目录
[二、为什么不能直接微调 DeepSeek-R1?(成本与数据的现实限制)](#二、为什么不能直接微调 DeepSeek-R1?(成本与数据的现实限制))
[四、DeepSeek-R1 与 DeepSeek-V3:两代模型的能力差异与适用性分析](#四、DeepSeek-R1 与 DeepSeek-V3:两代模型的能力差异与适用性分析)
[✦ DeepSeek-R1:](#✦ DeepSeek-R1:)
[✦ DeepSeek-V3:](#✦ DeepSeek-V3:)
[五、如何用 R1 帮助行业构建"小而强"的专科模型?](#五、如何用 R1 帮助行业构建“小而强”的专科模型?)
[(一)选择一个 7B--70B 的基础学生模型](#(一)选择一个 7B–70B 的基础学生模型)
[(二)用 R1 作为教师模型蒸馏](#(二)用 R1 作为教师模型蒸馏)
[(三)再用高质量行业数据做 SFT 微调](#(三)再用高质量行业数据做 SFT 微调)
[六、DeepSeek 开源的真正价值:能力迁移,而非参数竞赛](#六、DeepSeek 开源的真正价值:能力迁移,而非参数竞赛)
干货分享,感谢您的阅读!
大语言模型的技术浪潮以惊人的速度奔涌向前,但行业真正关心的问题只有一个:如何把模型的"深度思考能力"落地到真实业务中。
过去几年,无论是 GPT 系列、Llama 系列,还是国内各类基础模型,大家都在追求"更大参数、更好性能"。但当我们把模型真正落地到医疗、金融、政务、制造等场景时才发现,一味追求大模型无法解决核心矛盾:
-
现实数据不足;
-
私有化部署成本高;
-
业务场景更需要高逻辑、高稳定而非单纯高参数。
DeepSeek 系列模型,尤其是 DeepSeek-R1 与其蒸馏家族(如 DeepSeek-R1-Distill-Llama-70B、DeepSeek-R1-Distill-Qwen-14B),让我们第一次真正看到了"把深度推理迁移给小模型"的可能性。
我们将从 蒸馏原理 → R1 的价值 → 小模型为何需要深度思考能力 → R1 与 V3 对比 → 行业落地策略 做系统解析。
一、为什么蒸馏会成为行业落地的关键技术?
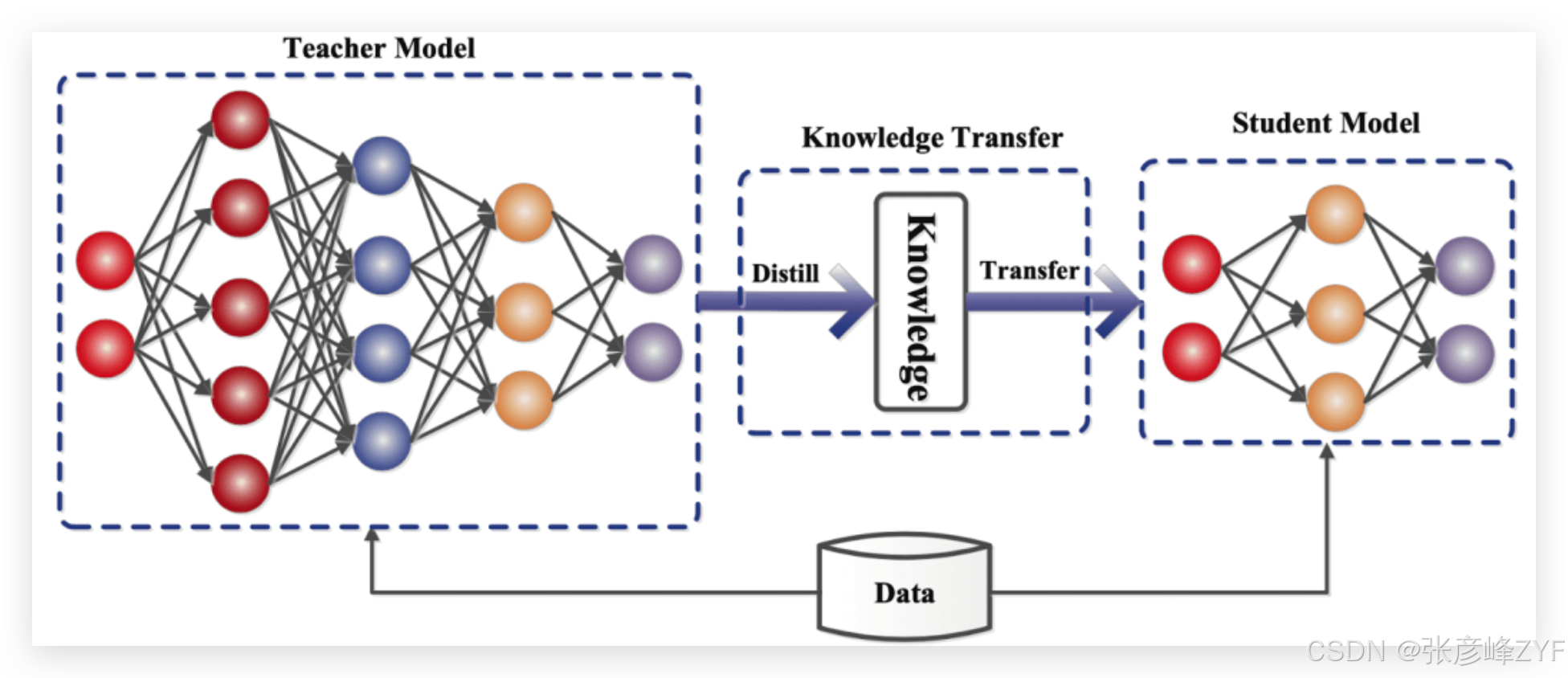
大模型蒸馏(Distillation)本质上是:
让一个能力强的教师模型(如 DeepSeek-R1)把推理、知识、决策能力"教"给参数更小的学生模型(如 Qwen-14B、Llama-70B)。
蒸馏流程一般包括:
-
教师模型生成"高质量示范"(解题链路、思考过程、结论)
-
学生模型通过监督微调(SFT)学习这些示范
-
学生在更小的参数规模下学到稳定的推理与思考策略
这意味着:
-
学生模型仍然是 Qwen-14B、Llama-70B 的结构;
-
但其行为能力会大幅提升;
-
且部署开销远小于 671B 的 R1。
随着蒸馏的成熟,小模型第一次具备了"像大模型一样思考"的可能。
二、为什么不能直接微调 DeepSeek-R1?(成本与数据的现实限制)
DeepSeek-R1 唯一官方版本是 671B 参数,即 6710 亿参数。如果要对它进行行业微调,需要面对以下直观难题:
(一)样本需求巨大
要有效微调 671B 模型,通常需要 数百万到数十亿条样本。
但在医疗、金融等场景里,真正可用、合法、安全的专业数据往往只有几万到几十万条。
(二)算力预算惊人
微调 R1 需要至少 1600GB 显存 ≈ 20 张 A100 80GB
-
单卡约 8--9 万
-
20 张需要 160--180 万人民币
对大多数医院、金融机构、中小企业来说几乎不存在现实可行性。
因此,行业落地不可能依赖"直接微调 R1",而必须用"R1 → 蒸馏 → 小模型增强"的方式来完成能力迁移。
三、小模型微调为何过去效果一般?蒸馏提供了什么突破?
行业 7B--70B 模型(如 Llama-13B、Qwen-7B、70B)过去之所以表现不理想,原因主要包括:
-
缺乏真实推理能力(只能"快速反应",不能"深度思考")
-
训练数据结构不够"严谨、专业、可解释"
-
行业知识难以覆盖
-
传统微调无法赋予复杂推理链路
但蒸馏带来的变化是根本性的:
小模型不必自己学会推理,它可以直接学会 R1 的推理方式。
这就是为什么像 DeepSeek-R1-Distill-Qwen-14B 这类模型表现会远超原生 Qwen-14B:它继承了 R1 的"思考框架",而不只是语言能力。
四、DeepSeek-R1 与 DeepSeek-V3:两代模型的能力差异与适用性分析
为了理解为何行业蒸馏更偏向 R1,而不是 V3,我们必须先弄清两者的定位差异。
(一)核心定位不同
✦ DeepSeek-R1:
-
定位:深度推理、结构化思考的专家型模型
-
特点:链式思维(CoT)、内部推理、过程监督(Process Supervision)
-
擅长:数学、规划、逻辑决策、多步骤任务分解、专业分析
✦ DeepSeek-V3:
-
定位:通用型、全能型基础大模型
-
特点:语言能力强、知识全面、生成自然
-
擅长:对话、文案、翻译、通用问答、知识整合
一句话总结:
R1 像"擅长逻辑和推理的数学教授",V3 像"知识全面、表达流畅的通用智者"。
(二)技术路线差异
| 对比点 | DeepSeek-R1 | DeepSeek-V3 |
|---|---|---|
| 核心目标 | 推理能力最强 | 全能、稳定、覆盖广 |
| 训练重点 | 过程监督、多步思考、链式推理 | 大规模训练、语言通用性 |
| 输出风格 | 逻辑链路清晰,可解释 | 平滑自然,贴近人类对话 |
| 典型表现 | 难题、逻辑、工具调用强 | 内容生成、写作能力突出 |
(三)哪个更适合做行业蒸馏的"老师"?
毫无疑问,是 R1 。
原因很清楚:
-
行业场景更需要"怎么判断""怎么推理"
-
不是"写得像人",而是"答得更准、想得更严谨"
因此:
要把深度思考迁移给小模型 → 选择 R1;
要提升小模型内容生成质量 → 选择 V3。
五、如何用 R1 帮助行业构建"小而强"的专科模型?
对于医疗专科(呼吸科、口腔科)、金融分析(行业研报、监管问答)、法律合规等任务,通常建议:
(一)选择一个 7B--70B 的基础学生模型
如:
-
Qwen 14B / 32B
-
Llama 34B / 70B
-
Yi 34B
-
InternLM 20B
(二)用 R1 作为教师模型蒸馏
蒸馏效果包括:
-
学到推理流程
-
学到思维拆解
-
学到专业判断方式
(三)再用高质量行业数据做 SFT 微调
例如:
-
医疗问诊对
-
病例摘要
-
金融研报总结
-
法律条款判断
(四)部署于私有环境
小模型参数量适中,可落地院内、银行内、政府私有云,无需 20 张 A100。
结果是:
你得到一个具备 R1 思考方式的"小巨人"。
六、DeepSeek 开源的真正价值:能力迁移,而非参数竞赛
DeepSeek-R1 的出现并不是为了让所有企业都尝试部署 671B 模型,而是为了:
-
把高级思考能力外溢给更小的模型
-
给行业小模型提供"推理上的加速器"
-
让 7B--70B 模型也能"像大模型一样思考"
从此,行业模型的落地路径变成:
大模型负责"教",小模型负责"干"
大模型贵,但小模型能部署
大模型思考,小模型执行
这才是真正意义上的产业革命。
七、结语:让深度思考真正走进行业
蒸馏 + 小模型微调,让我们第一次拥有了"既便宜又强大"的行业模型路线:
-
能部署
-
能推理
-
成本可控
-
数据可控
-
可解释、可审计、安全可控
DeepSeek 的开源价值,不在于让你部署 671B 的模型,而在于:
让你能用 14B、34B、70B 的模型,完成过去必须依靠超大模型才能完成的任务。
至此,我们真正找到了**"深度思考能力的普惠路径"。**