TL;DR
- 场景:Nginx access.log 采集到 Kafka,经 Logstash 清洗(含 GeoIP)落 ES
- 结论:Ubuntu 22.04 上 Filebeat 7.3 可能启动失败,升级到 7.17 可直接恢复
- 产出:可复用的 filebeat.yml + logstash_kafka_es.conf 及常见故障定位/修复表

版本矩阵
| 组件 | 版本 | 环境/系统 | 已验证 | 说明 |
|---|---|---|---|---|
| Filebeat | 7.3.0 | Ubuntu 22.04.3 | 否 | 文中出现 cgo/pthread 报错,无法启动(同机型/权限场景下) |
| Filebeat | 7.17.0 | Ubuntu 22.04.3 | 是 | 按文中配置可启动并向 Kafka 写入事件,事件 metadata 显示 7.17.0 |
| Logstash | 7.3.0 | 未明确 | 部分 | -t 配置测试通过并可启动;系统/JDK 未提供,跨环境结论不外推 |
| Kafka | 未提供 | 未提供 | 部分 | 仅验证到可被 filebeat 写入、可用 console-consumer 消费(版本/鉴权未描述) |
| Elasticsearch | 未提供 | 未提供 | 否 | 仅给出 output 配置与索引命名规则,未提供 ES 版本与落库验证截图/查询 |

Filebeat
官方地址
Filebeat主要为了解决Logstash工具是消耗资源比较严重的问题,因为Logstash是Java语言编写的,需要启动一个虚拟机。官方为了优化这个问题推出了一些轻量级的采集工具,Beats系列,其中比较广泛使用的是Filebeat。
shell
https://www.elastic.co/guide/en/beats/filebeat/7.3/index.html对比区别
- Logstash是运行在Java虚拟机上的,启动一个Logstash需要消耗500M的内存(所以启动特别慢),而Filebeat只需要10M左右
- 常用的ELK日志采集中,大部分的做法就是将所有节点的日志内容通过Filebeat发送到Kafka集群,Logstash消费Kafka,再根据配置文件进行过滤,然后将过滤的文件输出到Elasticsearch中,再到Kibana去展示。
项目安装
目前我选择在 h121 节点上,你可以按照自己的情况来安装。
shell
cd /opt/software
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.0-linux-x86_64.tar.gz结果如下图所示: 
解压配置
shell
tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz
mv filebeat-7.3.0-linux-x86_64 ../servers
cd ../servers对应的内容如下图所示:  修改配置文件如下:
修改配置文件如下:
shell
cd /opt/servers/filebeat-7.3.0-linux-x86_64
vim filebeat.yml当前文件内容如下所示: 
input部分
修改为如下的内容 filebeat.inputs 部分的内容:
shell
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /opt/wzk/logs/access.log
#- c:\programdata\elasticsearch\logs\*
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ['^DBG']
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ['^ERR', '^WARN']
# Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#exclude_files: ['.gz$']
# Optional additional fields. These fields can be freely picked
# to add additional information to the crawled log files for filtering
fields:
app: www
type: nginx-access
fields_under_root: true
### Multiline options修改的截图如下: 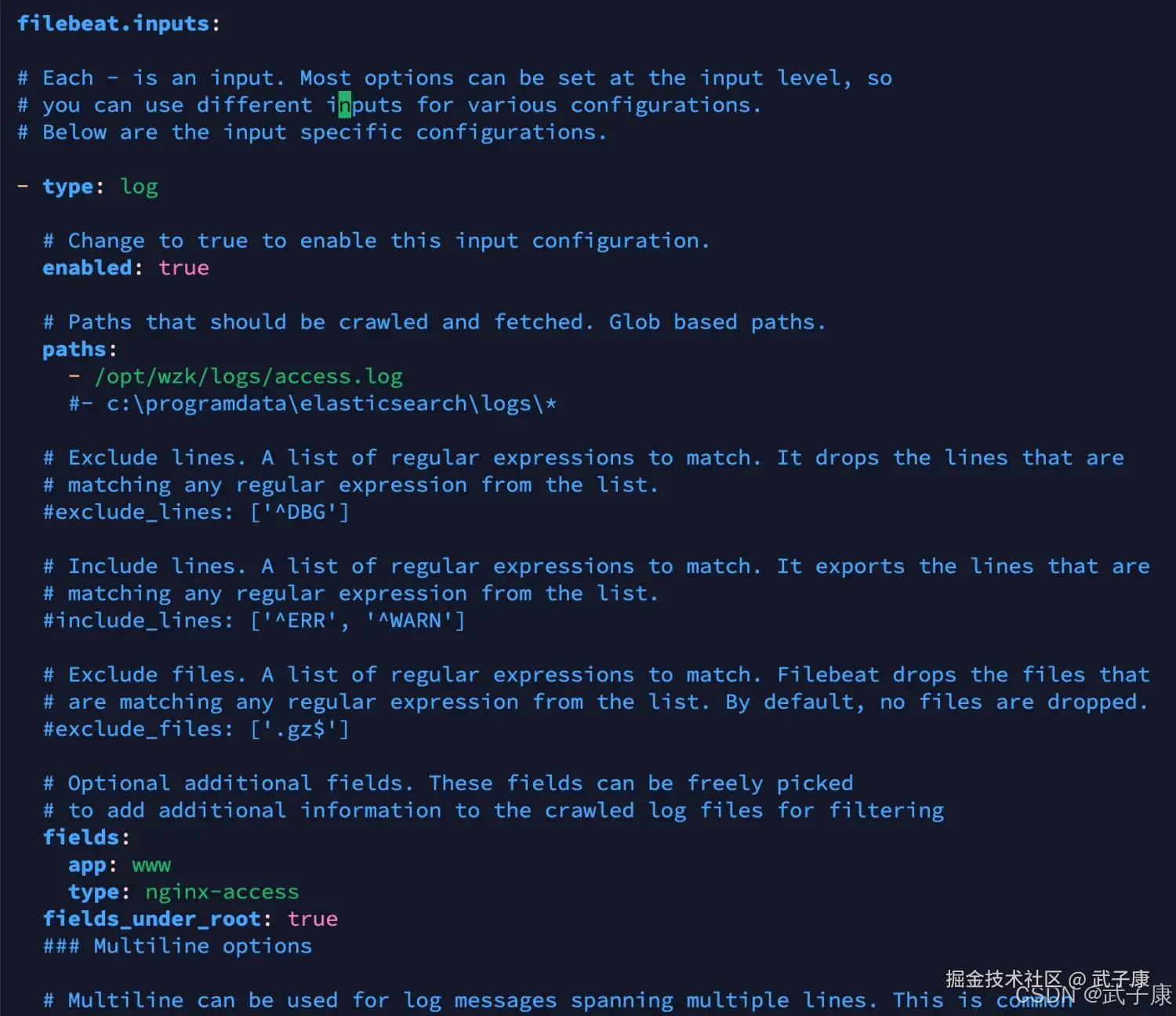
output部分
shell
output.kafka:
hosts: ["h121.wzk.icu:9092"]
topic: "nginx_access_log"对应的截图如下所示: 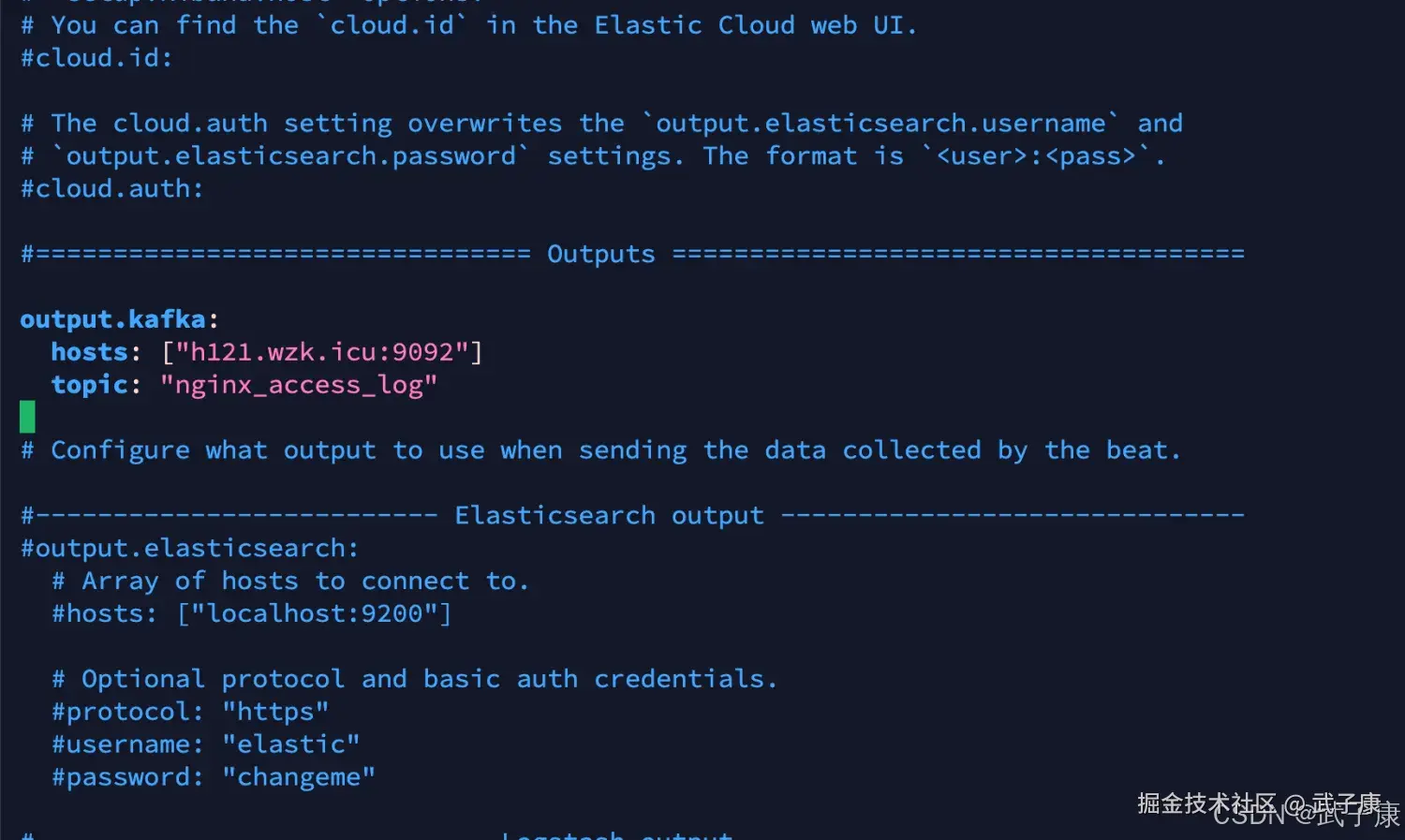
启动服务
shell
cd /opt/servers/filebeat-7.3.0-linux-x86_64
./filebeat -e -c filebeat.yml如果你在这里遇到了 runtime-cgo-pthread-create-failed-operation-not-permitted 的错误,那你可以尝试将 FileBeat 的版本进行提升,我这里就遇到了,所以后续进行版本提升
遇到错误 runtime-cgo-pthread-create-failed-operation-not-permitted
如果你没有遇到,直接跳过! 我这里版本一点点的往上尝试,大致猜测是操作系统的版本可能新一些,所以原来的Go的库无法支持新的操作系统了(猜测的)。 这里我测试到 7.17 的版本就好了:
shell
cd /opt/software
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.0-linux-x86_64.tar.gz根据刚才的操作,我已经配置好了路劲等内容,且修改了 filebeat.yml 的配置文件内容  进行启动测试:
进行启动测试:
shell
cd /opt/servers/filebeat-7.17.0-linux-x86_64
./filebeat -e -c filebeat.yml顺利启动,启动结果如下图: 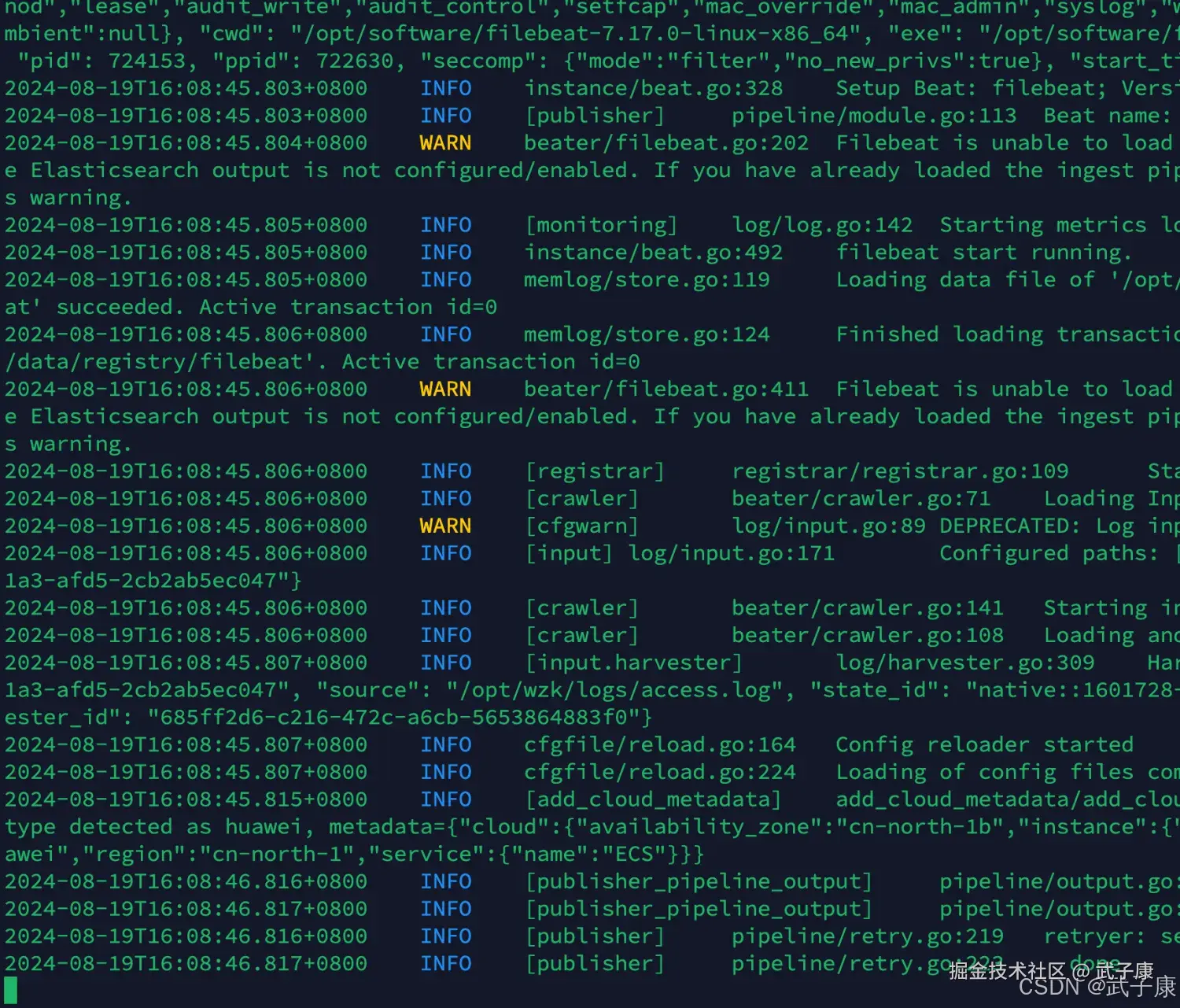
测试数据
启动一切正常之后,我们在Nginx刷新几次,来生成一些数据出来。
查看消费
shell
kafka-console-consumer.sh --bootstrap-server h121.wzk.icu:9092 --topic nginx_access_log --
from-beginning可以看到数据已经来了: 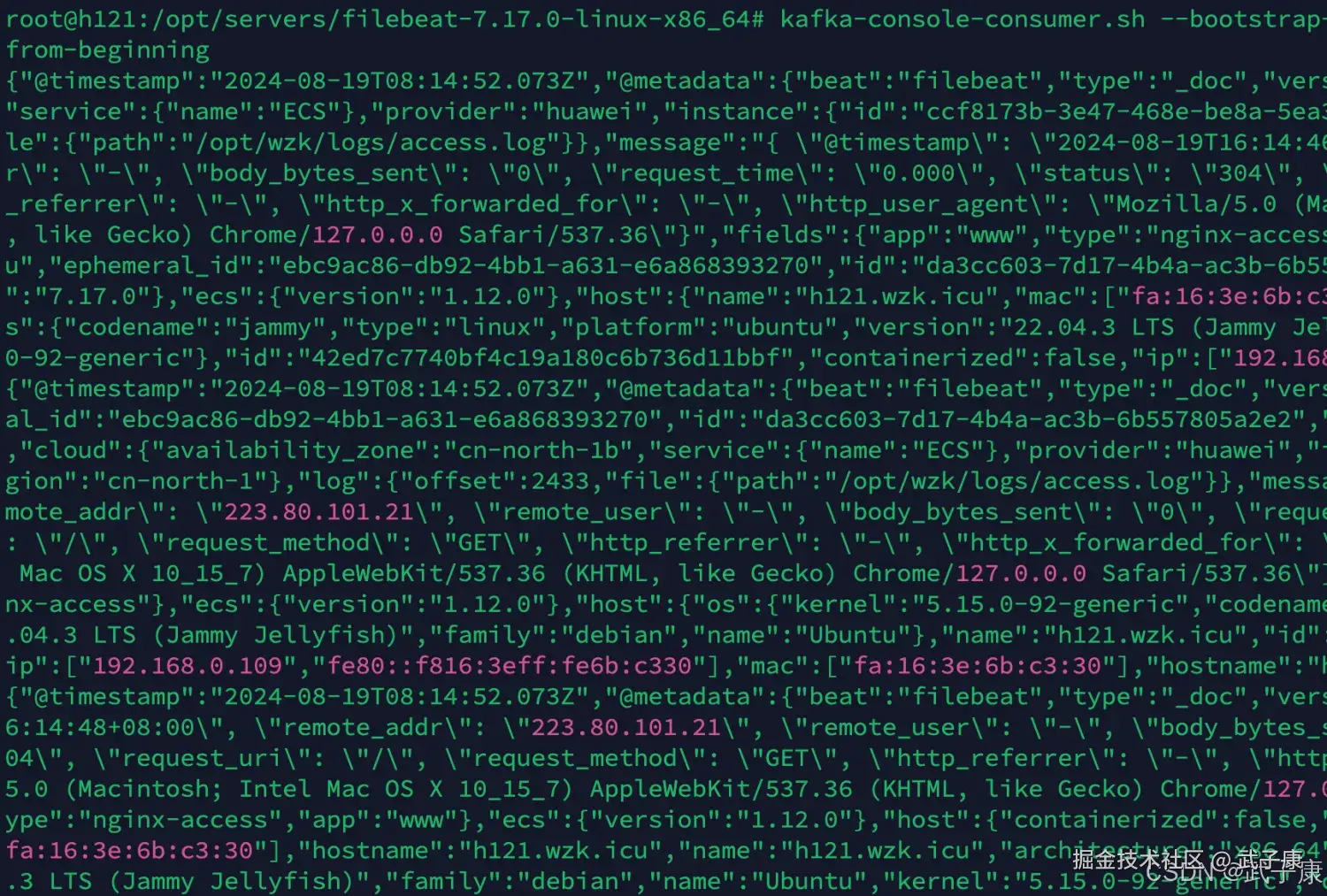 我们进行一下JSON的格式化操作:
我们进行一下JSON的格式化操作:
json
{
"@timestamp": "2024-08-19T08:14:52.073Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.0"
},
"cloud": {
"availability_zone": "cn-north-1b",
"service": {
"name": "ECS"
},
"provider": "huawei",
"instance": {
"id": "ccf8173b-3e47-468e-be8a-5ea3a03c76e0"
},
"region": "cn-north-1"
},
"log": {
"offset": 2034,
"file": {
"path": "/opt/wzk/logs/access.log"
}
},
"message": "{ \"@timestamp\": \"2024-08-19T16:14:46+08:00\", \"remote_addr\": \"223.80.101.21\", \"remote_user\": \"-\", \"body_bytes_sent\": \"0\", \"request_time\": \"0.000\", \"status\": \"304\", \"request_uri\": \"/\", \"request_method\": \"GET\", \"http_referrer\": \"-\", \"http_x_forwarded_for\": \"-\", \"http_user_agent\": \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36\"}",
"fields": {
"app": "www",
"type": "nginx-access"
},
"input": {
"type": "log"
},
"agent": {
"hostname": "h121.wzk.icu",
"ephemeral_id": "ebc9ac86-db92-4bb1-a631-e6a868393270",
"id": "da3cc603-7d17-4b4a-ac3b-6b557805a2e2",
"name": "h121.wzk.icu",
"type": "filebeat",
"version": "7.17.0"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "h121.wzk.icu",
"mac": ["fa:16:3e:6b:c3:30"],
"hostname": "h121.wzk.icu",
"architecture": "x86_64",
"os": {
"codename": "jammy",
"type": "linux",
"platform": "ubuntu",
"version": "22.04.3 LTS (Jammy Jellyfish)",
"family": "debian",
"name": "Ubuntu",
"kernel": "5.15.0-92-generic"
},
"id": "42ed7c7740bf4c19a180c6b736d11bbf",
"containerized": false,
"ip": ["192.168.0.109", "fe80::f816:3eff:fe6b:c330"]
}
}Logstash
官方文档
Logstash用来读取Kafka中的数据
shell
https://www.elastic.co/guide/en/logstash/7.3/plugins-inputs-kafka.html编写配置
shell
cd /opt/servers/logstash-7.3.0/config
vim logstash_kafka_es.conf修改如下的配置如何:
shell
input {
kafka {
bootstrap_servers => "h121.wzk.icu:9092"
topics => ["nginx_access_log"]
codec => "json"
}
}
filter {
if [app] == "www" {
if [type] == "nginx-access" {
json {
source => "message"
remove_field => ["message"]
}
geoip {
source => "remote_addr"
target => "geoip"
database => "/opt/wzk/GeoLite2-City.mmdb"
add_field => ["[geoip][coordinates]", "%{[geoip][longitude]}"]
add_field => ["[geoip][coordinates]", "%{[geoip][latitude]}"]
}
mutate {
convert => ["[geoip][coordinates]", "float"]
}
}
}
}
output {
elasticsearch {
hosts => ["http://h121.wzk.icu:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}下载依赖
我们看到这里用了一个 GeoLite2-City.mmdb,我们需要下载GeoLite2-City.mmdb:
shell
https://github.com/P3TERX/GeoLite.mmdb?tab=readme-ov-file这里我直接下载:
shell
cd /opt/wzk/
wget https://git.io/GeoLite2-City.mmdb下载过程如下图所示: 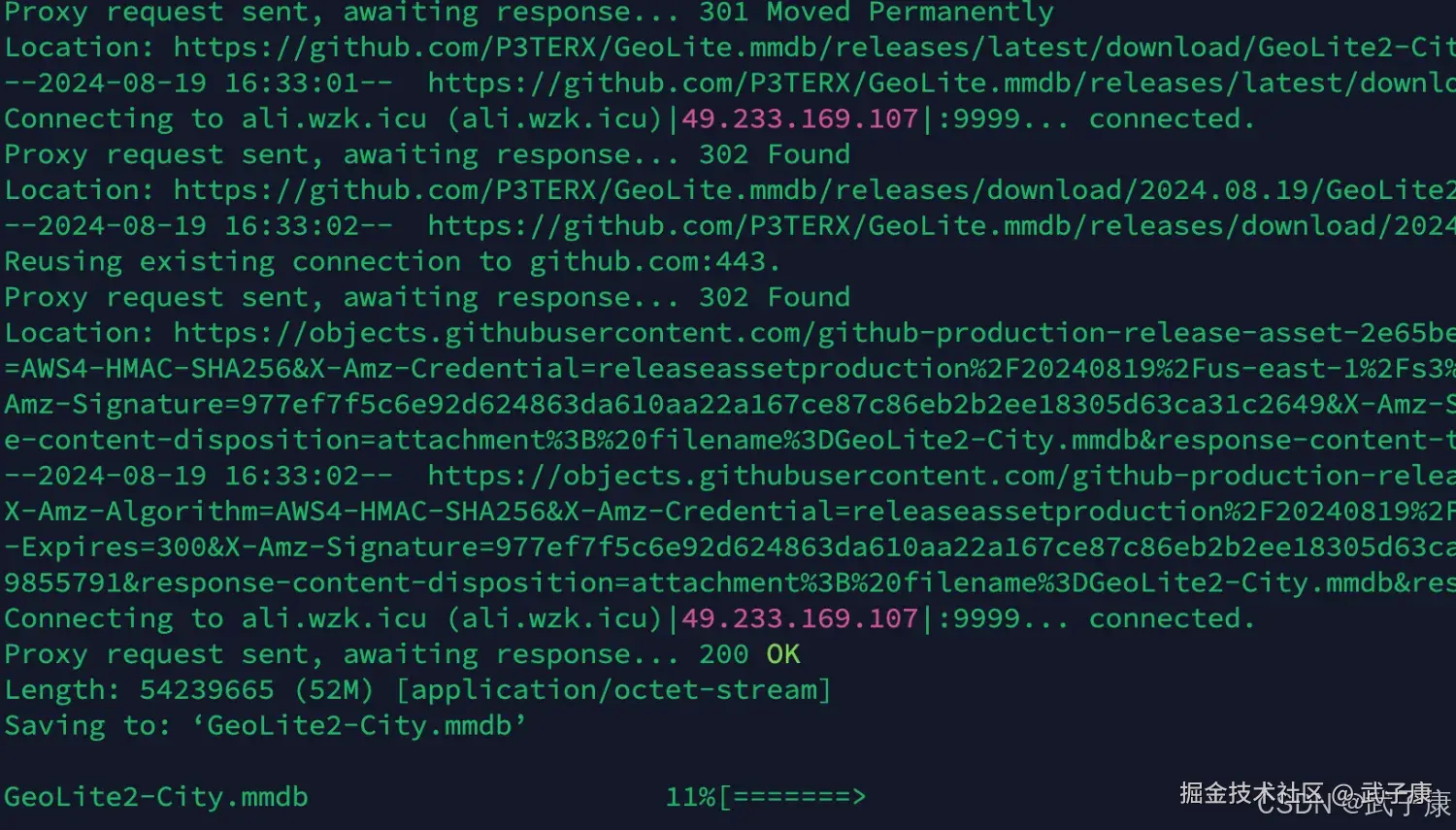
测试服务
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/logstash_kafka_es.conf -t运行的结果如下图所示: 
启动服务
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/logstash_kafka_es.conf启动之后结果如下图: 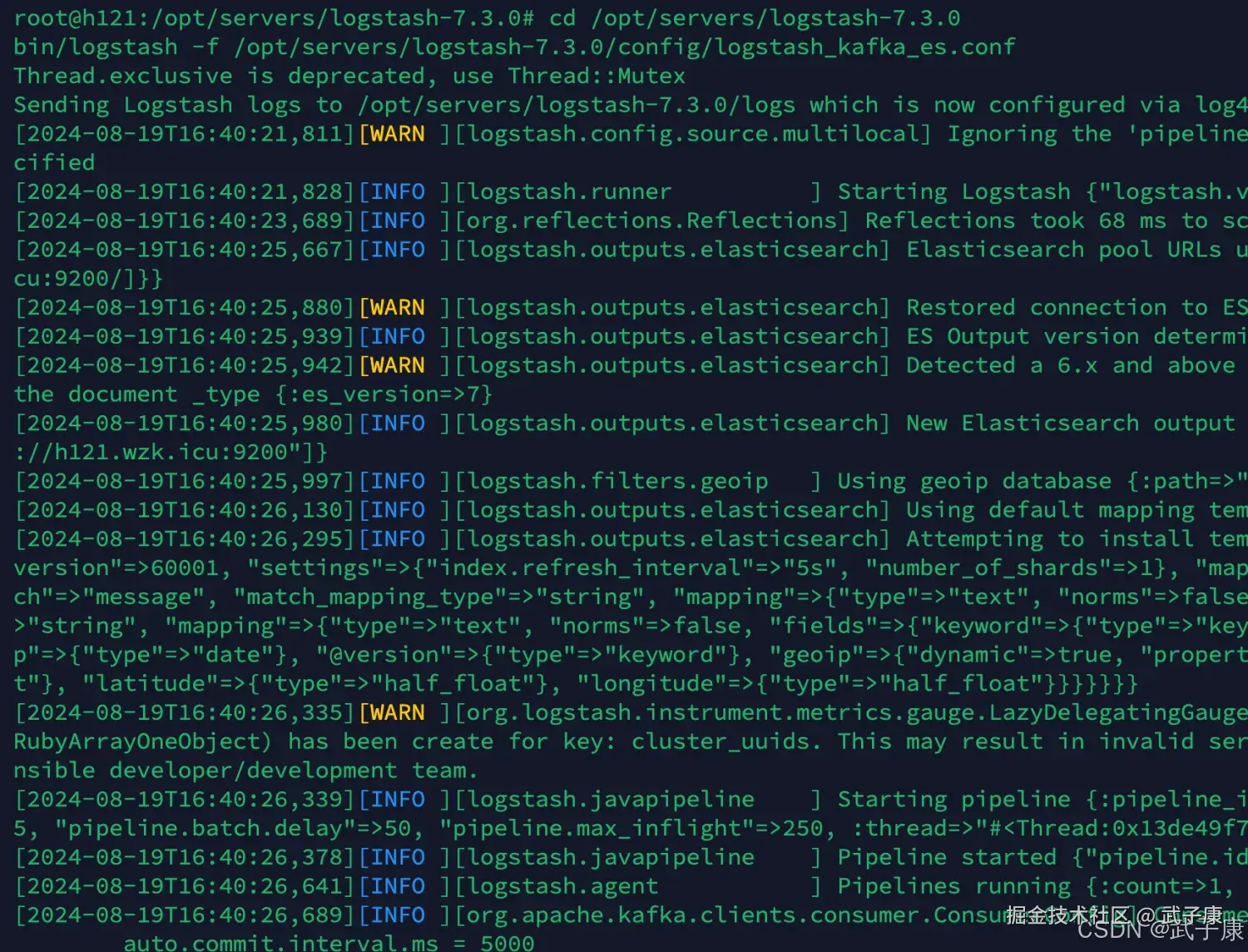 Kafa对应的日志部分:
Kafa对应的日志部分: 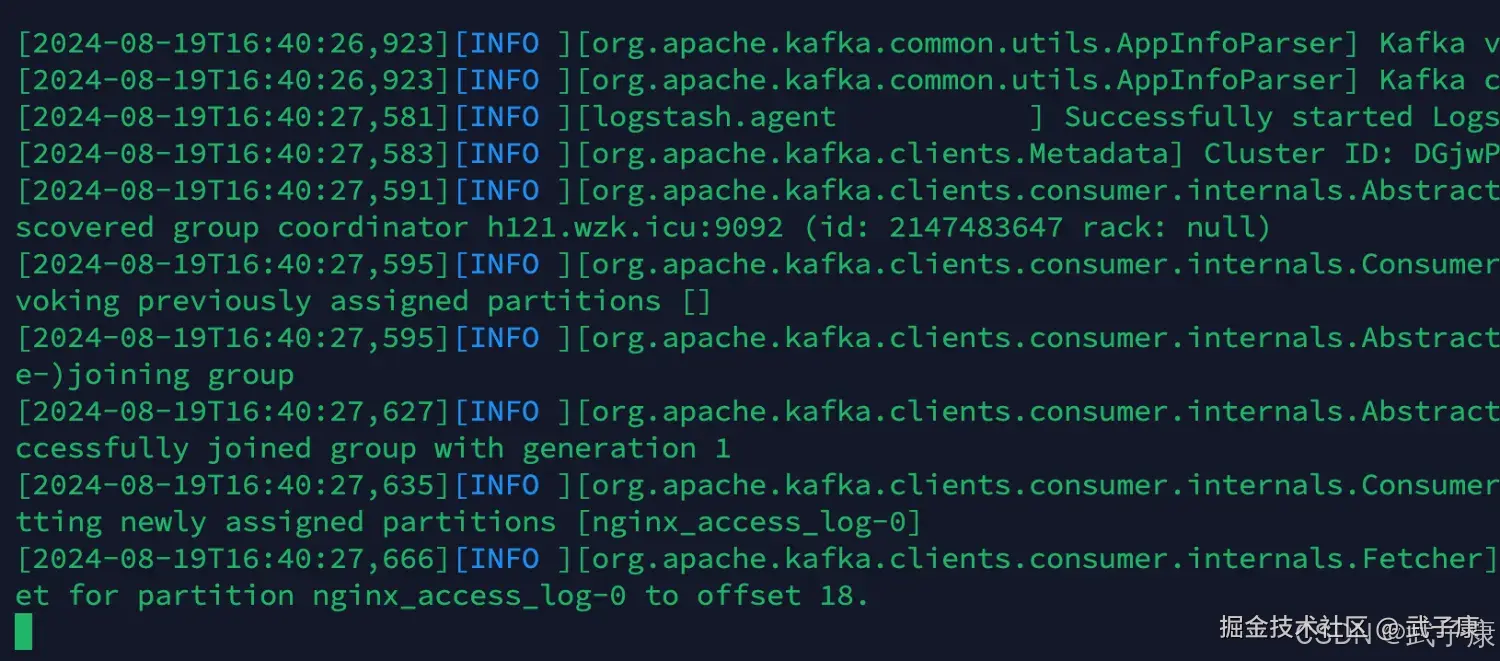
测试数据
我们刷新Nginx的页面,提供一些数据出来。 我们可以看到 Logstash 的控制台输出了对应的内容: 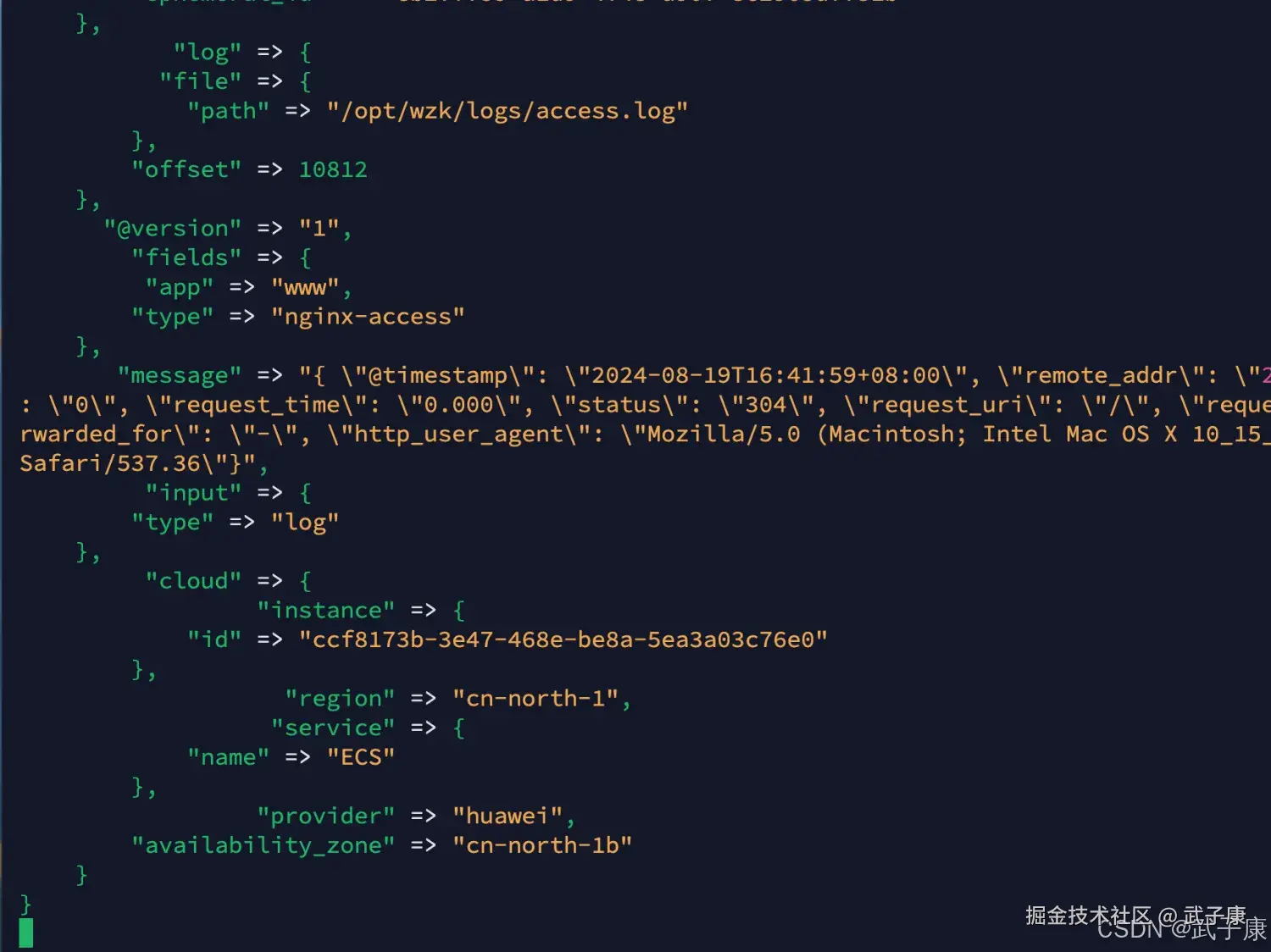
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Filebeat 启动报 runtime-cgo-pthread-create-failed-operation-not-permitted | 二进制/Go 运行时与系统/权限/线程限制不兼容(在新系统更常见) | 直接在 ./filebeat -e -c filebeat.yml 控制台复现 | 升级 Filebeat 到 7.17.0(文中验证可用),保持原配置迁移 |
| Kafka 端消费不到数据 | input 路径无新日志、enabled 未开、topic/hosts 配错 | Filebeat 控制台看 harvest/publish;Kafka 用 console-consumer 验证 | 确认 filebeat.inputs.enabled: true、paths 指向真实文件、output.kafka.hosts/topic 正确;刷新 Nginx 产生新行 |
| Kafka console-consumer 命令报错或不输出 | 命令参数被换行/截断(--from-beginning 写成 --\nfrom-beginning) | 直接看命令行回显 | 使用完整一行命令:kafka-console-consumer.sh --bootstrap-server ... --topic ... --from-beginning |
| Logstash 解析后字段缺失/仍是原 message 字符串 | codec => json 只解析 Kafka 外层事件;真正业务 JSON 在 message 字段内,需要二次 json filter | stdout(rubydebug) 观察事件结构:外层字段 vs message 字符串 | 保持 codec => json,再用 json { source => "message" remove_field => "message" } 二次解析(文中已配置) |
| GeoIP 不生效或启动报数据库路径错误 | mmdb 文件不存在/路径不对/权限不足 | Logstash 日志搜 GeoIP/mmdb;检查 /opt/wzk/GeoLite2-City.mmdb | 确保 mmdb 存在且可读;路径与配置一致;必要时调整文件权限/属主 |
| ES 无索引或写入失败 | ES 地址不可达、索引权限/模板问题、网络/认证未配置 | Logstash 输出中看 elasticsearch output 的错误堆栈 | 先用 curl 测 ES 连通;确认 hosts => "[http://...:9200](https://link.juejin.cn?target=http%3A%2F%2F...%3A9200 "http://...:9200")" 可访问;如启用安全认证需补充用户名密码/SSL 配置 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解