""
global selected_pdf_file
path = filedialog.askopenfilename(
title="请选择 PDF 文件",
filetypes=[("PDF 文件", "*.pdf"), ("所有文件", "*.*")]
)
if path:
selected_pdf_file = path
label_pdf.config(text=f"已选择 PDF:{path}")
append_log(f"已选择 PDF 文件:{path}")
def choose_output_and_run():
"""按钮2:选择输出目录并开始拆分"""
global selected_output_dir, selected_pdf_file
if not selected_pdf_file:
messagebox.showwarning("提示", "请先选择 PDF 文件!")
return
path = filedialog.askdirectory(title="请选择输出目录")
if not path:
return
selected_output_dir = path
label_output.config(text=f"输出目录:{path}")
append_log("")
append_log(f"输出目录设置为:{path}")
append_log("开始拆分,请稍候...\n")
# 清理一下旧的错误提示
try:
split_pdf_by_chapters(selected_pdf_file, selected_output_dir, logger=append_log)
messagebox.showinfo("完成", "拆分完成!\n请到输出目录查看各章节文件夹。")
except Exception as e:
append_log(f"❌ 出错:{e}")
messagebox.showerror("错误", f"处理过程中出现错误:\n{e}")
if __name__ == "__main__":
# 创建窗口
root = tk.Tk()
root.title("PDF 章节拆分工具")
root.geometry("400x400") # 固定为 400x400 的窗口
root.resizable(False, False)
# 上半部分:按钮区域
btn_frame = tk.Frame(root)
btn_frame.pack(padx=10, pady=10, fill="x")
# 按钮1:选择 PDF
btn_pdf = tk.Button(btn_frame, text="1. 请选择你的 PDF 文件", command=choose_pdf)
btn_pdf.pack(fill="x")
label_pdf = tk.Label(btn_frame, text="尚未选择 PDF 文件", anchor="w")
label_pdf.pack(fill="x", pady=(5, 10))
# 按钮2:选择输出目录 + 开始拆分
btn_output = tk.Button(btn_frame, text="2. 请选择输出目录并开始拆分", command=choose_output_and_run)
btn_output.pack(fill="x")
label_output = tk.Label(btn_frame, text="尚未选择输出目录", anchor="w")
label_output.pack(fill="x", pady=(5, 0))
# 下半部分:日志输出区域(带滚动条)
log_frame = tk.Frame(root)
log_frame.pack(padx=10, pady=10, fill="both", expand=True)
log_text = tk.Text(log_frame, state="disabled")
log_text.pack(side="left", fill="both", expand=True)
scrollbar = tk.Scrollbar(log_frame, command=log_text.yview)
scrollbar.pack(side="right", fill="y")
log_text.config(yscrollcommand=scrollbar.set)
append_log("日志初始化完成。")
append_log("提示:先选择 PDF 文件,再选择输出目录开始拆分。")
root.mainloop()