文章目录
-
- [📚 这篇到底想讲清楚什么(先给你一张"路线图")](#📚 这篇到底想讲清楚什么(先给你一张"路线图"))
- 第一部分:计算机视觉的处理层次------从像素到理解
- [第二部分:两大主线------几何理解 vs 语义理解](#第二部分:两大主线——几何理解 vs 语义理解)
- 第三部分:方法论演进------从手工特征到端到端学习
- 第四部分:核心挑战与解决方案
- [📝 本章总结(Summary)](#📝 本章总结(Summary))
- 附:知识体系全景图
-
- 从低层到高层的完整流程
- [传统方法 vs 深度学习方法](#传统方法 vs 深度学习方法)
- 应用领域全景
- 附:术语小词典(Glossary)
-
- [语义鸿沟(Semantic Gap)](#语义鸿沟(Semantic Gap))
- [几何理解(Geometric Understanding)](#几何理解(Geometric Understanding))
- [语义理解(Semantic Understanding)](#语义理解(Semantic Understanding))
- [端到端学习(End-to-End Learning)](#端到端学习(End-to-End Learning))
- [层次化表示(Hierarchical Representation)](#层次化表示(Hierarchical Representation))
- [迁移学习(Transfer Learning)](#迁移学习(Transfer Learning))
- [域适应(Domain Adaptation)](#域适应(Domain Adaptation))
⏱️ 预计阅读时间 :30-35分钟
🎯 学习目标:理解计算机视觉的整体框架,掌握从低层图像处理到高层语义理解,从几何重建到语义识别的完整知识体系
📚 这篇到底想讲清楚什么(先给你一张"路线图")
计算机视觉回答一个根本问题:如何让计算机像人一样"看懂"图像?从像素值到语义理解,从几何结构到场景理解,这是一个多层次的认知过程。
你只需要抓住 4 件事:
- 处理层次:从低层(像素)到中层(特征)到高层(语义)的递进
- 两大主线:几何理解(3D结构)vs 语义理解(识别分类)
- 方法论演进:从手工设计到端到端学习的范式转变
- 核心挑战:语义鸿沟、几何歧义、计算效率的权衡
目标:让计算机看懂图像 处理层次
低层→中层→高层 几何理解
3D结构重建 语义理解
识别分类 传统方法
手工特征 深度学习方法
端到端学习
第一部分:计算机视觉的处理层次------从像素到理解
一、核心问题:图像理解是一个多层次的认知过程
计算机视觉的本质可以用一句话说清楚:从像素值(数字矩阵)到语义理解("这是一只猫")是一个多层次的认知过程,每一层都在提取不同抽象程度的信息。
低层:像素值
0-255的数字矩阵 中层:特征
边缘/角点/纹理 高层:语义
物体/场景/行为 图像形成
光→像素 图像处理
滤波/变换 特征检测
Harris/SIFT 语义理解
分类/分割/检测
二、低层处理:从光到像素
图像形成回答了最基础的问题:场景中的光如何变成像素中的数字?
场景中的光 相机系统
针孔/镜头 传感器
曝光参数 像素值
0-255
核心洞察:
- 像素值是"这个位置收到了多少光"的记录
- 清晰成像需要限制光线方向(针孔/镜头)
- 曝光参数(光圈/快门/ISO)控制亮度,但都有代价
三、中层处理:从像素到特征
图像处理 和特征检测提取图像中的结构信息:
图像处理 几何变换
改位置 滤波
改值 边缘/直线检测
结构提取 对齐/校正/拼接 去噪/增强 轮廓/结构 特征检测 Harris角点
局部特征 SIFT
尺度不变特征 特征匹配
建立对应
核心洞察:
- 几何变换改变像素位置(坐标映射),用于对齐和校正
- 滤波改变像素值(局部邻域操作),用于去噪和增强
- 特征检测找到稳定、可重复的点,用于建立图像对应
四、高层处理:从特征到语义
语义理解将特征映射到语义概念:
特征表示 图像分类
识别类别 语义分割
像素级分类 目标检测
定位+分类 实例分割
检测+分割 语义理解
这是什么?
核心洞察:
- 语义鸿沟:像素值与语义理解之间的巨大差距
- 需要从数据中学习特征表示,而不是手工设计
- 深度学习通过端到端学习自动提取特征
第二部分:两大主线------几何理解 vs 语义理解
一、核心问题:计算机视觉的两大目标
计算机视觉有两个根本目标:理解几何结构 (3D重建)和理解语义内容(识别分类)。这两个目标相互独立又相互补充。
计算机视觉 几何理解
3D结构 语义理解
识别分类 相机投影
3D→2D映射 立体视觉
2D→3D重建 SfM
多视图重建 图像分类
识别类别 目标检测
定位+分类 语义分割
像素级分类
二、几何理解:从2D恢复3D
几何理解关注的是空间结构,回答"在哪里"和"什么形状"的问题。
单视图
只能知道方向 双视图
可以测量距离 多视图
重建完整场景 相机投影
透视投影/内参/外参 极线约束
基础矩阵/三角化 SfM
Bundle Adjustment/MVS
核心洞察:
- 单视图只能知道3D点位于某条射线上,无法确定距离
- 双视图通过极线约束和三角化可以测量距离
- 多视图通过SfM可以重建完整场景结构
关键挑战:
- 几何歧义:从2D恢复3D存在固有歧义
- 对应问题:需要在多视图间建立点对应
- 优化问题:Bundle Adjustment需要同时优化相机参数和3D点
三、语义理解:从像素到概念
语义理解关注的是内容识别,回答"是什么"的问题。
像素值
0-255的数字 特征表示
手工/学习 语义概念
猫/狗/鸟 传统方法
手工特征 深度学习方法
端到端学习 图像分类
整图→类别 目标检测
定位+分类 语义分割
像素→类别
核心洞察:
- 语义鸿沟:像素值与语义概念之间的巨大差距
- 特征表示是关键:从手工设计(SIFT、HOG)到自动学习(CNN)
- 深度学习通过多层非线性变换学习层次化特征
关键挑战:
- 语义鸿沟:如何从像素值提取语义信息
- 泛化能力:如何学习对变换不变的通用模式
- 计算效率:如何在精度和速度之间权衡
四、两大主线的融合
虽然几何理解和语义理解关注不同层面,但它们可以相互补充:
几何理解
3D结构 场景理解
完整认知 语义理解
识别分类 语义SLAM
结合几何和语义 增强现实
AR应用 机器人导航
理解环境
融合应用:
- 语义SLAM:同时进行3D重建和语义标注
- 增强现实:需要几何对齐和语义理解
- 机器人导航:需要理解空间结构和语义内容
第三部分:方法论演进------从手工特征到端到端学习
一、核心问题:如何从数据中提取有用信息
计算机视觉的方法论经历了从手工设计特征 到端到端学习的范式转变。
传统方法
手工设计 深度学习
端到端学习 特征工程
SIFT/HOG 分类器
SVM/KNN 特征学习
CNN自动提取 端到端训练
联合优化 问题:
需要专业知识
泛化能力有限 优势:
自动学习
泛化能力强
二、传统方法:手工设计特征
传统方法 的核心思想是:先手工设计特征,再用简单分类器分类。
图像 特征提取
SIFT/HOG/边缘 特征描述
直方图/统计量 分类器
SVM/KNN 类别标签
传统方法的优势:
- 可解释性强:特征有明确的物理意义
- 计算效率高:特征维度相对较小
- 适合小数据集:不需要大量训练数据
传统方法的局限:
- 需要专业知识:特征设计依赖领域知识
- 泛化能力有限:手工特征可能不适合新任务
- 表达能力有限:难以捕捉复杂的非线性模式
三、深度学习方法:端到端学习
深度学习方法 的核心思想是:让网络自动学习特征表示,端到端优化整个系统。
图像 CNN特征提取
自动学习 多层非线性变换
层次化特征 分类/检测/分割
端到端训练 语义输出
深度学习的优势:
- 自动学习特征:不需要手工设计
- 层次化表示:从低层到高层逐层抽象
- 端到端优化:整个系统联合优化
- 泛化能力强:在大数据集上训练后可以迁移
深度学习的挑战:
- 需要大量数据:通常需要百万级图像
- 计算资源需求高:需要GPU加速
- 可解释性差:特征表示难以解释
- 训练困难:需要解决梯度消失、过拟合等问题
四、从线性分类器到深度网络
方法论演进反映了对问题复杂度的认识:
线性分类器
只能学习线性边界 神经网络
多层非线性 CNN
保留空间结构 深度CNN
ResNet/GoogLeNet 问题:XOR无法解决 解决:非线性模式 解决:空间结构 解决:深度网络训练
关键演进:
- 线性分类器:只能学习线性决策边界,无法处理XOR问题
- 神经网络:通过多层非线性变换学习复杂模式
- CNN :保留图像空间结构,参数共享提高效率
- 深度CNN:通过残差连接、批量归一化等技术训练非常深的网络
XOR:线性不可分的核心特征
shell
x₂(第二个输入)
|
1 | ● 红(0,1)=1 ○ 蓝(1,1)=0
|
0 | ○ 蓝(0,0)=0 ● 红(1,0)=1
|______________________
0 1 x₁(第一个输入)
🔍 关键说明:
• 蓝色○:输出为0的点 (0,0)、(1,1)
• 红色●:输出为1的点 (0,1)、(1,0)
• 👉 无法画一条直线把○和●完全分开
• 这就是「线性不可分」的核心特征五、训练深层网络的关键技术
训练深层网络需要解决多个问题:
深层网络训练 梯度消失
信号衰减 训练不稳定
分布变化 过拟合
记忆训练数据 ReLU激活
批量归一化
残差连接 批量归一化
权重初始化 正则化
Dropout
数据增强
关键技术:
- 激活函数:ReLU保证梯度流动,避免梯度消失
- 批量归一化:稳定每层输入分布,允许更高学习率
- 残差连接:解决深度网络的退化问题
- 正则化:L2正则化、Dropout、数据增强防止过拟合
- 优化器:Momentum、Adam改进梯度下降效率
第四部分:核心挑战与解决方案
一、语义鸿沟:从像素到语义
语义鸿沟 是计算机视觉最根本的挑战:像素值(数字矩阵)与语义理解("这是一只猫")之间的巨大差距。
像素值
0-255的数字矩阵 语义鸿沟
巨大差距 语义理解
猫/狗/鸟 传统方法
手工特征 问题:
特征设计困难
泛化能力有限 深度学习方法
自动学习特征 解决:
端到端学习
层次化表示
解决方案:
- 特征学习:让网络自动学习从像素到语义的映射
- 层次化表示:从低层(边缘)到中层(纹理)到高层(语义)逐层抽象
- 大规模数据:在百万级图像上学习通用模式
二、几何歧义:从2D恢复3D
几何歧义 是几何理解的核心挑战:从2D图像恢复3D结构存在固有歧义。
单视图
只能知道方向 几何歧义
无法确定距离 双视图
极线约束+三角化 多视图
SfM重建 挑战:
对应问题
优化困难 解决:
特征匹配
RANSAC
Bundle Adjustment
解决方案:
- 多视图:使用多个视角消除歧义
- 极线约束:将2D搜索降低到1D搜索
- 特征匹配:SIFT等不变特征建立对应
- RANSAC:去除误匹配
- Bundle Adjustment:联合优化相机参数和3D点
三、计算效率:精度与速度的权衡
计算效率 是实际应用的关键:如何在精度和速度之间找到平衡。
计算效率 精度
准确识别 速度
实时处理 深度网络
高精度但慢 轻量网络
快速但精度低 解决方案:
模型压缩
知识蒸馏
硬件加速
解决方案:
- 模型压缩:剪枝、量化减少模型大小
- 知识蒸馏:用大模型指导小模型
- 硬件加速:GPU、TPU、专用芯片
- 算法优化:单阶段检测器(YOLO)vs 两阶段检测器(R-CNN)
四、泛化能力:从训练数据到新场景
泛化能力 是模型成功的关键:如何让模型在新场景、新数据上表现良好。
训练数据
有限场景 泛化能力
新场景表现 挑战:
过拟合
域适应 解决:
正则化
数据增强
迁移学习
解决方案:
- 正则化:L2正则化、Dropout防止过拟合
- 数据增强:通过变换增加数据多样性
- 迁移学习:在大数据集上预训练,在小数据集上微调
- 域适应:适应不同数据分布
📝 本章总结(Summary)
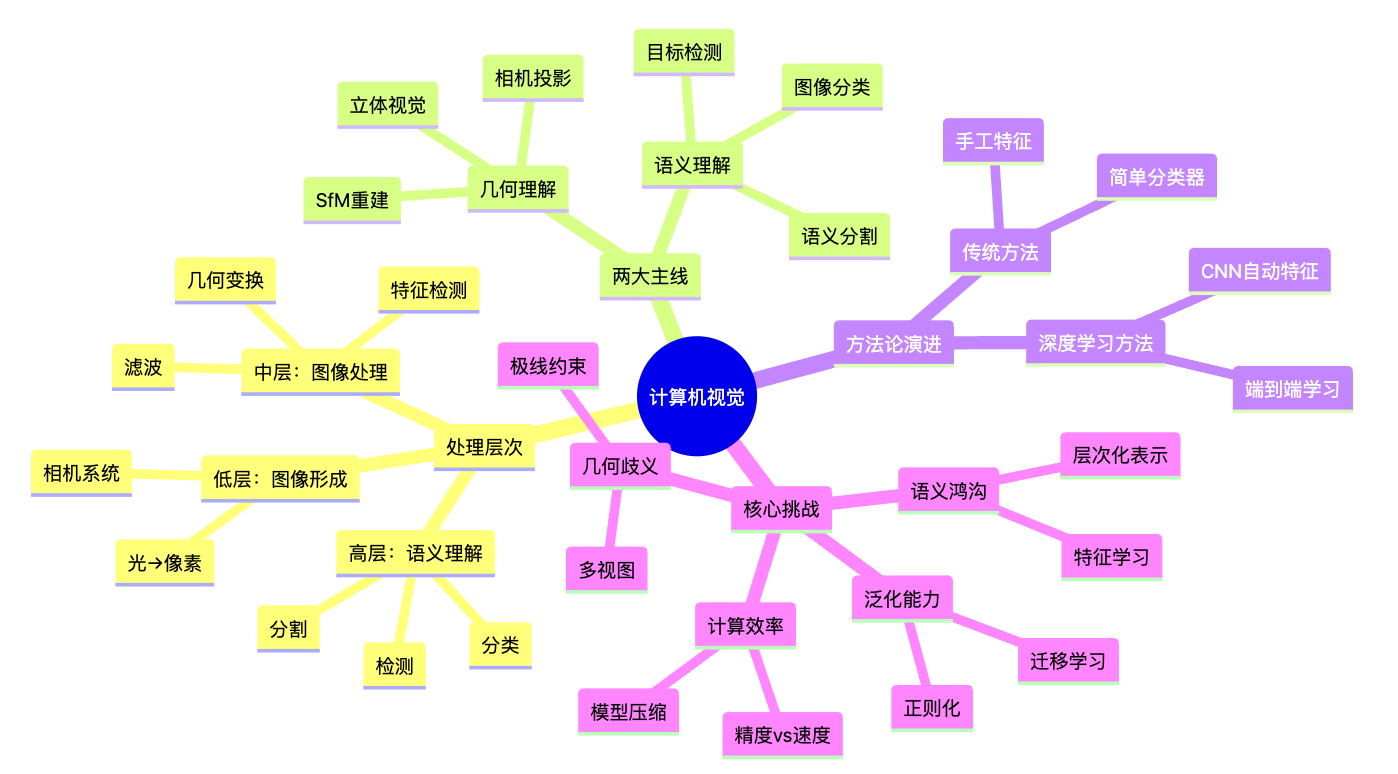
核心要点
-
处理层次:计算机视觉是一个从低层(像素)到中层(特征)到高层(语义)的递进过程,每一层提取不同抽象程度的信息
-
两大主线:几何理解关注3D结构重建,语义理解关注内容识别分类,两者相互独立又相互补充
-
方法论演进:从手工设计特征到端到端学习的范式转变,深度学习通过自动学习特征和层次化表示解决了语义鸿沟问题
-
核心挑战:语义鸿沟、几何歧义、计算效率、泛化能力是计算机视觉的核心挑战,需要综合运用多种技术解决
附:知识体系全景图
从低层到高层的完整流程
传统方法 vs 深度学习方法
传统方法 手工特征
SIFT/HOG 简单分类器
SVM/KNN 深度学习方法 自动特征
CNN学习 端到端训练
联合优化 优势:可解释
劣势:泛化差 优势:泛化强
劣势:需数据
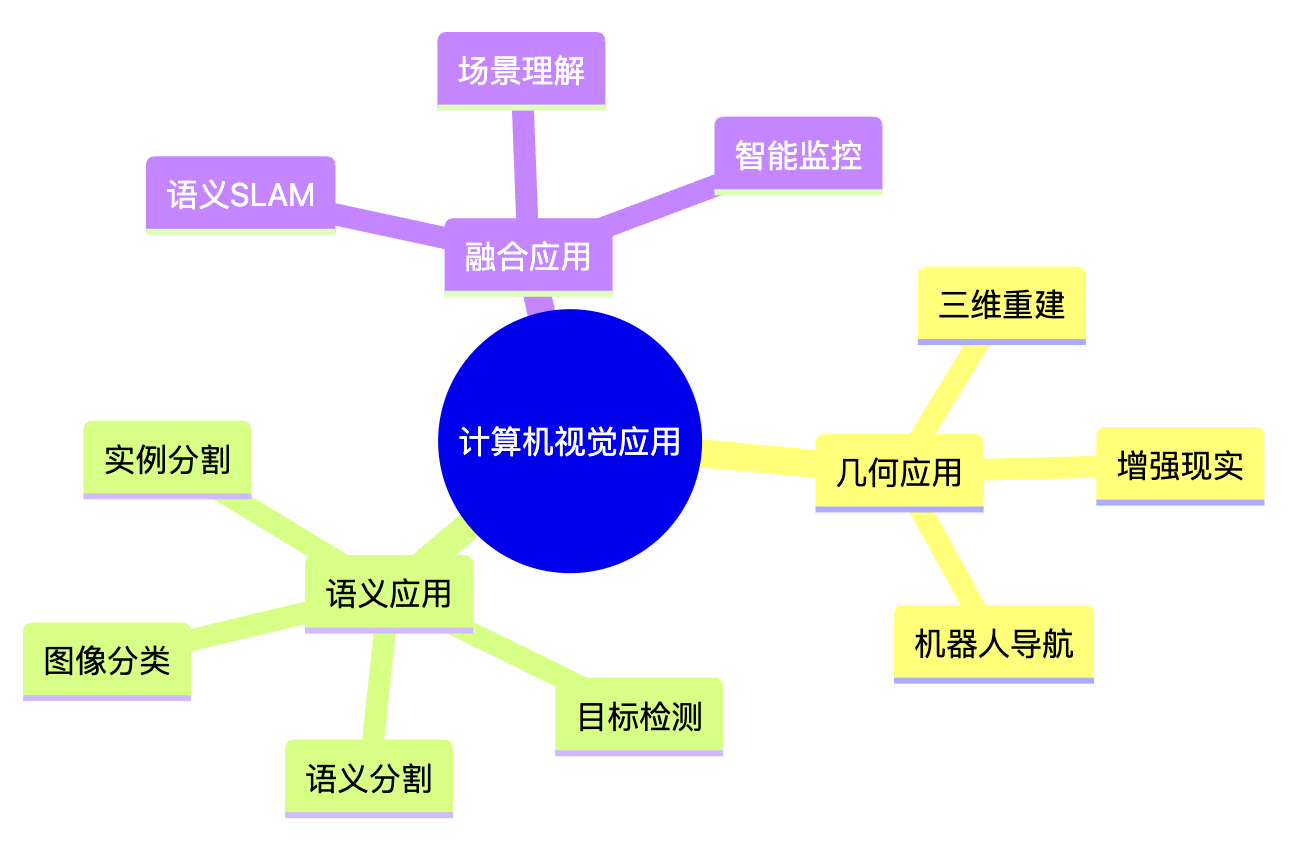
应用领域全景
附:术语小词典(Glossary)
语义鸿沟(Semantic Gap)
像素值(数字矩阵)与语义理解(如"猫"、"狗")之间的巨大差距。这是计算机视觉最根本的挑战,需要通过特征学习来桥接。
几何理解(Geometric Understanding)
关注空间结构和3D重建的计算机视觉任务,回答"在哪里"和"什么形状"的问题。包括相机投影、立体视觉、SfM等。
语义理解(Semantic Understanding)
关注内容识别和分类的计算机视觉任务,回答"是什么"的问题。包括图像分类、目标检测、语义分割等。
端到端学习(End-to-End Learning)
让网络自动学习从输入到输出的完整映射,整个系统联合优化。与传统方法的手工设计特征不同,深度学习通过端到端学习自动提取特征。
层次化表示(Hierarchical Representation)
从低层(边缘、纹理)到中层(局部模式)到高层(语义概念)逐层抽象的特征表示。CNN通过多层卷积自动学习层次化表示。
迁移学习(Transfer Learning)
在大数据集上预训练模型,然后在小数据集上微调。这允许模型利用大规模数据学习通用特征,然后适应特定任务。
域适应(Domain Adaptation)
让模型适应不同数据分布的技术。例如,在合成数据上训练的模型适应真实数据,或在一种场景下训练的模型适应另一种场景。