概述
MySQL作为最流行的开源关系型数据库,在互联网应用中扮演着核心角色。理解MySQL的架构原理与SQL执行流程,是每位后端工程师的必修课。本文从MySQL逻辑架构、InnoDB存储引擎、Buffer Pool缓冲池、B+树索引原理、SQL执行流程(SELECT/UPDATE)、EXPLAIN执行计划分析等多个维度,深入剖析MySQL的内部运行机制,并结合生产环境实战案例,讲解慢查询优化、索引优化等最佳实践,帮助读者构建完整的MySQL性能优化知识体系,在面试和实际工作中游刃有余。
一、理论知识与核心概念
1.1 MySQL的定位与特点
MySQL是一款开源的关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,现属于Oracle旗下产品。MySQL凭借其高性能、高可靠性、易用性,成为互联网应用的首选数据库。
核心特点:
- 开源免费: 社区版(GPL许可)免费使用,降低企业成本
- 跨平台: 支持Linux、Windows、macOS等多种操作系统
- 高性能: 支持千万级数据表,QPS可达数万甚至数十万
- 高可用: 支持主从复制、MGR集群等高可用方案
- 丰富的存储引擎: InnoDB、MyISAM、Memory等,满足不同场景需求
- ACID事务支持: InnoDB引擎支持完整的ACID事务特性
- 强大的社区支持: 庞大的开发者社区,丰富的文档和工具
1.2 InnoDB vs MyISAM
MySQL支持多种存储引擎,其中InnoDB和MyISAM是最常用的两种:
InnoDB (MySQL 5.5+默认引擎):
- ✅ 支持事务(ACID特性),适合金融、电商等对数据一致性要求高的场景
- ✅ 行级锁,并发性能好,支持高并发写操作
- ✅ 支持外键约束,保证数据完整性
- ✅ 崩溃恢复能力强,通过Redo Log保证数据不丢失
- ✅ MVCC多版本并发控制,提升读写并发性能
- ❌ 占用空间大,每个表对应.ibd文件,包含数据和索引
MyISAM (老版本默认引擎):
- ❌ 不支持事务,无法保证数据一致性
- ❌ 表级锁,并发写性能差
- ❌ 不支持外键约束
- ✅ 插入速度快,适合日志、历史数据等只读或少写场景
- ✅ 占用空间小,每个表对应3个文件(.frm/.MYD/.MYI)
结论: 生产环境强烈推荐使用InnoDB引擎,MyISAM已逐步被淘汰。
1.3 核心概念
Buffer Pool (缓冲池):
- InnoDB的核心内存结构,缓存数据页和索引页,减少磁盘I/O
- 默认大小128MB,生产环境建议设置为物理内存的50-80%
- 采用改进的LRU算法管理缓存,分为Young区和Old区
B+树:
- MySQL索引的底层数据结构,非叶子节点只存储键值,所有数据在叶子节点
- 3层B+树能存储约2000万行数据,查询只需3次磁盘I/O
- 叶子节点通过双向链表连接,范围查询高效
WAL (Write-Ahead Logging):
- 先写日志,再写数据的机制,核心是Redo Log
- Redo Log顺序写(快),数据文件随机写(慢),写入性能提升10-100倍
- 崩溃恢复时通过Redo Log重放,保证数据不丢失
2PC (Two-Phase Commit):
- 两阶段提交协议,保证Redo Log和Binlog一致性
- 流程: Redo Log prepare → 写Binlog → Redo Log commit
- 避免主从数据不一致
二、MySQL逻辑架构详解
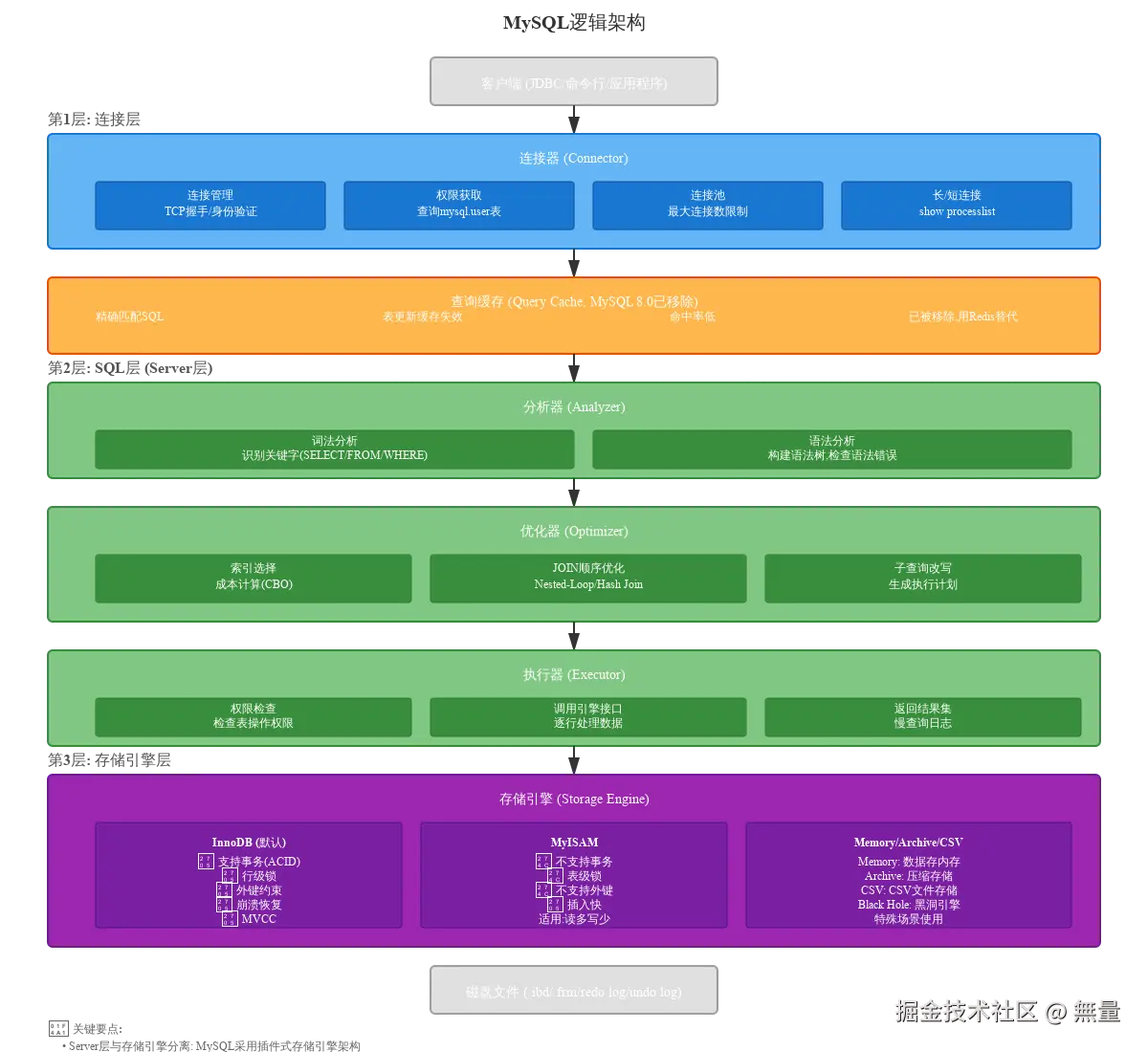
MySQL采用分层架构设计,从上到下分为3层:连接层、SQL层(Server层)、存储引擎层。这种分层设计实现了Server层与存储引擎的解耦,支持插件式存储引擎。
2.1 第1层: 连接层 (Connector)
连接层负责客户端连接管理,包括连接建立、身份验证、权限获取。
连接建立流程:
- TCP三次握手: 客户端(如JDBC、MySQL命令行)与MySQL Server建立TCP连接
- 身份验证 : 服务器验证用户名和密码,查询
mysql.user表 - 权限获取: 验证通过后,从权限表中读取该用户的权限信息,缓存到连接对象中
- 加入连接池 : 连接加入连接池,可通过
SHOW PROCESSLIST查看当前所有连接
连接类型:
- 短连接: 每次查询后立即断开,适合低频访问场景
- 长连接: 保持连接不断开,适合高频访问场景(如Web应用)
长连接的问题: 长时间使用后,MySQL Server内存占用会持续增长,因为连接过程中的临时内存不会释放。
解决方案:
- 定期断开长连接: 连接使用超过一定时间(如8小时)或执行过大查询后,主动断开重连
- 执行
mysql_reset_connection: MySQL 5.7+支持,重置连接状态,释放临时内存,无需重新建立连接
关键参数:
bash
max_connections=1000 # 最大连接数,默认151
wait_timeout=28800 # 非交互连接超时时间(秒),默认8小时
interactive_timeout=28800 # 交互式连接超时时间(秒)2.2 第2层: SQL层 (Server层) - 查询缓存
查询缓存是MySQL Server层的第一道关卡,在MySQL 8.0已被移除。
工作原理:
- 使用SQL语句作为key,查询结果作为value,存储到缓存中
- 后续完全相同的SQL直接返回缓存结果,跳过后续的分析、优化、执行步骤
为什么被移除?
- 命中率极低: SQL必须完全相同(包括空格、大小写),稍有差异就无法命中
- 失效频繁: 只要表有任何更新(INSERT/UPDATE/DELETE),该表的所有查询缓存全部失效
- 维护成本高: 缓存的加锁、失效、淘汰机制带来额外开销
- 适用场景少: 只适合静态表(如配置表、字典表),实际生产中极少
替代方案: 使用Redis、Memcached等外部缓存中间件,更灵活、命中率更高。
2.3 第3层: SQL层 (Server层) - 分析器
分析器负责对SQL语句进行词法分析和语法分析,生成语法树(AST)。
词法分析 (Lexical Analysis):
将SQL字符串拆解为一个个token(词法单元):
sql
SELECT id, name, age FROM users WHERE age > 25 ORDER BY id LIMIT 10;拆解结果:
- 关键字: SELECT, FROM, WHERE, ORDER BY, LIMIT
- 标识符: id, name, age, users
- 常量: 25, 10
- 运算符: >, =
语法分析 (Syntax Analysis):
根据MySQL的语法规则,将token序列组织成语法树(Parse Tree / AST):
vbnet
SELECT
├── SELECT LIST: id, name, age
├── FROM: users
├── WHERE: age > 25
├── ORDER BY: id
└── LIMIT: 10语法错误检查:
如果SQL不符合语法规则,分析器报错:
sql
SELECT * FORM users; -- 错误: 关键字拼写错误(FROM写成FORM)报错信息: You have an error in your SQL syntax; check the manual...
输出: 语法树(AST),供优化器使用。
2.4 第4层: SQL层 (Server层) - 优化器
优化器负责生成最优的执行计划,决定如何高效地执行SQL。
核心任务:
1. 索引选择:
查询users表有哪些索引可用:
- 主键索引:
PRIMARY KEY (id) - 二级索引:
idx_age (age),idx_name (name),idx_age_name (age, name)
成本计算 (CBO - Cost-Based Optimizer):
MySQL使用基于成本的优化器,计算每种执行方式的成本,选择成本最低的:
- 全表扫描成本: 读取所有数据页的I/O成本 + CPU计算成本
- 索引扫描成本: 读取索引页的I/O成本 + 回表I/O成本 + CPU成本
成本公式(简化版):
ini
Cost = I/O_cost + CPU_cost
I/O_cost = pages_read × io_cost_per_page
CPU_cost = rows_examined × cpu_cost_per_row索引选择策略:
- 条件字段有索引: 优先使用索引
- 多个索引可选: 选择选择性最高的索引(扫描行数最少)
- 索引扫描成本 > 全表扫描成本: 使用全表扫描(如查询结果占表总行数的30%以上)
2. JOIN顺序优化:
多表JOIN时,JOIN顺序影响性能:
sql
SELECT * FROM orders o
JOIN users u ON o.user_id = u.id
JOIN products p ON o.product_id = p.id
WHERE u.age > 25;可能的JOIN顺序:
orders → users → productsusers → orders → products(优化器可能选择这个,因为先过滤users.age > 25,减少JOIN行数)
3. 子查询改写:
优化器可能将子查询改写为JOIN:
sql
-- 原始SQL (子查询)
SELECT * FROM users WHERE id IN (SELECT user_id FROM orders WHERE status = 1);
-- 优化器改写为JOIN (可能更高效)
SELECT u.* FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.status = 1;输出 : 执行计划(Execution Plan),可通过EXPLAIN查看。
2.5 第5层: SQL层 (Server层) - 执行器
执行器负责执行SQL,调用存储引擎接口逐行读取数据。
执行流程:
1. 权限检查:
检查用户是否有该表的SELECT权限(权限在连接阶段已获取):
sql
SELECT id, name FROM users WHERE age > 25;如果无权限,报错: Access denied for user 'xxx'@'xxx' to table 'users'
2. 调用存储引擎接口:
执行器调用InnoDB引擎的read接口,传入条件age > 25:
ini
executor.read(table="users", condition="age > 25")3. 逐行读取数据:
- InnoDB根据执行计划(使用idx_age索引)定位数据
- 通过B+树查找age > 25的第一行
- 返回给执行器
- 执行器继续调用read接口,读取下一行
- 重复直到读完所有符合条件的行
4. 过滤、排序、限制:
- 过滤: WHERE条件过滤不符合条件的行
- 排序: ORDER BY id (可能使用idx_id索引避免排序,或使用filesort)
- 限制: LIMIT 10,只返回前10行
5. 返回结果集:
执行器将结果集返回给客户端。
6. 记录慢查询日志:
如果查询时间 > long_query_time(默认10秒),记录到慢查询日志:
bash
slow_query_log=ON # 开启慢查询日志
long_query_time=1 # 慢查询阈值1秒
slow_query_log_file=/var/log/mysql-slow.log2.6 Server层总结
Server层是MySQL的大脑,负责连接管理、SQL解析、优化、执行,与存储引擎无关。同一条SQL,无论使用InnoDB还是MyISAM,Server层的处理流程完全相同,只是最后调用的存储引擎接口不同。
Server层与存储引擎的分层设计优势:
- 解耦: Server层专注SQL处理,存储引擎专注数据存储和读写
- 插件式架构: 可自由切换存储引擎(InnoDB/MyISAM/Memory),无需修改SQL
- 灵活性: 不同表可使用不同存储引擎,满足不同业务需求
三、InnoDB存储引擎架构
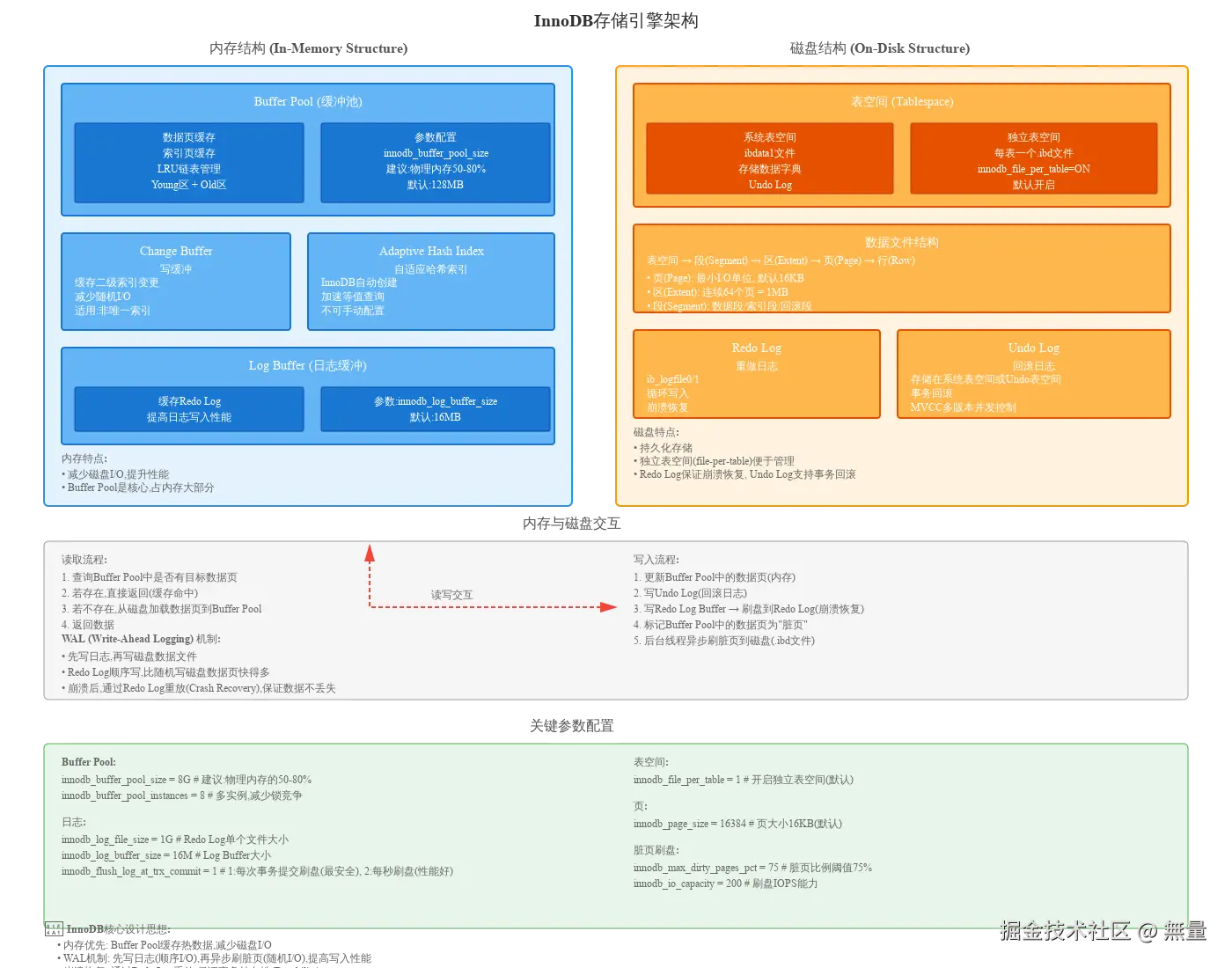 InnoDB是MySQL的默认存储引擎(MySQL 5.5+),专为事务处理设计,架构分为内存结构 和磁盘结构两大部分。
InnoDB是MySQL的默认存储引擎(MySQL 5.5+),专为事务处理设计,架构分为内存结构 和磁盘结构两大部分。
3.1 InnoDB整体架构
InnoDB的核心设计思想 : 内存优先 + WAL机制 + 崩溃恢复
- 内存优先: 数据优先缓存到Buffer Pool,减少磁盘I/O
- WAL (Write-Ahead Logging): 先写日志(Redo Log),再异步刷脏页,提升写入性能
- 崩溃恢复: 通过Redo Log重放,保证事务持久性(Durability)
3.2 内存结构 (In-Memory Structure)
1. Buffer Pool (缓冲池):
Buffer Pool是InnoDB性能的核心,缓存数据页和索引页,减少磁盘I/O。
缓存内容:
- 数据页 (Data Page): 表的行数据
- 索引页 (Index Page): B+树索引节点
- 插入缓冲 (Insert Buffer): 二级索引的插入缓冲
- 自适应哈希索引 (Adaptive Hash Index): InnoDB自动创建的哈希索引
- 锁信息 (Lock Info): 行锁、表锁信息
LRU链表管理:
Buffer Pool采用改进的LRU(Least Recently Used)算法管理缓存页,分为两个区域:
- Young区 (新数据区): 占Buffer Pool的5/8 (62.5%),存放热数据
- Old区 (老数据区): 占Buffer Pool的3/8 (37.5%),存放冷数据
Midpoint插入策略:
传统LRU算法的问题: 全表扫描会将大量冷数据加载到缓存,挤掉热数据(缓存污染)。
InnoDB的改进:
- 新数据页不插入链表头,而是插入Old区头部(Midpoint位置)
- 只有在Old区停留≥1秒(
innodb_old_blocks_time=1000)后再次访问,才移动到Young区 - 全表扫描的数据页只停留在Old区,不影响Young区的热数据
Buffer Pool参数配置:
bash
innodb_buffer_pool_size=8G # Buffer Pool大小,建议物理内存的50-80%
innodb_buffer_pool_instances=8 # Buffer Pool实例数,减少锁竞争
innodb_old_blocks_pct=37 # Old区占比37% (默认)
innodb_old_blocks_time=1000 # Old区停留时间1秒 (默认)2. Change Buffer (写缓冲):
Change Buffer用于缓存二级索引(非唯一索引)的变更操作,减少随机I/O。
工作原理:
当更新非唯一索引时:
- 如果索引页在Buffer Pool: 直接更新
- 如果索引页不在Buffer Pool: 将变更记录到Change Buffer (而不是立即从磁盘加载索引页)
- 后续读取该索引页时,合并Change Buffer中的变更(Merge操作)
适用场景: 非唯一索引,写多读少的场景(如日志表、历史记录表)
为什么唯一索引不能用Change Buffer?
唯一索引需要检查唯一性约束,必须读取索引页,无法延迟更新。
3. Adaptive Hash Index (自适应哈希索引):
InnoDB自动创建的哈希索引,加速等值查询。
工作原理:
- InnoDB监控B+树索引的访问模式
- 对于频繁访问的索引页,自动创建哈希索引
- 哈希查询O(1)时间复杂度,比B+树O(log n)更快
限制: 只支持等值查询(=),不支持范围查询(<, >),由InnoDB自动管理,无法手动配置。
4. Log Buffer (日志缓冲):
Log Buffer缓存Redo Log,提高日志写入性能。
工作流程:
- 事务修改数据时,先写Redo Log Buffer (内存)
- 事务提交时,将Redo Log Buffer刷盘到ib_logfile0/1 (磁盘)
- 刷盘策略由
innodb_flush_log_at_trx_commit控制
参数配置:
bash
innodb_log_buffer_size=16M # Log Buffer大小,默认16MB
innodb_flush_log_at_trx_commit=1 # 刷盘策略:
# 0: 每秒刷盘一次 (性能最好,但可能丢失1秒数据)
# 1: 每次事务提交刷盘 (最安全,推荐)
# 2: 每次提交写OS缓存,每秒刷盘 (折中)3.3 磁盘结构 (On-Disk Structure)
1. 表空间 (Tablespace):
系统表空间 (System Tablespace):
- 文件: ibdata1
- 存储: 数据字典、Undo Log、Change Buffer、Doublewrite Buffer
- 特点: 所有表共享,不推荐存储用户数据
独立表空间 (File-Per-Table Tablespace):
- 文件: 每个表一个.ibd文件 (如users.ibd)
- 存储: 表的数据和索引
- 参数:
innodb_file_per_table=ON(MySQL 5.6+默认开启) - 优势: 表级别管理,DROP TABLE直接删除.ibd文件,回收空间
2. 数据文件结构:
表空间 → 段(Segment) → 区(Extent) → 页(Page) → 行(Row)
- 页(Page) : InnoDB最小I/O单位,默认16KB (
innodb_page_size=16384) - 区(Extent): 连续64个页,大小1MB (64 × 16KB)
- 段(Segment): 数据段、索引段、回滚段
3. Redo Log (重做日志):
Redo Log是InnoDB崩溃恢复的核心,记录数据页的物理修改。
文件:
- ib_logfile0, ib_logfile1 (默认2个文件)
- 循环写入(Circular Write),写满ib_logfile1后回到ib_logfile0
作用:
- 崩溃恢复: 重启后,通过Redo Log重放(redo),恢复未刷盘的脏页数据
- 事务持久性(Durability): 事务提交后,即使立即崩溃,Redo Log保证数据不丢失
Redo Log vs Binlog:
| 维度 | Redo Log | Binlog |
|---|---|---|
| 层次 | InnoDB引擎层 | MySQL Server层 |
| 作用 | 崩溃恢复 | 主从复制、数据备份 |
| 内容 | 物理日志(数据页的修改) | 逻辑日志(SQL语句或行变更) |
| 写入方式 | 循环写(固定大小,覆盖旧数据) | 追加写(一直写新文件) |
| 事务提交 | 2PC两阶段提交 | 2PC两阶段提交 |
4. Undo Log (回滚日志):
Undo Log用于事务回滚和MVCC多版本并发控制。
作用:
- 事务回滚: 记录修改前的旧值,事务失败时通过Undo Log回滚
- MVCC: 其他事务读取旧版本数据,实现快照读
存储位置: 系统表空间(ibdata1)或Undo表空间(undo_001, undo_002)
3.4 B+树索引原理
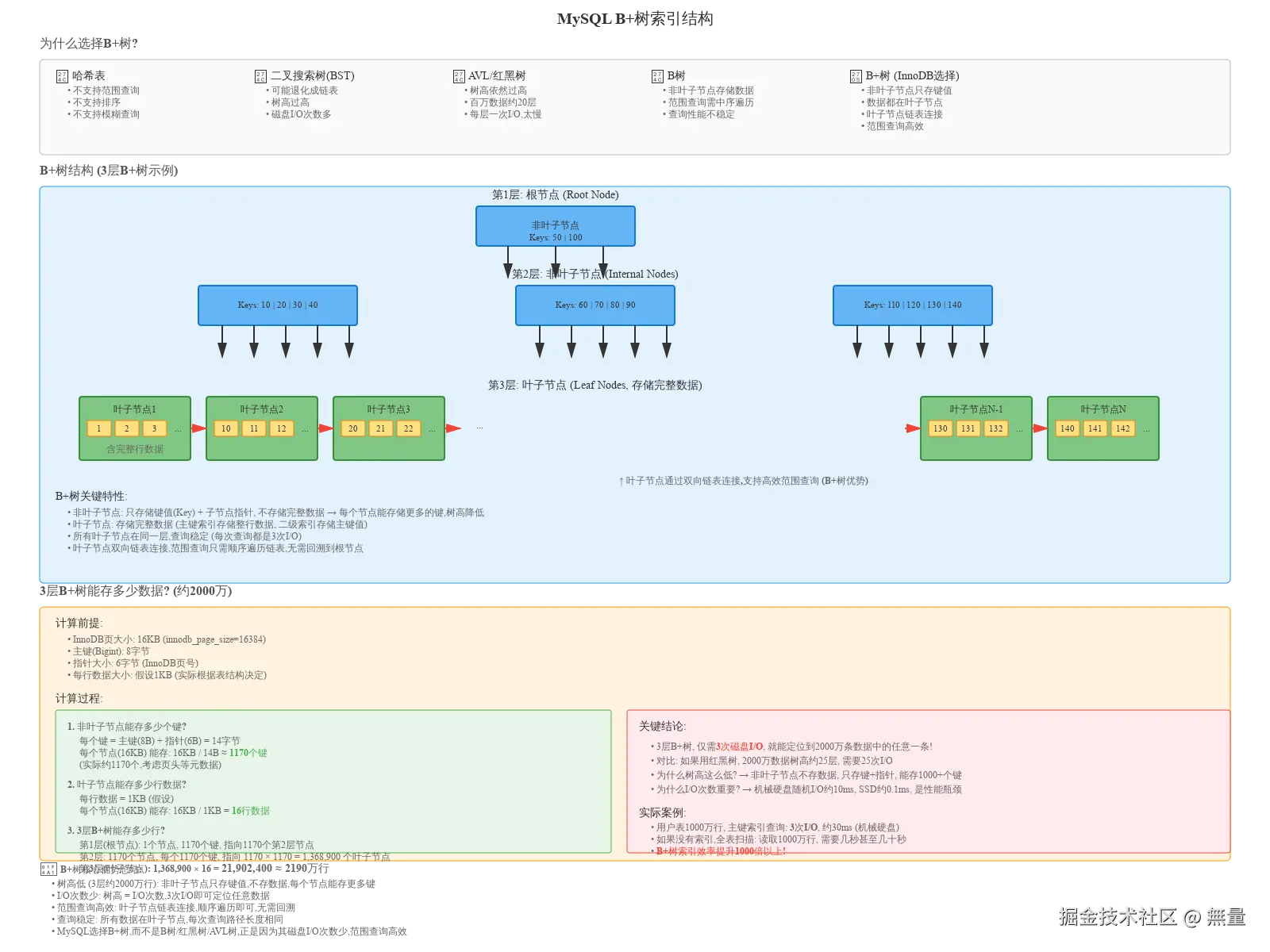
为什么MySQL选择B+树作为索引数据结构?
对比其他数据结构:
哈希表:
- ❌ 不支持范围查询:
age > 25无法使用哈希索引 - ❌ 不支持排序:
ORDER BY age无法使用哈希索引 - ❌ 不支持模糊查询:
name LIKE 'abc%'无法使用哈希索引
二叉搜索树(BST):
- ❌ 可能退化成链表: 插入顺序数据(如1,2,3,4,5)时,树变成链表
- ❌ 树高过高: 百万数据树高约20层,查询需要20次磁盘I/O
AVL树 / 红黑树:
- ❌ 树高依然过高: 百万数据树高约20层
- ❌ 磁盘I/O次数多: 每层一次I/O,太慢
B树:
- ❌ 非叶子节点存储数据: 浪费空间,每个节点存储的键值数量少
- ❌ 范围查询需要中序遍历: 需要回溯到根节点,效率低
B+树 (InnoDB选择):
- ✅ 非叶子节点只存储键值: 每个节点能存储更多键(约1170个),树高低(3层约2000万行)
- ✅ 所有数据在叶子节点: 查询稳定,每次查询路径长度相同
- ✅ 叶子节点双向链表连接: 范围查询只需顺序遍历链表,无需回溯
- ✅ 磁盘I/O次数少: 树高 = I/O次数,3次I/O即可定位任意数据
3层B+树能存多少数据?
前提条件:
- InnoDB页大小: 16KB (
innodb_page_size=16384) - 主键(Bigint): 8字节
- 指针大小: 6字节(InnoDB页号)
- 每行数据大小: 假设1KB
计算过程:
1. 非叶子节点能存多少个键?
每个键 = 主键(8B) + 指针(6B) = 14字节
每个节点(16KB) 能存: 16KB / 14B ≈ 1170个键
2. 叶子节点能存多少行数据?
每行数据 = 1KB (假设)
每个节点(16KB) 能存: 16KB / 1KB = 16行数据
3. 3层B+树能存多少行?
- 第1层(根节点): 1个节点, 1170个键, 指向1170个第2层节点
- 第2层: 1170个节点, 每个1170个键, 指向 1170 × 1170 = 1,368,900 个叶子节点
- 第3层(叶子节点): 1,368,900 × 16 = 21,902,400 ≈ 2190万行
结论 : 3层B+树, 仅需3次磁盘I/O, 就能定位到2000万条数据中的任意一条!
对比: 如果用红黑树, 2000万数据树高约25层, 需要25次I/O,性能差距1000倍以上!
为什么树高这么低?
非叶子节点不存储数据,只存储键+指针,每个节点能存储1000+个键,树的扇出(Fan-out)极大,树高极低。
为什么I/O次数重要?
磁盘随机I/O是性能瓶颈:
- 机械硬盘: 约10ms/次
- SSD: 约0.1ms/次
3次I/O约30ms,25次I/O约250ms,差距10倍!
四、一条SQL的执行流程
4.1 SELECT语句的执行流程
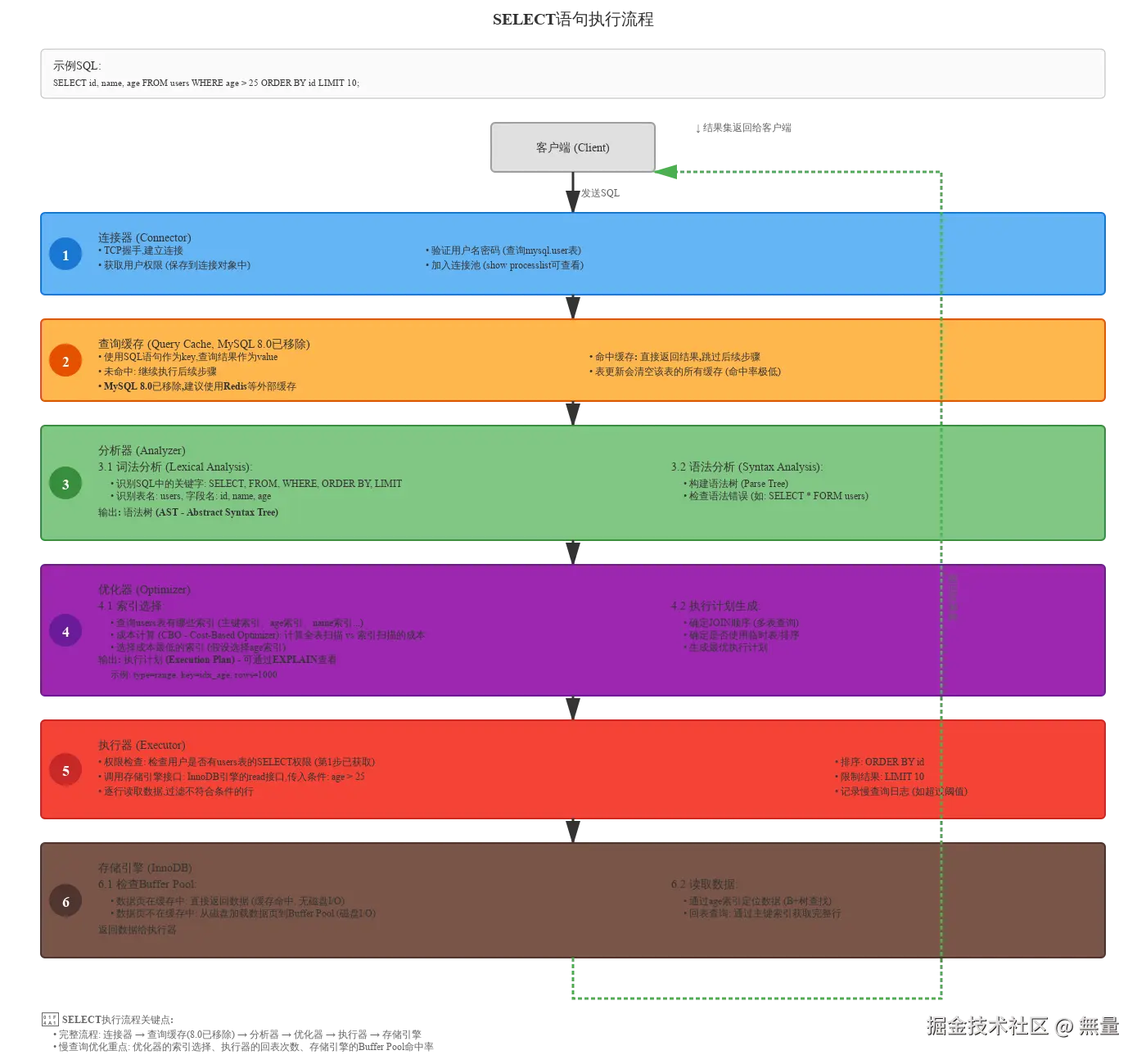
示例SQL:
sql
SELECT id, name, age FROM users WHERE age > 25 ORDER BY id LIMIT 10;完整流程:
步骤1: 连接器 (Connector)
- TCP握手,建立连接
- 验证用户名密码(查询
mysql.user表) - 获取用户权限(保存到连接对象中)
- 加入连接池(
SHOW PROCESSLIST可查看)
步骤2: 查询缓存 (Query Cache, MySQL 8.0已移除)
- 使用SQL语句作为key,查询结果作为value
- 命中缓存: 直接返回结果,跳过后续步骤
- 未命中: 继续执行后续步骤
- 表更新会清空该表的所有缓存(命中率极低)
步骤3: 分析器 (Analyzer)
3.1 词法分析 (Lexical Analysis):
- 识别SQL中的关键字: SELECT, FROM, WHERE, ORDER BY, LIMIT
- 识别表名: users, 字段名: id, name, age
3.2 语法分析 (Syntax Analysis):
- 构建语法树 (Parse Tree)
- 检查语法错误(如:
SELECT * FORM users)
输出: 语法树(AST)
步骤4: 优化器 (Optimizer)
4.1 索引选择:
- 查询users表有哪些索引(主键索引、age索引、name索引...)
- 成本计算 (CBO - Cost-Based Optimizer): 计算全表扫描 vs 索引扫描的成本
- 选择成本最低的索引(假设选择idx_age索引)
4.2 执行计划生成:
- 确定JOIN顺序(多表查询)
- 确定是否使用临时表/排序
- 生成最优执行计划
输出 : 执行计划(Execution Plan) - 可通过EXPLAIN查看
步骤5: 执行器 (Executor)
- 权限检查: 检查用户是否有users表的SELECT权限(第1步已获取)
- 调用存储引擎接口 : InnoDB引擎的read接口,传入条件:
age > 25 - 逐行读取数据: 过滤不符合条件的行
- 排序 :
ORDER BY id - 限制结果 :
LIMIT 10 - 记录慢查询日志(如超过阈值)
步骤6: 存储引擎 (InnoDB)
6.1 检查Buffer Pool:
- 数据页在缓存中: 直接返回数据(缓存命中, 无磁盘I/O)
- 数据页不在缓存中: 从磁盘加载数据页到Buffer Pool(磁盘I/O)
6.2 读取数据:
- 通过age索引定位数据(B+树查找)
- 回表查询: 通过主键索引获取完整行
返回数据给执行器 → 返回结果集给客户端
SELECT执行流程关键点:
- 完整流程: 连接器 → 查询缓存(8.0已移除) → 分析器 → 优化器 → 执行器 → 存储引擎
- 慢查询优化重点: 优化器的索引选择、执行器的回表次数、存储引擎的Buffer Pool命中率
4.2 UPDATE语句的执行流程

示例SQL:
sql
UPDATE users SET age = 26 WHERE id = 100;前5步与SELECT相同: 连接器 → 查询缓存 → 分析器 → 优化器 → 执行器
步骤6: InnoDB更新流程 (WAL + 2PC)
6.1 查找数据 (WHERE id = 100)
- 先查询Buffer Pool缓存: 数据页在缓存中,直接返回
- 数据页不在缓存: 从磁盘.ibd文件加载到Buffer Pool
6.2 写Undo Log (回滚日志)
- 记录旧值:
id=100, age=25(用于事务回滚) - 用于MVCC多版本并发控制(其他事务读取旧版本数据)
- 存储位置: Undo表空间或系统表空间(ibdata1)
6.3 更新Buffer Pool内存数据
- 在Buffer Pool中修改数据:
id=100, age=25 → age=26 - 标记数据页为"脏页" (Dirty Page)
- 此时数据只在内存中更新,尚未写入磁盘 (WAL机制核心)
6.4 写Redo Log - prepare阶段 (InnoDB引擎层)
- 先写Redo Log Buffer (内存)
- 刷盘到ib_logfile0/1 (磁盘,顺序写)
- 记录内容: "将users表id=100的age字段改为26"
- 状态: prepare (两阶段提交第1阶段)
- 作用: 崩溃恢复时,通过Redo Log重放,保证数据不丢失
参数 : innodb_flush_log_at_trx_commit=1 (每次事务提交刷盘,最安全)
6.5 写Binlog (MySQL Server层)
- Binlog是MySQL Server层的日志(所有存储引擎共享)
- 记录完整的SQL语句或行变更
- 刷盘到binlog文件(mysql-bin.000001)
- 参数 :
sync_binlog=1(每次事务提交刷盘,最安全) - 作用: 主从复制、数据备份、数据恢复(point-in-time recovery)
- Binlog格式: ROW(行模式,推荐), STATEMENT, MIXED
6.6 提交事务 - Redo Log commit阶段 (两阶段提交第2阶段)
- 将Redo Log状态从prepare改为commit
- 事务正式提交成功
- 2PC两阶段提交完成: prepare → 写Binlog → commit (保证Redo Log和Binlog一致性)
- 此时数据仍在Buffer Pool,尚未写入.ibd文件
6.7 刷脏页 (Flush Dirty Pages) - 异步后台线程
- 后台线程异步将脏页刷回磁盘 (.ibd数据文件, 随机写)
- 触发时机 :
- Redo Log满了(必须刷脏页,腾出Redo Log空间)
- Buffer Pool空间不足(淘汰脏页,需先刷盘)
- MySQL空闲时(后台线程定期刷盘)
- MySQL正常关闭时(刷所有脏页)
参数:
innodb_io_capacity=200: 刷盘IOPS能力(SSD可调高到1000-5000)innodb_max_dirty_pages_pct=75: 脏页比例阈值75%
WAL (Write-Ahead Logging) 机制核心:
为什么先写日志,再异步刷脏页?
- Redo Log顺序写 (append追加模式), 速度极快(磁盘顺序I/O约100MB/s)
- 数据文件随机写 (.ibd文件, 速度慢, 磁盘随机I/O约100次/s)
- 事务提交时只需刷Redo Log (快), 脏页异步刷盘(慢,但不阻塞事务) → 写入性能提升10-100倍
- 崩溃恢复: 重启后,通过Redo Log重放(redo),恢复未刷盘的脏页数据,保证事务持久性(Durability)
2PC (Two-Phase Commit) 两阶段提交:
为什么需要2PC? 保证Redo Log和Binlog一致性
- Redo Log (InnoDB引擎层) + Binlog (MySQL Server层) 两份日志,必须保持一致
- 2PC流程: Redo Log prepare → 写Binlog → Redo Log commit
- 崩溃恢复场景 :
- ① prepare成功,Binlog失败 → 回滚
- ② prepare成功,Binlog成功,commit失败 → 提交(通过Binlog恢复)
- 保证主从数据一致性: Binlog用于主从复制,2PC确保主库Redo Log和从库Binlog一致
UPDATE执行流程关键点:
- WAL机制: 先写日志(Redo Log/Binlog, 顺序I/O), 再异步刷脏页(数据文件, 随机I/O), 写入性能提升10-100倍
- 2PC两阶段提交: 保证Redo Log和Binlog一致性, 避免主从数据不一致
- 事务持久性保证: 事务提交后,即使立即崩溃,重启后通过Redo Log重放,数据不丢失
五、Buffer Pool缓冲池原理与优化
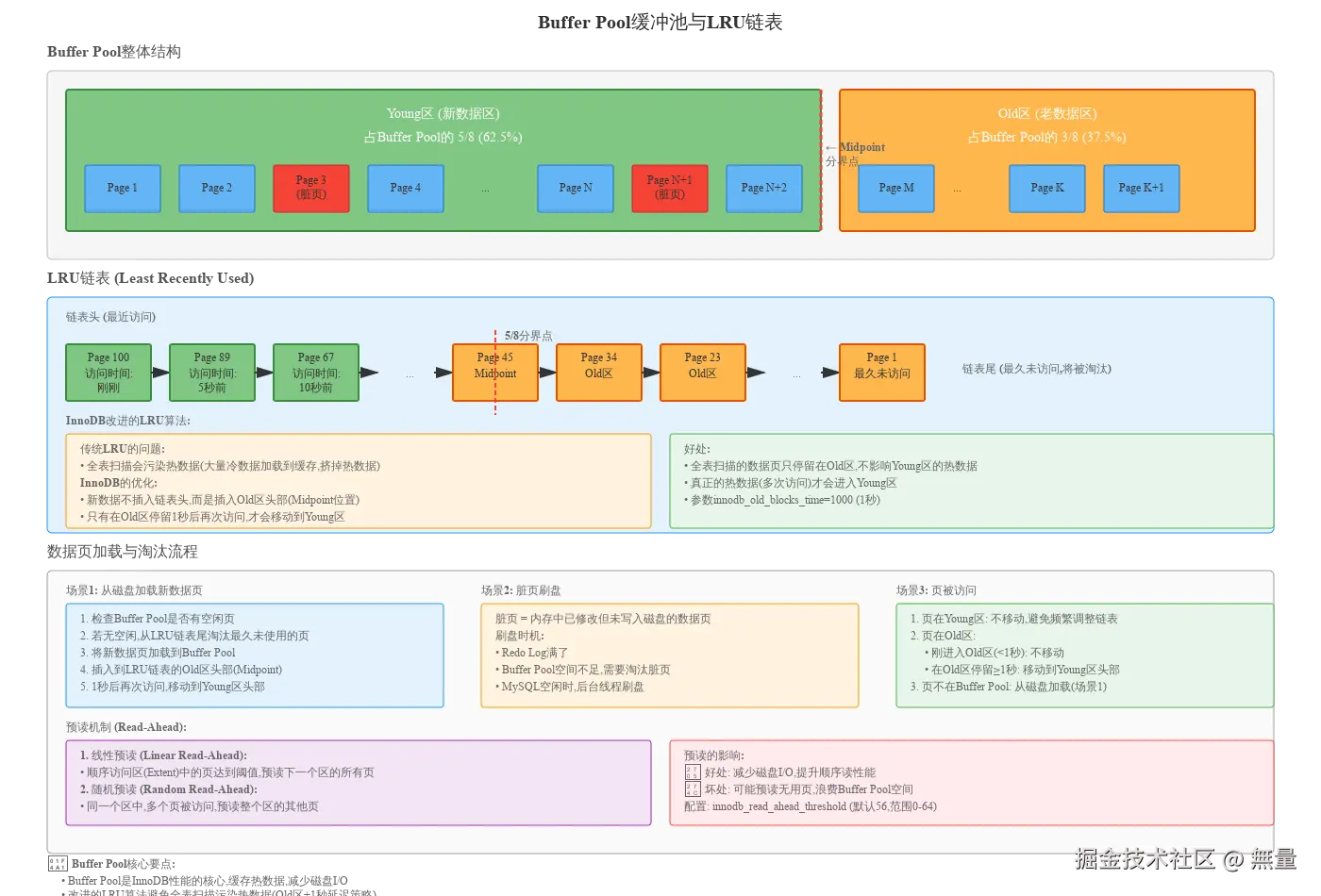
5.1 Buffer Pool整体结构
Buffer Pool是InnoDB性能的核心,缓存数据页和索引页,减少磁盘I/O。
Buffer Pool结构:
- Young区 (新数据区): 占Buffer Pool的5/8 (62.5%),存放热数据
- Old区 (老数据区): 占Buffer Pool的3/8 (37.5%),存放冷数据
- Midpoint分界点: Young区和Old区的边界
5.2 改进的LRU链表
传统LRU算法的问题:
全表扫描会将大量冷数据加载到缓存,挤掉热数据(缓存污染)。
示例:
sql
SELECT * FROM large_table; -- 全表扫描,加载几百万行数据到缓存传统LRU: 新数据插入链表头,热数据被挤到链表尾,最终被淘汰 → 缓存污染
InnoDB的改进 (Midpoint插入策略):
- 新数据页不插入链表头,而是插入Old区头部(Midpoint位置)
- 只有在Old区停留≥1秒后再次访问,才移动到Young区
- 全表扫描的数据页只停留在Old区,不影响Young区的热数据
参数:
bash
innodb_old_blocks_pct=37 # Old区占比37% (默认)
innodb_old_blocks_time=1000 # Old区停留时间1秒 (默认)好处:
- 全表扫描的数据页只停留在Old区,不影响Young区的热数据
- 真正的热数据(多次访问)才会进入Young区
- 有效防止缓存污染
5.3 数据页加载与淘汰流程
场景1: 从磁盘加载新数据页
- 检查Buffer Pool是否有空闲页
- 若无空闲,从LRU链表尾淘汰最久未使用的页
- 将新数据页加载到Buffer Pool
- 插入到LRU链表的Old区头部(Midpoint)
- 1秒后再次访问,移动到Young区头部
场景2: 脏页刷盘
- 脏页 = 内存中已修改但未写入磁盘的数据页
- 刷盘时机 :
- Redo Log满了
- Buffer Pool空间不足,需要淘汰脏页
- MySQL空闲时,后台线程刷盘
- MySQL正常关闭时
场景3: 页被访问
- 页在Young区: 不移动,避免频繁调整链表
- 页在Old区 :
- 刚进入Old区(<1秒): 不移动
- 在Old区停留≥1秒: 移动到Young区头部
- 页不在Buffer Pool: 从磁盘加载(场景1)
5.4 预读机制 (Read-Ahead)
预读机制: InnoDB预测即将访问的数据页,提前加载到Buffer Pool。
1. 线性预读 (Linear Read-Ahead):
- 顺序访问区(Extent, 64个连续页)中的页达到阈值,预读下一个区的所有页
- 参数:
innodb_read_ahead_threshold=56(默认56,范围0-64) - 适用: 全表扫描、范围查询
2. 随机预读 (Random Read-Ahead):
- 同一个区中,多个页被访问,预读整个区的其他页
- 默认关闭:
innodb_random_read_ahead=OFF
预读的影响:
- ✅ 好处: 减少磁盘I/O,提升顺序读性能
- ❌ 坏处: 可能预读无用页,浪费Buffer Pool空间
5.5 Buffer Pool核心要点
- Buffer Pool是InnoDB性能的核心,缓存热数据,减少磁盘I/O
- 改进的LRU算法避免全表扫描污染热数据(Old区+1秒延迟策略)
- 脏页异步刷盘,WAL机制保证性能和数据持久性
六、实战场景应用
6.1 使用EXPLAIN分析执行计划

EXPLAIN是SQL优化的第一步,分析执行计划,定位性能瓶颈。
关键字段:
type (访问类型,性能关键):
- ✅ system > const > eq_ref > ref (优秀,使用索引精确查找)
- ⚠️ range > index (可接受,索引范围扫描或索引全扫描)
- ❌ ALL (全表扫描,最差)
key (实际使用的索引):
- NULL: 未使用索引,需优化
- idx_name: 使用索引,性能好
rows (扫描的行数):
- 越少越好,rows过大(如>10万)需检查索引是否生效
Extra (额外信息):
- ✅ Using index: 覆盖索引,只读索引,不回表,性能最优
- ✅ Using where: 使用WHERE过滤
- ❌ Using filesort: 文件排序,性能差,需优化 → 在ORDER BY字段上建索引
- ❌ Using temporary: 使用临时表,性能差,需优化 → 在GROUP BY字段上建索引
示例1: 优秀的执行计划
sql
EXPLAIN SELECT id, name, age FROM users WHERE age = 25;结果: type=ref (优秀), key=idx_age, rows=1000
分析: 使用idx_age索引,扫描1000行,性能良好
示例2: 糟糕的执行计划
sql
EXPLAIN SELECT id, name, age FROM users WHERE YEAR(birthday) = 2000;结果: type=ALL (全表扫描), key=NULL (未使用索引), rows=5000000
问题:
- WHERE条件使用了函数
YEAR(birthday),导致索引失效 - 全表扫描500万行,性能极差
优化 : 改为 WHERE birthday BETWEEN '2000-01-01' AND '2000-12-31',可使用idx_birthday索引
示例3: 文件排序
sql
EXPLAIN SELECT id, name, age FROM users WHERE age > 25 ORDER BY birthday;结果 : type=range, key=idx_age, Extra=Using filesort
问题: ORDER BY的字段(birthday)与WHERE条件的索引(idx_age)不同,无法利用索引排序,需要额外的filesort操作
优化 : 创建联合索引idx_age_birthday(age, birthday),ORDER BY字段在索引中,避免filesort
6.2 慢查询优化实战
慢查询日志配置:
bash
slow_query_log=ON # 开启慢查询日志
long_query_time=1 # 慢查询阈值1秒
slow_query_log_file=/var/log/mysql-slow.log
log_queries_not_using_indexes=ON # 记录未使用索引的查询慢查询分析工具:
bash
# mysqldumpslow: MySQL自带的慢查询分析工具
mysqldumpslow -s t -t 10 /var/log/mysql-slow.log # 按时间排序,显示前10条
# pt-query-digest: Percona Toolkit工具(推荐)
pt-query-digest /var/log/mysql-slow.log常见慢查询场景与优化:
场景1: 索引失效 - 在索引列上使用函数
sql
-- ❌ 慢查询 (索引失效)
SELECT * FROM users WHERE YEAR(birthday) = 2000;
-- ✅ 优化 (使用索引)
SELECT * FROM users WHERE birthday BETWEEN '2000-01-01' AND '2000-12-31';场景2: 索引失效 - 隐式类型转换
sql
-- ❌ 慢查询 (name是varchar,与数字123比较,发生隐式类型转换,索引失效)
SELECT * FROM users WHERE name = 123;
-- ✅ 优化
SELECT * FROM users WHERE name = '123';场景3: 索引失效 - LIKE前缀通配符
sql
-- ❌ 慢查询 (前缀通配符,索引失效)
SELECT * FROM users WHERE name LIKE '%abc';
-- ✅ 优化 (后缀通配符,可使用索引)
SELECT * FROM users WHERE name LIKE 'abc%';场景4: 回表次数过多 - 使用覆盖索引
sql
-- ❌ 慢查询 (回表100万次)
SELECT id, name, age FROM users WHERE age > 25; -- 假设返回100万行
-- ✅ 优化 (覆盖索引,无需回表)
-- 创建联合索引 idx_age_name_id(age, name, id)
-- 或者只查询索引列
SELECT id, age FROM users WHERE age > 25;场景5: 深分页问题
sql
-- ❌ 慢查询 (扫描100万+10行,丢弃100万行)
SELECT * FROM users ORDER BY id LIMIT 1000000, 10;
-- ✅ 优化1: 使用id范围查询
SELECT * FROM users WHERE id > 1000000 ORDER BY id LIMIT 10;
-- ✅ 优化2: 延迟关联 (先查主键,再回表)
SELECT * FROM users
WHERE id IN (SELECT id FROM users ORDER BY id LIMIT 1000000, 10);场景6: 未添加必要索引
sql
-- ❌ 慢查询 (WHERE条件列无索引)
SELECT * FROM orders WHERE user_id = 123 AND status = 1;
-- ✅ 优化: 创建联合索引
ALTER TABLE orders ADD INDEX idx_user_id_status (user_id, status);七、最佳实践与总结
7.1 SQL编写规范
**1. 避免SELECT ***:
sql
-- ❌ 错误
SELECT * FROM users WHERE id = 1;
-- ✅ 正确 (只查询需要的字段)
SELECT id, name, age FROM users WHERE id = 1;好处: 减少网络传输、减少Buffer Pool占用、可能使用覆盖索引
2. WHERE条件列添加索引:
sql
-- ❌ 错误 (age列无索引)
SELECT * FROM users WHERE age > 25;
-- ✅ 正确 (添加索引)
ALTER TABLE users ADD INDEX idx_age (age);3. 避免在索引列上使用函数:
sql
-- ❌ 错误 (索引失效)
SELECT * FROM users WHERE YEAR(birthday) = 2000;
-- ✅ 正确
SELECT * FROM users WHERE birthday BETWEEN '2000-01-01' AND '2000-12-31';4. 使用LIMIT限制查询结果:
sql
-- ❌ 错误 (返回全部100万行)
SELECT * FROM users WHERE age > 25;
-- ✅ 正确 (限制返回1000行)
SELECT * FROM users WHERE age > 25 LIMIT 1000;5. 避免大事务,控制事务范围:
sql
-- ❌ 错误 (大事务,锁定时间长)
BEGIN;
UPDATE users SET age = 26 WHERE id = 1;
-- ... 执行100条SQL ...
COMMIT;
-- ✅ 正确 (拆分为多个小事务)
BEGIN;
UPDATE users SET age = 26 WHERE id = 1;
COMMIT;
BEGIN;
UPDATE users SET age = 27 WHERE id = 2;
COMMIT;7.2 索引设计最佳实践
1. 高选择性字段优先建索引:
- ✅ 选择性高: 主键、唯一键、手机号、邮箱 (每个值几乎唯一)
- ❌ 选择性低: 性别、状态、类型 (只有2-5个值)
2. 联合索引遵循最左前缀原则:
sql
-- 创建联合索引
ALTER TABLE users ADD INDEX idx_age_name (age, name);
-- ✅ 能使用索引
SELECT * FROM users WHERE age = 25; -- 使用age
SELECT * FROM users WHERE age = 25 AND name = 'Alice'; -- 使用age + name
-- ❌ 不能使用索引 (违反最左前缀原则)
SELECT * FROM users WHERE name = 'Alice'; -- name不是最左列3. 覆盖索引,避免回表:
sql
-- 查询: SELECT id, age FROM users WHERE age > 25;
-- ✅ 创建覆盖索引 (索引包含id, age)
ALTER TABLE users ADD INDEX idx_age (age); -- id是主键,自动包含在二级索引中
-- 执行计划: Extra=Using index (覆盖索引,无需回表)4. 索引列不宜过多:
- 单表索引数量建议 ≤ 5个
- 联合索引字段数量建议 ≤ 3个
- 索引过多: 影响INSERT/UPDATE/DELETE性能,占用空间
5. 定期清理无用索引:
sql
-- 查询未使用的索引 (MySQL 5.7+)
SELECT * FROM sys.schema_unused_indexes;
-- 删除无用索引
ALTER TABLE users DROP INDEX idx_unused;7.3 Buffer Pool调优
1. 合理设置Buffer Pool大小:
bash
innodb_buffer_pool_size=8G # 建议:物理内存的50-80%监控Buffer Pool命中率:
sql
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';
-- 计算命中率
Buffer Pool命中率 = (Innodb_buffer_pool_read_requests - Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests
-- 建议: 命中率 ≥ 99%2. 多实例减少锁竞争:
bash
innodb_buffer_pool_instances=8 # Buffer Pool实例数,默认8 (≥1GB时生效)7.4 日志参数调优
1. Redo Log配置:
bash
innodb_log_file_size=1G # Redo Log单个文件大小
innodb_log_files_in_group=2 # Redo Log文件数量
innodb_flush_log_at_trx_commit=1 # 刷盘策略:
# 0: 每秒刷盘一次 (性能最好,但可能丢失1秒数据)
# 1: 每次事务提交刷盘 (最安全,推荐)
# 2: 每次提交写OS缓存,每秒刷盘 (折中)2. Binlog配置:
bash
sync_binlog=1 # 每次事务提交刷盘(最安全)
binlog_format=ROW # ROW模式(推荐),记录行变更
expire_logs_days=7 # Binlog保留7天7.5 总结
MySQL架构核心要点:
- 逻辑架构分为3层: 连接层、SQL层(Server层)、存储引擎层,Server层与存储引擎解耦
- InnoDB是默认引擎: 支持事务、行级锁、外键、崩溃恢复、MVCC,生产环境首选
- Buffer Pool是性能核心: 缓存数据页和索引页,减少磁盘I/O,改进的LRU算法防止缓存污染
- B+树索引结构: 3层B+树能存2000万行,查询只需3次I/O,范围查询高效
- WAL机制: 先写日志(Redo Log/Binlog),再异步刷脏页,写入性能提升10-100倍
- 2PC两阶段提交: 保证Redo Log和Binlog一致性,避免主从数据不一致
- EXPLAIN是SQL优化第一步: 分析执行计划,定位性能瓶颈,type达到ref以上,避免全表扫描和Using filesort
性能优化建议:
- 合理设计索引: 高选择性字段优先,遵循最左前缀原则,使用覆盖索引避免回表
- 避免索引失效: 不在索引列上使用函数,避免隐式类型转换,LIKE避免前缀通配符
- 合理配置Buffer Pool: 设置为物理内存的50-80%,监控命中率≥99%
- 使用EXPLAIN分析每条SQL: 上线前必须EXPLAIN,确保type达到ref以上
- 定期Review慢查询日志: 发现性能瓶颈,及时优化
掌握MySQL架构原理与执行流程,是每位后端工程师的必备技能。通过深入理解MySQL的内部运行机制,结合EXPLAIN执行计划分析和慢查询优化实战,能够在面试和实际工作中游刃有余,构建高性能、高可用的数据库系统。
参考资料:
- 《MySQL技术内幕: InnoDB存储引擎》(第2版) - 姜承尧
- 《高性能MySQL》(第4版) - Baron Schwartz等
- MySQL官方文档: dev.mysql.com/doc/
- InnoDB存储引擎官方文档: dev.mysql.com/doc/refman/...